
毫米波大规模MIMO系统联合稀疏混合预编码优化算法
2023-11-09 11:23李正权李树梅
江苏大学学报(自然科学版) 2023年6期
李正权, 李树梅
(1. 江南大学 物联网工程学院, 江苏 无锡 214122; 2. 江苏省未来网络创新研究院, 江苏 南京 211111)
随着无线传输数据量爆炸式增长,毫米波大规模多输入多输出(multiple input multiple output,MIMO)技术受到越来越多关注.毫米波的使用提高了数据传输速率和带宽,但传播损耗变大;大规模天线阵列弥补了这一缺陷,因此,毫米波大规模MIMO技术成为第5代移动通信的关键技术之一.传统MIMO系统中,发送端通过数字预编码预先消除各个数据流之间的部分或全部干扰,使发送信号的空间分布特性与信道条件相匹配,获得更好的频谱效率性能[1-3].但针对大规模MIMO系统,天线阵列规模大幅度增加,若采用传统全数字预编码,需要大量的射频(radio frequency,RF)链路,增加了硬件设计难度和设计成本,不适用于实际场景[4].针对该问题,考虑将模拟预编码应用到大规模MIMO系统中;与数字预编码相比,模拟预编码只需要少量RF链路,降低了硬件成本及功耗.但模拟预编码中移相器只能改变发送信号的相位,因此存在一定的频谱效率性能损失,且其抗干扰能力较弱,故提出了将低维数字预编码和高维模拟预编码相结合的混合预编码技术[5-6],该结构在减少RF链路的同时能够充分利用大规模天线阵列带来的增益.
混合预编码设计中模拟移相器的相位分辨率影响系统频谱效率和误码率性能,由于采用高分辨率移相器的预编码码本量化精度高,系统通常具有更高的频谱效率和误码率性能,而高分辨率意味着码字训练开销大、计算复杂度增加,因此实际的毫米波MIMO系统往往采用低功耗、低分辨率的移相器,以降低系统计算复杂度[7].
此外,混合预编码的设计应充分体现信道特征[8-9],故部分研究者利用信道特征设计预编码算法.针对毫米波信道的稀疏特性,文献[10]采用正交匹配追踪算法(orthogonal matching pursuit,OMP)设计混合预编码矩阵,通过稀疏信号重建有效地提高了系统频谱效率,但OMP算法需要进行高维信道矩阵奇异值分解和求逆运算,导致计算复杂度明显增加.基于此,文献[11]中根据离散傅里叶变换(discrete Fourier transform,DFT)码本的正交特性,优化了OMP算法结构,对迭代运算进行并行处理,并采用旋转离散傅里叶变换DFT码本,根据DFT相同列的弦距离最小、弦距离越小的预编码向量与信道匹配度越高的特性,对水平维、垂直维码本分组,构成3D预编码码本,减少了搜索次数.针对大规模MIMO信道的空间相关性,文献[12]通过近似低秩信道矩阵的方法得到传输主路径方位角、仰角的信道分量,降低了计算复杂度.文献[13]根据大规模MIMO信道的快时变特性,改进模代数预编码(Tomlinson-Harashima precoding,THP)算法,利用信道统计信息及相关性补偿瞬时信道状态信息(channel state information,CSI),提高了误码率性能.
上述文献中混合预编码设计均采用时间簇信道建模,忽略了毫米波通信传输路径的角度稀疏特性,基于此,文献[14]中分析了毫米波传输路径到达角(angle of arrival,AOA)和离开角(angle of departure,AOD)的角度稀疏特性,根据传输路径AOA/AOD的不同,所有传输路径分布在几个波瓣内,且不同波瓣相互独立.在此基础上,文献[15-16]将信道分解为多个正交波瓣子信道,针对每个波瓣子信道设计模拟预编码和数字预编码矩阵,仿真结果表明此方法在降低系统计算复杂度的同时能保证频谱效率性能.
但以上算法只考虑混合预编码设计与信道矩阵的匹配,忽略了模拟预编码矩阵和数字预编码矩阵之间的相关性,未充分利用数字预编码矩阵的隐含稀疏结构,造成了系统部分频谱效率和误码率性能损失.因此在单用户大规模MIMO下行链路混合预编码系统中,为提高系统频谱效率、降低误码率和移相器分辨率,文中拟提出一种联合稀疏混合预编码优化算法.由于不同波瓣内的传输路径相互正交,大规模毫米波MIMO信道矩阵可重构为多个独立的波瓣子信道,对每个波瓣子信道分别进行混合预编码优化设计;针对混合预编码优化设计中含有非凸约束的多元稀疏信号重建问题,利用数字预编码矩阵的隐含稀疏结构,设计波瓣内每个数据流模拟预编码矩阵的自有支撑集和共有支撑集,从而联合优化设计模拟预编码和数字预编码.
