
基于语言模型增强的中文关系抽取方法
2023-10-24 14:16吴中海
中文信息学报 2023年7期
薛 平,李 影,2,吴中海,2
(1. 北京大学 软件与微电子学院,北京 100871;2. 北京大学 软件工程国家工程研究中心,北京 100871)
0 引言
作为自然语言处理领域的重要任务之一,关系抽取旨在识别文本中实体对之间的语义关系,例如在句子“哈尔滨是黑龙江省会”中,关系抽取方法可以提取出“哈尔滨”和“黑龙江”的语义关系是“位于”。抽取得到的实体关系三元组被用于知识图谱构建[1]、智能问答系统[2]、对话内容理解[3]等下游任务,并应用在多个领域,包括医疗[4]、金融[5]、法律[6]等。近年来随着深度学习方法的快速发展,关系抽取任务取得了长足的进步,大量基于深度学习的关系抽取方法被提出。Liu等人[7]在2013年首次提出基于深度学习的关系抽取方法,使用卷积神经网络对文本进行特征提取。之后,陆续有研究者提出基于循环神经网络[8-12]、基于图神经网络的方法[13-14]等等。但上述关系抽取的研究工作,主要集中于英文领域,以单词序列作为输入。而在中文自然语言中,单词与单词之间没有分隔符,使用英文领域的关系抽取的方法需要先进行分词处理,而分词过程中产生的错误,会影响关系抽取任务的结果。为了避免错误传递,目前大部分的中文关系抽取方法都是以字符序列作为输入。
基于字符序列的中文关系抽取方法,虽然可以避免分词处理所带来的错误传递问题,但却忽略了文本中单词所包含的高级别语义信息。例如“哈尔滨是黑龙江省会”中,“哈尔滨”“省会”等词所表示的城市的语义可以帮助推理出“位于”关系。目前,如何在中文字符序列中融合单词信息是中文关系抽取任务的主要研究内容之一,相关工作可以划分为基于词典的方法(lexicon-based)和基于预训练的方法(pretrain-based)。如图1(a)所示,基于词典的方法通过将文本匹配固定的词典,获得文本中所有可能存在的单词,然后通过Lattice-LSTM[15]或Flat-Lattice[16]等网络将单词信息动态地编码进字符序列中;而基于预训练的方法,如图1(b)所示,使用自然语言处理领域中流行的预训练语言模型,在大规模的语料中进行语言模型的训练。在训练的过程中通过全词遮蔽(Whole-Word-Mask)等方法[17],将单词信息在预训练的过程中编码进模型,然后在中文关系抽取的任务上进行微调(Fine-Tune)。

图1 基于词典的方法和基于预训练的方法
预训练语言模型如BERT[18],在大规模语料上进行遮蔽语言模型的训练。得益于复杂的模型结构和海量的训练数据,预训练语言模型可以对训练语料中的语言知识进行准确的刻画。相比于基于词典的方法,其包含的语言知识使得模型具有更好的泛化能力,能够抽取到更加准确的关系。但预训练语言模型的参数规模非常庞大,大部分的预训练语言模型都包含上亿的参数,在现实场景应用中需要消耗大量的存储资源和计算资源。
