
基于改进YOLOv5的盲人阅读辅助系统*
2023-10-23 02:58:34蔡玉树毛林聪陶雨松
计算机时代 2023年10期
蔡玉树,卢 仕,毛林聪,陶雨松
(湖北大学微电子学院,湖北 武汉 430061)
0 引言
作为世界上盲人数量最多的国家,我国盲人的阅读问题一直备受关注。盲用读物出版受成本与价格的限制,每年仅有10种出版物,种类较为匮乏,且盲文图书馆数量稀少,馆藏读物十分有限,这些导致了盲人用户的阅读需求无法得到满足[1]。
近年来,随着计算机软硬件技术快速发展,图像识别与可携带式智能设备取得了较大进步,继而盲人阅读辅助产品及相关技术不断被提出。文献[2]设计了基于卷积神经网络的盲人无障碍阅读系统,可通过手势控制文本识别区域,将识别到的内容进行语音输出,但图像输入的操作流程较为繁琐,系统交互方式对盲人并不友好;文献[3]运用嵌入式平台树莓派4B,以YOLOv5 为目标检测算法设计了盲人语音助手,在文字识别前进行灰度及缩放等操作,有效提高了印刷文本识别的准确率,但是对于书本版面的捕获存在不稳定性,无法保障盲人用户的阅读体验。其目标检测采用了较为先进的单阶段目标检测网络YOLOv5,该网络基于前四个版本的持续改进,已经具备了良好的目标检测性能[4]。YOLOv5s作为YOLOv5 五种基础模型中最轻量化的模型,在COCO2017 数据集上mAP@0.5 为56.8%。该模型部署灵活、检测准确,在实时对象检测中得到了广泛应用,因此本文采用YOLOv5s作为目标检测基础网络。
针对盲人用户阅读纸质图书时难以校准书本位置的问题,本文采用树莓派3B搭建了具备书本校准功能的智能阅读辅助系统,通过YOLOv5s实现了书本定位与位置建议;考虑嵌入式平台下检测速度及可靠性等问题,在YOLOv5s 主干网络中嵌入ECA 注意力模块增强检测网络的特征融合能力,在颈部网络采用GSconv实现轻量化设计,取得了检测精度与速度显著提升,保证了位置建议算法的可靠性,能够帮助盲人用户实现书本位置的有效校准。
1 系统总体设计
