
基于YOLOv7-Sim 和无人机遥感影像的烟株数量检测
2023-10-12 13:32:42耿利川王忠丰秦永志
中国烟草科学 2023年4期
耿利川,王忠丰,秦永志,马 莉
(1.许昌学院城市与环境学院,河南 许昌 461000;2. 92493 部队,辽宁 葫芦岛 125000;3. 61206 部队,北京 100042)
烟草种植信息是烟草信息化生产管理的重要依据,精确测算烟株数量,可为烟草管理部门及时、准确掌握烟草生产形势、调整烟草指导性种植计划以及评估有关政策执行情况等提供参考依据,为烟草的科学研究和定量化管理奠定基础。传统烟株数量核查方法主要通过人工实地量算,耗时费力,且无法保证精度。自动化定位与提取烟株数量,有利于提高核查速度和准确率,对加快农业智能化发展有重要意义。
随着遥感技术的进步,利用遥感影像对烟草种植信息进行提取已经受到国内外诸多研究人员的关注。从所利用的影像数据源来看,目前主要分为两大类。一类为卫星遥感影像。刘明芹等[1]基于资源三号卫星遥感影像对山区套种烟草面积进行了估测,经过分类后处理提取的烟草面积精度达到94.63%;张阳等[2]采用决策树分类方法提取了Sentinel-2A 数据中的烟草种植区域信息,精度达到90.29%;罗贞宝等[3]利用高分1/2 遥感卫星影像,以毕节市七星关区大河乡为试验区,开展了多源、多时相遥感数据与面向对象分类相结合的烟草种植区提取方法研究。另一类为无人机遥感影像。无人机遥感技术相较于卫星遥感技术,具有机动灵活、成本低、高分辨率、不受重访周期限制、可实现云下飞行的特点,有利于快速获取高精度地表地理空间信息,在烟草种植面积核查工作中也得到较多应用。董梅等[4]利用面向对象的分类方法对无人机遥感影像中的烟草种植面积进行了提取,扩展了烟草种植面积遥感监测的手段;ZHU 等[5]提出了一种组合监督分类和图像形态学方法的无人机遥感影像数据烟草识别方法,总体精度达到95.93%;夏炎等[6]提出了一种基于模糊超像素分割算法的无人机烟株提取方法,达到80%以上的检测精度;付静等[7]结合形态学方法与Otsu 算法,对无人机遥感影像中的烟草苗期株数进行了提取。综合分析近年来国内外针对烟草信息的提取研究可知,目前针对烟草种植信息的提取大多集中于种植面积,对于烟株数量提取方面则研究较少。前期研究中,多采用图像多尺度分割算法和形态学分割算法,存在边界依附性差,分割尺度难以确定以及分割错误等问题。由于无人机烟草遥感影像具有烟株形状差异大、目标较小且尺度不一致等特点,对烟株信息自动提取带来了诸多困难。图1 为无人机航拍影像,从中可以发现,烟草植株个体较小,呈现局部聚集,并且由于生长状况不同植株外形尺寸差异较大。

图1 烟草无人机遥感影像Fig. 1 Tobacco plant UAV remote sensing images
近年来,基于深度学习的目标检测技术发展迅速,其代表算法有R-CNN[8]、Fast R-CNN[9]、Faster R-CNN[10]、YOLO 系列算法[11-13]、SSD 算法[14]等。在无人机遥感影像目标检测算法的研究中,付虹雨等[15]利用YOLOv5 算法实现了无人机遥感影像中的苎麻植株计数。陈旭等[16]基于YOLOv5s 设计了一种改进的浅层网络YOLOv5sm,提高了无人机影像目标的检测精度。张瑞倩等[17]在YOLOv5 算法的基础上,增加了多尺度的空洞卷积模块,加大视野感知域,提高网络对无人机影像中的目标分布、尺寸差异等的学习能力,进一步提升网络对无人机影像中多尺度、复杂背景下的目标检测精度。杨蜀秦等[18]针对玉米雄蕊提取问题,提出去除CenterNet网络中对图像尺度缩小的特征提取模块,在降低模型参数的同时,提高了检测速度。马永康等[19]提出使用有效通道注意力机制对CSPDarknet53 骨干网络进行改进,避免降维的同时增强特征表达能力,实现了红树林单木目标检测。受上述研究的启发,本文针对无人机遥感影像烟草植株自动检测问题,提出了一种优化后的YOLOv7[20]模型。为提高模型跨长序列学习关联特征能力,将SimAM 注意力机制[21]引入到YOLOv7 算法中,同时为提高算法对小目标的检测精度,对原始YOLOv7 算法增加了小目标检测层,在损失函数方面引入了EIOU 函数[22],进一步优化模型对目标框与预测框之间的相似性计算,针对原始图像太大的问题,采用了分块裁剪检测后再合并的策略[23],最后,利用河南省驻马店市泌阳县某地无人机航拍烟草影像,构建了UAVTob 烟草数据集,对该模型提取检测烟草株数的效果进行了验证。
