
基于用户画像动态养成的高校图书馆数字素养教育模式研究*
2023-10-26 10:03冯晓娜沈亚婕于元勋付露瑶刘文云
新世纪图书馆 2023年8期
冯晓娜 沈亚婕 于元勋 冯 晓 付露瑶 刘文云
0 引言
为进一步提高全民数字素养与技能,构建数字中国,建设教育强国,促进教育数字化转型和智能化,中央网络安全和信息化委员会于2021 年11 月5 日发布了《提升全民数字素养和技能行动纲要》,凸显了国家对全民数字素养的重视。国际图联建议图书馆应全力以赴,为提升公民的数字素养做出贡献,从规划设计、经费和人员投入等方面予以充分支持,将培养读者的数字素养能力纳入图书馆服务的核心内容。在大数据技术应用和用户需求多元化的背景下,我们需要深入了解用户对数字素养知识的需求,并利用新型智能技术创新教育模式,以满足用户多元化的个性需求,从而提升用户的数字素养能力。
用户画像技术具有准确预测用户需求的能力,为图书馆的智慧化推送和个性化教育提供了新的思路。目前,基于用户画像的智慧化推送和个性化教育的研究主要关注学习者自身的知识需求和兴趣爱好,但忽略了用户可能存在的素养短板、知识盲区等方面的挖掘和推送。这导致学生只接触到符合其偏好的教育资源,无法全面按照数字素养能力框架进行发展。因此,本文旨在构建基于全面数字素养需求的用户画像养成模型,以满足用户个性化数字素养教育和全面数字素养提升的目标。
1 图书馆数字素养教育与用户画像应用
文献调研发现,已有数字素养教育的研究主要侧重于调研数字素养教育现状、挖掘数字素养教育影响因素、丰富数字素养教育内容、创新数字素养教育形式等方面。黄燕[1]对全国10 所高校883 位高校的数字素养进行了调研,结果显示,当前高校图书馆数字检索能力薄弱,存在数字检索渠道不够广泛、数字安全意识不强、数字创新力不足等问题;耿荣娜[2]利用DEMATEL 方法识别了数字素养教育关键影响因素,研究发现,高校数字素养政策、数字素养教育环境、ICT 基础设施、数字素养教学管理和数字素养评价体系等对高校数字素养教育起关键推动作用,以期对高校大学生数字素养教育的落实路径的制定有所借鉴;马捷[3]等人对公民的数字需求进行了探索,在此基础上,从构建数字素养内涵体系、拓宽数字素养实践的方式、构建数字素养应急教育系统三个方面,探讨了构建我国高校数字的新途径;董岳珂[4]将数字素养引入MOOC 课程学习,拓展了数字素养教育线上教育形式。
