
基于嵌入对比学习的广义零样本预分类模型
2023-10-23 02:58:32唐义承纪惠芬
计算机时代 2023年10期
唐义承,纪惠芬
(浙江理工大学计算机科学与技术学院,浙江 杭州 310018)
0 引言
在计算机视觉领域,传统的机器学习逐步向深度学习方向发展。监督学习模型在有大量标记数据的情况下已经能够取得卓越的表现。但是,由于有标签的数据收集费时费力,同时对每个类别的图片都需要人工来标注,这将大大提高深度学习的成本。为此,零样本学习成为了近年来的热门课题,已被广泛用于解决现实任务中出现的难题。在传统的零样本学习设定中,我们利用语义信息建立可见类与不可见类的联系,将可见类中学习到的知识转移到不可见类中,进而,完成对训练过程中没有出现过的不可见类的识别。然而,在现实的分类情境中,需要同时对可见类和不可见类进行分类,这被称为广义零样本学习(Generalized zero-shot learning,GZSL)。
最近,越来越多的方法采用了基于对抗生成网络(GAN)[1]或变分自编码器(VAE)[2]生成模型来解决广义零样本学习的问题。这种方法通过生成不可见类的合成样本,将零样本学习任务转化为传统的监督学习任务,从而缓解了可见类与不可见类之间的数据差异,提高了准确率。然而,GAN 生成模型易出现特征混淆问题,也无法保证每次训练的稳定性。相比之下,VAE 生成模型将视觉特征和语义属性映射到潜在空间中,使用潜在空间嵌入进行分类。但是VAE 模型可能导致域偏移问题,影响分类结果。此外,基于预分类的方法近期也成为热门研究方向。在测试阶段,将测试样本分为可见类和不可见类样本,然后对这两类样本使用特定的监督学习分类器或零样本分类器进行训练。但是由于训练集中没有不可见类样本,预分类可能不能取得很好的效果。
为了提高视觉特征与语义信息之间的关联性,缓解领域偏移问题,如图1 所示本文提出一种基于嵌入对比学习的广义零样本预分类模型。首先,利用超球面变分自编码器[3]将视觉特征和语义属性映射到一个统一的球形潜在空间中。提取出一个能够同时表达视觉模态和语义模态的潜在空间。然后潜在空间中,对齐两个模态的潜在特征,并且对潜在特征进行嵌入对比学习。最后,利用超球面空间中的分布流形对测试样本预分类,根据预分类的结果将测试样本分配给对应的专家分类器。
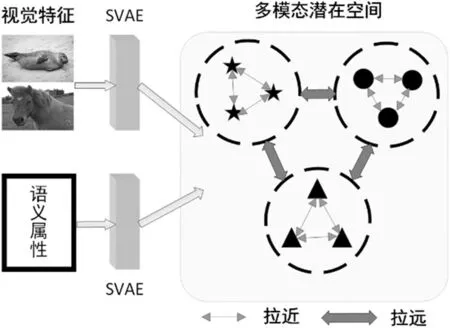
图1 基于嵌入对比学习的广义零样本预分类模型基本框架
本文所提出的预分类模型可以与任何的ZSL方法相结合。核心思想非常简单,易于实现。在四个最常见的基准数据集(CUB、SUN、AWA1、AWA2)上评估了本文的模型。实验结果表明,本文的方法在数据集上可以得到优秀的分类效果。
1 方法
