
基于支持向量机的气温自记纸图像数字化
2023-10-21 02:36支亚京吴兴洋胡兴炜
计算机技术与发展 2023年10期
支亚京,汤 宁,吴兴洋,汪 华,胡兴炜,张 军
(1.贵州省气象信息中心,贵州 贵阳 550002;2.重庆众仁科技有限公司,重庆 400021)
0 引 言
实时历史气象资料是开展天气预警预报、气候预测评估、科学研究的基础,对国家应对全球气候变化至关重要[1-2]。气象要素自记迹线是记录气象要素时间上连续变化的历史资料,中国气象要素自记观测从20世纪50年代开始,包括气温、气压、相对湿度、降水、风等。在数字引领科技发展的趋势下,纸质历史气象要素自记资料数字化是解决其保护和应用的重要途径。
近年来,随着图像处理技术、模式识别以及机器学习等技术的发展,2004年,王伯民等研发的降水自记纸彩色扫描数字化[3-5]处理系统实现了降水曲线自动跟踪提取相关技术;2017年,李亚丽等采用基于边缘检测法[6-7]开发了EL型电接风自记纸迹线提取软件系统,两大系统软件帮助全国各省先后完成了降水自记纸、EL型电接风自记纸数字化处理,建立了全国气象观测站降水、风的历史分钟、小时资料数据集;薛改萍等[8]利用全国推广软件完成了西藏风自记纸数字化工作,并对提取数据进行分析研究;张一博等[9]利用人机交互全国推广软件对提取和质量检查过程中的难点进行分析与处理;岑瑶[10]、贺美萍[11]、马宁等[12]研究了常规图像处理技术在气压自记纸和气温自记纸数字化处理方面的应用,实现了气压和气温自记纸曲线数据的提取。上述软件系统只有降水自记纸和EL电接风自记纸迹线提取软件在全国推广,但在自记纸出现轻微扭曲、歪斜等情况时,需要人工对自记纸图像重新扫描,不能实现自动订正,也未对仪器本身的系统器差进行订正。针对以上问题,研发功能全面的气温自记迹线数字化软件十分必要。
贵州省气象信息中心按照气温自记纸数字化技术标准,提出了基于SVM和形态学机器学习算法,以此技术开发了气温自记迹线数字化提取软件,实现了气温自记迹线智能化跟踪提取、质量控制、检查修正以及产品生成,极大提高了数字化工作效率和生产质量,节约了人工资源成本。该文主要介绍气温自记迹线数字化提取软件的设计、处理流程、主要功能、关键技术和评估结果分析。
1 气温自记纸数字化提取软件介绍
1.1 软件设计基本思路和目标
基于SVM和形态学机器学习算法,构建图像识别技术,根据中国气象局提出的气温自记迹线提取技术规定,实现对气温自记迹线信息全面自动跟踪、提取,系统智能,操作简单,自动输出气温自记迹线数字化成果,即标准化分钟、小时数据文件,为后期气压自记迹线、相对湿度自记迹线等图像档案的数字化工作奠定技术基础。
1.2 软件系统结构
气温自记纸数字化软件采用客户端离线加工,以关系型数据库SQLite[13]为存储工具,运行在PC及其兼容环境上。主要功能包括批量预处理、检查修正和成品数据生成等模块,最终输出数字化成果提交国家局。气温自记迹线数字化提取软件结构如图1所示。
1.3 系统主要功能
软件系统包括:批量处理、检查修正、成品数据等模块。