本文所设计的阅读辅助系统以视力障碍群体为服务对象,以桌面阅读为应用场景,具备书本校准、文字识别及语音交互等功能。系统整体设计框图如图1所示,主控平台的控制核心为树莓派3B,借助摄像头捕获桌面图像,通过改进的YOLOv5s目标检测网络实现准确快速的位置推理,有效反馈位置建议结果。语音模块由麦克风及扬声器组成,作为盲人用户的人机交互终端;云平台通过百度智能云的语音与视觉API构建[5],用于实现语音识别、语音合成及文字识别三种基础功能。
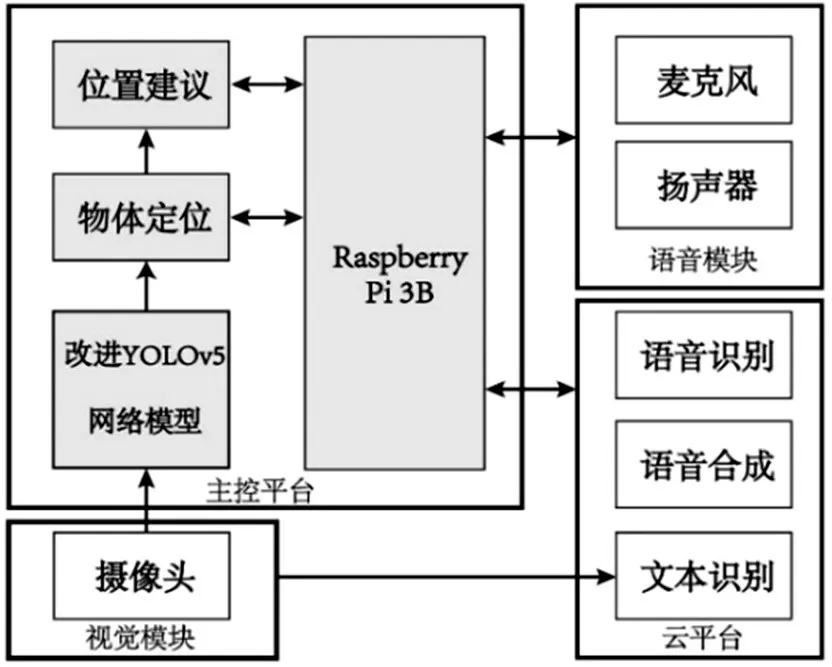
图1 系统设计框图
2 书本校准原理
2.1 物体定位系统
在物体定位系统中,深度学习方法采用大量数据训练模型,能提取更具鲁棒性的特征,克服了传统的计算机视觉易受视点变化及外界环境影响的缺点,在复杂环境下依旧表现出色,成为物体定位领域的热门方法之一[6]。本文选用的YOLOv5s 网络模型基于深度学习算法,对于输入图像该模型会框选出感兴趣目标,给出物品类别及选框边角的图像坐标。为实现桌面物体的精确定位,需要建立图像坐标与世界坐标间的映射关系矩阵,即完成相机参数的标定。本文采用DLT 算法[7]完成相机标定,其坐标变换图如图2 所示,OXYZ 为世界坐标系,Ocxyz 为相机坐标系,ouv 为图像坐标系,R为旋转矩阵,T为平移向量。
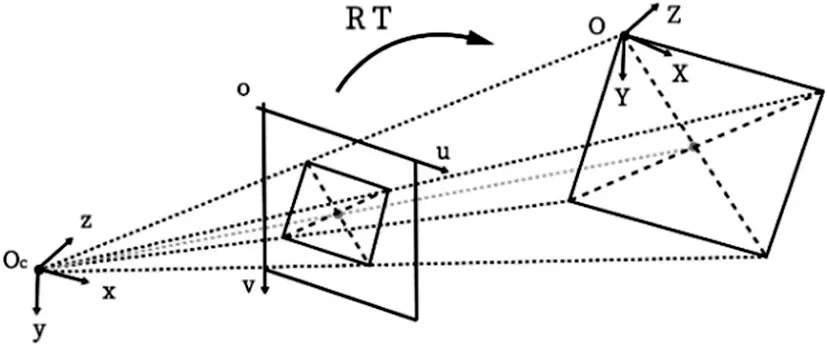
图2 坐标变换关系图
图像坐标系与世界坐标系存在不同尺度,需要考虑两者间的尺度变换,两坐标系的尺度系数λ 通过去质心点集确定,其定义式如下:
其中,、分别为图像坐标与世界坐标下已知的N个对应点的集合,Pcp、Pcw为对应点集的质心。通过去质心坐标可构造Hankle 矩阵H,对H 进行奇异值分解[8]得到矩阵U、S、V,结合尺度系数λ可得旋转矩阵R、平移向量T分别为:
2.2 位置建议算法
物体定位结果显然无法通过定量的方式反馈给盲人用户,区域划分法针对该问题提供了定性的解决方案[9]。本文位置建议算法以选区划分法为基础,根据书本的形貌特征进行了特定的区域划分,通过目标检测网络确定书本质心位置,计算其到达画面中心的位移量(Δx,Δy),根据位移量的正负与大小生成书本校准的定性建议,指导盲人用户校准书本位置,选区划分与检测示例如图3所示。书本校准的目标区域定义为有效区,如图3(a)中部的深色区域,当书本质心移入有效区后,校准任务即为完成,有效区其宽与高分别为:
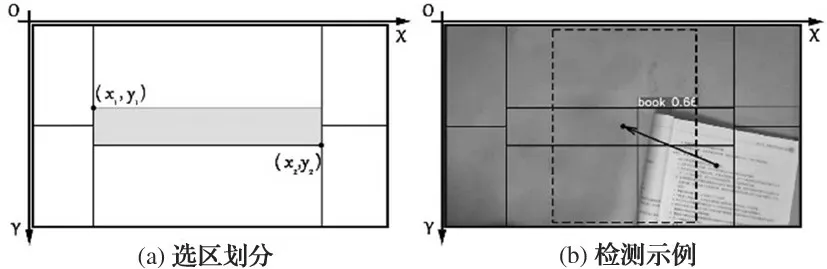
图3 选区划分与检测示例
其中,W为桌面可视区域的实际宽度,Wp与Hp分别为书页的实际宽度与高度;S为有效因子,描述了文字区域对书页的占有情况,其定义式如下:
其中,Hs为版心高度,Hp为书页高度。对于待阅读书籍,其单张版面由版心与空白两部分组成,通过测量版心高度与书页高度可得到有效因子S。
3 YOLOv5s算法的改进
3.1 GSconv卷积
在通过增加模型参数提升网络非线性表达能力的同时[10],计算能耗会显著增加。在网络模型性能优化中有必要采取轻量化设计以降低计算成本,这一点对于计算资源有限的嵌入式平台尤为重要。深度可分离卷积(DSC)[11]通过减少模型参数与浮点运算降低计算成本,但较标准卷积(SC)存在丢失大量通道信息的缺点,精度较低。GSConv[12]较DSC 提升了精度,同时降低了网络计算量,其结构如图4 所示。该结构将SC 与DSC 结合,利用concat 将SC 的输出信息与DSC 的输出信息进行顺序拼接,再借助均匀混合策略Shuffle 将拼接特征图中顺序拼接的两种信息完全均匀地混合,实现不同通道上特征信息的均匀交换。
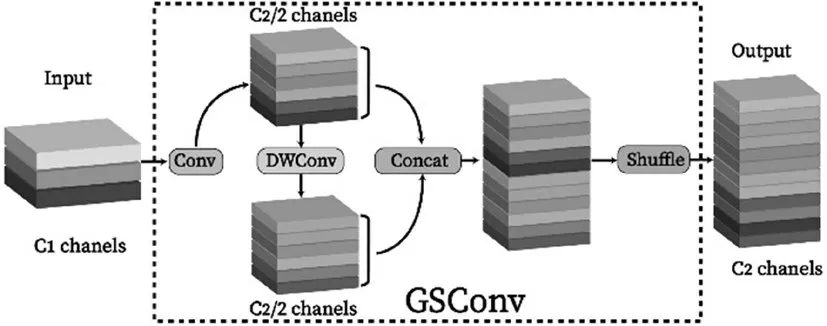
图4 GSconv结构
3.2 注意力机制
引入通道注意力机制常用于增强网络模型的非线性表达能力[13],其即插即用的特点使得注意力机制在深度学习任务中得到了广泛应用。ECA 模块是目前最先进的注意力模块之一,其结构如图5所示,该模块首先对各个通道进行全局平均池化,再通过一维卷积实现相邻通道交互信息的局部捕获,最后用Sigmond 函数对各组特征通道生成不同的权重,实现注意力的按组分配,在增加少量模型复杂度的同时带来显著的性能提升。
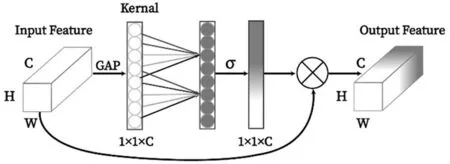
图5 ECA模块
