
空调控制参数用户设定偏好的预测方法
2023-11-11 09:38孙齐鸣庄大伟曹昊敏丁国良戚文端邵艳坡
暖通空调 2023年11期
孙齐鸣 庄大伟 曹昊敏 丁国良△ 戚文端 邵艳坡 郑 雄 张 浩
(1.上海交通大学,上海;2.广东美的制冷设备有限公司,顺德)
0 引言
随着我国经济发展水平的提高,人们对建筑室内环境的热舒适性要求也越来越高[1]。在不同的环境条件下,空调器满足用户热舒适性要求的设定参数是不一样的。在环境条件变化时,用户为了满足舒适性,不得不相应地调整设定参数,这会给用户带来不便。而根据用户偏好自动化调整空调设定参数的方法可以免去用户的操作。
现有的空调器自动化程度较低,需用户手动输入指令或定义设定参数,不具备根据用户偏好自动化调整空调设定参数的功能。为了自动化设定空调参数,需要对设定参数的变化规律进行分析,这要求对空调运行的历史设定数据进行学习。目前有关空调设定数据的研究涉及到大量的数据计算与分析,均需借助计算机的快速计算能力[2-4]。例如Zhou等人在高性能计算机上对收集的房间内环境参数数据进行学习与分析,并以此识别了空调器的运行模式[2]。Zhao等人在计算机上运用神经网路模型对房间内环境参数进行了分析,实现了对空调能耗的准确预测[4]。而目前空调器单片机的存储器宽度多为16位,处理能力不足,仅依靠空调器单片机无法完成学习和预测设定参数的任务[5-7]。
快速发展的云计算技术为分析处理大量数据提供了便捷的解决方法[8-9]。例如谢宜鑫使用云计算技术对空调能耗数据进行挖掘,从而实现空调能耗模式的预测[10]。如果将复杂的计算分析任务放在空调企业云端服务器上,空调器单片机则可以节省出空间执行其常规任务。
为了能够实现空调器运行中参数的自动设定,本文拟基于云端学习与空调器本地计算相结合的思路,实现对于空调器运行中控制参数用户偏好的预测。
1 技术路线
