
基于主成分分析的基因芯片数据研究
2023-10-16 08:46:26孙鑫
黑龙江科学 2023年18期
孙 鑫
(泰州学院数理学院,江苏 泰州 225300)
0 引言
白血病是血液系统常见的恶性肿瘤,以血液与骨髓中成熟白细胞及其前体不受控制的恶性增殖为特征[1]。白血病是最常见的癌症,而急性髓细胞白血病(AML)是一种严重危害人类健康的恶性血液系统疾病,在儿童急性白血病中的发生率占15%~30%[2]。近年来,我国AML发病率逐渐增高[3-4],给家庭及社会造成了严重的负担[5]。随着大量基因序列数据的出现,基因芯片技术成为基因序列数据研究的重点。基因芯片在疾病预测、太空探索、药物开发、食品安全、个体化治疗、农业生物等领域都有一定的应用。目前,医生主要根据临床经验进行诊断,精确度不高,如果将基因芯片技术应用于检查中,能够快速判断疾病的原因及类型,针对性地制定科学合理的治疗方案。白血病对人类健康威胁较大,对AML患者进行基因芯片分析将显著提高诊断的准确性,有利于疾病治疗。但基因芯片包含大量的数据,难以直接分析原始数据,故对基因芯片数据的降维至关重要,其便于人们快捷地从基因芯片大数据中提取关键信息。
1 数据来源
基因芯片数据可以看作是一个N×M的矩阵:
其中,M为样本个数,N为基因个数(一般情况下N≫M);行向量Xi=(xi1,xi2,…,xiM)表示基因i在M个样本下的表达水平;列向量Xj=(x1j,x2j,…,xNj)T为在第j个样本中每个基因的表达水平;元素xij为基因i在第j个样本中的表达水平。基于该基因表数据矩阵进行分析,从国家生物技术信息中的GEO基因数据库获取数据,选取AML的原始数据集。表1为该数据集的样本类型及基因个数。AML的数据集包含两种类型的样本,即突变型(mutated)与野生型(wide-type),共78个。其中突变型样本量为57,野生型样本量为21,每个样本包含13 515个基因,故将该数据集视为一个13 515×78的基因芯片数据矩阵。

表1 AML数据集的样本类型与基因数Tab.1 Sample type and gene number of AML dataset
2 差异表达分析
AML的原始数据集包含探针信息,故对该数据进行预处理,获取基因表达谱数据,并将其对数化处理。对处理后的数据进行差异表达分析,从而筛选表达显著的基因。差异基因是指一个基因在不同环境压力条件下呈现显著差异表达的基因。基因差异表达分析可以筛选出差异表达显著的基因,倍数法是最简单的差异分析方法。一般令FC=xs/xd,其中xs为实验条件的基因表达值,xd为对照条件的基因表达值,如果某基因的FC值小于0.5或大于2,则说明该基因差异表达显著。
