
机器学习在钢铁材料研究中的应用综述
2023-10-28 04:26:06王海伟种晓宇
中国材料进展 2023年10期
王海伟,叶 波,冯 晶,种晓宇
(1. 昆明理工大学信息工程与自动化学院,云南 昆明 650500) (2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500) (3. 昆明理工大学材料科学与工程学院,云南 昆明 650093) (4. 昆明理工大学 材料基因工程重点实验室,云南 昆明 650093)
1 前 言
钢铁是人类文明中最重要的材料之一,20世纪末钢铁成为现代世界位于核心地位的金属材料[1]。随着时代的不断发展,钢铁材料应用于各种领域,例如铁路、石油、建筑、汽车、船舶、航空航天等,不同的应用领域对钢铁性能的需求不同[2],钢的性能主要取决于其化学成分和工艺参数。钢的主要化学成分是铁(Fe)、碳(C)和10余种合金元素[3]。此外,钢材的生产工艺极其复杂,例如,钢材的生产涉及到高温冶炼过程,包括炉料的加热、熔化、脱氧等多个阶段。而每个阶段都需要控制温度、压力、保护气氛等参数,从而确保所制造的钢材符合特定的质量标准[4]。生产钢材最常用的加热工艺是退火、回火、淬火和正火[5]。为了获得符合服役性能需求的钢材,需要研究化学成分、热处理工艺参数和其他工艺参数对钢材性能的影响。因此,具有不同元素组合和工艺参数的候选组合种类多达百万,目前通过传统实验试错法几乎不可能研究所有组合。
近年来,机器学习技术已广泛应用于各种材料的研究与设计中,成为材料研究的新兴方法和热门领域[6,7]。牛程程等[8]综述了机器学习技术在材料信息学方面的应用,总结了机器学习方法在多种材料性能预测中的研究现状,介绍了最常用的材料数据库资源和多种应用于材料领域的机器学习算法,并对国内外机器学习在材料中应用的研究进展进行了对比和总结。Arroyave等[9]综述了数据科学、机器学习和人工智能在金属和合金中的应用研究,总结了应用于解决材料科学和工程中的正向与反向问题的研究框架。Liu等[10]综述了材料基因组计划中的机器学习技术,介绍了材料科学中使用的机器学习算法以及机器学习在材料结构确定、性能预测、描述符构建和新材料的发现中的应用,指出了机器学习在材料设计领域未来的研究方向。
机器学习已成为材料科学领域中揭示和开发材料成分-组织/结构-性能-服役行为关系的有力工具。Reddy等[11]利用人工神经网络和遗传算法构建预测模型,通过成分和热处理参数预测钢的性能,并设计出具有所需力学性能的中碳钢。Xie等[12]基于11 101个数据样本,以合金成分、加热炉工艺参数、轧制数据和冷却数据为输入,预测了热轧钢板的4种力学性能,并依据预测模型探究C元素在钢种中的作用,预测模型的解释结果与实验测量的结果吻合较好。
本文主要综述机器学习技术在钢铁材料设计与开发中的应用。首先介绍在材料领域中常用的机器学习算法和模型,然后介绍钢铁材料在构建机器学习模型中特征选择的重要性,综述机器学习技术在钢铁材料成分-工艺-性能预测、服役行为预测以及逆向设计中的研究进展。最后,分析机器学习在钢铁材料领域面临的问题并展望其发展前景。
2 机器学习算法与模型
