
面向深度网络的小样本学习综述
2023-10-17 11:03潘雪玲李国和郑艺峰
计算机应用研究 2023年10期
潘雪玲 李国和 郑艺峰

摘 要:深度学习以数据为驱动,被广泛应用于各个领域,但由于数据隐私、标记昂贵等导致样本少、数据不完备性等问题,同时小样本难于准确地表示数据分布,使得分类模型误差较大,且泛化能力差。为此,小样本学习被提出,旨在利用较少目标数据训练模型快速学习的能力。系统梳理了近几年来小样本学习领域的相关工作,主要整理和总结了基于数据增强、基于元学习和基于转导图小样本学习方法的研究进展。首先,从基于监督增强和基于无监督增强阐述数据增强的主要特点。其次,从基于度量学习和基于参数优化两方面对基于元学习的方法进行分析。接着,详细总结转导图小样本学习方法,介绍常用的小样本数据集,并通过实验阐述分析具有代表性的小样本学习模型。最后总结现有方法的局限性,并对小样本学习的未来研究方向进行展望。
关键词:小样本学习; 数据增强; 元学习; 度量学习; 转导图小样本学习
中图分类号:TP181 文献标志码:A 文章编号:1001-3695(2023)10-001-2881-08
doi:10.19734/j.issn.1001-3695.2023.02.0074
Survey on few-shot learning for deep network
Pan Xueling1a,1b, Li Guohe1a,1b, Zheng Yifeng2,3
(1.a.Beijing Key Lab of Petroleum Data Mining, b.College of Information Science & Engineering, China University of Petroleum, Beijing 102249, China; 2.School of Computer Science, Minnan Normal University, Zhangzhou Fujian 363000, China; 3.Key Laboratory of Data Science & Intelligence Application, Fujian Province University, Zhangzhou Fujian 363000, China)
Abstract:Deep learning is widely used in various fields, which is data-driven. Data privacy and expensive data labeling or other questions cause samples absent and data incompleteness. Moreover, small samples cannot accurately represent data distribution, reducing classification performance and generalization ability. Therefore, few-shot learning is defined to achieve fast learning by utilizing a small target samples. This paper systematically summarized the current approaches of few-shot learning, introducing models from the three categories: data augmentation-based, meta-learning based, and transduction graph-based. First, it illustrated the data augmentation-based approaches according to supervised and unsupervised augmentations. Then, it analyzed the meta-learning based approaches from metric learning and parameter optimization. Next, it elaborated transduction graph-based approaches. Eventually, it introduced the commonly few-shot datasets, and analyzed representative few-shot learning models through experiments. In addition, this paper summarized the challenges and the future technological development of few-shot learning.
Key words:few-shot learning; data augmentation; meta-learning; metric learning; transductive graph few-shot learning
0 引言
大數据时代,深度学习[1]以大量的标签数据为驱动,已广泛应用于计算机视觉[2,3]、自然语言处理[4,5]、动物学[6]和人口统计学[7]等领域。然而,标注数据的收集与获取需要消耗大量的人力与时间,并且在某些领域(例如医学、军事和金融等)中,由于隐私安全等问题无法获得充足的样本。现实世界中人类仅依靠少量样本就可快速学习,受此启发,研究人员提出小样本学习(few-shot learning)。小样本学习方式更贴近于人类思维,可有效解决上述问题。