1 材料与方法
1.1 数据集来源
本实验基于Pytorch 深度学习框架,利用GPU进行训练,具体配置如表1 所示。
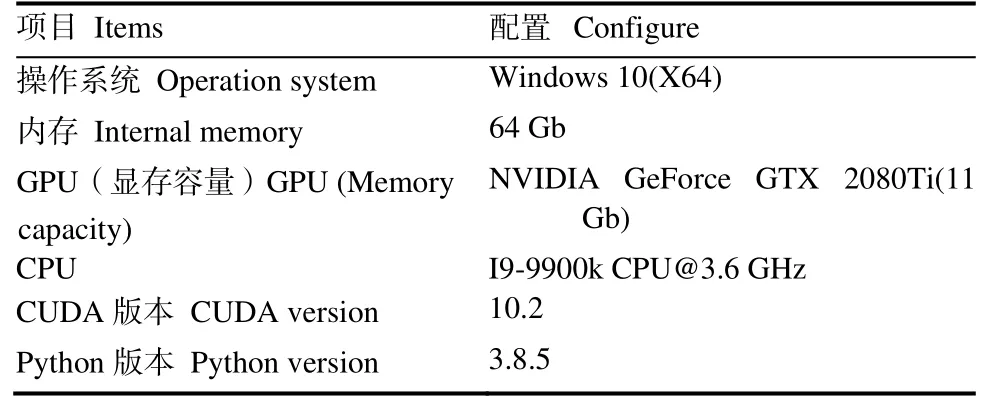
表1 实验环境配置Table 1 Experimental environment configuration
本实验数据分别使用了VisDrone2019 数据集[24]和UAVTob 数据集。VisDrone2019 数据集由天津大学机器学习与数据挖掘实验室AISKYEYE 队伍负责收集,包括288 个视频片段,总共包括261908帧和10209 个静态图像,由各种无人机安装的相机拍摄,涵盖位置、环境、物体和密度等方面,影像分辨率无固定大小。UAVTob 数据集由本课题组利用无人机航拍建立,获取地点泌阳县位于河南省驻马店市西南部,介于北纬 32°34ʹ~33°09ʹ,东经113°06ʹ~113°48ʹ之间,年平均日照时数2 066.3 h,年平均气温14.6 ℃,年平均降水量960 mm,地处浅山丘陵区,地势中部高,东西低,平均海拔142.1 m,属大陆性季风气候。UAVTob 数据集由85 幅大疆精灵4P 无人机航拍影像组成,航拍时间为2022 年5月,为避免云层遮挡及太阳光照阴影影响,选择晴朗无风天气,10:00—14:00 时间段进行航飞,影像原始大小为5472×3648 像素,地面分辨率为3 厘米。在图像标注前,将原始影像裁剪为1312 幅912×912 像素分块影像。
1.2 研究方法
在目标检测领域,YOLO 系列算法作为单阶段检测算法得到了广泛应用,YOLO 算法将目标检测看作回归问题,利用卷积神经网络提取图像特征,并直接从中获取目标类别与位置。YOLO 算法将图像划分为S×S 大小网格单元,针对每个网格单元生成若干边界框,如果某目标的中心落入一个网格单元中,该网格单元负责检测该目标,并预测出目标的位置、类别与置信概率。
1.2.1 YOLOv7 算法介绍 YOLOv7 算法由Wang等[20]于2022 年提出,为YOLO 系列算法的进一步改进。其网络结构如图2 所示,主要由骨干网络、颈部以及预测层3 部分组成。骨干网络利用卷积神经网络在不同图像细粒度上聚合并形成图像特征。颈部网络通过一系列操作来混合和组合图像特征,并将图像特征传递到预测层。预测层对图像特征进行预测,生成边界框并预测类别。YOLOv7 算法输入端整体沿用了YOLOv5 的预处理方式和相关源码,融合了Mosaic 数据增强、自适应锚框计算、自适应图片缩放等操作。骨干网络使用了ELAN 和MP 结构。颈部层采用了SPPCSPC 结构,同时也使用了ELAN 与MP 结构。预测部分使用了CIOU 损失函数。
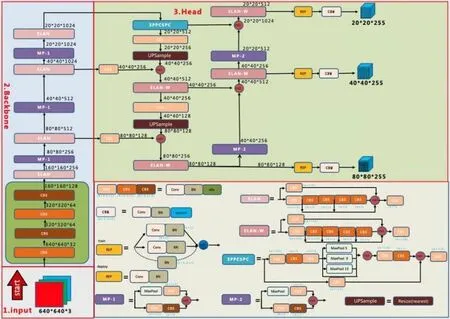
图2 YOLOv7 算法网络结构图Fig. 2 YOLOv7 network structure
1.2.2 YOLOv7 算法改进 (1)注意力机制改进。为了全局聚合网络提取的图像特征,基于卷积的架构需要堆叠多层网络特征[25]。尽管堆叠更多的层确实提高了网络的性能[26],但计算量随之增加。注意机制通过基于内容的寻址机制可以实现成对的实体交互,从而能够跨长序列学习关联特征层次结构,极大缩短远距离依赖特征之间的距离,更有效地利用远距离网络特征。本文受此启发将SimAM 注意力机制引入到YOLOv7 算法中,其原理如图3 所示[21]。现有注意力机制普遍存在2 个问题:(1)只能沿通道或空间维度细化特征,限制了它们学习不同通道和空间中变化的注意力权重的灵活性;(2)结构上通常由一系列复杂因子建立组成,计算复杂。SimAM 模块无需向原始网络添加参数,而是在一层中推断特征图的3-D 关注权重。通过优化一个能量函数来挖掘每个神经元的重要性,该模块能够根据定义的能量函数解对特征进行增强处理,避免在结构调整上花费太多精力,提高网络的表达能力。