机器学习是一门多学科交叉专业,涵盖计算机科学、概率论、统计学、近似理论和复杂算法等知识,本质是基于大量的数据和一定的算法规则,使计算机可以自主模拟人类的学习过程,并能够通过不断的数据“学习”提高性能并做出智能决策的行为[13]。机器学习模拟人类学习主要过程可以分为数据收集、特征选择、算法/模型选择、模型训练和评估、模型预测和应用。机器学习的学习流程如图1所示。
数据是机器学习过程的核心,机器学习算法通过收集的数据进行训练,揭示数据中存在的隐藏规律。通常会对收集的数据进行预处理,例如归一化处理。用于机器学习的数据可以为数值或者图像,将初始数据进行转换为更适合所选择的机器学习算法的输入数据的过程称为特征选择。所选特征越合适,输出结果的精度就越高。
机器学习需要选择合适的算法,模型中的结构与参数的选择也会影响模型的精确度,为了使所选模型达到最优,通常有两种方式对模型进行优化,第一种是采用优化算法,例如粒子群算法、遗传算法等[14];第二种是增加训练集的数据容量,使模型参数不断迭代更新直至达到最优值。模型训练结果通过选取的评价指标进行评价,回归问题中常用的评价指标有均方根误差、决定系数等。
模型预测是利用训练及优化好的模型对新的数据进行预测,预测精度取决于模型的精度。通过评价指标对模型的精度评估后,进一步通过改变模型输入实现新型材料的预测并完成模型输出规律的探究。
根据学习风格不同,机器学习算法可以分为监督学习、无监督学习和强化学习[15]。监督学习是指通过带有属性标签的样本进行训练,每组样本都由输入和输出数据构成。无监督学习是指样本的类别是未知的,不带有属性标签,可以将未分类的样本进行分类。表1列举了材料信息学中常用的机器学习算法模型以及它们的特点和应用。强化学习是一种通过智能系统与环境互动学习如何做出一系列决策以最大化累积奖励的机器学习方法,其核心思想是在试错过程中通过学习来找到最优策略,而不需要显式的监督标签。

表1 常用的机器学习模型Table 1 Common machine learning models
3 机器学习在钢铁材料设计中的应用
3.1 特征构建与选择
钢铁材料的机器学习预测模型是对合金成分及其加工处理工艺数据训练,然后对材料的性能做出预测。机器学习预测模型需要揭示被表征的钢铁数据及其性能之间的隐式关系,材料被表征后的数据被称为材料特征或材料描述符,钢铁材料特征的构建需要尽可能多地保留钢铁的特性。针对钢铁进行性能预测时,材料特征通常选取钢铁的合金成分或者其热处理工艺。Reddy等[28]利用人工神经网络预测低合金钢的力学性能,预测模型输入特征包括合金成分和2种热处理参数,并根据预测模型探究了各种合金成分及2种处理工艺对该低合金钢性能的影响。
机器学习模型的材料描述符需要根据模型输出进行合理设计与选择,合理的材料描述符往往需要在考虑材料描述符与目标输出之间关联性的基础上,根据相关专业知识来进行设计。在钢铁材料的成分及性能预测中,如果反将钢铁材料的合金成分以及处理工艺作为输入来建立机器学习模型,会存在特征冗余的问题。因此,应进行特征选择,将高维数据进行降维,保留重要的材料信息。利用特征筛选后的强相关特征进行模型建立,可以提高模型的预测精度以及计算速度。Xiong等[29]在进行钢铁材料性能预测时,利用随机森林和符号回归分别对影响疲劳强度、抗拉强度、断裂韧性和硬度的特征进行特征选择,成功地在16个特征中筛选出与4个性能强相关的特征,特征选择结果如图2所示,随机森林筛选的特征为Mo和Cr的含量以及均匀化温度和回火温度,符号回归选择的特征为C,Mo和Cr含量以及回火温度,最后将上述2种算法选择出的特征分别构建预测模型,得出利用符号回归模型选择特征构建的预测模型具有更高的预测精度(决定系数R>0.9550,均方根误差RRMSE<3.25%),预测结果如图3所示。
