
面向光场显示的虚拟视点生成技术进展
2023-10-13 01:56赵健戴子尧丁义权夏军
液晶与显示 2023年10期
赵健, 戴子尧, 丁义权, 夏军
(1.南京工程学院 计算机工程学院, 江苏 南京 211167;2.东南大学 信息显示与可视化国际联合实验室, 电子科学与工程学院, 江苏 南京 210096)
1 引言
近年来,随着新型显示技术的发展,三维显示技术开始走进普通大众的视野,已经广泛应用于医疗、军事、教育、广告、游戏等领域[1-4]。例如,在医疗立体显示领域,医疗专业人员可以依靠三维显示器轻松完成内科手术[5];在汽车导航领域[6],自由立体显示系统可以为驾驶员提供基于现实场景的沉浸式导航体验;在中小学教育方面[7],学生可以直观地体验3D模型的外观和结构。这些应用涉及到的三维显示技术包括近眼显示[8]、全息显示[9]、超显微成像[10]、自由立体显示[11]等。
人之所以能感知三维空间,是因为双目的辐辏与调节机制使得人眼采集到的空间信息具有一定的水平视差。大脑通过生理立体视觉和心理立体视觉共同决策,进而获取立体视觉感知。因此,现有的三维显示技术普遍利用双目视差原理进行三维重建。然而,长时间观看会出现眼干、眼涩、眩晕等问题。这种问题产生的根本原因在于人眼的辐辏调节机制被阻断。传统的近眼显示技术或者裸眼立体显示技术,由于其重建的虚拟场景一般处于一个固定深度,且该深度往往会区别于物理显示器所在位置,会引起人眼的辐辏深度和调节深度不一致的问题,进而产生冲突。研究表明,基于多视点的光场显示技术,通过向单目投射多角度信息,可以有效缓解辐辏调节冲突,提升视觉舒适度。
基于多视点的光场显示技术通过特质光学器件精确控制每个像素的光线传播方向,双目可以在特定位置接收预先设计好的视点信息。根据视点数量的多少,光场显示技术可以分为双视点显示技术、多视点显示技术和超多视点显示技术。同时,为了满足多视点光场显示技术的发展,虚拟视点生成技术也是必不可少的。
从人眼立体视觉原理出发,本文对多种三维显示技术典型案例进行分类总结,并对重要性能参数进行对比分析,如视场角和视点数量。现有三维显示技术朝着更多视点、更快渲染速度方向发展,因此,本文对虚拟视点生成算法进行整理归类,并对虚拟视点图像的生成质量和渲染速度进行比较。
2 光场显示原理及显示设备分类
2.1 双视点显示技术
自然状态时,双眼利用双目视差原理可以将空间一点在视网膜上清晰成像,并产生深度立体感知[12]。目前,双视点显示技术均是利用特殊光学器件向双眼投射具有一定视差的双视点内容,典型方案包括抬头显示技术(HUD)[6]、3D眼镜显示技术[13]和基于眼跟踪的裸眼3D显示技术,如图1所示。
由Sony推出的27 in(1 in=2.54 cm)4K裸眼3D显示器[7]如图2所示。屏幕集成眼球跟踪功能,可以快速跟踪用户眼球移动,在各个角度都能带来舒适自然的3D立体画面,已广泛应用于教育[14]、设计、医疗[15]等领域。

图2 基于人眼跟踪的裸眼3D显示器Fig.2 Naked-eye 3D display based on eye tracking
2.2 多视点显示技术
正常情况下,人眼的辐辏汇聚深度和调节深度是一致的,如图3(a)所示。当人眼聚焦在非明视距离内的近眼显示器而辐辏距离仍为真实世界的某点时,就会产生辐辏调节深度不一致的问题,即辐辏调节冲突(VAC)[16]。这个问题是造成视疲劳的主要因素之一,如图3(b)所示。同理,在裸眼3D显示中,也会存在这个问题,如图3(c)所示。

图3 人眼辐辏调节原理图。(a)正常状态;(b)近眼显示;(c)裸眼3D显示。Fig.3 Schematic diagram of vergence-accommodation.(a) Natural state;(b) Near-eye display;(c) Naked eye 3D display.
