
基于机器学习的智能商品推荐系统研究
2023-10-25 10:46胡迪
无线互联科技 2023年16期
胡 迪
(成都锦城学院,四川 成都 610000)
0 引言
在互联网和电子商务的迅速发展下,电商平台已经成为人们主要的购物方式之一[1-2]。然而,随着电商平台上商品种类的不断增加和用户需求的多样化,用户往往在面对大量商品时遇到信息过载的问题,难以快速找到符合个人兴趣和需求的商品。智能商品推荐系统作为一种帮助用户在众多商品中发现个性化推荐的工具变得越来越重要[3]。在上述问题中,传统的商品推荐方法基于人工规则和经验,存在推荐效果不佳、无法满足用户个性化需求等问题。机器学习技术的快速发展促使基于机器学习的智能商品推荐系统成为研究的热点和应用的趋势。基于机器学习的智能商品推荐系统通过分析用户的历史行为、兴趣偏好、社交网络等信息,利用机器学习算法挖掘隐藏在海量数据中的潜在关联,提供更准确、个性化的商品推荐服务[4-5]。
为了解决上述问题,本文设计了基于XGBoost分类器[6-7]的商品推荐系统。该系统采用基于内容的过滤方法,包括数据库、XGBoost分类器、总体预测、预测和推荐、推荐商品5个组件的协调工作。实验通过处理和分析某在线购物平台的10 000条数据集,展示系统在识别率和计算时间方面的良好性能。本文为电商平台的商品推荐提供了一种有效的解决方案,未来的研究可进一步优化系统性能,提高推荐的准确性和用户体验。
1 模型架构
1.1 问题分析
推荐系统是一种用于过滤信息并预测用户兴趣和物品评价的平台,在许多应用场景中得到广泛应用,如淘宝、拼多多、亚马逊等电商平台。推荐系统通常包含不同的组成部分,其中基于内容的过滤和协同过滤是两种常见的方法。产品推荐系统旨在为用户生成各种项目和信息的推荐意见,从而使购买过程更加便捷和舒适。创建产品推荐系统的方法主要包括基于用户-产品关系、用户-用户关系和产品-产品关系3种方式。用户与产品之间的关系基于个人对产品的偏好,而用户-用户关系则是基于相同情境下的用户,例如相同年龄、相同兴趣等;产品-产品关系则是基于相似的补充产品,如钢笔和铅笔之间的关系。
