
面向音素序列的黏着语词干提取研究
2023-10-18 13:09:26古再力努尔依明米吉提阿不里米提哈妮克孜伊拉洪艾斯卡尔艾木都拉
小型微型计算机系统 2023年10期
古再力努尔·依明,米吉提·阿不里米提,哈妮克孜·伊拉洪,艾斯卡尔·艾木都拉
(新疆大学 信息科学与工程学院,乌鲁木齐 830046)
1 引 言
从随机序列中准确定位和提取基本粒度单元是自然语言信息处理研究的核心内容.这项研究需要大量高质量的现实语料信息.但是很多小语言标准化工作跟不上,给信息处理研究带来更多困难.由于词干单元比其他附加成分长些且结构相对稳定,因此从语言随机序列中确定和提取词干单元是较有效的处理方法.
维吾尔语是派生类语言,句子由一个个分离的词构成,词可以通过词干缀加若干词缀派生.在派生和缀加过程中会产生语音协调等变化,并在文本中体现出来.词干本身是一个词,表达词的固有词义,而词缀独立时没有含义,但功能强大.词缀可分为构词词缀和构形词缀两个部分[1].构词词缀跟词干连在一起改变词义,而构形词缀只会改变词形,却改变不了词义.由丰富且复杂的多种词缀和形态缀加形式,从而可以构成大量的派生词.根据对本文数据集进行的统计,维吾尔语存在120多种的词缀和几千种组合形式,这给词干提取工作带来困难.

表1 维吾尔语词干加词缀举例Table 1 Examples of Uyghur stems and affixes
如表1所示,单词“vorunlaxturux”由词干“vorun”与3个构词词缀“lax,tur,ux”构成.其中词干“vorun”(位置)是名词,给它加词缀“lax”可以构成“vorunlax”(表演),其可以做动词,也可以做名词.接着给这个词加词缀“tur”,即构成动词“vorunlaxtur”(安排),最终该动词后面加词缀“ux”变成了名词“vorunlaxturux”(安排).
维吾尔语文字中的每个元音和辅音对应的字母以不同的字母形式出现在词首、词中和词末的位置[2].它们的写法至多有四种或至少有两种形态.为了减少每个字母的多种写法以及便于处理,本文使用拉丁字母对维吾尔语文本进行转换,对应的字母对照表如表2所示.

表2 字母对照表Table 2 Alphabetical chart
在黏着语词干提取过程中,当处理某个句子时,先对句子中的成分(单词)进行词干切分,获得词素(词干和词缀)形式,如前缀+词干+复合词缀(后缀1+后缀2+后缀3).切分过程中通常会存在一些歧义现象,如下面例子所示.例子中“tepix”和“berix”都是具有两种词义的词.它们在这两种词义的基础上可分成两组词干.“tepix”的词干为“tAp”(踢)和“tap”(找),“berix”的词干为“bar”(去)和“bAr”(给).这两个词因在句子中包含的意思不同,而决定这个词是包括前者词干的“tepix”(踢)或者“berix”(去)还是包括后者词干的“tepix”(挣)或者“berix”(给).
tepix(踢挣)=tAp(踢)+ix=tap(找)+ix
berix(去给)=bar(去)+ix=bAr(给)+ix
在自然语言处理领域中,维吾尔语是属于一种资源稀缺的语言,如果只考虑语言本身存在的词干词缀问题,最终结果可能得不到提升,因此可以从另一个角度上进行全面考虑,即考虑句子层面的上下文信息.本文提出了通过字符级向量和上下文信息相融合并使用双向LSTM、注意力机制和条件随机场在句子层面上进行分析.由于本文数据是以句子为单位,每个句子成分都会受到上下文语义关系的影响,因此该方法能有效利用上下文信息.