我国高校图书馆数字素养教育尚处于初步探索阶段:第一,用户数字素养学习需求表现出阶段性、多样性、层次性,以及满足程度差异性,人们更加期望能够获得及时的、个性化的针对性训练。第二,开设多种类型的教学,例如MOOC,线下课程、混合式课程,讲座和微课等,但是内容统一、刻板,不具针对性,无法实时满足用户的个性化能力提升需求。第三,缺乏黏性,不适应用户终身素养提升。高校图书馆数字素养教育的对象多是群体性和粗颗粒的受众,其服务模式远未达到个性化、及时化和精准化,数字素养教育往往停留在浅层次上而无法适应数字技术和数字环境的变化。
随着用户画像在各场景中的应用,为解决上述问题,笔者认为要提升用户数字素养能力,应结合用户画像技术来实现培育模式。
用户画像(User Profile)的概念最早由Alan Cooper 提出,是指以真实数据为基础,对目标用户进行建模,从大量数据中抽取用户特征的图像集合[5],其通过可视化分析技术快速、精准分析用户行为模式、消费习惯等数据[6],能够准确地预测用户的实际需要和潜在需要,从而为各个产业提供精准的服务,提升用户体验奠定了基础。在图书馆领域,用户画像准确的预测用户需求并为之提供匹配度较高资源的特性为图书馆的智慧化推送与个性化教育提供了新的思路。
(1)智慧化推送:刘海鸥[7]等人利用多标签分类算法,从用户多维兴趣特征标签维度构建了用户的兴趣画像,从而实现了信息资源推送结果的多样化;卢思佳[8]等深度挖掘用户全方位的知识需求,刻画了图书馆知识服务中的用户画像,有效缓解了高校图书馆粗放式知识服务供给与用户个性化知识需求之间的矛盾,从而推动了知识需求对应的知识产品的生成,大幅提升了知识资源服务效能;Mahak Dhanda和Vijay Verma[9]提出的高效项集挖掘技术(High Utility Itemset Minng Technique, HUIM),将论文内容和科研人员兴趣偏好进行对比分析,为科研人员推送学术论文,满足其个性化要求;吴智勤[10]等利用社交网络分析法深度刻画了用户隐藏需求特征画像,有效提升了图书馆隐性知识服务效率。
(2)个性化教育:徐畅[11]等人根据用户的需求、兴趣绘制用户画像实现用户信息素养教育的精准化和个性化;朱青[12]等人提出基于异质性的用户标签体系设计层次分明的信息素养教育内容,动态契合用户画像与教学科研节点;尹婷婷[13]等人通过对学习者个性特征的描述、学习需求的识别绘制了学习者需求画像,构建了教育资源个性化推荐服务模型。
2 全面数字素养核心能力框架
通过分析国内外具有代表性的数字素养框架,进行合并整理相似能力领域,将数字素养基础能力划分为7 个层次,如表1 所示。

表1 数字素养核心能力框架
