
一种基于注意力机制和上下文感知的三维目标检测网络
2023-10-21 03:40张吴冉李菲菲
电子科技 2023年10期
张吴冉,李菲菲
(上海理工大学 光电信息与计算机工程学院,上海 200093)
相较于基于纯点云的处理方式,体柱(Pillars)编码方法可节省更多的运算空间,具备更快的计算速度。体柱化模块首先沿着X-Y坐标平面将点云均匀分割成柱体形式,然后对体柱内的点云进行随机采样,保留一定量的点云,最后使用PointNet网络逐点的特征抽象,并接入均值池化或最大池化获取体柱级特征表示。体柱特征生成后通过鸟瞰视角映射将体柱特征从三维空间映射到二维空间,由此转换为基于二维图像的处理过程。体柱规则模块在随机采样过程中会丢弃一些细节信息,影响检测效果。二维伪图特征提取网络将多尺度输出特征堆叠融合,不仅没有关注多尺度特征的相关性,还忽视了特征冗余导致的空间杂乱问题。针对以上诸多限制,借鉴文献[5~8],本文提出了一种新型基于注意力机制和上下文感知的三维目标检测网络。网络架构如图1所示。此网络具有3个核心模块:点云双向注意力机制、上下文感知模块以及注意力导向模块。
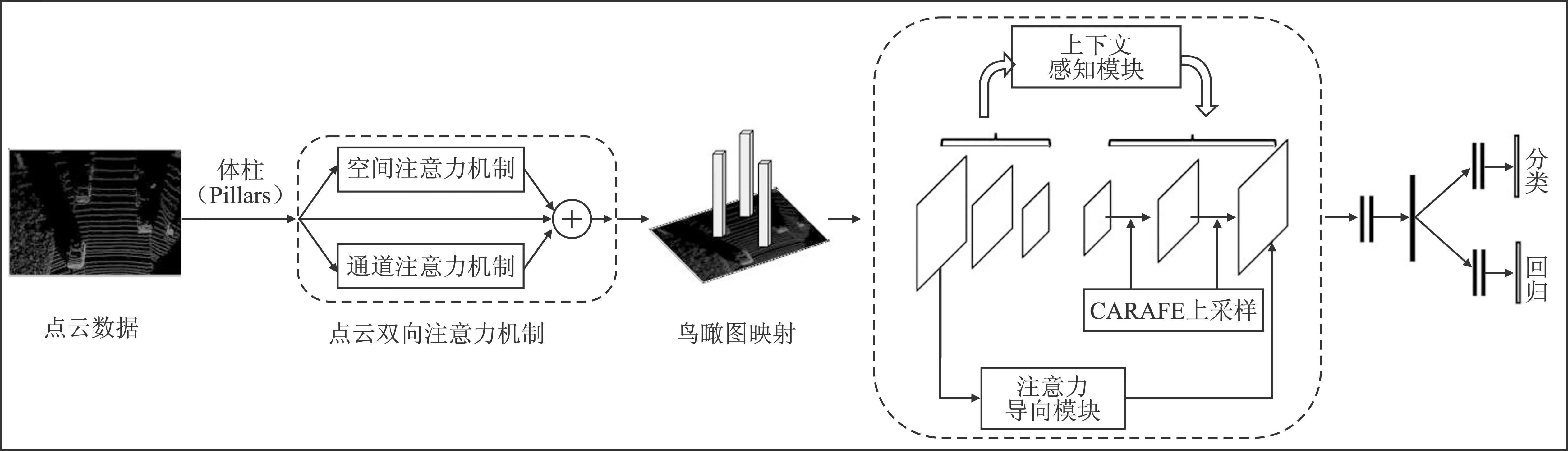
图1 三维检测网络结构Figure 1. The structure of 3D object detection network
1)点云双向注意力机制(Double Attention Mechanism,DAM)。在体柱编码模块中,增加联合空间注意力和通道注意力的点云双向注意力机制,通过分配权重的方式有辨别地凸显重要点数据,缓解背景点带来的干扰。
2)上下文感知模块(CAM)。通过增加特征金字塔[9]网络(FPN)对鸟瞰图进行多尺度特征处理,并在FPN结构上增加上下文感知模块,捕捉多比例上下文语义,为高维特征增加多尺度信息感知能力。
3)注意力导向模块(AGM)。特征在经过FPN和上下文感知模块融合处理后,冗余的融合特征在一定程度上会模糊位置关系。为了缓解融合特征导致的空间偏差问题,该模块将注意力机制作用于输入源特征,生成空间信息清晰的权重导向图,引导网络发现输出特征的空间位置关系。