依据网络结构确定模块插入位置对于注意力机制的有效性极为重要[14]。改进的YOLOv5网络结构如图6 所示,ECA 模块被嵌入在了主干网络向颈部传递特征图的部位,即三个连接分支P1、P2、P3 的起点处,网络颈部的标准卷积通过轻量化的GSConv 替换,以期降低模型复杂度。
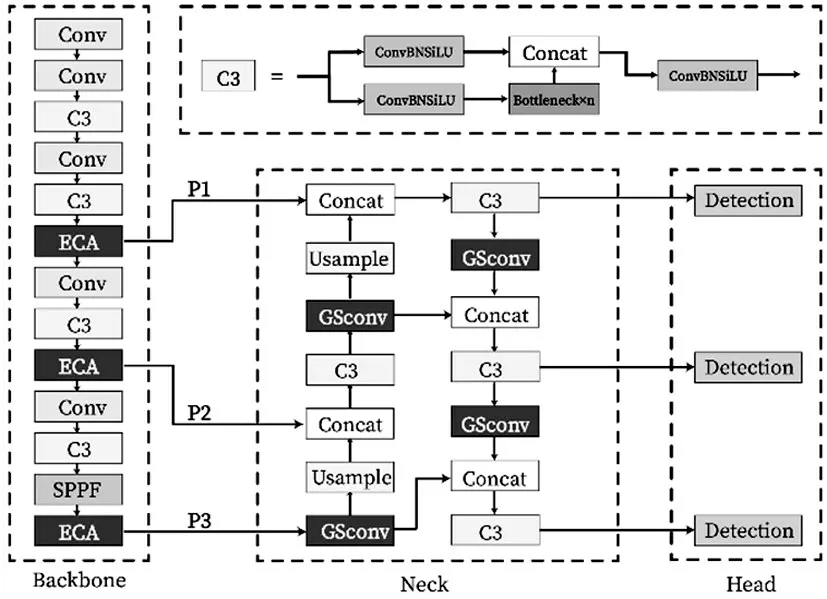
图6 改进YOLOv5网络结构图
4 实验与结果分析
4.1 数据集及实验环境
根据盲人桌面阅读场景中的常用物品构建训练数据集,以书本为主要检测对象,同时加入手机、杯子、水瓶、墨镜、苹果等五类盲人生活场景中的常见物品;采集设备为USB摄像头罗技c270i,固定于桌面正上方,图像采集分辨率为1280×720,采集光线包括顺光、逆光、背光等情况,六类物品每类200 张,一共1200 张图像,按照8:2 随机划分为训练集与验证集,如图7 为不同光照条件下的训练图样。

图7 盲人阅读场景图
网络训练所用主机平台处理器为32GB内存AMD Ryzen 9 5950X,显卡为NVIDIA GeForce RTX 4090,操作系统为Windows 11,采用Python 平台的深度学习框架Pytorch1.13 构建网络模型。以640×640RGB图像作为模型输入,训练轮数设置为600,批处理大小设置为32,初始学习率为0.01,初始权值为COCO数据集上训练好的原始权重。在训练结束后取最优权重部署至树莓派3B中,进行书本定位与位置校准的测试评估,完整实验流程如图8所示。
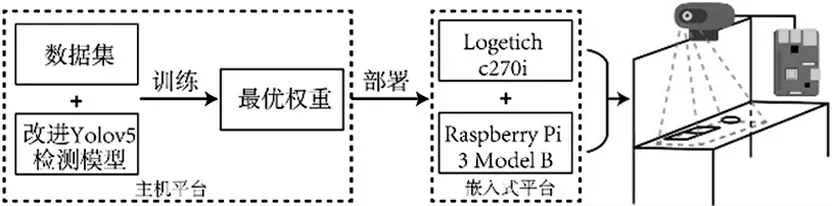
图8 实验流程图
4.2 评价指标
通过平均精度均值(mean Average Precision,mAP),每秒检测帧数(Frames Per Second,FPS)及平均建议精度(Presision suggestion,Ps)作为评价指标,PS用于评价书本位置校准任务,其定义如下:
其中,C为世界坐标下书本实例的有效位移矢量,通过手动测量得到;Di(i=1,…,N)为N 种光照条件下校准建议算法给出的校准建议矢量。
4.3 实验结果与分析
4.3.1 注意力对比实验
