
基于注意力机制藏文乌金体古籍文字识别研究
2023-10-21 02:36龙炳鑫
计算机技术与发展 2023年10期
童 攀,龙炳鑫,拥 措*
(1.西藏大学 信息科学技术学院,西藏 拉萨 850000;2.西藏大学 藏文信息技术人工智能西藏自治区重点实验室,西藏 拉萨 850000;3.西藏大学 藏文信息技术教育部工程研究中心,西藏 拉萨 850000)
0 引 言
藏文乌金体古籍文字识别是计算机视觉领域的一个难题,同时也是国内外文献资源数字化领域的一个重要研究方向。藏文乌金体古籍是藏族文化的重要组成成果,同时也是中华宝贵文化遗产的一部分,藏文古籍的数字化,对研究藏族文化教育,藏学研究、传承优秀传统文化等方面都发挥着极其重要的作用。目前,多数藏文乌金体古籍识别算法在清晰的藏文乌金体古籍图像中能取得较好的识别效果,而对于藏文乌金体古籍中存在的文字粘连和背景复杂的图像,其识别效果有待进一步提高。
国内外关于藏文古籍识别的研究相对稀少。20世纪90年代日本情报处理学会为了研究藏文佛教典籍,设立了藏文字符识别项目,1996年完成了识别系统[1]。该系统并没有解决藏文古籍图像中的文字切分问题,需要人工切分,并且只完成了字符识别功能。为了解决藏文古籍字切分的问题,Hedayati等人[2]首次将广义隐马尔可夫模型应用在藏文古籍识别流程中。西藏大学赵栋材等人[3]首次将反向传播网络应用在藏文古籍文字识别研究。为了增加识别效果,西藏大学高飞[4]进行藏文古籍图像二值化研究。随着深度学习技术的不断发展,藏文古籍文字识别有了更多的研究。2018年,王筱娟[5]首次将深度神经网络应用于藏文古籍相似字的识别,该方法有效提高了在藏文乌金体古籍相似字符的识别准确率。2019年,西北民族大学李振江[6]提出基于边缘对比的二值化方法,西北民族大学韩跃辉[7]进行基于色彩空间转换的二值化研究。同年李振江[8]提出利用基线信息进行字符识别方法,将藏字分为上下两部分进行识别,提高了藏文字符的识别准确率。2021年,由于藏文古籍数据稀少且难以收集的问题,西藏大学仁青东主[9]进行了藏文古籍文字识别数据的合成方法研究,一定程度上解决了藏文古籍训练规模小的问题。在藏文古籍的系统应用中,韩跃辉[10]采用基于卷积神经网络 (Convolutional Neural Network,CNN)模型的字丁识别算法,设计并完成了藏文古籍识别系统,提高了藏文古籍7 240类字丁的识别率。胡鹏飞[11]采用藏文文本行数据集合成的方法以及端到端的深度学习模型,实现了文本行图像的整行识别。仁青东主[12]使用残差网络和双向循环长短期记忆循环神经网络以及基于滑动窗的行识别技术,解决了行文字较长的问题。2021年,西藏大学完成承担的国家重点研发项目,设计并完成了藏文古籍木刻本版面分析于文字识别系统,可以完成对整页藏文乌金体古籍的识别。
现有的藏文乌金体古籍文字识别中的问题包括:(1)藏文乌金体古籍文字识别数据集资源稀少;(2)藏文乌金体古籍文字粘连图像和背景复杂图像识别效果不佳;(3)缺少一个行之有效的藏文识别评测指标。针对这些问题,该文的主要贡献为:(1)提出以藏文字丁为基本单位的藏文字丁准确率评测标准,并应用在西藏大学国家重点研发项目中;(2)在文献[13]提出的Encoder-Decoder模型以及文献[14]提出的注意力机制的基础上设计了识别模型算法,该模型在只有616张藏文乌金体古籍图像作为数据集的情况下,以藏文字丁准确率为标准取得了90.55%的字丁识别效果。
1 相关工作
1.1 文字识别
近些年来,主流的文字识别方法主要分为两种:基于连接时域分类(Connectionist Temporal Classification,CTC)的识别方法(如文献[15])和基于注意力机制的识别方法。
基于CTC的识别方法的框架模型,首先使用卷积神经网络对图像进行视觉特征提取,再将视觉特征沿着宽度方向进行切片以形成特征序列,将特征序列输入至序列建模之中,如RNN。再生成具有序列上下文的特征序列,最后使用CTC解码每个序列特征进行字符类别预测并基于动态规划对预测结果进行去重。该识别方法只依赖于视觉特征和视觉特征之间的序列关系,所以面对模糊文本和低质量图像等难识别样本时性能不好。
基于注意力机制的识别算法,同样是先使用卷积神经网络进行图像特征提取,然后使用编码器生成具有序列上下文信息的特征序列,使用注意力机制取所有特征序列为键和值,取解码器中前一个时间步的预测为查询进行注意力权重的计算,并对特征序列进行加权求和生成当前时间的解码特征,将其送入解码器中进行结果预测,持续过程直到输出终止符或超过预定时间步。该方法可以自动寻找需要预测的文本区域,并将注意力集中在图像中字符对应像素点位置,显著地提高了模型的准确率。
1.2 藏文特点