1 网络模型结构
1.1 体柱规则模块
点云可由M行4列的矩阵表示。其中,M表示点的数量,矩阵的4列分别是三维空间坐标(x,y,z)和点云反射强度r。基于点云的体柱规则化模块具体流程如下:
1)点云规则化。将点云离散到X-Y-Z坐标系下,均匀分割X-Y平面,不对Z轴方向的点云作分割处理,获得点柱形式的集合P,每个点柱内均包含一定数量的点。此方式减少了高度维度的参数计算,加快了检测网络的推理效率。虽然损失了高度信息,导致精度略有下降,但是取缔了稀疏算子[10]的使用,直接使用二维卷积提取算法,方便网络嵌入到视觉硬件系统。
2)特征扩充。首先,逐体柱求取所有点的算数平均值,计算出所有点到该值的距离(xc,yc,zc),求出X-Y平面上体柱底面中心坐标,计算所有点到该中心的偏移值(xp,yp,zp);然后,将原始的四维特征扩充到九维特征(x,y,z,r,xc,yc,zc,xp,yp,zp)表示。
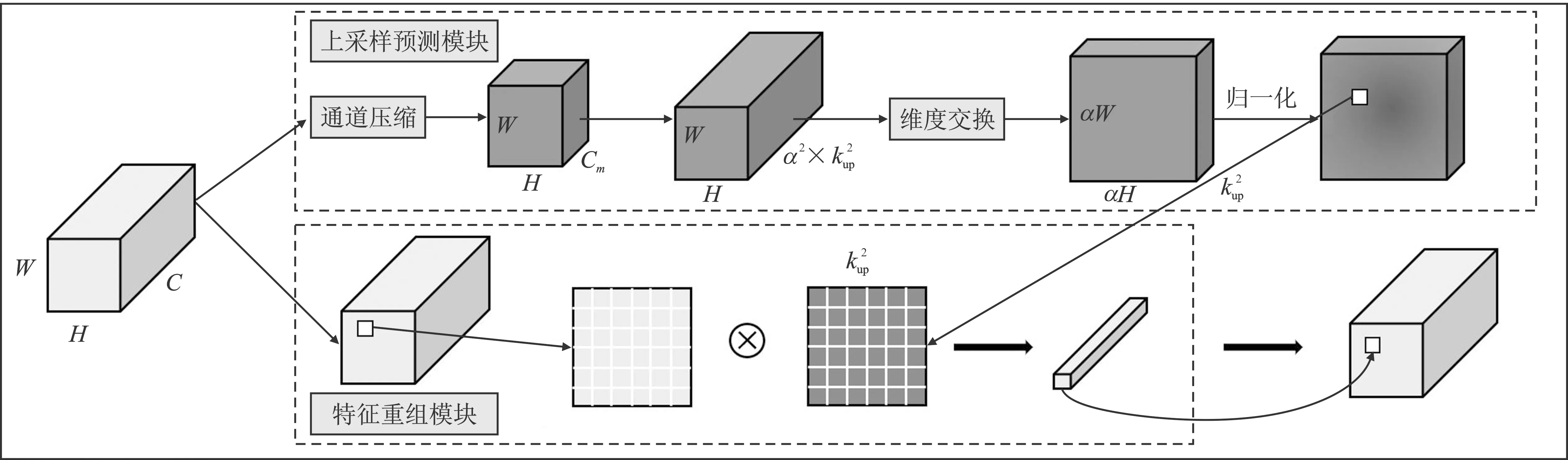
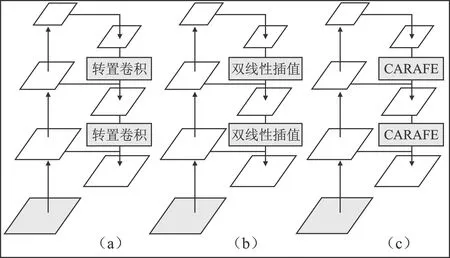
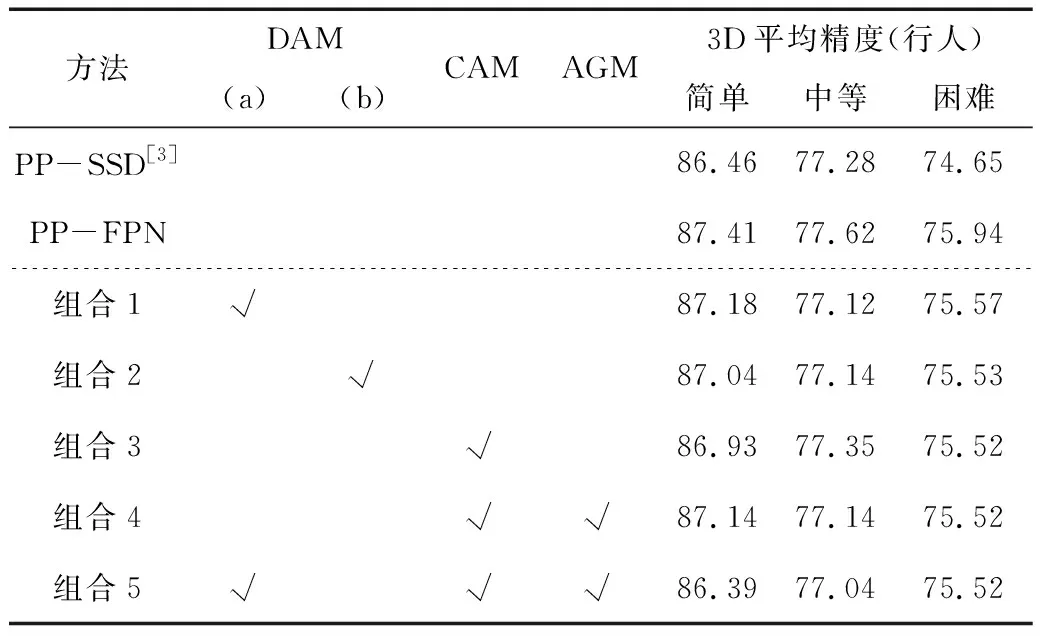
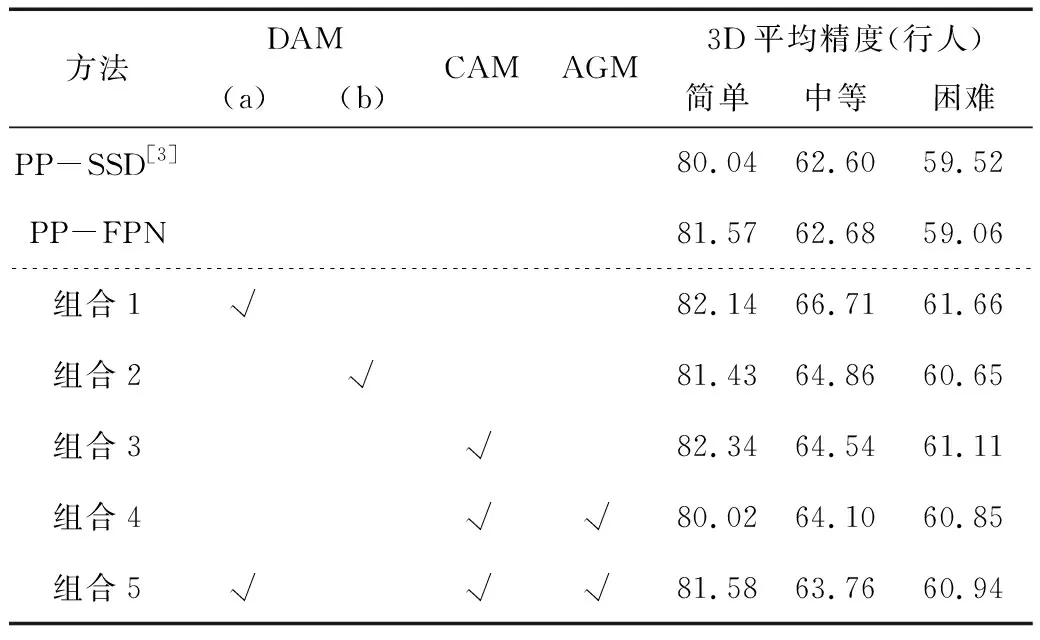
3)张量生成。由于点云具有稀疏性,空体柱数量占比较高,为降低计算复杂度,设置采样体柱数量为P,固定体柱内点数为N。若体柱内点数>N,则使用随机采样进行缩减,若点数 4)点特征网络。使用由线性层和BN层和ReLU组成的简化PointNet网络对D维特征进行抽象,生成尺度为C×P×N的新张量,沿着N维度使用最大或均值池化操作,最终得到尺度为C×P的张量。 5)伪图生成。把体柱网格单元设为单位像素,使用体柱P的索引值将C×P大小的张量返回原始坐标,沿着P维度扩展,输出大小为C×H×W的二维伪图。 在三维点云场景中,小目标和远目标的采样点数量较少,而且随着特征的不断下采样,这些目标会失去更多的有效信息。点云场景中还存在较严重的遮挡问题,目标与目标、目标与背景之间相互遮挡。在杂乱的三维空间环境中,背景占据更多区域,这时通过网络学习会获取大量背景信息,导致检测器对前景目标的检测性能下降。