
基于YOLOv3 算法的肋骨骨折诊断模型的构建及应用
2023-10-15 08:44白洁孙晶程晓光刘凡刘华王旭
法医学杂志 2023年4期
白洁,孙晶,程晓光,刘凡,刘华,王旭
1.北京市公安局,北京 100192;2.首都医科大学附属北京积水潭医院,北京 100035;3.中国政法大学证据科学教育部重点实验室,北京 100088
肋骨骨折是法医临床鉴定中的常见损伤,在钝性胸部损伤患者中,40%~50%的人群存在肋骨骨折[1-2]。对于肋骨骨折损伤,现行法医临床学标准主要以骨折数量为判定依据,因此,骨折数量是鉴定的关键,对于定罪、量刑、赔偿等司法实践至关重要。典型的完全性肋骨骨折通过影像学检查较容易诊断,对于肋骨细微结构的骨性损伤,虽然有高分辨率CT,但在实际工作中,一些隐匿性肋骨骨折仍然容易被漏诊及误诊。同时肋骨影像学片的判读需要大量的时间并要求鉴定人具有丰富的阅片经验,技术门槛高,工作量大。如何快速、准确地对肋骨骨折影像学资料进行判定,是法医工作者面临的难题。
人工智能(artificial intelligence,AI)自1956 年在达特茅斯会议被提出后,其研究领域不断扩展深入[3]。机器学习是AI 领域的重要分支,其子领域深度学习近年来被广泛应用。深度学习中的神经网络模型最早尝试和应用的领域就是图像分类与目标识别,因其基于语义识别的特点,神经网络模型逐渐应用于影像学诊断[4],应用深度学习中的神经网络模型进行肋骨骨折诊断的研究也不断开展[5-6]。目标检测是计算机视觉和数字图像处理的热门方向,是一种基于目标几何和统计特征的图像分割,其可将目标的分割和识别合二为一,能够快速识别目标。
本研究旨在介绍一种基于热门目标检测YOLOv3算法[7]建立的对胸部CT 图像进行肋骨骨折标定与诊断的方法,以期辅助法医学鉴定人缩短阅片时间,提高诊断准确性及工作效率。
1 材料与方法
1.1 材料
采集北京积水潭医院2020 年1 月—7 月门急诊外伤患者的肋骨骨折胸部CT 扫描DICOM 格式图像。经过筛选后选择884 例数据用于建模,其中801 例(男性438 例、女性363 例,年龄27~81 岁)共计29 388 张骨折图像作为训练集和验证集,83 例(男性47 例,女性36 例,年龄25~78 岁)共计7 752 张图像作为测试集。
纳入标准:(1)胸部外伤患者;(2)原始影像学资料涵盖两侧所有肋骨;(3)18 岁以上成年人。
排除标准:(1)患有影响骨骼系统的疾病,如肿瘤、骨代谢性疾病等;(2)因依从性差等原因导致的影像学图像不清晰者。
本研究为回顾性研究,已经获得北京积水潭医院伦理委员会的批准(审批文号:积伦科审字第201903-24 号)。
1.2 评判标准
由2 名具有高级职称的影像学专家(从事肌骨影像诊断工作20 年以上)对801 例患者的胸部CT 图像进行诊断,意见不一致时,由第3 位更高年资专家进行确认。通过多平面重组、三维重建及复查CT观察是否有骨质断裂、骨痂等判定有无骨折,协商后共同在CT 图像上进行骨折标注,作为模型训练和验证的“金标准”数据集,同时记录骨折具体位置、数目及所在层面。将专家发现的轻微骨折、移位骨折、骨折修复性改变等作为阳性结果,专家未发现骨折为阴性结果。