在推荐系统中,机器学习技术,特别是基于机器学习的推荐技术,被广泛应用于数据过滤和预测过程中。本文采用的是基于内容的过滤和协同过滤相结合的方法。其中,基于内容的过滤是基础,该方法在提取用户指标,例如用户点击次数、购买的商品、访问的页面、在网站上经过的时间、产品类别等。根据这些信息,制作客户档案,并使用这些信息推荐该区域的商品。协同过滤基于用户行为和优先级提取信息,并预测用户与其他用户之间的相似性。例如,如果用户1点草莓,用户2也点草莓,那么系统会识别出这些用户有相同的选择,并向他们推荐一些类似的商品。
1.2 商品推荐系统总体架构
本文设计的推荐系统根据用户之前的活动和点击信息提供基于内容的过滤推荐项。图 1 显示了包含5个部分的系统架构,分别为数据库、XGBoost分类器、总体预测、预测和推荐、推荐商品。
数据库用于存储用户之前的活动和点击信息,例如用户的历史购买记录、浏览记录、评价等。这些信息作为推荐系统的输入数据,用于构建用户的兴趣模型。XGBoost分类器是系统的关键部分,用于构建基于内容的推荐模型。它通过训练一个梯度提升树模型(XGBoost模型),基于用户之前的活动和点击信息进行特征提取和模型训练,从而得到一个强大的分类器,用于预测用户对不同商品的兴趣。总体预测部分使用XGBoost分类器对所有商品进行预测,得到每个商品的兴趣度得分。这些兴趣度得分用于后续的推荐过程。在预测和推荐部分,系统根据用户的历史活动和点击信息,通过XGBoost分类器对用户对所有商品的兴趣度进行预测,并选择得分较高的商品作为候选推荐项。这些候选推荐项会进一步经过过滤和排序的处理,从而得到最终的推荐商品列表。推荐商品部分将经过过滤和排序的推荐商品列表呈现给用户,用户可以根据自己的兴趣和需求选择并进行购买。
