
三种气温插补方法在中国西南地区的应用分析
2023-11-14 01:57:46盖长松曹丽娟阳园燕
干旱气象 2023年5期
盖长松,曹丽娟,阳园燕,3
(1.中国气象局气候资源经济转化重点开放实验室,重庆市气象信息与技术保障中心,重庆 401147;2.国家气象信息中心,北京 100081;3.重庆市气象科学研究所,重庆 401147)
引言
全球变暖对天气气候系统产生重要影响,IPCC第6次评估报告指出,未来每0.5 ℃的升温都会干扰包括极端高温、降水等在内的极端天气气候事件发生频率与规模(严中伟等,2020;唐懿等,2022),特别是中国西南地区尤为明显(伍清等,2018;曾剑等,2022),而长时间序列的气温资料能够有效反映气候冷暖变化程度,是判断极端天气气候事件强度的重要指标(Cao et al.,2017;冯蜀青等;2019;金红梅等,2019)。同时,气温也是陆面过程模型、数值预报模式等的重要输入参量,高质量、高精度的长时间序列气温资料有利于模式模拟和预报水平的提升。因此,对气温观测数据进行插补、质量控制及偏差订正,提升数据完整性、质量及均一性,是气象观测系统发展的重点(吴国雄等,2014;廖捷和周自江,2018)。
针对气温序列数据插补订正的研究成果较多,通常历史长年代际的气温序列数据插补多依靠历史文献、冰芯和树木年轮等代用资料及统计方法(丁玲玲等,2013;郑景云等,2014;郑景云等,2015;刘炳涛等,2018;邓国富和李明启,2021)。余君等(2018)采用贝叶斯方法,对中国北疆地区8条树轮气温重建资料、器测资料与CMIP5(Coupled Model Intercomparison Project Phase 5)模式资料进行融合试验,发现该方法能够纠正先验分布及气候模拟数据的明显偏差。对于实际观测的气温数据多采用单站资料或多站资料联合方式,结合标准序列法(Degaetano et al., 1995;余予等,2012)、回归分析(王海军等,2008;杨青等,2009;陈鹏翔等,2014)、SVD(Singular Value Decomposition)迭代(张永领等,2006)、偏最小二乘法(李庆祥等,2008)、最优配对分段插补(黄蓉等,2014)等方法,建立气温插补订正模型,实现对日、月、年等时间尺度的气温序列插补。闫丽莉等(2019)采用多站联合方式,建立线性回归插补模型,对唐山逐小时气温观测序列进行插补重建,结果表明该方法重建序列误差在±0.8 ℃范围内的比例为80.3%,平均绝对误差为0.84 ℃。在百年站气温要素序列重建方面,基于传统统计方法与资料的同时,部分研究还引入了再分析资料(彭嘉栋等,2014;司鹏等,2017;肖晶晶等,2021;杜泽玉等,2021;司鹏等,2022)。刘蕾等(2022)基于本站气温观测资料,联合使用英国CRU(Climatic Research Unit)格点气温资料作为补充和对比,采用多元逐步回归模型,重建了芜湖站百年(1880—2020年)月平均气温序列,结果表明近140 a来芜湖春、夏、冬季增温显著,但近20 a增温有所停滞,存在40~50 a和20~30 a的变化周期。随着机器学习、深度学习等大数据技术的发展,该类技术也逐渐应用于气温序列数据插补中。郑欣彤等(2022)基于编码—解码结构的序列—序列深度学习结构(BiLSTM-I),利用同一区域较低时频的人工观测气温序列数据搭建插补模型,重建了野外小气象站30 min时间尺度的气温序列数据,并与BRTS-I和卡尔曼方法的重建结果相比较,发现BiLSTM-I方法在气温插补方面有良好的适用性。孟欣宁等(2020)应用随机森林模型整合中亚地区65个气象站逐日最高气温数据和ERA-Interim再分析资料以及经纬度、海拔数据,构建插补方案,补全了气象站观测缺失值,并插值得到中亚1979—2016年逐日最高气温格点数据集(空间分辨率为0.75°×0.75°)。