小样本学习分为非深度学习和深度学习两个研究阶段。在非深度学习阶段,主要以构造先验概率的生成模型为主[8],该策略通过引入中间潜在变量,将输入样本和其类别建立联系,以构造先验概率,其发展相对缓慢。Miller等人[9]于2000年最先提出利用每个类的单个样本来训练分类器,并指出大量数据的分类器性能正在趋于稳定。单样本学习(one-shot lear-ning)问题将有助于缩小人机性能差距[10]。随着深度学习技术的发展, Koch等人[11]于2015年首次将深度学习融入到小样本学习问题中,提出孪生网络(siamese neural network) 用以衡量两个样本间的相似度,使得模型精度有了很大的提高。小样本学习进入深度学习阶段,其研究重点主要以构造后验概率的判别模型为主 [8](基本流程如图1所示),即通过深度神经网络f(·|θ)(例如:CNN)对输入样本进行特征提取,再通过预测层C(·|φ)(例如:softmax)对提取的特征进行标签预测,其中,θ和φ均为可学习的深度网络参数。特征表示和端到端优化等深度学习技术使小样本学习得到快速发展。Wang等人[12]根据研究人员如何利用先验知识来解决小样本学习经验风险不可靠这一核心问题,将小样本学习方法分为基于数据、基于模型、基于算法三个研究方向。赵凯琳等人[13]根据所采用方法的不同,将小样本学习分为基于模型微调、基于数据增强和基于迁移学习[13]。此外,安胜彪等人[14]从基于有监督、基于半监督、基于无监督的角度进行归纳总结小样本方法,其中,将基于有监督细分为元学习、度量学习和数据增强进行归纳总结;将基于半监督细分为低密度可分假设和自监督学习方法进行归纳总结;将基于无监督细分为基于无标签数据和基于聚类方法进行归纳总结。本文主要从解决小样本学习样本量少、模型训练容易过拟合问题出发,将小样本研究方法分为基于数据增强、基于元学习和基于转导图小样本学习三个方面。基于数据增强的小样本学习方法的本质是通过数据合成或特征增强方式解决样本量少的问题,本文根据是否需要额外的辅助信息(比如语义属性[15]或词向量[16]等)将基于数据增强的小样本学习方法进一步细分为监督数据增强和无监督数据增强。研究人员从跨任务学习的角度提出基于元学习的小样本学习方法来解决模型过拟合问题,本文将其细分为基于度量学习和基于参数优化。基于转导图小样本学习方法是一种相对較新的转导推理小样本学习方法,但也取得了先进的效果。
本文首先从基于数据增强、基于元学习和基于转导图小样本学习三个角度介绍小样本学习的研究进展,总结了小样本图像分类和识别任务中的常用数据集以及已有模型在这些数据集上的实验结果,最后在结束语中将针对小样本学习的主要挑战展望其未来的发展趋势。
1 基于数据增强的小样本学习
小样本学习面临的根本问题是样本量少、样本多样性低,易导致模型过拟合。相比传统变换规则(例如平移、旋转、缩放和添加噪声 [17,18]),基于数据增强的方法旨在通过数据合成或特征增强的方式提高训练样本的数量和特征多样性[19]。随着深度学习的发展,研究人员提出了许多相对复杂的增强模型、算法和网络来进行数据扩充或特征增强。根据是否需要额外的辅助信息,可将其分为监督增强和无监督增强。
1.1 监督增强方法
监督增强方法核心思想是利用语义属性或词向量等辅助信息对原有数据集进行数据扩充或特征增强,防止模型过拟合。
Chen等人[20,21]提出自编码网络(dual TriNet)以实现语义空间的数据增强,与传统图像级别或特征空间中的数据扩充不同,其核心是将特征映射到语义空间,在语义空间中通过语义高斯或者语义近邻的方式进行语义特征增强。dual TriNet模型(如图2所示)由 encoder TriNet和decoder TriNet两部分组成。首先,encoder TriNet将ResNet-8提取的多级深度特征{fl(Isupporti)}映射到语义空间(该语义空间和标签语义空间对齐)。然后在此空间中,或者如式(1)所示,将语义高斯引入语义特征,构造以语义特征gEnc({fl(Isupporti)})为均值,以σ为方差的高斯分布,并从中随机采样作为扩充后的语义特征VGki;或者如式(2)所示,从已训练好的词向量空间中选取与语义特征向量gEnc({fl(Isupporti)})最接近的向量作为扩充后的语义特征VNki。最后,将扩充后的语义特征通过decoder TriNet逐级还原为特征图(即gDec(VGki)或gDec(VNki)),并通过KNN、SVM或者逻辑回归等分类器完成分类任务。
与dual TriNet不同,Yu等人[22]提出生成属性的迁移学习模型(author topic,AT),其核心是通过为每个属性建立一个生成式的属性模型来学习图像特征的概率分布,并将不同类别的公共属性视做属性先验来学习目标任务。该模型所采用的特征包图像表示法有利于加强空间约束,提高属性定位的精确度,但会丢失一些有价值的空间信息。
Lu等人[23]则考虑为每个属性建立一个模型,提出一种新的神经网络结构(attribute-based synthetic network,ABS-Net)自动为缺少图像标注的类合成伪特征表示,以解决类间数据不平衡或者类内数据缺乏等问题。其核心思想是利用辅助数据集进行属性学习,建立属性特征存储库。当给定一个类的属性特征描述时,采用概率抽样策略从特征存储库中抽取一些属性特征用于向量合成,通过此方式合成伪特征,实现特征层的数据增强。伪特征合成与图像合成方法相比,前者无须将迁移知识映射到真实的图像领域,有效规避了域适应问题。
Frederik等人[24]提出利用多模态信息合成图像来训练细粒度小样本学习模型,其在训练时是多模态的,而在测试时则采用单模态(即图像)。此外,还提出文本条件生成对抗网络(text conditional generative adversarial network,tcGAN),在细粒度文本描述的条件下产生附加图像,促进小样本学习。2022年,潘理虎等人[25]提出多特征融合关系抽取方法实现语义增强,该方法通过构建一个融合位置、词性和句法依存等信息的分段卷积神经网络来最大化表示语义特征,并将其融入词嵌入以提高模型上下文共性学习。此后,吕天根等人[26]提出将视觉特征与文本特征融合再进行局部特征选择的方法,利用文本数据增加特征多样性,提高了模型精度。
近年来,通过语义增强特征的方法成为新的研究热点之一,Schwartz等人[27]重点研究额外语义信息的作用,并进一步证明通过结合多种更丰富的语义信息(类别标签、属性和自然语言描述)可有效提升模型精度。
1.2 无监督增强方法
无监督增强方法进行数据扩充或特征增强无须额外的辅助信息,主要通过提出新的网络模型学习类内变形信息或添加随机噪声进行图像合成。
Hariharan等人[28]提出新的小样本学习基准算法,主要包括表征学习和小样本学习两个阶段,通过正则化项来约束两个学习阶段分类器间的差异。表征学习阶段旨在提高特征提取网络的表征能力,小样本学习阶段主要侧重于将类内不同样本间的变形信息泛化到其他类别,然后利用多层感知机合成新样本,然后利用扩充后的数据集训练分类模型。
2018年,Schwartz等人[29]利用类内变形扩充数据,提出改进的自动编码器(delta-encoder),其核心思想是在编码阶段学习同类别中几个样本间的可迁移的类内变形,然后在解码阶段,结合学得的类内变形信息和源样本生成所属源样本类别的新数据,该模型很好地解决了小样本学习训练样本少的问题。
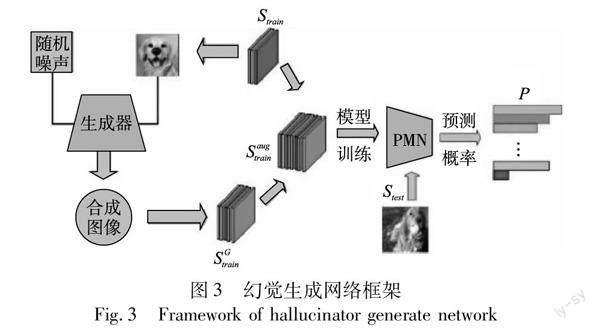