针对空调器单片机计算能力不足导致无法自动化预测设定参数的问题,本文提出云端学习与空调器本地计算相结合的技术路线,如图1所示。具体的做法是:在高计算能力的云端服务器上建立学习算法,用于解决复杂的数据分析和模型建立的任务;云端服务器将建立好的模型转化为可供空调器单片机识别的多维矩阵格式;而在仅可执行简单命令的本地单片机上建立预测方法,用于识别云端服务器生成的多维矩阵;单片机下载包含关系模型信息的多维矩阵后即可计算出用户设定参数的预测值。
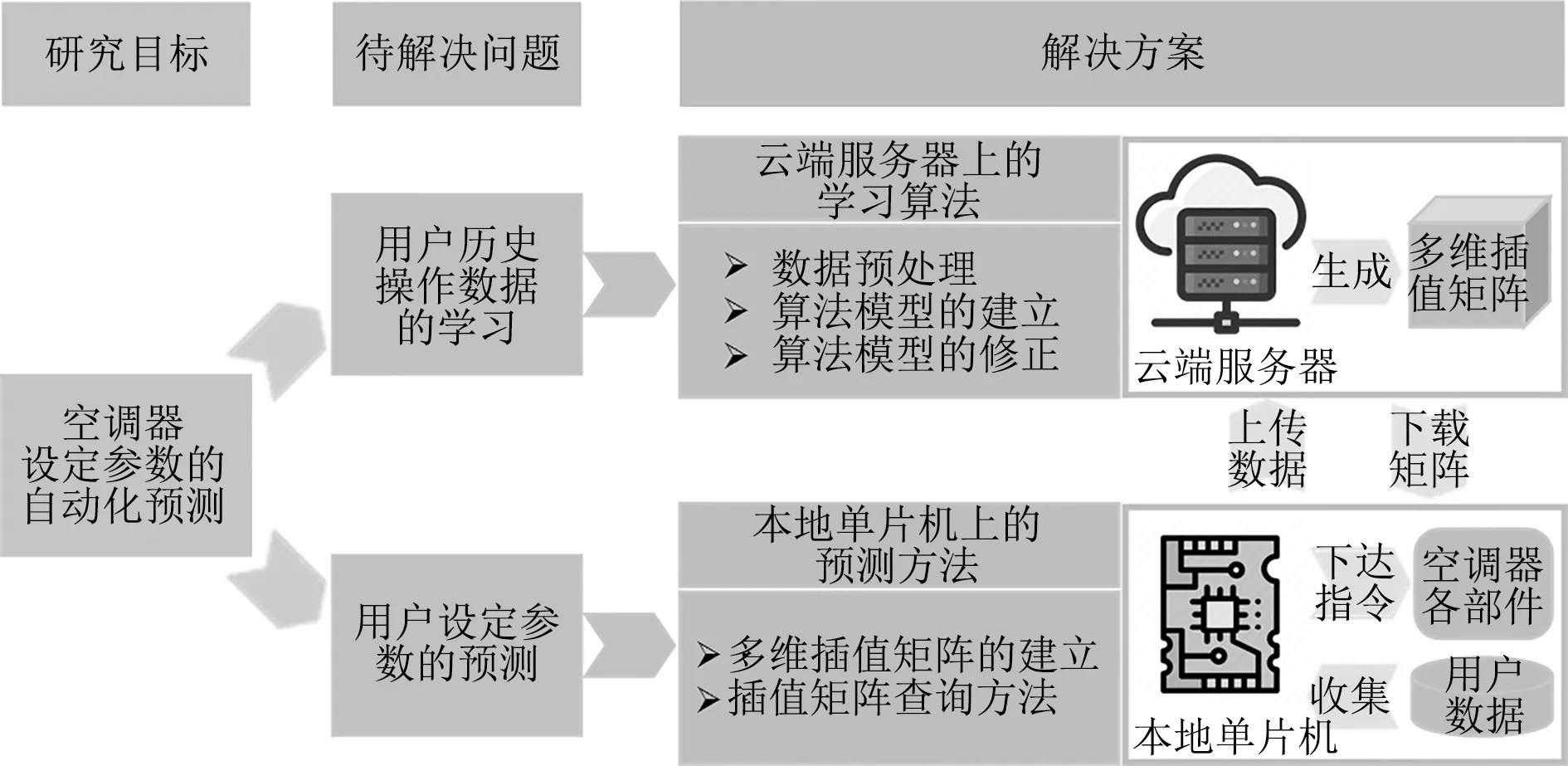
图1 空调云端服务器与本地单片机的交互流程图
在上述方案中,需要解决的是“云端服务器上学习算法的开发”和“本地单片机上预测方法的开发”问题。云端学习算法的开发,包括建立环境参数与用户设定参数之间的关系模型,以及针对用户高频调节时关系模型的动态修正方法。本地预测方法的开发包括关系模型的读取,关系模型向多维插值矩阵的转化,以及多维插值矩阵预测值的计算。
云端学习算法和本地预测方法在实际应用过程中需要保证可靠性和准确率。为了验证二者的可靠性与准确率,本文基于用户历史操作数据分别对算法和方法进行交叉验证和测试验证,操作数据中的一部分用于验证云端服务器上开发的学习算法的可靠性,剩余的用于验证本地单片机上建立的预测方法的准确率。
2 云端学习算法
2.1 数据预处理
开发云端学习算法需要对用户的历史操作数据进行分析与学习,而分析与学习的效果取决于数据的质量。由于数据采集过程中的硬件失效或人为误导等因素,采集到的数据可能混有噪声数据;又由于用户偏好设定参数集中于某一区间,使用数据中存在着不平衡的问题。这2个问题会降低数据整体的质量,对分析过程中的精度和性能影响极大[11-12]。而噪声数据消除和数据重采样的方法可以分别解决这2个问题。
噪声数据消除旨在对数据中的错误值和离群值进行消除。空调器的运行数据主要包括时间、型号、环境温湿度、设定参数、各项功能启停状态、各部件的运行参数等。空调器每隔15 min自动监测、记录1次运行参数,当用户通过遥控或其他方式调整设定参数或运行模式时,空调器也会自动记录该次调整数据。因为断网、机器故障或人为操作等原因,空调器会产生不合要求的噪声数据。本文通过对相关参数进行约束来删除噪声数据,并通过对非数值格式的数据赋予数字标签的方式来对数据进行格式转化,从而能够筛选出有效的数据集。