上述研究大多针对单站或区域内气温资料开展的单一统计学或机器学习插补方法的应用,缺乏同一区域内上述多类插补方法的对比研究,同时也较少考虑地形地貌对插补方法的影响。鉴于此,本文基于中国西南地区气象站点逐日及逐月平均气温数据,综合台站及其所处区域的高程、坡度坡向、地表覆盖类型、地形起伏度和气候区等信息,开展空间回归、标准序列法与随机森林等3种插补方法在西南地区的适用性分析,以期为该区域长序列、高质量基础数据产品研制提供科学支撑。
1 数据与方法
1.1 数 据
选取1970—2020年川、渝、滇、黔4省(市)日平均气温数据,数据来源于中国地面气象站均一化气温日值数据集,经过内部一致性、气候界限值、时间一致性检查等数据质量控制以及序列均一化检验与订正(Cao et al., 2016)。百年站气温数据来自中国近百年均一化气温数据集(Cao et al., 2017)。观测站点的坡度、坡向来自ASTER-GDEM V3数据集,本文将坡度(S)分为5级:S≤2°为1级,2°<S≤6°为2级,6°<S≤15°为3级,15°<S≤25°为4级,S>25°为5级。地形起伏度来自中国地形起伏度公里网格数据集(https://geodoi.ac.cn/WebCn/doi.aspx?Id=887)。地表覆盖类型来自全球地表覆盖遥感制图数据集(GlobeLand30 V2020,http://www.webmap.cn/mapDataAction.do?method=globalLandCover),地表覆盖包括耕地、林地、草地、灌木地、湿地、水体、苔原、人造地表、裸地、冰川和永久积雪10种类型,空间分辨率30 m。
1.2 研究区域
中国西南地区包括川、渝、滇、黔四省(市),该地区地形地貌复杂、气候类型丰富,分布着川藏高山峡谷区、云贵高原、四川盆地、湘鄂西山区、秦巴山区等,自西北向东南依次为亚寒带、温带、中亚热带及南亚热带湿润和半湿润区,气候区划(郑景云等,2010)及气象站点分布如图1所示。从图1看出,四川盆地及其周边气候区内气象站点分布最密,云贵高原及其周边次之,而川西北高原、横断山脉等地区气候区内气象站点分布最为稀疏。本文研究范围主要为气象站点分布较为密集的川西南滇北山地中亚热带湿润区(VATb-c,简称“川西南滇北山地”)、滇西山地滇中高原中亚热带湿润区(VATc-d,简称“滇西山地滇中高原”)、贵州高原山地中亚热带湿润区(VATd-e,简称“贵州高原山地”)、四川盆地中亚热带湿润区(VATe-f,简称“四川盆地”)和湘鄂西山地中亚热带湿润区(VATf,简称“湘鄂西山地”)等5个区域。西南地区省(市)行政边界基于国家自然资源部标准地图服务网下载的审图号为GS(2023)2767号的标准地图制作,底图无修改。
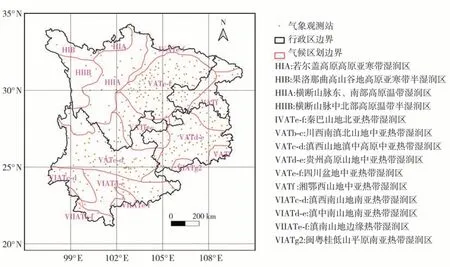
图1 中国西南地区气候分区(郑景云等,2010)与气象站点分布Fig.1 The climatic divisions (Zheng et al., 2010) and distribution of meteorological observation stations in southwestern China
