
基于改进SSA-LSTM的销量预测研究*
2023-10-23 02:58:28楼泽霖郑军红何利力
计算机时代 2023年10期
楼泽霖,郑军红,何利力
(浙江理工大学计算机科学与技术学院,浙江 杭州 310018)
0 引言
准确地预测销售情况,可以为市场部门提供有效地营销数据支撑,有助于按需制定生产计划、采购计划,更好地控制库存量,其在市场竞争中具有重要意义。
传统的线性回归方法进行预测,会忽视非线性因素的影响[1]。神经网络在复杂的数据中能够完成特征的提炼,同时还具备优良的自适应学习能力,在销量预测领域得到了广泛应用[2]。其中LSTM 长短期记忆网络在许多序列数据预测任务中表现优异。柯苗等人采用LSTM 模型预测电商商品销量,相比于传统的时间序列预测方法,其预测效果更准确[3]。陈盼提出基于多变量的LSTM 模型,对菜品销量进行预测,结果表明,多变量的LSTM 模型的变化趋势和预测结果更接近于真实销量数据,预测精度更高[4]。
但是在LSTM 模型建立和训练过程中,超参数的设定能显著影响其表现,若设置了不恰当的超参数则会导致模型难以达到预期效果。固定不变的超参数难以保证预测精度稳定性[5],因此,为神经网络模型选择合适的超参数就显得十分重要。
本文提出一种改进的麻雀搜索算法,对LSTM 神经网络模型的超参数进行优化,以得到预测精度更高的网络模型。考虑到实际场景中,产品的销量趋势会受到多种因素的影响,如所属地区的零售户数量、人口数量等[6]。某些宏观经济因素也会在一定程度上影响市场对产品的需求波动,如商品零售价格指数、全社会消费品零售总额等[7-8]。本文在销量数据的基础上考虑了零售户数量、零售户的购进次数、社会消费品零售总额、月平均价格等数据,将其加入特征变量中,建立了包含相关预测特征条件的多变量模型。最后对销量进行预测对比实验,证明了该模型的有效性。
1 相关理论
1.1 LSTM网络模型
长短期记忆神经网络(Long Short Term Memory Network,LSTM) 是由循环神经网络改进而来的一种网络模型,解决了传统循环神经网RNN在长序列数据训练过程中容易产生的梯度消失和梯度爆炸问题。LSTM 网络能够学习到数据间的长期依赖关系,在处理时序问题上有比较好的预测效果。
图1 是LSTM 单元的内部结构,与RNN 相比,LSTM 加入了输入门、遗忘门及输出门三个门和一个记忆单元。
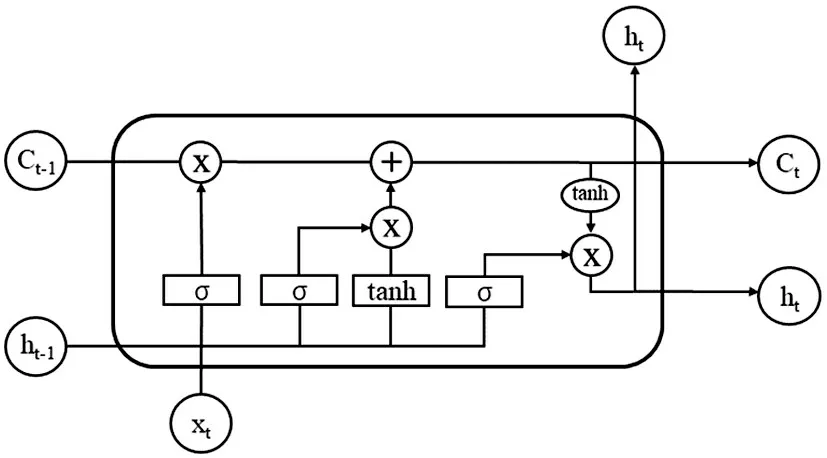
图1 LSTM单元结构
遗忘门可以对历史信息进行选择性遗忘,表达式如下:
其中,Wf为遗忘门的权重矩阵,ht-1为上一时刻的输出,xt为当前的输入信息,bf为遗忘门的偏置矩阵,σ为sigmoid 激活函数。ft的值介于0 到1 之间,0 代表完全忘记信息,1代表完全保留信息。
输入门负责将新的信息选择性的记录到细胞状态中,表达式如下:
其中,Wi为输入门的权重矩阵,bi为输入门的偏置矩阵。为新的细胞候选量。新状态结合遗忘门的输出和上一时刻的细胞状态得到新的细胞状态Ct。
输出门负责控制信息的输出,表达式如下:
其中,Wo为输出门的权重矩阵,bo为输出门的偏置矩阵。
1.2 麻雀搜索算法
麻雀搜索算法(sparrow search algorithm,SSA)是由薛建凯提出的一种新型群智能优化算法[9],麻雀搜索算法主要模拟了麻雀群体觅食和反捕食行为[10]。相比于其他群智能优化算法,麻雀搜索算法具有收敛速度快、鲁棒性强、寻优能力强、参数少等特点。
算法将麻雀种群分为发现者和加入者,发现者负责提供觅食区域和方向,加入者追随它们来获得食物,发现者和加入者的身份是根据适应度动态变化的。
在SSA中,发现者的位置更新公式如下:
T 为设置的最大迭代数,t 为当前迭代次数;为第t代种群中的第i个麻雀的第j个属性值,α 为[0,1]范围内的随机数。R2为预警值,ST 为安全值。Q 为服从正态分布的随机数,L是值都为1的1×d 的矩阵。
当R2 以下为加入者的位置公式: 为t+1 代种群中位置处于最优的麻雀个体,Xworst处于为当前全局最差位置的麻雀个体,A为的1×d的矩阵,其内部元素由1和-1随机组成,A+=A⊤(AA⊤)-1。 当意识到危险时: 为处于当前全局最优位置的麻雀个体。β用于控制步长,是一个服从均值为0 方差为1 的正态分布随机数。K用于控制麻雀移动的方向,为[-1,1]范围中的一个随机数。fg和fw分别为当前全局最优适应度和最差适应度值,fi为第i个麻雀个体的适应度。 虽然麻雀搜索算法具有寻优能力强、鲁棒性强等优点,但是存在其他常见的群智能算法也会出现的问题,即在迭代过程中容易陷入局部最优。为了解决此问题本文通过引入重心反变异策略来增强算法跳出局部最优的能力。 反向学习是一种经典的智能优化算法加速技术,它通过在当前点和它的反向点之中择优选择[11]。传统的反向学习通过计算反向点来探索更多的空间,获取更优质解。但是该方法没能利用到整个种群间的信息。 Rahnamayan 等人提出了一种基于重心的反向学习[12],重心反向学习能够结合整个麻雀种群的搜索经验,提高搜索效率,还能扩大问题空间的探索范围。使算法迭代到后期可以保留个体的有用信息,防止种群的多样性降低,从而能够使麻雀搜索算法能够更好地发现全局最优解,避免算法出现早熟收敛。 