数据重采样旨在解决数据集中存在的不平衡问题。用户设定偏好预测包括对空调器设定温度和设定风速的预测,而用户的偏好设定温度和风速多集中于某一固定区间,存在着明显的不平衡现象。为了防止模型训练出的结果出现失衡问题,本文对数据集进行了样本重采样,即在用户设定频次较少的数据集附近插入调和后的新数据点,使设定频次较少的数据集的数量扩充至高频设定数据集的数量。以上海地区10户用户夏季的使用情况为例,用户设定温度和设定风速的频数分别如图2a、b所示。用户设定温度偏好集中在24~28 ℃的区间内,出现64 344次,占据总频次的93.2%;而用户设定风速偏好多为自动风,出现54 723次,占据总频次的84.1%。
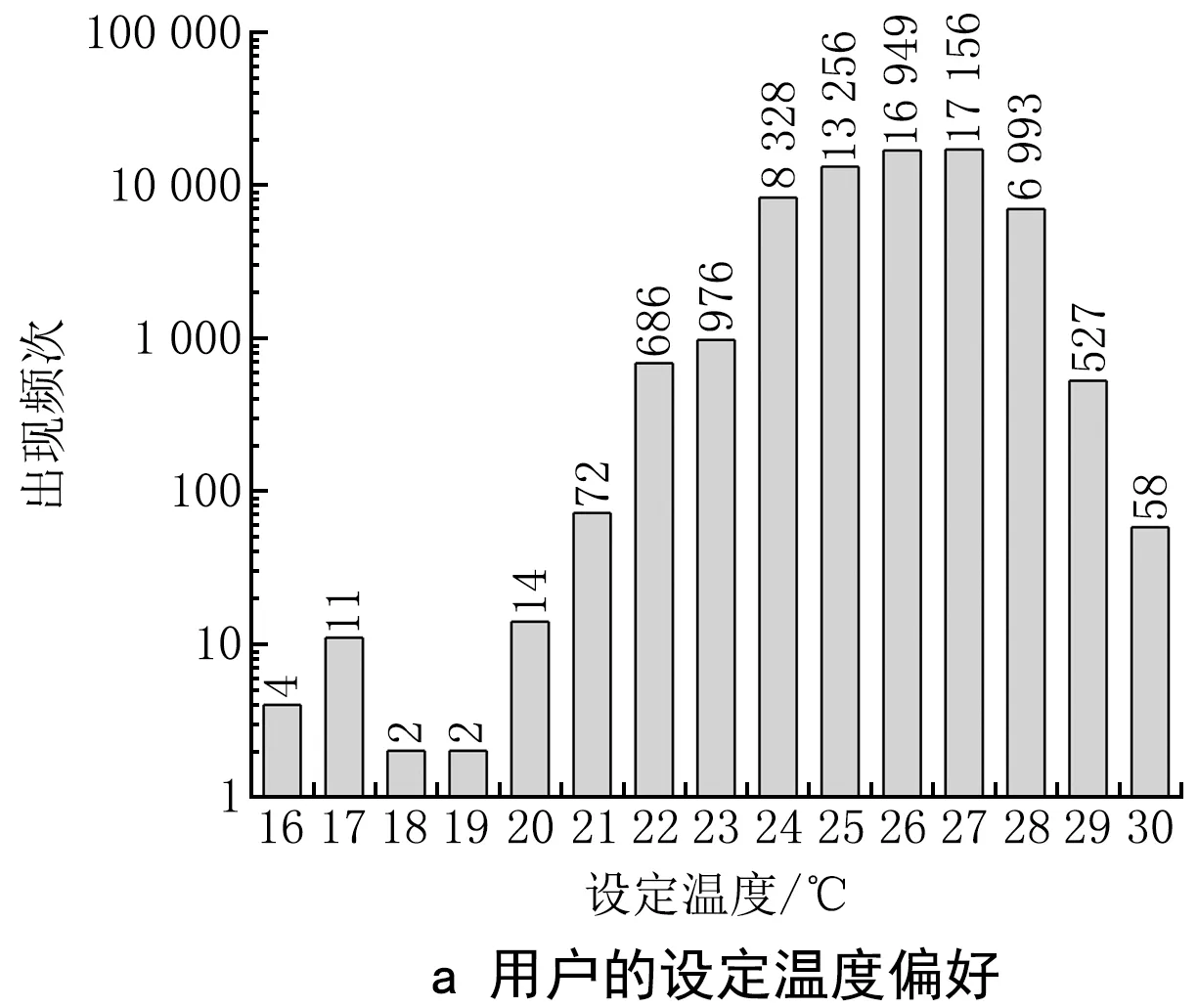
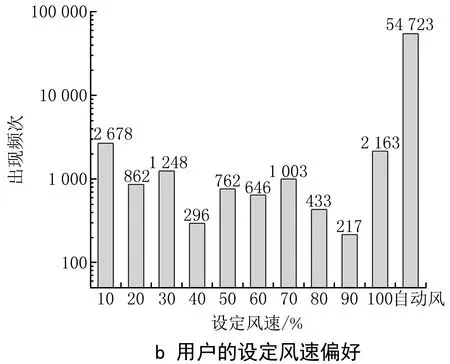
图2 上海地区10户用户的总体设定偏好
以上海地区10户用户的原始数据为例,经过数据重采样后,用户低频设定的数据量与高频设定的数据量持平。具体数据的对比结果如表1所示。
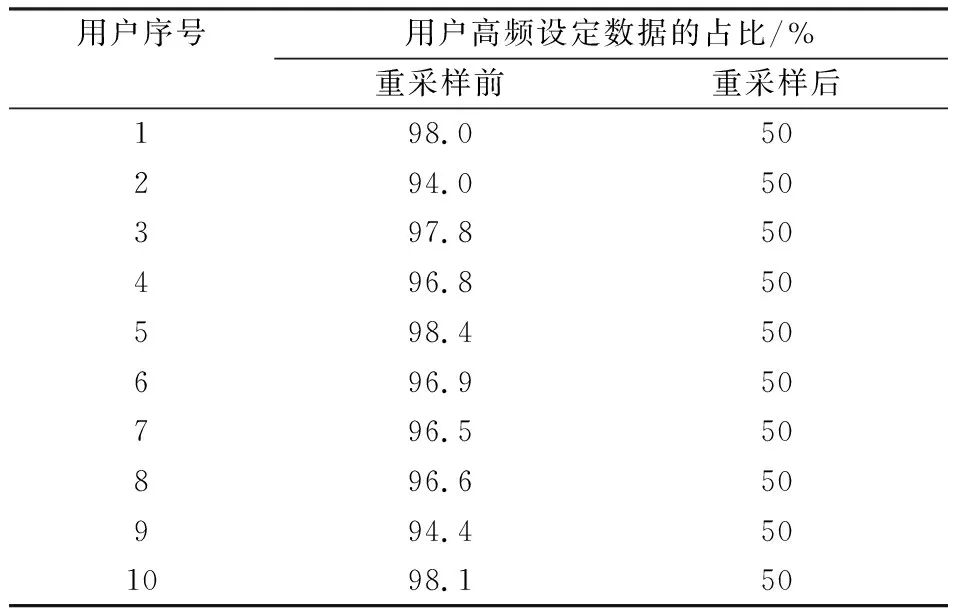
表1 上海地区10户用户数据重采样前后对比
2.2 算法模型的建立
为了实现对用户设定温度和风速偏好的预测,需要对使用数据中自变量与因变量的关系进行分析并建立预测模型,而快速发展的机器学习算法为找出变量间相互关系提供了有效的解决手段[13]。梯度提升算法(light gradient boosting machine,LightGBM)[14]具有快速性、高精度、内存消耗低的优点,且处理大批量数据的效果好,可以高效学习与分析用户历史操作数据。该算法学习输入自变量和因变量之间的关系,将自变量与因变量之间的关系储存在算法模型之中。