(1)A文件导入是用于导入A文件气温数据,根据N和I字段联合判断定时观测时次,供数字化自动识别和对比。其中,如果A文件中存在I7,I8或者N9要素标识符,则默认有北京时08、14、20点三次定时观测,其他则为02、08、14、20点四次定时观测。且在1960年6月(含6月)之前的定时观测时间差1小时,1960年6月前为01、07、13、19时,其后为02、08、14、20时。
(2)批量处理模块是对选择自记纸图像逐张迹线自动提取。第一步:加载图像列表,系统自动对图像的基本要素(文件名、日期是否连续、图像分辨率以及倾斜度等)进行检查;第二步:设置迹线、网格的开始结束时间和观测值范围,用于创建气温自记纸的初始坐标系;第三步:批量自动提取,点击开始自动提取后,界面显示不同提取状态的文件数量,同时可以利用异常信息导出异常日期列表。
(3)检查修正模块是对批量提取的迹线数据进行回放检查对比,手动修改提取有误的迹线数据,针对不同情况合理添加备注,并保存到迹线对应的txt文件。主要步骤包括:迹线矫正、时间记号线矫正、器差订正、A文件气温对比。
(4)成品数据模块是将经过检查修正的数据转换成标准数据进行输出,得到精细化小时、分钟气温数据。第一步:将数据库中同站号气温迹线提取数据进行合并,包括分钟小时数据、图片、txt数据文件;第二步:将数据转换为标准数据。
(5)图像矫正模块是对台站异常数据如倾斜、扭曲的自记纸进行手动矫正,通过手动的上下、左右拉伸获取规范的自记纸图片,并替换原始异常图片。
2 核心算法
气温自记迹线自动识别提取原理主要包括以下三部分:边框识别、迹线识别和时间记号线识别。下面简单介绍边框识别和时间记号线识别原理,重点介绍基于支持向量机和形态学的迹线识别方法。
2.1 边框提取识别原理
根据前期对贵州省多年多站的气温自记纸图像进行红色(R)通道、绿色(G)通道、蓝色(B)通道三个通道像素统计结果显示,R通道像素值较大、B通道像素值较小的点对应了橘黄色表格线点,即对应边框线的像素点。
根据边框线呈横向、竖向分布特征,软件设计采用横向和竖向投影方式确定各方向边框位置,图2中对应波峰位置分别对应竖向和横向表格线位置。

图2 横向竖向表格线位置
2.2 时间记号线识别原理
时间记号线是迹线开始结束时间,首先计算定时观测时次参考位置,在定时观测时次左右15分钟区间内识别竖直短竖线位置即为时间记号点位置,对每个小矩形框竖向投影,找到最小的列,再求与迹线的交点为准时间记号点。时间起始终止位置如图3所示。
但是根据时间记号线平行于网格线的基本特征,位于表格上下两端的时间记号线竖向投影往往存在一定偏差。为进一步矫正时间记号线精度,软件在准时间记号点左右两分钟范围内,再次进行竖向投影,找出投影最小列即为时间记号点所在列,再次重新计算与迹线的交点即为时间记号点。
2.3 基于支持向量机和形态学的迹线自动识别方法
基于支持向量机和形态学的气温自记纸迹线自动识别方法流程如图4所示。该方法第一步是去除图像大部分背景像素;第二步是将气温自记纸图像进行灰度化处理,形成灰度化像素值,然后采用对通道像素值进行伽马变换对比度拉伸,增强图像局部对比度用以扩大迹线点与表格线点和噪声点之间的差别,形成自适应增强像素值;第三步是输入图像中每个点的原始RGB通道值、灰度值、自适应增强像素值和R-B通道值,由支持向量机模型分类器进行分类,并获得初步迹线像素值集合;第四步是采用形态学方法对SVM分类器识别结果进行形态噪声去除,确定最终迹线像素点。