如果要从单词中提取形态信息,则必须考虑单词的所有字符特征,并选择哪些特征对当前任务更重要.例如,在词干提取任务中,信息特征分别出现在开头(如“navAqil”(无知)中的前缀“na”)或者在结尾(如“vAhlaqliq”(有礼貌的)中的后缀“liq”).为了解决这个问题,有必要在具有句子上下文信息的数据集上考虑词干与词缀特征.
维吾尔语作为典型的黏着语,在词干提取研究中,通常会出现不切分、过度切分和歧义切分等情况,其中歧义现象出现得比较离散,而且没有固定的规则,它是因上下文信息而改变.如果仅仅考虑词语本身,就会出现歧义切分的问题,因此为了避免切分错误,必须考虑句子上下文信息.此外,当遇到罕见词时,如果不考虑它的前后特征,则会产生该切分的单词不切分的现象.如果过度切分的情况变多,则不切分的情况会变少,如果过度切分的情况变少,那么不切分的情况就会变多.本文提出的BiLSTM-Attention-CRF模型能平衡以上经常存在的情况,根据输入序列句子内部中的词干和词缀之间的关系,突出词干和词缀的界限,通过上下文更有效地解决上述问题.

表3 词干提取对比实例Table 3 Stemming comparison example
表3所示,当对第1条句子进行词干提取时,传统模型无法提取“tilxunaslar”(语言学家们)中的词干“til”(语言),而误切分为词干“tilxunas”(语言学家)和词缀“lar”,即出现不切分的现象.到句子中的第3个词“nuqta”时,传统模型将词干尾部的“ta”视为词缀,并误切分为词干“nuq”和词缀“ta”,此时出现过度切分的情况.在第2个和第3个句子中,“basma”是一词多义的词.第2句中的“basma”是动词,可以切分成“bas+ma”.但是第3句中的“basma”是形容词,不能再切分.传统模型把这两个句子中的“basma”视为同一个词,均切分为词干“bas”和词缀“ma”,而未考虑该词在不同句子中所包含的意思.一般情况下,当传统的词干提取模型遇到上述类似的情况时,它根据文本数据中统计的单词特征和形态规则来计算出各类切分形式的出现概率,但无法进行映射,从而得不到正确的切分形式.而本文提出的BiLSTM-Attention-CRF模型根据输入的上下文,考虑句子中所包含的前后词之间的关联和单词中的字符特征,可以正确的切分成为词干“til”和词缀“xunas”、“lar”.当处理“nuqta”时,本文模型将它看作为一个单词,不会进行过度切分.到第2和第3条句子,模型根据上下文语义信息可以正确识别出第2句中的词干“basma”和第3句中的词干“bas”和词缀“ma”.当本文模型处理歧义现象问题时,尽管或多或少存在一些歧义切分,并不能完全解决该问题,但是本文提出的模型还是能有效地解决歧义现象问题.
2 相关工作
词干提取在自然语言处理研究中起着关键性作用,它在各种NLP任务中得到广泛使用.词干提取本身就是对文本中的每个词进行切分,并将词干和词缀拆分开来,从而获得词干[3].词干提取能获取有效的、有意义的语言特征,并减少信息的重复出现率和特征位数[4],如以下例子所示:
(原型)vAllikkA vAllikni qoxsaq vAllikniN vikki hAssigA tAN bolidu.(五十加五十等于两倍的五十.)
(切分后)vAllik+kAvAllik+niqox+saqvAllik+niNvikki hAssi+gA tAN bol+idu.
以上句子由8个词组成,对它进行词素切分和词干提取,可以将其中的3个词切分为一个词干和3个词缀的形式.它们的词干(下划线文字)都是vAllik(五十).由3个词缀(粗体字)连接在同一个词干后面表示3种词义,从其获取3种词特征,如表4所示.由此可见,将维吾尔语词切分成有效的词素序列,可以降低词干和词缀的重复率,从而促进文本信息处理的发展.

