
一种具有结构先验的贝叶斯网络结构学习算法
2023-11-17 07:28:46仝兆景李金香乔征瑞
电子科技 2023年11期
仝兆景,李金香,乔征瑞
(河南理工大学 电气工程与自动化学院,河南 焦作 454003)
贝叶斯网络(BN)结合概率论和图论的知识,能解决概率事件的不确定性问题,是目前不确定知识表达和推理领域较有效的理论模型之一。BN具备多元知识图解可视化的能力,能通过有限不完整的知识推理并融合多源信息,被应用于设备故障诊断[1]、医学诊断[2]、图像处理[3]、可靠性分析与风险分析[4]等多领域。BN还具有处理变量不确定性与不完整性的能力,可被用于变压器[5]、电网[6]和输电线路[7]等多种故障诊断领域[8-10]。但是基于传统的BN具有节点多和网络结构复杂等缺点,影响了其在实际使用中的性能。元启发式搜索策略被广泛应用于BN结构学习,对识别分类算法具有良好的改进效果[11-12]。文献[13]通过交叉变异策略对BN节点序寻优,在小样本学习下的BN结构较优,但其在大样本学习下的结构较差。文献[14]采用独立性测试和爬山算法的最大-最小爬山算法优化BN结构,降低了搜索空间复杂度。目前有研究人员利用改进鲸鱼算法对BN结构寻优,但复杂度较高[15]。文献[16]将PC算法与改进的粒子群算法结合来优化BN结构,获得了较好的学习效果,但该方法的参数设置较多,在标准贝叶斯网络的测试中不稳定。
BN由表示随机变量和机率分配的拓扑构造与基本参数构成,故BN的学习包括结构学习和参数学习。结构学习分为3种:基于约束的学习方法、基于分数的学习方法和混合学习方法。将基于约束的方法通过条件独立测试(Conditional Independence,CI)来学习BN结构[17]。基于分数的学习方法应用较广泛,它可将专家知识作为结构先验灵活地引入到学习过程中。K2和粒子群算法[18]等群智能算法都是基于分数的方法。混合方法将二者结合起来,通过条件独立测试减少搜索空间,并采用基于分数的方法进行结构学习。
基于上述分析,本文提出一种基于PC-SSA(Sparrow Search Algorithm)的BN混合结构学习方法。将通过PC算法生成的初始网络图作为结构先验,并基于它们生成初始解。采用麻雀搜索算法作为BN的分数学习算法,提高网络结构的寻优性能。本文所提算法参数设置少,在标准网络上的测试分数更接近标准分数。
1 贝叶斯网络结构学习
1.1 贝叶斯网络理论
