
基于注意力机制的文本挖掘深度混合推荐模型
2023-10-16 12:33陈增照
华中师范大学学报(自然科学版) 2023年5期
张 婧, 陈增照, 段 超, 王 虎
(1.江汉大学教育学院, 武汉 430065; 2.华中师范大学人工智能教育学部, 武汉 430079;3.浙江师范大学浙江省智能教育技术与应用重点实验室, 浙江 金华 321004)
手机等移动设备的普及使人们的日常生活更加依赖移动服务,人们从移动设备中获取业务信息、产品信息、促销信息和推荐信息.移动服务的重要应用是视频推荐[1].推荐算法作为信息过滤的重要手段,旨在为用户推荐个性化、小规模的信息集合以解决“信息过载”和“信息迷航”等问题[2],已在电子商务、社交平台、新闻、电影、音乐等众多应用服务[3]中得到初步应用.协同过滤是目前应用最广泛的一种推荐算法[4],它首先分析历史行为数据生成与当前用户行为兴趣最相近的用户群,再将该用户群当前的喜好推荐给当前用户.
协同过滤不依赖于物品和用户本身的特征,具有领域无关的特性,但该方法易遭受冷启动和数据稀疏问题[5].为缓解这两类问题的影响,研究者往往将用户或者物品的辅助信息应用到协同过滤中以提高推荐的准确性[6-7].现有研究中用到的辅助信息主要包括社会网络、用户和项目的属性和上下文信息等,在文件形式上则包括文本、图片、视频、音频等多种类型,其中使用最多的是文本信息.
近年来,由于深度学习在特征提取方面以及注意力机制在特征选择方面的突出表现,越来越多的研究使用融合注意力机制的深度学习模型挖掘辅助信息的潜藏因子以生成有效的表示形式.如卷积神经网络与概率矩阵分解相结合的模型[8](convolutional matrix factorization,ConvMF),堆叠式降噪自编码器与概率矩阵分解相结合的模型[9](a variant of stacked denoising autoencoder, aSDAE),以及将卷积神经网络和自编码器相结合的模型[10](a probabilistic model of hybrid deep collaborative filtering,PHD).最近注意力机制在自然语言处理领域表现突出,Wang等[11]将注意力机制与长短时记忆网络(long short-term memory,LSTM)相结合进行语义关系抽取.基于注意力的模型[12](dual attention-based,D-Attn),通过使用局部和全局注意力机制和卷积神经网络提取文本信息的特征做评分预测.自编码器与注意力机制相结合的模型[13]CATA++(collaborative dual attentive autoencoder,CATA++),提高了科技论文推荐的准确率.谷歌提出的Transformer[14]是基于注意力的机器翻译架构,它是一个混合神经网络,具有前馈层和自注意层,其研究首次提出了多头注意力机制,将多个自注意力连接起来,同时通过降低维度减少计算消耗,并且能够捕捉长距离单词之间的相关性.
本文提出了一种融合多头注意力机制的卷积矩阵分解模型(multi-head attention convolutional matrix factorization,MACMF).该模型将描述项目的文本信息转化为词向量,经过预训练的词向量完成初始化,在卷积神经网络的嵌入层和卷积层之间加入多头注意力机制,提取项目的潜在因子,再结合概率矩阵分解做评分预测.
本文的主要贡献包括以下三个方面.首先,将多头注意力机制融入卷积神经网络,优化了ConvMF模型,利用超参数平衡上下文信息和评分信息,减少了数据稀疏带来的不利影响.其次,优化了卷积神经网络模型.在卷积层中增加长度为1的卷积核,有利于提取单一词特征,在池化层中采用k-max-pooling技术,减少信息丢失.最后,在ML-100k、ML-1m、ML-10m、Amazon四个公开数据集上的大量实验表明,与所有基线模型相比,其结果均能取得更好的效果.
1 相关工作
本节深入分析与本研究相关的研究有两条线,第一条是基于深度学习的推荐模型,第二条是融合注意力机制的推荐模型.