为了避免预训练语言模型高昂的模型开销,同时利用其包含的语言知识,本文提出基于语言模型增强的中文关系抽取方法,其核心是采用多任务学习结构,在中文关系抽取模型基础上,训练一个语言模型来拟合预训练语言模型,学习预训练模型包含的语言知识。具体来说,我们使用轻量化的基于循环神经网络的关系抽取模型作为基准模型,同时以该循环神经网络训练一个双向语言模型。不同于一般的语言模型以下个字符作为标签训练,我们使用预训练语言模型的输出作为训练标签,使双向语言模型去拟合预训练语言模型,从而来学习其包含的语言知识。得益于多任务学习中的参数共享机制,双向语言模型学习到的语言知识可以对中文关系抽取模型进行增强,避免了预训练模型的高昂开销,同时有效利用预训练语言模型中的语言知识。
与我们方法类似的是基于知识蒸馏的模型压缩方法[19],同样是使用轻量化的模型学习复杂模型的知识,但这两种方法的结构与所涉及的知识类型是不同的。知识蒸馏方法是使用复杂的老师模型在相关任务的数据集上先行进行学习,然后再将学习到的数据集内数据分布相关的知识蒸馏到轻量化的学生模型中,其中老师模型和学生模型都是关系抽取模型。而基于语言模型增强的中文关系抽取方法则是在关系抽取模型的基础上同时学习一个双向语言模型,通过双向语言模型来拟合预训练语言模型,来学习预训练模型中包含的语言知识。
本文的贡献主要包括:
(1) 针对基于预训练语言模型的中文关系抽取方法参数多及开销大的问题,提出了基于语言模型增强的中文关系抽取方法,采用多任务学习结构,训练双向语言模型从预训练语言模型学习语言知识,在高效抽取实体关系的同时避免了预训练模型的高昂开销。与知识蒸馏等压缩模型方法不同的是,本文提出的方法通过拟合预训练语言模型学习语言知识,突破了数据集的限制,提高了模型的泛化能力;
(2) 在三个中文关系抽取数据集上进行实验,证明本文提出的方法可以有效地提高基准模型的效果,超过了目前基于词典的方法。与基于预训练语言模型的方法相比,本文提出的方法使用其大约1%的参数量即可达到其95%的性能。
本文组织结构如下: 第1节介绍相关工作;第2节给出中文关系抽取任务的定义和基准模型;第3节介绍基于语言模型增强的中文关系抽取方法;第4节给出实验结果和分析;第5节总结本文工作。
1 相关工作
目前,基于深度学习的关系抽取方法成为主流。Liu等人[7]在2013年首次探索了深度学习方法在关系抽取任务中的应用,提出基于卷积神经网络的关系抽取方法。之后,Zeng等人[20]在该方法的基础上加入了位置向量,用来表示文本中实体的位置信息。卷积神经网络的局限在于只能提取文本序列局部的特征信息。为了捕捉到全局的特征,在2015年,Zhang[8]等人使用循环神经网络对文本和实体进行特征提取,以捕捉文本序列中的全局特征。在之后,为了进一步对文本进行表示,Zhang[13]等人引入了额外的基于单词构建的依存句法树,使用图神经网络[21]提取依存句法树的特征,来提高关系抽取任务的结果。
在中文关系抽取领域,为了避免分词错误导致的错误传递问题,主要工作都是字符级别的关系抽取方法,以字符序列作为输入。Zhang等人[22]指出了中文文本中分词错误问题导致的错误传递现象,提出了基于词典的方法并设计了在字符序列动态融合单词信息的Lattice-LSTM网络。之后,Li等人[15]提出了MG-Lattice,在Lattice-LSTM的基础上融合了多粒度的信息,进一步提高中文关系抽取任务的准确率。Lattice-LSTM虽然可以动态地融合单词信息,但是由于模型结构的限制,无法并行计算。为此,Zeng等人[16]使用可以并行计算的Flat-Lattice网路来动态地融合单词信息到字符序列中。