首先,以研究区域内某一气象观测站为目标站,以100 km为半径,其内所有观测站初步设定为该目标站的参考站;然后,将海拔高度纳入到参考站的筛选条件中,当目标站海拔高度小于(大于)1 500 m时,选定的参考站与目标站的海拔高差需小于350 m(500 m)。按照此原则,上述5个气候区内目标站与参考站分布情况见表1。
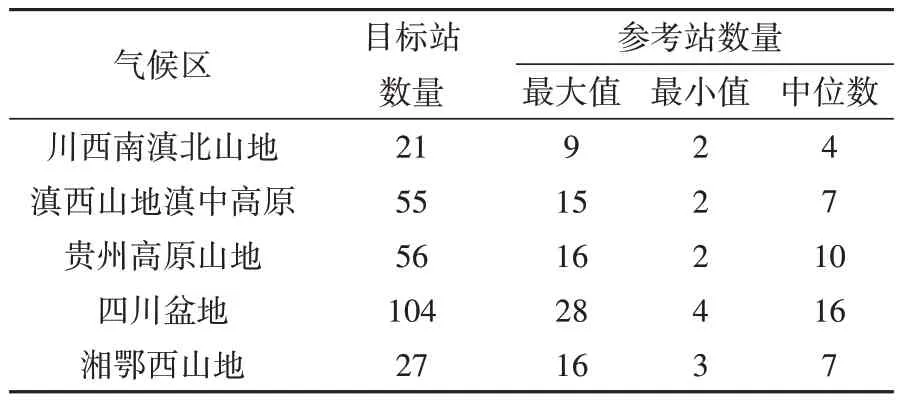
表1 5个气候区内目标站与参考站数量Tab.1 The numbers of target and reference stations in five climatic divisions
1.3 插补方法与评估指标
应用空间回归、标准序列法和随机森林3种插补方法,对中国西南地区5个气候区内观测站日平均气温与2个百年站月平均气温进行插补试验,并对插补结果进行检验评估。
(1)空间回归插补方法
该方法基于Hubbard等(2007)的空间回归质量控制算法,围绕目标站与参考站的均方根误差序列建立的一种插补方案。其步骤:首先,对参考站与目标站的观测要素进行相关分析,剔除未通过α=0.05显著性检验且相关系数小于0.5的参考站;其次,建立目标站与参考站观测要素的回归方程,并计算构建参考站的均方根误差序列;最后,计算基于加权的目标站观测要素估计值。计算公式如下:
截至2018年9月底,培训班已经完成22期,学员超过460人,培训也已经进入第四轮。而且,随着培训班一轮轮积累经验,课程设计也日益完善。
式中:i为参考站序号;n为参考站数量;j为日期序号;m为日数;xij为第i参考站第j日平均气温观测值;̂、xj分别为目标站第j日平均气温估计值与观测值;ai、bi是第i参考站的回归系数;ei为第i参考站平均气温的均方根误差;k为回归方程的阶数,本文取值为1;̂'j是基于加权(参考站)的目标站第j日平均气温估计值。
(2)标准序列插补方法
该方法是基于目标站和参考站观测要素数据的多年均值序列与标准差序列建立的插补方法,计算公式如下:
(3)随机森林插补方法
该方法是基于机器学习采用Scikit-Learn建立的一种插补方法。其中,随机森林模拟器决策树数量为100,迭代深度为5,以均方误差(Mean Squared Error,MSE)值作为节点分割指标。在特征值设定上,除观测值信息外,还纳入了参考站经纬度、地表覆盖类型和坡度坡向以及观测日期等信息。计算流程:依据前面空间回归插补方法中已得到的目标站及其对应的参考站序列,以逐站增加的方式建立多个不同特征值序列,如若该目标站有n个参考站,则对应分别建立n组特征值序列;对由每一组特征值序列构成的数据集按照3∶7的比例分成训练集和测试集,其中训练集数据输入随机森林回归器进行训练并生成回归器模型,再将测试集数据输入该模型,以生成插补计算结果,即可获得不同参考站组合条件下随机森林插补结果。具体流程如图2所示。

图2 随机森林插补方案流程图Fig.2 The flowchart of random forest interpolation scheme
采用平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Squared Error, RMSE)(黄嘉佑,2004)以及误差位于±0.5 ℃和±0.8 ℃区间的样本数与总样本数的比值(分别记为P0.5和P0.8)作为评估指标(插补精度),对上述3种方法插补结果进行精度检验。
2 三种气温插补结果对比分析