1.1 基于深度学习的推荐模型
近年来,深度学习在语音识别,图像处理和自然语言处理(natural language processing,NLP)领域受到了极大的关注[15].深度学习技术已成为人工智能领域和推荐系统的研究前沿.深度学习具有非线性变换、表征学习、序列建模、灵活性等特点,基于深度学习的推荐系统可以分为两大类:集成模型和神经网络模型[16].集成模型又分为两种类型:1)将深度学习与传统推荐模型集成在一起,并且仅依靠深度学习模型进行推荐;2)将深度学习模型与传统推荐模型集成在一起,试图以一种或多种方式将深度学习方法与传统推荐技术相结合.按照所采用的深度学习技术的类型, 将神经网络模型分为两类:使用单一深度学习技术的模型和深度复合模型.在单一深度学习技术中,分为八个子类:基于MLP、AE、CNN、RNN、RBM、NADE、AM、AN和DRL的推荐系统[17].深度学习技术的使用提高了推荐模型的适用性,例如多层感知机可以有效地对用户和项目之间的非线性交互进行建模[18],CNN能够从异类提取局部和全局表示[19].深度复合模型的动机在于,不同的深度学习技术可以互相补充,并能够提供更强大的混合模型[16].
1.2 融合注意力机制的推荐模型
注意力机制的思想是由人类的视觉系统以及人的眼睛如何关注和集中于图像的特定部分或者句子中的特定单词所激发的[13].它的核心逻辑是从关注全部到关注重点,并非所有的输入信息都同等重要,只有一小部分信息对模型起关键作用,深度学习中的注意力可以简单地描述为权重向量,用来显示输入元素的重要性.注意力机制最早使用在图像分类任务中[20],当看一张图片时,一般不会关注图片的全部内容,而是将注意力集中在图片的部分焦点上.后来研究者将其引入自然语言处理领域,成功提升了机器翻译的性能.目前,在不同的推荐任务中也使用了注意力机制[21-22].例如MPCN[21]结合评论级和文本级信息解决文档级问题,通过利用指针网络挑出重要的评论从而用来建模当前的用户项目矩阵.此外,NAIS[22]使用注意力网络区分用户配置文件中的项目,这些项目在模型预测中具有更大的影响力.
2 多头注意力卷积矩阵分解模型
本节将对MACMF的原理和主要模块进行详细介绍.首先介绍概率矩阵分解模型,描述了组合概率矩阵分解和融合注意力机制的卷积神经网络的主要思想.接下来,给出了融合注意力机制的卷积神经网络的详细架构,说明了MACMF模型可以通过分析项目描述文档产生项目的潜在因子.最后,描述了优化MACMF模型的方法.
2.1 MACMF概率模型
本研究在ConvMF模型结构图的基础上改进得到图1 所示的MACMF模型结构,该模型在卷积神经网络的嵌入层和卷积层之间加入多头注意力机制,将融合多头注意力机制的卷积神经网络模型(multi-head attention convolutional neural network,MACNN)集成到概率矩阵分解(probabilistic matrix factorization,PMF)中.

图1 MACMF模型结构Fig.1 MACMF model structure
假设有N个用户和M个项目,目标是找到用户和项目的潜在因子,将它们的乘积重构评分矩阵.
p(R∣U,V,σ2)=∏∏N(Rij∣Ui,Vj,σ2),
(1)
其中,N是均值为μ、方差为σ2的零高斯正态分布的概率密度函数.作为用户潜在模型的生产模型,将零均值的球面高斯先验放在方差为σ2的用户的潜在因子上.
图1中U为用户的潜在因子,V为项目的潜在因子,R为评分矩阵,Xj表示项目j的描述文档,W为内部权重.从MACNN模型获得的文档潜在向量用作高斯分布的均值,项目的高斯噪声用作高斯分布的方差,这是MACNN和PMF之间的桥梁,有助于将文本特征与评分矩阵组合在一起分析.