表4 维吾尔语词语变体Table 4 Uyghur word variants
在国内派生类语言词干提取研究中,文献[5]以哈萨克语词干词缀连接点为出发,采用N-gram语言模型进行词干提取,并将准确率达到了72.34%.文献[6]开发了一个句子级多语言形态处理工具.该工具提供句子级的词素提取功能,使用平行语料库来训练一个统计模型,并且将词素切分准确率达到了98%.文献[7]分别使用Lovins算法、条件随机场(CRF)模型和双向门控循环单元网络(BiGRU),在不同的两种数据集上通过一系列处理对于词干提取研究进行了对比实验.从实验结果可知,基于CRF模型的词干提取方法优于传统方法.如果序列标注方式不同,则得到的词干提取效果也不同.但是数据中词与词之间的独立性给CRF模型学习更多的信息带来不便.文献[8]采用BiGRU进行了维吾尔语词干提取,并且解决了其中存在的数据稀疏的问题.此项实验表明,通过充分利用上下文信息可以有效解决歧义消解的问题,而且该方法在各个性能上面超过了几种主流的统计方法.文献[9]采用N-gram模型对于维吾尔语进行了词干提取.在使用N-gram模型的前提下通过词性特征提取的词干准确率达到了95.19%,同时把词性特征和上下文词干信息融合到一起,将准确率达到了96.60%.
在本文中,提出了一种基于双向LSTM、注意力机制和CRF的神经网络词干提取模型.该词干提取模型使用双向LSTM从文本中学习输入之间的长距离依赖关系,并提取更好的特征.此外,还引入了注意力机制来计算注意力概率分布,并突出了词干提取的性能.
3 融合BiLSTM和注意力机制的维吾尔文词干提取
本文提出BiLSTM-Attention-CRF词干提取模型,主要由输入层、预处理层、句子级字符嵌入层、BiLSTM层、Attention层和CRF层构成.整体框架如图1所示.首先以句子级文本数据为输入,对其进行预处理,先删除标点符号,然后人工切分句子中的词干与词缀部分,接着以字符为单位再对它们进行切分和标注,并将它们的特征向量输入到BiLSTM层,BiLSTM学习输入之间的依赖关系获取上下文特征.将BiLSTM的输出作为Attention层的输入获取全局特征信息,然后把它送入到CRF层,最终通过CRF得到对应的标注序列.
3.1 BiLSTM模型
到目前为止,神经网络有很多种类型,每种类型都有自己的特点.循环神经网络(RNN)具有非常重要的能力,那就是记住以前的事件.LSTM结构由文献[10]引入,被视为由RNN发展而来的变形结构.RNN通常存在梯度消失或者梯度爆炸的问题,LSTM为了解决其不足,在RNN的基础上额外增加记忆单元而生成的.

图1 模型整体框架Fig.1 Overall framework of the model

图2 LSTM网络单元Fig.2 LSTM networks
常见的LSTM网络结构由记忆单元、遗忘门、输入门和输出门组成[11],其结构如图2所示.记忆单元直接沿着整个链条流动,存储长时间或短时间的信息.记忆单元的作用是学习3个门的参数来获取或控制本单元中的信息,使有效的信息通过较长的距离也能保存到记忆单元中[12].遗忘门决定了要在单元格中丢弃哪些信息,输入门控制哪些新信息将存储在单元格中.在LSTM单元中,输入门与遗忘门在记忆长期依赖层面上能够起到关键性作用,它们的功能是摒弃无用信息,将需要的有用信息传入到下一时刻.输出门根据记忆单元控制LSTM单元的输出值.
其结构用以下公式来表示.其中,xt表示当前时刻的输入信息.it表示当前时刻的输入门,ht-1表示前一时刻的隐层状态,σ表示非线性激活函数,ft表示当前时刻的遗忘门,ct表示用于存储序列信息的自循环神经元,tanh是双曲正切激活函数,ot表示当前时刻的输出门,ht表示当前时刻的隐层状态,Wi、Wf、Wc、Wo是依次对应输入门、遗忘门、记忆单元与输出门的权重矩阵,bi、bf、bc、bo是偏置向量.