图3是中国西南地区5个气候区日平均气温3种插补方法P0.5、P0.8检验指标与参考站数量的关系。可以看出,5个气候区3种插补方法的P0.5、P0.8变化具有一致性,起初均随参考站数量增加迅速增大,当参考站为5~8个时拟合结果较好,之后变化较为平缓,表明参考站数的增加有助于提高插补精度,整体上最优参考站数为7。从P0.8指标变化曲线来看,3种方法在四川盆地的日平均气温插补精度基本在0.90左右,远高于其他区域,贵州高原山地、湘鄂西山地和滇西山地滇中高原插补精度依次降低(0.70~0.80),而川西南滇北山地插补精度最低(0.60~0.70)。对比发现,各气候区3种方法的日平均气温插补精度P0.5均小于P0.8。其中,四川盆地空间回归和标准序列方法的插补精度P0.5最高,基本都在0.70以上,而随机森林方法的P0.5为0.45~0.70;贵州高原山地和湘鄂西山地3种方法的插补精度P0.5都为0.50~0.70,而滇西山地滇中高原和川西南滇北山地最小为0.40~0.60。3种插补方法对比来看,空间回归方法的插补精度在5个气候区基本都是最高,尤其在贵州高原山地和湘鄂西山地。
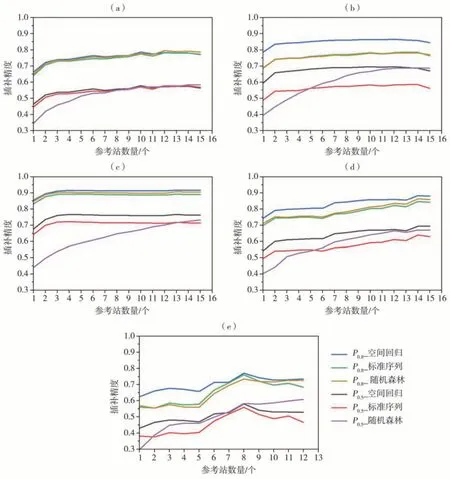
图3 1970—2020年中国西南地区5个气候区日平均气温3种方法插补精度与参考站数量的关系(a)滇西山地滇中高原,(b)贵州高原山地,(c)四川盆地,(d)湘鄂西山地,(e)川西南滇北山地Fig.3 The relation between the accuracy of daily mean temperature interpolated by three methods and numbers of reference stations in five climatic divisions in southwestern China from 1970 to 2020(a) western Yunnan mountains and central Yunnan plateau, (b) mountainous region of Guizhou plateau, (c) Sichuan Basin,(d) mountainous region of western Hunan and western Hubei, (e) mountainous region of southwestern Sichuan and northern Yunnan
表2是以7为最优参考站数条件下西南地区5个气候区3种气温插补方法的MAE和RMSE。总体来看,随机森林方法插补的气温MAE和RMSE均最小,分别为0.15~0.26 ℃、0.35~0.62 ℃,标准序列方法插补误差最大,且两种误差具有同步性;川西南滇北山地气温插补误差最大,其次是滇西山地滇中高原,四川盆地最小。
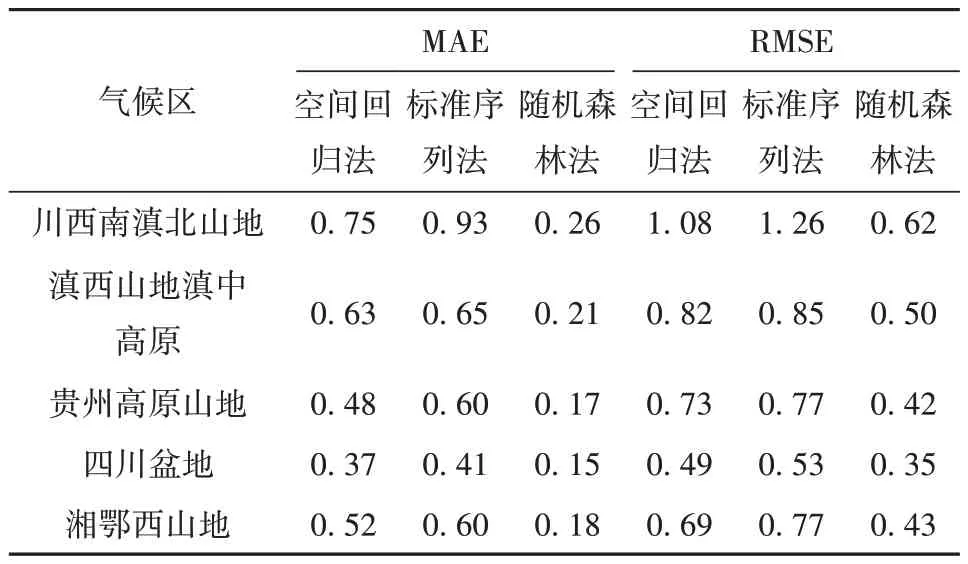
表2 最优参考站数量条件下1970—2020年中国西南地区各气候区3种气温插补方法的MAE与RMSETab.2 The MAE and RMSE of temperature with three interpolation methods under the optimal numbers of reference stations in five climatic divisions in southwestern China from 1970 to 2020 单位:℃