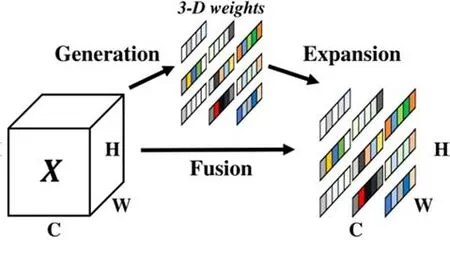
图3 SimAM 注意力机制原理图Fig. 3 Schematic of the attention mechanism of SimAM
(2)增加小目标检测层。在无人机影像上,烟草植株目标均小于32×32 像素,与其他类型影像相比可被看作是为小目标,如图1 中所示。如果针对原始影像进行训练,YOLOv7 在训练过程中会将图像下采样为80×80、40×40、20×20 像素大小,由于图像过度下采样会导致图像中的小目标特征信息丢失。针对小目标的检测,本文在原始算法中新增加了160×160 的检测特征图,用于检测4×4 以上的目标锚框,同时在训练时利用K-means 均值和遗传算法对数据集进行分析,自动学习新的预定锚框,获得更适合该数据集的预设锚框。
(3)损失函数优化。YOLOv7 采用CIOU 作为目标定位损失函数,其损失函数如公式(1)所示,
其中,ρ2(b,bgt)表示真实框与预测框中心的欧式距离,c表示真实框与预测框最小闭包区域对角线距离,a为损失函数的权衡参数,具体定义如公式(2)所示;v表示真实框与预测框的长宽比,具体定义如公式(3)所示,其中w和h是包含预测框和真实框的最小闭包区域的宽度和高度。
CIOU 损失虽然考虑了边界框回归的重叠面积、中心点距离、纵横比,但是其公式中的v反映的是纵横比的差异,而不是宽高分别与其置信度的真实差异,所以会阻碍模型对边界框相似性的有效优化。针对这一问题,Zhang 等[22]在CIOU 的基础上将纵横比拆开,提出了EIOU 损失函数,定义如公式(4)所示。该损失函数包含3 个部分:重叠损失、中心距离损失、宽高损失。前两部分延续CIOU 中的方法,但是宽高损失直接使目标框与锚框的宽度和高度之差最小,使得收敛速度更快。将纵横比损失项拆分成预测框宽高分别与真实框宽高的差值,加速了收敛,提高了回归精度。本文对YOLOv7 算法中的损失函数进行了改进,利用EIOU 损失函数,代替原始YOLOv7 算法中的CIOU 损失函数。
其中,c、cw、cw分别代表能够同时包含预测框和真实框的最小外接矩形的对角线长度、宽度和高度。
(4)影像分块检测策略。无人机获取的原始影像大小为5472×3648 像素,直接利用原始影像进行训练或测试,会将图像缩放为640×640 像素大小,导致烟株像素值太小,从而检测困难。本文采用了YOLT 算法[23]方式,利用滑窗方式将原始图像裁剪为912×912 像素的图像作为模型的输入,裁剪后的区域称为chip,为了保证每个区域都能被完整检测到,相邻的chip 会有15%的重叠,图4 为分块策略示意图,之后将检测结果合并,经非极大值抑制(NMS)处理后获得最终的检测结果。

图4 原始影像分块策略示意图Fig. 4 Schematic diagram of the original image segmentation strategy
2 烟株检测结果与评价
2.1 评价标准
本文实验评价标准包括:召回率R(Recall),精确率P(Precision),平均精确率AP(Average precision)和均值平均精确率mAP(Mean average precision),各标准的具体公式如公式(5)-(8)所示:
式(5)-(8)中,TP表示正样本被正确识别为正样本,FP表示负样本被错误识别为正样本,FN表示正样本被错误识别为负样本。此外,本文还使用MS COCO[27]中的评估标准来评估检测算法的结果,包括mAP@0.5、mAP@0.5:0.95。其中,mAP@0.5 即将IOU 设为0.5 时,计算每一类的所有图片的AP,然后所有类别求平均,即mAP。mAP@0.5:0.95 表示在不同IOU阈值(从0.5 到0.95,步长0.05)上的平均mAP,该值被用作排名的主要依据。
2.2 VisDrone2019 数据集实验结果与对比