为缓解以上问题,本文参考卷积块注意力模块(Convolutional Block Attention Module,CBAM)的二维混合注意力机制和文献[11~12]的三维注意力机制的构成原理,设计了点云双向注意力机制(DAM)。点云双向注意力机制模块由面向点的空间注意力机制和面向特征的通道注意力机制两个子模块组成。该注意力机制可通过分析体柱内点的位置关系和通道关系关注体柱内重要区域,同时抑制不重要区域,进一步增强体柱特征的表达能力。点云双向注意力机制模块结构如图2所示。 图2 点云双向注意力机制结构(a)并联双向注意力机制 (b)串联双向注意力机制Figure 2. The structure of double attention mechanism(a)The double attention mechanism of parallel mode (b)The double attention mechanism of series mode 网络以B×C×N大小的点云张量作为输入数据。其中,B表示batch_size数量,C表示特征维度,N表示体柱内点的数量。 1.2.1 空间注意力机制 (1) 其中,MLPH→L表示多层感知机从高维到低维的映射。 1.2.2 通道注意力机制 (2) 其中,MLPH→H表示多层感知机的同维映射。 点云双向注意力机制通过并联和串联两种方式于体柱中实现。并联双向注意力如图2(a)所示。将输入数据并级处理,获取通道域和空间域注意力权值,将两域权值和输入特征分别作乘法和加和操作,具体如式(3)所示。 (3) 串联双向注意力机制如图2(b)所示。首先使用通道注意力机制对输入数据处理;然后将通道域的权值与输入相乘获得新特征;最后再输送到空间注意力机制作同样处理。具体如式(4)所示。 (4) 点云双向注意力机制对体柱内所有点进行增强处理后,输出更具分辨性的点特征;然后使用简化的PointNet网络对体柱内点进行特征扩充,经最大池化函数作用后得到体柱级特征;再使用Scatter算子将体柱级特征返回初始位置,生成二维伪图。 