1.3 建模方法
1.3.1 数据预处理
影像学专家诊断骨折后,根据患者编号以及左、右侧肋骨骨折所在层数等信息制作肋骨骨折断层位置描述表格文件。患者肋骨断层扫描得到的原始CT图像的命名规则为Iabcdefg,其中a~g 均是数字。根据CT 图像的命名规律构建CT 图像名与上述肋骨骨折断层位置描述表格文件中序数之间的映射关系,由此可以得到患者有肋骨骨折图片的文件名,从而将骨折图片从患者所有DICOM 格式文件中提取出来。
用基于python编程语言的pydicom工具包将DICOM格式图像数据读取到内存之后,像素值的变化范围为-2 048~2 048,通过设置窗宽与窗位参数的方法将像素值进行变换(窗宽值1 500、窗位值350),将CT 图像的骨质部分提取出来。
用OpenCV 工具包将DICOM 格式文件转化成JPG格式,由影像学专家采用与CT 图像背景颜色差异较大的黄色矩形框进行骨折目标的标记。
对上述JPG 格式文件分别进行处理,得到TXT 格式骨折位置标注文件及归一化的JPG 图像。
1.3.1.1 TXT 格式骨折位置标注文件
采用图像识别中的模板识别原理,运用图像识别工具包识别骨折标注矩形框,设置图像中黄色部分像素值的提取条件,得到二值化图像,黄色矩形框经过二值化处理后得到白色矩形框,其内部为骨折所在区域。
采用OpenCV 的cv2.findContours 函数对二值化图像骨折位置标注的白色矩形框轮廓进行提取。采用基于python编程语言的图像处理算法对矩形框的顶点坐标进行识别,得到骨折标记矩形框左上点和右下点的坐标。如图像中有多个骨折的位置,会得到多个矩形框,提取不同矩形框的左上点和右下点坐标,分别记为(xmin,ymin)和(xmax,ymax),其中xmin表示标记框上所有点的横坐标的最小值、xmax表示标记框上所有点的横坐标的最大值、ymin表示标记框上所有点的纵坐标的最小值、ymax表示标记框上所有点的纵坐标的最大值。将上述坐标信息生成TXT 格式骨折位置标注文件。
1.3.1.2 归一化JPG 图像
使用基于python 编程语言的PyTorch 模块中的函数将图像数据尺寸归一化成512×512×3 大小,以提高模型构建的计算效率。
1.3.2 基于YOLOv3 算法的模型训练
YOLOv3算法的训练阶段包括:构建基于YOLOv3算法的目标算法框架,将JPG格式的肋骨骨折图像数据与标注文件数据导入算法框架中进行模型训练计算。
1.3.2.1 构建目标算法框架
YOLOv3 算法框架主要由卷积模块、残差模块、上采样模块与Darknet53 骨干特征提取网络构成。
卷积模块是由计算机随机生成若干卷积核,不同的卷积核用于提取图像中不同的特征。卷积核中的权重参数是模型训练过程中需要优化的参数。
残差模块最显著的特点是使用了快捷路径机制来缓解神经网络算法训练过程中的梯度消失问题,从而使得神经网络变得更容易优化。其通过恒等映射的方法使输入和输出之间建立起一条直接的关联通道,从而使得网络集中学习残差模块输入和输出之间的差值。
上采样模块的作用是在后续YOLOv3 网络中进行相加操作时保证两个特征图的宽和高相同。