计算AML基因芯片原始数据中每个基因的FC值及其差异显著性检验的P值,P值越小说明基因表达差异越显著。绘制火山图用以反映总体基因的差异表达情况。如图1所示,火山图的横坐标是log2(FC),纵坐标是-lgP,图中每点表示每个基因。平行于Y轴有两条虚线,分别为X=1与X=-1,X=-1左侧的点表示FC<0.5的基因,X=1右侧的点表示FC>2的基因。平行于X轴的虚线是Y=1.3(-lg0.05),Y=1.3上方的点表示p值小于0.05的基因,故将图中绿色与红色部分的基因标记为差异表达显著的基因。
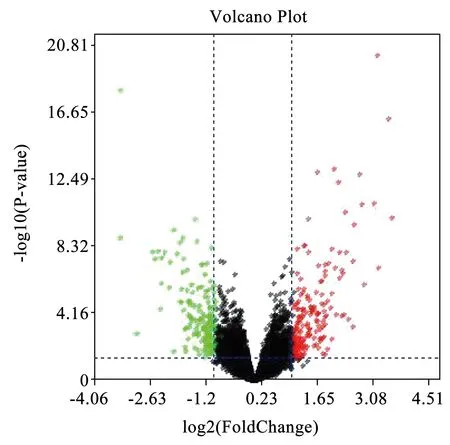
图1 火山图Fig.1 Volcano plot
AML基因芯片数据中包含较多差异表达显著的基因,筛选后对这部分基因进一步分析。为了严格筛选基因,设定FC值大于1.5或小于2/3,设定P<0.05、P<0.01、P<0.001 三组显著性检验水平,分别筛选基因数据集,三组数据集包含的基因个数如表2所示。

表2 三组数据集中的基因个数Tab.2 Number of genes in 3 datasets
3 主成分分析
对基因芯片数据进行降维处理,有一些基因承担相同的功能,可以用综合性指标来描述相似性。主成分分析是一种常用的降维方法,对筛选出来的三组基因数据集分别进行主成分分析,观测其结果。
探讨P<0.05数据集的主成分分析结果。根据表3,前3个主成分的累计方差贡献率为80.18%,达到80%的门槛,而越往后每个主成分的方差贡献率逐渐下降,无限接近0,增长率也逐渐平稳,故选取前3个主成分代表原有的78个样品点。

表3 P<0.05数据集的主成分方差贡献率Tab.3 Principal component variance contribution rate of P<0.05 dataset
3个主成分的表达式为:F1=0.12X1+0.12X2+0.11X3+0.11X4+…+0.11X78,F2=0.03X1+0.06X2-0.03X3-0.001X4+…+0.15X78,F3=0.15X1+0.15X2+0.12X3+0.25X4+…-0.08X78。
观察3个主成分的表达式可以发现,F1的系数在0.11左右波动,相对平稳,说明该主成分的基因表达水平波动较平稳,说明F1可视为基因表达水平的平均状态,故对F1不做具体研究。F2的系数变化较大,且时正时负,波动范围较广,说明F2中基因表达差异显著。计算第二主成分的得分并排序,选取前20名及后20名的基因,对筛选出的基因功能再做深入研究,从而达到降维目的。F3与F2一样,波动水平也不平稳,也可能表示某种基因表达模式。同样选取前20名及后20名的基因,研究这些基因功能对AML的影响。
表4为P<0.05数据集中F2得分前20名与后20名的基因,将这些基因视为影响AML的关键基因。