近些年,预训练语言模型BERT[18]被提出,大幅提高了大部分自然语言任务的指标。预训练语言模型在大规模的语料上进行遮蔽语言模型的学习,然后在特定的任务上进行微调(Fine-Tune)。得益于在大规模语料中学习到的语言知识,目前,大部分的自然语言处理任务中最优的模型都是基于BERT或BERT的变体。同样地,基于预训练语言模型的中文关系抽取方法也得到了更优的结果。但预训练语言模型包含的参数量非常庞大,大部分的预训练语言模型都包含上亿的参数,在现实世界的实际应用中,需要耗费大量的计算资源和存储资源。目前,针对预训练语言模型的压缩,有知识蒸馏[23]、模型剪枝[24]、模型量化[25]等方法。与这些方法不同,本文提出的基于语言模型增强的中文关系抽取方法,直接学习预训练语言模型中包含的语言知识,使用这部分语言知识来增强中文关系抽取模型,相比于知识蒸馏等方法学习数据集相关的知识,语言知识能够突破数据集的限制,有效地提高模型的泛化能力。
2 中文关系抽取
本节介绍中文关系抽取的任务定义和中文关系抽取任务的基准模型。
2.1 任务定义
中文关系抽取一般被定义成分类问题,根据输入的文本和其中包含的实体对,对实体对之间的语义关系进行分类。将输入的文本表示为字符序列s=c1,…,cT,其中T表示字符序列的长度。字符序列中包含两个实体,将其表示为头实体ehead和尾实体etail。中文关系抽取任务的目的是根据字符序列s,提取出头实体ehead和尾实体etail之间的语义关系r∈R,其中R表示关系类型的集合。
2.2 基准模型
本文使用的基准模型是基于循环神经网络的中文关系抽取模型,如图2所示,包括嵌入层、编码层和分类层。
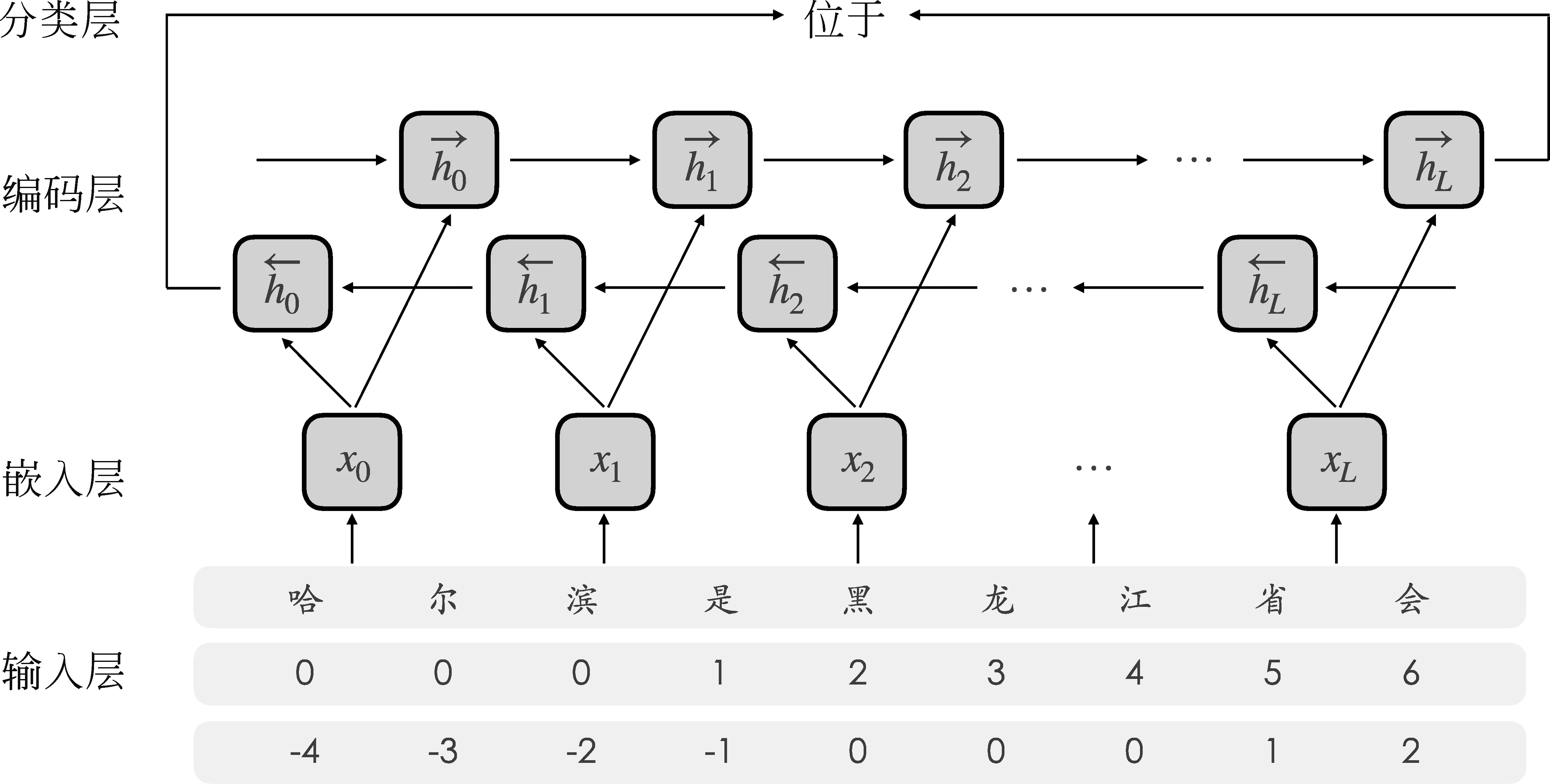
图2 基于LSTM的中文关系抽取模型
嵌入层:首先,将字符序列映射到特征空间,得到每一个字符对应的向量表示。
(1)

(2)

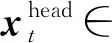
(5)
编码层:编码层使用双向的LSTM(Long Short-Term Memory)[26]网络作为编码器,接收来自嵌入层的字符序列的特征表示,计算全局的上下文相关特征。每个方向的LSTM网络根据上个时间步的输出特征和当前时间步的输入来计算当前时间步的输出特征。
(6)
(7)

(8)
分类层:分类层在获得编码层的特征后,首先将其映射到关系特征空间,然后使用Softmax方法获得对应关系集合R中关系类别r的概率分布。
P(r|s,ehead,etail)=Softmax(Woh+bo)
(9)
其中,P(r|s,ehead,etail)表示抽取得到的关系类别的概率分布,Wo和bo是分类层的训练参数。最后,使用交叉熵函计算中文关系抽取模型的目标函数Lre。
Lre=-log(P(r|s,ehead,etail))
(10)
3 基于语言模型增强的中文关系抽取方法
本节介绍本文所提出的基于语言模型增强的中文关系抽取方法,包括双向语言模型和语言模型增强两个部分。首先介绍在基准模型的结构之上构造双向语言模型,其次介绍以预训练语言模型对双向语言模型进行增强。
3.1 双向语言模型
为了学习预训练语言模型中包含的语言知识,首先在基于循环神经网络的基准关系抽取模型的基础上构造一个双向语言模型。