YOLOv3 使用了具有53 个卷积层的骨干网络Darknet53。YOLOv3设定每个网格单元都有3个检测框负责检测,而且每个检测框需要有x、y、w、h、confidence 5 个基本参数(其中x为检测框的中心横坐标、y为检测框的中心纵坐标、w为检测框的宽度、h为检测框的高度、confidence 为检测框内有检测物体的概率),同时还要有80 个类别的概率,因此每个输出的通道数都是3×(80+5)。将一张416×416 的彩色图片输入Darknet53 网络后得到3 个分支,这些分支在经过一系列的卷积、上采样以及合并等操作后最终得到3 个特征映射,尺寸分别为[13,13,255]、[26,26,255]和[52,52,255]。
1.3.2.2 导入数据
将TXT 格式骨折位置标注文件以及从DICOM 格式数据转化成的JPG 格式的图像数据导入YOLOv3算法框架,将模型得到的检测框信息转化为原图上的坐标信息,通过交并比阈值检测及非极大值抑制处理,清除冗余的预测框。
经过第1 次模型构建后,得到肋骨骨折识别图像,识别出的骨折位置以蓝色矩形框标记,同时在矩形框上方标注此处骨折的识别概率,如图1 所示。
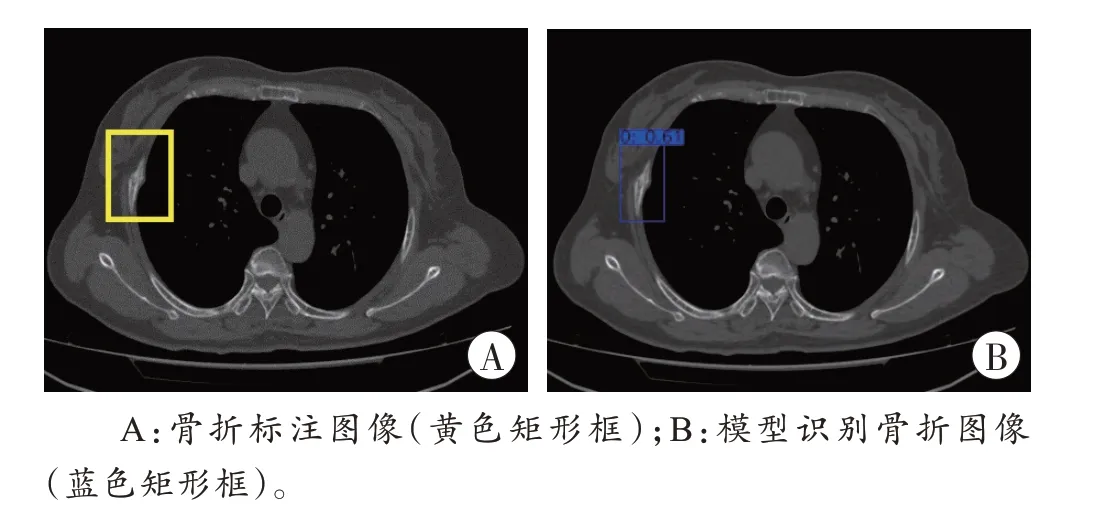
图1 第1 次建模得到的肋骨骨折标注及识别图像Fig.1 Rib fracture labeling and recognition images obtained by the first modeling
第1 次建模后,识别的准确率不理想,为优化模型,进行了第2 次建模(图2)。通过不断调整模型的参数,最小化损失函数,提高了模型的预测能力。
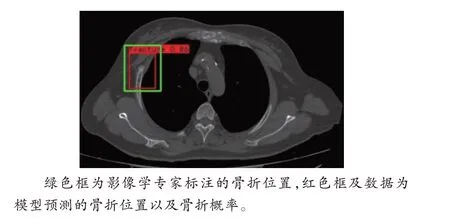
图2 第2 次建模得到的肋骨骨折识别图像Fig.2 Rib fracture recognition images obtained by the second modeling
1.3.3 模型测试
为测试模型的准确性和泛化性,将测试集数据输入模型进行判别,根据模型的精确率(precision rate,PR)、召回率(recall rate,RR)、F1 分数评价模型的训练效果。其中,精确率是指所有被预测为阳性(即骨折)的样本中实际为阳性的样本比例;召回率是指所有实际为阳性的样本中被预测为阳性的样本比例;F1 分数是精确率和召回率的调和平均值。公式如下:
式中,TP为真阳性,即模型预测为骨折而实际也为骨折的样本数量;FP为假阳性,即模型预测为骨折而实际非骨折的样本数量;FN为假阴性,即模型预测为非骨折而实际为骨折的样本数量。
使用配置为NVIDIA GeForce GTX 1080Ti 显卡、英特尔®至强®处理器E5-2630 v3(2.40 GHz)的服务器对测试集DICOM 格式数据进行识别,同时记录模型阅片时间。
1.4 案例应用