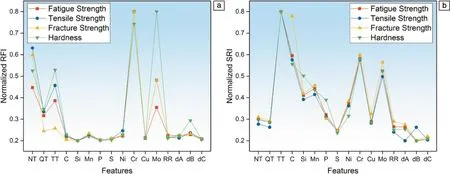
图2 疲劳强度、抗拉强度、断裂强度和硬度的16个特征的归一化[29]:(a)随机森林特征重要性,(b)符号回归特征重要性Fig.2 Normalized random forest importance (a)and symbolic regression importance (b)of the 16 features for fatigue strength,tensile strength,fracture strength and hardness[29]
3.2 成分-工艺-性能预测
目前机器学习算法在钢铁材料领域最广泛的应用是建立钢铁成分-工艺-性能之间的隐式关系,以辅助钢铁材料的设计与开发。钢铁材料元素成分的多样性和加工工艺的复杂性都会对钢铁的抗拉强度、屈服强度和延伸率等力学性能产生重大影响。因此将钢铁材料的元素成分和工艺参数作为预测模型的输入,以力学性能作为输出建立预测模型,可以辅助钢铁材料的设计和工艺参数优化,从而加快新型钢铁的设计与研发。
魏清华等[30]使用日本国立材料研究所数据库中的360条钢材数据,以元素成分、制备工艺和夹杂物参数为输入,利用正则化线性回归、随机森林和正则化人工神经网络3种算法构建预测模型,成功预测了钢材的4种力学性能。谢少捷等[31]基于冶金机理选取影响热镀锌钢卷生产的基本特征,利用梯度提升树算法对其他化学元素特征进行筛选,并构建钢卷屈服强度的预测模型,最后利用预测模型分析了各种特征对钢卷屈服强度的影响。Guo等[32]利用人工神经网络模型模拟合金成分、加工参数和马氏体时效钢性能之间的相关性,输入参数为13种元素的含量、时效前冷变形程度、时效温度和老化时间,输出参数为8个力学特性和马氏体起始温度,模型预测结果与实验数据非常吻合。Capdevila等[33]等利用贝叶斯神经网络探究了钢的元素成分和马氏体起始温度之间的关系,并根据预测模型进一步研究了合金中C浓度对马氏体起始温度的影响,发现随着合金中C浓度的增加,马氏体起始温度的下降速率降低。Guo等[34]基于6万多个钢铁的工业数据样本,以工艺参数和化学成分共27个特征为输入,构建普通最小二乘法、支持向量机、回归树和随机森林4种预测模型,对钢铁的屈服强度、抗拉强度和延伸率进行性能预测,借助预测模型,计算了不同合金含量下3种性能的可能边界,并设计出了满足性能要求的新钢种。Qiao等[35]提出了一种改进的成分-结构-性能的预测模型,将物理特征加入到机器学习的模型中,并利用果蝇优化算法和粒子群优化算法分别对广义回归神经网络的参数进行寻优,根据预测模型证明了物理特征对珠光体钢的层间距和力学性能有较大的影响,并用制备的样品证明所提出的果蝇优化算法-广义回归神经网络模型预测结果与实验结果非常吻合,该模型可以用于开发具有目标特性的新型钢铁,所提出的方法流程如图4所示。