模型的输入参数为月份、日期、小时数、分钟数、室内环境温度、冷凝器出口温度、蒸发器出口温度、室外环境温度、室内湿度、设定温度变化量和设定风速变化量,这些不同输入参数统称为数据特征;模型的输出参数为用户设定温度和用户设定风速。为了降低算法的消耗并提高算法适用性,需要寻找到与用户设定参数(设定温度和设定风速)关联性较强的数据特征。本文使用递归式特征消除的方法对空调运行数据进行筛选,递归地分析特征集来选择与目标值关联性最强的数据特征,并用特征重要度来反映与目标值的关联性强弱[15]。
对各个用户数据集进行递归式特征消除后,得到了数据特征的重要度排序,如图3所示。本文为了降低插值矩阵的维度,使之能储存于空调器单片机上,选取4条排序靠前的特征量作为算法模型的输入,即室内环境温度、室外环境温度、分钟数和室内湿度。用户设定温度和风速作为算法模型的输出。
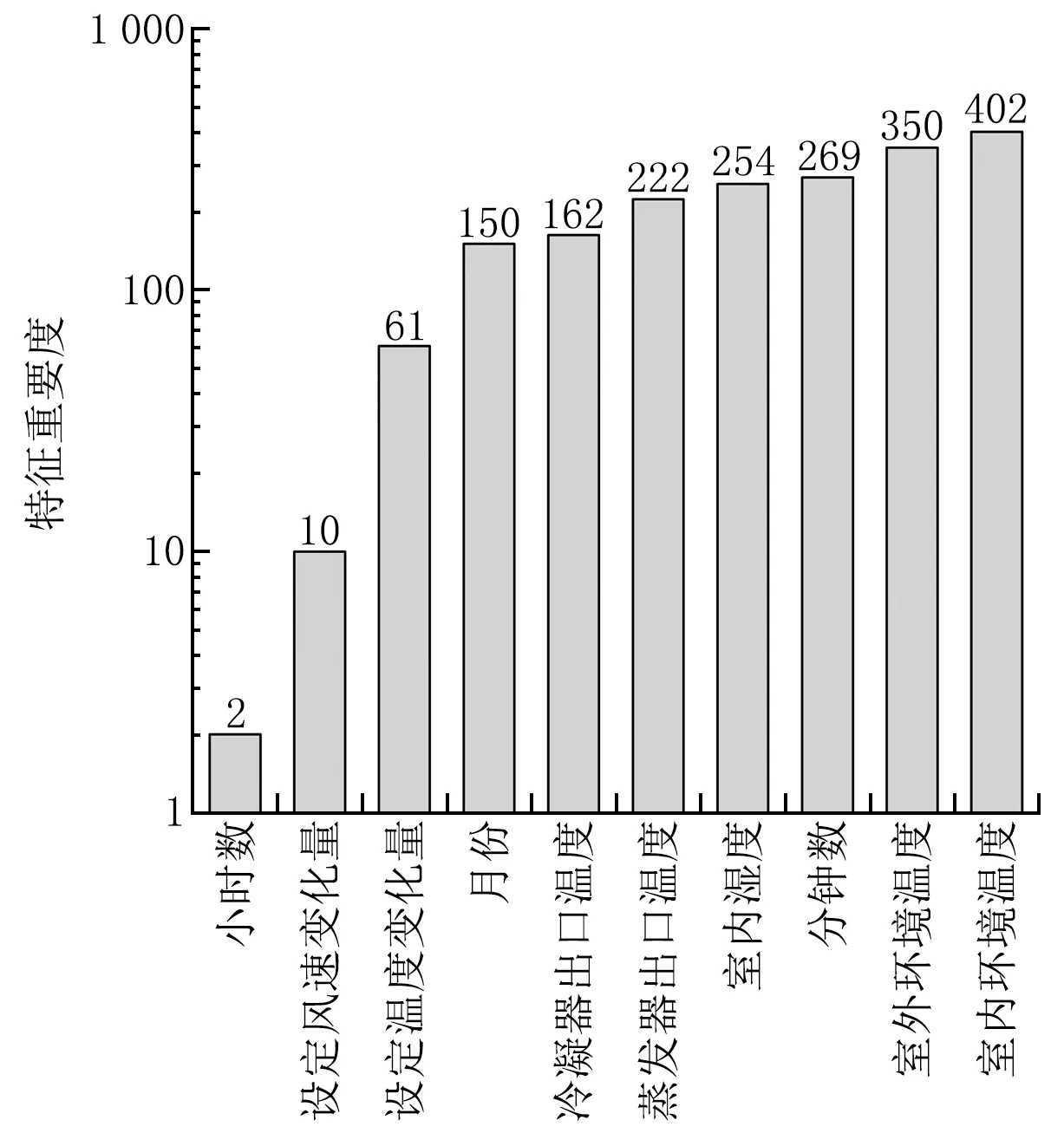
图3 递归式特征消除后的数据特征重要度排序
2.3 算法模型的修正
建立的算法模型学习了用户的历史使用习惯,但此模型不会随着用户的使用而更新。随着使用时间的延长,模型预测的设置参数可能会偏离近期用户的使用偏好,为此需要对模型进行修正,使用户在长期使用过程中仍能给出高准确率的预测值。本文提出将该模型修正为短期频繁训练的动态模型的方法。
此动态模型的更新周期可以由用户设定,确保捕捉用户近期的使用习惯,具体的训练过程如图4所示。首先基于历史数据对模型进行训练,经过一个周期后,空调器所记录的新的操作数据将被添加到训练数据集中,模型被重新训练并用于下一周期的用户偏好预测。随着使用时间的延长和训练次数的增加,动态模型给出的预测值会更加符合用户的使用习惯。
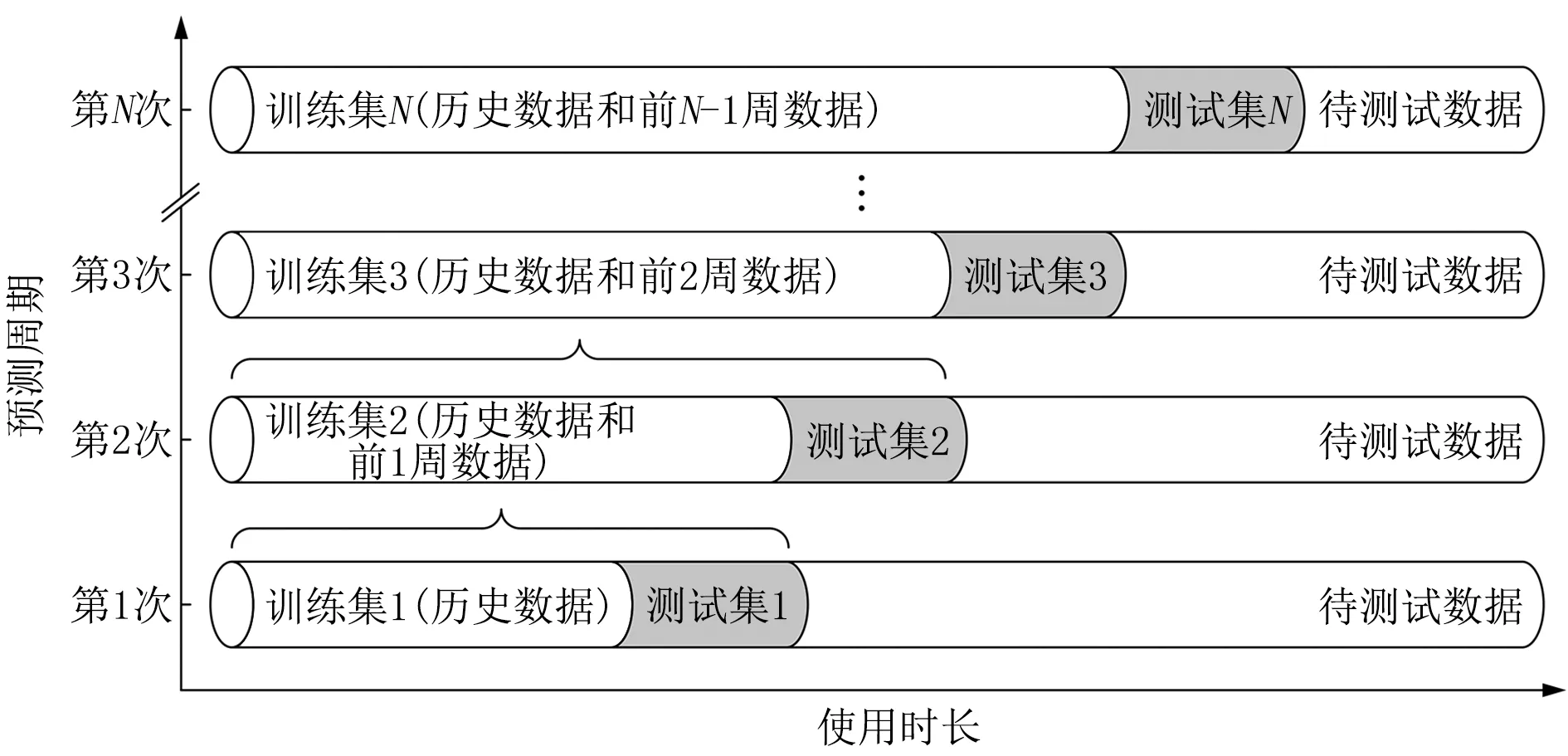
图4 动态模型更新方法示意图
3 本地预测方法
3.1 多维插值矩阵的建立