为验证改进算法的有效性,本文首先在VisDrone2019 数据集上进行了实验验证,实验选取YOLOv7 模型作为参考基准,在此基础上对其进行优化。实验基于算法原有配置,批处理大小(batch size)设置为4,轮次(epochs)设置为150。图5给出了算法优化前后的P-R 曲线和mAP@0.5 对比。由图5 对比结果可以看出,优化后的YOLOv7-Sim模型在VisDrone2019 数据集上取得了较好的结果。YOLOv7 模型优化后mAP@0.5 由49.6%提高到49.9%,精度提高了0.3%。表2 给出了FPN[28]、CornerNet[29]、 Light-RCNN[30]、 DetNet59[31]、RetinaNet[32]、Cascade R-CNN[33]、RefineDet[34]各算法在该数据集上的实验结果与本文算法的实验结果对比,表中标粗数据为该类别精确率最高值。由表2 对比结果可以看出,优化后的算法精确率较优化前在多数类别上均有不同程度的提升,仅在bicyle、tricycle 和motor 类别上出现了精确率略微下滑现象,可能在参数上需要进一步优化,但相比于其他算法结果,优化后的YOLOv7 算法均取得了最优的检测结果,尤其是对ped、car、van、bus 的检测提升效果明显,验证了本文算法的有效性。

表2 各算法AP 与mAP 结果对比Table 2 Comparison of each algorithms’ AP and mAP results %

图5 YOLOv7 优化前后的P-R 曲线、精确率与mAP@0.5 对比Fig. 5 P-R curves, AP and mAP@0.5 before and after YOLOv7 optimization
2.3 UAVTob 数据集实验结果与对比
为进一步验证本文算法针对无人机遥感影像中烟株的检测效果,本实验对自建UAVTob 数据集进行了实验验证。实验中批处理大小(batch size)设置为6,轮次(epochs)设置为150。图6 给出了YOLOv7 与优化后的YOLOv7 在训练过程中,召回率、精确率、均值平均精确率 mAP@0.5、mAP@0.5:0.95 的增长曲线对比。其中红色曲线为优化前,绿色曲线代表优化后,横坐标表示训练epoch 数,纵坐标表示各评价参数值。通过各指标的对比可以发现,在训练过程中优化后的算法召回率、精确率以及均值平均精确率增长速度和最终值均优于原算法,算法在训练到100 epoch 时接近收敛。

图6 训练中YOLOv7 优化前后各评价标准增长对比曲线Fig. 6 The growth curve between YOLOv7 and optimized YOLOv7 during training
为了验证各优化模块对YOLOv7 模型的改进,对各改进模块单独与原YOLOv7 模型进行组合,并测试了其结果。各改进模块间的消融实验结果如表3 所示。其中标记“√”的表格表示使用了该模块。由表3 的消融实验结果可以看出,本文提出的每一个改进模块对提升均值平均准确率mAP@0.5 都有一定的作用,综合各优化方式后的改进算法检测烟草的平均精确率均值mAP@0.5 达到94.5%,相比原算法提高了6.3%。改进算法的均值平均准确率mAP@0.5:0.95 达到47.7%,相比原算法提高了18.3%。图7 给出了两组检测结果,其中每组中左图为YOLOv7 算法结果,右图为YOLOv7-Sim 算法结果。对比后可以发现,改进后的算法对影像边缘部分的不完整与较小烟株的检测结果要优于原算法,说明YOLOv7-Sim 算法对遥感影像中的小目标检测具有一定的优越性。

表3 YOLOv7-Sim 各模块间消融实验的mAP 对比Table 3 mAP comparison of ablation experiments between modules of YOLOv7-Sim %

图7 不同方法在UAVTob 数据集上检测结果对比Fig. 7 Detection results comparison of different methods on UAVTob dataset