根据数字素养的能力要求,本文基于数字素养框架能力体系构建了动态多维度标签的数字素养知识需求画像方法。该方法主要包括两个方面:首先,在画像构建体系中构建实时数字素养知识需求画像,动态跟踪用户阅读行为,以解决用户的实时数字素养知识需求,并实现教育资源的实时个性化推送。其次,引入机器学习等相关技术,实现数字素养能力测评、计算和分析模型。通过将用户的原始数据与数字素养能力框架进行对比、分析和预测,识别用户数字素养的短板和能力缺陷。这样可以弥补用户对数字素养的感知不足,提供有针对性的能力培养和教育资源,从而提高数字素养知识需求画像的质量,实现用户数字素养能力的全面发展,同时也促进图书馆数字素养教育的提升。通过这种方法,可以更准确地理解和满足用户的数字素养知识需求,为他们提供个性化的教育资源和能力培养,从而实现用户数字素养能力的全面发展,并推动图书馆数字素养教育的提升。
3 基于核心能力框架的全面数字素养画像构建
在本研究中,用户数字素养知识需求的数据收集和需求主题分析是构建和修正用户画像的基础。由于不同用户具有不同的知识结构、工作重点和情境,其数字素养知识需求的内容和层次各不相同。为了准确描述用户的个性化需求和动态需求,并及时提升他们的数字素养能力,选择能够刻画用户实时数字素养知识需求的关键指标是用户数字素养知识需求画像指标体系的关键。
本研究主要从数据收集层、数据标签层、画像构建层和画像应用层四个层次考虑了数字素养动态养成用户画像的构建流程,如图1 所示。通过这个流程,可以收集用户的个性化需求和动态需求,并准确描述用户的数字素养知识需求,以满足他们的需求并提升他们的数字素养能力。同时,为了加强对用户隐私问题的审查和管理,以全面维护用户数据的安全,必须将用户隐私保护融入到用户画像构建的全过程中[8]。
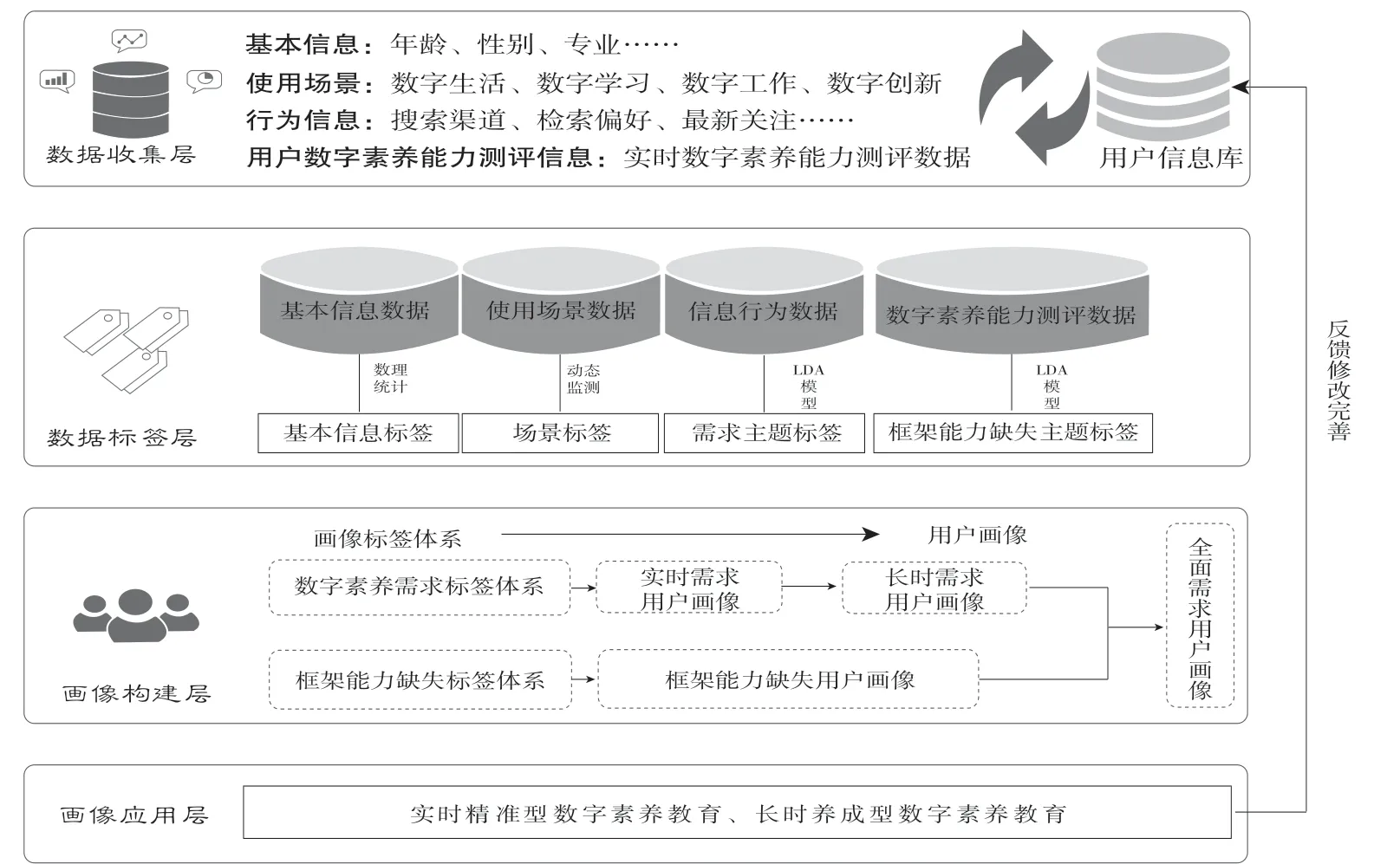
图1 用户画像构建模型
3.1 数据收集层
用户数字素养知识需求包括用户在学习、生活等场景中应具备的数字素养能力,涉及用户的学习阶段、兴趣爱好及能力变化等因素,因而在用户画像数据搜集阶段,本文融合Nasraoui[14]与Adomavicius[15]的用户动态行为画像模型构建方法,将用户数字素养知识需求画像的信息收集涵盖了“静态稳定”用户基本信息及“动态可变”用户行为信息、使用场景信息、用户数字能力测评信息两部分属性,着重四类信息的收集。
(1)用户基本信息。用户数字素养知识需求画像基本信息构成要素为:用户的基本素养、学历层次、专业类别、已有研究成果等。为了确保用户画像建设质量,可以依据学校归档范围表制定学校大数据采集计划,整合学校用户大数据资源[16],大数据归档资源相比于用户自己填写的用户基本信息,具有数据真实准确、齐全完整、及时迅速、安全可靠等优势[16]。该阶段要注意对用户数据进行加密处理,确保用户基本信息不被泄露。