贝叶斯网络的数学形式用B(G,P)表示,其中G为有向无环图(Directed Acyclic Graph,DAG),包含节点、弧线以及箭头3个元素。节点一般为离散型随机变量,通过直线连接。箭头用于描述节点之间的关联关系,由父节点指向子节点。P为条件概率,用来说明有向线连接的两个目标节点或者条件节点之间变量的概率关系。贝叶斯网络通过其节点间的父子关系和概率论的知识对不确定问题进行概率推理。
贝叶斯网络中的全概率的定义如下
(1)

当贝叶斯网络节点数量较多时,以N=(G,Θ)代替上述计算式,其中G=〈V,E〉,V={V1,V2,…,Vn}代表贝叶斯网络的所有节点集合体,E代表有向无环图中全部有向边的集合,Θ={Θ1,Θ2,…,Θn}表示每个节点Vi在已知其父节点pa(vi)时的条件概率表。
假设节点Vi=(vi),其父节点集合为pa(vi),则其联合概率分布为
(2)
对于节点Vi=(vi)中的任一随机变量X,其联合概率分布如下所示。

(3)
根据随机变量的联合概率分布计算式,进一步将其表示为以下形式。
(4)
以某节点为例,通过其父节点信息,在BN体系中根据式(4)可知,如果某节点其父节点的状态信息可知,那么该节点的条件完全独立于由其父节点中给定的任何非子节点所组成的集合体。以节点的独立性为前提,对提出的问题进行分析,选取特征变量后对数据进行预处理,再进行BN学习。本文构建贝叶斯网络的流程如图1所示。

图1 贝叶斯网络决策流程Figure 1.Flow of Bayesian network decision
1.2 基于约束的结构学习
基于约束的学习方法一般采用条件独立性检验或互信息检查确定变量间的相互依赖性或独立性关系。该方法的性能主要取决于CI测试的数量和约束集的大小。由于约束集和高阶CI测试数量增加,基于约束的方法精度将降低,因此本文选用CI确定变量间的依赖关系。PC算法便是利用CI测试来确定变量间依赖关系的典型算法之一,其通过检测两个最邻近节点子集的有向分离(D-separation)来减少搜索空间与时间复杂度。本文通过PC算法选择初始网络,对网络结构进行修改。
根据D-separation思想确立网络结构中节点间的依赖关系,对任意3个以有效依赖关系边相连的节点X-Z-Y,其依赖关系为图2所示的类型之一。

图2 贝叶斯网络中的4种依赖关系Figure 2. Four kinds of dependencies in Bayesian network
D-separation可将无向图扩展为DAG。节点集合O能D分隔节点i和节点j,当且仅当给定O时,i与j不存在有效路径,即i和j在O条件下独立,记作i⊥j∣O。已知有向无环图G以及节点X、Y和点集O,当X和Y之间的路径满足以下任意一条结论时,该路径堵塞,那么X、Y关于O条件独立:1)若节点Z属于图2的a、b、c3种情况,且Z包含在点集O中;2)若节点Z属于图2中的d情况,且Z不包含在点集O中。