在保证足够高空间分辨率的基础上,尽可能地提高角度分辨率,被认为是解决或缓解VAC的有效途径之一[17]。以近眼显示为例,放置在非明视范围的近眼显示器通过特殊光学器件向视网膜投影,进而在大脑中被动产生一个位于正前方的虚拟像,如图4所示。空间分辨率取决于虚拟显示器能够提供的最小虚拟像素尺寸,而角度分辨率取决于相邻抽样光线的最小角间距。如果空间某深度虚拟点可以形成单目聚焦,那么定向射线束的角间距需要在约0.2°~0.4°[18]以允许每只眼睛有两个以上的视图样本,才能诱发单目调节反应。另外,出瞳范围、视场角、眼盒大小也是评价近眼显示性能的核心指标。
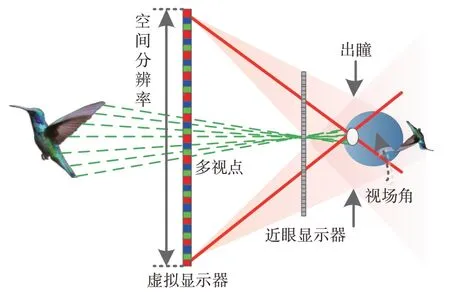
图4 近眼光场显示系统原理图Fig.4 Schematic diagram of near-eye light field display system
北京理工大学王涌天团队提出的基于光场和麦克斯韦的近眼显示方案[19]可以提供接近准确的深度线索。该方案对背景区域(31.5°)和视网膜凹窝区域(10.1°)分别进行独立渲染,在实现大视场角的同时,对凹窝区域进行高角度分辨率光场成像,如图5所示。

图5 基于麦克斯韦和光场显示的近眼显示[19]Fig.5 Near-eye display combining Maxwellian-view and light-field methods[19]
Byoungho Lee[20]团队提出基于双层液晶的近眼光场显示模型[21],将三维场景的光场分解成两层,通过改变双层液晶的透过率来实现光线精确调控,如图6所示。该方案可以成功诱发单目调节效应,且空间分辨率更高。但是,该方案面临着景深受限和通道串扰严重的问题。斯坦福大学的Gordon Wetzstein[22]团队提出的基于叠加图方法的全息近眼显示方案可以对密集视点图像进行压缩计算,解决了传统全息显示在空间和角度分辨率之间需艰难权衡的问题,如图7所示。多视点视网膜投影法[23]和可变焦透镜法[24]可以将多视点信息按照视点阵列的方式在视网膜上聚焦成像。但是,上述方案都面临着重建光场景深范围受限的难题。针对这个问题,东南大学夏军团队提出基于集成成像原理的复合光场景深拓展方案[25-26],相比于传统的单光场重建,有效拓展复合光场景深范围150%以上,光路图见图8。
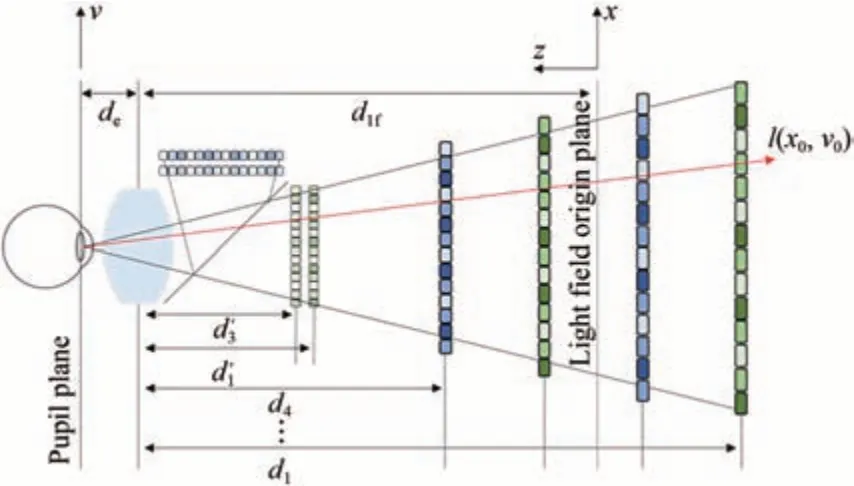
图6 基于多层液晶的近眼显示Fig.6 Near-eye display based on multilayer liquid crystal