图1 现代藏文音节结构

图2 现代藏文字丁结构
由于受印度文化的影响,藏文中还存在特殊的梵文藏文转写形式,梵文藏文转写并不符合藏文文法规则,而是符合梵文的文法规则,在藏文古籍文献、藏文新闻等中时有出现,如图3所示。在识别中对藏文字进行字丁切分的主要目的有:

图3 梵文藏文转写
(1)保持藏文字的空间结构信息;
(2)简化识别任务。
2 模型算法
2.1 基于注意力机制的卷积循环神经网络
模型使用编码器-解码器(Encoder-Decoder)的模型结构,如图4所示,其中x表示输入信息,c表示通过Encoder层输出的语义编码,y表示通过Decoder层获得的识别结果。该结构可以有效地将长度不同的图像特征与之对应的文本序列进行对齐,同时注意力机制会自动寻找需要预测的文本区域,将注意力集中在图像中字符对应的像素点位置从而显著提高模型的准确率。
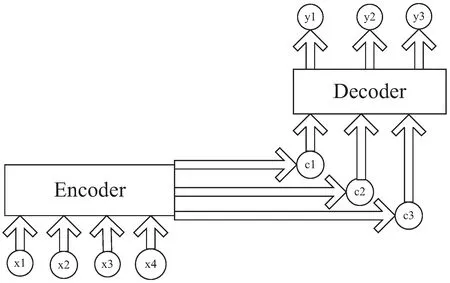
图4 编码器-解码器结构
该文使用的基于注意力机制的卷积循环神经网络(CRNN+ATTENTION)识别算法流程如图5所示。该算法可以支持的字丁长度是有限的,根据训练结果,该识别算法可识别的字丁个数为25。网络对于输入图像的长宽并没有限制。通过对收集的藏文古籍乌金体数据的藏文字丁统计共获得了1 353个藏文字丁,并以此作为网络支持的类别数。

图5 藏文古籍图像识别流程
在网络的前端,卷积神经网络自动从输入的图像中提取特征,将特征结果送入双向长短期记忆(Bidirectional Long Short Term Memory,Bi-LSTM)网络进行特征增强。接着注意力模型根据循环神经网络(Recurrent Neural Network,RNN)神经元的隐藏状态及上一时刻的输出计算出注意力权重,最后将卷积神经网络输出的特征图与注意力权重结合起来,输入循环神经网络进行编解码后,得到整个字符集的概率分布,最后直接提取概率最高的编号所对应的字符作为最后的识别结果。
主要模型架构包括以下两个方面:
(1)编码器。
第一步,使用CNN网络提取输入图像的特征序列,输出为特征矩阵。在特征提取过程,imgH(图像高度)方向经过4个pooling和1个卷积(Valid模式),imgW(图像宽度)方向经过2个pooling和1个卷积(Valid模式),原图高度变为imgH/32,原图宽度变为 imgW/4+1。获得图像的特征矩阵。
参数设置如表1所示。其中K、S和P分别是卷积核(kernel size)、步长(stride)和填充大小(padding size)。BatchNorm2d为参与特征的通道数。

表1 卷积层参数
第二步,使用Bi-LSTM的方法对卷积层结果进行前后序列特征的增强。BLSTM在LSTM的基础上,进一步学习上下文特征,结合了输入序列在前向和后向两个方向上的信息。对于t时刻的输出,前向LSTM层具有输入序列中t时刻以及之前时刻的信息,而后向LSTM层中具有输入序列中t时刻以及之后时刻的信息。
循环参数设置如表2所示。其中nIn是输入特征数,nHidden是LSTM中隐藏层的维度,Bidirectional表示是否使用双向LSTM,nOut是输出特征数。

表2 循环层参数
(2)解码器。
第一步,计算注意力权重之前先对前一次的输出进行词嵌入,并进行特征融合,然后计算注意力权重。
注意力权重的计算需要三个指定的输入Q(query),K(key),V(value),分别表示查询,键值,值。然后通过计算得到注意力的权重结果。可以将其归纳为三个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二阶段对第一阶段的原始分值进行归一化处理;第三个阶段根据权重系数对Value进行加权求和。第一阶段计算Query和Key某个的相似性,使用点向量积的方法进行计算。公式如下:
Sim(Query,Keyi)=Query*Keyi,i∈I
(1)
第二阶段一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。公式如下:
(2)
式中,ai为Valuei对应的权重系数,第三阶段将每一个ai进行加权求和即可获得注意力的权重,公式如下:
(3)
第二步,将卷积神经网络输出的特征图与注意力权重结合起来,根据Attention权重合并成1个最大概率的字符。
第三步,输入循环神经网络进行编解码后,得到整个字符集的概率分布,直接提取概率最高的编号所对应的字符作为最后的识别结果。
参数设置如表3所示。其中out_size表示字典的维度,Dropout表示每个神经元不被激活的可能性。