D-separation可将判断BN边的方向规则分为3条:
规则1如图3所示,如果X→Y-Z,则将Y-Z变为Y→Z;
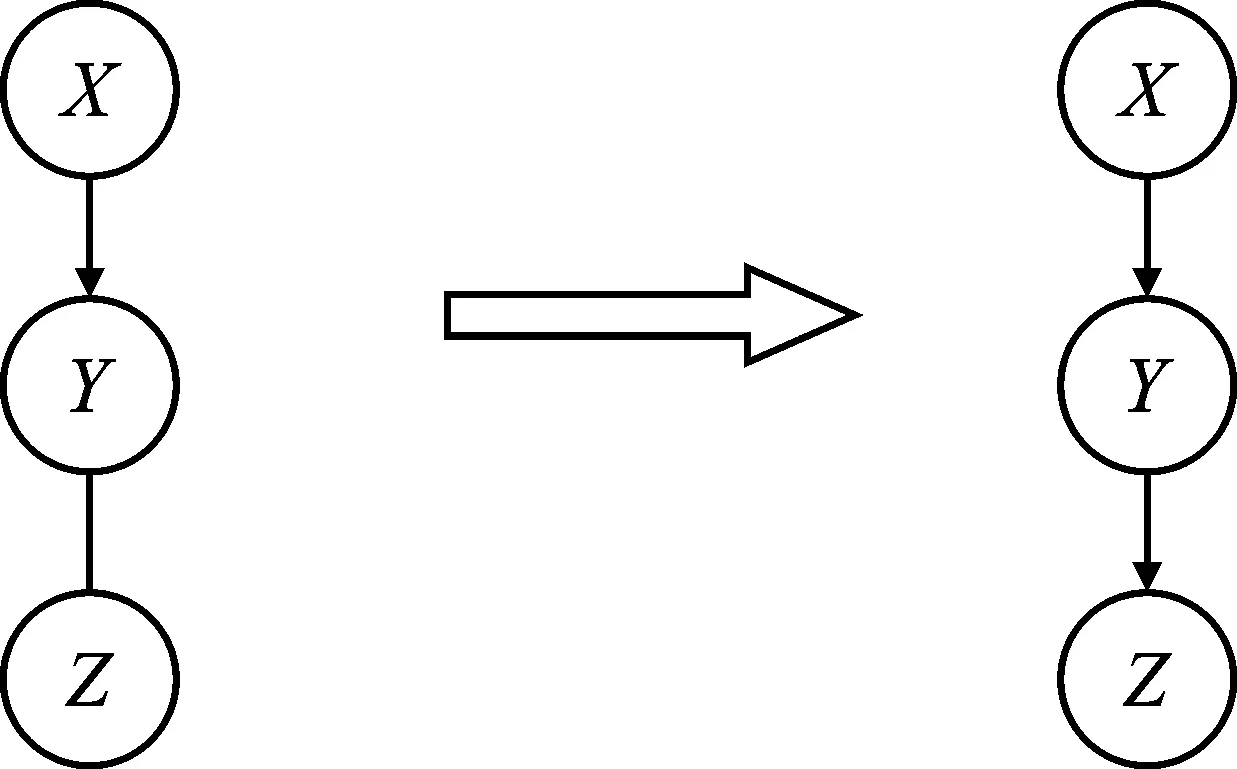
图3 方向判断规则1Figure 3. Direction judgment rule 1
规则2如图4所示,如果X→Z→Y,则将X-Y变为X→Y;

图4 方向判断规则2Figure 4. Direction judgment rule 2
规则3如图5所示,如果X-Z1→Y,X-Z2→Y,且Z1,Z2不相邻,则将X-Y变为X→Y。
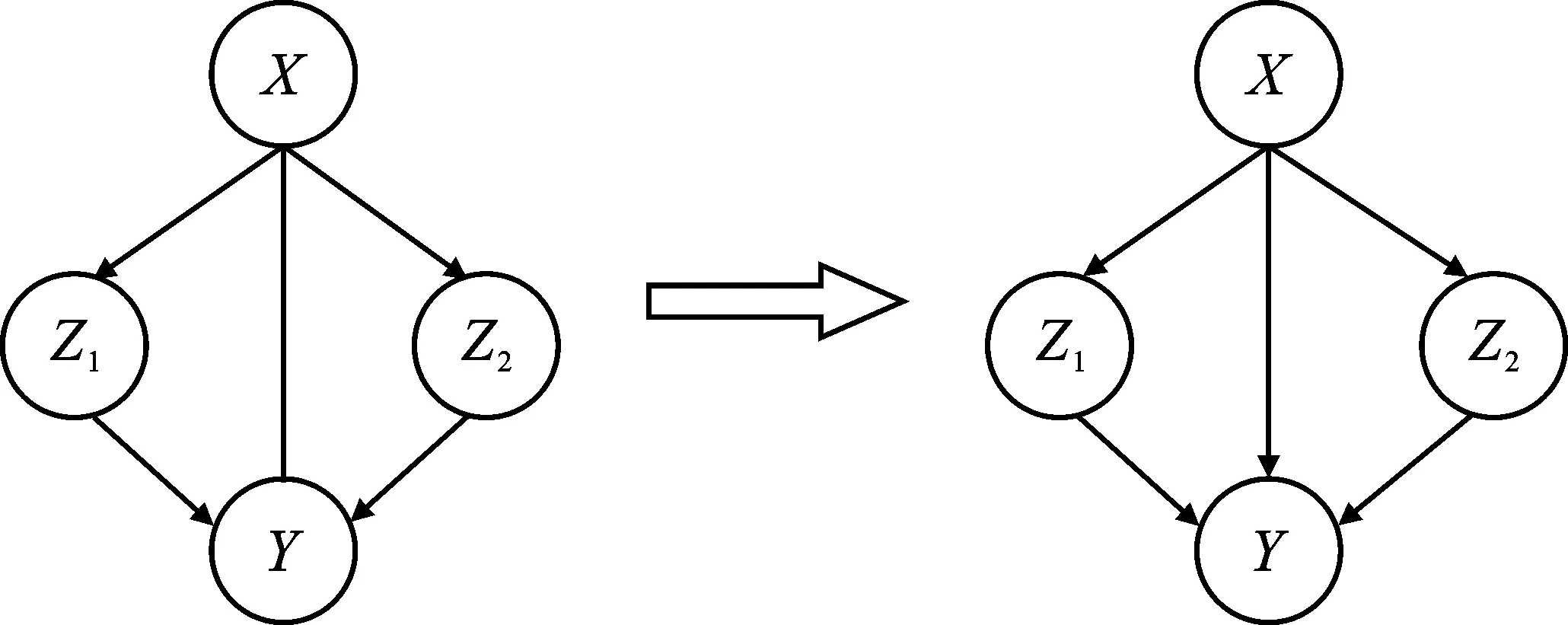
图5 方向判断规则3Figure 5. Direction judgment rule 3
1.3 基于分数的结构学习
基于分数的学习方法主要思想是遍历所有可行结构,根据评分函数寻最优结构。常用的评分函数有贝叶斯狄利克雷等价(Bayesian Dirichlet Equivalent,BDE)、最小描述长度(Minimum Description Length,MDL)和贝叶斯信息准则(Bayesian Information Criterion,BIC)。与BDE相比,基于MDL或BIC的BN结构学习更容易,BDE则需考虑参数的先验分布。由于学习结构的复杂性,BDE倾向于选择更复杂的网络结构,而MDL和BIC倾向于选择更简单的网络结构。在实际应用中,MDL和BIC的计算结果比较简单。BIC评分函数较简单,可以更好地均衡计算的精准度和网络结构的复杂性,在确保获得最优贝叶斯网络的同时提升了BN的学习效率。
根据以上分析,本文以BIC评估学习过程中的DAG。假设一个BN含有n个节点,其BIC定义为
(5)
式中,ri表示节点xi可能取值的种数;qi表示节点xi的父节点可能取值的种数。计算式的前半部分为BN的似然对数,表示BN与样本集间的匹配程度,后半部分表示BN的复杂度。
BIC评分函数可判断搜索流程中的可行结构以及数据的匹配度,其评价值越高,函数的适应度值越高,样本集与网络结构的匹配度越高,网络结构越优。搜索算法用来计算由各种可能构造形成的空间上搜索分数最高的结构。其中,启发式算法被普遍用于搜索可行解,本文通过群智能算法寻找BN空间,从而优化其结构。
2 麻雀搜索算法
