
基于改进U-Net的面部红外热成像的分割*
2023-10-23 02:58詹文栋龚庆悦朱金阳万泽宇
计算机时代 2023年10期
詹文栋,龚庆悦,朱金阳,万泽宇,黄 敏,王 锐
(南京中医药大学人工智能与信息技术学院,江苏 南京 210046)
0 引言
面诊是指中医通过望、闻、问、切四诊法,对患者面部和五官整体观察,从而判断人体局部与整体的病变情况。望诊法是中医诊断中的诊法之一,几千年来许多中医一直沿用此简单有效的诊断方法。
传统中医望诊聚焦于病人的面色及光泽,对于临床经验很少的中医来说,要基于这些非常有限的面部指标做出诊断是十分困难的。
可见光自动化面诊技术受制于人体肤色和季节变化等因素,导致检测结果可能出现误差。相比之下,红外热成像技术能够通过观察人体表面的温度分布与变化,将中医的阴阳、虚实、寒热等信息以数字可视化的方式呈现,避免了可见光检测技术的限制。
面部红外图像分割是面诊客观化中去除不规范操作如头发遮挡、佩戴眼镜、帽子等造成的干扰背景,排除与体质、疾病等分类识别无关的因素的重要步骤,为后续面部红外热成像的疾病识别分类提供基础。
通过传统的方法分割人体红外热成像,如区域生长[1]、水平集[2]、聚类[3]、图割[4]等,需要大量人工干预,无法实现图像分割自动化。Ronneberger[5]等研究者首次提出了将跳跃连接引入卷积神经网络的一种U形网络(U-Net)。Liu[6]等人提出了基于深层U-Net 和图割的方法并平滑分割结果,此方法加深了特征提取网络的深度,以便于提取更高层次的特征,在腹部CT 序列肝脏肿瘤图像上具有较好的分割效果。江智泉[7]等将U-Net 的主干特征提取网络替换为VGGNet16 的卷积层,并且对特征融合进行优化改进,实验证明该改进方法在舌象分割上取得了较好的分割效果。
本研究对原始U-Net 网络进行改进,将特征提取表现更好的Resnet50代替U-Net原始的主干特征提取模块,去除复制和裁剪(Copy and Crop)部分的Crop,改进后的模型优化了特征融合,并提高了模型的通用性,在中医面部红外热成像图片的分割上取得了较好的结果。
1 模型设计
1.1 本文设计的Facial Res-UNet模型结构