本文提出了一种基于潜在空间对比的广义零样本预分类模型,模型架构如图2所示,该模型可以划分为三个阶段:嵌入阶段、潜在特征对比阶段和分类识别阶段。
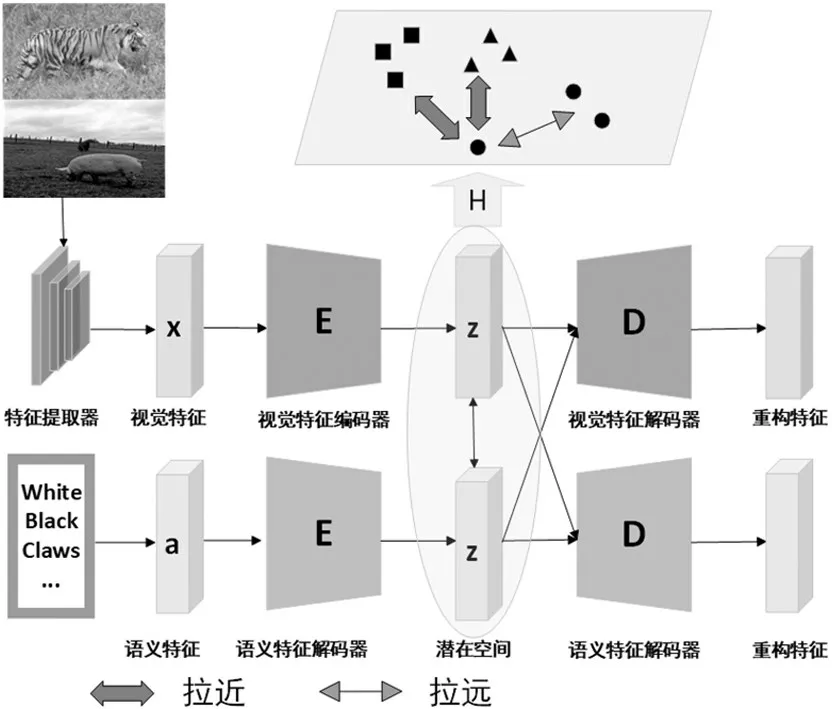
图2 模型具体框架
⑴在嵌入阶段,利用超球面变分自编码器,为视觉特征和语义属性构造统一的球形潜在空间。
⑵在潜在特征对比阶段,使用分布对齐约束、分类约束、对比约束三种约束条件,将视觉特征的分布与语义属性分布进行对齐,并加强同一类别类内联系和同一类别不同模态之间的联系。
⑶在分类阶段,通过对潜在空间中可见类分布情况的分析,判断测试样本是否属于可见类,并据此将其分配给相应的分类器进行分类。
1.1 嵌入阶段
在嵌入阶段,利用两个独立的球面自编码器将视觉和语义信息投影到潜在空间中。在球面自编码器中,编码器将视觉特征x 嵌入到潜在空间中得到潜在向量z,并且解码器重构视觉特征以保证模态一致性。同时,通过潜在向量z 的分布计算出视觉特征的vMF分布,使用另一球面自编码器预测的vMF 分布作为先验分布,计算分布差异。每个球面编码器需优化重构误差和vMF分布差异,球面编码器的优化函数如下:
其中,Eq(z|x)[log pΦ(x|z)]表示重构误差。DEMD代表了两个球面编码器预测的vMF分布之间的差异。λ表示加权差异项的超参数。由于两个分布支持区域不完全重合时,KL 散度可能失败,因此本文采用推土机距离(Earth Mover’s Distance,EMD)表示两个分布之间的相似程度。
1.2 潜在特征对比阶段
为了在球形潜在空间中,对齐视觉模态与语义模态,并且使潜在空间中的向量分布更加紧凑,同时提高可见类之间的差异度。在潜在特征对比阶段采用交叉对齐约束、分类约束、对比约束三种约束。
交叉对齐约束将某个特定模态的嵌入向量通过其他模态的解码器进行重构,得到重构特征,然后计算该重构特征与真实语义样本之间的误差。交叉对齐损失为:
其中,Eqθa(z|a)[log pϕf(x|z)]和Eqθf(z|x)[log pϕa(a|z)]代表重构误差。交叉对齐约束学习的是两种不同模态的共享潜在空间中的嵌入向量,因此需要捕获模态不变的信息,以确保不同模态之间的嵌入向量具有相似的表示。
分类约束引入softmax 分类器对潜在空间向量进行分类,使潜在变量更具有区别性,分类损失如下:
其中,ϕcls代表了线性softmax 分类器的参数。分类约束的引入对于可见类与不可见类之间的关联性可能会产生一定的影响,但他同时降低了将不可见类特征误判为可见类的风险,这有助于提高模型的二分类性能。本文模型的重点是分离可见特征和不可见特征,而不是将不可见特征分类到具体的不可见类中。