王某,女,50 岁,被人致伤胸部。受伤当日就诊病历记载:胸部可及压痛,左侧胸廓挤压痛。胸部CT显示:左侧第4 前肋骨皮质局部走行扭曲,欠规整。诊断证明书记载:左侧第4 前肋疑似骨折。经阅片,王某胸部CT 显示左侧第4 前肋骨皮质欠规整,仅依靠人工判读影像学资料明确诊断有一定难度。法医建议王某于伤后3 个月复查胸部CT,并由办案单位调取王某胸部CT 的DICOM 格式数据,采用AI 肋骨骨折诊断模型进行辅助诊断。
2 结果
2.1 模型训练情况
模型训练过程的损失函数曲线见图3。随着迭代次数的增加,损失函数逐渐降低,识别准确率逐渐升高。当迭代次数在10 以内时,损失函数下降较快,模型快速收敛;当迭代次数在10~50 时,损失函数下降缓慢,趋于常值;当迭代次数大于50 时,损失函数稳定。最终选择100 作为模型的最大迭代次数,模型达到最优状态。
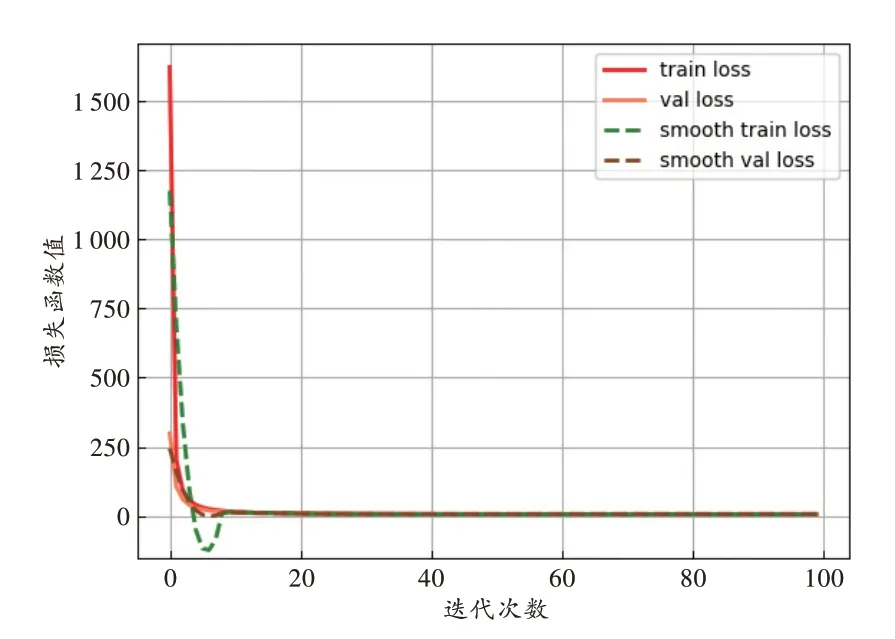
图3 第2 次建模的损失函数曲线Fig.3 The loss function curve of the second modeling
2.2 模型测试情况
该模型存在将滋养孔、神经血管沟、肋骨局部不完全性钙化及因扫描容积效应造成的局部高密度影误诊为骨折的现象(即假阳性,图4),对修复期骨折、无明显移位的肋骨骨折及骨皮质损伤较轻的不完全性骨折存在漏诊现象(即假阴性,图5)。
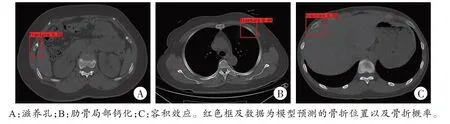
图4 假阳性结果Fig.4 Results of the false positive
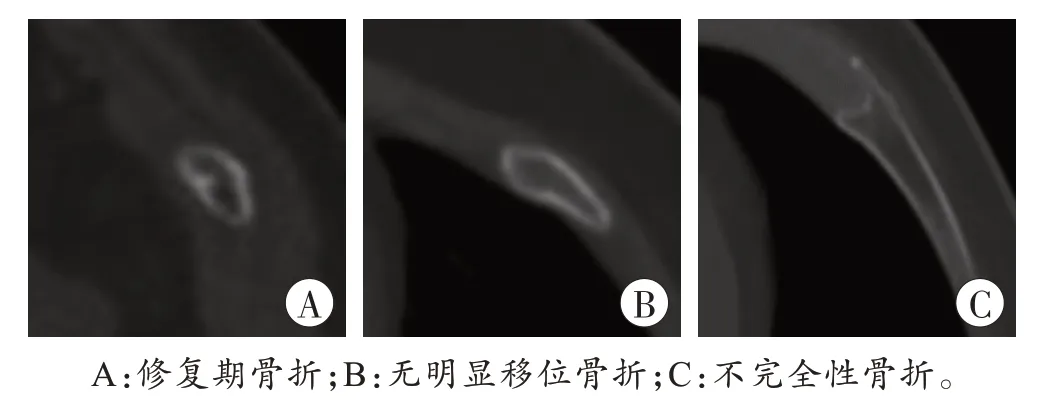
图5 假阴性结果Fig.5 Results of the false negative
在83 例测试集的胸部CT 图像中,准确判定骨折(即真阳性)845 张,假阳性89 张,真阴性6 542 张,假阴性276 张。经计算,本模型的精确率为90.5%,召回率为75.4%,F1 分数为0.82。
2.3 阅片时间
测试集的83 例患者共计7 752 张图像,模型完成全部图像的识别耗时1 761 s,每秒可识别4.4 张图像,对每位患者的数据识别花费时间平均为21 s。
2.4 案例应用
将王某受伤当日和伤后3 个月的胸部CT 数据导入模型,模型识别左侧第4 肋骨的骨折概率分别为73%和59%。前后两次CT 片的模型识别结果见图6。影像学专家阅伤后3 个月复查片:左侧第4 肋骨局部硬化,骨痂形成,为陈旧性骨折。最终法医根据阅片及AI 识别结果认定被鉴定人左侧第4 肋骨骨折。
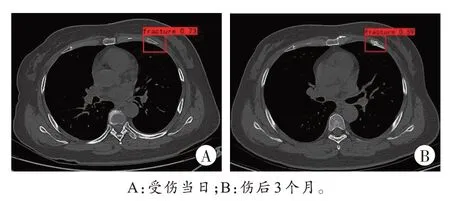
图6 实际肋骨骨折案例的模型识别结果Fig.6 Model recognition results of the practical rib fracture case
该案例运用本研究构建的模型对可疑肋骨骨折进行识别和诊断,两次影像学资料均识别为骨折,对此结果双方当事人未有异议。
3 讨论
3.1 YOLO 概述