重心计算公式如下: 重心反向解的计算公式: 其中,k 是[0,1]范围内均匀分布的随机数,加入收缩因子可以拓展反向搜索空间的范围,增大找到更优解的概率[13]。 在算法迭代过程中,对更新位置后的麻雀种群进行重心反向变异。但是无法保证变异后的麻雀位置一定能够优于变异前的原位置,故采用贪心的思想决定是否要更新麻雀位置,只有当变异更新后的位置更优时才替换原位置,否则舍弃。 LSTM 网络虽然在时间序列数据预测上具有明显的优势,但是网络的超参数选择不当会直接影响预测模型的性能。通过人为经验去设置超参数很难保证选择到最优值,采用网格搜索穷举则会花费大量的时间。 本文使用改进的麻雀算法来搜索LSTM 网络模型的超参数,能够避免超参数选取不当带来的误差,提升网络模型的精度。将LSTM 网络模型与改进后的麻雀搜索算法相结合,构建了改进的SSA-LSTM 模型。 改进的SSA-LSTM 模型流程如图2 所示,主要步骤如下: 图2 改进SSA-LSTM流程图 步骤1 将历史销售数据与零售户等数据进行整合、清理。 步骤2 基于时间序列构建数据样本,并划分训练验证集。 步骤3 把LSTM 的隐含层神经元个数、网络学习率、训练次数作为优化对象,超参数的值即为麻雀的位置。 步骤4 将模型的预测值与实际值的均方误差作为适应度。 步骤5 开始迭代,利用改进的麻雀搜索算法寻找最优超参数。 步骤6 判断是否已经达到最大迭代次数,如果未达到,返回步骤5;反之则输出最优的LSTM 模型超参数。 步骤7 通过改进麻雀搜索算法得到的最优超参数,重新训练得到高精度的LSTM网络模型。 步骤8 使用该LSTM 模型进行产品销量预测,输出预测结果。 本文实验数据来源于某企业的销售数据,实验收集了某款产品从2013 年1 月至2019 年12 月的月销量记录,其中2013 年至2018 年的销量数据作为训练集,2019 年的月销量数据作为测试集。并结合零售户数量、零售户的购进次数、月平均价格、社会消费品零售总额等数据构建了本文使用的销量预测数据集,提供给算法模型做训练,进行月销量预测。为该模型引入了多个相关特征变量作为输入,用以提高模型的预测准确性。 企业所拥有的大量零售数据来源于不同的数据源,如业务系统、终端采集等。由于数据源之间的结构不同,需要先将数据进行预处理和整合汇总。此外原始特征数据的量纲相差较大,在数据输入模型前,需要对原始数据先进行归一化处理来消除量纲对结果分析的影响。 归一化公式如下: 其中,x为原始数值,xnew为归一化处理后的数值,xmax、xmin分别为数据中的最大值和最小值。 本文选用平均绝对误差(MAE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE)来评价本文提出的销量预测模型的效果[14],并对各个模型的预测结果进行对比与分析。 