对比约束中构造正例的方法,不同于传统的对比学习方法,并不是通过简单的数据增强方式来构造数据对,而是利用类别标签来确定潜在空间中哪些向量可以作为正例,从而增加正例的数量。相较于传统的对比学习方法,不仅可以增加正例数量,还可以增加类内一致性。同时,该方法还具有较好的可解释性,能够更好的理解模型的决策过程。
对比约束在对潜在空间向量后添加一个共享权重的神经网络模块h(∙),将潜在空间向量映射到一个更深层的空间当中。在更深层的空间中,通过计算余弦相似度来测量潜在向量的相似性。公式如下:
其中,τ >0 表示对比嵌入的温度参数,N 表示样本的个数。l[k≠i]是一个指示函数,当且仅当k=i 时,取0,否则为1。
为了降低对比损失,模型将正样本对特征距离拉近,负样本对特征对拉远。对比约束能够捕获同类样本中共享的强判别信息和结构,并且因为增加了正对的数量,可以更好的刻画类内相似性,使得类内投影更加紧凑。
综上所述,训练模型的损失函数可以表示为:
其中,α、β、γ是用于加权的超参数。
1.3 分类阶段
在潜在特征对比收敛后,视觉特征和语义属性在潜在空间中呈现出按照类对齐的特点。这种按照类对齐的特性,使得在球面潜在空间中每个类的流形都是单独的一个簇,因此,可以用可见类流形的中心和流形的边界来推断测试样本是否属于可见类或不可见类。这个方法的优点是不需要建立传统的分类器模型,直接使用可见类样本的流形信息,可以实现对可见类和不可见类的鲁棒分类。
对于每个类,通过语义信息找到该类中心,然后通过训练样本的统计数据计算类的流形边界。将训练样本嵌入到潜在空间,计算它们与类中心的余弦相似度并进行排序,使用分类精度δ来计算类边界值。取所有类边界值的最大值作为可见类的阈值N。
给定一个测试样本x,首先将其编码为潜在向量z。然后计算z 与所有可见类中心的余弦相似度,找到距离z 最近的可见类流形。使用事先计算的阈值N,判断z 是否属于可见类,如果余弦相似度大于等于阈值,则将x 归类到可见类中;否则,将其归类到不可见类中。根据这个分类结果,将训练样本分配给相应的可见类分类器或不可见类分类器进行训练。
2 实验及结果分析
2.1 实验数据集
本文在零样本学习领域常用的四个基准数据集上进行实验来对模型进行评估,这四个数据集分别是Caltech-USCD Birds-200-2011(CUB)、SUN Attribute(SUN)、Animals With Attributes 1(AWA1)、Animals With Attributes 2(AWA2)。所有数据集都为每个样本提供对应都属性信息。本文按照标准划分[4]将数据集划分为可见类样本和不可见类样本,实验数据集如表1所示。
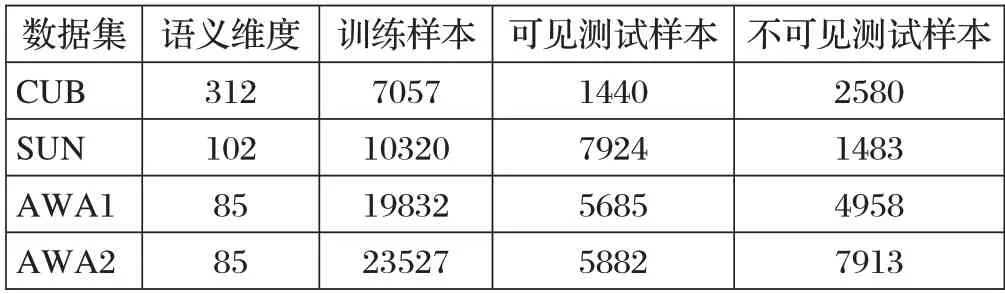