2.2 融合多头注意力的MACMF
本研究中的MACNN体系结构是在卷积神经网络的嵌入层和卷积层之间加入多头注意力机制,目的是从电影的描述文档信息中获取项目的潜在因子.该体系结构包含五层:1) 嵌入层;2) 多头注意力层;3) 卷积层;4) 池化层;5) 输出层.
嵌入层是根据单词的长度将原始文档转换成数字矩阵,然后输出到下一层.如果有一个单词,通过将文档中单词的嵌入向量进行级联对文档进行矩阵表示.然后,通过优化过程进一步训练词向量.
多头注意力层选择重要特征.多头注意力机制首先将向量信息经过一个线性变换,然后将其输入到缩放点积注意力中,总计做h次,每一次算一个头,头之间参数不共享,然后将h次的缩放点积注意力结果进行拼接,最后进行一次线性变换得到的值作为多头注意力的结果.
(2)
MultiHead(Q,K,V)=
Concat(head1,…,headh)WO.
(3)
公式表明多头注意力的不同之处在于进行h次计算而不仅仅算一次,这样的优点是可以允许模型在不同的表示子空间里学习相关的有用信息[23].
卷积层提取上下文特征.由于文档在上下文信息的本质上与信号处理或计算机视觉不同,因此使用NLP中的特定卷积架构正确提取文档特征.在卷积层中,采用窗口大小分别为1、3、5、7的一维卷积核对词向量矩阵进行上下文特征提取.
池化层不仅从卷积层中提取代表性特征,而且还通过构建固定长度特征向量的合并操作处理可变长度的文档.在池化层中,采用k-max-pooling技术提取代表性特征.k-max-pooling认为每一块不只一个点重要,前几个点可能都比较重要,所以在每一个pooling块中取前k大的值.
(4)
在输出层,通过转换从上一层获得的高级功能以用于特定任务.为推荐任务投影了用户和项目的潜在因子的K维空间,最终通过使用常规的非线性投影生成文档的潜在向量.
2.3 最大后验估计优化方法
为了优化模型,例如用户的潜在因子和项目的潜在因子,MACNN的权重和偏差参数,使用最大后验估计优化变量U、V和W,操作如下:
(5)
通过对式(5)等号两边取负对数,将其重构为最小化损失函数L.
我家住在三楼,楼层并不算高,不知何故,一气上楼,竟累得我气喘吁吁的,躺在床上,休息了半个多小时,也硬是没有歇过来。
L(U,V,W)=
(6)

采用坐标下降法最小化L,在固定其余变量的同时迭代优化潜在变量,式(6)为关于U的二次函数,同时暂时假定V和W为常数,可以通过Ui微分求损失函数L.对V采取同样的操作得到如下表示,ui←(VIiVT+λUIK)-1VRi,
(7)
vj←(UIjUT+λVIK)-1(URj+λVMACNNW(Xj) ),
(8)
其中,Ii、Ij、IK为单位对角矩阵,λU和λV为平衡参数.式(8)显示了文档潜在向量MACNN(即MACNNW(Xj))通过λV更新vj作为平衡参数的效果.
然而,无法像处理U和V那样更新W,因为W和MACNN体系结构中的非线性相关.众所周知,当U和V暂时恒定时,损失函数L可以解释为L2的正则项加权平方误差函数.得到ε(W)如下式,
(9)
同样的,使用在神经网络中通用的反向传播算法求得公式(10),优化W直至收敛或者达到预定义的迭代次数为止.
∇wkε(W)=
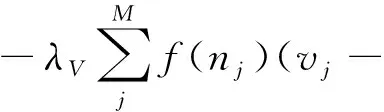
(10)
通过优化U、V、W,最终可以得到预测的用户对项目的未知评分信息.
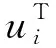
(11)
其中,Vj=MACNNW(Xj)+εj.算法流程图如下所示.