3.3 服役行为预测
钢铁材料服役条件各不相同,服役性能主要包括腐蚀速率、蠕变寿命和疲劳强度等,钢铁结构和部件的疲劳断裂是钢材在实际服役过程中主要的失效形式之一,因此对钢铁材料的服役行为进行预测越来越受到学者们的关注。利用机器学习算法,构建服役环境因素与服役性能之间的预测模型,可以对钢铁的服役行为进行预测。
Aghaaminiha等[36]基于26 855个低碳钢在CO2水溶液中的腐蚀数据样本,以缓蚀剂浓度、时间和温度等12个环境和操作因素为输入,采用随机森林构建机器学习模型,预测缓蚀剂对低碳钢的腐蚀速率的影响,经过训练的随机森林模型可以很好地预测低碳钢腐蚀速率随时间的变化趋势。Verma等[37]采用各种机器学习方法,包括线性回归、套索回归和t分布随机邻域嵌入,建立9%~12%Cr(质量分数)钢的加工/微观结构和蠕变特性之间的统计关系,为650 ℃、100 MPa和蠕变寿命≥105h的新型马氏体钢的设计提供了参考。Wang等[38]建立了具有高蠕变寿命的低合金钢设计框架,如图5所示,首先比较各种机器学习策略,得到预测蠕变寿命的最佳机器学习模型,然后利用带有过滤器的遗传算法在特定蠕变条件下获得具有最佳成分和加工参数的新合金。He等[39]利用人工神经网络、支持向量回归和随机森林方法预测含有缺陷/夹杂物的焊接马氏体不锈钢(13Cr-5Ni)和KSFA90钢(为曲轴制造)的疲劳寿命,在3种机器学习的预测结果中,随机森林的预测结果精度最高,因此在预测材料的疲劳寿命时,使用多种算法要优于单一算法。
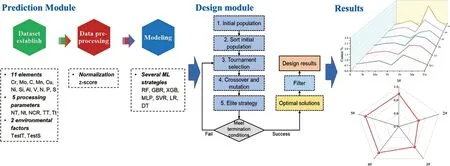
图5 蠕变寿命预测模型和高通量设计模型的基本流程[37]Fig.5 Basic flow of the creep life prediction module and high-throughput design module[37]
3.4 逆向设计
钢铁材料的正向设计[40]是指以钢铁成分或工艺为输入、性能为输出,通过改变输入来达到优化钢铁材料性能的目的。但由于钢铁材料成分的多样性以及工艺的复杂性,通过正向设计需要对大量数据进行筛选,并且难以保证所获取的材料性能为最优性能。因此,需要在已知材料性能的前提下,设计材料的成分和工艺,即逆向设计[41]。钢铁材料的逆向设计能够快速准确地设计开发满足性能需求的新钢铁材料。
Lee等[42]开发了一个包含16种算法的集成机器学习平台,如图6所示,基于收集到的5473组热机械控制工艺钢合金数据建立屈服强度与极限抗拉强度比值(YS/UTS)的预测模型,利用经过充分训练的7种非线性机器学习算法构建基于精英策略的非支配排序遗传算法的逆向预测模型,使用全息搜索策略技术在16维决策变量空间中将预测结果进行图形可视化,从而可以系统地了解数据状态,并且在输入特征空间引入可视化解决方案,从而实现了真正意义上的机器学习预测。在合金逆向设计中,Wang等[43]提出了以性能为导向的铜合金机器学习设计系统,如图7所示,用反向传播神经网络构建了成分预测性能(C2P)和性能预测成分(P2C)这2种模型,初始合金成分预测由P2C模型得出,将得到的结果输入到预测精度更高的C2P模型中,将预测属性与目标进行比较并得到误差,如果预测值和目标值之间的所有误差都超过预设阈值,则将重新训练P2C模型,直到筛选出合理的合金成分设计方案,实验证明,机器学习设计系统在解决目标特性的成分设计问题上具有更高的效率和可靠性。