X=[ht-1xt]
(1)
it=σ(Wi·X+bi)
(2)
ft=σ(Wf·X+bf)
(3)
ct=ft⊙ct-1+it⊙tanh(Wc·X+bc)
(4)
ot=σ(Wo·X+bo)
(5)
ht=ot⊙tanh(ct)
(6)
LSTM只能捕获输入序列的上文信息,但无法捕获下文信息.BiLSTM在LSTM的基础上进行优化而被提出来的,它实际上是由两个LSTM网络构成,一个是正向输入的LSTM,另一个是反向输入的LSTM,它们的参数是独立的,输出也是相互不干扰.BiLSTM网络结构如图3所示.
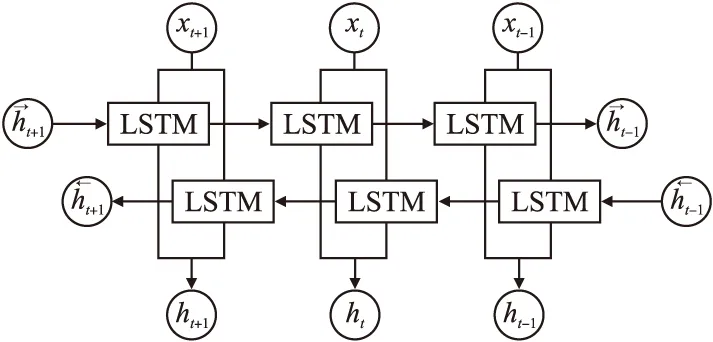
图3 BiLSTM结构Fig.3 BiLSTM structure
图3中,xt+1、xt、xt-1表示输入的向量数据,ht是前向LSTM和后向LSTM的隐藏状态,ht-1和ht+1表示在t时刻关于过去和未来的隐藏信息.向量化文本进入BiLSTM进行上下文语义特征提取,它同时处理上下文信息,能分别获取历史信息和未来信息.为了获得更多上下文依赖关系,本文将采用以双向LSTM的特点为出发点进行模型训练,由产生的前向和后向语义信息获取上下文信息.
3.2 注意力机制
注意力机制(AM)由Bahdanau等人[13]首次提出,是深度学习研究中最有价值的突破之一.注意力机制计算注意力概率分布,从而体现出输入与输出之间的相关性,并且优化神经网络模型.注意力机制对文本的前后语义编码赋予不同的权重,以更精确的区分文本中的词干与词缀信息,来提高词干提取的效果.注意力层的结构为如图4所示.

图4 注意力机制结构Fig.4 Attention mechanism structure
对句子级形态分析而言,句子中的单词与单词之中的字符对词干提取的作用是不同的.为了区分它们之间的关键特征,通过引入注意力层来更进一步提取其中存在的文本特征.注意力模型用于将句子、单词、字符与输出之间的联系体现出来.注意力权重的学习是通过在原有网络结构的结构基础上添加一个前馈网络来实现.
多元GARCH模型主要包括条件均值方程和条件方差方程。条件均值方程采用向量自回归VAR(n)模型分析。其中n为VAR模型的滞后阶数,根据AIC准则选取。VAR模型采用多方程联立的形式,每个方程中的内生变量对所有内生变量滞后期进行回归,从而估计出跨期动态关系。对于条件方差方程,本文主要采用GJR-GARCH的形式分析。
an=softmax(hnst)
(7)
(8)
其中,an是注意力权重,hn是编码器的隐藏状态值,ct是各个输出状态hn的一个加权和,将模型生成的注意力权重赋给相应的隐藏层状态,使得注意力权重起到作用.在文本模型中引入注意力层之后,将其跟BiLSTM模型一起训练.