(2)用户行为信息。借鉴杨帆[17]的以画像分析为基础的图书馆大数据构建方法,提出用户数字素养知识需求画像行为信息构成要素为:在校园网内检索、查阅、文献传递、在线浏览、图书收藏、最新关注、学术兴趣、搜索渠道、检索行为、检索偏好、网站访问等动态行为数据。由于用户数字素养知识需求会随着环境变化而有动态性改变,为满足用户数字素养行为的动态监测需求,利用嵌入系统的页面行为监控插件收集用户行为数据;同时为精确表达数字素养实时需求,可借鉴区块链的时间戳技术[18]动态监测整个数字素养水平生命周期,清晰展示出数字素养知识需求整个生命周期发展路径展示用户的需求、偏好、意愿、观点等数据。
(3)使用场景信息。借鉴《行动纲要》提出了全民数字生活、数字学习、数字工作、数字创新四大场景,基于在这四大场景中映射出现实场景内部的数字素养知识与技能,为用户提供数字素养教育。在动态行为需求监控同时,利用传感器和移动终端等设备,获取用户的情境数据,包括用户在某功能页面的操作交互和视觉、跨功能界面的操作路径等,最终提取场景标签。
(4)用户数字素养能力信息。用户实时数字素养能力信息是构建基于框架缺失能力框架的核心部分。为获取用户实时数字素养能力真实数据,主要分为以下几个步骤:①基于数字素养核心能力框架构建数字素养能力评价指标体系。②依据数字素养能力评价指标体系设立测试模块:分为初始测试和教育过程中的测试,以获取用户的初始数字素养能力和实时数字素养能力数据。将收集到的用户数据及时同步至用户信息库中,为后续的数据预处理提供数据基础。
在数据处理阶段,主要涉及以下两点:第一,用户数据清洗。删除与用户需求服务不相关信息、过滤价值低的数据、删除重复数据[19]。第二,用户数据分析。首先实现潜在用户数据的全流程挖掘,通过关联分析、变异分析等技术手段剔除与数字素养教育不相关数据,通过语义分析等算法进行分类挖掘,提炼出用户数字素养知识需求的语言表达形式。同时由于信息行为等半结构化数据和非结构化数据冗杂,且需要更多的时间进行预处理,为提高用户数据分析效率应将多维度用户数据转化为维度一致的结构数据。在该阶段,应注重用户实际需求,避免对数据进行过度挖掘。该阶段使用了数据的分类、聚类、合并、关联等多种方法完成用户识别与用户多维信息采集工作,由此建立用户信息数据库,通过对用户相关数据进行聚类与统计分析处理后,形成具有数字素养知识需求特质用户画像数据。
3.2 数据标签层
构建用户画像模型需要采集并处理用户数据后,通过分析数据中关键词汇及文本来抽取用户特征标签[7]。其中,用户基本属性维度标签、场景维度标签能够不经加工直接生成;而需求主题特征维度数据及框架能力缺失主题特征维度数据需经过一定的加工过程才能够确定标签的属性。
