
全局视野多层次特征增强的人脸伪造检测方法①
2023-11-05 11:51左邦
佳木斯大学学报(自然科学版) 2023年5期
左 邦
(安徽理工大学计算机科学与工程学院,安徽 淮南 232001)
0 引 言
随着深度伪造技术的快速发展,各种算法被提出用于生成逼真的人脸图像以及视频,这些多媒体内容能够让人眼或人脸识别系统无法分辨,因此极有可能被滥用于非道德和恶意的用途,比如进行政治宣传、生成虚假新闻以及电信欺诈等等。给民众和社会带来巨大的恶劣影响。基于该背景,人脸伪造检测已成为多媒体信息安全领域的研究者的研究热点。
出于安全方面的考虑,最近几年有一系列的深度伪造检测算法被提出。这些方法通常基于卷积神经网络(Convolutional Neural Networks, CNN)并在数据集内取得了有效的检测精度。但是当这些已训练的方法在其他数据集上的测试精度会大幅下降。这是因为这些基于CNN的方法通过学习局部纹理信息来分辨伪造媒体内容,然而不同数据集样本之间的局部纹理伪造信息具有差异性,不足以作为深度伪造泛化性检测的依据[1]。
尽管深度伪造媒体复杂多样,但是它们都面临一个问题:局部纹理部分正常但全局视野下则扭曲异常。比如,伪造图像中会出现不能匹配的面部表情,非正常的头部姿态,异常的颜色或光照等全局视野下的伪造痕迹。因此,需要根据全局语义确定局部伪造区域,并在空域中建立长距离依赖关系以此向网络提供全局伪造信息。
近期研究表明,基于vision transformer (ViT)[2]网络结构的模型在很多视觉任务中取得了优异的指标。ViT利用一种其固有的多头注意力机制作用于一系列图像分块,有效拓宽了网络的感受野,从而有利于全局信息的捕获。因此,可以应用transformer来解决图像中长距离依赖关系建模困难的问题。因此基于多头注意力机制并应用transformer模块,设计一种多层次transformer网络,通过构建长距离依赖关系提升网络全局信息获取能力,从而有利于获取更多具备泛化性的全局伪造模式用于深度伪造泛化性检测。
此外,为了减半输入特征的空间尺寸并加倍特征的维数,结合MBConv[3]设计了一种下采样模块(Downsample Module, DM),其中MBConv融合了通道注意力机制[4],通过特征图通道层面筛选出模型感兴趣的伪造区域,达到伪造特征精炼的效果。
由于伪造数据集中存在较小尺寸的伪造人脸,在经过多个层次网络会有大量有效的伪造信息丢失的问题,因此采用多层次特征增强策略(Multi-Layer Feature Enhance Strategy, MLFE),通过基于ImageNet[5]上预先训练的ConvNeXt[6]增强检测网络的空间感知局部能力,从而改善网络不同层次的表征能力。
因此,针对以上的分析提出了一种基于全局视野多层次特征增强的人脸伪造检测模型。该模型使用基于transformer的网络作为骨干模型,通过对输入一系列的图像块构建长距离依赖关系解决网络提取全局伪造特征,从而提升算法的泛化性检测能力;其次,结合所设计的DM模块对特征图进行下采样,进一步精炼所提取的篡改痕迹并形成多层次网络结构。最后,采用MLFE策略提升网络的空间感知局部能力以应对数据集中小尺寸篡改人脸的检测精度。结合以上的三种设计思路来最大限度地提升模型对于未知类型深度伪造媒体内容的泛化性检测水平。
1 相关技术介绍
绝大多数的人脸伪造检测方法从空域中提取细微的篡改痕迹。早期的检测方法通过媒体内在的统计规律或者人工构造特征对空域篡改特征的建模[7-8]。随着深度学习的兴起,有研究工作[9]训练CNN架构的模型从伪造输入中寻找可区分性的篡改特征。近几年,一些工作开始关注检测器的泛化能力,如跨越数据集评估其测试性能。Face X-ray[10]使用CNN模型来检测伪造人脸的混合边界来提升伪造人脸检测器泛化性能。Patch-DFD[11]则将人脸部位划分固定的几个区域分别使用CNN模型进行检测。这些方法通过基于CNN的模型取得了优越的检测性能,然而CNN模型的局限性使得检测器泛化性能的进一步提升受到限制。
基于CNN结构的模型利用局部感受野,参数共享以及空域下采样机制对于局部特征的学习比较擅长,但是它由于感受野尺寸限制而无法获取图像的全局信息。相反,基于自注意力机制的transformer架构对全局关系以及长距离特征依赖的良好建模,使得网络提取全局伪造痕迹特征成为可能。对于人脸检测领域,早期基于CNN架构的检测模型由于感受野尺寸限制而无法获取全局篡改模式。最近一段时间,FTCN[12]使用transformer架构来探究时空域不连续的伪造信息。M2TR[13]和LiSiam[14]进一步将transformer架构和CNN架构相结合,从而将特征块中建立全局关系以及获取局部伪造痕迹两个方面优势互补,促使模型捕获更多的细微伪造特征用于泛化性检测。