Wang等人[30]提出一种基于生成对抗网络的图像合成模型(如图3所示)。该模型主要贡献有两点:a)样本空间的扩充;b)小样本分类模型的优化。样本空间的扩充即结合随机噪声和训练样本通过生成器合成图像;小样本分类模型的优化即结合原型网络与匹配网络的优势提出PMN(prototype matching network)分类器,因为匹配网络利用双向长短时记忆网络和注意力机制使得样本嵌入聚焦于对分类贡献度大的特征,但是对于样本量少的类别,有用的特征容易被遗忘,容易被常见类别的样本特征淹没,这对样本量少的类别是一种极大的偏见,而原型网络为每个类别学习一个类原型,可有效缓解这一问题。基于这一动机,PMN提出先借助原型网络的思想计算类原型,再利用双向长短时记忆网络和注意力机制学习样本的上下文嵌入,这一改进有效提高了模型精度。
与上述方法不同,Hang等人[31]通过建模样本的潜在分布进行数据增强,提出保存协方差的生成对抗网络(covariance preserving adversarial augmentation network,CP-AAN),在给定相关类别样本的情况下,对每个新类样本的潜在分布进行建模。此外,在生成过程中保存协方差信息作为相关类别样本的变形信息来进行数据合成。
2 基于元学习的小样本学习
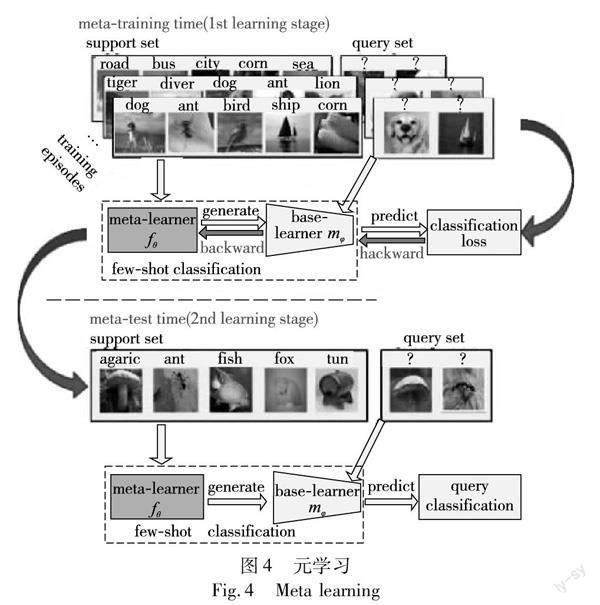
元学习即学会学习,其与小样本学习模拟人类学习方式的初衷相契合,旨在从跨任务学习的角度训练一个可以用于快速学习的模型。在元学习中,每一个episode即一个N-way K-shot分类任务(其中,N表示每个任务的类别数,K表示每个类别的样本数),每个任务包括一个支撑集S(support set,包含N·K个样本数)和一个查询集Q(query set,包含M个样本)。其过程主要包括元训练(meta-training)和元测试(meta-test)阶段[32](如图4所示)。
a)元训练(meta-training)阶段先通过大量不同的源任务训练元学习器(meta-learner)f(·,·)学习先验知识(如模型的初始参数、优化器和神经网络的超參数等[33]),再利用已学得的先验知识结合少量目标任务达到快速训练基学习器(base-learner)m(·,·)的目的,如式(3)所示。需要注意的是在利用损失函数(如式(4))做反向传播优化元学习器(meta-learner)的参数θ时,必须贯穿整个小样本训练过程(包括元学习器和基学习器两个训练过程),而非仅仅优化元学习器的参数。
其中:f(·,·)为元学习器;m(·,·)为基学习器;L(·,·)为交叉熵损失函数;θ和φ分别为元学习器和基学习器可学习的参数;S为支撑集;Q为查询集。
b)元测试(meta-test)阶段,元学习器通常固定不变(即不再优化其参数),仅为新的查询集任务生成一个适合的新的基分类器。
本章将从基于度量和基于参数优化两个方向对基于元学习的小样本方法进行归纳分析。
2.1 基于度量学习方法
基于度量学习方法的基本思想是先通过神经网络提取图像特征向量,再采用线性度量方式(比如余弦距离或欧氏距离)或非线性度量方式(神经网络)评估支撑集与测试样本之间的相似程度。现阶段,研究人员也开始考虑引入跨模态信息训练网络以提高模型精度[34,35]。
Vinyals等人[36]于2016年提出匹配网络(matching networks)(如图5所示),利用注意力机制和外部记忆结构帮助模型快速学习。该网络主要有两个核心模块:一是引入双向长短期记忆网络(LSTM)学习支撑集样本间的上下文嵌入,通过LSTM各单元间的连接构建支撑集样本间的联系;二是引入注意力机制构建支撑集和测试集样本间的联系。基本流程为:a)利用gθ和fθ两个嵌入函数分别对支撑集样本和查询集样本xi进行特征提取;b)计算查询集样本和支撑集各类别之间的余弦距离cosine(·,·),并输入注意力机制a(,xi)(如式(5)所示);c)通过对预测值yi的加权求和评估支撑集和测试集样本间的匹配程度(如式(6)所示)。该网络是小样本学习方法中比较典型的基于线性度量的学习策略。
其中:fθ和gθ表示嵌入函数;表示支撑集样本;xi表示查询集样本;cosine(·,·)表示余弦距离;a(,xi)表示注意力机制,yi表示预测值。
此后,Snell等人[37]提出原型网络(prototypical network,Proto Net),与孪生网络相同,其亦通过学习度量空间完成小样本分类。该网络主要贡献是为每个类别的样本学习一个类原型,从几何空间度量查询集中各样本点与每个类原型之间的相似度,进而得到各样本点属于各类的概率值。类原型的定义为
2019年,Chen等人[35]在原型网络的基础上,提出基于跨模态信息增强的度量学习方法(adaptive modality mixture mecha-nism,AM3),核心思想是利用跨模态信息(比如文本语料库)弥补图像分类任务样本信息的不足,解决由于训练样本少导致的类原型的求解存在偏差的问题,当图片信息较少时,AM3提出通过语义信息微调类原型(图6)。具体流程为:a)AM3利用特征提取网络f(·)(ResNet-12)提取图片特征向量Pc;b)支撑集的类标签语义信息通过词嵌入模型w(提前在一个大规模文本语料库中经无监督训练得到)[38]提取对应的语义特征向量ec,并通过维度变换网络g(仅包含一个隐藏层)将其转换为可以用于融合的词向量Wc=gθg(ec),融合方式如式(8);c)通过自适应混合网络h(仅包含一个隐藏层)控制语义特征求解类原型的参与度λc(如式(9)),将融合后的混合特征Pc作为类原型;d)采用原型网络的方式对查询集样本qt进行类别预测(如式(10))。AM3网络首次在特征提取阶段引入语义特征信息以补充图片信息的不足,并采用自适应混合网络调整语义特征与图像特征的融合比例,结构设计精简,使模型精度有了较大提升。2020年,Li等人[39]提出K-tuplet Net,将原型网络的NCA损失函数改为K-tuplet 度量损失,从优化损失函数的角度改进原型网络。AM3网络将语义和图像视为独立的数据源学习类别原型表示,与之不同,2023年,Yang等人[40]提出语义指导注意力机制,利用语义先验知识以自上而下的方式指导视觉类原型表示,即将语义知识映射到类别特定注意力向量网络,利用该网络进行语义特征选择以增强视觉原型。
其中:Pc为语义调节后的类原型;Pc为初始类原型,由式(7)计算得到;Wc为维度变换后的词向量;λc为文本和图像的混合系数;h为自适应混合网络;f(·)为嵌入函数;d(·,·)为欧氏距离;qt为查询集样本。
此外,Sung等人[41]提出关系网络(relation network),其包含嵌入模块f(或g)和关系模块h两部分(图7)。与孪生网络、匹配网络和原型网络不同,关系网络是一种非线性度量方式的小样本学习方法,即通过神经网络自学习xi和xj两个样本间的匹配程度r(xi,xj),如式(11)所示。
