
基于手机信令的交通出行特征分析
——以日照市为例
2023-11-22 09:27李秋曼
现代交通技术 2023年5期
李秋曼
[华交科(上海)规划设计有限公司,上海 200433]
利用手机信令数据能够较完整地识别手机用户的出行信息,可进一步应用于人口规模、职住分布、出行特征等指标的分析,进而更全面地把握城市交通现状特征。近年来,对手机信令数据的分析和应用逐渐增多,手机信令数据分析在样本量、覆盖范围、更新周期上与传统居民出行调查相比更具优势,是当前交通数据采集的重要补充手段[1-2]。手机信令数据的处理技术已相对成熟,基于信令数据的研究已从方法和技术的研究逐步转入实践应用。文献[3-5]对通过手机信令数据获取信息的主要方法进行了梳理;张天然[6]将手机信令数据应用到上海市的职住空间研究及通勤分析中;丘建栋等[7]利用手机信令数据的时空信息,对深圳市交通出行特征进行分析。
本项目以手机信令数据为研究对象,梳理数据处理流程及主要算法,研究关键参数确定方法,并结合实例提取案例城市的有关特征指标。
1 数据处理
1.1 数据格式
手机信令数据产生于用户手机端与无线通信网络的互动联系中,两者之间用于感知控制的信号即信令。信令依靠运营商的基站进行传递,基站将捕获的数据,如手机编号、通信时间、通信类型和基站编号传回运营商数据后台,由此生成具有时空属性的信令数据记录,每条信令数据记录包括移动用户识别号、时间戳、位置区编号等字段信息。信令数据字段如表1 所示。

表1 信令数据字段
1.2 数据清洗
基于通信网络产生的原始信令数据,有很多无效数据,如一人多卡数据、乒乓数据、漂移数据等,无效数据会影响数据处理的效率和质量,可通过数据清洗处理无效数据。
(1) 一人多卡数据清洗。同一用户多个同运营商的手机卡,通过计算多个加密移动用户识别号的轨迹重合度进行去重。
(2) 乒乓数据清洗。在邻近基站交叉覆盖区域,手机数据会在基站间频繁切换,产生乒乓效应。具体处理方法是将用户在乒乓效应发生期间连接次数最多的基站设为主基站,剔除乒乓效应期间产生的信令数据中主基站以外的记录,完成对数据的清洗。
(3) 漂移数据清洗。数据漂移是指移动通信用户数据突然从邻近基站切换至远处基站,一段时间后又切回邻近基站的情况。具体处理方法是根据每条信令记录的停留时间、停留位置及其下一条记录的停留时间、停留位置,剔除短时间内发生大位移的信令记录。
1.3 有效轨迹点算法
将经过数据清洗后的信令数据作为输入数据,轨迹生成过程中会有大量的中间点,其中会有差异性较大的点,为提高数据运算效率,首先筛除轨迹点中差异性较大的点,然后让有效轨迹点再参与到后续停留点识别算法的计算中。
离群点检测有多种方法,考虑到出行路径中轨迹点的具体点线集聚特征,选用基于密度的离群检测算法,即根据数据的密集情况,计算每个数据对象的离群因子,以此标识数据的离群程度[8],检测出与所需数据行为或特征属性差别较大的数据。算法具体实现步骤如下。
步骤1:遍历所有轨迹点对象,对轨迹点集D中的任意一点p,计算k距离dk(p),并定义两点间距离d(p,o) 满足:至少有不包括p在内的k个点o',使得d(p,o') ≤d(p,o);最多有不包括p在内的k-1 个点o″,使得d(p,o″)<d(p,o)。
步骤2:获得每个数据点的k距离领域Nk(p),包含k距离以内的所有数据点。
步骤3:计算每个点的可达距离reach_distk(p,o)=max{dk(o),d(p,o)}。
步骤4:计算每个点的可达密度,将Nk(p) 邻域内点到p的平均可达距离的倒数作为每个点的可达密度,即
步骤5:计算每个点的离群因子LOFk(p),即点p的邻域点Nk(p) 的可达密度与点p的可达密度之比的平均值,即
步骤6:判断密集点和离群点,如果是密集点,则该点的可达密度与其邻近点的可达密度相近,离群因子≤1;相反,如果是离群点,则该点位于低密度区域,离群因子>1。
1.4 出行识别算法
出行识别算法可对有效轨迹数据进行停留点提取,从而获得用户的出行信息,该算法是提取城市交通出行活动特征的关键算法。研究中首先给出出行识别的常用算法,同时结合交通出行的有关特征,给出出行识别主要参数的确定方法。
传统的DBSCAN(density-based spatial clustering of applications with noise,基于密度的聚类算法)依据距离度量,仅从空间维度判定核心对象。考虑交通出行特征及手机信令数据的时空属性,基于时空维度的聚类算法是出行识别的常用算法,算法中的参数主要有以下5 项。
(1) 时空Eps 邻域:对于轨迹点集D中的每一数据点p,以p为圆心,在时间阈值T内,Eps 为半径的区域,为p的Eps 时空邻域。
(2) 核心点:MinPts(领域密度阈值)为各用户Eps 内的点数量均值,若点p的Eps 邻域中的点数量≥MinPts,则标记为核心点。
(3) 直接密度可达:对于任意两点p、g,如果g为核心点,p位于g的Eps 邻域内,那么将点p和点g作为直接密度可达。
(4) 密度可达:假设轨迹点集D中存在一系列点p1,p2,p3,…,pn-1,pn,其中p1=g、pn=p。如果点pi+1从点pi直接密度可达,那么点p从点g是密度可达的。
(5) 密度相连:对于轨迹点集D的点p、g、o,如果点p与点g都是到点o密度可达的,则称点p与点g密度相连。
有效停留算法是针对有效轨迹链在时空距离阈值范围内的再次聚合,停留点识别实现步骤如下。
步骤1:给定时间阈值T、距离阈值Eps,判定阈值MinPts,遍历所有轨迹点,找出核心对象。
步骤2:以核心点为中心,找出与核心点密度可达的数据对象,形成一个密度聚类簇。
步骤3:对聚类簇内所有核心点重复步骤2,找出其密度相连点,并转到聚类簇中,直到密度可达的对象全部找出。
步骤4:重复以上步骤,获得停留区域。
步骤5:确定停留点位置和时间,提取停留区域的几何中心点坐标,将其作为停留点的空间位置点;将停留区域内最早轨迹点的时间作为起始时间,最晚轨迹点的时间作为终止时间,停留点划分示意如图1 所示。