首先借鉴江智泉[7]的方法,改进原始U-Net 模型,下文简称为Facial VGG-UNet 模型。将原始U-Net模型的主干特征提取模块替换为VGGNet16,由5个卷积核和ReLU 激活函数构成的卷积模块和四个最大池化模块不断堆叠而成。将多个使用3×3 卷积核的卷积层进行串联,可以看作是对使用一个大尺寸卷积核的卷积层的分解,比如三个3×3卷积核的卷积层串联相当于一个7×7 卷积核的层,这么做的优势是,多个小尺寸卷积核堆叠起来的卷积层具有的参数比直接使用一个大尺寸卷积核的卷积层的参数少,在感受野相同的情况下,增加了网络的非线性,使得网络的判别性更强[8]。但该方法的主干特征提取网络存在缺陷:主干特征提取网络是通过对图像进行多次卷积和池化操作堆叠而成,而大量网络堆叠容易造成梯度消失和梯度爆炸问题[9]。
同时,对解码部分进行优化:取消了五个初步有效特征层在上采样过程中的剪切(Crop)操作,直接复制(Copy)特征层,从而提高网络模型的通用性。最终,改进的U-Net网络结构如图1所示。
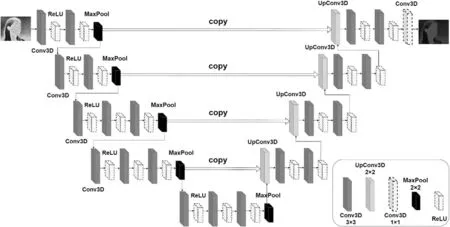
图1 Facial VGG-UNet网络结构
由于存在上文提到的梯度爆炸和梯度消失问题,在Facial VGG-UNet 网络模型的基础上,我们又做出了新的改进。
本文提出的改进UNet 模型Facial Res-UNet,采用ResNet50 替换传统U-Net 的主干特征提取模块,不仅能因残差块避免梯度爆炸和梯度消失的问题,还能保留U-Net 网络结构简单和训练数据量需求小的优势,非常契合中医面部红外热成像图片的对比度低、边界模糊等导致的特征提取效果差以及数据集量少的特点。再对U-Net 的解码区优化特征融合,去除初步提取特征层的剪切(Crop)操作,一方面使得输入图像与输出图像尺寸保持一致,增加模型的通用性,另一方面也能使得模型学习到更多细节信息,以便进一步对像素进行分类,提高模型的泛化能力。其网络结构如图2所示。
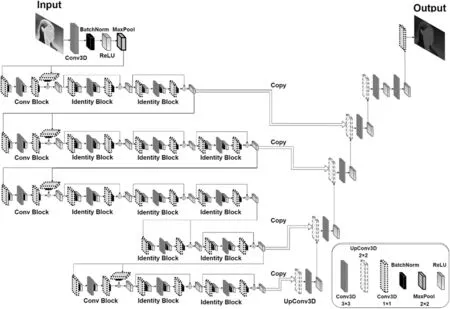
图2 Facial Res-UNet模型结构