其中:h(·)表示可学习的CNN;θf=θg;θh表示其参数;C(·,·)表示将特征向量级联。
2022年,孙流风等人[42]提出双重度量的孪生神经网络,充分考虑了图像级特征度量和局部描述符度量的关系,解决了图像级特征度量对位置、复杂背景及类内差异比较敏感的问题,提高了模型分类准确率。韦世红等人[43]于2023年提出出多级度量网络的小样本学习,该方法利用第二、第三层卷积得到的特征图计算两个图像—类关系得分,通过全连接层的特征图与查询集样本计算图像—图像从属概率,最后将图像—类的关系得分和图像—图像的从属概率进行加权融合作为最终的预测结果,该方法通过利用不同卷积层的图像语义信息提高模型分类效果。综上,可看出基于度量的小样本学习从最初的孪生网络至今已有较大发展,单纯利用线性度量的方式(传统距离函数)已很难对模型精度再有较大提升,非线性度量方式的提出以及跨模态信息的引入拓展新的研究思路。
2.2 基于参数优化方法
深度学习得益于大量模型参数,然而小样本学习极易导致模型过拟合,采用元学习方法优化模型参数有效改善模型的泛化能力。基于参数优化方法一般先通过支撑集训练元学习器学得不同任务的共同特征(即先验知识),再将所得元知识运用于查询集精调基学习器(如图8所示)。基于上述思想,2017年,Finn等人[44]提出未知模型的元學习方法(model agnostic meta learning,MAML),旨在通过跨任务训练策略为基学习器学得最优初始化参数,在面对新任务时仅需少量样本通过几步训练即可取得较好的分类效果,总体流程如下:
假设分类模型为fθ(·),θ为模型参数,P(T)为任务分布,首先随机初始化模型参数θ。再从P(T)中随机抽取一批任务Ti,即Ti~P(T)。假设随机抽取五个任务T={T1,T2,T3,T4,T5},那么对于每个任务Ti,可随机抽取K个数据点训练模型,随后计算损失LTi(fθ),并通过梯度下降法最小化损失,在此过程中利用式(12)为每个任务学得一个最优参数,即θ^={θ^1,θ^2,θ^3,θ^4,θ^5}。在对下一批任务进行抽样之前,先执行元优化来更新随机初始化的模型参数θ(如式(13))。从而使得随机初始化的参数θ移动到一个最优的位置,在训练下一批任务时,仅需少量样本通过几步训练即可获得较好的模型效果。
MAML将学习率设置为一个较小的标量数值,随着时间的推移而衰减,并沿着梯度的方向更新。与之不同,Meta-SGD(meta stochastic gradient de-scent)通过学习的方式获得最优学习率和梯度更新方向[45]。Meta-SGD也需要通过梯度下降最小化损失来为每个任务寻找最优参数(如公式θ^i=θ-αΔθLTi(fθ)),但其α不是标量而是向量,α被随机初始化为和θ同样形状的值,并随着θ一起被学习和更新。αΔθLTi(fθ)表示更新方向,长度表示学习率。此外,Meta-SGD模型沿着αΔθLTi(fθ)的方向而非梯度方向更新参数。θ和α的更新如式(13)和(14)所示。
在Meta-SGD基础之上,Zhou等人[46]提出深度元学习(deep meta learning,DEML),将深度学习的表征能力集成到元学习中以提高元学习的表征能力。其核心是在概念空间而非复杂的样本空间学会学习。为了实现在概念空间中学习,DEML为元学习器配备一个概念生成器(例如深度残差网络),旨在为每个样本学习一个特征表示,捕捉样本的高级概念,同时使用一个概念鉴别器来增强概念生成器,并以端到端方式联合训练概念生成器、元学习器和概念识别器三个模块。借助概念空间,深度元学习模型实现了对本身较少的训练数据的最大化利用。文献[47]提出条件类感知元学习(conditional class-aware meta data learning,CAML),其核心是利用度量空间中结构化的类信息辅助调制基学习器当前任务的表示。具体地,设计一个参数条件变换模块来实现表示调制,并将该模块与基础学习器相结合作为CAML的元学习器。CAML采用和MAML相同的渐进学习策略进行元学习,相比MAML, 模型精度有了很大程度的提升。
2019年,Jannal等人[48]为了防止元学习器在训练数据极少时过度学习学得有偏知识,提出一种任务不可知的元学习(task agnostic meta learning,TAML)算法,该算法提出基于熵减最大化和基于不等式最小化两种方法解决模型泛化能力差的问题。基于熵减最大化的方法旨在通过最大化元学习器预测的标签的熵防止其在某些任务上表现过度,但该方法局限于具有离散输出的分类任务。为解决这一问题,在经济学中不平等度量的启发下,提出基于不等式最小化的方法, 该方法旨在通过最小化初始模型在不同任务上损失不平等的问题,帮助元学习器学得一个无偏倚的初始化模型参数,以防止模型在某些特定任务上表现过度。基于不等式最小化的方法可以采用任何形式的损失函数,不局限于离散输出,可用于解决连续性输出的任务,适应于更普遍场景。2022年,Huang等人[49]结合MAML参数更新思想提出模型不可知的联邦小样本学习,但公共数据与私有数据存在标签不一致和邻域偏差的问题,该方法通过共享公共数据集上的模型预测结果实现公私通信,并通过对抗性学习解决领域偏差问题。结合联邦学习策略的小样本学习不共享私有数据,有效保护了数据隐私和安全,具有极其重要的研究意义,但目前该方面的研究相对较少。
基于参数优化的学习策略主要以元学习的思想解决小样本学习模型训练问题,目前主要以MAML算法为代表进行扩展研究,核心思想是如何设计元学习器在源任务间寻找可推广的先验知识,在新的目标任务中仅需少量样本通过几步训练即可快速训练基学习器。3 转导图小样本学习方法
传统归纳学习旨在从大量训练样本中归纳学得通用模型用于预测未知数据。然而,小样本学习本身样本少,其样本量不足以归纳出具有良好泛化能力的全局模型。为此,研究人员提出转导学习方法,试图通过局部有标签的训练样本预测无标签的数据。在训练样本不足时,可利用无标签数据补充标签数据信息的不足。转导图小样本学习将支撑集和查询集的样本视为图节点,并利用支持集和查询集节点间的近邻关系进行联合预测,可通过无标签数据补充标签信息的不足(如图9所示)[50,51]。而归纳图小样本方法只根据支持集之间的关系学习通用模型来对每个查询集样本进行单独分类。