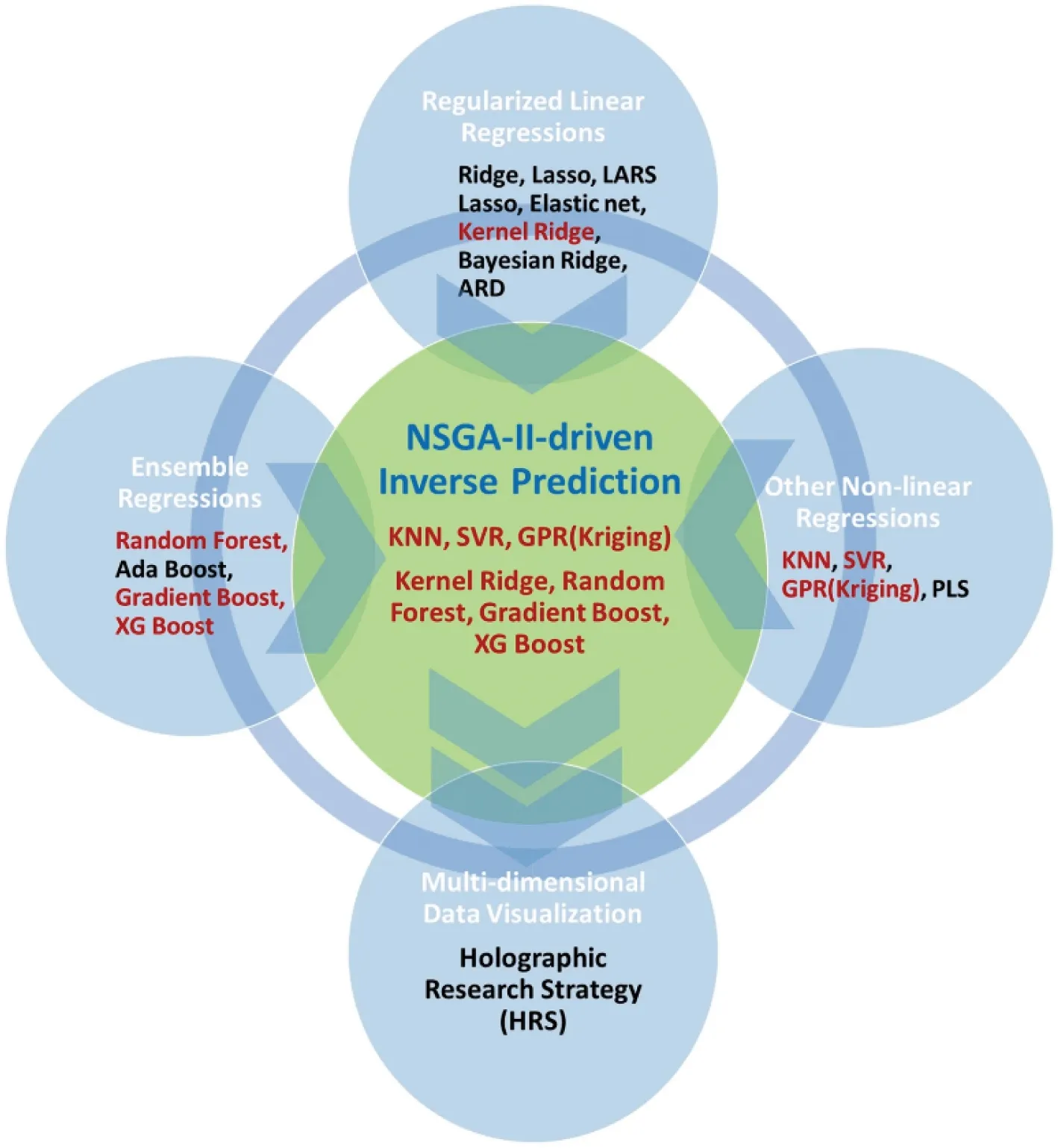
图6 集成机器学习平台的总体框图,包括3组机器学习算法、NSGA-II驱动的逆预测和高维数据可视化方法[42]Fig.6 The overall graphical description for the integrated machine learning platform,three groups of machine learning algorithms,the NSGA-II-driven inverse prediction,and the high-dimensional data visualization method are given[42]
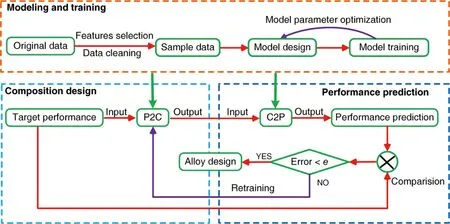
图7 用于快速准确成分设计的机器学习设计系统流程图[43]Fig.7 Flow chart of the machine learning design system for rapid and accurate compositional design[43]
4 结 语
近年来,机器学习已广泛应用于材料研究中,本文针对机器学习在钢铁材料研究中的应用进行了综述,由于钢铁材料成分的多样性以及工艺参数的复杂性,采用传统实验进行钢铁设计与开发的成本过于昂贵且效率较低,相比传统实验,机器学习在揭示和开发钢铁材料成分-组织/结构-性能-服役行为关系方面具有巨大的潜力。
目前,钢铁材料领域可以用于机器学习的数据规模还比较小,基于小规模数据集构建的预测模型预测的结果往往只能接近真实数据集,不能用于真正的实验指导。钢铁材料领域针对特定钢铁材料的研究已经发表了很多文献,但由于缺少成熟的方法,难以从大量文献中收集数据作为机器学习的训练集。扩充钢铁材料的数据集可以通过数据挖掘技术从文献中提取有效数据,并建立可以用于机器学习的钢铁材料数据库,基于钢铁材料大数据驱动的机器学习将会快速推动钢铁材料的研发。
猜你喜欢
阅读(高年级)(2022年10期)2022-11-11 01:02:46
黄河之声(2022年10期)2022-09-27 13:59:46
环球时报(2022-07-13)2022-07-13 17:18:39
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
环球时报(2022-03-14)2022-03-14 18:19:44
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:00
电影(2018年8期)2018-09-21 08:00:06
航空世界(2018年12期)2018-07-16 08:34:50
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