本文基于数字素养核心能力框架进行用户画像构建,因此在主题加工聚类方面,结合上表1 中“数字素养核心能力框架”将数字素养知识主题如下分类:数字信息源选取、数字技术的学习及操作、专业信息获取与检索技巧、数字信息处理与协作、数字信息批判性反思与创新、数字信息安全意识及数字伦理道德、数字实践。
(1)需求主题标签加工。LDA 模型以概率为基础,善于利用文本发现用户的需求主题,并对用户的集中关注点和特征词进行分析。在需求主题挖掘方面,本文以LDA 技术挖掘用户的数字知识素养需求主题为例,对用户行为中的搜索关键词进行爬取,通过LDA 主题挖掘技术对这些关键词进行搜索主题聚类,具体步骤如下:①对用户的搜索语句进行爬取,归档后做分词,并过滤掉无意义词,得到语料集合W={w1,w2,…,wx}。②对这些词做统计,得到集合p(wi|d)。③为语料集合W 中的每个wi,指定对应到某个主题t 中,作为初始主题。④通过Gibbs Sampling 公式,重新采样每个w 的所属主题t,并在语料中更新直到Gibbs Sampling 收敛。收敛以后得到主题—词的概率矩阵,这个就是LDA 矩阵,而文档—主题的概率矩阵也是能得到的,统计后,就能得到文档-主题的概率分布。⑤得到XX 个主题,这些主题含有和文章列出的主题不相关的,以及具有噪声的干扰的主题,经过人工判别,剔除掉不相干的主题,最终得到和本文相同或相近的主题。
本研究使用LDA 主题模型计算公式,如公式(1)所示:
(2)缺失主题类目加工。该阶段首先应基于用户数字素养能力评价体系对用户数字素养能力测评进行分析,对比出用户缺失能力数据,进行归档后做分词,得出语料集合N={N1,N2,NX},下面步骤与上文中需求主题标签加工②~⑤类似,剔除掉不相关主题,最终得到用户缺失主题类目。
3.3 画像构建层
标签体系构建是构建用户画像的关键一步,用户画像多维度标签能够体现用户多变性,将其抽象成图像,并与用户动态需求相结合[20],从而实现图书馆个性化数字素养教育服务。如表2 所示为用户数字素养知识需求标签体系和框架能力缺失标签体系。
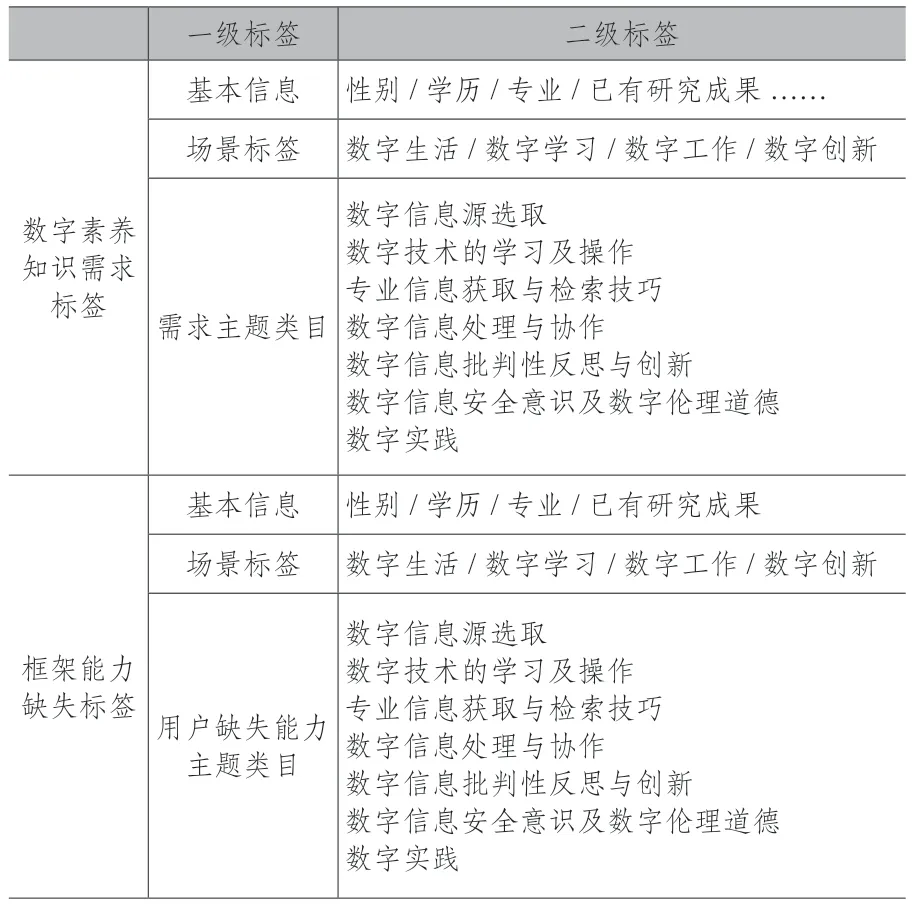
表2 用户画像标签指标体系
表2 使用了用户画像特征指标建立画像标签,其中用户基本属性维度标签、场景维度标签可直接生成,而主题特征维度数据需经过加工才能确定标签属性。在此阶段,可采用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法进行标签聚类,输出用户画像。同时,需加强画像隐私保护,对信息进行加密处理并限制使用权限。