1 系统模型及问题表述
1.1 系统模型
文中考虑单用户大规模MIMO系统混合预编码结构,如图1所示.
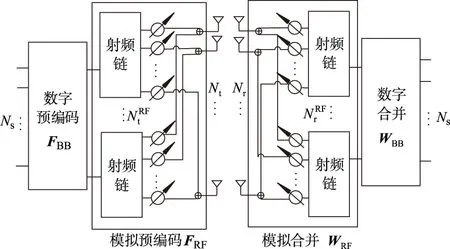
图1 大规模MIMO系统混合预编码结构
(1)
式中:s∈Ns×1为发射信号向量,且满足E[ssH]=INS;FRF为维模拟预编码矩阵;FBB为Ns维数字预编码矩阵;WRF为维的模拟合并矩阵;WBB为维的数字合并矩阵;FRFFBB为混合预编码矩阵;总发送功率满足为合并矩阵;n∈(0,σ2)为信道噪声矢量,其中σ2是噪声功率;H∈Nr×Nt为信道矩阵;ρ为平均接收功率.
1.2 信道模型
文中采用文献[14]中具有角度稀疏特征的波瓣分解信道,图2为28 GHz毫米波波瓣分解信道特征图[14].
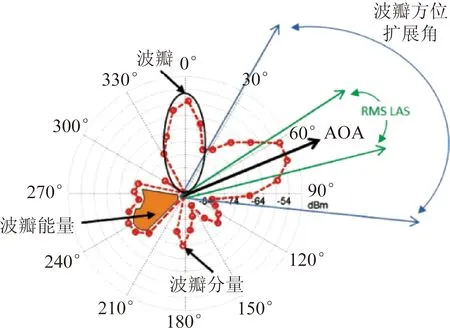
图2 28 GHz毫米波波瓣分解信道特征图
由图2可见,传输路径的AOA或AOD分布在多个波瓣内,每个波瓣内传输路径均在波瓣方位扩展(lobe azimuth spread,LAS)角度范围内,不同波瓣内AOA或AOD彼此分离,故认为不同波瓣内的传输路径相互独立.因此将大规模毫米波信道矩阵划分为多个独立的波瓣,波瓣信道重构为
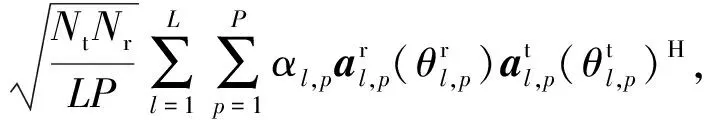
(2)
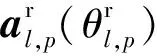
(3)
(4)
式中:λ为载波波长;d为天线间距,且满足d≥0.5λ.
1.3 问题表述
针对上述模型,当发射信号服从高斯分布时,系统频谱效率为
(5)
(6)
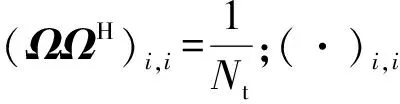
然而,式(6)为含有非凸约束的多元优化问题,求解该类问题的全局最优解比较复杂.为简化收发端预编码矩阵的设计,分别对发送端和接收端进行混合预编码优化设计.假设接收端可实现最优解码,即WRF、WBB为最优设计,故式(6)中只需设计发送端模拟预编码矩阵FRF和数字预编码矩阵FBB.根据文献[17],在信噪比较高的情况下,FRF和FBB的设计问题转化为求解欧式距离最小的问题,因此,式(6)中混合预编码的设计问题可转化为
(7)
式中:Fopt为最优预编码参考矩阵,可通过信道矩阵H的奇异值分解H=UΣVH得到,即Fopt=V(:,1:Ns).
由式(2)可知,不同波瓣内路径相互独立,大规模毫米波信道H可分解为L个低秩波瓣子信道,则针对每个波瓣子信道分别设计模拟预编码矩阵和数字预编码矩阵,式(7)可分解为多个优化子问题:
(8)
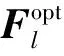
2 算法设计
2.1 模拟预编码码本设计
(9)
式中:第i个码字为
(10)
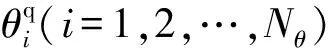
若模拟预编码码本采用均匀量化,每个子码本对应的均匀量化角度[15]为
(11)
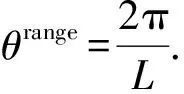
(12)
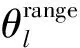
(13)
由式(13)可知,在移相器相位分辨率b相同的情况下,非均匀量化码本的量化误差低于均匀量化码本,因此,非均匀量化精度更高,从而提高了频谱效率.