图7 基于图像叠加的全息近眼显示Fig.7 Holographic near-eye displays based on overlap-add stereograms

图8 基于复合光的近眼显示Fig.8 Near-eye display based on composite light field
多视点技术不仅应用在近眼显示领域,在裸眼3D领域也有广泛应用。集成成像技术可以提供高角度分辨率的多视点显示技术,具有景深连续、视觉舒适度高等特点。但是分辨率损失严重是这项技术的主要挑战之一。近些年,集成成像与散射膜结合的研究取得了很大进展。如图9所示,基于光学低通衍射膜的集成成像技术[27]可以极大地减少重建三维场景的颗粒感,视点数量达到31×31时,理论分辨率提升2.12倍。

图9 基于投射镜的集成成像技术。(a)系统结构图;(b)子图排布。Fig.9 Integral imaging 3D display by using a transmissive mirror device. (a) System structure diagram; (b)Elemental image array.
2.3 超多视点光场显示技术
由于视点数量有限,多视点方案仅能通过提供近似准确的深度线索来缓解辐辏调节冲突,但不能完全消除。基于超多视点的方案,不仅可以在超大视场角内提供连续的视差成像,并且有望彻底解决视疲劳的问题。
北京邮电大学的桑新柱团队[28]发明的基于新型柱透镜阵列的光场显示器由柱透镜阵列、微透镜阵列和全息功能屏组成。该显示器具有水平70°、垂直30°的可视角,并且具有高达11 000个视点,是目前为止视点数量最多的裸眼3D显示器,如图10所示。2022年,Joonku Hahn团队[9]基于不对称扩散全息光学元件的体三维显示系统,通过时序的方法投射512个视点,最终实现了360°范围内连续视差成像,如图11所示。但是该方案需要强大的投影系统,成本高昂和体积庞大是它面临的最大问题。北京航空航天大学的王琼华团队提出的基于集成成像的桌面3D显示系统通过观看区叠加的形式,实现了在360°环形观看区内连续视差分布,如图12所示。

图10 基于新型柱透镜阵列的光场显示器Fig.10 Light field display based on a new lenticular lens array
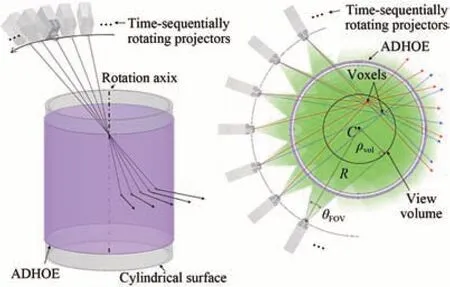
图11 体三维显示技术Fig.11 Volumetric display

图12 桌面集成成像显示技术Fig.12 Tabletop integral imaging 3D display