在构建完成多维度的标签体系后,通过标签匹配构建出相应的用户画像。
(1)实时需求用户画像。通过分析用户的基本属性、场景属性和需求主题特征,构建多维标签的数字素养知识需求模型。匹配和整合这些标签,创建用户画像模型,形成实时需求用户画像数据库。用户基本属性数据来源于全流程数据集合深度挖掘的结果,而用户场景维度根据人机交互行为确认。需求主题特征维度包括数字信息源选取、数字技术学习与操作、专业信息获取与检索技巧、数字信息处理与协作、数字信息批判性反思与创新、数字信息安全意识与数字伦理道德、数字实践等。这些维度的分析有助于全面了解用户需求和兴趣,为提供个性化的数字素养教育服务提供依据。
(2)长时需求用户画像。利用大数据技术,可以通过动态行为监测对用户的使用场景和行为信息进行标记,并准确提取用户最新的访问行为特征。通过挖掘具有相似兴趣和偏好的知识需求之间的关联度,可以揭示出知识需求之间的隐藏关联。同时,结合用户的基本信息和访问节点(如备考阶段、开题阶段、论文撰写阶段等),可以分析收集到的用户信息,从而预测用户的需求偏好。通过对用户需求的预测,可以构建出在某个特定节点内的长期需求的用户画像。这样的用户画像能够更好地满足用户的个性化需求。
(3)框架能力缺失用户画像。以上实时需求的用户画像描绘出用户对数字素养和兴趣偏好等属性的实时需求,长时需求也是根据用户行为信息对用户某段时间节点的知识需求、偏好进行预测,这种基于需求推送的资源和服务,皆为显性需求,用户自身存在的数字素养短板、盲点,即用户没有感知到数字素养弱项不能根据显性需求而获得。因此,需要基于数字素养能力框架绘制框架能力缺失用户画像,如图2所示。
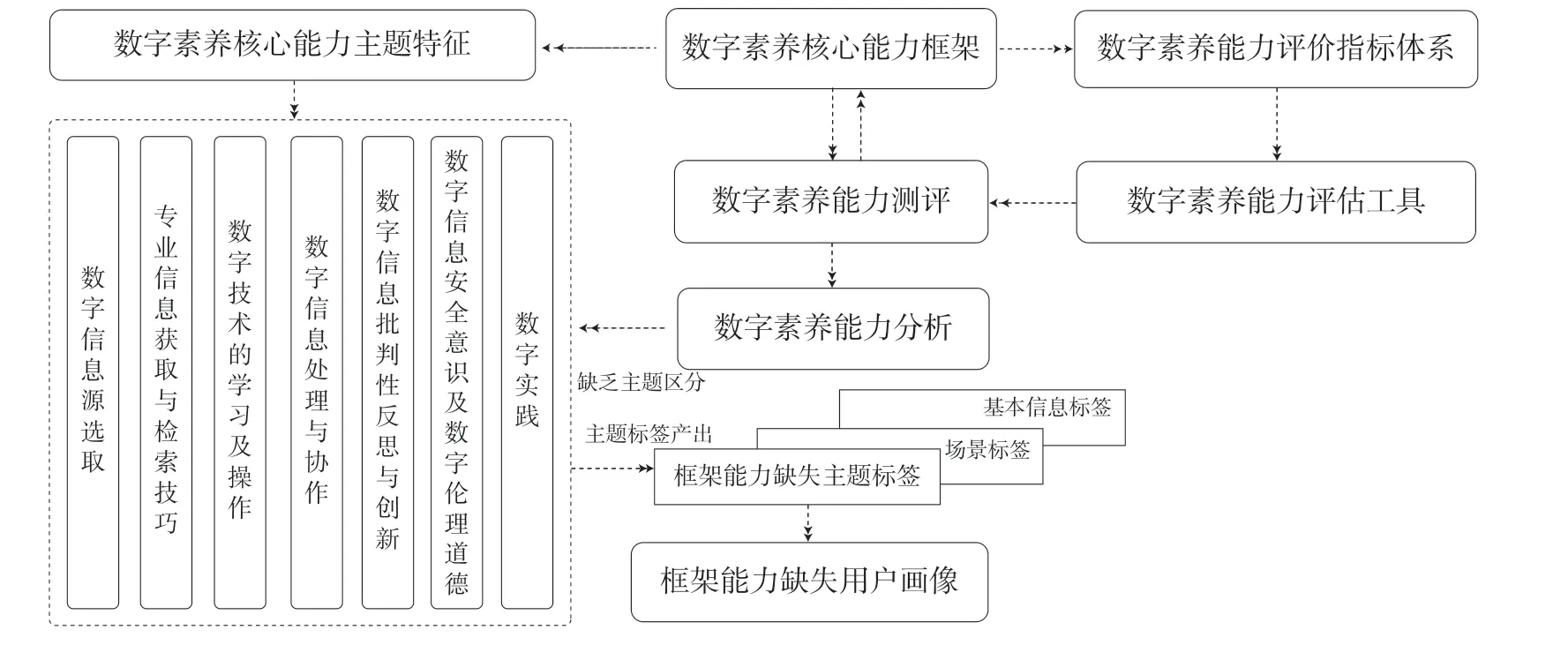
图2 框架能力缺失用户画像流程
框架能力缺失用户画像基于上述数字素养核心能力框架产生,分为以下几个步骤:①基于以上数字素养能力测评结果与数字素养核心能力框架进行对比,找出测评数据与数字素养能力框架对比出能力欠缺部分,测评数据并能及时地反馈用户的数字素养能力水平,有利于对用户画像进行优化并实现对用户动态画像模型的构建,准确掌握用户需求动态变化情况。②根据欠缺部分对用户数字素养能力二级指标进行全面对比分析,将缺失能力数据归档后,应用LDA 技术挖掘其欠缺能力主题,并打上缺失能力标签。其中缺失能力主题依据核心能力框架主题类目产生,包括数字信息源选取、数字技术的学习及操作、专业信息获取与检索技巧、数字信息处理与协作、数字信息批判性反思与创新、数字信息安全意识及数字伦理道德、数字实践7 个子维度。③依据以上缺失能力主题标签,构建指标体系,最终应用DBSCAN 算法,实现标签聚类,绘制成最终的基于核心能力框架的缺失能力用户画像。