图2 中,主干特征提取网络Resnet50 由两个基本模块组成,分别为Conv Block和Identity Block[10]。前者由于输入与输出的维度不同,因此Conv Block 一般可用于改变网络的维度;后者输入与输出维度一致,因此一般选用Identity Block来加深网络深度。
Conv Block 可以分为主路径和跳跃路径两个部分。主路径由二次大小分别为1×1 和3×3 的卷积操作和标准化(BatchNorm)、激活函数ReLU、一次1×1卷积操作和标准化(BatchNorm)组成。跳跃路径由1×1卷积操作和标准化(BatchNorm)组成。Conv Block 最终由主路径输出和跳跃路径输出相加,并经过一次ReLU 激活函数得出,结构如图3所示。Identity Block也可以分为主路径和跳跃路径两个部分。Identity Block 的主路径与Conv Block 的主路径相同,而跳跃路径直接与主路径的输出相加,最后经过一次ReLU激活函数得出总体输出结果,结构如图4所示。
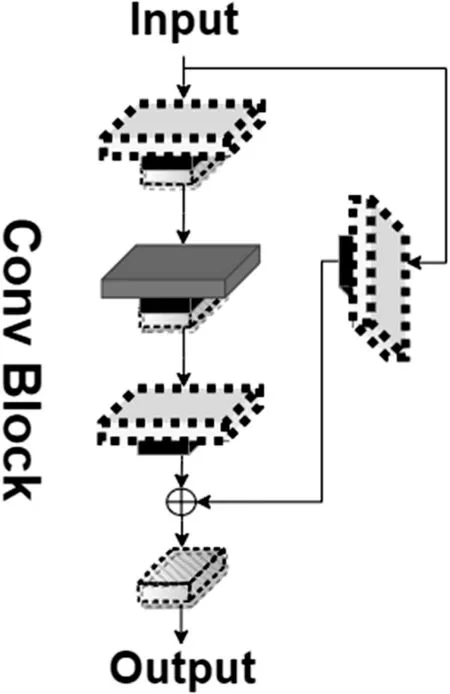
图3 Conv Block
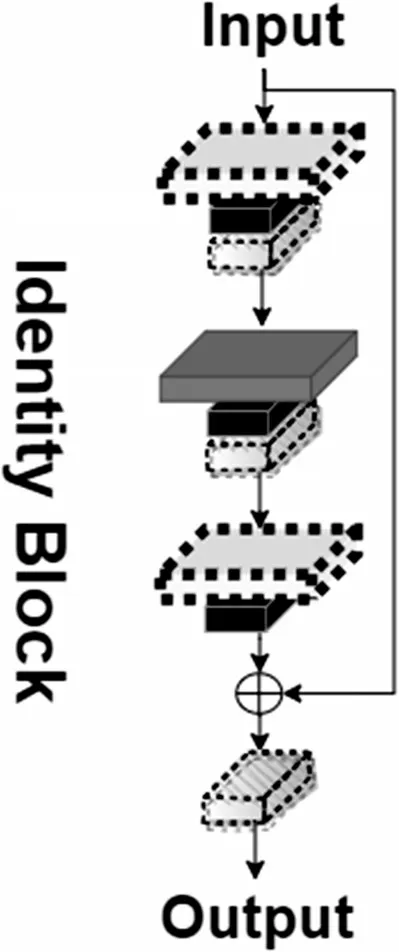
图4 Identity Block
2 数据收集与预处理
2.1 数据收集
本研究按照《中医红外热成像技术规范摄像环境》[11]标准严格搭建数据采集环境。数据来源有效且符合伦理审查规范,且仅用于本次学术研究,遵循被采集者意愿。数据集包含300 张标准面部红外热成像图片,其中160 张和40 张分别作为训练集和验证集,100张作为测试集用于模型泛化性能测试。
2.2 数据标注
本研究使用Labelme 工具对面部红外热成像样本进行标注,该工具基于多边形框对目标物体进行标注[12],能够得到图像有效分割标签。本研究分割任务究其根源是二分类问题,即对无关背景和面部进行分割,标签灰色部分和黑色部分分别表示红外热成像的面部和无关背景。中医红外热成像图片标注过程如图5所示。
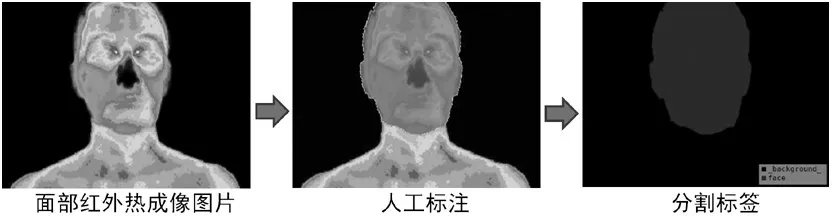
图5 中医红外热成像图片的标注
3 模型训练与性能评估
3.1 模型训练