本文通过引入ECA 注意力机制实现了跨通道信息的高效交互,取得了检测精度的提升,为了体现本文模型所添加的注意力模块较其他注意力模块的优势,设计了本次注意力机制对比实验,在主干与颈部的连接处嵌入四种典型注意力模块CA[15]、CBAM[16]、SE[17]及ECA,训练测试后得到的实验数据如表1所示。
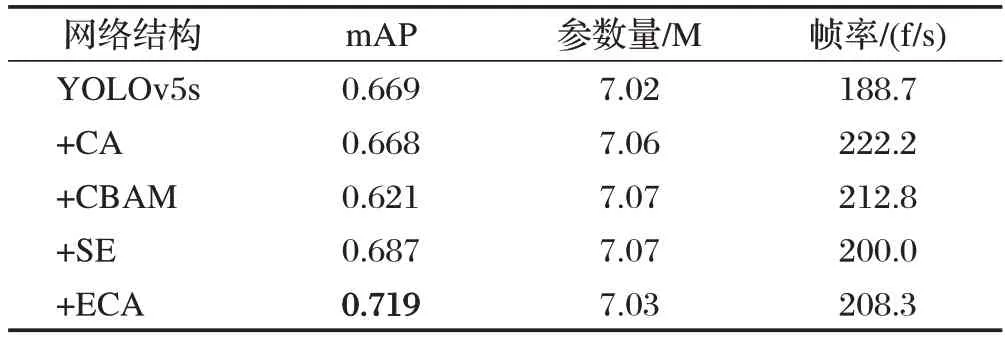
表1 注意力机制对比实验
以YOLOv5s 为基线引入ECA 模块后模型检测精度及检测速度为最优,mAP 提升了7.4%,帧率提升了8.47%;引入SE 模块后mAP 提升了2.7%,而CA 与CBAM 注意力机制未能有效引入,表现为负面提升;4 种注意力机制的引入均会带来参数量的提升,其中ECA模块带来的参数增量最少。
4.3.2 消融实验
深度学习领域常用消融实验来分析不同网络分支对于网络模型整体性能的影响。为了分析本文通过GSConv 替换标准卷积带来的性能提升及引入ECA 注意力机制后对网络整体性能的影响,设计了消融实验,实验结果如表2所示。
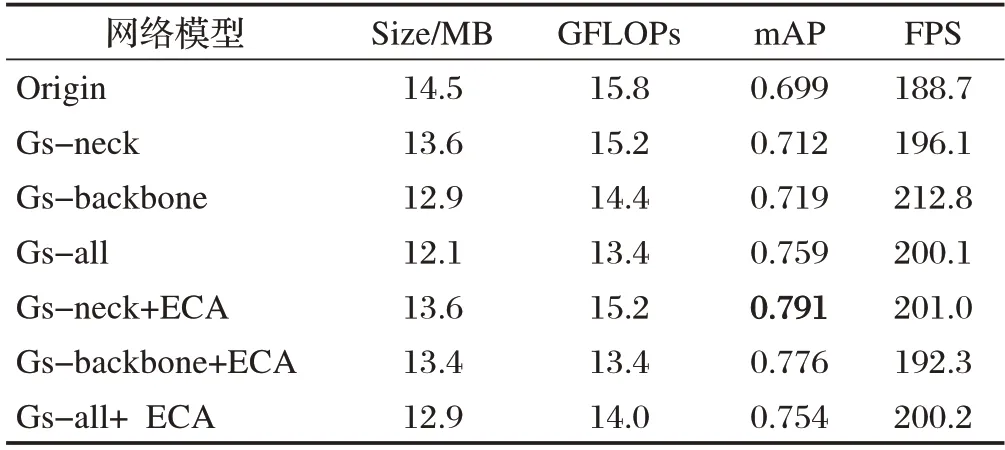
表2 网络结构消融实验
第一组为YOLOv5s 原始模型的检测结果,第二、三、四组改变Gsconv 的作用部位,第五、六、七组在前三组基础上加入ECA 模块。由于当前实验平台性能优越,六组实验组别的帧率提升并不显著,但与原始模型相较,均取得了浮点操作数的减少、权值体量的降低及mAP 的提升,其中第五组的提升最为显著,mAP提升至79.1%;对比ECA模块嵌入前后mAP的变化,第七组较第四组降低了0.66%,ECA 模块的引入表现为负面提升。可见,GSconv能初步提升检测网络的精度与速度;ECA 模块可进一步提升精度,但过度地使用GSconv会造成重要特征信息丢失,影响整体精度。
4.3.3 位置建议实验
在树莓派3B中部署最优模型,搭建试验平台进行测试,评估本文书本校准方法中位置建议算法在实际应用中的平均建议精度与光线鲁棒性。相机到桌面的距离固定为538mm,通过DLT 算法完成相机标定,得到的结果如表3。
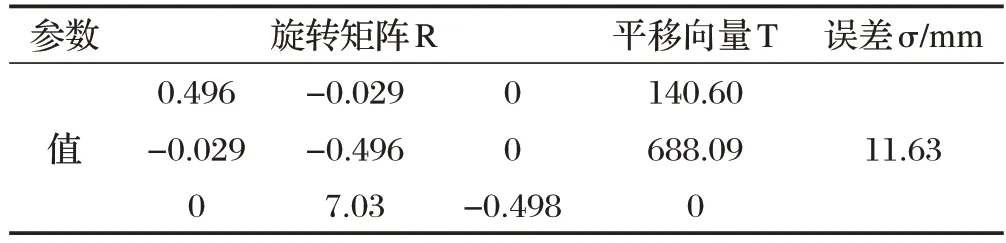
表3 DLT算法标定结果