以前向语言模型为例,根据前t-1个字符来预测第t个字符的概率分布。基于多任务学习的结构,双向语言模型和中文关系抽取模型共享嵌入层和编码层的参数。如图3左半部分所示, 语言模型层对LSTM网络的输出进行非线性特征映射,然后计算下个字符的概率分布。

图3 基于语言模型增强的中文关系抽取方法

3.2 语言模型增强
在中文关系抽取模型的基础上训练双向语言模型的目的是通过双向语言模型来拟合预训练语言模型,从而学习预训练语言模型中包含的语言知识。基于多任务学习的参数共享机制,通过双向语言模型学习到的语言知识可以对中文关系抽取模型进行增强。
学习预训练语言模型中包含的语言知识的本质,是使中文关系抽取模型学习更多样的关系表达,增加中文关系抽取模型的泛化能力。比如,当我们对“哈尔滨是黑龙江省会”中的“是”进行遮蔽,得到“哈尔滨[MASK]黑龙江省会”。然后使用预训练语言模型进行预测时,预测结果包含“是”“为”“,”等,用预测结果替换回遮蔽字符,可以得到“哈尔滨是黑龙江省会”“哈尔滨为黑龙江省会”和“哈尔滨,黑龙江省会”等多种组合。这些组合均表达了“哈尔滨”和“黑龙江”两个实体之间的“位于”关系,但是后两种表达是数据集内不包含的。基于语言模型增强的中文关系抽取方法可以看作是一种自动的数据增强(Data Augmentation)[27]方法,通过预训练语言模型中的语言知识来对数据集进行数据增强,对每一条数据,生成多种不同但表达同样关系语义的文本,使中文关系抽取模型在训练过程中学习到多样的关系表达。
本文使用的预训练语言模型是BERT-wwm[28]。BERT-wwm是一个12层深度的Transformers模型,在大规模的中文语料上进行遮蔽语言模型的训练,对输入文本进行部分字符的遮蔽,替换为固定的遮蔽符,通过被遮蔽字符的上下文信息来预测被遮蔽的字符。同时在训练的过程中,通过全词遮蔽(Whole-Word-Mask)的处理,在基于字符序列的预训练语言模型的训练中融合单词信息。
对已经预训练好的BERT-wwm模型,输入包含遮蔽符的字符序列,可以得到被遮蔽的字符预测结果,表示为概率分布。如图3右半部分所示,对于字符序列“哈尔滨是黑龙江省会”中的“是”进行遮蔽,替换为遮蔽符“[MASK]”,输入到BERT-wwm模型中。通过BERT-wwm的预测,被遮蔽的字符可能为“是”“为”“,”等,括号内是其预测的概率值。BERT-wwm对该遮蔽字符的预测结果是其包含的语言知识的具体表现,本质上是其对大规模训练语料的统计结果。我们将BERT-wwm对字符ct的预测形式化为PBERT(ct)。
PBERT(ct)=BERT(…,ct-1,mask,ct+1,…)
(15)
其中,mask表示遮蔽符[MASK]。为了使双向语言模型拟合BERT-wwm,如图3所示,将BERT-wwm对字符ct的预测分布作为双向语言模型的训练标签。我们通过KL散度(Kullback-Leibler divergence)来拟合双向语言模型和预训练语言模型对字符预测的概率分布,作为双向语言模型的目标函数。
(16)
(17)

(18)
其中,λ表示双向语言模型目标函数的权重,通过调整λ来平衡多任务学习结构中两部分模型的训练过程。
4 实验分析