2.2 联合稀疏混合预编码算法优化设计
为避免复杂的矩阵运算,信道矩阵H可简写为
(14)
(15)
针对L个波瓣子信道,天线阵列响应对应于L个子天线阵列响应,发送端表示为At=[At1,At2,…,AtL],接收端表示为Ar=[Ar1,Ar2,…,ArL],Atl与Arl分别表示发送端、接收端的第l个天线阵列响应,l=1,2,…,L.由式(14)可知,max(rank(H))=LP,为保证通信效率,需满足Ns≤LP.为简化设计,设Ns=LP.
式(8)是含有非凸约束的多元优化问题,当用稀疏信号重建法设计模拟预编码矩阵时,预编码参考矩阵Fres的选择会影响预编码性能.为避免高维信道矩阵的奇异值分解,选择天线阵列响应At作为Fres,受大规模天线阵列及码本训练负载限制;该简化方式会带来一定的性能损失,故还需设计数字预编码以弥补性能损失,同时消除信号干扰.
由式(7)可知,当Nt>>LP时,Fres每个列向量可近似表示为天线阵列响应向量的线性组合,且每个列向量在不同天线阵列响应向量上存在不同强度的投影,故数字预编码矩阵行向量与模拟预编码矩阵列向量之间具有不同强度的相关性,且数字预编码矩阵具有隐含稀疏结构.因此,可以利用模拟和数字预编码矩阵之间的相关性大小来联合优化模拟预编码矩阵列向量和数字预编码矩阵行向量分布,设计相适应的混合预编码算法,达到提高系统频谱效率及误码率性能的目的.
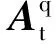
(16)
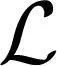
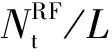
(17)
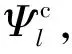
(18)
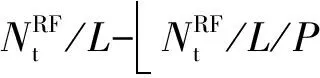
(19)
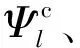
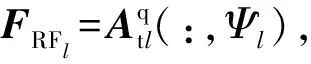
重复上述步骤,设计每个自有支撑集,得到Ψ={Ψ1,Ψ2,…,ΨL}.则模拟预编码矩阵为FRF=[FRF1,FRF2,…,FRFL],相应的数字预编码矩阵为FBB=blkdiag(FBB1,FBB2,…,FBBL),其中blkdiag(X1,X2)表示生成以矩阵块X1、X2为对角线的矩阵.同理可得模拟合并矩阵WRF=[WRF1,WRF2,…,WRFL]、数字合并矩阵WBB=blkdiag(WBB1,WBB2,…,WBBL).为满足功率限制条件,对FBB进行功率量纲一化.算法具体实现过程见算法1.
算法1联合稀疏混合预编码优化算法如下:
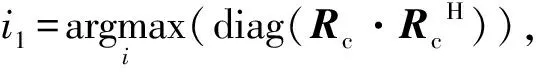
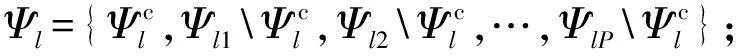
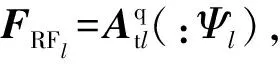
6) 重复执行步骤2)-5)共L次,求解所有波瓣子信道预编码矩阵;FRF=[FRF1,FRF2,…,FRFL]、FBB=blkdiag(FBB1,FBB2,…,FBBL)、WRF=[WRF1,WRF2,…,WRFL]、WBB=blkdiag(WBB1,WBB2,…,WBBL);
8) 算法结束,输出FBB、FRF、WRF、WBB.
2.3 计算复杂度分析
以均匀量化为例,表1从预编码参考矩阵Fres、模拟预编码矩阵FRF与数字预编码矩阵FBB的设计3个方面比较了文中算法与文献[15]中均匀量化正交匹配追踪(UQ-OMP)算法、均匀量化空间波瓣分解(UQ-SLD)算法主要步骤的计算复杂度.