表4 P<0.05数据集的第二主成分关键基因Tab.4 Second principal component key gene of P<0.05 dataset
表5为P<0.05数据集中F3得分前20名与后20名的基因。观察表4、表5发现,HOXA9、VCAN等基因重复出现,说明这些基因差异表达更为显著,在AML中具有一定的作用。
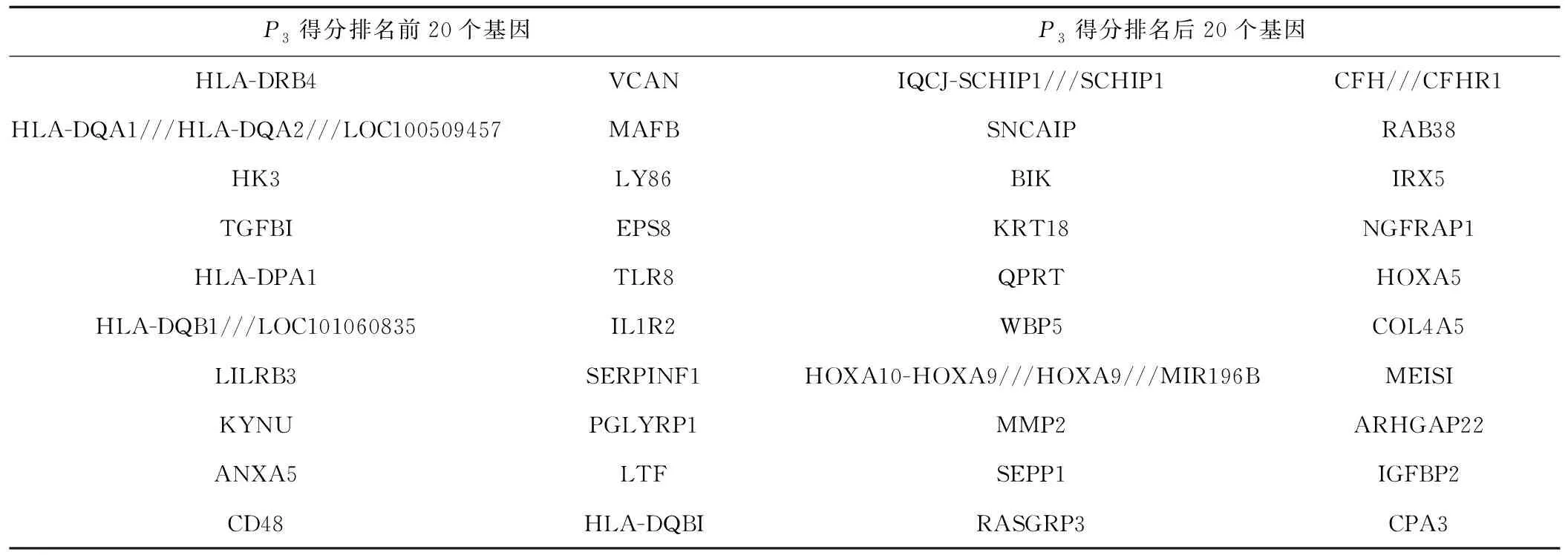
表5 P<0.05数据集的第三主成分关键基因Tab.5 Third principal component key gene of P<0.05 dataset
对P<0.01与P<0.001的数据集同样进行主成分分析,筛选关键基因,结果发现,HOXA9基因在这两个数据集中都差异表达显著。根据3组数据集的主成分得分排名结果发现,HOXA9基因高频出现,说明HOXA9差异表达十分显著,其在AML中起着至关重要的作用。相关研究证实,HOXA9基因在造血干细胞的扩增中发挥着关键作用,是调控胚胎干细胞向造血细胞转化的关键分子,该基因在急性髓细胞白血病中发生失调[6],故该基因功能异常可能会导致AML的发生。
4 结论
运用差异表达分析筛选差异表达显著的基因,将数据分成3组数据集,利用主成分分析提取第二、三主成分得分排名前20名及后20 名的基因作为关键基因。结果显示,HOXA9基因均高频出现,说明HOXA9基因差异表达显著,是影响AML的关键基因,在AML中发挥着重要的作用。基因芯片技术应用广泛,但基因芯片包含的数据量巨大,目前的主要任务是寻找研究基因大数据的方法。主成分分析可用于提取基因芯片数据中的关键基因,但也有不足之处。筛选基因时,基因数目的确定没有具体标准,可能会对后续研究造成影响,要么增加后续工作量,要么忽略某些关键基因。需进一步探讨更快速有效的基因芯片数据降维方法。
猜你喜欢
军事文摘(2024年2期)2024-01-10 01:59:00
车主之友(2022年4期)2022-08-27 00:57:12
今日农业(2021年4期)2021-06-09 06:59:56
海峡姐妹(2019年12期)2020-01-14 03:24:40
河南畜牧兽医(2017年12期)2017-11-13 04:05:18
现代检验医学杂志(2016年4期)2016-11-15 02:01:00
哈尔滨医药(2015年3期)2015-12-01 03:57:44
中国科技信息(2015年6期)2015-11-10 03:35:44
应用数学与计算数学学报(2014年2期)2014-09-26 05:40:23
计算物理(2014年1期)2014-03-11 17:00:18