以书本为主要对象设置了桌面场景的光线变化检测试验,每组试验图像场景样本10 个,光线变化设置了顺光与逆光二组,共计20 个样本,不同场景的构造主要通过改变书本的内容与位置进行,其他生活物品如杯子、水瓶、墨镜等随机置入,现场测试图样如图9,位置建议结果如表4。
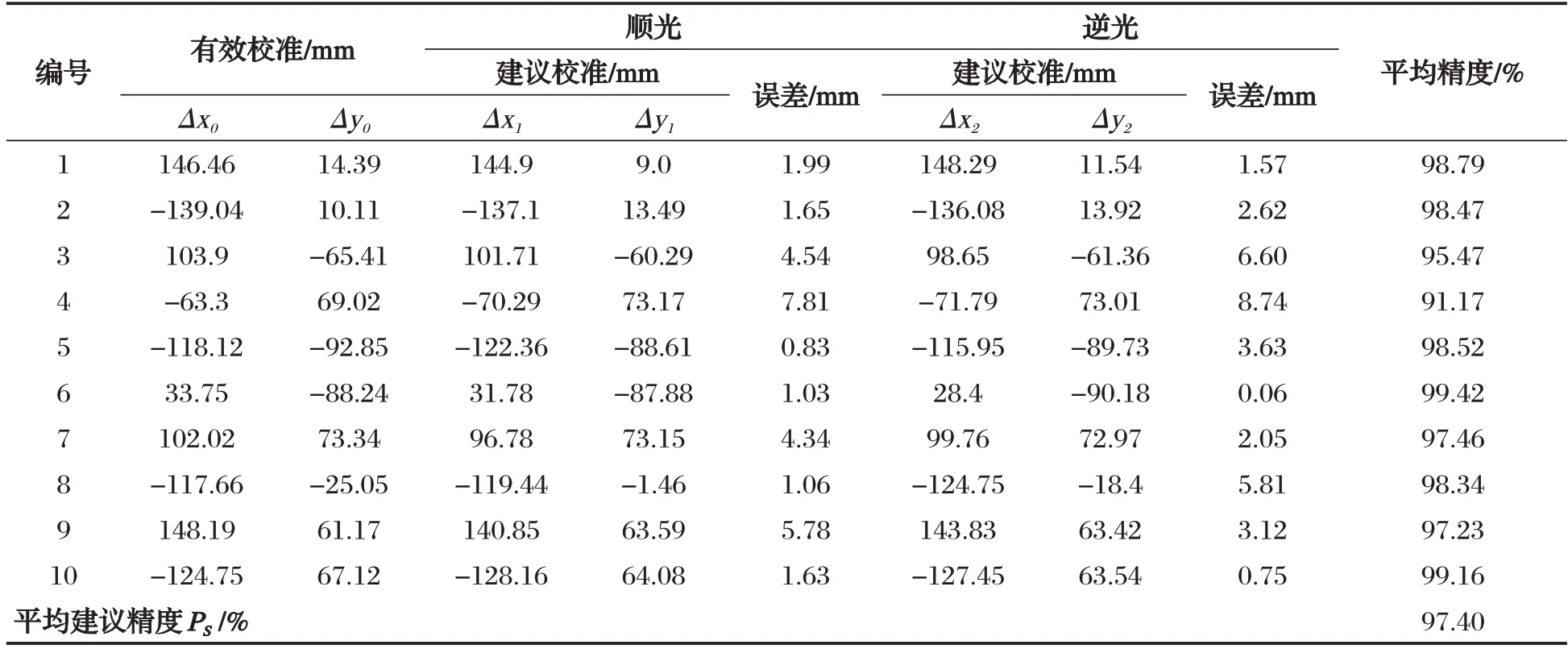
表4 两种光照条件下位置建议实验

图9 现场测试图样及检测结果
对于书本类别,所有实例在顺光与逆光条件下均成功检出。表4 中,书本校准建议算法的平均误差为3.28mm,平均建议精度为97.40%,算法精度较高,对于光线变化表现了较好的鲁棒性。该模型在树莓派3B 中的平均单帧处理时间为5.9s,在算力资源有限的情况下速度表现良好。
5 结束语
本文研究设计并搭建了具备物体定位与书本校准功能的新型智能阅读辅助系统,以YOLOv5s 为基线,通过加入ECA 模块增强主干网络特征提取能力,在网络颈部采用GSconv降低模型体量与浮点运算量,保证在算力有限的嵌入式平台中准确快速的响应;在位置建议任务中通过DLT 算法结合区域划分法,以较高的准确率给出了书本实例的校准建议。实验表明本文模型的平均精度均值达到79.1%,对于书本实例的平均建议精度达到了97.4%,能够满足桌面阅读场景中盲人阅读前对于书本校准的需求。
猜你喜欢
小猕猴智力画刊(2023年11期)2023-11-30 03:21:16
幼儿100(2023年17期)2023-05-29 08:32:24
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
作文小学中年级(2020年4期)2020-12-29 17:16:02
疯狂英语·新悦读(2019年10期)2019-12-13 09:02:24
小天使·一年级语数英综合(2019年8期)2019-08-27 02:23:00
小学科学(学生版)(2018年11期)2018-11-22 07:12:26
小天使·一年级语数英综合(2017年10期)2017-10-31 07:21:28
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