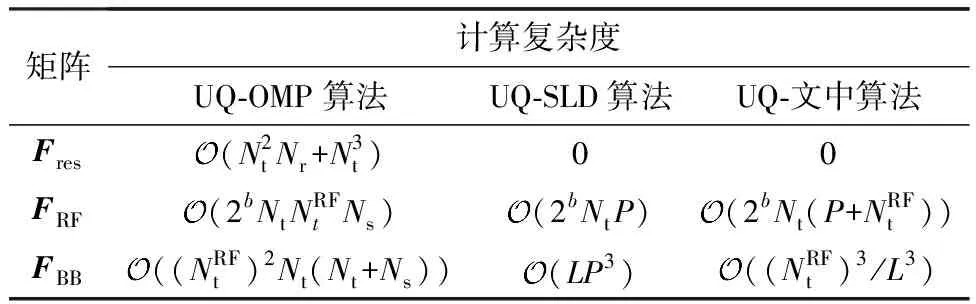
表1 计算复杂度对比
3 仿真分析
为验证文中算法的频谱效率及误码率性能,采用均匀与非均匀量化两种模拟预编码码本,将文中算法与文献[15]中最优预编码(OPT)、UQ-OMP算法、UQ-SLD算法、文献[16]中非均匀量化空间波瓣分解(NUQ-SLD)算法以及非均匀量化正交匹配追踪算法(NUQ-OMP)进行了仿真对比,仿真结果如图3-10所示.图3、4给出了系统频谱效率随信噪比变化曲线.
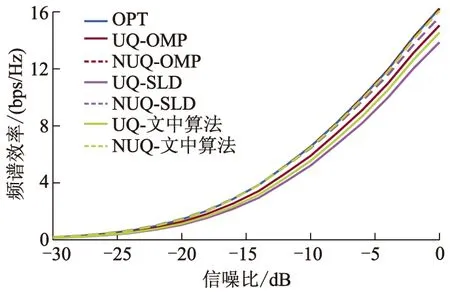
图3 算法频谱效率变化,Nt=32、Nr=16;L=P=2、b=6
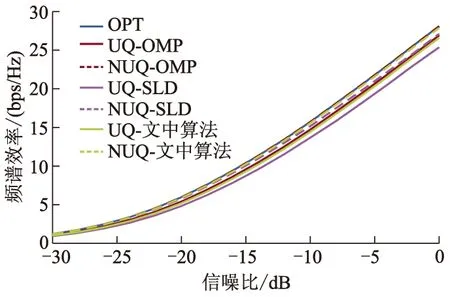
图4 算法频谱效率变化,Nt=128、Nr=32;L=P=2、b=8
从图3、4可见,随着信噪比的不断增加,几种算法的频谱效率均随之提高.与文献[15-16]中算法相比,文中算法的频谱效率明显提升.当Nt=32、Nr=16、采用均匀量化码本时,与UQ-SLD算法相比,文中算法频谱效率提升了0.68 bps/Hz,采用非均匀量化码本时,与NUQ-SLD算法相比,文中算法频谱效率提升了0.44 bps/Hz,两种情况下,文中算法频谱效率分别达到OPT算法的89.6%、99.0%.同样,当Nt=128、Nr=32、b=8时,文中算法频谱效率明显提升.与OMP算法相比,文中算法频谱效率虽存在一定的性能损失,但文中算法计算复杂度大幅降低,且天线数量越大,计算复杂度降低幅度越大(见2.3节).文中算法与SLD算法均选择天线阵列响应作为参考矩阵以避免复杂的矩阵运算,牺牲了部分系统频谱效率性能,因此文中通过联合优化设计模拟预编码与数字预编码,提升了频谱效率性能;而且与SLD算法相比,两种量化方式情况下,文中算法频谱效率差距缩小,表明模拟预编码码本量化方式对系统频谱效率的影响减小,从而降低了对移相器相位分辨率的要求.
图5为采用非均匀量化码本时,不同移相器相位分辨率情况下算法频谱效率变化曲线.
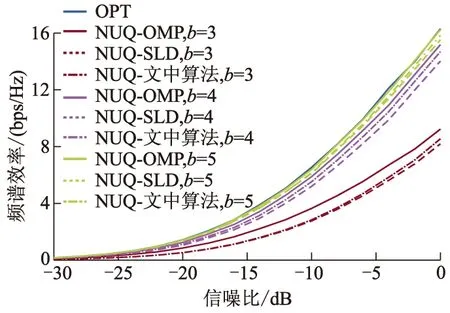
图5 算法频谱效率变化,Nt=32、Nr=16、
由图5可见,随着移相器相位分辨率b的增加,几种算法的频谱效率均随之提高,且频谱效率逐渐逼近OPT算法.图6为均匀量化和非均匀量化情况下算法频谱效率对比图.