使用160 张面部红外热成像图片进行模型训练,Epoch设为100。为了使占用内存更少,计算效率更高,优化器选择Adam,学习率设置为0.0001,最小学习率设置为学习率的0.01倍。动量(Momentum)设置为0.9,这有助于跳出局部最小值,加速模型的收敛。权值衰减(weight_decay)可以防止模型过拟合,但由于采用的优化器是Adam,可能会导致权值衰减(weight_decay)发生错误,故weight_decay设为0。
采用相似系数(LossDice)和交叉熵函数平均值(LossCE)的和来计算Loss 的组合损失函数,具体计算公式如下:
图6 分别表示传统U-Net 模型、Facial VGGUNet 模型和本文提出的Facial Res-UNet 模型在训练过程中的trainloss、valloss、smooth train loss、smooth val loss与Epoch的关系图。
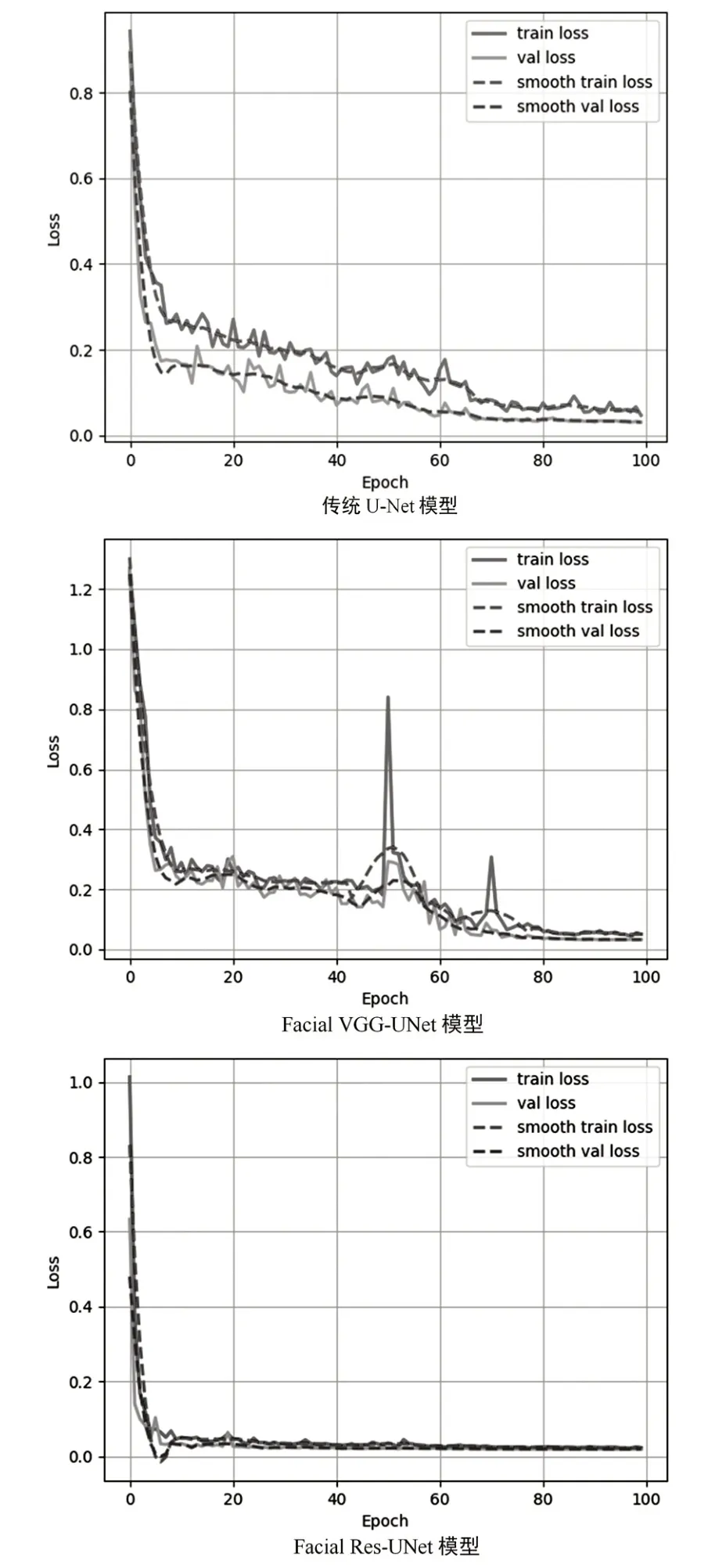
图6 模型训练过程中损失值的对比
通过观察loss 在训练集和验证集上的表现,可以看到三种模型的loss 值最终能逐渐收敛并趋于稳定,但很明显本文提出的模型收敛的速度更快,并且loss值更低,更稳定。而传统的U-Net存在收敛速度慢,最终收敛的loss 值较高的问题。Facial VGG-UNet 模型在50 轮和70 轮出现了大的波动,稳定性较差。由此可见本文提出的模型具有更好的鲁棒性。
3.2 模型评估
本文使用平均交并比(mean Intersection over Union,mIoU)作为评估指标,计算过程如下:
其中,k为图像中标签类别数,i表示真实类别,pij表示属于i类但被判定为j类的像素数量,即假阳性像素数量,pji为假阴性像素数量,pii为预测正确的像素数量。
图7 表示本文提出的改进模型Facial Res-UNet,在训练集上的mIoU 值随着Epoch 增大的变化情况。从图7 可以发现,训练的前8 轮TrainmIoU 波动很大,拟合度逐渐上升。在第8轮以后,TrainmIoU 就已经上升不太明显,逐渐稳定下来,60 轮以后,模型的TrainmIoU 不再上升,达到了98.19%。图8 表示验证集上模型的mIoU 达到了98.20%,由此可见,模型的图像分割效果较为优异。