算法1 MACMF算法输入:用户项目评分矩阵R,电影简介信息X.目标:优化潜在因子U、V和W1:随机初始化U和W2: for j ≤M do3: 通过vj ←MACNNW (Xj )初始化V4:end for5:重复6:for i≤N do 更新 ui←(VIi VT+λU IK )-1VRi end for for j ≤M do 更新 vj←(UIj UT+λV IK )-1(URj+λV MACNNW (Xj ) ) end for 重复 for j ≤M do wk ε(W)=-λV Mjf(nj )(vjwk MACNNW (Xj ) )+λW wk end for 直到收敛直到满足早期停止使用验证集.
3 实验结果与分析
本节使用来自不同领域的四个数据集评估MACMF模型的性能,并将MACMF模型与五个经典的基线算法进行比较,同时分析不同超参数对本文提出的MACMF模型的实验结果的影响.
3.1 数据集及其预处理
为评估MACMF方法的效果,在MovieLens[24]和Amazon[25]两个公开数据集上进行测试.原始的MovieLens数据集包含72 000个用户,10 681部电影和10 000 054个评分数据,评分范围为1到5分.本实验采用它的三个子集,分别为ML-100k,ML-1m和ML-10m.为了将用户的评分数据和相应的评论数据关联,从IMDB网站上收集了相关电影的简介信息.Amazon数据集既包含用户的评分,又包含评论信息.两个数据集都非常稀疏.
为进行公平的比较,采用与文献[8]相同的方式对原始数据集做了预处理工作:删除了MovieLens中没有包含电影简介信息的项目,并删除Amazon数据集中评分低于3项的用户.经过预处理之后的数据集信息如表1所示.对于文本信息,通过以下步骤进行预处理:将原始文档的最大长度设置为300,去掉停用词;计算每个词的TF-IDF值作为特征值,删除文档频率高于0.5的词;最后选择前8 000个词作为词汇表.在对文本进行处理时,采用预训练的词嵌入模型Glove转化为300维词向量,生成300×300的词向量矩阵作为卷积神经网络的输入.

表1 四个经过预处理的数据集统计结果
3.2 对比模型及软硬件环境
为评估模型的性能,选择五种经典模型作为基线算法.
PMF[26]:概率矩阵分解是一种通用的基线方法,它可以根据用户和项目的潜在特征预测用户评分.潜在特征代表用户的不同兴趣点.这种方法的前提假设是用户和项目的评分都服从高斯分布.
CTR[27]:协作主题回归是一个紧密耦合的模型,该模型将协同过滤PMF和潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)相结合.该模型尝试将评分和文本信息结合预测评分.
CDL[28]:协作深度学习是一种新提出的深度贝叶斯模型,该模型使用精心设计的深度学习模型堆叠式降噪自编码器预测评分,试图从辅助信息中提取用户的偏好.
ConvMF[8]:卷积矩阵分解是最新的上下文感知推荐模型之一,该模型将卷积神经网络集成到PMF中,学习文档上下文的文本特征.
ConvMF+[8]:此方法是在ConvMF的方法的基础上通过使用预训练的词嵌入模型Glove扩展应用.
本实验软件环境为集成开发平台PyCharm Community Edition 2020.1.1 x64,Python 3.7,Keras 2.3.1.硬件环境为Intel Core i7 4790K 4.00 GHz CPU,GeForce GTX 1080 GPU、32GB内存和1T存储空间.
3.3 评价指标
推荐系统的评价指标通常分为三类[29]:1) 预测准确性指标(例如RMSE和MAE),主要用于评估推荐系统预测评分的准确性;2) 分类准确性度量(例如Precision和Recall),用于测量推荐系统做出正确决策的频率;3) 排名准确性度量(例如DCG和MAP),评估由推荐系统执行的项目排名的正确性.本文的目标是做评分预测,因此采用RMSE和MAE作为评价指标.通常RMSE和MAE可以表示如下:
(12)
(13)

3.3 实验结果
表2展示了MACMF和五个基线算法的总体评分预测误差.表中长短期记忆网络矩阵分解(long short-term memory matrix factorization,LSTMMF)是将所提MACMF模型中的CNN部分替换为LSTM所得到的实验结果.其中,最后一行表示本文模型相对于基线算法在每组数据集中最佳结果(粗体标识基线模型的最优效果,下划线标识每组数据集的最佳效果)的提升,分别2.07%、1.12%、0.79%和2.68%.表明多头注意力机制在卷积层之前选择了对推荐结果有影响的重要特征.可见,对于四组数据集,MACMF均能达到最好的RMSE值.