图1 停留点划分示意
根据有效停留算法的提取,筛选满足出行停留时空阈值的位置信息,两次停留点间作为一次出行,识别用户出行的起讫点,获取出行 OD(origin-destination,起讫点)表。一次交通出行通常指为完成其出行目的、步行超过5 min 或使用交通工具单程距离超过500 m 的出行。
根据出行定义判断,停留区域内相邻两点的空间距离应小于500 m,时间间隔应小于5 min,分别对应时空邻域的时间阈值和距离阈值。鉴于停留点的聚集效应,通过密度可达不断扩充停留区域,可将时间阈值设置为15 min,以此作为参数基准值开展调节测试。出行识别的具体步骤如下。
步骤1:根据时空邻域阈值定义及相应基准值,给出时间阈值和距离阈值的可选集合,其中,时间阈值集合为{900 s,1 800 s,2 800 s},距离阈值集合为{300 m,500 m,1 000 m}。
步骤2:针对停留时长和出行距离条件建立时空阈值参数组合,即时空邻域阈值集合。例如停留点停留时长>1 800 s 且与上一停留点之间累计出行距离>300 m,即为(1 800 s,300 m)。依次读取阈值集合参数,开展出行识别算法计算。
步骤3:提取出行识别算法结果,将平均出行率作为主要核算因子,与调查数据进行验证比对,确定最终阈值参数。
1.5 职住地识别
职住地识别主要目的是识别出用户的居住地和工作地,主要通过3 个参数共同确定。
(1) 时间段,包括日间时段(当日9 点至18点)和夜间时段(当日20 点至次日8 点)。
(2) 停留时间,以第一次在A 基站出现为起始时间,以第一次出现在其他基站为A 基站的结束时间,两值相减即为A 基站的停留时间。其中,日间在停留点的停留时长≥3 h,夜间在停留点的停留时长≥6 h。
(3) 日期逗留频次,每个停留点的停留天数比例≥60%的总样本天数。
职住地识别的具体步骤如下:
步骤1:读取完整的用户轨迹数据,基于时间段判断出居住标记和工作标记的点集合;
步骤2:计算居住标记和工作标记的点集合中每个位置的累计停留时间,判断其是否满足停留时间,每天每个基站的累计停留时间大于日间或夜间停留时间阈值的地点,作为备选工作地点或居住地点;
步骤3:统计备选工作地点或居住地点的总天数,将超过总样本天数比例阈值且停留时间最长的地点作为工作地或居住地。
1.6 通勤识别
通勤识别的主要目的是获取通勤数据,分析通勤特征。其中输入数据是基于出行识别算法和职住地识别算法获取的结果数据,通勤识别的具体实现步骤如下。
步骤1:通过手机唯一标识码,关联职住表和出行OD 表;
步骤2:判断职住表中既有居住地又有工作地的移动用户;
步骤3:在出行OD 表中筛选出步骤2 的移动用户,遍历出行数据,其中,从居住地到工作地的出行标记为上班通勤,从工作地到居住地的出行标记为下班通勤。
2 实例应用
以采集的中国移动运营商2 个月的手机信令数据作为基本数据,其范围涵盖山东省日照市市域范围内的移动用户,对信令数据的整体情况、时间分布等进行综合评价,每日移动用户数量基本稳定,人均记录数超过120 条,数据质量相对较高。样本日用户量及信令记录整体分布如图2 所示,样本信令数据时间分布如图3 所示。