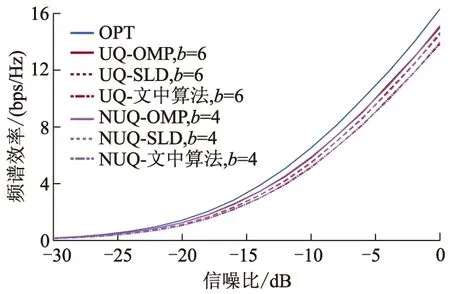
图6 算法频谱效率变化,Nt=32、Nr=16、L=P=2;
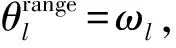
图7、8分别为均匀量化和非均匀量化不同路径数P情况下频谱效率变化对比图.由图7、8可见,无论采用均匀量化还是非均匀量化码本,随着路径数P的增加,各种算法的频谱效率均提高,且非均匀量化b=4时频谱效率与均匀量化b=6相近,当P=2和P=1时,文中算法相较于SLD算法频谱效率分别提升了1.00、0.54 bps/Hz.
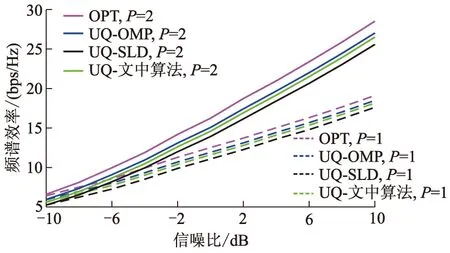
图8 算法频谱效率变化,Nt=32、Nr=16、
图9、10分别为均匀量化和非均匀量化时,各算法误码率随信噪比变化情况.
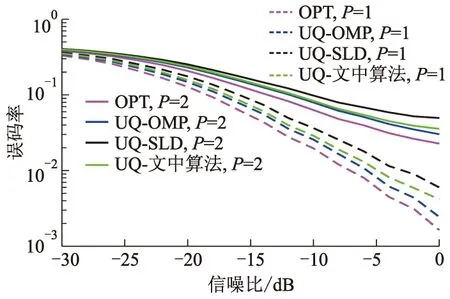
图9 算法误码率变化,Nt=32、Nr=16、L=2;
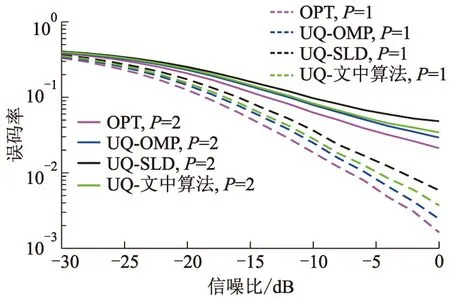
图10 算法误码率变化,Nt=32、Nr=16、L=2;
由图9、10可见,无论采用均匀量化还是非均匀量化,与P=2相比,P=1时各算法误码率更低.因为路径数P越小,波瓣内传输路径之间的干扰越小,系统误码率越低.两种量化方式下,文中算法误码率性能均接近于OPT算法,与SLD算法相比,当误码率为6×10-2时,P=1情况下信噪比增益提升约2 dB,与OMP算法相比误码率差距缩小了50%;当误码率为5×10-1时,P=2情况下信噪比增益提升约3.7 dB,与OMP算法相比,信噪比损失仅为0.3 dB.
4 结 论
1) 文中提出了一种联合稀疏混合预编码优化算法.在有限相位分辨率移相器情况下,文中算法频谱效率及误码率性能与OPT算法近似,但计算复杂度大幅降低,且天线规模越大,计算复杂度降幅越大;
2) 与SLD算法相比,文中算法的频谱效率及误码率性能明显提升;
3) 模拟预编码码本量化方式对于系统性能影响减小,表明文中算法对移相器相位分辨率要求不高,更适用于多种应用场景.
猜你喜欢
中国民航大学学报(2022年5期)2022-12-19
物理学报(2022年19期)2022-10-16
南京邮电大学学报(自然科学版)(2022年4期)2022-09-20
雷达与对抗(2022年1期)2022-03-31
中国民航大学学报(2021年3期)2021-08-04
燃气涡轮试验与研究(2020年5期)2020-12-31
工业加热(2019年1期)2019-03-11
纯粹数学与应用数学(2018年3期)2018-10-10
沈阳航空航天大学学报(2014年5期)2014-08-29
单片机与嵌入式系统应用(2014年7期)2014-03-24