表2 四个数据集上的评价结果
表3给出了在不同λu和λv组合值下,RMSE和MAE的变化情况.实验结果表明,(λu,λv)在ML-100k、ML-1m、ML-10m和AIV上分别取(2,50)、(2,210)、(8,50)、(1,40)时,MACMF模型能取得最好的结果,说明合适的λu和λv组合可以有效地平衡评分信息和物品描述文档信息,从而降低MACMF模型的RMSE和MAE值.
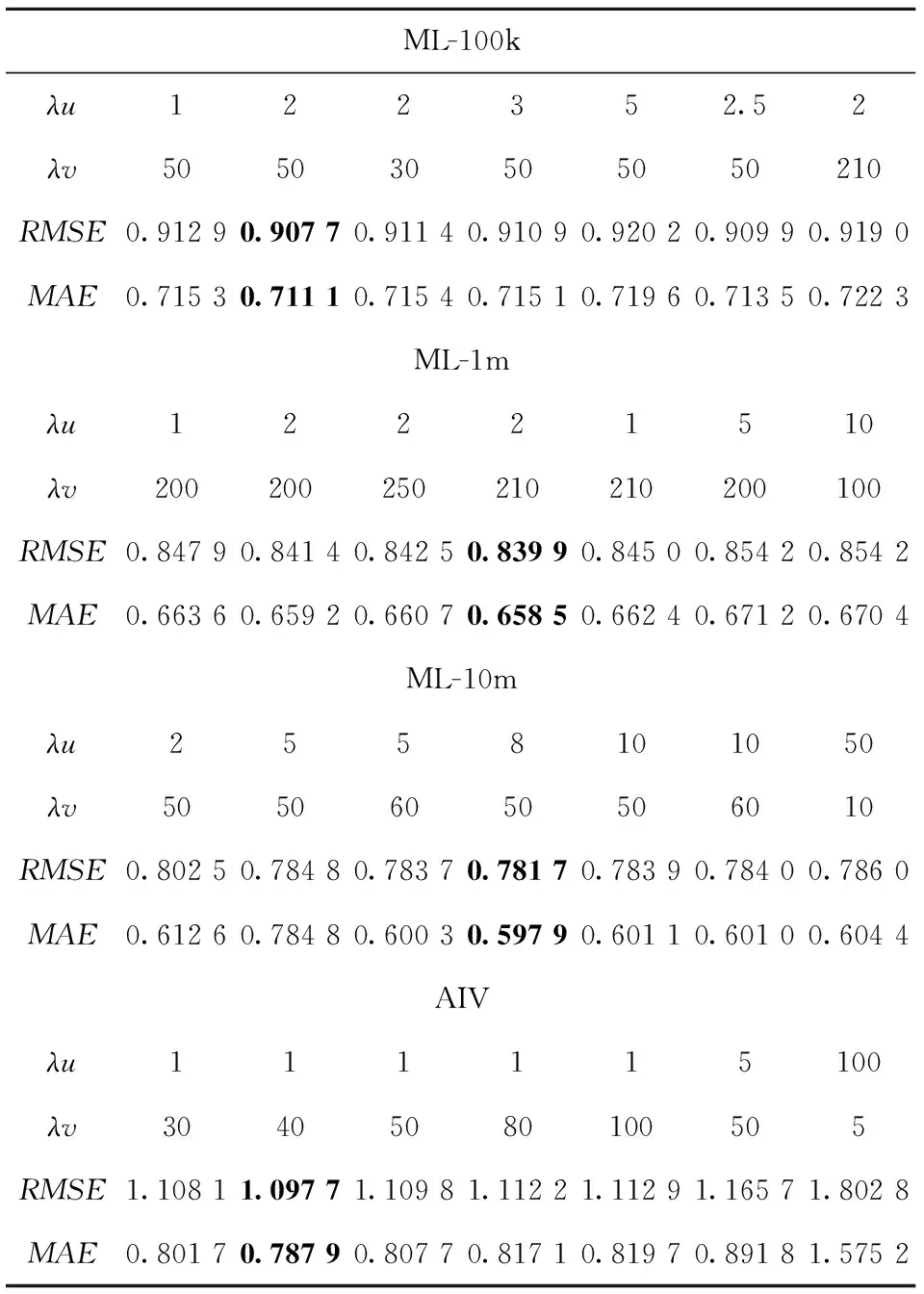
表3 λu和 λv 在四个数据集上对RMSE和MAE的结果影响
此外,还研究了训练数据的比例如何影响模型性能.将ML-1m数据集的密度从20%提高到80%,相应的RMSE结果如图2所示.从中可看出,MACMF模型始终表现最佳,而且ConvMF是次佳的.随着训练数据比例的增加,所有方法的RMSE均逐渐下降,这与研究的预判相同,即随着训练数据增加,模型的性能也随之提高.
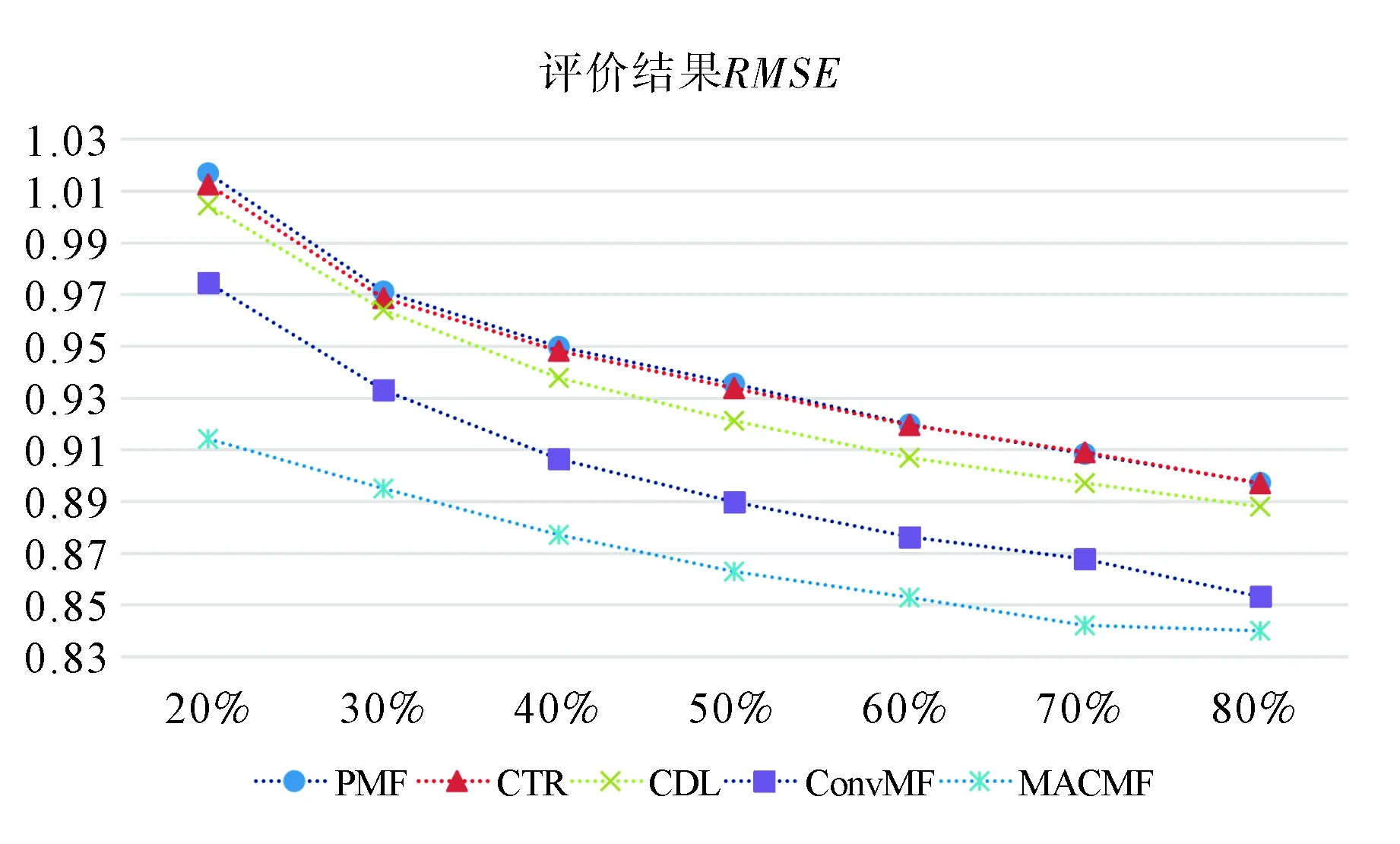
图2 调整不同训练数据的百分比对评价结果的影响Fig.2 Effect of adjusting percentages of different training data on evaluation results