本节通过实验验证证明基于语言模型增强的中文关系抽取方法的效果。首先在4.1节中描述实验中使用的数据集和评估指标。在4.2节对实验环境设置进行描述,包括方法中使用的工具和重要的超参数。然后在4.3节中,与多种基线方法进行多维度的比较。最后在4.4节,对本文提出的方法进行消融实验。
4.1 实验数据与评价指标
本文使用三个中文关系抽取数据集作为实验数据,分别是SanWen(1)https://github.com/lancopku/Chinese-Literature-NER-RE-Dataset、ACE2005(2)https://catalog.ldc.upenn.edu/LDC2006T06和ACE2004(3)https://catalog.ldc.upenn.edu/LDC2005T09。其中,SanWen是根据文学数据构建的,一共包含10类关系,并按照一定比例被划分为训练集、验证集和测试集。ACE2005和ACE2004数据集是新闻领域的关系抽取数据集,分别包含18类和19类关系,对于ACE2005和ACE2004数据集的划分,我们和Li等人[15]的研究工作保持一致,我们随机选取其75%的数据训练,使用剩下的25%的数据进行验证。数据集的统计信息如表1所示。

表1 实验数据集统计
为衡量不同中文关系抽取方法在上述数据集上的效果,我们使用分类任务中的F1(%)值和AUC(%)值作为评价指标。
4.2 实验设置
本文使用PyTorch深度学习库来实现本文的方法,为了与相关工作进行合理的比较,实验环境中涉及的大部分超参数都和Li等人[15]研究工作中使用的保持一致。我们使用Li等人[15]工作中预训练的100维字符向量对嵌入层参数进行初始化,相对位置向量的维度设为10维,在训练开始时进行随机初始化,两者在训练过程中进行更新。编码层使用双向LSTM,每个方向的LSTM的隐藏层维度设为200。同时,我们对嵌入层和编码器的输出特征分别进行Dropout,比例为0.5。
在语言模型增强的部分,我们使用在中文维基数据上进行预训练的BERT-wwm模型。预训练语言模型的输出结果是所有字符上的概率预测,其中只有部分字符是有意义的预测结果,其余则没有意义。为了减少无意义字符对结果的影响,需要对预训练语言模型的预测结果进行截断,每个字符的预测结果按输出值的大小取前100个预测结果,根据截断后的输出值重新计算这100个字符的概率分布,作为双向语言模型的标签。
对于模型的训练,我们使用Adam优化器[29],学习率设为0.000 5。在训练过程中,双向语言模型目标函数的权重λ设为0.01。重要超参数的值如表2所示。
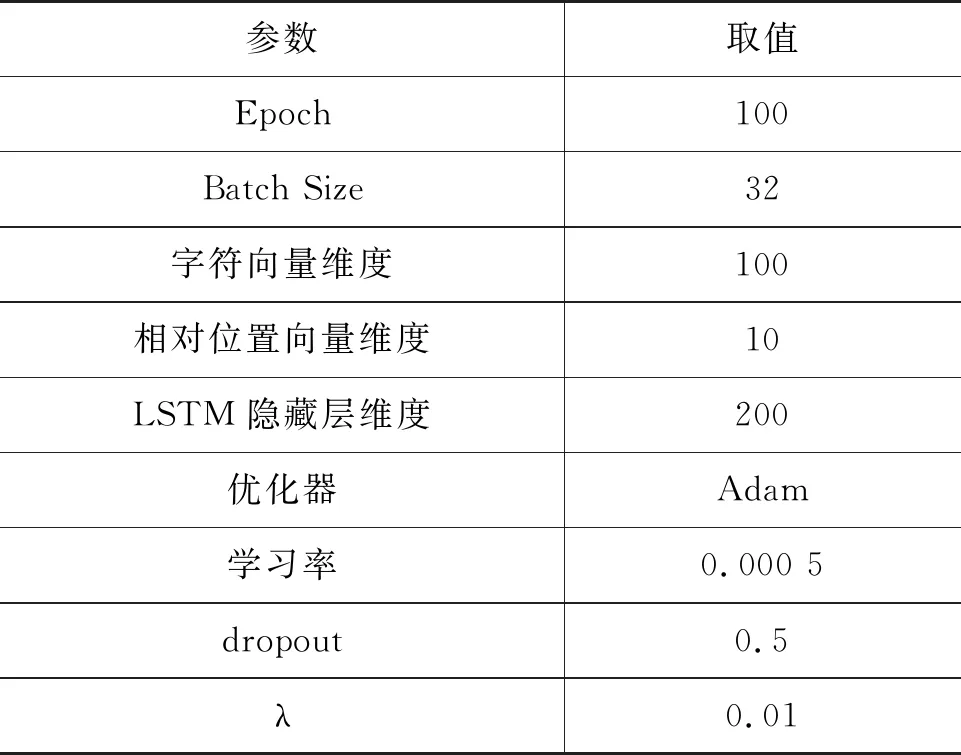
表2 实验相关超参数
4.3 实验结果
本节将基于语言模型增强的中文关系抽取方法与多个基线模型进行对比实验,证明基于语言模型增强的方法能够有效降低预训练语言模型的开销。在4.3.1节,与非预训练模型进行对比;在4.3.2节,与预训练模型在关系抽取任务指标和模型参数量上进行对比。
4.3.1 与非预训练模型的对比结果
