
基于YOLOv5s的头盔和反光背心实时检测算法研究
2023-10-23 02:58:38徐春鸽
计算机时代 2023年10期
徐春鸽
(广东培正学院数字科学与计算机学院,广东 广州 510830)
0 引言
智能施工现场[1],目标检测技术在智能监控系统中起着至关重要的作用,其中安全帽和反光背心检测成为研究热点[2]。目前,安全帽和反光背心检测已经从传统的机器学习方法转向深度学习方法。
许多学者提出将YOLO 算法应用于头盔和反光背心的实时检测。目前,利用YOLO 算法对头盔和反光背心进行检测时,精度还无法满足实时性要求,容易出现漏检,同时存在精度和速度无法兼顾等问题。
为了解决这些问题,本文提出了一种头盔和反光背心的检测模型,选择YOLOv5s 网络模型作为主体,采用GhostNet 模块代替原始的卷积Conv,以及采用C3Ghost 替换C3 模块,这样可以极大减少冗余,提高检测速度;用CAFAFE 模块替代原上采样Upsample,来提高模型的检测精度。
1 融入CARAFE、GhostNet 模块的YOLOv5s算法
1.1 原始YOLOv5s算法
YOLOv5 是由Ultralytics 提出的,其在YOLOv4基础上进行了改进。YOLOv5吸收了先前版本和其他网络(例如CSPNet 和PANet[3-4])的优点,并在准确性和速度之间取得了良好的效果。YOLOv5利用深度倍数和宽度倍数来控制网络的宽度和深度。YOLOv5s是这个系列中深度最小,特征图宽度最小的网络,其他网络版本也在这个基础上不断深化和拓宽。YOLOv5s 主要由以下几个部分构成:①输入(马赛克数据增强、自适应anchorbox计算和自适应图像缩放);②骨干网络(CSPNet和Focus模块);③颈部网络(FPN和PANet);④检测端(CIoU损失函数)。如图1所示。
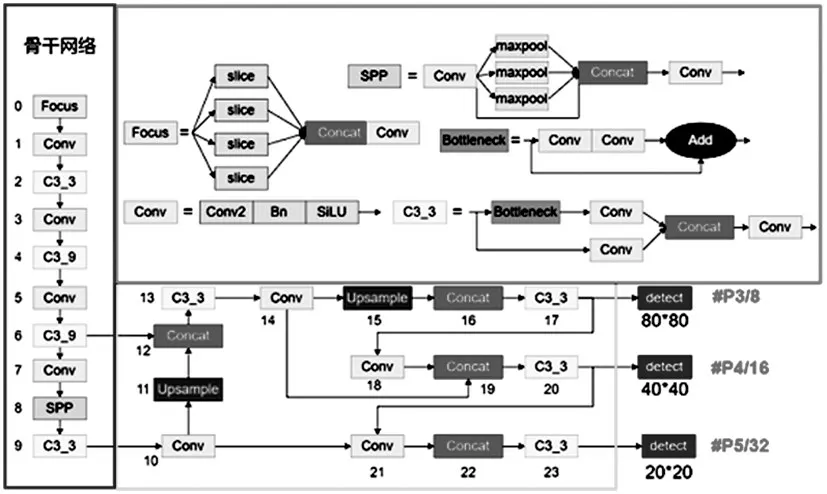
图1 YOLOv5s结构图
1.2 基于CARAFE算子的特征重组上采样
YOLOv5s中有很多上采样方法,其中最近邻法和双线性插值法通过现有像素的空间关系进行插值,实现简单,但前者会改变图像元素值的几何连续性,后者会导致边缘被平滑,都不能有效地保持特征。虽然反卷积可以通过参数学习来减少特征失真,但不可避免地引入了大量的参数。为了在上采样期间保持特征而不引起参数峰值,本文使用CARAFE 算子进行上采样。轻量级上采样算子CARAFE[5]结构如图2所示。