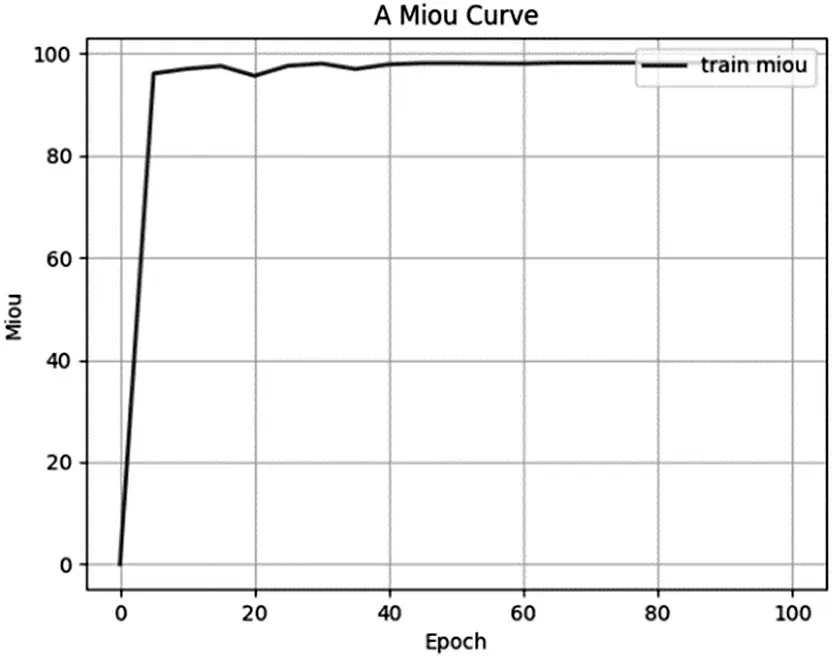
图7 训练集上的mIoU值
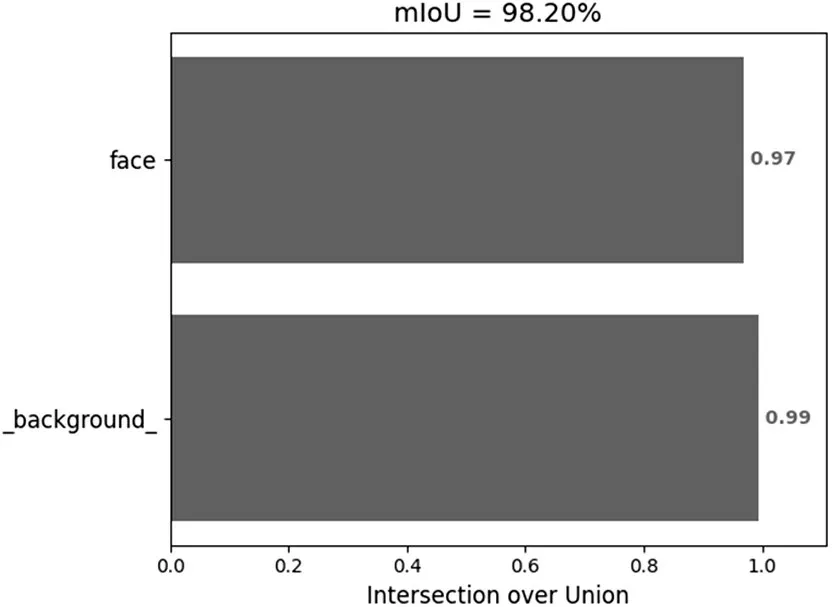
图8 验证集上的mIoU值
3.3 模型性能与分割效果的比较
本文使用人工智能实验室服务器进行实验,具体的硬件环境为TELSA-T4,软件环境为Window10、Torch1.2.0 深度学习框架和CUDA10.0。表1 对比了传统U-Net 模型、Facial VGG-UNet 模型和本文改进模型对面部红外热成像的图像分割性能,本文提出的Facial Res-UNet 方法的mIoU 和Accuracy指标优于前两种方法,在训练时长上稍处于劣势。
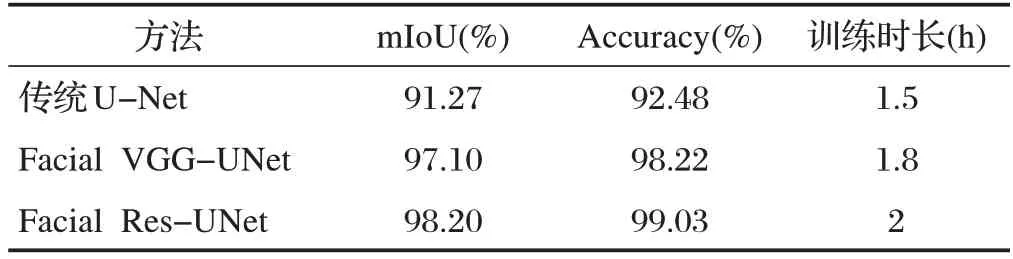
表1 模型性能对比
图9 为原始U-Net 模型、Facial VGG-UNet 模型和Facial Res-UNet 模型的分割效果对比。通过对比可以发现传统U-Net 模型和Facial VGG-UNet 模型对人脸分割都存在边缘震荡问题,而本文提出的模型表现更优秀,边缘相比前两者更加清晰,分割精度更准确。

图9 模型的图像分割效果对比
4 结束语
本文介绍了一种基于U-Net 的改进模型Facial Res-UNet,其在面部红外热成像数据集上的分割效果更优,分割图像的均交并比mIoU 达到98.20%。该技术为面部红外热成像图片的自动化分类识别提供了坚实基础,未来的研究将扩展至人体全身红外热成像的图像分割和分类识别,为中医疾病诊断提供更多客观数据支持,打破“中医缺乏客观性”的偏见。
猜你喜欢
军事文摘(2024年2期)2024-01-10
广东教育·高中(2022年1期)2022-03-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子制作(2018年19期)2018-11-14
数学物理学报(2017年5期)2017-11-23
自动化学报(2017年11期)2017-04-04
新课程研究(2016年21期)2016-02-28
中国交通信息化(2015年2期)2015-06-05
噪声与振动控制(2015年4期)2015-01-01