原特征提取网络首先对二维伪图进行深度卷积特征提取,输出3种尺度的特征;然后使用转置卷积算法将其统一尺度;最后堆叠输送到检测模块。 多尺度特征堆叠融合会导致上下文信息过度冗余,不仅影响网络推理速度,且干扰正常检测。针对该问题,本文采用FPN的融合策略,将特征提取层的最终输出进行持续上采样,和特征提取层的特征逐层相加融合,使多尺度特征得以复用,缓解了堆叠操作带来的冗余效应和推理速度问题。FPN结构通过使用转置卷积算子和双线性插值法对特征进行上采样。双线性插值法通过利用像素点的位置设计上采样核,感知域通常较小,对特征周围语义信息利用率低。转置卷积算子对特征图的所有位置均使用相同的上采样核,不能有效捕捉特征空间内信息的变化。本文插入带有内容感知功能的上采样算子:CARAFE[13](Content Aware Reassembly of Features)。此算子基于输入的语义信息设计采样范围较大的动态核,然后通过生成的动态核参数进一步利用特征图周围的内容信息,可改善上采样后的特征质量。CARAFE算子分别由上采样预测模块和特征重组模块组成。 1.3.1 上采样预测模块 图3 CARAFE结构Figure 3. The structure of CARAFE 1.3.2 特征重组模块 对于上一阶段输出的上采样核,需要将其映射回输入特征图。取出两者对应区域,彼此作矩阵乘法,输出上采样后的新特征,结构如图3所示。 本文分别使用双线性插值、转置卷积和CARAFE这3种上采样方式实现二维伪图的尺度恢复,网络架构如图4所示,详细实验见章节2.2.1。 图4 FPN结构(a)转置卷积 (b)双线性插值 (c)CARAFE上采样Figure 4.The structure of FPN(a)Transposed convolution (b)Bilinear interpolation (c)Up-sampling of CARAFE 图5 上下文感知模块结构Figure 5. The structure of context awareness module (5) 将上下文感知模块输出的3组特征和FPN上采样获取的3组特征进行堆叠(Concatenate),输入到1×1卷积消除特征重叠效应,再使用上采样算法将3种尺度特征恢复成相同大小并逐层相加融合,如式(6)所示。 (6) 上下文感知模块密集融合输出多组特征,获取具有多尺度感受野信息的高维语义特征,但冗余的特征融合会导致空间位置信息杂乱。为缓解冗余上下文对空间信息的误导,本文设计了基于注意力机制的空间导向模块(AGM)。模块结构如图6所示。 图6 注意力导向模块结构Figure 6. The structure of attention guide module 首先,输入最低层的鸟瞰图特征FBEV,此特征保留足够多的空间上下文信息;其次,使用平均池化操作提取FBEV的全局特征,对全局特征的空间维度进行复制扩展,恢复特征空间尺度;然后,将其与输入特征FBEV堆叠(Concatenate),并使用1×1卷积将其压缩为1通道;最后,使用Sigmoid函数获取归一化的注意力权值矩阵,将权值矩阵和FPN的输出特征相乘,以空间权重程度限制特征中目标的空间位置,最终获得包含清晰语义和详细细节的新特征。 网络训练总的损失函数Lall由3部分组成:定位损失Lreg、分类损失Lcls以及方向损失Ldir。计算式为 (7) 式中,α=2,β=1和γ=0.2用以平衡各损失的权重。定位损失基于Smooth L1 loss[16]计算,方向损失基于Softmax loss计算,分类损失基于Focal loss[17]计算。 本文基于KITTI[18]数据集进行实验,此数据集包含7 481个样本数据,分割出3 712个样本数据进行训练,余下3 769个样本数据用于验证。本文共评估3类目标:汽车、行人、骑行者。根据3D目标的大小和遮挡程度将检测分为3种难度级别:简单、中等、困难,对应于表1中的Easy、Mod和Hard。为了综合评估算法性能,本文参考基线网络,将汽车的交并比(IOU)阈值设置为0.7,并将行人和骑自行车者的交并比阈值设置为0.5。表1中mAP表示3类难度的均值平均精度。硬件环境为Ubuntu18.04系统和NVIDIA RTX 3080服务器。基于Pytorch1.8、Python 3.7.2平台实现。使用Adam[19]优化器,共训练80个epochs,batch_size为2,初始学习率为0.003。 