云端服务器协助空调器本地进行设定参数预测的主要过程为:云端服务器接收空调运行参数,经过修正后的动态模型学习与训练后,将输出的用户设定参数作为目标值下达给空调器单片机,单片机再结合控制策略调节空调器各部件。而空调器单片机存在算力不足和断网时无法接收云端数据的问题。本文提出多维矩阵插值的方法用于识别云端指令并下达指令给单片机,以解决单片机存在的算力不足和断网时无法接收云端数据的问题。
本地多维矩阵用于插值预测方法的示意图见图5。首先,云端算法在对空调运行历史数据进行学习后,会得到输入输出变量之间关系的数学模型;随后,根据输入自变量的特征值数目确定插值矩阵的维度,对每个特征按指定间隔进行划分后再组合,并在插值矩阵中储存不同特征维度组合下的设定参数。每次有新数据上传至云端时,云端算法都会对模型进行一次修正并更新插值矩阵。空调器单片机便从云端下载更新完成后的插值矩阵。
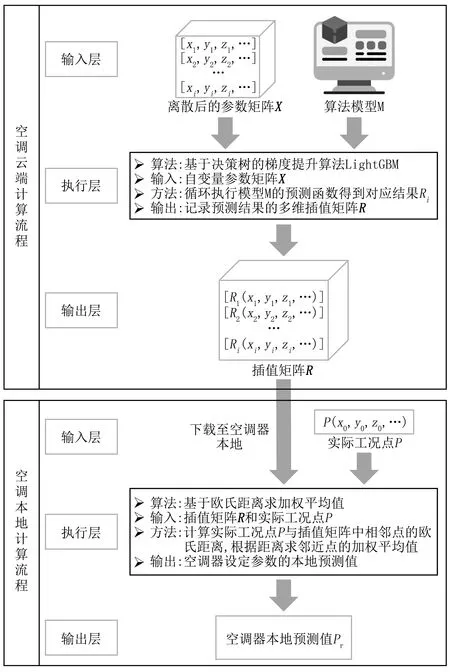
图5 多维矩阵插值预测方法示意图
3.2 插值矩阵查询方法
矩阵查询方法被编写入空调器本地的单片机上,以三维插值矩阵预测方法为例,如图6所示,室内温度、室外温度和时间3个特征属性作为x、y、z坐标,实际工况点与其相邻节点的坐标的欧氏距离di为
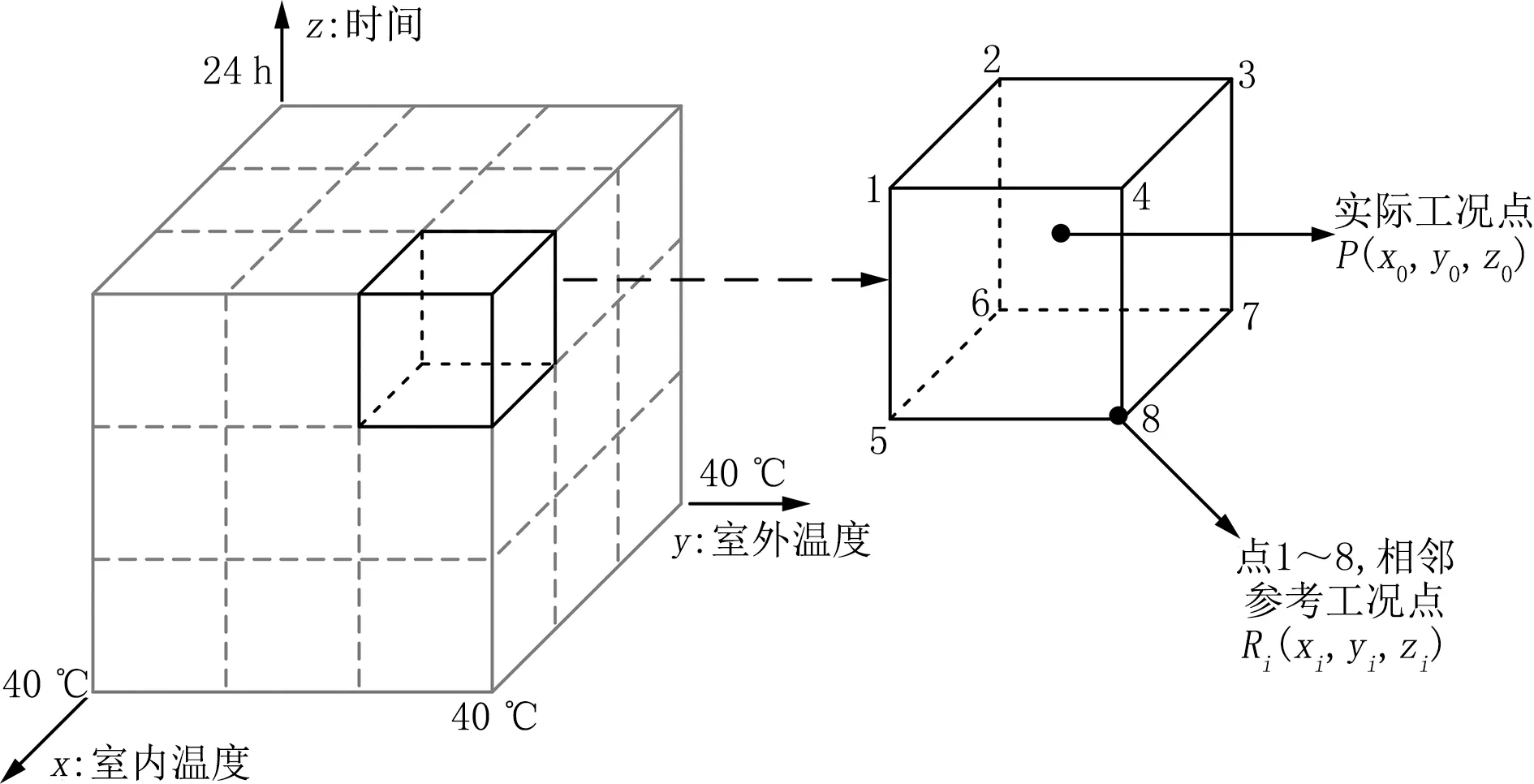
图6 插值矩阵方法示意图
(1)
式中i为三维矩阵下实际工况点的相邻节点的序号;x0、y0、z0分别为实际工况点的三维特征参数,即对应室内温度、室外温度和时间;xi、yi、zi分别为第i个相邻节点的三维特征参数。
为了确定预测推荐值,需分析实际工况点与相邻参考工况点的关系,在考虑计算负荷和预测准确度的前提下,本文提出了8点加权平均法则。根据实际工况点与相邻节点的欧氏距离的倒数对节点的设定参数做加权,与实际工况点距离越近的节点,其权重越高。加权后得到的设定参数即作为本地模型的预测值y,可由下式给出:
(2)
式中pi为储存在插值矩阵上的第i个相邻节点的设定参数。
空调器本地单片机读取运行数据后,定期上传至云端服务器,由云端学习算法根据最新数据来训练模型,并定期更新插值矩阵,再由空调器本地下载该矩阵,最后根据矩阵查询方法得到用户设定参数的预测值。