表1列出了双视点显示、多视点显示和超多视点显示中几种典型显示方案,并对视场角和视点数做了对比。从表1可知,视场角更大、视点数量更多是目前新型立体显示的主流发展方向。
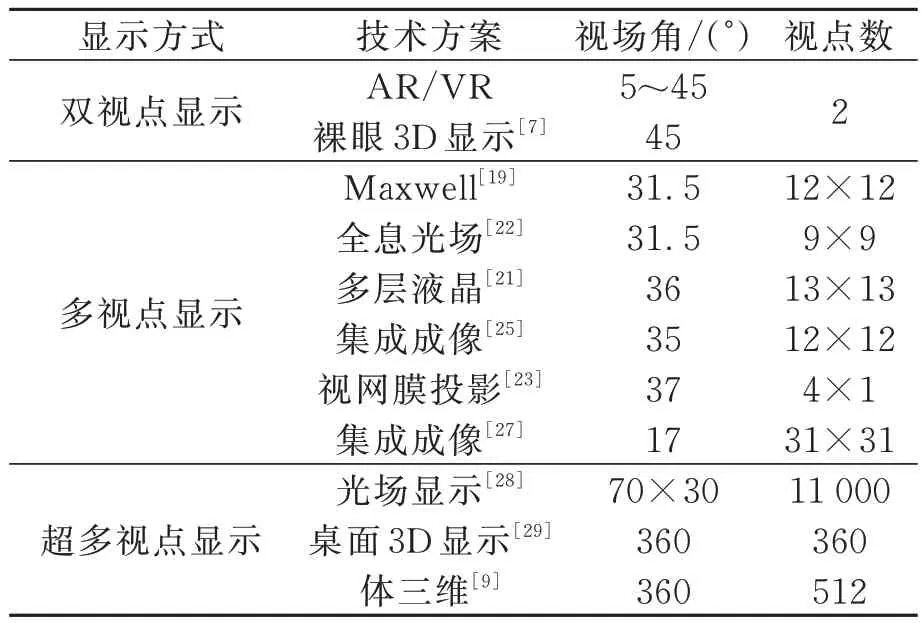
表1 典型的光场显示器参数比较Tab.1 Parameter comparison of typical light-field displays
3 虚拟视点生成方法
虚拟视点生成方法有多种,包括单信源虚拟视点生成和多信源虚拟视点生成。其中,单信源虚拟视点生成是基于2D图像或者2D视频完成3D虚拟视点生成;而多信源虚拟视点生成法是指基于多视点信息、深度信息或者点云等多辅助信息,实现任意视角虚拟视点生成。
3.1 单信源虚拟视点生成
3.1.1 卷积神经网络虚拟视点生成法
2016年,Jure Zbontar[30]团队首次将卷积神经网络(CNN)引入到立体显示虚拟视点生成中并取得成功。CNN通过卷积层进行特征提取,反卷积层进行重构,将代表不同视角下的空间特征重建为新的图像,生成目标场景的新视角图。本部分仅讨论基于单信源的CNN虚拟视点生成算法。
Richard Tucker团队[31]提出一种基于尺度不变的虚拟视点合成神经网络,实现了从单一2D图片预测并渲染密集虚拟视点。该神经网络可以对在线视频数据进行训练,实现前景边缘缺失信息有效填充,提升合成图像质量,如图13所示。虚拟视点的峰值信噪比(PSNR)最高为19.3 dB,结构相似性(SSIM)最高为0.696。Evain[32]提出的基于单张图片的虚拟视角合成方法,采用了MobileNet编码器,可以在少量参数下获得较好的视差预测结果。在出现伪影的区域、被遮挡的区域和误判的区域中,使用Refiner进行进一步的优化。该方法能够估计自身视差预测的置信度,并能够识别其不能正确预测的结构。该方法在KITTI数据集中优于现有技术(Deep3D),并且适用于不同分辨率的图像。合成虚拟视点的PSNR和SSIM最高可达19.24 dB和0.74。
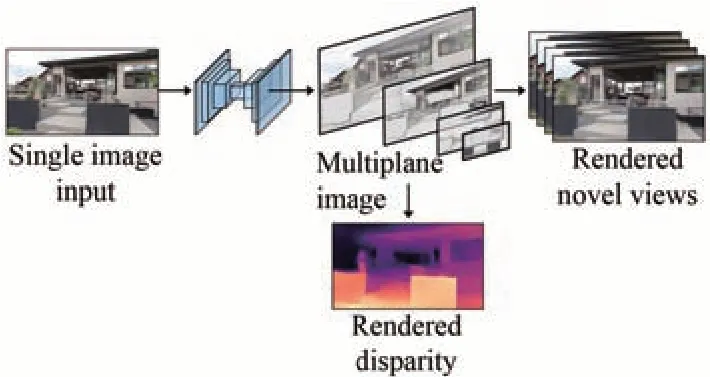
图13 基于单视点的虚拟视点合成技术Fig.13 Virtual viewpoint synthesis technology based on single viewpoint
为了进一步提升虚拟视点图像质量,来自牛津大学的Olivia Wiles 提出SynSin模型[33]。这是一种端到端的神经网络模型,与现有方法不同的是,该模型在测试时无需任何基准3D信息。该模型利用可微分的点云渲染器将潜在的3D点云特征转换为目标视角,并通过修饰网络解码出所需的3D细节,从而为缺失的区域进行精确填充,生成虚拟视点。此外,还可以生成高分辨率虚拟视点,对输入图像的分辨率要求很低。该模型在Matterport、Replica和RealEstate10K数据集上均优于基准方法,PSNR和SSIM最高可达22.21 dB和0.74。