3 讨 论
本文研究发现YOLOv7 深度学习算法对烟草植株数自动清点具有显著作用,通过从注意力机制、小目标检测、损失函数、检测策略4 个方面对原始YOLOv7 算法进行改进,利用召回率、精确率、均值平均精确率mAP@0.5,mAP@0.5:0.95 4 个评价指标对原始算法与改进算法性能进行对比分析。本文利用无人机航拍烟田遥感影像构建了UAVTob 数据集,YOLOv7 算法在该数据集上测试的均值平均精确率mAP@0.5 为88.2%,通过引入注意力机制后该指标达到93.0%,增加小目标层后该指标为90.9%,利用改进的EIOU 损失函数后该指标为93.5%,综合3 种改进模块后mAP@0.5 达到94.5%。YOLOv7 算法对UAVTob 数据集上的均值平均精确率mAP@0.5:0.95 为29.4%,通过添加3 种改进模块后该指标分别达到44.7%、43.6%、46.6%,提升幅度均超过 14%,综合 3 种改进模块后mAP@0.5:0.95 达到47.7%。对比结果说明本文的改进方法对提高原始YOLOv7 算法在检测烟草植株数量方面具有较高的适用性,相对于夏炎等[6]提出的基于模糊超像素分割的烟株提取方法约80%的检测精度,本文检测结果更加精确。
烟草长势对烟株数检测算法有重要影响,如果烟草长势较快,航飞时间滞后,烟草叶片交叉连成片的情况下,利用无人机遥感影像进行烟株数清点将面临巨大挑战,因为在该情况下,烟草植株在影像上不再是独立个体,而是成行或成片,利用视觉算法很难将其独立区分,因此在利用无人机遥感方式进行烟草植株数清点时,需要在烟草叶片还未连接成片的时间节点前完成航拍作业。
影像地面分辨率(Ground Sample Distance,GSD)是遥感影像的一个重要指标,它与航拍高度及镜头焦距相关。不同GSD 影像中烟草植株的大小、纹理特征有明显区别,航拍高度越高,影像地面分辨率越低,GSD 越大,烟草植株的特征信息越模糊,特别是细节特征被忽略。研究表明,利用高分辨率影像构建的模型具有更加稳定的性能,能够显著提高目标识别的精度。因此应该在不影响航拍效率的基础上,尽可能获取高分辨率影像。
本研究仅在单个烟株影像数据集上构建了模型,很难扩展到其他作物。当出现新的作物品种需要检测时,还需要针对该作物单独构建模型,因为模型的性能主要取决于训练样本集的数量及其多样性,由于样本标记过程比较繁琐,高效开发稳定的模型仍然面临挑战。研究如何提高模型的通用性,或在少量训练样本的基础上,保持模型的检测精度具有重要意义。
4 结 论
结果表明,针对无人机遥感影像中烟株目标检测存在的烟株形状差异大、目标较小且局部聚集的问题,对YOLOv7 算法进行了优化,提出了一种改进的模型YOLOv7-Sim。通过加入SimAm 注意力机制,强化了卷积捕获特征之间的聚合能力,加入小目标检测层增强算法对小目标的检测能力,选取了EIOU 定位损失函数,直接利用目标框与锚框的宽度和高度之差信息,加快了算法收敛速度,针对遥感影像尺寸过大问题采用了分块检测后拼接的策略。实验结果表明,优化后的YOLOv7 算法在VisDrone2019 数据集以及课题组自建UAVTob 烟草数据集上的目标检测精度得到有效提升,本文方法为精确检测烟草种植位置及数量提供了有效手段。
猜你喜欢
奥秘(创新大赛)(2023年3期)2023-05-06 01:48:20
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
江西农业(2022年2期)2022-02-25 04:09:26
作文小学中年级(2020年6期)2020-07-24 08:33:10
浙江中西医结合杂志(2017年2期)2017-01-12 18:23:59
中国烟草学报(2016年1期)2016-11-16 08:38:11
西南农业学报(2016年4期)2016-05-17 05:42:12
当代化工研究(2016年9期)2016-03-20 16:22:08
声屏世界(2014年6期)2014-02-28 15:18:09
自然资源遥感(2014年3期)2014-02-27 11:56:38