2019年,Liu等人[52]提出转导传播网络(transductive pro-pagation network,TPN),模型主要包含特征嵌入、图构造、标签传播和损失计算四个模块(如图10所示)。其中,图构造是一个关键步骤,其利用流形结构为每个样本以端到端的方式联合学习一个自适应的高斯核σ参数。具体流程为:a)利用深度神经网络CONV-4提取样本的特征向量;b)利用支撑集和查询集的并集构造图结构,并通过高斯核函数度量样本间的相似度作为近邻图的边权值wij,如式(15)所示;c)通过标签传播算法将标签从支撑集传播到查询集,如式(16)所示,该模型利用转导推理的元学习框架一次性对整个测试集进行分类,有效缓解了低数据量问题,但每当有新的测试样本加入时必须重新运行模型,时间成本相对较高。此后,汪航等人[53]于2022年提出基于多尺度的标签传播网络,其核心思想是利用关系度量模块度量不同尺度特征下的样本相似度,并通过聚合不同尺度的相似性得分进行标签传播获得分类结果。
其中:fθ(·)为嵌入函数;σ为高斯核参数,通过构造的图网络学习;d(·,·)为欧氏距离。
其中:S=D-1/2WD-1/2表示归一化的拉普拉斯矩阵, D=diag(dii=∑N×K+Mj=1wij)表示对角矩阵, W=[wij](N×K+M)×(N×K+M);α∈(0,1)为预先设定的权重系数;F为最终的预测标签;Y为初始标签集。
与TPN不同,Ma等人[54]提出了转导关系传播图神经网络(transductive relation propagation network,TRPN),其采用图神经网络(graph neural network,GNN)构图,旨在学习支撑—查询样本对间的关系信息,将样本对间的关系视为图节点(命名为关系节点),并利用已知的支撑集样本间的关系(包括类内共性和类间唯一性)来估计不同支撑—查询对之间的邻接关系,并为支撑—查询样本对生成判别关系。此外,进一步将支撑—查询对的伪关系引入辅助关系传播,并设计了一种快速有效的转导学习策略来充分利用不同查询样本间的关系信息。 Zhang等人[55]于2022年提出基于图的转换特征传播和最优类分配小样本学习模型,为了解决嵌入网络和图神经网络优化方式(前者多类预训练,后者情景元训练)不同导致的特征分布不匹配的问题,提出将图像特征向量转换为近似高斯分布,并且利用支撑集和查询集间的样本关系计算最优类分配矩阵来估计类中心以解决类分配不准确的问题。
为充分利用不同任务的共享先验知识辅助识别未见过的类别,Liu等人[56]提出一种基于类原型分类的门控传播网络(gated propagation network,GPN),核心是学习如何在图上的节点(即类原型)之间传递信息,以实现知识共享。具体为:给定图结构,每个类将该类原型作为消息发送给其近邻,并会通过一个门模块过滤来自不同发送者的信息,接收到多条消息的类需要结合不同的权重(通过多头点积注意力机制学习得到)并进行聚合操作,再用于更新相应的类原型。由于注意力机制和门模块都是跨任务共享的,且具有很好的泛化能力,可将其推广到整个图和未见过的任务。
上述方法综合考虑样本的图像级关系,学习将类标签从支持集传播到查询集。2021年,Chen等人[57]提出一种显式类级知识传播网络(explicit class knowledge propagation network,ECKPN),核心思想是通過学习跨模态知识表示,将类级上下文知识可视化为图节点辅助图像数据完成查询样本的推理预测。该网络主要包括比较、挤压和校准三个模块。具体为:a)可通过比较模块探索样本对间的关系,以学习样本级图中丰富的样本表示;b)通过对样本级图中具有类似特征的样本进行聚类挤压,以生成类级图;c)采用校准模块对类间关系进行显式刻画,以获得更具判别性的类级知识表示;d)将类级图与样本级图相结合,指导查询样本完成预测。
上述模型主要集中于赋予图节点不同的表示以传播不同的信息辅助预测无标签数据。小样本学习本身样本少,转导图小样本无须学习通用模型,一定程度上缓解了样本不足的压力,但是研究人员发现现实生活中文本信息相比图片样本比较容易获得,于是将文本信息引入图结构辅助训练取得不错的效果,可以思考如何利用跨模态信息提高转导图小样本的模型精度。
4 实验分析
在小样本图像识别与分类任务中,广泛使用的标准数据集是Omniglot[58]、miniImageNet[59]和tieredImageNet[60]。除此之外还有CUB[61]、CIFAR-100、Stanford Dogs和Stanford Cars数据集。接下来主要介绍Omniglot[58]、miniImageNet[59]和tiered-ImageNet[60]三个常用数据集、相关信息详见表1。
miniImageNet是ImageNet[62]数据集的子集,包含100个类别,共有60 000个图像。其中,每个类别有600个图像,每个图像的像素大小均被调整为84×84,训练集、验证集和测试集的类别数分别为64、16和20。
tieredImageNet是ImageNet[62]数据集更具有挑战性的子集,共有608个类别,大约是miniImageNet数据集类别种类的6倍。每个图像的像素大小均被调整为84×84,训练集、验证集和测试集的类别数分别为351、97和160。
Omniglot由50个不同字母中的1 623个手写字符组成,每个字符都是由20个不同的人通过亚马逊的Mechanical Turk[63]在线手工绘制,共有32 460个手写字符图像。每个图像的像素大小均被調整为28×28,并且每个图像均通过90°旋转进行数据增强,其中训练集有1 200个字符,测试集有 423个字符。
为了更好地分析小样本学习模型的有效性,本文选取较为经典的小样本学习模型在miniImageNet和tieredImageNet数据集上进行对比总结,结果如表2所示。所有对比算法均选取5-way 5-shot(即随机选取五个类别,每个类别随机选取五个样本组成一个支撑集)和5-way 1-shot(即随机选取五个类别,每个类别随机选取一个样本组成一个支撑集)的实验表现进行对比分析。所有小样本学习模型中,比较常用的嵌入函数有CONV-4、VGG、RestNet和WRN-28-10[64,65]。
分析表2实验数据可以发现:
a)对于采用不同嵌入函数的同一模型(比如表中TPN、TRPN、ECKPN、EPNET和DPGN模型),采用RestNet和WRN-28-10的模型精度优于采用CONV-4的模型。这说明嵌入函数的选择会影响最终的模型精度,为了保证实验对比的公平性和可信性,研究人员在进行对比实验时应尽量保证所对比的模型均采用相同嵌入函数。
b)对于小样本模型,由于tieredImageNet数据集比mini-ImageNet数据集类别更多,数据量更大(表1),无论是5-way 5-shot还是5-way 1-shot,tieredImageNet数据集上的模型精度都比miniImageNet数据集上的高(对比表2中模型精度可以得出),这说明数据集的选择对于模型训练也有很大的影响。