图4 气温自记纸迹线自动识别流程
(1)去除图像背景像素。利用Otsu二值化方法[14-15]去除图像大部分背景像素,这种方法一方面减少数据计算量,提升计算速度;另一方面能够减少多余图像部分对算法本身的干扰。
(2)气温自记纸图像灰度化。由于最小均值法得到的灰度图像迹线和噪声像素间对比度较大,且迹线像素间的灰度方差较小,迹线像素点基本得以保留,因此,本软件中采用最小均值法将气温自记纸彩色图像转换为灰度图像,其计算公式如公式[16-17](1)所示。
(1)
式中,fi(x,y)分别表示R、G、B三个通道彩色分量图像,fgray(x,y)表示变换后的灰度图像。
(3)增强图像局部对比度。由于局部对比度增强后,迹线像素点与噪声像素点更容易区分,为了有效抑制背景像素点对图像对比度的影响,本软件定义气温自记纸图像的局部对比度C(x,y)如公式[18-21](2)所示。
(2)
式中,fmax(x,y)和fmin(x,y)分别表示图像在以(x,y)为中心的领域内的灰度最大值和最小值。
(4)建立SVM分类器模型。分为以下两步:第一步是构建样本集;第二步是构建SVM分类器模型。(a)构建样本集。分类样本数据主要包括:表格点、迹线点、噪声点等对应的邻域像素RGB通道值、灰度值、自适应增强值和R-B通道值,构造N*5训练集、测试集。首先,收集山东、江西、宁夏、黑龙江、贵州、重庆等多省(1960年-2003年)气温自记纸图像进行步骤1~步骤3的预处理;其次,形成N*5点序列,取70%作为训练集,10%作为验证集,剩余20%作为测试集。(b)构建SVM分类器模型。选择多项式核函数,将数据集映射到高维特征空间,利用SVM机器学习算法在训练集特征空间中找出迹线点和表格线点的最优分类超平面,形成判断迹线点和表格线点的分类函数;将验证集中的像素值集合输入分类函数进行参数调优;将测试集中的像素值集合输入调优后的分类函数,评价模型的准确性,并获取初始的迹线数据集合。
(5)去除形态噪声。通过形态学方法对表格线和迹线的识别结果进行连通域形态特征检测,如每个连通域面积、线性度、周长面积比、与主连通域平均距离等,通过以上特征判断连通域是否为噪声点,进一步去除图像中噪声数据,剩余像素点则为迹线点坐标。
3 应用效果分析
对国家局纸质资料数字化技术组下发的54749、56079、50136、53619、57883等5站约2 750张气温自记纸图像进行气温自记迹线数字化,其中各站资料时间分别为1964年12月-2007年10月、1962年1月-2004年11月、1963年1月-2004年11月、1967年1月-2006年11月、1966年1月-2006年11月。将A文件记录的气温值视为基准值,迹线提取计算值与A文件中记录的小时气温、日最高气温和日最低气温值进行对比分析,计算其平均偏差,评估分析软件的迹线自动识别效率以及计算值的准确性,针对差异较大的进行原因分析。
3.1 气温记录对比分析
从表1可以看出,计算值与A文件数据对比呈偏大趋势,平均偏差在0.07 ℃~0.64 ℃之间。总体而言,小时计算值与原值的差异小于日极值气温计算值与原值的差异。