3.1.2 神经辐射场虚拟视点生成法
神经辐射场(Neural Radiance Fields,NeRF)[34-35]根据相机光线采样提取出静态场景图片的5D函数,即空间位置(x,y,z)和视角方向(θ,ϕ),将其转化为对应的辐射亮度和密度,通过图像投影渲染技术,实现虚拟视点合成,原理图如图14所示。因其具有高质量的3D场景渲染能力,已成为研究热点。目前,该领域研究主要集中在提升虚拟视点图像质量和渲染速度两个方面。
在提升图像质量方面,基于预训练的MVSNeRF[36]方法通过将预先提取输入视图的图像特征映射到3D体绘制中,可以大幅提升图像质量。NeRF in the wild(NeRF-W)[34]基于稀疏视图集合,将图像序列中的NeRF参数进行共享分析,进而提升虚拟视点质量。但这些方法都严重依赖大量外部数据,不适用于单信源虚拟视点生成的场景。另外,传统的NeRF是像素级光线渲染,因此,对不同分辨率的图像进行训练或者测试时,就会出现过度模糊或者混叠现象。Mip-NeRF[37-38]模型通过抗锯齿锥形截锥体(Anti-aliased conical frustums)渲染,成功减少了虚拟视点的锯齿伪影,并显著提高了NeRF表示精细细节的能力,如图15(a)所示。相对于NeRF,错误率最高降低了60%,同时速度提升了7%。虽然,这种方法可以很好地提升虚拟视点的图像质量,但是对于具有镜面反射的场景渲染效果不佳。Ref-NeRF[39]方法通过在物体表面的法向量上引入正则化矩阵,以定向MLP作为图像差值核心,周边镜面区域渲染共享该矩阵,如图15(b)所示。该方法可以显著提升虚拟视点图像质量,渲染结果的PSNR达到33.99 dB,相对于传统方法至少提升了6 dB。
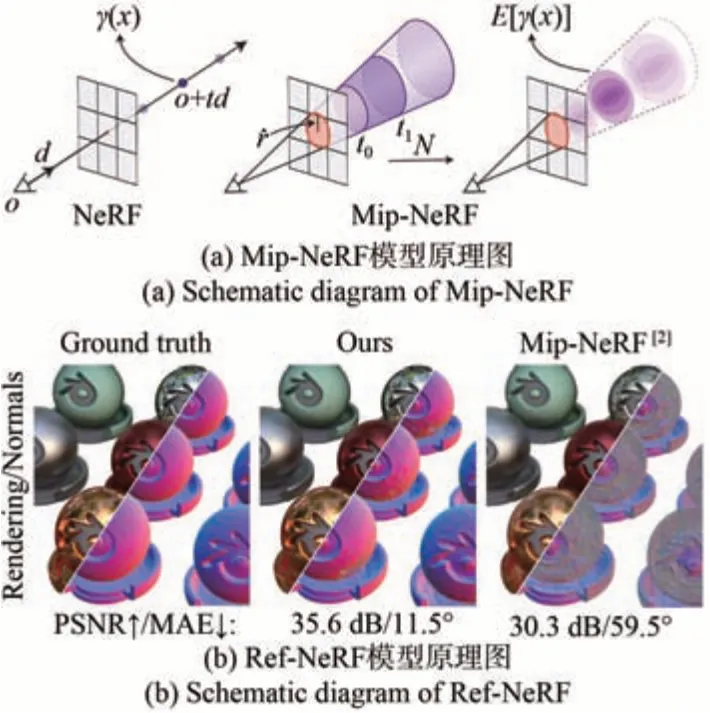
图15 虚拟视点图像质量提升算法Fig.15 Algorithm for enhancing virtual view image quality