首先,与非预训练的模型做对比实验,首先实现了两种经典的关系抽取模型,分别是Zeng等人[20]提出的基于CNN的关系抽取模型和Zhang等人[9]提出的基于LSTM的关系抽取模型。同时,我们也和两种目前流行的基于词典的中文关系抽取方法进行对比,分别是Li等人[15]提出的MG-Lattice模型和Zeng等人[16]提出的Flat-Lattice模型。其中,考虑到ACE2005数据集随机划分可能造成的数据分布不一致,我们使用MG-Lattice方法公开的源代码进行实验,获得实验结果。Flat-Lattice方法则使用其论文中给出的结果进行对比。与非预训练模型的对比结果如表3所示。

表3 与非预训练模型的对比结果 (单位: %)
(1) 首先,我们可以观察到,基于语言模型增强的中文关系抽取方法,在表中表示为“LSTM+语言模型增强”,在三个数据集的F1值和AUC值均达到了最高。在SanWen数据集上,与目前最好的基于词典的中文关系抽取模型Flat-Lattice相比,F1值提高了2.53%,AUC值提高了6.74%,在其他数据集上也有相应的提升。
(2) LSTM+语言模型增强与LSTM模型相比,仅增加了以预训练模型的预测结果作为训练标签的双向语言模型。对比LSTM模型,LSTM+语言模型增强在三个数据集上的提升即是语言模型增强的效果。在SanWen数据集上,F1值提升了6.2%,AUC值提升了8.28%。证明了预训练语言模型的语言知识确实能够对中文关系抽取模型进行增强。
(3) 最后,我们通过模型的预测结果进行示例分析,我们选择LSTM方法和MG-Lattice方法与本文所提出的基于语言模型增强的方法进行对比,示例结果如表4所示。我们在SanWen数据集中的测试集内选择了两条文本作为示例,从预测结果中可以看出,LSTM方法与MG-Lattice方法预测出了错误的关系类型,而我们所提出的方法可以预测出正确的关系类型。对于第二个示例,“当包谷杆上长出第一个包谷棒时”这条文本中,如果实体1是“包谷杆”,与实体2“包谷棒”的关系则是LSTM方法与MG-Lattice方法预测的“部分整体”。但实体1是“包谷杆上”,与实体2“包谷棒”的关系是“位于”。该示例结果证明本文所提出的基于语言模型增强的方法可以准确地根据实体的细微差别识别出正确的关系类型,具有更强的关系抽取能力。

表4 模型预测结果对比
4.3.2 与预训练模型的对比结果
为了与基于预训练语言模型的方法进行对比,我们实现了Livio等人[30]所提出的基于预训练语言模型的关系抽取方法,使用BERT-wwm预训练模型。同时,为了比较不同参数规模下预训练语言模型的效果,我们分别取BERT-wwm的前6层的参数和前3层的参数进行实验。同时,我们也与Tang等人[23]提出的针对预训练语言模型的知识蒸馏方法进行对比。除了比较三个数据集上的分类指标,同时也比较模型的参数规模,表中表示为Parameter,含义为模型的参数量。与预训练模型的对比结果如表5所示。

表5 与预训练模型的对比结果 (单位: %)
(1) 我们可以从表中观察到,BERT-wwm在三个数据集上均达到最好,LSTM+语言模型增强与BERT-wwm模型在F1值和AUC值上仍然有差距。但BERT-wwm的参数规模非常庞大,达到了102.27M(M表示百万)。我们以BERT-wwm作为基准(表示为100%),计算其他方法与其在性能和参数规模上的百分比。本文提出的基于语言模型增强的方法在三个数据集上的平均性能都可以达到BERT-wwm的95%,而参数规模仅为1.29M,为BERT-wwm的1.3%。实验证明了基于语言模型增强的中文关系抽取方法可以在达到相似性能的同时大幅降低预训练模型的开销。