表1 FPN模块3种上采样方式对比实验Table 1. Comparison experiment of three sets of upsamplings of FPN 2.2.1 FPN模块上采样方式结果对比 本文对FPN模块上采样阶段的3种上采样算子进行对比试验,详细数据如表1所示。3种算子分别为转置卷积上采样、双线性插值上采样和CARAFE上采样,分别对应表1中的UPD、UPB和CARAFE。PP-SSD表示基线网络[3]。 从表1可知,转置卷积上采样方式主要提升骑行者目标精度,在困难指标下精度提升1.53%。双线性插值上采样方式主要提升汽车目标检测精度,在简单、中等、困难3种指标下分别提升0.84%、0.58%和1.62%。CARAFE自适应上采样算子上采样方式对比其他两种上采样方式,主要提升行人类别精度。 考虑到CARAFE模块推理速度消耗,实验中主要采用双线性插值上采样方式恢复特征尺度。 2.2.2 消融实验 本节对上文提出的3组模块:DAM(a)(b)、CAM、AGM分别进行组合实验。在DAM(a)(b)中,(a)表示并联双向注意力机制,(b)表示串联双向注意力机制,CAM表示上下文感知模块,AGM表示注意力导向模块。PP-SSD为基线网络,PP-FPN为替换FPN模块的新基线网络。组合1~组合5为以上3组模块的具体组合形式。 表2、表3和表4分别展示了行人、汽车、骑行者的检测结果。从PP-SSD和PP-FPN的实验结果可看出,替换FPN模块后,汽车和骑行者精度指标都有小幅提升,但是行人指标下降较多。往后实验均基于PP-FPN改进。组合1和组合2在PP-FPN基础上增加了点云双向注意力机制。组合1中并联双向注意力机制和基线网络PP-SSD相比,骑行者3种指标分别提升2.10%、4.11%和2.14%,汽车精度指标基本持平。组合2中串联双向注意力机制和新基线网络PP-FPN相比,行人3种指标分别提升1.12%、1.89%和1.77%,骑行者对比PP-SSD有小幅提升。串联方式和并联方式相比,串联方式行人精度较高,并联方式骑行者精度较高,汽车精度持平。 