麻雀搜索算法[19](Sparrow Search Algorithm,SSA)改善了优化搜索空间的探索和利用方式,促进了优化搜寻空间技术的研究与使用。该方法在搜寻准确性、收敛速率、稳定性以及避免局部最优值问题等方面都优于现有方法,故本文在基于分数学习的BN结构优化中采用SSA来进一步提升算法性能。
假设d维空间中有n只麻雀,则麻雀组成的种群X以及每只麻雀对应的适应度函数F表示为
(6)
(7)
探索者的位置在t次迭代中更新为
(8)
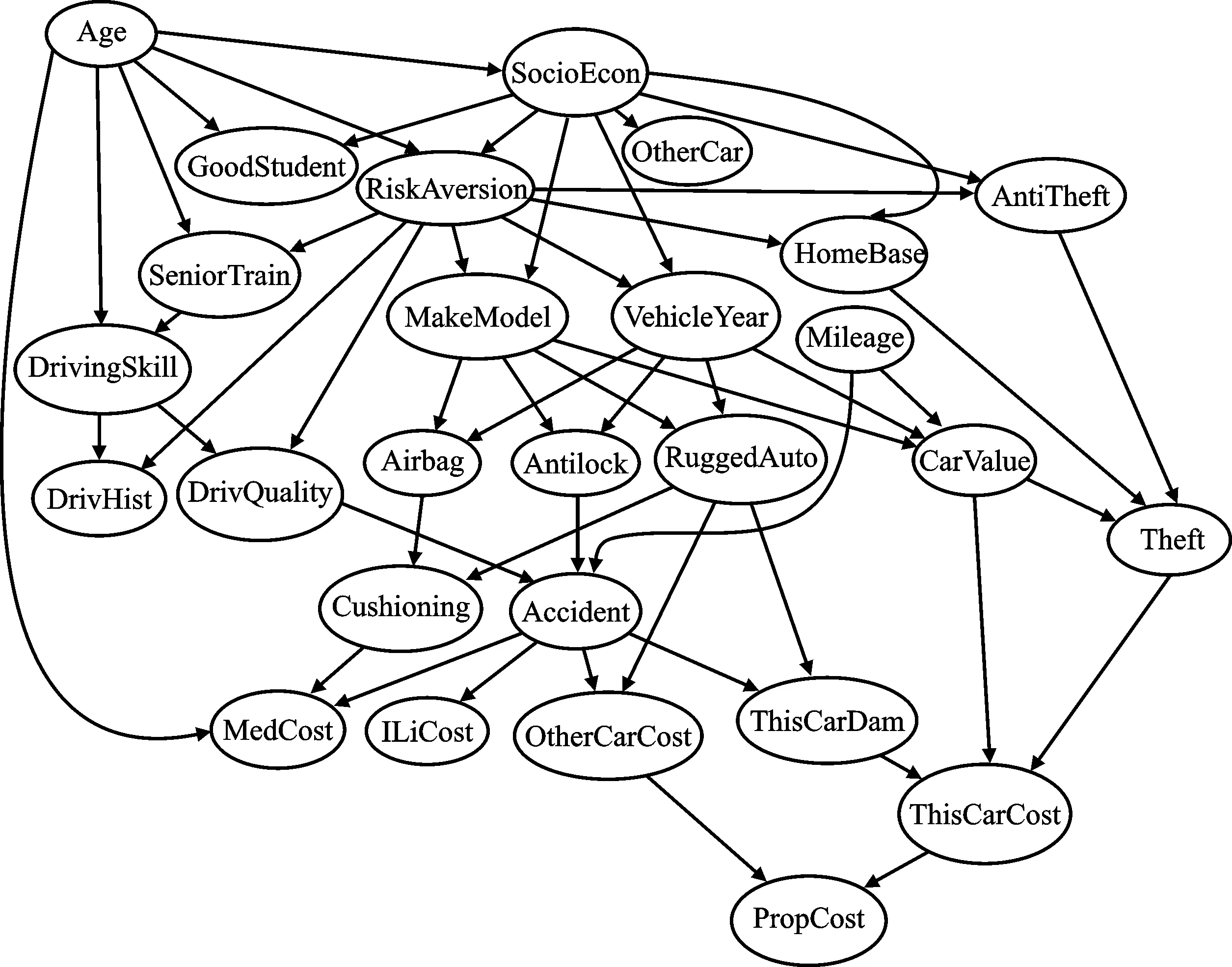
其中,j为维值,且j=1,2,…,d;α∈(0,1];itermax为最大迭代次数;R2为报警值,且R2∈[0,1];ST为安全阈值;Q代表所有满足于正态分布的随机数,L为1×dim的全1矩阵。当R2 追随者的位置更新计算式为 (9) 其中,Xworst为当前迭代中全局最差的麻雀位置;XP为当前迭代全局最优的麻雀位置;A为1×dim随机数为1或-1矩阵。当i>n/2时,当前追随者的位置较差,找不到食物,需要飞往其他地区觅食;反之则表示当前追随者的位置较好,将会跟随离自己最近的适应度值高的探索者觅食。 警戒者的位置更新计算式为 (10) 其中,Xbest代表当前迭代中全局最佳的麻雀位置;β代表一个服从平均数为0、方差为1的正态分布的随机数;K代表下一个随机数,取值范围为[-1,1];ε表示最小的随机常数;fi表示当前迭代麻雀的适应度值;fg和fw分别表示最优和最差的适应度值。当fi>fg时,当前麻雀的位置处于易被捕食者发现的种群边缘,此时麻雀需要寻找更优的位置觅食;当fi=fg时,当前麻雀处于种群中间的位置,此时麻雀会靠近距离自己较近的同伴,以此来缩减它们的危险区域。 本文采用SSA搜索DAGs空间。与其他启发式算法相比,麻雀搜索算法不需要学习较多参数,适用于各种搜索空间,能够快速找到最优解。本文结合BN知识,将寻找最优BN结构的过程等价为最优麻雀位置的过程。基于PC-SSA算法的结构学习,便是将数据集中学习BN结构的过程等价为麻雀寻找最优位置的过程。 对于有n个随机变量的固定域S={0,1},其BN用n×n邻接矩阵a表示,aij的元素定义如下所示。 (11) 以癌症网络为例,其BN以及编码如图6所示,网络结构包含5个节点和4个弧。根据图6可知,污染和吸烟会导致癌症,癌症会导致患者X-射线检测结果呈阳性并出现呼吸困难的症状。 图6 癌症网络及其邻接矩阵Figure 6. Cancer network and its adjacency matrix 首先采用PC算法生成具有结构先验的初始网络,然后利用SSA算法对最优DAG结构进行搜寻。本文的贝叶斯网络采用n个节点,m个种群个体,即(n,m)维的搜索空间。