表3 转录层参数
2.2 评测标准
对于藏文文字识别,目前并没有一个固定的评测标准。该文采取编辑距离作为藏文古籍乌金体文字识别的准确率计算标准。编辑距离可以充分反映出藏文古籍乌金体识别中出现的错识,漏识以及多识的情况。有利于对识别结果进行分析。藏文与中英文不同,每一个中英文都有对应的编码,而一个藏字是由多个藏文字符编码组成的,简单的理解就是一个藏字就是多个藏文字符组合在一起的字符串,不易于比较且计算量较大。考虑藏文文字的结构特点,该文以藏文字丁为基本单位进行准确率计算。
提出的藏文字丁准确率算法的计算公式如下所示:
Acc=rd/(rd+ld)
(4)
式中,Acc是字丁准确率,rd是字丁匹配中对应位置正确的字丁个数,ld是字丁匹配中错误的字丁个数,包括识别中出现的多识,漏识,错识三种情况。rd+ld是总共的比较次数,其计算结果并不一定等于标注文件的字丁个数。
3 实 验
实验运行环境:CPU 12th Gen Intel(R) Core(TM) i5-12400F 2.50 GHz;GPU NVIDIA GeForce RTX 3060;内存12 G;程序为Linux系统pytorch框架编写运行。
以500张整页藏文乌金体古籍作为训练集,116张藏文乌金体古籍作为测试集。实验训练参数如表4所示。图6为所使用的藏文乌金体古籍样本图。正常整页藏文乌金体古籍识别流程应该是先进行藏文古籍文本检测以及文本行切分处理,文本行切分处理结果送入文字识别模块最后将识别结果进行后处理。该文主要说明识别模型的识别效果,故文本检测,文本行切分处理和识别后处理这里不详细解释。

表4 训练参数

图6 藏文古籍图像样本图
为了展示各模型的藏文乌金体古籍识别效果,特意截取两小块识别难度高的藏文乌金体古籍文本行图像,如图7所示,图8为各模型针对两小块的识别结果。图9为文中模型在116张整页藏文乌金体古籍中随机截取300个文本块的识别准确率曲线。

(a)文字粘连图像

图8 各模型识别结果

图9 CRNN+ATTENTION识别曲线

将文中识别模型与文献[16]提出的CRNN+CTC识别模型以及文献[17]提出的基于ABINET识别模型进行实验对比。同时为了进一步验证采用的注意力机制有效提高了藏文乌金体古籍识别效果,在文中算法基础上删去注意力机制进行实验,如表5、表6所示,分别为文中模型与对比模型,文中模型与删去注意力机制的文中模型进行500 epoch训练之后使用116张样本测试获得的平均字丁准确率。

表5 不同算法识别结果对比

表6 注意力机制的文中模型对比
由表5可以看出,在使用小样本的文字粘连和背景复杂的藏文乌金体古籍图像进行模型训练情况下,引入注意力机制能有效提高藏文乌金体古籍的识别准确率,使用CTC算法的模型其识别准确率明显低于基于注意力机制的识别模型。同时文中模型与去掉注意力机制的文中模型进行比较,充分说明注意力机制能有效提高对藏文乌金体古籍中文字粘连和背景复杂图像的识别效果。文中模型在少样本的情况下,能充分利用样本整体的上下文信息,并取得了较好的效果。同时,文中模型相比其他模型,在提升识别精度的同时,有效压缩了模型的大小,提升了算法的实用价值。
4 结束语
针对藏文乌金体古籍图像中的背景复杂和文字粘连的识别问题,采用卷积循环神经网络CRNN与Attention注意力机制相结合的模型解决行文字粘连问题;以动态规划的方法结合藏文字丁结构设计出来的藏文字丁识别准确率为评测指标;以统计藏文古籍中单独出现的藏文字丁为识别字典。通过与CRNN+CTC模型和ABiNet模型在相同条件下的实验结果进行对比,文中模型的识别效果最好,其字丁准确率为90.55%,在只有500张藏文乌金体古籍进行模型训练的情况下取得了高效的识别结果。通过对文中模型测试的结果分析来看,后续计划训练藏文古籍语言模型以及添加藏文文法规则的方法来对识别结果进行后处理,以提高最终的识别效果。
猜你喜欢
VOGUE服饰与美容(2022年5期)2022-05-01
小猕猴学习画刊·下半月(2022年2期)2022-04-16
——探访煤炭博物馆
奇妙博物馆(2022年3期)2022-03-23
汉字汉语研究(2021年3期)2021-11-24
天一阁文丛(2020年0期)2020-11-05
布达拉(2020年3期)2020-04-13
西夏学(2019年1期)2019-02-10
中成药(2018年12期)2018-12-29
天一阁文丛(2018年0期)2018-11-29
金桥(2017年5期)2017-07-05