上述方法虽然都显著提升了虚拟视点的图像质量,但是在渲染过程中,NeRF需要查询深度多层感知器(MLP)数百万次,导致图像处理时间过长。这是NeRF面临的另外一个挑战。Lingjie Liu[40]尝试通过引入神经稀疏体素场(NSVF)定义了一组以稀疏体素八叉树组织的体素边界隐式字段,以模拟每个元格中的局部属性。相对于Mildenhall[35]方法,该方法的渲染速度提升了10倍以上。Tao Hu[41]设计了一种新颖的数据结构,在测试过程中缓存整个场景以加快渲染速度。该方法减少了超过88%的训练时间,渲染速度达到200 FPS以上,同时生成了具有竞争力的高质量图像。KiloNeRF[42]方法通过将复杂的空间场景分解为规则网格并为每个网格单元分配小容量网络的方式,实现了NeRF实时渲染。该方法沿坐标轴均匀分解场景,把场景最多分为4 096个小场景。同时对数千个独立的MLP进行并行处理,相对于传统的NeRF,速度提升3个数量级。Instant NeRF[43]引入了一种新的编码方法,该方法可以在不牺牲图像质量的情况下使用更小的神经网络进行训练,这种架构可以很轻松地在全融合CUDA内核上完成并行加速运算,如图16所示。在同等的渲染图像质量(PSNR)的情况下,渲染速度提升20~60倍,可以在数十毫秒内完成1 920×1 080分辨率的图像渲染。
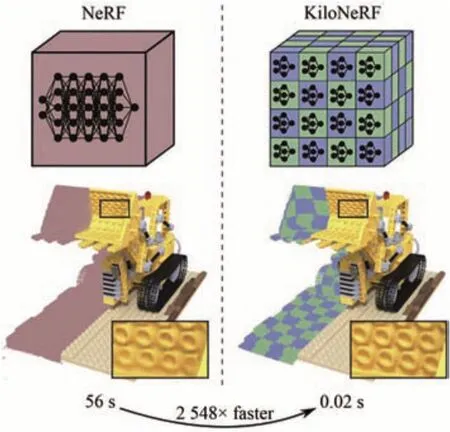
图16 Instant NeRF原理图Fig.16 Schematic diagram of Instant NeRF
为了评估上述算法的性能,根据公开的论文资料,基于相同数据集Synthetic-NeRF Database,对几种典型NeRF模型的虚拟视点图像质量和合成速度做定量比较,结果见表2和表3。
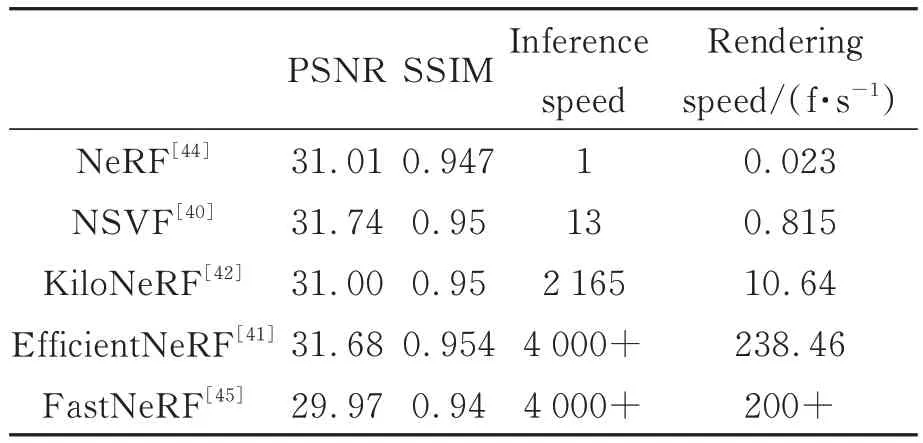
表2 典型的NeRF模型性能比较Tab.2 Performance comparison of typical NeRF mode
表3 典型的NeRF模型源码链接Tab.3 Source link of typical NeRF mode
3.2 多信源虚拟视点生成
相对于单信源虚拟视点生成,多信源虚拟视点生成需要依赖更多的目标场景特征信息作为辅助。目前,多信源虚拟视点生成算法已较为成熟,并广泛应用于科研和商用领域[46]。对于采用相机阵列[47]和光场相机[48-49]等多视点直采方式,这里不做讨论。几种典型的生成算法如下。
基于深度信息的虚拟视点生成算法(Depthimage-based rendering,DIBR)[50-52]利用深度信息,将2D图像的像素进行三维空间拓展,并按照需要的角度进行二维投影即可得到相对应的虚拟视点。但遮挡区域的空洞填充是该方法所面临的挑战之一。东南大学的赵健团队提出基于傅里叶切片理论的图像修复算法[53],可以快速、自然地修复空洞区域,如图17所示。但对于较大的空洞区域,一般需要参考其他视点内容进行填充[54-56]。