表2 DAM(a)(b)、CAM、AGM模块对比实验(行人)Table 2. Comparison experiments of DAM(a)(b)、CAM、AGM(Pedestrian) 表3 DAM(a)(b)、CAM、AGM模块对比实验(汽车)Table 3. Comparison experiments of DAM(a)(b)、CAM、AGM(Car) 表4 DAM(a)(b)、CAM、AGM模块对比实验(骑行者)Table 4. Comparison experiments of DAM(a)(b)、CAM、AGM (Cyclist) 组合3是在PP-FPN基础上增加了CAM模块的实验结果。和PP-SSD相比,在简单、中等和困难3项指标下,骑行者类别精度分别提升2.30%、1.96%和1.59%,行人类精度略有降低,猜测是多尺度感受野特征的密集融合,淡化了小目标的重要程度。 组合4是增加了AGM和CAM的双模块实验结果。和组合3的单模块性能对比,行人类目标在3种难度指标下分别提升了3.08%、2.71%和2.03%,骑行者指标略有下降,结果证明AGM模块对小目标更加敏感。 组合5是DAM、CAM和AGM的3模块组合实验。对比PP-SSD,在困难(Hard)指标下,3种类别精度分别提升了0.59%、0.87%和1.42%。对比PP-FPN,在困难(Hard)指标下,3种类别精度分别提升3.23%、-0.42%和1.88%。结果证明3种模块组合对遮挡截断等困难场景更加鲁棒。 2.2.3 结果可视化 本文将改进网络和原始网络输出结果可视化并进行直观对比。点云可视化结果如图7所示。由图7(a)可知,原网络的行人检测结果为0.85,改进网络结果为0.88。在图7(b)中,原网络检测汽车精度为0.92,改进网络检测结果为0.95。在图7(b)、图7(c)、图7(d)和图7(e)中,白色框表示原网络检测时出现的误检和漏检问题,改进网络则较好地避免了此问题,由此可见改进网络相较于原网络鲁棒性更强。 图7 点云结果可视化(a)~(f)现实场景可视化Figure 7.Visualization of point cloud results(a)~(f)Visualization of real scenes 本文在PointPillars基础上,引入注意力机制和上下文感知模块进一步提升算法的准确性和鲁棒性。