图2 CARAFE结构图
CARAFE 由两个模块组成即采样核预测模块和内容感知特征重组模块。采样核预测模块主要用于生成重组核,假设输入特征映射大小为H×W×C,采样多重度为σ(=2)。首先,使用1*1卷积层将输入特征通道从C压缩到Cm,以减少参数数量和计算成本。然后,执行内容编码以生成重组内核。这是通过使用大小为kencoder×kencoder的卷积层来预测压缩特征图的采样内核,以获得输出通道数为σ2×的采样内核。设置kup=5和kencoder=3作为性能和效率之间的折衷。将其在空间维度上展开,可以得到一个大小为σH×σW×kup×kup的重组核。最后,使用Softmax 函数在空间维度上对生成的大小为kup×kup的每个重组核进行归一化操作,归一化操作之后两核之间相加小于1。内容感知特征重组模块先将不同位置映射到输入特征上,并且在中心位置处取一块kup大小的区域,然后与该处的上采样做乘积得到输出值。对于一个目标位置l'和对应的以l=(i,j)为中心的正方形区域N(χl,kup),计算方法如下:
其中,χ'表示新的特征映射,wl'表示重组内核,r=[kup/2]。
1.3 融入GhostNet模块
GhostNet 是一种神经网络架构,旨在平衡高精度和低计算成本。GhostNet[6]的出现解决传统深度神经网络模型过于复杂而无法在资源受限的设备上运行的缺点。本文对YOLOv5s 网络进行改进,将原来的C3 模块替换为来自GhostNet 的C3Ghost 模块,该模块可以通过在多个卷积层之间共享权重来降低模型的计算复杂性。因此,采用GhostNet 可以在保持准确率的同时具有更少的参数。并且本文还将CBS 模块替换为Ghost Conv 模块,该模块可以减少模型参数量。图3描述了Ghost模块的操作。
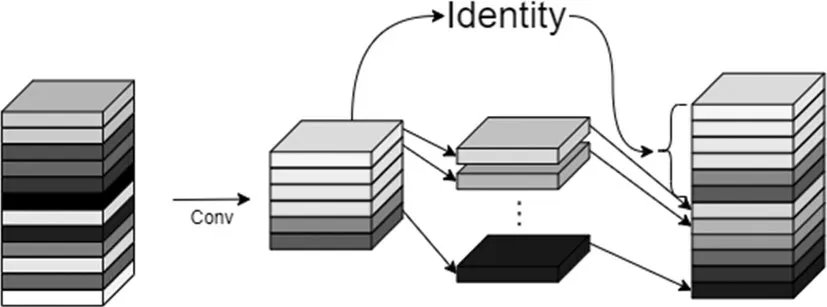
图3 GhostNet卷积过程图
与传统的卷积块不同,GhostConv 分两步对图像进行特征图提取。第一步还是用普通的卷积计算,此时得到的特征图通道较少。第二步使用廉价操作(depthwise conv)再次进行特征提取,得到更多的特征图,然后使用concat两次得到新的特征图,形成新的输出。
从图3 可以看出,廉价操作将在每个通道上执行廉价计算,以增强特征获取并增加通道数量。与传统的卷积计算相比,这种模式需要的计算量要少得多。
1.4 改进算法YOLOv5s-GC