YOLO(You Only Look Once)系列算法于2015 年由REDMON 等[8]首次提出,是当前目标检测领域较为热门的算法之一,是目标检测算法的经典代表,其核心思想是直接对Bbox 进行回归,然后进行类别的预测,将目标边界定位问题转换成回归问题,不需要分别训练各个部分的网络,可以实现端对端的训练,只需要一次完整的过程即可完成目标识别及定位,是典型的一阶段(one-stage)算法。相比两阶段(two-stage)算法,如区域卷积神经网络(region-convolutional neural network,R-CNN)、Fast R-CNN、Faster R-CNN 等,YOLO的检测速度大大提升,是R-CNN的1 000倍、Fast R-CNN 的100倍[9]。为克服YOLOv1框坐标定位不准、召回率较低、对小目标或比较密集的目标检测效果欠佳等缺点,YOLOv2[10]及YOLOv3 版本[7]对此进行了改进。YOLOv3 采用Darknet53 网络进行图像的特征提取,较之前的v2 版本(使用Darknet19)准确率更高[7]。研究[11]认为YOLOv3 算法结构简单,鲁棒性好,检测速度快,精度较高。YAO 等[12]对YOLOv3 算法和Fast RCNN、Faster R-CNN 的性能进行了评估,认为YOLOv3算法的精确率、召回率、F1 分数、阴性预测值均高于其他两种算法。
3.2 模型应用
本研究基于YOLOv3 算法构建了AI 辅助肋骨骨折诊断模型,该模型实现了网络端到端的完全自动化的肋骨骨折影像学诊断,并提供骨折识别概率,避免了因经验不足等原因引起的人工判读造成的漏诊、误诊;该模型可识别CT 影像通用DICOM 格式文件,普适性高;所使用的训练集涵盖多种类型骨折,具有一定的差异度,模型精确率较高;该模型操作简单、便捷,识别速度快,辅助法医进行肋骨骨折诊断不仅可以提高鉴定效率,同时计算机判读结果不受人为因素影响,作为客观证据更具有信服力,容易被当事双方接受。通过实际案例的应用及测试,该模型识别结果与影像学专家判定结果一致,可靠性高,重复性好,有助于解决法医临床鉴定实践中隐匿性骨折诊断困难等问题,可辅助鉴定人进行肋骨骨折诊断,具有良好的应用前景。
有研究[13]显示,肋骨骨折人工判读的召回率为63.5%,本研究模型的召回率为75.4%,高于人工判读。召回率越高,说明模型识别骨折的假阴性率越低。对于输入骨折图片但模型输出结果为阴性的漏诊现象,分析认为主要有以下原因:(1)相同部位连续的骨折图片存放在同一文件夹内,仅标注少数图片,默认其他图片相应位置也为骨折,这个标注方法对大部分图片适用,但是部分图片在标记框对应位置并没有骨折特征,因此造成模型识别性能降低;(2)受算法的限制,特征不能百分之百被识别并训练,加之部分特征区分度低,较难训练,影响了模型的识别效率;(3)训练样本中涵盖不同类型的骨折,但部分类型骨折数据量较少,有效训练不足,使得模型识别效率降低;(4)部分骨折轻微,无移位,仅表现为骨皮质的改变,特征不明显,不易被训练。