MAE、RMSE、MAPE的计算公式如下: 将改进的SSA-LSTM 模型与SSA-LSTM、传统LSTM 的预测结果进行对比。不同模型的预测结果如图3所示。 图3 不同模型预测结果对比 通过图3 和表1 可以看出,改进的SSA-LSTM 的MAE、RMSE、MAPE 指标均小于其他模型,模型精度最高。而单一的LSTM 模型预测相对较差,这是因为单一的LSTM 模型的超参数随机设定不当引起。当超参数经过算法的寻优调整之后,得到的模型具有更高的预测精度。改进的SSA-LSTM 其预测销量与真实销量相差较小,预测得到的销量曲线与实际销量曲线比较接近,预测拟合效果优于其他模型。说明改进的SSA-LSTM 模型预测效果更好,更适合用于销量的精准预测。 表1 预测模型误差对比 本文提出一种改进的SSA-LSTM 预测模型,优化了LSTM 的超参数搜索,解决了依靠人工调参耗时长且预测效果不佳的问题;结合海量零售户数据,有效地利用企业积累的数据,提升了预测的准确性。该模型对于商品的销量预测具有一定的应用价值。本文方法不仅能够为企业在经营决策方面提供有效依据,还可应用于其他领域的预测。在未来的工作中,可以获取更多影响销量的相关因素,加入更加丰富的特征变量来进一步提高预测效果。2 改进的SSA-LSTM模型
2.1 麻雀算法的改进
2.2 超参数优化
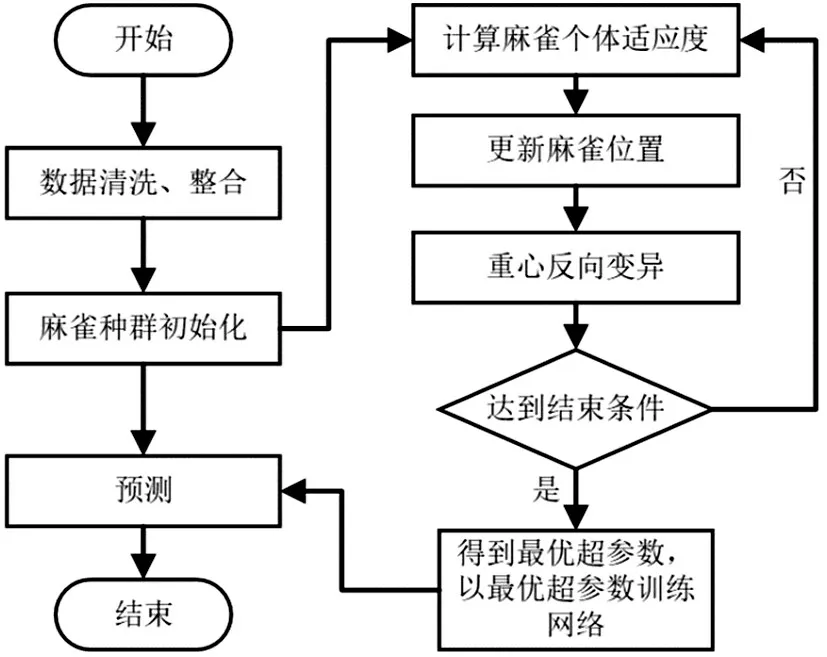
3 实验与分析
3.1 实验数据
3.2 评价指标
3.3 实验结果
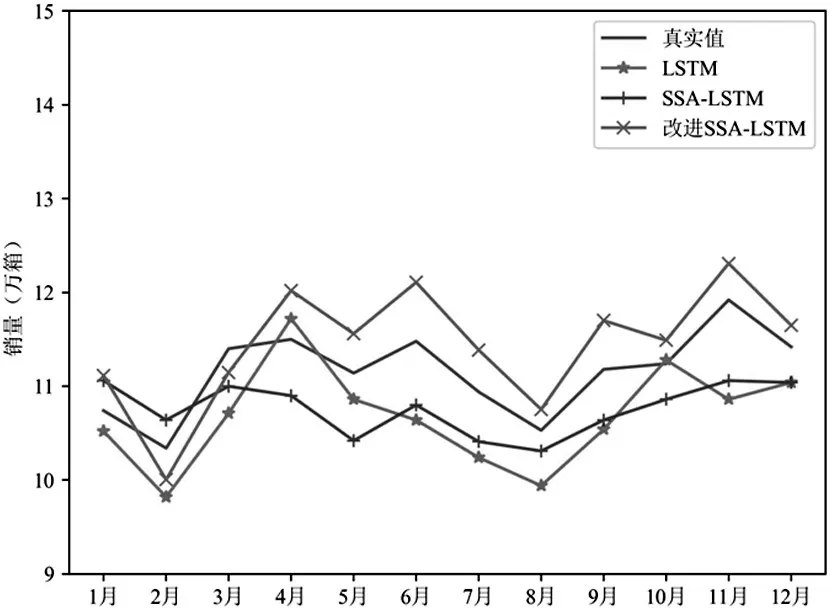
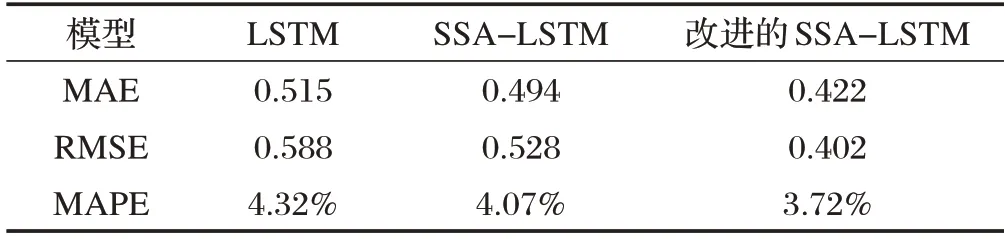
4 结束语
猜你喜欢
当代水产(2021年7期)2021-11-04 08:17:32
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:42
作文小学中年级(2019年10期)2019-11-04 00:39:52
汽车观察(2019年2期)2019-03-15 06:00:12
新世纪智能(高一语文)(2018年11期)2018-12-29 11:32:06
趣味(语文)(2018年2期)2018-05-26 09:17:55
山东青年(2016年1期)2016-02-28 14:25:22
家用汽车(2016年4期)2016-02-28 02:23:37
电测与仪表(2015年15期)2015-04-12 00:43:48
河北科技大学学报(2015年5期)2015-03-11 16:16:37