改进的YOLOv5s的网络结结构,主要在骨干网络和颈部网络进行改进。骨干网络和部分颈部网络采用GhostConv 和C3Ghost 模块组成,以此降低模型的复杂性,提高模型的检测效率。颈部网络的上采样Upsample 是用CAFAFE 模块所替代,CARAFE 模块是由内核预测模块(KPM)和内容感知重组模块(CaRM)两部分组成,其功能是通过上采样核预测和特征重组。相当于是用内核预测模块(KPM)和内容感知重组模块(CaRM)来替代其Upsample 上采样模块中的FPN 和PAN 结构,来提高模型的检测精度。本文将融入GhostNet模块、CAFAFE模块的YOLOv5s算法称为YOLOv5s-GhostNet-CAFAFE 算法(简称YOLOv5s-GC算法),其算法结构如图4所示。
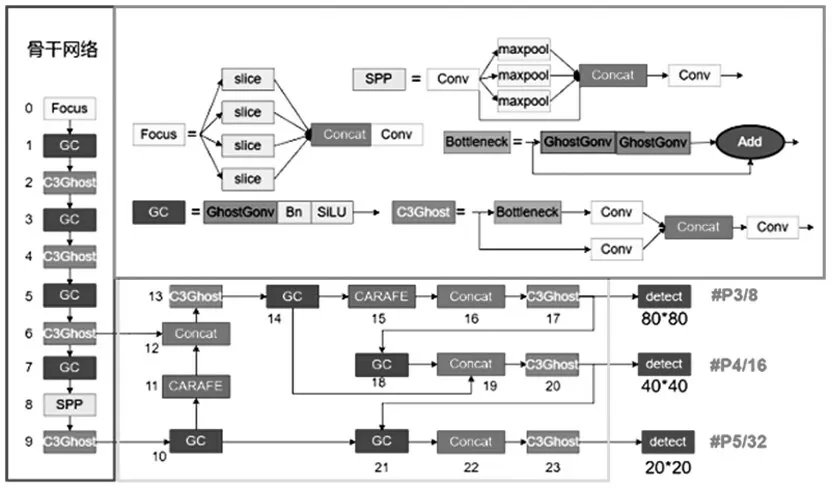
图4 YOLOv5s-GC结构图
2 实验与结果分析
2.1 实验环境
实验的电脑设备使用了NVIDIA GeForce RTX 3060,显卡类型为GDDR6,显存容量为16 GB。在虚拟环境使用Anaconda 3,IDE 环境使用了PyCharm Community,开源框架使用了CUDA11.1 对应的PyTorch,开发环境为Python 3.9。
2.2 数据集介绍与分析
本文采用了Kaggle[7]的铁路工人安全帽和反光衣数据集,数据集有三个类别,涉及人、安全帽和反光衣,数据集总数量为1898张。数据集中的大部分数据为小目标。
2.3 模型评价指标
为了验证改进算法的有效性,本文采用精度率(P)、召回率(R)和平均精度(mAP)这三个评价指标对模型进行评估。在目标检测中,mAP 是一个关键的综合指标,它能够对模型检测的准确性进行全面评估。精确率P和召回率R可以表示如下:
其中,TP、FP和FN分别表示真阳性、假阳性和假阴性。要计算mAP,必须计算出每个类的平均精度(AP),该值可以通过全点插值方法计算,并绘制精确率和召回率曲线。此外,通过对每个类取AP 的平均值来计算mAP。公式可以表示如下:
其中,i 是指标值,P 和R 分别表示精确率和召回率,N数据的类别数,APi是第i 类的平均精度。此外,本文还引入了每秒帧数(FPS)和模型的参数大小作为模型性能的评价指标之一。速度越高,就越能满足安全帽和反光衣实时检测的需求。
2.4 网络训练