第i个个体的位置为Xi={X11,…,X1n,X21,…,X2n,…,Xn1,…,Xnn}。在搜索最优结构的过程中,每只麻雀的位置都代表一种有效的贝叶斯网络结构,以BIC评分函数作为算法寻优过程的适应度函数,通过测试的样本集对当前DAG评分。在麻雀的位置更新过程中,对当前DAG不断进行添加弧、删减弧和修正非法网络等操作,具体过程如下所示: 步骤1初始化网络结构的参数。麻雀种群规模为n,最大迭代次数为max_iteration,BN搜索空间维度为dim以及上下界,预警值ST=0.6,探索者比例PD=0.7,意识到有危险的麻雀比例为SD=0.2。按照比例划分训练集和测试集,将训练数据集D作为输入。 步骤2根据PC算法生成初始网络,通过CI测试进行加减边并测试节点的独立性,再根据方向判断规则生成完全部分DAG。最后,结合专家经验生成初始麻雀种群,对网络结构进行修复。 步骤3根据式(5)计算当前麻雀个体的BIC函数评分值并排序记录最优DAG结构。 步骤4判断算法是否达到最大迭代次数,若达到终止条件,则算法结束并返回全局最优DAG;反之则返回步骤3。 基于PC-SSA的BN流程如图7所示。 图7 基于PC-SSA算法的BN流程Figure 7. Flow of BN based on PC-SSA algorithm 为验证本文所提算法的寻优性能,选取CANCER网络(图6)、ASIA网络(图8)和INSURANCE网络(图9)3个标准BN测试BIC评分。这3个网络的节点和有向边的数量递增,复杂程度也逐渐增高,能有效测试算法在简单网络和复杂网络的寻优能力。其中,CANCER网络包含5个节点和4条有向边,ASIA网络包含8个节点和8条有向边,INSURANCE包含27个节点和52条有向边。 图8 ASIA网络Figure 8. ASIA network 图9 INSURANCE网络Figure 9. INSURANCE network 将数据集划分为500、1 000、1 500和2 000,分别在上述3个网络进行实验验证,实验结果如表1所示。 由表1可知,本文提出的PC-SSA可得到接近真实网络的BIC分数。在ASIA网络的1 000个样本的测试中,标准BIC分数为-2 246.94,本文算法得到的BIC分数为-2 247.82,表明通过PC-SSA获得的网络是一个合理的亚洲网络结构,并且在寻优过程中获得的分数接近标准分数。随着网络复杂度的增高,该算法在测试网络上的BIC分数与标准分数误差增大。PC-SSA在ASIA网络上的平均测试结果最优,在2 000样本的测试中,最小误差为0.2。