4 云端与本地预测方法的验证
4.1 学习算法交叉验证结果
云端服务器上建立的学习算法在应用过程中需要有足够的准确率,为此需要对算法模型的准确率进行验证。算法模型的输入参数为室内温度、室外温度、时间和室内湿度。模型的输出参数为用户设定温度和风速。模型的验证准确率Av定义为
(3)
式中npre为用户设定温度(风速)与预测值的绝对误差在±0.5 ℃(±10%)内的次数;nt为测试数据集中的总条目数。
为了避免训练集数据自验证而产生过拟合的问题,本文在验证上述模型时使用k折交叉验证方法,即将初始数据集均分为k个子集,其中k-1个子集作为训练集,剩余1个作为测试集用于测试,依次重复k次,并将测试k次得到的准确率平均后作为交叉验证的准确率。考虑到需要对数据集充分使用,以及各个子集需要有足够的数据,k取值建议在3~6之间,此处交叉验证的k值取为5。
为了评价算法模型在单个地区的通用性和适用性,定义地区平均准确率Aa为
(4)
式中k为用户序号;m为地区用户的数目;nt,k为第k个用户测试集的数据容量;Ak为第k个用户测试集的分类准确率。
本文选择了位于重庆、广州和上海3个大型城市共30户用户的历史数据,这些用户的数据具有地域差异大、涵盖范围广、使用时间长的特点,数据集的主要信息如表2所示。对于上海地区的10户用户,其交叉验证数据集包含的条目最多为14 949条,最少为1 777条,平均为6 503条;对于广州地区的10户用户,其交叉验证数据集包含的条目最多为9 337条,最少为1 889条,平均为7 190条;对于重庆地区的10户用户,其交叉验证数据集包含的条目最多为7 513条,最少为1 911条,平均为4 296条。

表2 交叉验证数据集的主要信息
数据集交叉验证结果如图7~9所示。

图7 上海地区用户夏季运行数据交叉验证结果
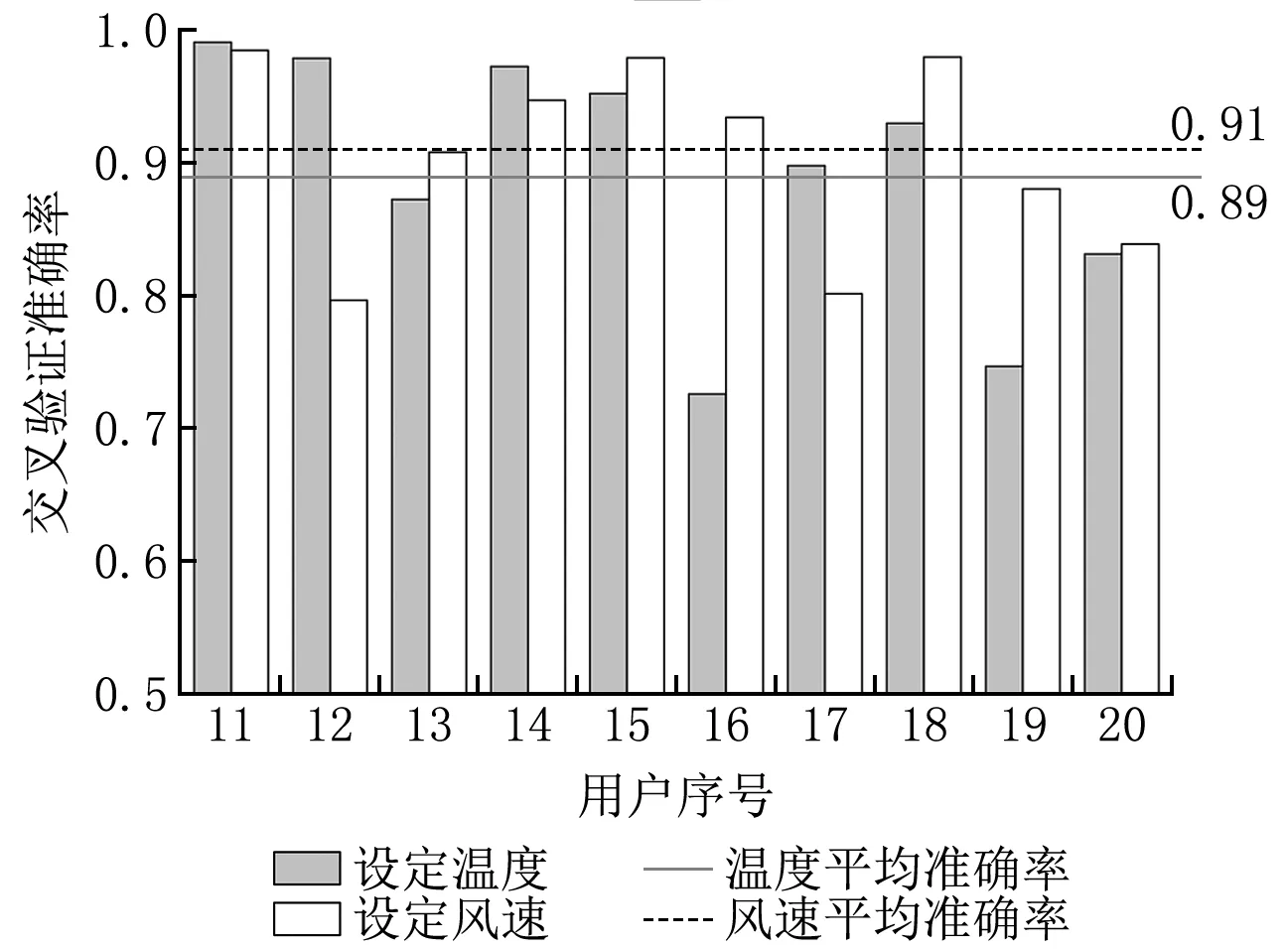
图8 广州地区用户夏季运行数据交叉验证结果