针对自动驾驶[20]场景下点云场景杂乱、背景干扰较大的问题,本文在数据处理初期增加点云双向注意力机制,通过抑制背景区域,凸显目标区域来增强前景目标被感知到的概率。通过增加FPN模块和注意力导向模块,强制网络学习原始数据的空间位置信息,进而改善原网络特征过度冗余所引起的特征空间位置偏差问题。由于FPN模块的上采样阶段恢复信息较少,设计了上下文感知模块,逐层进行多尺度感受野的特征采集,输出具备多尺度上下文信息的融合特征。KITTI数据集上的实验结果验证了本文所提方法可有效提升目标检测效果。1.2 点云双向注意力机制
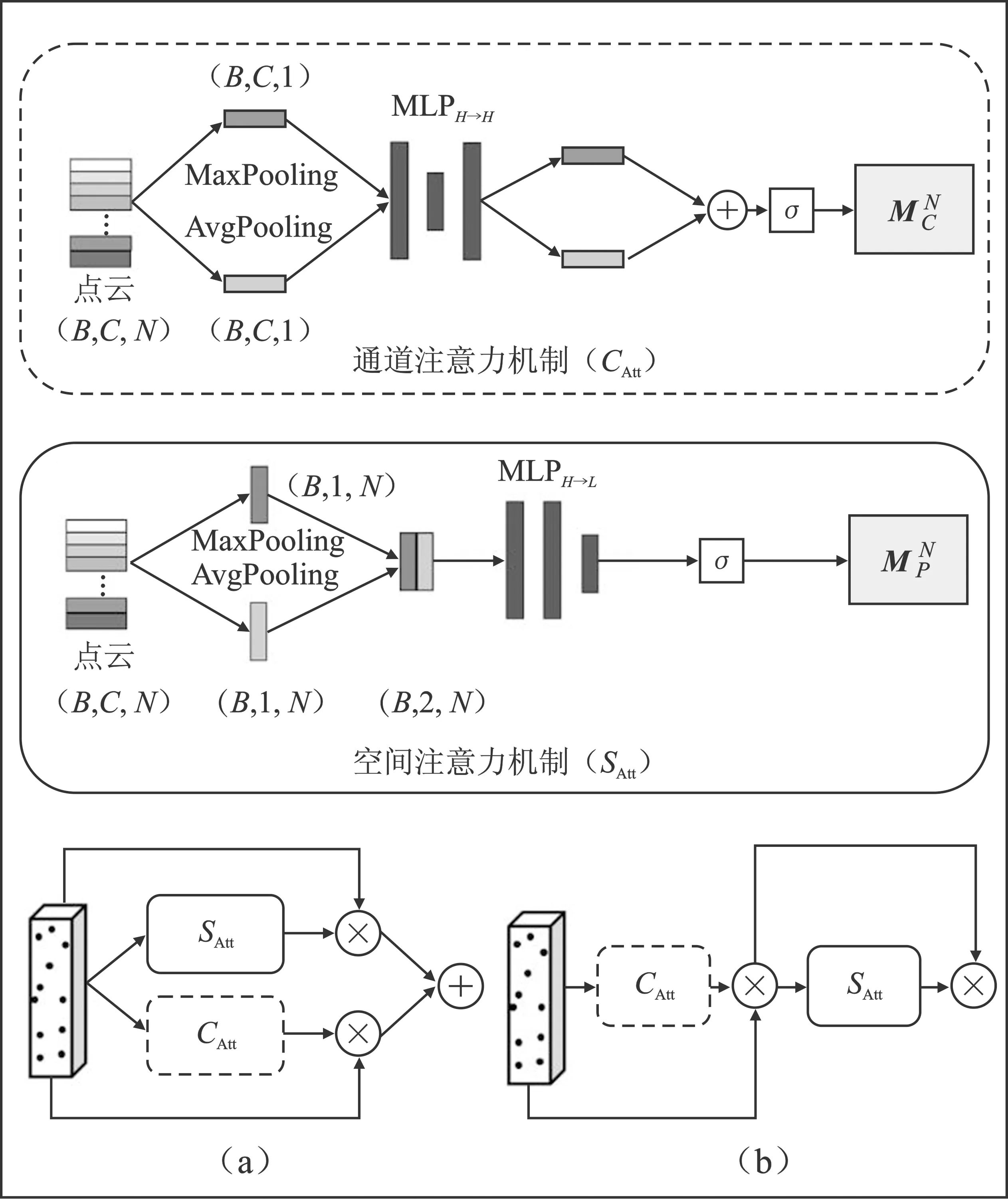
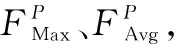
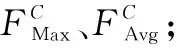
1.3 特征金字塔(FPN)模块
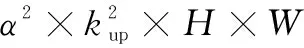
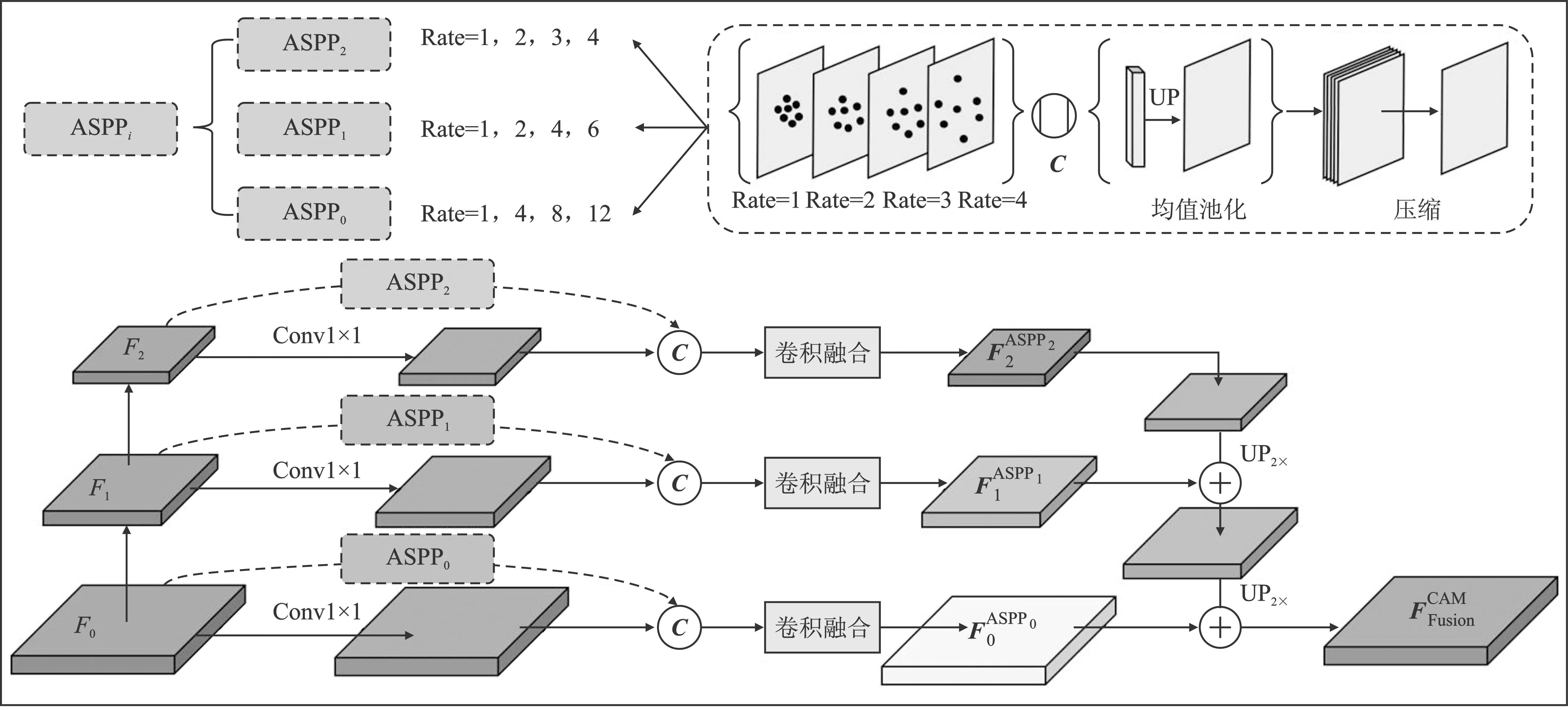
1.4 上下文感知模块
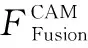
1.5 注意力导向模块
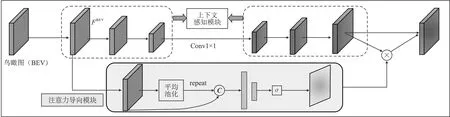
2 实验描述
2.1 训练环境

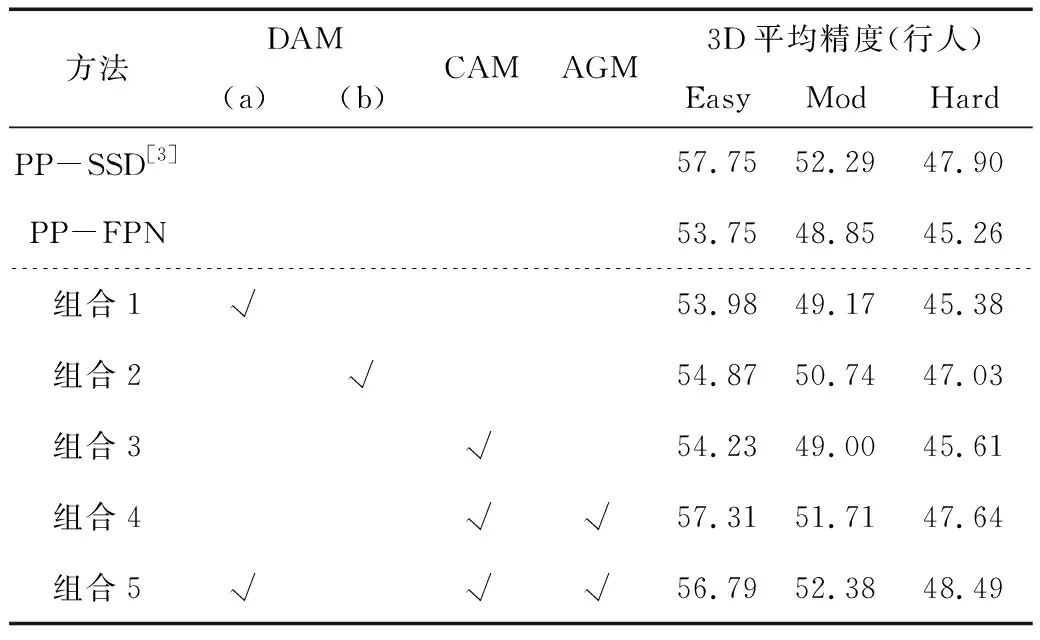
2.2 实验结果

3 结束语
猜你喜欢
出版人(2022年11期)2022-11-15
小雪花·成长指南(2022年1期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
通信电源技术(2016年5期)2016-03-22
电源技术(2015年9期)2015-06-05
时代英语·高三(2014年5期)2014-08-26
河南科技(2014年19期)2014-02-27