在对模型进行训练时,需要对超参数进行设置,超参数的好坏直接影响模型训练的结果,具体设置的参数如表1所示。

表1 网络训练参数设置取值
2.5 实验结果与对比分析
2.5.1 YOLOv5s-GC和YOLOv5s算法P、R对比
为了更好地理解两种算法之间的性能差异,对训练过程中P、R 进行打印。具体来说,对YOLOv5s-GC算法和原YOLOv5s 算法训练过程中P 和R 的变化进行打印,对比如图5所示。
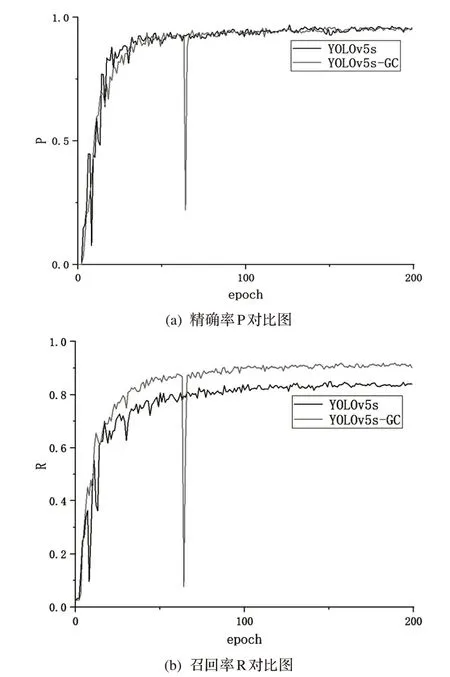
图5 YOLOv5s-GC和YOLOv5s算法P、R对比图
图5a 可以看出,YOLOv5s-GC 和YOLOv5s 算法P 精确率相比,其收敛速度和精确率的值相似。图5b可以看出,YOLOv5s-GC 和YOLOv5s算法R召回率相比,其收敛速度和召回率的值更高更快。因此,YOLOv5s-GC 和YOLOv5s 算法相比,其实际检测安全帽和反光衣佩戴情况的准确率更高。
2.5.2 消融实验
为了深入探究不同的改进方案对YOLOv5 算法性能的影响而设计了三组实验,以研究各种不同的改进方案。其中“√”表示在模型中引入了改进方法,“×”表示在模型中没有引入改进方法。其消融实验的性能对比表如表2所示。
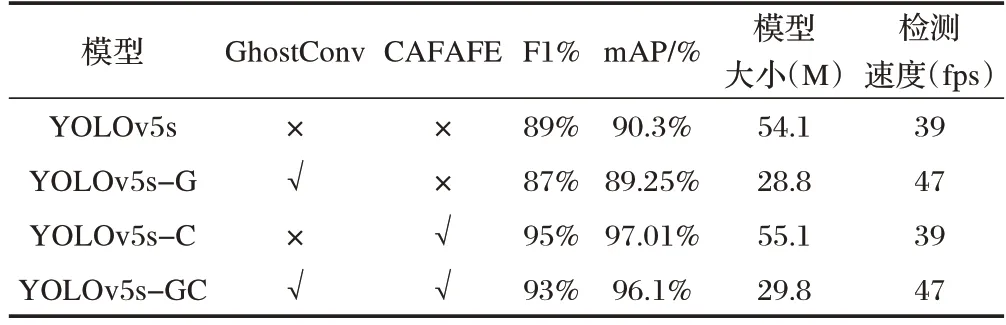
表2 消融实验性能对比
从表2 可以看出,YOLOv5s-G 相比YOLOv5s 采用GhostNet 模块代替原始的卷积Conv,以及采用C3Ghost 替换C3模块,其F1 和mAP 略微有所下降,但模型大小减少了一半,检测速度提升了8fps,可以证明采用GhostNet 模块可以降低模型的复杂性,提高模型的检测效率。YOLOv5s-C 相比YOLOv5s 采用CAFAFE 模块替代原上采样Upsample,其F1 提升了6%,mAP 提升了6.71%,模型大小略微有所增加,检测速度持平。YOLOv5s-GC 融入GhostNet 模块、CAFAFE 模块,其F1 提升了4%,mAP 提升了5.8%,模型大小减少了24.3M,检测速度提升了8fps。实验结果表明,采用CARAFE 方法进行改进,可以提高精度。采用GhostNet 模块方法进行改进,可以降低模型的复杂性,提高模型的检测效率。
为了看出模型对三类的检测效果,分别打印出YOLOv5s 和YOLOv5s-GC 在测试集上混淆矩阵图,如图6(a)YOLOv5s 混淆矩阵和图6(b)YOLOv5s-GC混淆矩阵。