图2 样本日用户量及信令记录整体分布

图3 样本信令数据时间分布
2.1 停留点参数测试
在移动用户有效轨迹中,对停留时间超过1 800 s、2 400 s、3 000 s、3 600 s,且距离超过300 m、500 m 组成的时空邻域参数集合开展停留点识别计算,依次获取出行率指标,不同时空邻域下的出行率计算如图4 所示。对计算值与城市居民出行调查值(2.53 次/人·d)进行校核,其中停留点时空阈值为(1 800 s、500 m),计算所得的出行率2.51 次/人·d 最为接近。

图4 不同时空邻域下的出行率计算
2.2 人口岗位分布识别
通过手机信令数据识别出常住人口数量,结合移动市场占有率、一机多卡率、手机用户占比等进行综合扩样,得到该市常住人口数量约为296 万人,计算数值与统计数据基本一致。但对于不同的区域,尤其是人口活动密集的市区范围,两者结果略有不同,手机识别常住人口数量略高于统计值。对于城市人口岗位密度分布的分析,主要聚集在主城区与外围区县的核心区域,中心城区人口密度远高于外围区域,其中日照市秦楼街道与石臼街道的常住人口密度较大。
2.3 出行特征分析
2.3.1 出行规模
结合手机信令数据的出行识别算法,使用停留距离的阈值为500 m,停留时间的阈值为1 800 s,计算得出居民出行率为2.51 次/(人·d),与居民出行调查分析所得的2.53 次/(人·d)基本吻合。另外,从对不同区域统计分析中可以看出,中心城区由于公共设施、生活配套设施相对完善,相应出行次数最高,出行率为2.65 次/(人·d),约占出行总量的40%,日照市居民出行总量与出行率统计如图5 所示。

图5 日照市居民出行总量与出行率统计
2.3.2 出行空间分布
出行空间分布与城市空间结构、土地布局、人口密度、基础设施的布置有密切关系,通过数据分析可获取不同区域间的出行联系量。在案例城市分析中,得到主城区内各个街道间的出行联系强度,通过数据分析发现,联系主要集中在日照街道与秦楼街道、秦楼街道与石臼街道之间,全日双向交换量分别约为24 万人次与14 万人次。同时,得到日照全市跨区出行总量为54 万人次,区间出行量主要集中在该市东港区与岚山区,约占总区间出行总量的一半。
2.3.3 出行时间分布
基于信令数据识别居民的出行时间分布情况,居民工作日存在明显的早、晚高峰出行特征,其中,早高峰时间段为7:00 至9:00,晚高峰时间段为17:00 至19:00,平均出行时间约为28 min,出行时间及时长分布如图6 所示。