3.3 条件随机场
条件随机场(Condition Random Field),简称为CRF,是结合隐马尔可夫模型(HMM)和最大熵模型(ME)的优点[14]用于对输入序列进行标注与切分的条件概率模型.BiLSTM只考虑上下文信息,无法考虑到相邻标签之间的依赖关系,而CRF能考虑标签之间的依赖关系获取一个最优序列,并且能解决BiLSTM的不足.通过CRF来对字符、单词和句子上下文特征进行融合.
图5 CRF层结构Fig.5 CRF layer structure
在神经网络模型中通常使用Softmax函数来进行分类预测,它跟CRF序列标注存在着密切的逻辑关系[15].本文采用的BiLSTM、注意力机制和CRF相结合的模型能够处理上下文和相邻标签之间存在的依赖关系,有效地处理序列标注问题.CRF层是神经网络架构的最后一层,它的输入是注意力层的输出结果,将其作为输入通过转移分数矩阵和发射分数矩阵来对于输出之间的关系进行全面的衡量,最终得出最优的输出序列,从而显著提高词干提取的效果.CRF层对于全局特征进行归一化获得全局最优,它的结构如图5所示.
4 实 验
4.1 实验数据
本文所采用的数据集是从官方网站人民网(uyghur.people.com.cn)爬取得到的20030条维吾尔文句子.数据包含于体育、教育、旅游、生活等4个领域,本文将其以8∶1∶1的比例分成训练集、测试集和验证集,具体的数据统计如表5所示.
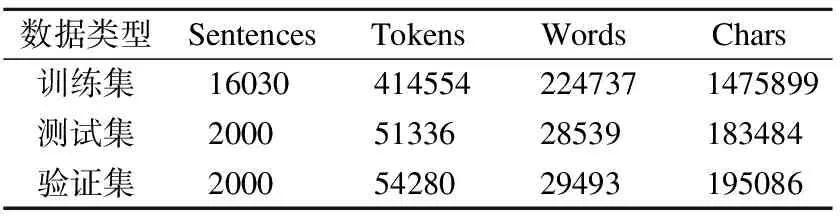
表5 数据统计信息Table 5 Data statistics
首先对数据中的所有句子成分进行词干与词缀切分,以便处理后续的标注数据工作.如图6所示是对本文实验数据包含的所有句子里面的词素(词干和词缀)与单词进行统计之后得出的结果,图中的数据没有包含重复的词汇与词素.
一般维吾尔语词具有两三个词缀,而且它们的形式比较多样化,因此本文实验数据需要手动切分和自动标注.在此过程中,本文列出了最长和最短的单词、词干及词缀,如表6所示.

图6 语料统计分布Fig.6 Corpus statistics distribution

表6 最长最短的词素与单词Table 6 Longest and shortest morphemes and words
4.2 实验设置
当标注数据时,本文使用BIOES序列标注方法来标记词干和词缀.在定义标记集时,为了更全面、有效地表示文本,将词干词缀部分以字符为单位进行细切分,由标记集{B-S、I-S、B-E、I-E、O}来表示句子中的每个字符所对应的词干词缀标签.其中,B-S表示词干首字符、I-S表示词干非首字符、B-E表示词缀首字符、I-E表示词缀非首字符,O表示非词干词缀(数字).例如,mAn bu yil 17 yaxqa kirdim(我今年17岁了).如果对该句子中的每个字符进行标注,则所对应的标注序列为“m/B-S a/I-S n/I-S b/B-S u/I-S y/B-S i/I-S l/I-S 1/O 7/O y/B-S a/I-S x/I-S q/B-E a/I-E k/B-S i/I-S r/I-S d/B-E i/I-E m/I-E”.符号“/”后面表示每个字符所对应的标记.CRF层从输入序列学到更多的信息,从而更有效地描述上下文信息.本文通过对训练集进行训练,使得模型对输入进行辨别分类,从而提高整体模型的效果.
(9)
(10)
(11)
本文实验的深度学习框架为PyTorch,采用CPU进行训练,实验的超参数设置为如表7所示.