(4)全面需求用户画像。全面需求用户画像不仅描绘了用户兴趣、及时的知识需求,还包含用户未察觉的基于数字素养核心能力框架的知识短板。因此全面需求画像沿着上述画像的生成过程产生,将用户缺失能力画像与用户实时、长时需求画像进行反馈对比;最后将用户欠缺的数字素养能力但是用户自身未察觉的能力需求补齐,形成最终的全面需求用户画像。
4 基于用户画像的高校图书馆数字素养教育模式
基于用户画像可以同时开展实时精准型、长时养成型数字素养教育。其中,实时精准型数字素养教育基于实时用户需求画像与数字素养资源语义匹配后进行的知识推荐结果,解决实时用户数字素养知识需求;长时养成型数字素养教育是基于全面需求用户画像,整合相关数字素养资源,对用户实行长期稳定的个性化数字素养教育,既可以大幅提升数字素养精准化个性化效率,又能提升用户全面数字素养能力,如图3 所示。
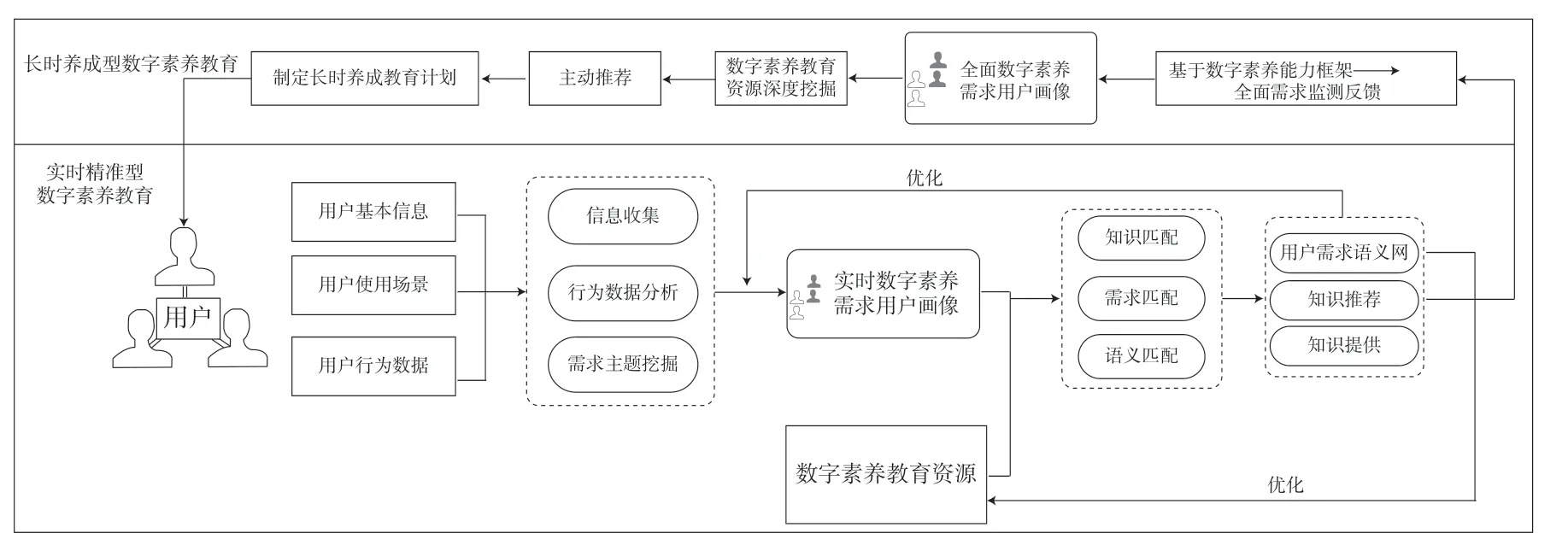
图3 数字素养教育优化模式
4.1 实时精准型数字素养教育
只有当知识精准服务于用户需求时,“知识服务”才可以被认为是高质量的,高校实时精准型数字素养教育的核心就是把用户需求精准衔接数字素养教育资源。仅对用户数字素养需求画像解剖还不够,需要通过建立“画像对接+服务匹配+反馈优化+画像修正+画像对接”的循环式画像迭代和实时精准数字素养教育实施机制,进一步实现用户需求与数字素养资源供给的精准对接。
4.1.1 画像对接与服务匹配
在用户画像创建流程中,考虑到场景的多变性与常见性,故添加“使用场景”这一影响因素,创建了反映用户的数字素养知识需求主题特征的画像,进而将用户画像与使用场景所综合呈现出来的用户数字素养知识需求全貌与数字素养教育资源相对接,通过需求匹配、语义匹配、知识匹配、实体融合等算法途径筛选出资源匹配的最优解,为其提供知识地图、知识报告、知识定制、知识咨询等知识产品及服务。
4.1.2 反馈优化与画像修正
当用户收到对应知识产品和服务时,可以通过评价反馈渠道将自身数字素养知识需求和数字素养知识服务匹配度,以及当前知识服务满意度等指标量化评价并反馈。图书馆则运用关联数据技术,通过对收集获取到的用户需求反馈节点及其内部的关联进行标准化的语义表示,从而建立了用户数字素养需求的语义网络。用户评估反馈数字素养需求语义网反作用到用户画像建立和数字素养教育资源库中,对数据进一步修改和完善,细化用户画像,尽可能向用户提供匹配度高的数字素养教育服务,极大提升问题解决效率,并增强用户的依赖性与满意度。