(2) BERT-wwm (6层)和BERT-wwm (3层)分别仅使用BERT-wwm的部分参数。可以观察到,随着层数的降低,基于预训练语言模型的方法在三个数据集上的指标也随之降低。在使用BERT-wwm (3层)进行实验时,LSTM+语言模型增强的方法在三个数据集上的指标上已经超过BERT-wwm (3层)方法。但BERT-wwm (3层)的参数规模仍然是LSTM+语言模型增强方法的30倍。证明相比于使用小规模的预训练语言模型,基于语言模型增强的中文关系抽取方法是一个更优的选择。
(3) 最后,我们与基于知识蒸馏的方法(表中表示为LSTM+知识蒸馏)相比,我们的方法在三个数据集上的指标均超过基于知识蒸馏的方法。实验证明了相比于数据集内的知识,语言知识对于中文关系抽取任务的提升更大。
4.4 消融实验
本节对基于语言模型增强的中文关系抽取方法进行消融实验,对方法中的模块进行消融,分析各个模块带来的性能提升。消融实验的结果如表6所示。首先,我们对来自预训练语言模型的增强进行剥离,仅进行标准的双向语言模型训练,以下个字符作为标签,在表中表示为LSTM+语言模型。可以观察到,在剥离了预训练语言模型的预测结果时,三个数据集的指标均有所下降,在SanWen数据集上,F1值下降3.21%,AUC值下降3.74%。下降的结果即是来自预训练语言模型的语言知识对中文关系抽取任务的增强结果。

表6 消融实验结果 (单位: %)
之后,我们继续剥离掉方法中基于多任务学习结构中的语言模型的部分,方法退化为标准的基于LSTM的中文关系抽取方法。三个数据集的指标继续下降,下降的结果为基于多任务学习的语言模型带来的提升,在SanWen数据集上,F1值下降2.99%,在AUC值上下降4.54%。在消融实验中,我们分别对基于语言模型增强的中文关系抽取方法中的两个核心模块进行消融,验证了每个模块对中文关系抽取任务带来的提升效果。
5 总结
针对预训练模型参数量多开销大的问题,本文提出基于语言模型增强的中文关系抽取任务,采用多任务学习结构,在中文关系抽取模型的基础上训练双向语言模型,以训练语言模型的预测结果作为训练标签,通过拟合预训练语言模型来学习预训练语言模型中包含的语言知识。预训练语言模型中的语言知识可以对训练数据进行自动的数据增强,使中文关系抽取模型在训练过程中学习到多样化的关系表达,提高中文关系抽取方法的性能和泛化能力。
未来计划对预训练语言模型中的语言知识进行更细粒度的蒸馏,进一步提升语言模型增强方法的性能。
猜你喜欢
出版人(2022年11期)2022-11-15
电脑爱好者(2022年15期)2022-05-30
文苑(2020年4期)2020-05-30
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
小学生作文(中高年级适用)(2018年3期)2018-04-18
华北电力大学学报(社会科学版)(2016年4期)2016-12-01
通信电源技术(2016年5期)2016-03-22
少儿科学周刊·少年版(2015年4期)2015-07-07