2 模型设计细节
全局视野多层次特征增强的人脸伪造检测方法分别由基于transformer架构的骨干模型(Base),不同层级进行下采样特征精炼的Downsample模块(DM)以及结合ConvNeXt网络构建的多层次特征增强策略(MLFE)构成。如图1所示。
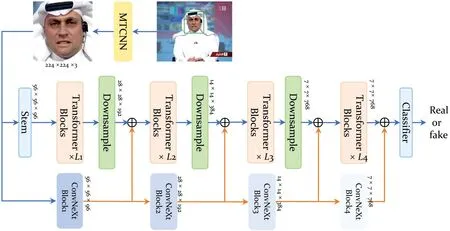
图1 模型总体设计
2.1 骨干网络设计
由于局部纹理伪造特征因为不同数据集而呈现不同差异,而全局伪造模式,如不协调的嘴形,真实与伪造区域之间的光照,色彩与纹理等全局伪造痕迹相对于局部特征更具有泛化性。因此,使用基于transformer模块的Base网络能够发挥基于CNN网络不具备的对图像分块构建长距离依赖关系能力,从而捕获伪造图像中的全局伪造特征。首先将输入图像通过MTCNN[15]网络裁剪人脸,排除掉其他冗余的干扰区域。此时得到人脸图像I∈H×W×C,作为Base输入。Base网络由多个结构相同的transformer块构建,其中transformer块包含多头注意力机制(MSA),多层感知机(MLP)和Layer归一化(LN),MSA机制如图2所示。输入图像经过分块操作后得到x∈N×D,N表示图像被切分的块数,D表示每个块进行拉平并通过线性层MLP投射得到的向量维数。因此,MSA结合M注意力头部数的公式描述:
Q=xWq,K=xWk,V=xWv
(1)
(2)
z=cat(z1,…,zM)Wo
(3)
其中σ(·)表示softmax函数,d表示D/M,是每个头部的维数。Qm,Km,Vm∈N×D分别表示嵌入向量Query,Key以及Value。Wa,Wk,Wv,Wo∈D×D分别是MLP的参数。MSA的输出被LN层进行归一化得到嵌入向量,并输入到MLP中进行域映射,MLP层包含有两个线性层以及一个GELU非线性激活层。MLP产生的输出作为下一个transformer块的输入。
借助transformer结构中的多头注意力机制对伪造图像块建模长距离依赖关系,从而使得Base网络能够捕获具有泛化性的全局特征。
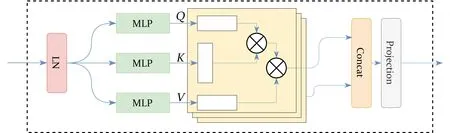
图2 MSA机制
2.2 DM模块
Base网络不同层之间需要对输入特征进行下采样操作,从而去除冗余信息得到伪造语义特征。从CNN模型中的借鉴空间域收缩理论,通过减少维度的同时强制施加局部偏置以及跨通道交互,因此设计了一种下采样模块(DM),如图3所示。它包含有一个MBConv模块,一个3×3,步长为2的卷积算子以及一个Layer归一化层。其中MBConv模块和文献[3]类似:
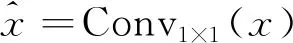
(4)
其中SE,GELU,DWConv3×3分别指通道注意力机制,高斯误差线性单元以及深度可分离卷积。MBConv在这个下采样模块设计中提供了归纳偏置以及多通道依赖的特性,从而将CNN模型的优势结合起来为伪造特征提取提供有利条件。
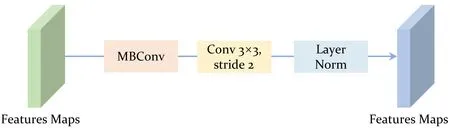
图3 MLFE策略
2.3 MLFE策略
针对数据集中存在小尺寸的伪造人脸,在Base网络提取关键伪造特征时丢失了一些纹理信息后,人脸图像存留的关键信息较少使得Base网络容易产生误判的问题。借鉴CNN模型对于获取局部纹理信息能力强于基于transformer架构的Base网络,借助ResNet的改进版本ConvNeXt网络[6]设计了多层次特征增强策略MLFE。Base网络与ConvNeXt网络被划分为4个阶段,将图像I∈H×W×C分别输入两个网络中,ConvNeXt网络每个阶段提取的伪造特征分别和Base网络对应阶段特征进行相加操作,从而改善了提取的小尺寸人脸在正向传播过程中的信息减益问题,使得Base网络提取的特征得到了增幅。其中ConvNeXt网络如图3所示。
3 模型设计细节
3.1 实验设置