当获得新的知识服务时,用户还会重新评估反馈并持续发挥作用到用户画像创建过程中去。及时得到用户的反馈信息,并在此基础上优化精准数字素养教育,有利于对用户画像进行优化并实现对用户动态画像模型的构建,准确掌握用户需求动态变化情况,保持知识服务准确有效。在此过程中,高校图书馆数字素养教育的供给逐渐逼近其用户的真实数字素养知识需求。
4.2 长时养成型数字素养教育
长时养成型数字素养教育不仅满足用户长时数字素养知识需求,还是一个基于数字素养能力框架不断补齐用户数字素养能力短板,为用户长远数字素养知识需求提供服务的方案集合。其在实时分析用户画像数字素养知识需求和用户自主设置的知识需求基础上,对用户某节点的知识需求进行预测,同时将数字素养能力测评结果与数字素养能力框架对比,挖掘、预测追踪用户数字素养能力欠缺范畴,全面综合勾勒出用户相对长期的、稳定的且规律的知识需求。其演绎产生长效数字素养教育方案,结合用户参与数字素养培训、测试的结果,分析学生数字素养能力现状,拟定符合用户能力要求的渐进式数字素养培养计划。自动启动特定主题领域内的资源最新动态追踪,将文本、图像和音视频等多模态资源整合查询并深度加工,以实现多模态信息之间的相互转换,向用户端智能推送以主动更新。
5 结语
数字素养教育是高校图书馆在数字环境下开展教育服务所肩负的一项新任务。本研究根据数字素养能力框架对用户进行数字素养能力评估,弥补了用户本身没有感知到的对数字素养的认知要求,改变了过去单纯依赖用户本身兴趣、喜好的用户画像建构过程,关注用户所欠缺的数字素养,重构了一个较为完整的以数字素养能力框架为核心的需求画像,提出了基于画像的实时精准、长时养成数字素养教育,为提升图书馆知识服务能力及用户数字素养能力提供了一定的理论基础和应用借鉴。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
小资CHIC!ELEGANCE(2022年1期)2022-01-11
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
数学物理学报(2020年3期)2020-07-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
法大研究生(2017年1期)2017-04-10
公民与法治(2016年10期)2016-05-17
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