表7 实验参数Table 7 Experimental parameters
4.3 实验结果与分析
为了验证本文所提出的BiLSTM-Attention-CRF模型的有效性,本文选择由清华大学所提供的维吾尔语词级形态切分语料库(THUUyMorph)[16]和本文手动构建的人民网数据集作为研究对象,使用BiLSTM、BiLSTM-CRF和BiLSTM-Attention-CRF等不同模型进行消融实验,对比了它们在不同数据集上的词干提取效果.如表8所示是THUUyMoprh数据集以词为单位统计的数据分布情况.在不同数据集上的消融实验结果如表9、表10所示.

表8 THUUyMoprh数据集的数据分布Table 8 Data distribution of the THUUyMoprh dataset
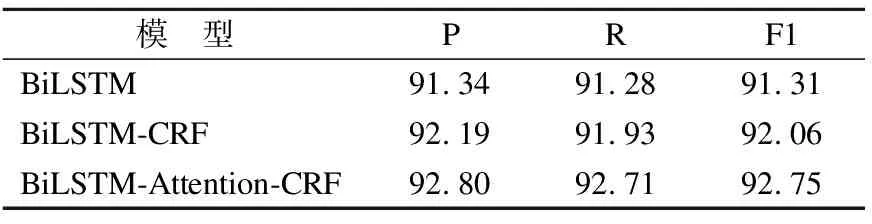
表9 THUUyMorph数据集上的消融实验(%)Table 9 Ablation study on THUUyMorph dataset(%)

表10 人民网数据集上的消融实验(%)Table 10 Ablation study on People′s Daily Online dataset(%)
从实验结果可以看出,通过神经网络模型使用不同类型的两种数据集提取的词干效果截然不同.THUUyMorph是由一个个单独的维吾尔语词构成,没有句子上下文信息的数据集.人民网数据集是因本文所需而采集的句子级数据集.当使用词级数据集时,3种模型的词干提取效果几乎差不多,但是可以看出本文提出的BiLSTM-Attention-CRF对于词级数据集还是能起到一定的作用.对于句子级数据集而言,BiLSTM-Attention-CRF模型的词干提取效果更明显.由此可见,本文提出的词干提取模型应用于两种不同的数据集,能充分体现出本文模型的普适性.此外,实验结果表明,句子级数据集考虑字符特征的同时,全面考虑上下文,更充分地获取词干词缀边界信息,跟词级数据集相比,可以更有效地提取词干.
本文构建与采用的句子语料有益于神经网络模型学习更多的信息.通过BiLSTM模型,使用句子级语料来获取正向和反向的上下文序列特征.在BiLSTM模型的基础上添加注意力机制层进行权重学习,充分利用长距离和全局特征信息,从而得出的词干提取性能更好.
根据本文定义的序列标签,当进行测试时,对于数据中的词干和词缀部分分别进行提取后的效果如图7所示.正确识别并提取词干首字符(B-S)、词干非首字符(I-S)、词缀首字符(B-E)、词缀非首字符(I-E)和非词干词缀字符(O)的准确率依次为96.16%、97.98%、93.57%、95.38%、99.4%.从整体来看,由于词缀包含前缀和后缀,识别前缀相对比较困难,因此词缀的识别率比起词干的识别率略低.本文数据集中数字占的比例相对比较少,而且数字是指0~9的10个数,所以它的识别率最高.