3种方法的气温插补精度与下垫面有关,西南地区多山地高原,平坝、河谷、山岭纵横其间,地形起伏大。地形起伏度是表征下垫面地貌状况的重要指标(马士彬和安裕伦,2012)。经统计,5个气候区区域平均地形起伏度为0.90~3.13,站点平均起伏度为0.59~2.20,川西南滇北山地起伏度最大,其次是滇西山地滇中高原,四川盆地最小(表3),即盆地地势最为平坦,而川西南滇北山地地势最为崎岖。
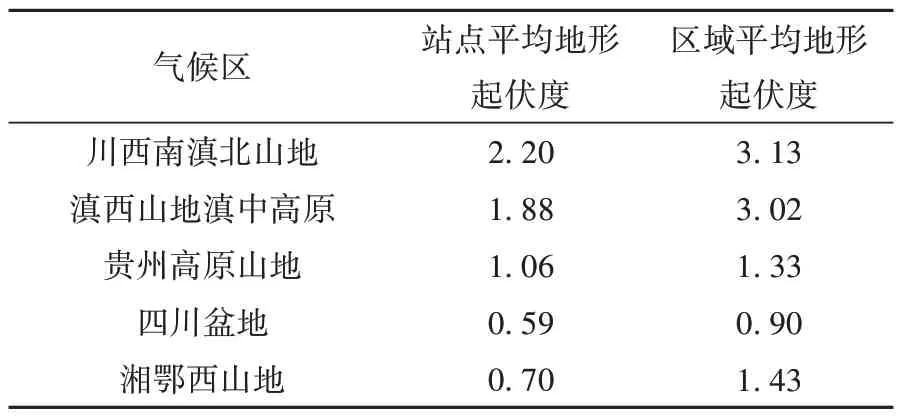
表3 中国西南地区5个气候区站点及区域平均地形起伏度Tab.3 The station and regional average relief in five climatic divisions in southwestern China
这一地貌分布状况也可以从坡度变化看出,四川盆地、湘鄂西山地、贵州高原山地坡度大部分在3级以下(S≤15°),而川西南滇北山地、滇西山地滇中高原坡度大部分在4级以下(S≤25°)。其中,四川盆地54%的格点坡度为1级(S≤2°),占比最大,其次为2级(2°<S≤6°),占比为27%;贵州高原山地和湘鄂西山地坡度大多为2级,占比分别为49%和43%,前者其次为1级,占比32%,后者其次为3级(6°<S≤15°),占比33%;川西南滇北山地、滇西山地滇中高原近40%的格点坡度为3级,其次是2级,占比分别为31%、34%[图4(a)]。总体来看,地形起伏程度自四川盆地、贵州高原山地、湘鄂西山地、滇西山地滇中高原、川西南滇北山地逐渐增大。另外,从各气候区站点坡度分级情况[图4(b)]看出,各站点坡度均在3级以下,四川盆地、滇西山地滇中高原60%以上的测站坡度为1级,占比最高,而川西南滇北山地的站点坡度大多也为1级,占比41%;贵州高原山地站点坡度以1级和2级为主,2级占比略高于1级,而湘鄂西山地的站点坡度2级占比最大,其次为3级。

图4 中国西南地区5个气候区区域(a)及站点(b)平均坡度等级占比Fig.4 The proportion of regional (a) and station (b) average slope grades in five climatic divisions in southwestern China
上述分析可见,各气候区下垫面状况对3种方法日平均气温插补精度影响明显,下垫面越平坦,插补精度越高,四川盆地及其测站平均地形起伏度最小,坡度等级最低,其插补精度曲线变化较平缓,精度也最高;下垫面崎岖地区气温插补精度曲线变化较大,插补精度有所下降,如川西南滇北山地和滇西山地滇中高原,2个气候区平均地形起伏度都在3.00以上,且坡度在3级以上的占比约50%,但站点平均起伏度在2级以上的占比前者(59%)远高于后者(40%),因而气温插补精度曲线的波动前者比后者明显,前者插补精度相对更低;湘鄂西山地与贵州高原山地的区域平均地形起伏度相似,站点平均地形起伏度前者略低于后者,但前者区域平均坡度在3级以上的占比(36%)远大于后者(19%),且站点平均坡度为3级的占比前者(32%)也远高于后者(10%),故湘鄂西山地气温插补精度曲线相对贵州高原山地有一定的波动。
此外,还统计了5个气候区及其站点下垫面地表覆盖情况(图5),发现5个气候区下垫面都以耕地、林地、草地为主,而观测站大都修建于城镇,故而所处的地表覆盖类型大部分为人造地表,表明西南地区观测站的地表覆盖状况对气温插补结果影响不明显。