c)对于miniImageNet和tieredImageNet数据集,从表2可看到,5-shot的模型精度比1-shot的模型精度高,这说明支撑集数据量的设置对于模型训练也有一定的影响,通常适当增加数据量可以帮助模型学得更多的特征从而提高模型分类效果。
d)基于度量学习的小样本学习方法中,从表2可看到,Relation Net相比Matching Nets和Proto-Nets模型精度有一定的提升(特别是在1-shot情况下),说明采用神经网络学习样本间的匹配程度相比线性度量方式有一定优势,特别是对于样本量更少的小样本分类问题。
e)基于参数优化的小样本学习方法中,从表2可以看到,MAML的改进算法(Meta-SGD、TAML和CAML)相比MAML均取得相对不错效果,这说明通过研究优化模型训练过程中存在的问题,针对影响模型精度的不确定因素进行改进,有助提高模型稳定性。
f)基于转导图的小样本学习凭借图结构的直观表现力等优势得到快速发展,相比另外两个研究方向,无论1-shot还是5-shot在两个数据集上的表现均最优,提高幅度最高均在30%左右(1-shot或5-shot情况下各自最优模型效果与最次模型效果的差距),说明基于转导图的方法是解决小样本学习问题比较有效的研究方向之一。
g)dual TriNet、AM3和ECKPN方法均引入跨模态信息辅助训练,使模型精度有了较大程度的提升,其中ECKPN模型在表中所有模型中表现最优。这说明引入跨模态信息辅助训练模型有助于提高小样本学习模型精度,也是未来不错的研究方向之一。
5 结束语
随着深度学习的发展,小样本学习方法研究得到广泛研究,但仍面临一些挑战(核心思想见表3)。
基于数据增强的小样本学习方法旨在通过增强模型、算法或网络来对数据集进行数据扩充或特征增强,本文根据是否需要额外的辅助信息将其分为监督增强和无监督增强两个角度来介绍,该方向是公认的解决小样本学习问题的比较简单和直接的方法,但在数据扩充或特征增强的过程中难免会产生噪声数据从而对模型训练产生负面影响。基于元学习的小样本学习方法很好地解决由于训练样本少而导致的模型过拟合问题。本文从基于度量学习和基于参数优化两个角度介绍该部分,基于度量学习的小样本方法旨在通过线性或非线性度量方式度量样本间的相似程度,但对于小样本学习训练样本较少的情况仅简单通过距离评估样本匹配程度会影响模型精度。基于参数优化的小样本学习旨在通过元学习器学习跨任务通用的模型参数,使得基学习器在面对新任务时仅需少量样本通过几步训练即可获得最优模型。但其难点在于学习器的设计,应提高对先验知识的利用,避免选择性遗忘已学得的和任务相关的知识。基于转导图小样本的学习方法旨在通过图节点传递信息辅助预测,该方法无须构建分类模型,但每次引入新数据点时,必须重新运行所有图结构,导致时间复杂度较高。
通过梳理当前小样本学习的研究进展,展望未来小样本学习的几个发展方向:
a)基于数据增强的小样本学习是比较简单且直接的解决训练样本少的方法。监督增强一般采用额外的词向量或语义信息进行数据增强,而无监督增强更多是通过学习类内变形信息进行数据增强,利用辅助信息进行数据增强使得生成的数据更易迁移到其他数据集。相比于图像合成,特征增强生成的数据维度大大降低比生成图像更容易,特征增强可以生成大量数据以增加数据多样性,并且增强的特征具有可判别性和稳定性。因此,未来方向可以更多考虑基于监督的特征增强。并且现实世界中存在大量无标注数据和跨模态信息(比如文本信息),其蕴涵大量可迁移的知识,较图片数据更易获得,因此,利用无标注数据或跨模态信息辅助特征增强是比较有潜力的研究方向之一。此外,目前已有研究将数据增强作为数据预处理然后结合小样本度量学习模型进行训练[30],尽管取得很好的效果,但还不成熟,未来可以尝试结合数据增强和小样本分类模型优化两个方面来提高模型精度。
b)对于元学习而言,基于度量学习的小样本学习发展相对较早,经典的度量学习方法比如原型网络、匹配网络等多采用固定度量方式,但该方面的研究已相当成熟,未来应设计性能更好的非线性度量方式让模型自己学会度量。而基于参数优化的小样本学习未来应更好地设计元学习器,使其学习到更多或更有效的元知识来辅助训练基学习器以提高模型训练速度。
c)基于转导图的小样本学习方法近几年研究比较火热。图作为计算机的一种数据结构,具有较强的可解释性,比较直观,未来可以考虑如何设计图的网络结构、如何进行标签传播或节点间的信息传递。
深度学习的发展对小样本学习有一定的推动作用,然而深度學习更像是一个黑盒具有不可解释性,未来应考虑如何利用外部先验知识和内部数据知识增强小样本学习模型的可解释性。此外,跨模态信息不仅用于数据增强,目前其在小样本学习的各个研究领域均有应用,并且取得了不错的效果,未来也可考虑如何利用跨模态信息辅助训练小样本模型。
参考文献:
[1]LeCun Y, Bengio Y, Hinton G. Deep learning[J].Nature,2015,521(7553):436-444.
[2]Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//Proc of International Confe-rence on Neural Information Processing Systems.2012:1106-1114.
[3]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE International Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2016:770-778.
[4]Mikolov T, Tarafiát M, Burge L, et al. Recurrent neural network based language model[C]//Proc of Conference of International Speech Communication Association.2010.
[5]Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Proc of International Conference on Neural Information Processing Systems.2014:3104-3112.
[6]Norouzzadeh m S, Nguyen A, Kosmala M, et al. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning[J].Proc of the National Academy of Sciences,2018,115(25):5716-5725.