图6 出行时间及时长分布
2.3.4 出行距离分布
通过手机信令数据分析人口出行距离分布情况,可以得到出行距离以中短距离为主,平均出行距离约为5.1 km,其中工作出行距离相对其他出行目的的出行距离略远,出行距离分布及分目的出行距离分布如图7 所示。
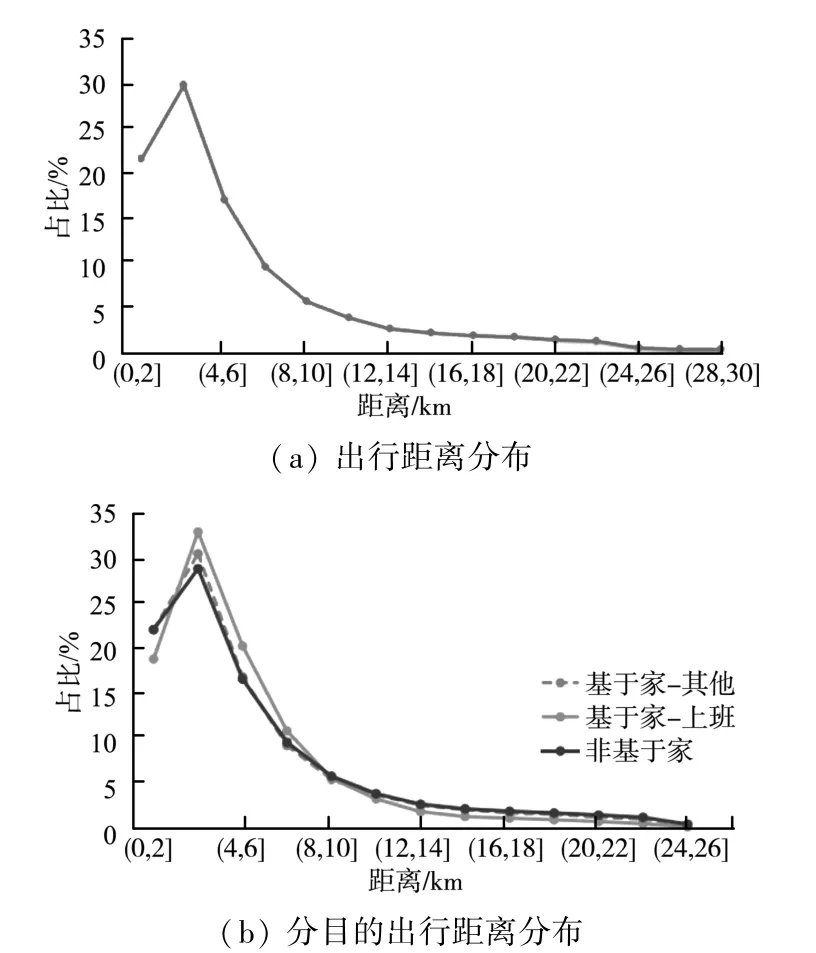
图7 出行距离分布及分目的出行距离分布
2.4 通勤特征分析
结合通勤识别算法获得通勤出行的时间及距离分布。其中,通勤时间主要集中在6:30 至8:30、17:00 至19:00,平均通勤出行时间约28 min。出行距离以中短距离为主,与职住的计算结果相吻合,跨区出行较少,4 km 以内的出行占比约为70%。通勤时间及距离分布如图8 所示。

图8 通勤时间及距离分布
3 结语
本研究对手机信令数据处理和出行特征提取的过程进行梳理,详细介绍了关键处理算法,给出出行轨迹识别及提取的关键参数和验证方法,可为其他城市开展数据应用实践提供参考。
猜你喜欢
四川党的建设(2022年8期)2022-04-28
小学生学习指导(低年级)(2020年11期)2020-12-14
铁路通信信号工程技术(2019年10期)2019-11-06
中国交通信息化(2019年2期)2019-03-25
作文大王·低年级(2018年10期)2018-12-06
消费导刊(2017年24期)2018-01-31
探索科学(2017年4期)2017-05-04
中国交通信息化(2016年8期)2016-06-06
小猕猴智力画刊(2016年5期)2016-05-14
互联网天地(2016年2期)2016-05-04