基于建模的虚拟视点生成算法(Model-based Rendering,MBR)[57-58],根据自然场景中物体的构造特征对目标场景进行几何建模(图18)。按照光场设备的光学参数,通过虚拟相机阵列对三维模型进行视差图像序列采集[57,59]。该方法可以获得任意角度的高质量虚拟视点,但是三维场景建模的难度高、周期长,不能满足光场显示对复杂、多变场景的生成需求,但在游戏、教育等场景相对固定的应用领域具有巨大潜力[60-61]。

图18 MBR原理图Fig.18 Schematic diagram of model-based rendering
基于稀疏视点的密集虚拟视点生成算法(Sparse viewpoint-based Rendering, SVBR)[62]利用已有的稀疏视点,通过几何信息编码获得虚拟视点插值(图19)。该方法可以获得高质量的合成视点[63-64]且理论视点密度无限大,但该方法存在计算资源消耗大、渲染速度慢、相机基线有限等问题。来自北京邮电大学的Binbin Yan[65]团队提出基于cutoff-NeRF的虚拟视点合成算法,实现了8K分辨率的虚拟视点实时渲染。虚拟视点的PSNR约为29.75 dB,SSIM约为0.88,合成8K 3D图像时间约为14.41 s。

图19 SVBR原理图Fig.19 Schematic diagram of sparse viewpoint-based rendering
4 结论
光场显示技术具有沉浸感好、视觉舒适度高等特点,已成为新型显示技术的研究热点。目前,光场显示技术向着视点数量越来越多、视场角越来越大、光场渲染速度越来越快的方向发展。但现有显示技术仍不能完全消除辐辏调节冲突,更符合人眼立体视觉的光学设计和更加密集的虚拟视点被认为是解决该问题的关键。另外,相对于多信源虚拟视点生成技术,单一信源虚拟视点生成技术还不成熟,图像质量和渲染速度均有待提高。但是,单一信源虚拟视点生成技术具有广泛的市场前景和发展潜力,有望彻底解决光场成像技术内容缺少的难题。
猜你喜欢
无线电工程(2022年4期)2022-04-21
科学(2020年5期)2020-01-05
常州工学院学报(2017年3期)2017-09-16
电子世界(2017年16期)2017-09-03
河南电力(2016年5期)2016-02-06
西部广播电视(2015年4期)2016-01-15
新闻前哨(2015年2期)2015-03-11
浙江大学学报(工学版)(2015年1期)2015-03-01
中国水利(2015年5期)2015-02-28
摄影之友(2014年3期)2014-04-21