本研究模型在测试集上的精确率为90.5%,有学者研究医疗公司的uAI EasyTriage-Rib 软件及uAIBoneCare软件得到的精确率分别为91%[14]及89.3%[15],周清清等[16]构建Faster R-CNN 模型诊断不同类型的肋骨骨折,精确率最高为90.2%,本研究所建立模型的精确率与其基本相同。精确率越高,模型识别骨折的假阳性率越低,考虑本研究模型存在假阳性结果的主要原因是:(1)部分类型骨折数量较少,在学习过程中特征学习不足,导致模型在训练过程中对无骨折的图像与本类骨折图像有所混淆,对无骨折部位进行了识别,造成假阳性;(2)模型会对放入相同文件夹的多个连续层面的阳性图片进行学习,在标注过程中仅标注少量图片,其他层面在标注的相同位置上可能为非骨折结构,模型默认相同位置的特征为骨折,因此出现识别错误;(3)由于CT 的容积效应或者钙化等原因,正常骨组织结构内出现了局部高密度影,与骨折的修复性改变相似,从而被模型判定为骨折;(4)在模型的实际应用过程中,会将被鉴定人胸部CT 的全部DICOM 格式数据输入模型,其中部分矢状位层面肋骨呈现出与横断面肋骨相似的走行及形态特征,因而被识别为骨折。
在阅片时间上,本研究模型每秒可识别4.4 张图像,对每位患者的数据识别仅平均花费21 s 即可给出诊断及骨折概率,而临床上结合容积再现、多平面重组等后处理技术诊断用时分别平均为7.6 min 及8.2 min[17],模型比人工识别用时更短。尤其对于隐匿性骨折,因骨折比较轻微,人工识别往往需要花费更多时间,对于此类骨折的判读,模型的优势更加凸显。更换先进的硬件设备及优化算法,阅片速度还有进一步提升的空间。
本研究亦有一定的局限性:(1)骨折判定标准基于高年资影像学专家的诊断,而非病理结果,也存在误诊或漏诊的可能,因此可能对模型的整体效能产生影响;(2)该模型目前仅能识别骨折,尚无法完成骨折的分类任务;(3)本研究排除了因依从性差导致的图像不清晰病例,但实际工作中,此类病例并不少见;(4)本研究的主要样本为CT 横断面图片,未结合多平面重组、曲面重组、容积再现等重组图像,不利于肋骨骨折的检出。在今后的研究中,应通过加大样本量、细化骨折分类、改进标注方法、优化算法等手段,不断提高模型的整体效能,为司法鉴定提供有力的技术支撑。
3.3 展望
目前国内外学者利用AI 技术对肋骨骨折进行诊断的研究不断开展,AI 与医师联合阅片检出肋骨骨折的敏感度优于单独医师阅片[13]。同时在AI 的辅助下,医生的诊断效率显著提高,诊断时间缩短,召回率提高,减少了误诊[12]。笔者认为,在以下几个方面还有进一步深入研究的可能:
(1)骨折分类方面。法医学鉴定实际工作需要区分骨折与非骨折、是否为完全性骨折、新鲜与陈旧骨折、是否有二次骨折、不同时期的骨折等,后续研究可继续细化分类,提高骨折分类的诊断能力。
(2)骨折定位方面。应用AI 辅助诊断肋骨骨折,在准确定位方面还存在问题:一是目前研究多采用横断面CT 图像进行模型构建,一名患者完整的胸部CT图片有几百张,每张图片会显现2~16 根肋骨,除了个别不完全性骨折,常见的骨折都会连续出现在几张图片中,需要采取一定的措施避免出现在多张图片上的一处骨折被识别为多处骨折;二是如何对一张图片中显示的肋骨进行解剖学准确定位,明确骨折具体位置。为解决第一个问题,有学者[16]设计了结果合并程序,将1~2 mm 薄层CT 图像的多个预测框合并成一个骨折病灶,并输出包含肋骨骨折的相应层数的结构化报告,使用骰子函数来判断不同层面或同一层面不同部分的检测结果是否属于同一骨折。徐传冰等[18]使用了AI 全自动肋骨骨折检测系统,可自动切换骨窗并对图像上的肋骨进行计数。解剖学定位方面,目前关于椎体的研究[19-20]较多,而对于CT 横断面图像上的肋骨进行解剖学定位的问题,还需要大量算法的研究。解决定位问题,可以准确、快速地判定骨折部位,帮助法医预判可能存在的其他损伤,同时可以一定程度上减少本模型存在的假阳性问题。