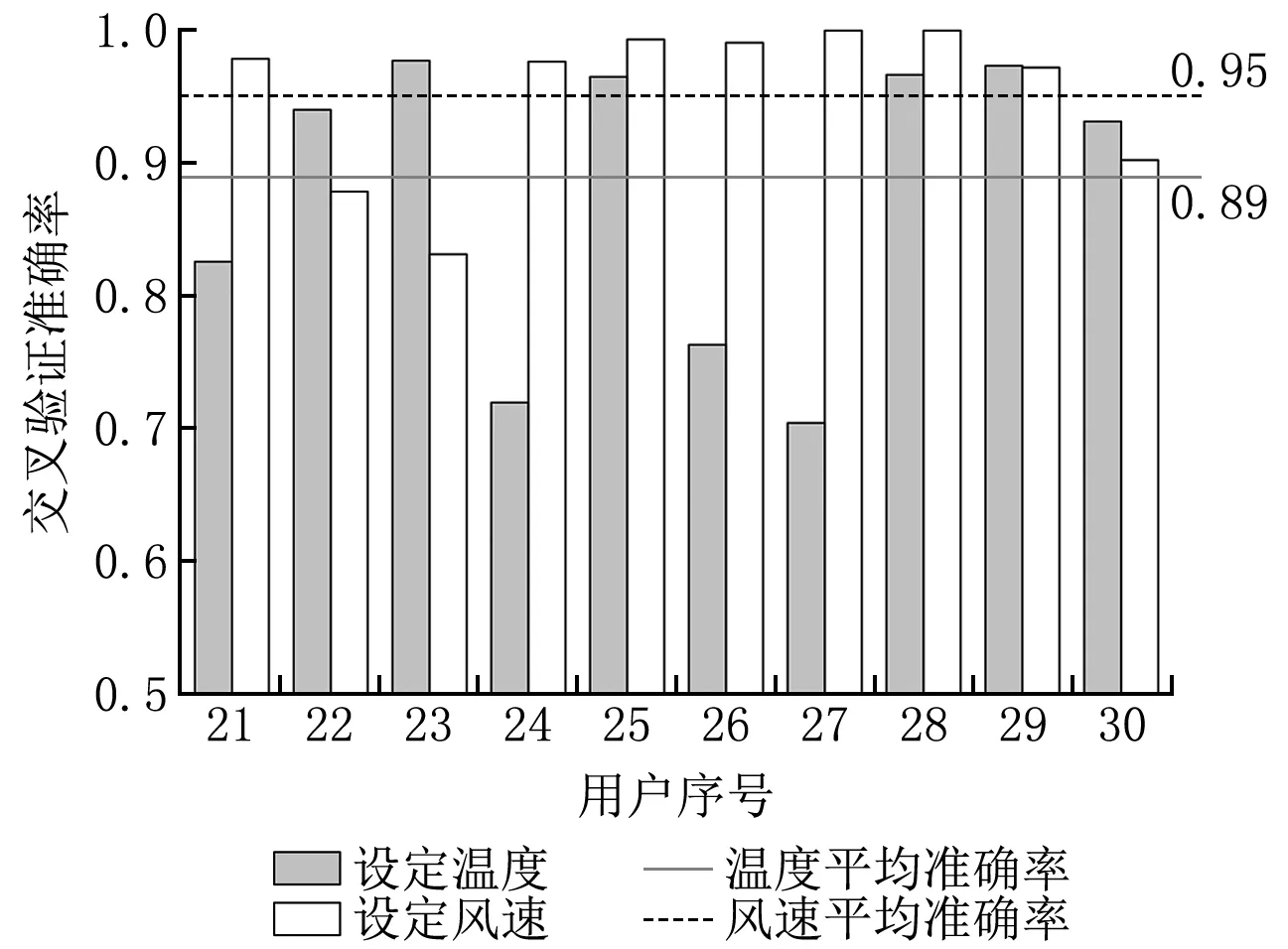
图9 重庆地区用户夏季运行数据交叉验证结果
对于设定温度的交叉验证结果而言,上海、广州、重庆地区的平均验证准确率分别为0.92、0.89、0.89。对于设定风速的交叉验证结果而言,上海、广州、重庆地区的平均验证准确率分别为0.93、0.91、0.95。
由此可见,云端算法模型在多数空调用户的运行数据集上的表现良好,能有效地反映出用户的行为特征与输入环境特征的关系。
4.2 预测方法测试结果
本地单片机上建立的预测方法在应用中需要有较高的准确率,为此需要对预测方法的准确率进行验证。用户操作数据中的一部分用于训练算法模型,剩余的用于验证本地单片机上建立的预测方法的准确率。时间、室内湿度、室内温度和室外温度的组合作为模型的输入参数,用户设定温度和设定风速则是模型的输出参数。预测方法的衡量指标采用预测准确率与地区平均准确率,计算公式沿用式(3)、(4)。
本文将具有代表性的3个城市共30户用户的夏季空调运行大数据分为训练组和测试组,其中,5—7月的空调运行数据作为模型的训练组,8月的空调运行数据作为模型的测试组,用于检验连续1个月内的预测效果。训练组和测试组数据的主要信息如表3所示。
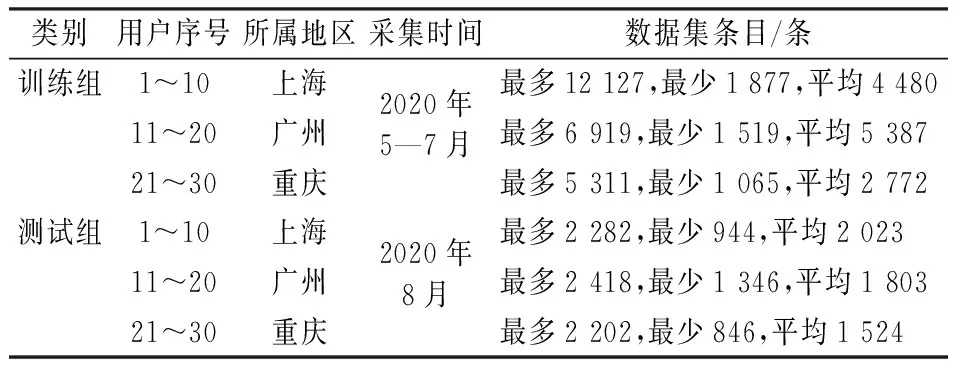
表3 训练组和测试组数据集的主要信息
3个城市共30户用户的数据集预测结果如图10~12所示。
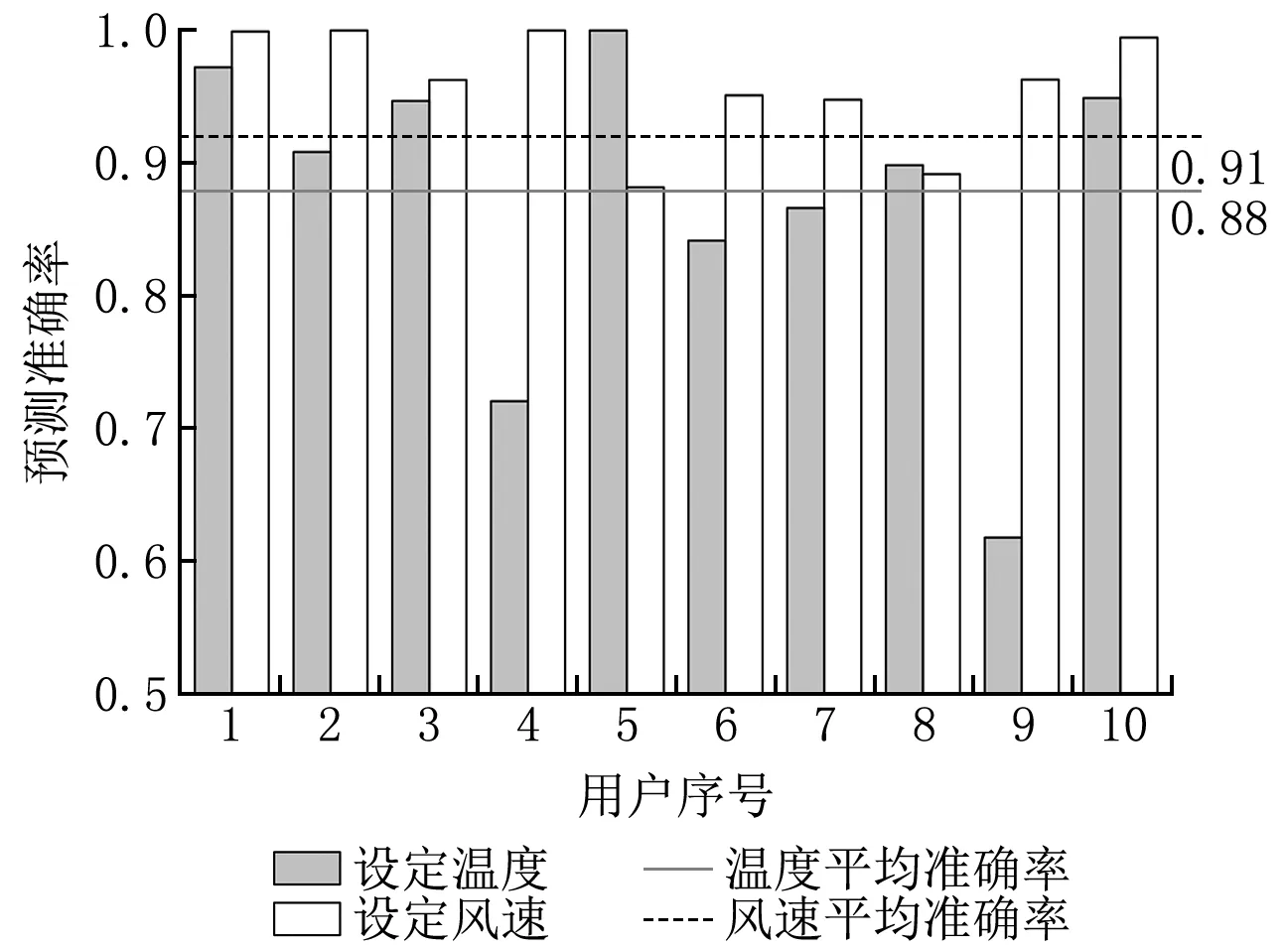
图10 上海地区用户夏季运行数据的本地预测结果
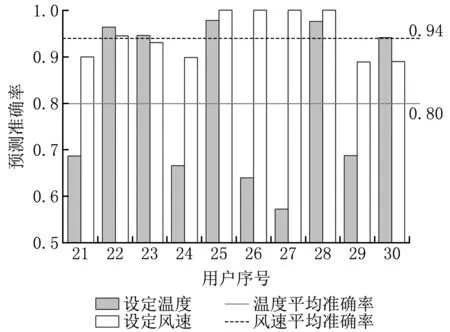
图12 重庆地区用户夏季运行数据的本地预测结果