1)相关数据集介绍:实验用到的数据集分别是常见并且公开的FaceForensics++(FF++)和CelebDF数据集。FF++数据集中包含有1000个原始视频以及由四种不同伪造手法:Deepfakes(DF),FaceSwap(FS),Face2Face(F2F)和NeuralTexture(NT)得到的共4000个伪造视频。并对这些视频进行了3中级别的压缩:Raw(无压缩),c23(高质量)以及c40(低质量)。其中c23版本作为实验对象。所有视频按照官方预定的划分比例750:150:150,分别为训练集,验证集以及测试集。而CelebDF数据集包含有590个真实视频以及5639个伪造视频。我们按照官方预设的测试集列表作为实验中跨越数据集验证对象。
2)模型实现细节:实验中使用PyTorch框架。MLFE策略所使用的ConvNeXt网络在ImageNet-1K上预先训练。使用了Adam优化器,其中学习率为2e-5且权重衰减系数为1e-5。输入人脸是由MTCNN网络对视频进行截取帧裁剪得到的,尺寸为224×224×3,批量大小为8,迭代25个轮次。
3)实验使用测试指标:准确率ACC以及ROC曲线下面积AUC。
3.2 同类方法在FF++数据集上的比较
将所提出的方法和当前的深度伪造检测方法在FF++数据集上进行比较,实验结果如表1所示,与同类方法相比,所提出方法能够达到先进水平的检测精度。本方法在AUC指标上远远超过ADT,达到了98.34%,虽然ACC相差不多,但说明了所提出方法相比于ADT有较高的准确性和稳定性。此外,所提出方法均高于其他三种方法,尤其是基准模型Xception。但由于模型缺乏对伪造图像提供掩码并进行解码进而增强模型对于伪造区域定位的精确性,因此数据集内的准确率相对于M2TR稍有落后。总体而言,在检测伪造人脸方面达到了先进水平。
3.3 同类方法在CelebDF数据集上的泛化性比较
因为目前的大多数检测方法能够在单个数据集内取得优异的检测精度,但是往往无法对未知类型的伪造内容提供有效的检测结果,因此关于人脸伪造检测方法跨越数据集检测泛化能力得到了研究者的关注。将FF++数据集上训练的检测方法和所提出方法进行了跨越数据集检测能力的对比实验,如表2所示。相比于表中所列举的模型测试结果,所提出方法在跨越数据集检测的AUC得分均高于其他方法,达到了74.12%,体现了检测能力的优越性。

表1 与同类方法在FF++(c23)上的比较结果

表2 与同类方法在CelebDF上的泛化性AUC得分结果比较
3.4 消融实验
为了探究所提出模型中骨干网络,DM模块以及MLFE策略对于检测性能的贡献,对所提出模型进行修改,分别得到两个子模型和所提出方法本身,并将分别在FF++数据集上训练,CelebDF上进行测试得到AUC结果,如表3所示。可以看到,借助骨干网络,通过对伪造图像的长距离关系建模,从而捕获具有泛化性的全局特征。实验中AUC得分取得了69.71%,说明了这一点。借助DM模块,将每一个层次网络提取特征进行精炼,迫使网络提升感知伪造区域能力进而将AUC得分提升到72.43%。为了解决样本中存在小尺寸伪造人脸检测难度大的问题,提出了MLFE策略,通过提升骨干网络每个层次的空间局部感知能力,进而提升网络对于小尺寸伪造人脸检测能力,实验中CelebDF数据集检测得分74.12%证明了这一点。
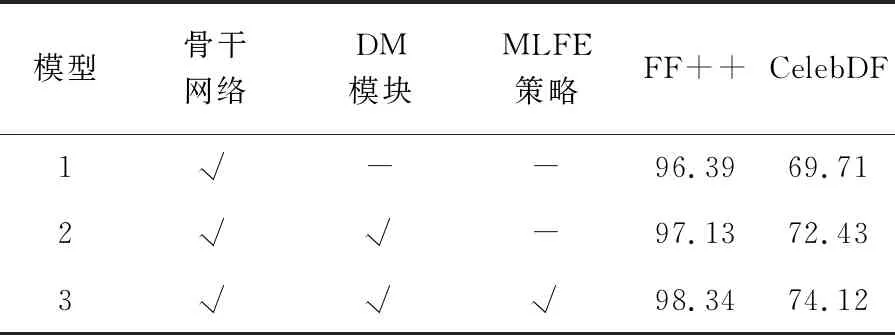
表3 所提出方法消融研究的AUC得分比较结果
4 结 语
提出的这种基于全局视野的多层次检测网络。通过基于transformer架构的骨干网络对伪造图像块之间的长距离依赖关系进行建模,从而提取全局性伪造特征,有利于提升检测模型对于未知类型伪造内容检测能力。并借助DM模块,对骨干网络不同层次提取的特征进行精炼,去除冗余干扰信息进而提升网络的伪造区域定位能力。最后为了解决数据集中存有的小尺寸伪造人脸检测不精确的问题,提出了MLFE策略,通过对网络各个层次进行空间局部区域感知能力增强进而提升模型的伪造检测性能。在数据集内以及跨越数据集检测实验中验证了所提出方法的有效性。此外,对模型的消融实验验证了各个模块对于模型检测精度的贡献。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
少儿美术·书法版(2021年9期)2021-10-20
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
动漫星空(2018年9期)2018-10-26
金桥(2018年4期)2018-09-26
数学小灵通·3-4年级(2017年9期)2017-10-13
发明与创新(2015年33期)2015-02-27
中国卫生(2014年5期)2014-11-10