PC-SSA在网络复杂的INSURANCE网络上的测试结果最差,在2 000样本的测试中,其最大误差达557.5。 将本文算法与粒子群优化 (Particle Swarm Optimization, PSO) 算法以及未加先验结构的SSA进行比较,样本容量为500,分别在CANCER、ASIA和INSURANCE网络上进行对比实验,结果如图10所示。 (a) 由图10可知,采用SSA的评分高于PSO;相比于PSO和SSA,PC-SSA初始评分更高,表明采用PC生成的先验结构提高了算法的初始评分;SSA提高了整体的BIC分数,本文算法的初始值和最终评分都高于其他算法。该结果证明了本文采用的PC算法可以有效地提高BN结构学习问题的初始解。在初始解最优的情况下,SSA实现了更好的搜索过程,得到更好的最终解。随着迭代次数的增加,BIC分数趋于不变,表明本文方法可以收敛到BN结构学习问题的固定解,且本文算法比其他算法能够更快地搜索到最优解。将图10收敛的BIC分数和在达到最佳BIC分数时的迭代次数进行比较,结果如表2所示。 表2 不同算法在标准贝叶斯网络上的实验结果 由表2可知,本文算法比其他算法的迭代次数少,BIC评分更接近标准分数整体,性能更优,说明PC-SSA更易实现,收敛速度更快,整体评分高,性能更优良。 本文提出了一种基于PC-SSA的混合方法优化贝叶斯网络结构,并通过CANCER网络、ASIA网络和INSURANCE网络进行了测试。实验结果证明了基于PC-SSA学习贝叶斯网络结构的评分更高,收敛速度更快,能在最短时间内寻出最优贝叶斯网络结构,获得与标准评分误差最小的BIC评分。本文采用的PC算法对网络初始解的优化也说明了结构先验在BN结构学习中的重要性。3 基于PC-SSA的贝叶斯网络结构学习
3.1 贝叶斯网络结构学习的编码设计

3.2 贝叶斯网络结构学习实现过程

4 标准贝叶斯网络的结构学习测试



5 结束语
猜你喜欢
作文小学中年级(2019年10期)2019-11-04 00:39:52
新世纪智能(高一语文)(2018年11期)2018-12-29 11:32:06
趣味(语文)(2018年2期)2018-05-26 09:17:55
数理化解题研究(2017年4期)2017-05-04 04:07:54
铁道通信信号(2016年6期)2016-06-01 12:10:20
山东青年(2016年1期)2016-02-28 14:25:22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
电子器件(2015年5期)2015-12-29 08:43:15