这5个部分构成了一个完整的基于内容的推荐系统总体架构。用户的历史活动和点击信息存储在数据库中,XGBoost分类器根据这些信息进行模型训练,并通过总体预测对所有商品进行兴趣度预测。预测和推荐部分根据预测的兴趣度得分对商品进行过滤和排序,从而得到最终的推荐商品列表,呈现给用户进行选择和购买。
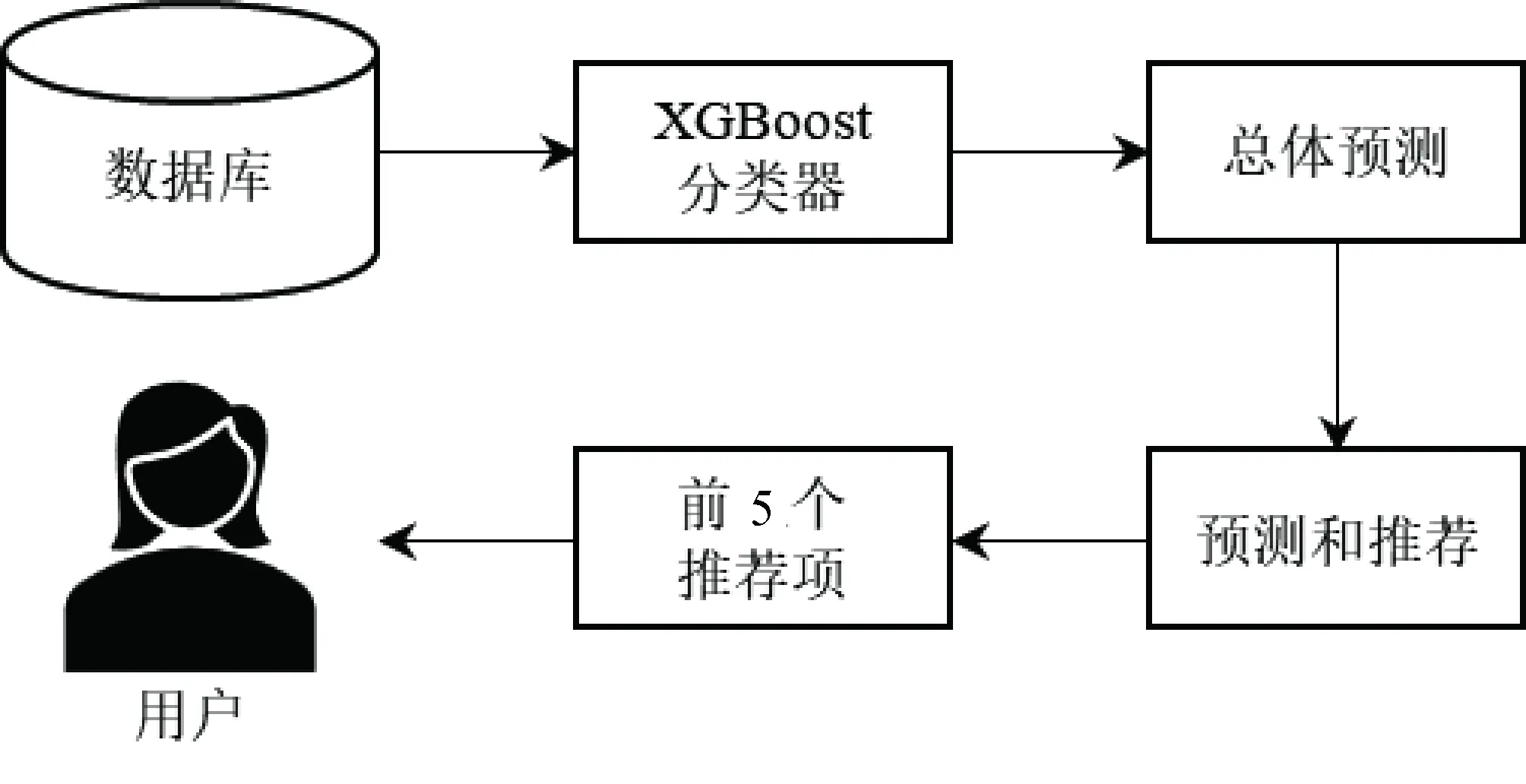
图1 系统总体架构
推荐系统中的算法体系结构流程如图2所示,第一部分为数据预处理,第二部分为预测过程,最后部分为产品推荐结果。
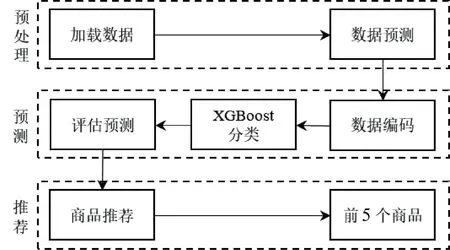
图2 推荐系统中的算法体系结构
1.3 XGBoost分类器
XGBoost分类器是系统的关键算法。该算法是一种基于梯度提升树的机器学习模型,用于解决分类和回归问题。
XGBoost通过集成多个弱学习器(本文采用决策树[8-10])来构建一个强大的分类模型。每个弱学习器都是在之前弱学习器的基础上进行训练,通过对之前弱学习器预测错误的样本进行更加关注,从而不断优化模型的预测性能。另外,XGBoost采用了梯度提升的策略,通过迭代的方式不断优化模型的预测性能。在每一轮迭代中,XGBoost计算损失函数的负梯度(即残差),然后将负梯度作为新的目标,构建一个新的弱学习器,将其加入模型。这样,模型在每一轮迭代中都会不断提升,从而得到一个强大的模型。XGBoost还引入了正则化项,包括了L1和L2正则化,用于防止过拟合。正则化项在目标函数中添加了一个惩罚项,限制模型的复杂度,从而提高模型的泛化能力。
XGBoost允许用户自定义损失函数,从而可以灵活地适应不同的问题和场景。用户可以根据问题的特点定义自己的损失函数,并在训练过程中使用该损失函数进行优化。XGBoost的目标函数包括了目标函数和损失函数,分别为:
Obj(Θ)=L(Θ)+Ω(Θ)
(1)
(2)

(1)初始化:首先,初始化模型的预测值,通常可以使用均值作为初始值。
(2)计算残差:通过计算预测值与实际标签之间的残差,得到当前模型的预测误差。
(3)构建弱学习器:使用弱学习器(通常是决策树)对预测误差进行建模,将其添加到模型中。
(4)更新模型:通过梯度下降法对模型的预测值进行更新,从而减少预测误差。
(5)迭代优化:重复上述步骤,直到达到指定的迭代次数或者预定的停止条件。
(6)集成模型:最终将所有弱学习器集成,得到最终的XGBoost分类器。
2 实验与分析
2.1 实验环境和数据集
实验设置如表1所示。本系统的所有实验和结果均在搭载Intel(R) Core(TM) i7-8700 CPU @3.20 GHz处理器、32 GB内存的计算机上进行。推荐系统采用了XGBoost机器学习算法。同时,本系统所使用的库和框架为Jupyter notebooks。在系统设计中,使用了WinPython-3.6.2作为编程语言。本研究中所使用的数据集来自某在线购物商城的记录,具体信息如表1所示。数据集总共包含10 000条记录。每个用户的最大点击信息数为12次,最小点击数为4次,因为少于4次点击的信息无法提供足够的推荐依据。本文将80%的数据作为训练集,20%的数据作为测试集。
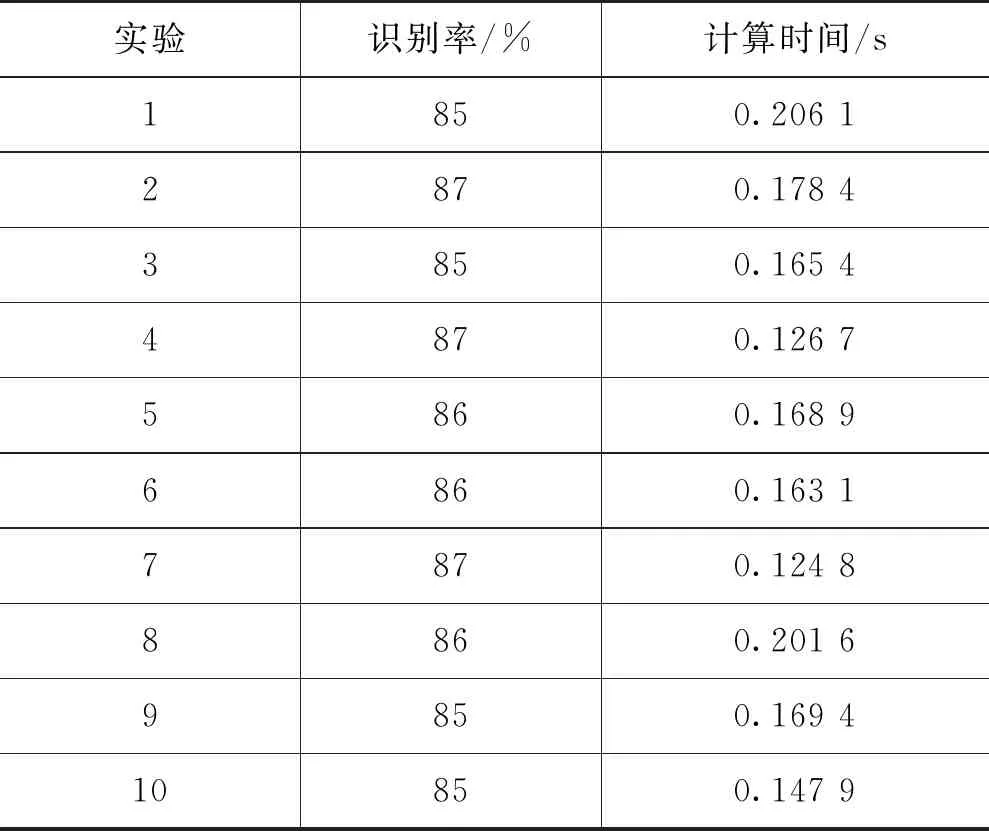
表1 识别率和计算时间
2.2 实验结果
为了剔除少于4次点击的信息,本实验对验证系统的识别率和计算时间进行了验证,表1展示了本系统10次实验的测试结果。最高的识别率达到了87%,而最短的计算时间为0.124 8 s。
经过预测处理后,系统会推荐5个最接近预测商品的商品。表2展示了推荐结果。第一列显示了预测的值,第二列显示了文本值,第三列显示了推荐的商品。通过将推荐的商品与用户的点击列表进行对比,可以判断推荐的商品是否出现在用户的点击列表中。为了在推荐系统中进行处理,本文首先使用了标签编码的过程,将收集到的数据进行编码,使其适用于推荐系统的使用。