[7]Gebru T, Krause J, Wang Yichun, et al. Using deep learning and google street view to estimate the demographic makeup of neighborhoods across the united states[J].Proc of the National Academy of Sciences,2017,114(50):13108-13113.
[8]Lu Jiang, Gong Pinghua, Ye Jieping, et al. Learning from very few samples:a survey[EB/OL].(2020).[2021-10-12].https://arxiv.org/abs/2009.02653.
[9]Miller E G, Matsakis N E, Viola P A. Learning from one example through shared densities on transforms[C]//Proc of IEEE International Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2000:464-471.
[10]Li Feifei, Robert F, Pietro P. A Bayesian approach to unsupervised one-shot learning of object categories[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2003:1134-1141.
[11]Koch G, Zemel R, Salakhutdinov R. Siamese neural networks for one-shot image recognition[C]//Proc of International Conference on Machine Learning.2015.
[12]Wang Yaqing, Yaoquanming. Few-shot learning: a survey[EB/OL].(2019).[2021-10-12].http://arxiv.org/abs/1904.05046v1.
[13]趙凯琳,靳小龙,王元卓.小样本学习研究综述[J].软件学报,2021,32(2):349-369.(Zhao Kailin, Jin Xiaolong, Wang Yuanzhuo. Survey on few-shot learning[J].Journal of Software,2021,32(2):349-369.)
[14]安胜彪,郭昱岐,白宇,等.小样本图像分类研究综述[J].计算机科学与探索,2023,17(3):511-532. (An Shengbiao, Guo Yuqi, Bai Yu, et al. Survey of few-shot image classification research[J].Journal of Frontiers of Computer Science and Technology,2023,17(3):511-532.)
[15]Lampert C H, Nickisch H, Harmeling S. Attribute-based classification for zero-shot visual object categorization[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2013,36(3):453-465.
[16]Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Proc of International Conference on Neural Information Processing Systems.2013:3111-3119.
[17]Chatfield K, Simonyan K, Vedaldi A, et al. Return of the devil in the details: delving deep into convolutional nets[C]//Proc of International Conference on British Machine Vision Conference.2014.
[18]Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]//Proc of European Conference on Computer Vision.Berlin:Springer,2014:818-833.
[19]Shen Xiaoyong, Hertzmann A, Jia Jiaya, et al. Automatic portrait segmentation for image stylization[J].Computer Graphics Forum,2016,35(2):93-102.
[20]Chen Zitian, Fu Yanwei, Zhang Yinda, et al. Semantic feature augmentation in few-shot learning[C]//Proc of European Conference on Computer Vision,2018.
[21]Chen Zitian, Fu Yanwei, Zhang Yinda, et al. Multi-level semantic feature augmentation for one-shot learning[J].IEEE Trans on Image Processing,2019,28(9):4594-4605.
[22]Yu Xiaodong, Aloimonos Y. Attribute-based transfer learning for object categorization with zero/one training example[C]//Proc of European Conference on Computer Vision.Berlin:Springer,2010:127-140.
[23]Lu Jiang, Li Jin, Yan Ziang, et al. Attribute-based synthetic network (ABS-Net):learning more from pseudo feature representations[J].Pattern Recognition,2018,80:129-142.
[24]Frederik P, Patrick J, Tassilo K, et al. Cross-modal hallucination for few-shot fine-grained recognition[EB/OL].(2018).[2021-10-12].http://arxiv.org/pdf/1806.05147.pdf.
[25]潘理虎,刘云,谢斌红,等.基于语义增强的多特征融合小样本关系抽取[J].计算机应用研究,2022,39(6):1663-1667.(Pan Lihu, Liu Yun, Xie Binhong, et al. Multi-feature fusion and few-shot relation extraction based on semantic enhancement[J].Application Research of Computers,2022,39(6):1663-1667.)
[26]呂天根,洪日昌,何军,等.多模态引导的局部特征选择小样本学习方法[J].软件学报,2023,34(5):2068-2082.(Lyu Tiangen, Hong Richang, He Jun, et al. Multimodal-guided local feature selection for few-shot learning[J].Journal of Software,2023,34(5):2068-2082.)
[27]Schwartz E, Karlinsky L, Feris R, et al. Baby steps towards few-shot learning with multiple semantics[J].Pattern Recognition Letters,2022,160:142-147.
[28]Hariharan B, Girshick R. Low-shot visual recognition by shrinking and hallucinating features[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2017:3018-3027.
[29]Schwartz E, Karlinsky L, Shtok J, et al. Delta-encoder: an effective sample synthesis method for few-shot object recognition[C]//Proc of International Conference on Neural Information Processing Systems.2018:2845-2855.
[30]Wang Yuxiong, Girshick R, Hebert M, et al. Low-shot learning from imaginary data[C]//Proc of IEEE International Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2018:7278-7286.
[31]Hang Gao, Zheng Shou, Zareian A, et al. Low shot learning via covariance-preserving adversarial augmentation networks[C]//Proc of International Conference on Neural Information Processing Systems.2018:975-985.
[32]Tsendsuren M, Yu Hong. Meta networks[C]//Proc of International Conference on Machine Learning.2017:2554-2563.
[33]Vilalta R, Drissi Y. A perspective view and survey of meta-learning[J].Artificial Intelligence Review,2002,18(2):77-95.
[34]Oreshkin B, López P R, Lacoste A. TADAM: task dependent adaptive metric for improved few-shot learning[C]//Proc of International Conference on Neural Information Processing Systems.2018:721-731.
[35]Chen Xing, Rostamzadeh N, Oreshkin B, et al. Adaptive cross-modal few-shot learning[C]//Proc of International Conference on Neural Information Processing Systems.2019:4848-4858.
[36]Vinyals O, Blundell C, Lillicrap T, et al. Matching networks for one shot learning[C]//Proc of International Conference on Neural Information Processing Systems.2016:3630-3638.
[37]Snell J, Swersky K, Zemel R. Prototypical networks for few-shot learning[C]//Proc of International Conference on Neural Information Processing Systems.2017:4077-4087.
[38]Pennington J, Socher R, Manning C D. GloVe:global vectors for word representation[C]//Proc of International Conference on Empirical Methods in Natural Language Processing.2014:1532-1543.
[39]Li Xiaomeng, Yu Lequan, Fu Chiwing, et al. Revisiting metric learning for few-shot image classification[EB/OL].(2019-07-06).https://arxiv.org/abs/1907.03123.