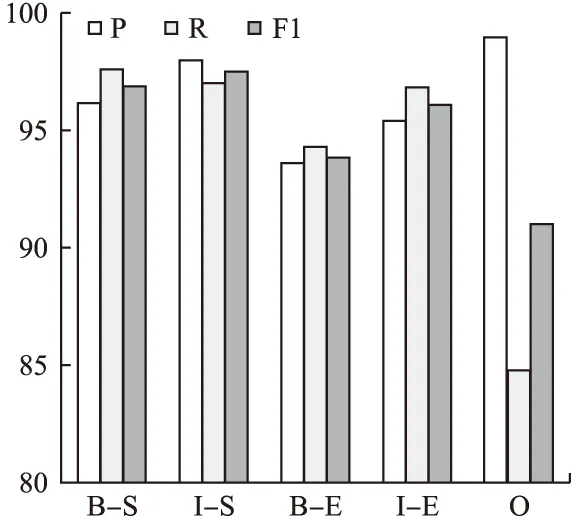
图7 词干和词缀识别率Fig.7 Recognition rate of stems and affixes
为了验证传统模型和本文提出的神经网络模型在词干提取任务上的性能,将本文模型分别与统计模型HMM、CRF和几个常见的神经网络模型进行了对比.对比过程是使用BiGRU、BiGRU-CRF以及两种统计模型在本文构建的人民网数据集上进行词干提取.对比实验结果如表11所示.
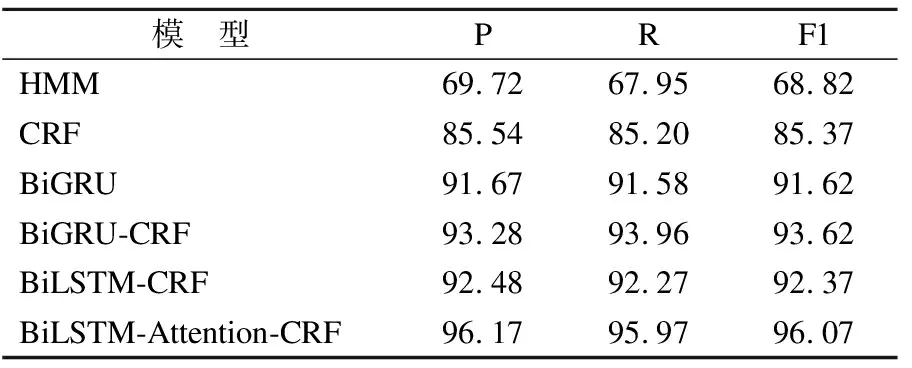
表11 对比实验结果(%)Table 11 Comparative experimental results(%)
从表11可以看出,在相同的数据集上,神经网络模型的词干提取效果优于基于传统的HMM和CRF模型.如果进一步进行分析,BiLSTM-Attention-CRF模型的效果比BiGRU和BiGRU-CRF的效果更好,可以视为本文模型的词干提取效果最佳.
5 总 结
针对黏着语词干提取研究中字符向量表征过于单一,无法有效地处理具有上下文信息的数据.本文研究根据大量高质量的句子级语料库,提出了一种基于神经网络的融合字符和上下文特征的词干提取模型.当采用双向LSTM时,通过连续表示可以缓解词与词素之间的数据稀疏问题.本文将黏着语词干提取任务视为序列标注问题,采用两种不同的数据集,通过不同的模型进行了词干提取.实验结果表明,本文提出的模型对于具有句子上下文的数据集上的词干提取效果更优.同时本文将传统模型和神经网络模型在本文数据集上对词干提取效果进行了对比.由对比结果可知,BiLSTM-Attention-CRF模型优于其他模型,并且具有显著的准确度.与此同时,当考虑字符特征和上下文信息时可以有效地解决黏着语中常存在的不切分、过度切分和歧义切分等现象.总而言之,同时考虑长距离和全局特征极其重要.本文没有探讨属于黏着语的其他语言,因此在往后的研究中,尝试考虑更多黏着语语言特征,学习更多更丰富的形态关系,深入研究多语言形态分析,进一步提高词干提取效果,并将其迁移到语系相似的更多低资源语言当中.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
红河学院学报(2021年4期)2021-11-19 08:59:14
现代职业教育·高职高专(2020年22期)2020-03-24 22:46:34
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
中文信息学报(2018年11期)2018-12-20 06:08:44
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
西夏研究(2017年1期)2017-07-10 08:16:55
中文信息学报(2015年5期)2015-04-21 10:41:55
中文信息学报(2015年3期)2015-04-21 08:33:49