表1 实验数据集
2.2 评价指标
对于预分类器,可见类的流形分布内样本被视为可见样本,分布外样本被视为不可见样本。其本质上就是一个二分类问题,因此主要通过扫描阈值来计算受试者工作特征曲线下的面积(Area-Under-Curve,AUC)来判断二分类的效果。在广义零样本图像分类的情况下,依据文献[4]中提出的评估方法,S和U 分别代表可见类与不可见类的平均精度。广义零样本图像分类的性能通过调和平均值H=2*S*U/(S+U)衡量。调和平均值可以同时反映识别可见类与不可见类图像的能力。
2.3 对比模型
将本文提出的模型与以下相关模型进行对比实验:ReViSE[5]、SYNC[6]、DeViSE[7]、CVAE[8]、SP-AEN[9]、f-CLSWGAN[1]、COSMO[10]。
上述模型采用不同的方式来提高广义零样本的分类性能。其中ReViSE、SYNC、DeViSE 学习嵌入模型,将视觉特征和语义属性统一起来用于相似度度量。CVAE、SP-AEN、f-CLSWGAN 采用生成模型的方法,利用GAN 或者VAE 生成不可见类的合成特征。COSMO 使用门控模型来学习预分类器,以划分可见类特征与不可见类的特征。
2.4 实验结果对比
为了验证本文提出的预分类模型的分类性,本文在三个数据集上将其与四个近些年提出的门控方法进行对比,结果如表2所示。

表2 各模型在三个数据集上AUC分类指标
最佳结果用黑体加粗表示。根据表2 可以看出,本文提出的模型在衡量二分类的重要指标AUC 上,在AWA2 数据集上达到了90.3%的优异结果,超过了其他任何模型。
为进一步验证本文模型在广义零样本分类中的准确率,与上述的模型作为基准(baseline)进行实验。实验结果如表3 所示。表中黑体表示每列的最优值,“-”表示原文没有该数据集的实验结果。其中,S表示分类可见类的准确率,U表示分类不可见类的准确率,H表示调和平均值。本实验与基准模型采用相同的基准数据集的划分标准。根据表3 数据,在AWA1 和AWA2 数据集上,本文模型的调和准确率分别达到了61.0%和62.9%,超过了表3 中列出的其他所有模型。值得注意的是,本文模型在U 的指标上表现不如嵌入模型的方法,这可能是因为可见类和不可见类之间不存在交集,存在域偏差的问题。当模型提高不可见类的精度时,会降低可见类的精度。然而,本文模型在S的指标上远远超过嵌入模型的方法,这表明在某些方面本文模型比嵌入模型更优秀。尽管与其他模型针对可见类或不可见类的性能单独比较时,本文模型并非总是最优的,但就最重要的调和准确率这一指标而言,基于嵌入对比学习的广义零样本预分类模型具有一定竞争力。
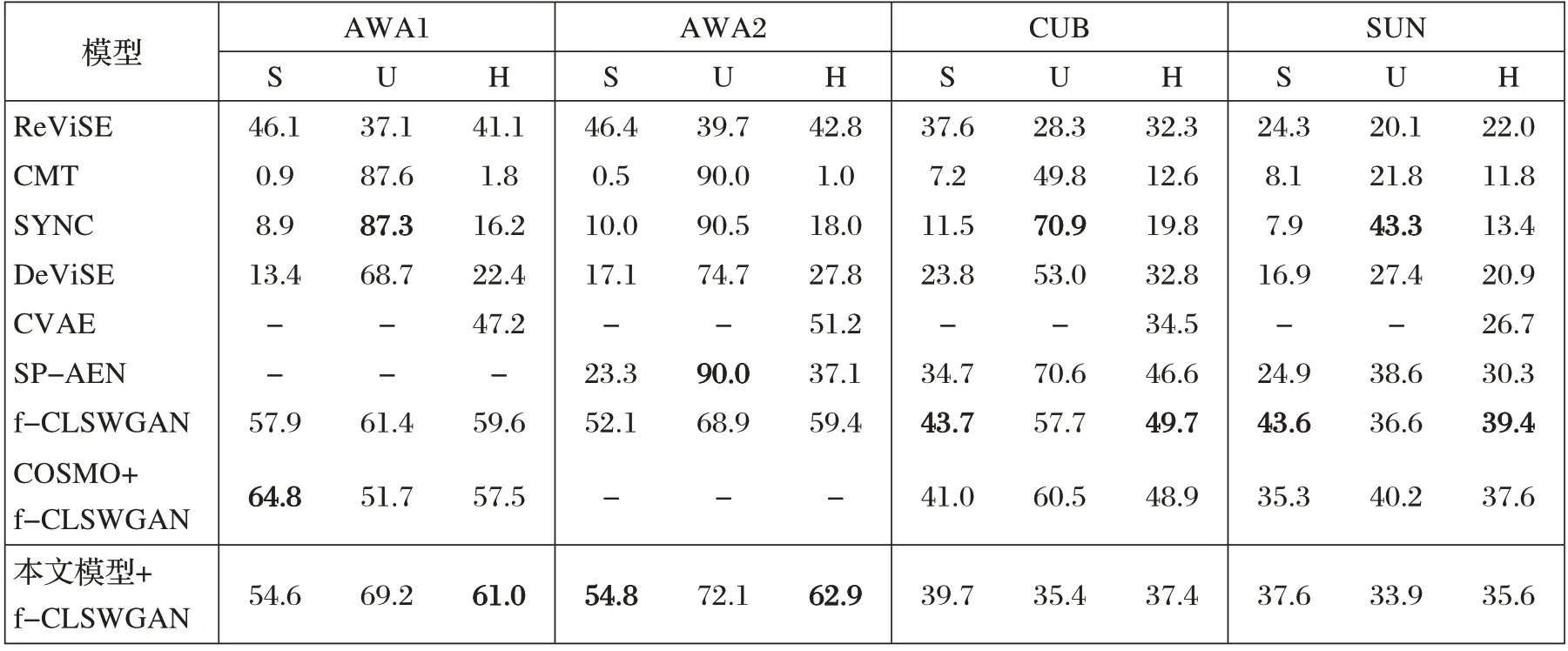