由空调用户8月运行数据的预测结果可知:对于设定温度的预测结果而言,上海、广州、重庆地区的平均预测准确率分别为0.88、0.84、0.80;对于设定风速的预测结果而言,上海、广州、重庆地区的平均预测准确率分别为0.91、0.90、0.94,这主要是由于多数用户的设定风速偏好均为自动风挡。对于设定温度预测准确率低于0.70的部分数据集来说,用户的设定偏好多呈现不规律且频繁的波动,模型无法根据历史习惯给出准确的预测值。可能原因之一是该空调室内存在人员的频繁变动。
多维矩阵插值方法能较好地复现云端算法模型的结果,继承模型的内在关联。由此可见,云端学习模型与本地预测模型的结合在大多数空调用户运行数据集上的表现良好,可以准确地反映出用户的设定温度和设定风速偏好。
5 结论
1) 通过云端学习与本地计算相结合的方法,可以在空调器单片机有限计算资源下实现用户偏好设定参数的预测。
2) 云端服务器上建立的学习算法能够学习用户操作数据并建模,建立的模型可以反映用户设定温度和设定风速与环境参数的关联。
3) 本地单片机上建立的预测方法可以继承云端算法模型的内在关联,能够在低计算消耗下对用户设定温度和风速进行预测。
4) 云端学习算法的数据交叉验证结果显示:交叉验证数据集的设定温度与预测值的偏差在±0.5 ℃内的比例平均为90%,最高为92%;设定风速与预测值的偏差在±10%内的比例平均为93%,最高为95%。说明云端学习算法的适用性较好。
5) 本地预测方法的验证结果表明:用户实际设定温度与预测值的偏差在±0.5 ℃内的占比平均为84%,最高为88%;用户实际设定风速与预测值的偏差在±10%内的占比平均为92%,最高为94%。说明本地预测方法效果良好,可用于空调用户设定偏好的预测。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
现代装饰(2020年5期)2020-05-30
中国交通信息化(2018年5期)2018-08-21
电子制作(2017年17期)2017-12-18
丝路艺术(2017年5期)2017-04-17
初中生(2017年3期)2017-02-21
小学生优秀作文(趣味阅读)(2017年3期)2017-02-11
河南科技(2014年11期)2014-02-27