图5 中国西南地区5个气候区区域(a)及站点(b)地表覆盖类型占比Fig.5 The proportion of regional (a) and station (b) land cover types in five climatic divisions in southwestern China
3 气温插补方法在百年气象站的应用
采用上述3种插补方法,对中国西南地区重庆市北碚和四川省犍为2个百年站的历史月平均气温数据进行插补试验,其中以各站为中心100 km内与目标站高度差小于300 m的其他百年站作为参考站。
图6是基于空间回归和标准序列2种方法插补的犍为和北碚站月平均气温P0.5、P0.8检验指标与参考站数量的关系。整体来看,2种方法的月平均气温插补精度随参考站数增加都保持着较高精度,P0.5、P0.8值皆在0.90以上,但2站随参考站数增加变化不一致,当参考站数为5时,2种方法插补精度相对最高。因此,以5作为最优参考站数,则该条件下北碚站空间回归和标准序列方法插补的月平均气温RMSE(MAE)分别为0.211(0.149)、0.223(0.171),犍为站分别为0.187(0.130)、0.225(0.159),误差较小,2种方法具有较好的插补效果。

图6 犍为(a)和北碚(b)站2种方法插补的月平均气温P0.5与P0.8检验指标与参考站数量的关系Fig.6 The relation between P0.5, P0.8 test indexes of monthly mean temperature with two interpolation methods and numbers of reference station at Qianwei (a) and Beibei (b) stations
依据上述最优参考站数(5个),将2站的经纬度、坡度坡向和地表覆盖信息作为特征值输入,在样本总量不变、训练集和测试集分割比例固定条件下进行4次随机森林插补试验,每次参与试验的样本随机。图7是犍为和北碚站基于随机森林方法的月平均气温插补值与观测差值随样本数的变化,发现绝大部分样本气温插补值与观测的差值在±0.5 ℃以内,犍为和北碚站月平均气温插补的RMSE(MAE)分别为0.147(0.061)、0.142(0.060),P0.8(P0.5)分别为0.98(0.95)、0.99(0.95),误差小且位于±0.5 ℃和±0.8 ℃区间的样本数占比高,表明随机森林插补方法对于具有连续属性的气温序列数据具有较好的拟合能力。
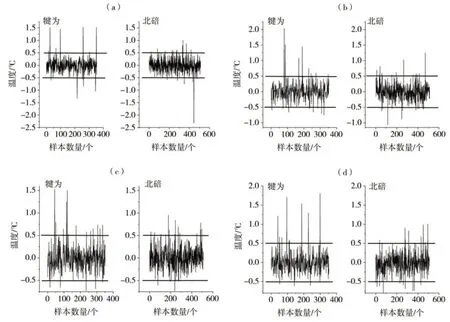
图7 随机森林方法插补的犍为和北碚站月平均气温与观测差值随样本数的变化(a)第1次试验,(b)第2次试验,(c)第3次试验,(4)第4次试验Fig.7 The variation of difference between monthly mean temperature interpolated by random forest method and observation with sample numbers at Qianwei and Beibei stations(a) the first test, (b) the second test, (c) the third test, (d) the forth test