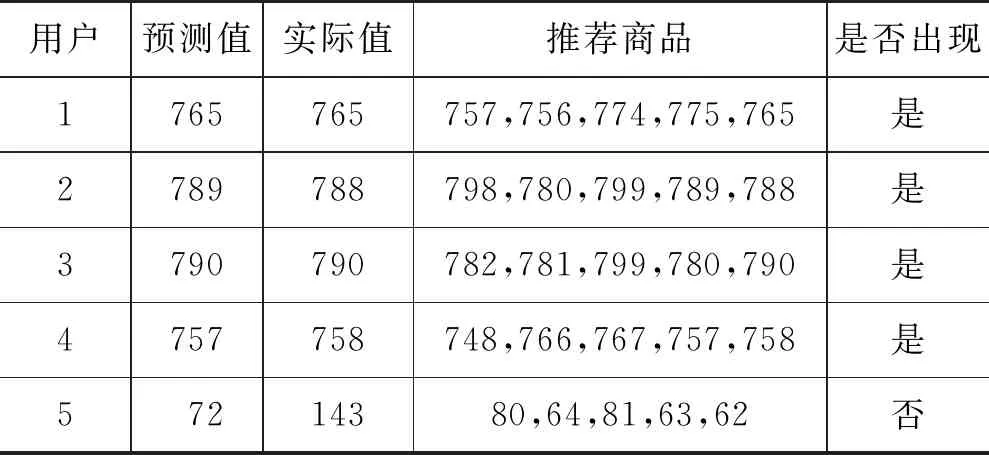
表2 5个最近的推荐结果
在向用户推荐项目后,为了进一步处理标签编码项目以转换为真实的商品编号。表3显示了将项目编号转换为实际项目编号的结果。
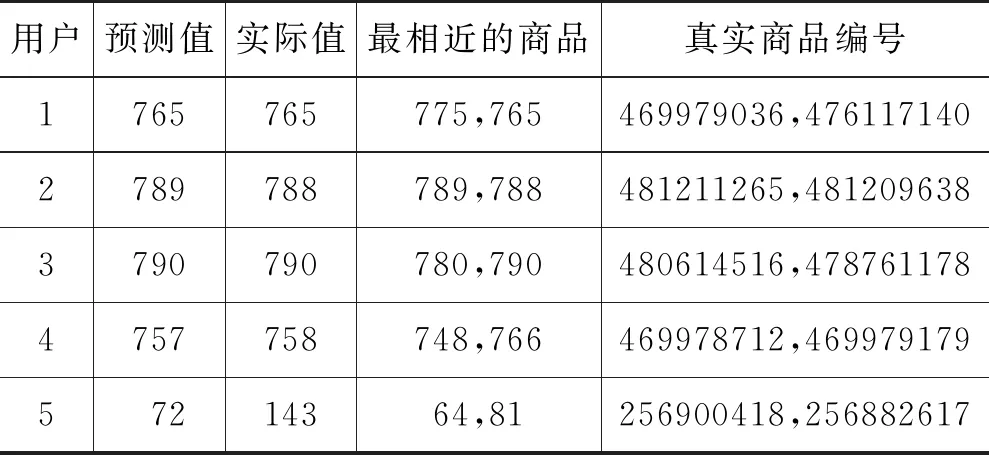
表3 将推荐结果转换为真实商品结果
3 结语
推荐系统作为一种信息过滤和用户兴趣预测的平台,在现代电商平台得到了广泛应用。然而,随着电商平台上商品种类的增多和用户需求的多样化,用户面临信息过载的问题,难以快速找到符合个人兴趣和需求的商品。为解决这一问题,本文设计了一个基于XGBoost分类器的商品推荐系统。系统通过数据库、XGBoost分类器、总体预测、预测和推荐、推荐商品5个部分的协调工作,实现了基于内容的过滤推荐。经过测试,实验结果表明该系统的识别率最高可达87%,计算时间最小为0.124 8秒。在商品推荐方面,系统通过预测过程后,推荐5个最接近预测商品的商品,并通过标签编码的方式处理数据,使其适用于推荐系统。通过与测试值的对比,可以判断推荐的商品是否出现在用户的点击列表中,从而为用户提供更为准确的推荐。未来可以进一步优化系统性能,提高推荐准确性和用户体验。
猜你喜欢
今日农业(2022年16期)2022-11-09
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
现代企业文化(2018年13期)2018-06-09
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
机电信息(2015年28期)2015-02-27
电测与仪表(2014年15期)2014-04-04