[40]Yang Fengyuan, Wang Ruiping, Chen Xilin. SEGA: semantic guided attention on visual prototype for few-shot learning[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision.2022:1586-1596.
[41]Sung F, Yang Yongxin, Zhang Li, et al. Learning to compare: relation network for few shot learning[C]//Proc of IEEE International Confe-rence on Computer Vision & Pattern Recognition.2018:1199-1208.
[42]孙统风,王康,郝徐.面向小样本学习的双重度量孪生神经网络[J].计算机应用研究,2023,40(9):2851-2855.(Sun Tongfeng,Wang Kang, Hao Xu. Dual-metric siamese neural network for few-shot learning[J].Application Research of Computers,2023,40(9):2851-2855.)
[43]韋世红,刘红梅,唐宏,等.多级度量网络的小样本学习[J].计算机工程与应用,2023,59(2):94-101.(Wei Shihong, Liu Hongmei, Tang Hong, et al. Multilevel metric networks for few-shot learning[J].Computer Engineering and Applications,2023,59(2):94-101.)
[44]Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//Proc of International Conference on Machine Learning.2017:1126-1135.
[45]Li Zhenguo, Zhou Fengwei, Chen Fei, et al. Meta-SGD:learning to learn quickly for few shot learning[EB/OL].(2017).[2021-10-12].http://arxiv.org/abs/1707.09835.
[46]Zhou Fengwei, Wu Bin, Li Zhenguo. Deep meta-learning: learning to learn in the concept space[EB/OL].(2018).[2021-10-12].http://arxiv.org/pdf/1802.03596.
[47]Jiang Xiang, Havaei M, Varno F, et al. Learning to learn with conditional class dependencies[C]//Proc of International Conference on Learning Representations.2019.
[48]Jamal M A, Qi Guojun. Task agnostic meta-learning for few-shot learning[C]//Proc of IEEE International Conference on Computer Vision & Pattern Recognition.Piscataway,NJ:IEEE Press,2019:11719-11727.
[49]Huang Wenke, Ye Mang, Du Bo, et al. Few-shot model agnostic federated learning[C]//Proc of the 30th ACM International Confe-rence on Multimedia.New York:ACM Press,2022:7309-7316.
[50]Rodríguez P, Laradji I, Prouin A, et al. Embedding propagation: smoother manifold for few-shot classification[C]//Proc of European Conference on Computer Vision.2020:121-138.
[51]Qiao Limeng, Shi Yemin, Li Jia, et al. Transductive episodic-wise adaptive metric for few-shot learning[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2019:3602-3611.
[52]Liu Yanbin, Lee J, Park M, et al. Learning to propagate labels: transductive propagation network for few-shot learning[C]//Proc of International Conference on Learning Representations.2019.
[53]汪航,田晟兆,唐青,等.基于多尺度標签传播的小样本图像分类[J].计算机研究与发展,2022,59(7):1486-1495.(Wang Hang, Tian Shengzhao, Tang Qing, et al. Few-shot image classification based on multi-scale label propagation[J].Journal of Computer Research and Development,2022,59(7):1486-1495.)
[54]Ma Yuqing, Bai Shihao, An Shan, et al. Transductive relation-pro-pagation network for few-shot learning[C]//Proc of International Joint Conference on Artificial Intelligence.2020:804-810.
[55]Zhang Ruiheng, Yang Shuo, Zhang Qi, et al. Graph-based few-shot learning with transformed feature propagation and optimal class allocation[J].Neurocomputing,2022,470:247-256.
[56]Liu Lu, Zhou Tianyi, Long Guodong, et al. Learning to propagate for graph meta-learning[C]//Proc of International Conference on Neural Information Processing Systems.2019:1037-1048.
[57]Chen Chaofan, Yang Xiaoshan, Xu Changsheng, et al. ECKPN: explicit class knowledge propagation network for transductive few-shot learning[C]//Proc of IEEE International Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2021:6596-6605.
[58]Fort S. Gaussian prototypical networks for few-shot learning on Omniglot[EB/OL].(2017).[2021-10-12].http://arxiv.org/pdf/1708.02735.
[59]Malalur P, Jaakkola T. Alignment based matching networks for one-shot classification and open-set recognition[EB/OL].(2019).[2021-10-12].http://arxiv.org/pdf/1903.06538.
[60]Ren Mengye, Triantafillou E, Ravi S, et al. Meta-learning for semi-supervised few-shot classification[EB/OL].(2018).[2021-10-12].http://arxiv.org/abs/1803.00676.
[61]Yin Cui, Feng Zhou, Lin Yuanqing, et al. Fine-grained categorization and dataset bootstrapping using deep metric learning with humans in the loop[C]//Proc of IEEE Conference on Computer Vision & Pattern Recognition. Piscataway,NJ:IEEE Press,2016:1153-1162.
[62]Deng Jia, Dong Wei, Socher R, et al. ImageNet: a large-scale hierarchical image database[C]//Proc of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2009:248-255.
[63]Michael B, Tracy K, Samuel D. Amazons mechanical turk[J].Perspectives on Psychological Science,2011,6(1):3-5.
[64]Rusu A A, Rao D, Sygnowski J, et al. Meta-learning with latent embedding optimization[C]//Proc of International Conference on Lear-ning Representations.2018.
[65]Sun Q, Liu Yaoyao, Chua T S, et al. Meta-transfer learning for few-shot learning[C]//Proc of IEEE International Conference on Compu-ter Vision & Pattern Recognition.Piscataway,NJ:IEEE Press,2019:403-412.
[66]Yang Ling, Li Liangliang, Zhang Zilun, et al. DPGN: distribution propagation graph network for few-shot learning[C]//Proc of IEEE Conference on Computer Vision & Pattern Recognition.Piscataway,NJ:IEEE Press,2020:13387-13396.
收稿日期:2023-02-25;修回日期:2023-04-10
基金项目:国家自然科学基金資助项目(62376114);克拉玛依科技发展计划项目(2020CGZH0009);福建省自然科学基金资助项目(2021J011004,2021J011002);教育部产学研创新计划资助项目(2021LDA09003)
作者简介:潘雪玲(1992-),女,山东聊城人,博士研究生,CCF会员,主要研究方向为机器学习、小样本学习;李国和(1965-),男,福建平和人,教授,博导,博士,主要研究方向为人工智能、机器学习、知识发现等;郑艺峰(1980-),男(通信作者),福建漳州人,讲师,硕导,博士,主要研究方向为数据挖掘、特征工程、机器学习、深度学习等(zyf@mnnu.edu.cn).