为进一步判断百年站气温序列数据中极值对随机森林插补方法的影响,分别将12、1月和7、8月作为出现极端低温和高温的月份(简称“极值月”),以4次插补试验中超出±0.5 ℃的数据作为极值,分别统计2站每次试验中极值出现于极值月的样本量及其占比(与极值总样本量的百分比),占比越大表明序列中的极值对插补方法的影响也越大。图8是随机森林方法4次插补试验的极值位于极值月的样本量占比,发现犍为站70%以上的极值出现在极值月,而北碚站极值出现在极值月的样本量占比相对较低,平均在50%左右,表明气温观测序列中的极值对插补方法有一定影响,犍为站序列中的极值较北碚站影响更大,即随机森林插补方法不能完全拟合气温观测序列中的极值。这说明还需要进一步优化该方法中的特征值和超参数设置,其中本文超参数设置未进行迭代优化而是采用固定值,一定程度上影响了插补能力,而特征值选择上,虽然引入经纬度、坡度坡向、地表覆盖等地形地貌信息,但仍有其他相关要素有待挖掘。因此,通过上述两方面优化,可以进一步提高随机森林插补方法精度和适用性。
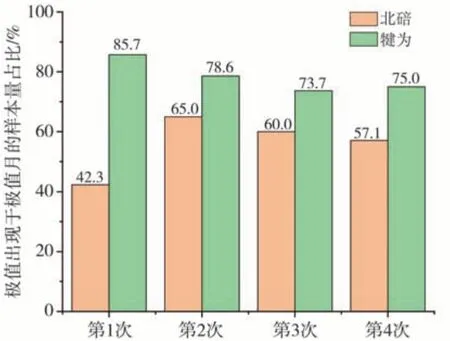
图8 随机森林方法4次月平均气温插补试验极值出现在极值月的样本量占比Fig.8 The proportion of extreme temperature samples in extreme value months to all samples of extreme value in four interpolation tests with random forest method
4 结论
应用标准序列法、空间回归和随机森林3种方法,对中国西南地区5个主要气候区内观测站的日平均气温序列数据及北碚、犍为2个百年站的月平均气温序列数据进行插补试验,发现3种方法对西南地区5个气候区各站点气温日均值序列数据和百年站气温月均值序列数据插补精度较高,但地形因素的影响不容忽略,主要结论如下:
(1)3种方法对中国西南地区5个气候区日平均气温和2个百年站月平均气温的插补效果较好,整体上空间回归方法的插值精度最高、适用性最好,无论在地形相对平坦的四川盆地,还是在地形较为崎岖的川西南滇北山地,空间回归方法的插补精度相较其他两种方法高,日平均气温插补的P0.8在四川盆地约0.90,在川西南滇北山地在0.60以上。
(2)不同气候区日平均气温插补精度随参考站数增加变化特征虽有不同,但大都在5~8站时插补精度较高,最优参考站数可有效降低插补误差。下垫面状况对3种方法气温插补精度影响明显,下垫面越平坦,插补精度越高,地势较平坦的四川盆地插补精度远高于地势较为崎岖的滇西山地滇中高原、川西南滇北山地等区域。
(3)随机森林插补方法对于具有连续属性的气温序列数据具有较好的拟合能力,绝大部分样本的气温插补值与观测差值在±0.5 ℃以内,但不能完全拟合序列中的极大值,未来还需要通过迭代优化等技术进一步优化该方法中的超参数设置,同时结合气温要素特点,补充更多的关联特征值。
猜你喜欢
青海草业(2022年2期)2022-07-23 09:34:58
小哥白尼(军事科学)(2019年5期)2019-08-27 00:44:06
新农民(2019年2期)2019-08-16 07:11:02
乡村地理(2018年3期)2018-11-06 06:50:54
农家科技下旬刊(2017年12期)2018-04-16 08:53:10
乡村地理(2018年4期)2018-03-23 01:53:48
现代农业科技(2018年22期)2018-01-15 11:44:10
农家科技下旬刊(2017年9期)2017-11-12 12:51:10
科技资讯(2017年23期)2017-09-09 13:08:43
山东林业科技(2017年1期)2017-06-29 07:53:48