(3)诊断的准确性方面。隐匿性骨折在初次检查中常不易被发现,是法医学鉴定中的难点问题。如有大量后期复查影像学资料,可将前后CT 图像输入模型进行比对以提高初次影像学检查的诊断准确率,为法医学诊断提供依据,帮助鉴定人对血管或神经沟等易与隐匿性骨折混淆的表现进行鉴别诊断。为消除AI 辅助诊断过程中的假阳性,对于肋骨不完全性钙化、呼吸运动产生的伪影、滋养孔、神经血管沟等可能误判为骨折影的影像学表现,可搜集数据,增加训练的样本量,进一步提高模型的准确性。利用本方法已能对部分隐匿性骨折进行预判,希望后期能够进一步提高识别概率。
(4)算法方面。从深度学习的角度看,肋骨骨折诊断被定义为一个目标检测问题,不同的学者采用不同的深度学习算法。在YOLOv3 之后,Ultralytics 公司相继推出v4、v5 等版本,目前已推出v8 版本。相比单一的模型和算法,罗鑫等[21]提出了基于多重注意力机制的深度学习模型,利用图像技术对肋骨进行定位,缩小目标识别区域,并提出残差通道双注意力模块(residual channel bi-attention module,RCBM),同时使用通道注意力模块(channel attention module,CAM)与RCBM,相较于只使用CAM 模块,准确率和F1 分数均大幅提升。由此可见,随着科技的进步,可进一步优化算法或使用更为先进、适宜的模型及方法,以提高模型的精确度和泛化性。
(5)应用范围方面。目前应用AI 辅助诊断肋骨骨折的模型多采用CT 横断面图像数据进行构建,后期可结合多种重组方法,如横断面图像结合多平面重组、容积再现、曲面重组等后处理数据进行模型训练;也可利用其他影像学方法如MRI 来提高诊断的准确性。对于胸部CT 影像学资料,除了肋骨骨折,也期待利用AI 方法识别更多对法医学鉴定有意义的邻近组织损伤,如气胸、纵隔损伤、锁骨骨折、椎体骨折、肩胛骨骨折等。如能对上述损伤进行准确判定,对CT 片上可能呈现的损伤进行全面、系统的诊断,将会大大提高法医的工作效率,也有望进一步拓宽AI 辅助CT诊断技术在法医临床学中的应用前景。
猜你喜欢
中国临床医学影像杂志(2022年5期)2022-07-26
保健医苑(2022年6期)2022-07-08
世界最新医学信息文摘(2021年12期)2021-06-09
世界最新医学信息文摘(2021年12期)2021-06-09
中国临床医学影像杂志(2019年1期)2019-04-25
中华骨与关节外科杂志(2016年3期)2016-05-17
Coco薇(2015年5期)2016-03-29
中外医疗(2015年11期)2016-01-04
河南畜牧兽医(2015年13期)2015-11-28
中国当代医药(2015年36期)2015-03-11