多头的本质是多个独立的注意力计算,作为一个集成作用,防止过拟合,同文献[14]中输入序列是完全一样的;Q、K、V通过线性转换,每个注意力机制的函数只负责最终输出序列中一个子空间,而且相互独立.深度学习技术的超参数众多,不同的超参数组合对实验结果产生极其重大的影响,本实验通过大量的实验得出了MACMF模型的最佳组合结果.
4 结论及展望
本文提出融合注意力机制的深度卷积神经网络模型MACMF,通过将多头注意力机制的卷积神经网络巧妙地融合到PMF框架中,多头注意力机制在CNN的嵌入层和卷积层之间,增强了CNN模型的特征选择和提取能力,有效防止过拟合,通过大量参数的调整使得模型达到了最佳性能.并通过多组实验分析了实验的具体参数对实验结果的影响,特别是通过利用LSTM与PMF融合的LSTMMF模型的对比结果,检验了本文提出的MACMF模型的有效性.大量实验结果表明,MACMF可以从文本上下文中提取更多的物品潜在因子,从而提高模型的性能.
虽然本文所提模型取得了较好的效果,但是未来还存在继续改进的可能性.主要表现在如下几个方面,第一是评论文本特征提取有巨大的发展空间,随着人工智能在自然语言处理领域取得的不断突破,将有更高效更精准的评论文本特征提取模型产生,可以为基于评论文本的深度推荐系统获得更大的发展空间,取得更好的效果.第二是用户、项目以及用户-项目上下文信息纷繁复杂,呈现多源异构性,如何从这些海量的辅助信息中提取对推荐结果产生影响的因子是未来的重要研究方向.例如模型中没有考虑对用户辅助信息的特征挖掘、对用户进行画像、利用用户的相关信息提取用户的潜在因子,预测可以进一步提升模型的准确率,为线上用户提供更加个性化的视频资源推荐服务.第三是海量特征提取后的特征融合以及时间因素对特征的影响.当提取出多源异构辅助信息后,调节各种辅助信息之间的作用大小是重要的研究点.用户的兴趣偏好存在动态性,会随着时间不断发生变化,如何提取用户的动态偏好特征也是下一步的研究难点.总而言之,利用物联网技术全方位采集数据,然后通过大数据和人工智能技术从海量数据中挖掘影响推荐结果的影响因素是进一步研究的热点.
猜你喜欢
客联(2022年3期)2022-05-31
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
中国新闻周刊(2021年26期)2021-07-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
信息安全研究(2016年4期)2016-12-01
第二课堂(课外活动版)(2016年2期)2016-10-21