表3 各模型在四个数据集上性能对比
实验证明,本文模型在广义零样本分类任务中取得了较高的分类准确率,有效缓解了可见类与不可见类之间没有交集所产生的域偏差问题。同时,本文模型还能够降低视觉特征中冗余信息对分类的影响,使得广义零样本分类任务的精度得到了进一步提高。
2.5 实验结果可视化
本文模型在AWA2 数据集上类别样本的t-SNE(t-Distributed Stochastic Neighbor Embedding)投影的可视化结果如图3、图4所示。
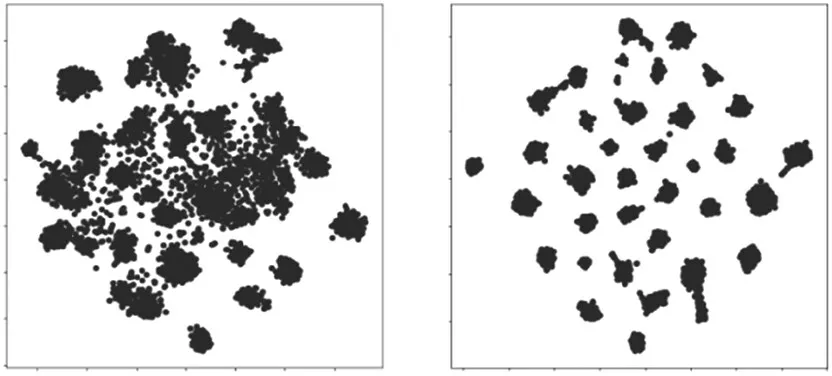
图3 AWA1原始特征与嵌入后的特征对比图
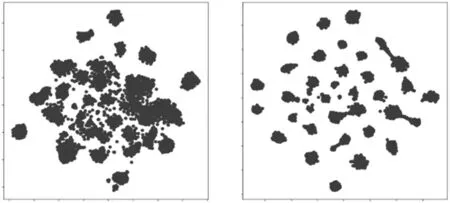
图4 AWA2原始特征与嵌入后的特征对比图
由图3、图4中的对比可以看出,在对比嵌入之后,可见类之间的簇更加紧密,并且与其余的可见类之间也更加远。
3 结论
广义零样本学习是一个有挑战性的问题,具有广泛的应用前景。本文提出了一种基于嵌入对比学习的广义零样本预分类模型,采用超球面自编码器将视觉特征映射到潜在空间中,利用对比学习缩小可见类的流形边界。利用每个可见类流形边界和中心,将测试样本分为可见类样本和不可见类样本,之后使用两个专家分类器分别对可见类与不可见类分类。从而将广义零样本问题转化为传统的零样本学习和有监督学习问题。因为可以在不使用不可见类样本的情况下,将可见类与不可见类分类,所以可以缓解广义零样本中领域偏移的问题。但是,本文模型非常依赖于可见类样本在训练集中的质量。因此,尽管本文模型在AWA1 及AWA2 上获得了比基准方法更好的实验结果,但不能完美适用于CUB 和SUN 数据集。今后需要进一步研究在样本数据较少的情况下采用数据增强等方法,以获得更好的信息表示并提高模型的性能。
猜你喜欢
数学物理学报(2022年3期)2022-05-25 13:33:00
中国中医急症(2019年10期)2019-05-21 07:20:28
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子测试(2018年1期)2018-04-18 11:52:35
电子设计工程(2017年20期)2017-02-10 03:39:29
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
数学年刊A辑(中文版)(2016年2期)2016-10-30 01:46:38
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2014年15期)2014-04-04 12:05:20