表1 日最高/日最低/定时气温对比
分析差异较大的原因主要有以下几类:(1)有部分迹线已经设置为缺测了,统计与A文件记录误差的时候未排除这种情况,将其视为误差进行统计,这部分原因占90%以上;(2)50136站1989年5月命名错误引起较大误差;(3)A极值日界为20点,实际小时中没有完整时间段,并不存在当日的日极值数据。
3.2 迹线自动识别效率
通过统计分析提取迹线节点人工修正情况,即以站、时间为单位统计修正率。修正率公式如式(3)所示,人工修正率计算结果如表2所示。
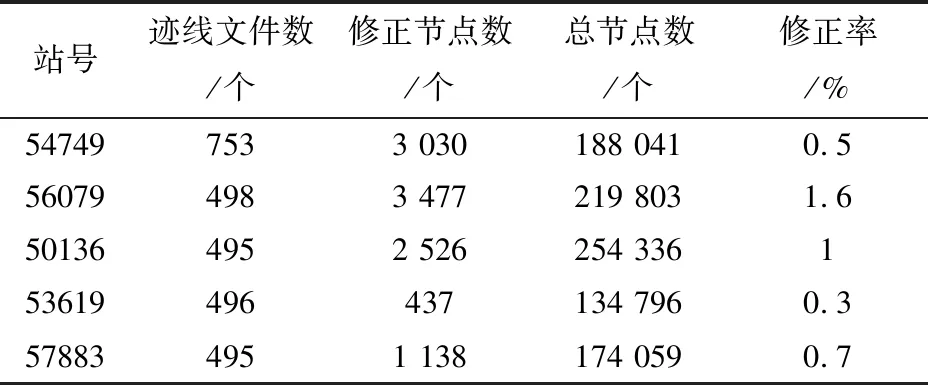
表2 软件的迹线人工修正率统计
修正率=修正节点数量/节点总数量
(3)
由表2可以看出,自动识别人工修正率在2%以下,表明软件的迹线自动识别效率高,减轻人工处理的工作量,在满足技术要求的前提下,提升了气温自记纸数字化效率。
3.3 图像矫正效果
按照以站点为单位统计分析待数字化的气温自记纸图像中倾斜、扭曲、被挤压等异常图像个数、自动矫正的图像个数和人工手动矫正的图像个数,统计结果如表3所示。
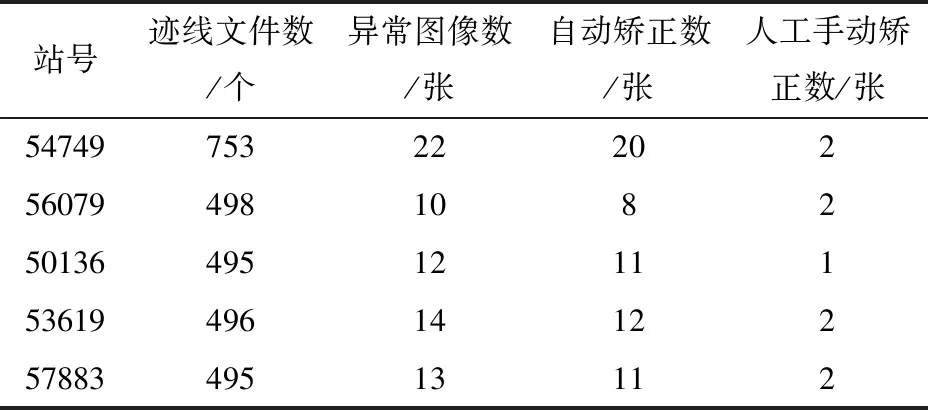
表3 图像矫正个数统计
由表3可以看出,一是通过软件的图像矫正功能可以实现异常图像矫正率达到100%,其中,通过软件自动矫正率为80%以上,通过软件手动矫正率为20%以下(表2中的人工修正50%的工作量为软件人工手动矫正工作);二是异常图像占比为2%左右(站点资料保存较好、扫描图像较好的情况下),以贵州省为例,总的气温自记纸图像数约为147.9万张,预估异常图像个数为29 580张,如重新扫描需要耗费很多时间。通过以上表明该软件对于异常图像无需再重新人工扫描就可以实现图像迹线正常提取,帮助业务人员减少了大量时间,提高了工作效率。
4 结束语
该文简要介绍了气温自记纸数字化软件系统设计目标和思路、设计结构和功能,以及基于SVM和形态学算法的迹线提取算法,通过对比A文件数据差异、分析差异原因以及软件的迹线自动识别效率等,结果表明,一是SVM机器学习算法对小样本下的分类回归问题具有准确的识别率;二是与前期开发的降水自记纸、EL电接风自记纸数字化软件相比,实现了自记纸轻微扭曲、歪斜等情况不需人工对自记纸图像重新扫描,可以通过自记纸本身微调自动订正和器差订正,软件能够满足气温自记纸迹线提取对数据质量和精度的要求。但是对于纸张质量差、墨迹污染褪色以及图像污渍严重、字迹特别多的图像数字化仍需进一步研究。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
今日农业(2021年2期)2021-03-19
中国自行车(2018年2期)2018-05-09
中国工作犬业(2017年8期)2017-08-22
中国工作犬业(2016年12期)2017-01-04
福建人(2016年6期)2016-10-25
小雪花·成长指南(2015年10期)2015-10-23
Coco薇(2015年7期)2015-08-13
中国医疗美容(2015年2期)2015-07-19