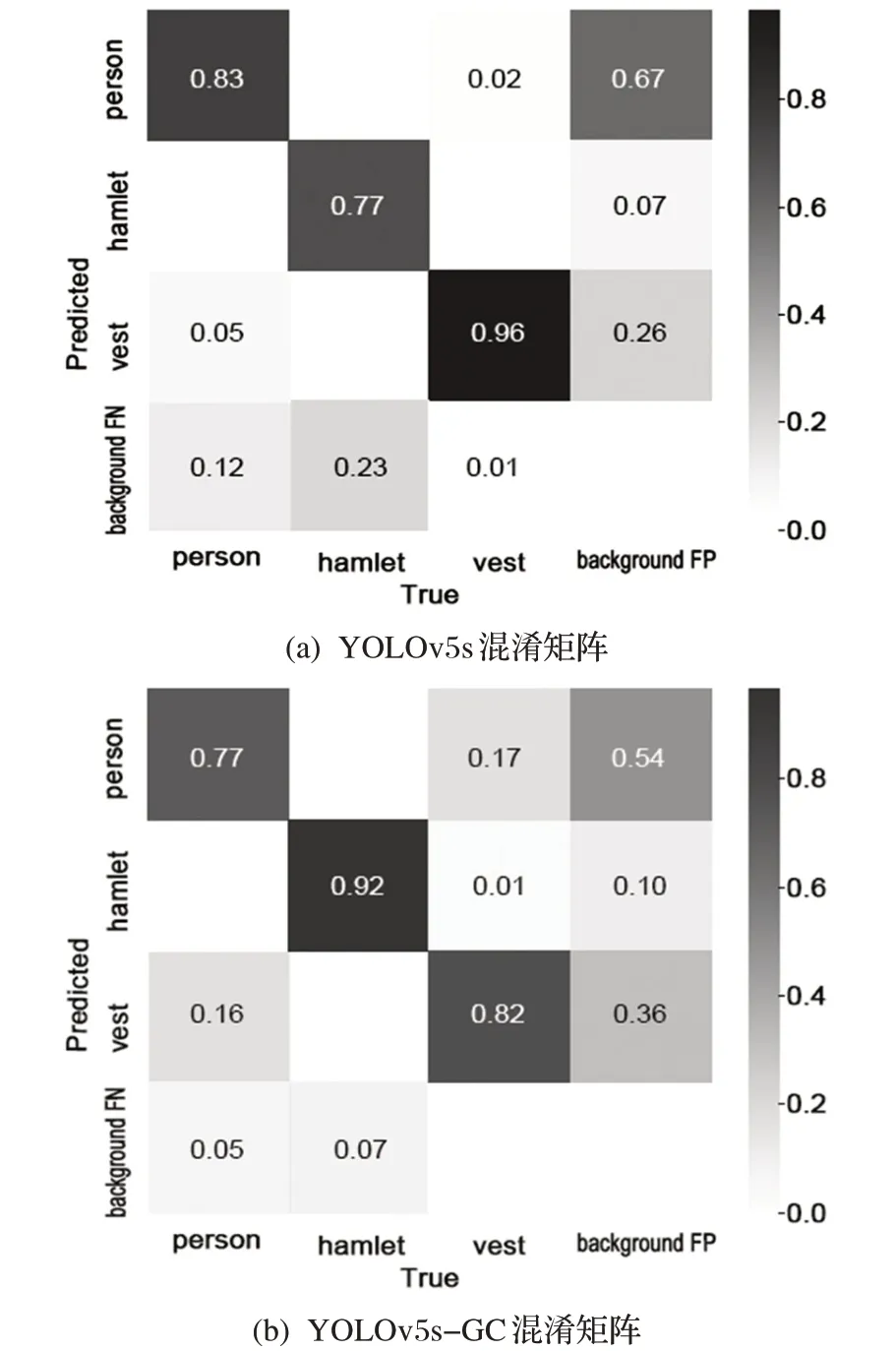
图6 YOLOv5s-GC和YOLOv5s混淆矩阵对比图
混淆矩阵图对角线上深色方块代表了预测正确类别的比例,图6(b)可以看出YOLOv5s-GC 识别为hamlet 的概率为92%,图6(a)可以看出YOLOv5s 识别为hamlet 的概率为77%,可以说明本文改进算法YOLOv5s-GC 相比YOLOv5s 识别正确率更高,效果更好。
2.6 检测结果对比
通过前文可知,YOLOv5s-GC 算法精确率、效率较高,且更易于部署,更满足工业检测要求。为了更加直观的看出效果,将本文改进算法YOLOv5s-GC 与原YOLOv5s 对实际图片进行测试,得到检测结果如图7、图8 所示。其中图7 为YOLOv5s 检测图,图8 为YOLOv5s-GC检测图。

图7 为YOLOv5s检测图

图8 YOLOv5s-GC检测图
通过检测结果图8(a)、图8(b)和图7(a)、图7(b)对比表明,YOLOv5s-GC 算法相比YOLOv5s 算法,检测精度有所提升,对实际场景的检测效果较好。
3 结论
由于原YOLOv5s算法存在模型复杂、准确率低等局限性,本文提出了一种基于YOLOv5s 的改进算法YOLOv5s-GC。该算法首先采用GhostConv和C3Ghost模块替换Conv 卷积,以此降低模型的复杂性,提高模型的检测效率。其次将颈部网络的上采样Upsample用CAFAFE 模块替代,其功能为通过上采样核预测和特征重组。即用内核预测模块(KPM)和内容感知重组模块(CaRM)来替代其Upsample 上采样模块中的FPN 和PAN 结构,以提高模型的检测精度。实验结果表明,本文提出的YOLOv5s-GC 算法相比原YOLOv5s 算法,其F1、mAP、检测速度均有所提升,且模型大小减少了一半,更利于模型的实时检测和部署,更适合安全帽和反光背心佩戴的实时检测。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年11期)2018-08-04 03:25:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
电视技术(2014年19期)2014-03-11 15:38:20
河南科技(2014年14期)2014-02-27 14:11:53
