
逆合成孔径成像雷达隐身目标零样本识别
2023-10-11 13:31周春花魏维伟张学成程冕之
系统工程与电子技术 2023年10期
周春花, 魏维伟, 张学成, 郑 鑫, 程冕之
(1. 上海无线电设备研究所, 上海 201109; 2. 上海目标识别与环境感知工程技术研究中心, 上海 201109; 3. 中国航天科技集团交通感知雷达技术研发中心, 上海 201109; 4. 陆军装备部驻上海地区第三军事代表室, 上海 200031; 5. 上海航天技术研究院, 上海 201109)
0 引 言
传统机器学习任务依赖大量有良好标注的数据,并且在许多识别任务中都取得了重大进展。然而,传统机器学习方法仅能识别与训练类别相同的目标,当一个新的类别出现时,传统模型无法识别出这一新的目标类型。逆合成孔径雷达(inverse synthetic aperture imaging radar,ISAR)隐身目标的实际应用即面临这一问题。一方面,直到目前为止,没有公开、确凿的隐身目标ISAR的数据支撑;另一方面,隐身目标的ISAR成像受目标位置、姿态、雷达照射角度和隐身目标的低可探测性影响,难以实现人工标注。由已有的先验数据可知,隐身目标的视觉图像信息和文本语义特征信息与ISAR成像信息相比较为充裕,由此提出ISAR隐身目标零样本学习,通过借助文本语义描述信息,生成图像特征信息,以支撑不可见未知的新目标识别。
文献[1]将图像小块分割后引入多头自监督的视觉注意力转换机制以解决可鉴别属性定位问题;文献[2]基于二维视觉图像和无纹理的三维模型训练零样本学习模型推理三维未知模型;文献[3]提出了既可以处理分类,也可以泛化处理的语义分割零样本学习模型;文献[4]通过部组件识别重构图像场景的主谓宾语义理解关系,从而实现场景生成模型的性能提升;文献[5]提出意大利语的文本语义与图像特征对零样本学习模型;文献[6]利用双层注意模块结合区域和场景上下文信息来丰富特征,以更好地实现多标签的零样本学习分类。
本文提出使用两个生成模型分别处理隐身目标ISAR图像信息和语义描述信息,通过学习具备模态不变特征的潜在变量来实现对于不可见类别的识别。使用所提模型在公开数据集和私有数据集均获得了良好效果,其中对于隐身目标的识别率达到了75%。
1 算法原理
零样本学习指借助文本语义信息的辅助来实现对于不可见类型目标的识别。通常情况下,零样本学习算法会首先利用可见类别目标的视觉图像和对应的语义描述来训练一个生成网络,实现以输入语义描述生成视觉图像的生成过程。然后,使用该生成网络和不可见类语义描述来生成与之对应的不可见类图像,从而解决不可见类图像的样本缺失问题,借助常见的分类器网络实现对于不可见类目标的识别。
本文首次在ISAR隐身目标零样本识别问题中引入零样本学习,采用的零样本学习同样遵循了生成式的方法,实现文本语义特征信息到雷达图像特征生成迁移。所谓生成式指的是训练一个生成网络,该网络能够根据给出的语义描述生成对应的图像特征。在生成式的零样本学习研究中,有两种典型的生成网络,一种是生成式对抗网络(generative adversarial network, GAN)[7],另一种是变分自编码器(variational auto-encoder, VAE)[8]网络。通过生成网络,借助不可见类的文本语义描述信息,可以获得对应的不可见类的图像特征。采用生成的不可见类图像特征来进行分类识别,当生成的图像特征具备了真实目标特征时,就能够实现对于真实不可见类目标的识别,从而实现利用文本语义信息辅助来实现对于不可见类目标的识别,能够成功地分辨出各类型的实体。其中,GAN需要的计算资源丰富、训练成本高、训练时间更长,而VAE需要的计算资源较少、训练时间较短,但存在一定程度的生成图像失真问题。为了能够实现高效网络运行,本文采取VAE的结构。

Ez~qθ(z|x)[lnpφ(x|z)]-DKL(qθ(z|x)‖p(z))
(1)
式中:qθ(z|x) 表示参数为θ的编码器;pφ(x|z)表示参数为φ的解码器。式(1)中的第1项为自编码器的重构误差,第2项DKL(·)为KL散度(Kullback-Leibler divergence),这一项的作用是约束编码器qθ(z|x)以更加接近符合高斯分布的前验分布p(z)。
为了能够充分利用语义描述和视觉图像特征两种模态的信息,设计了两个用于生成的模型,一个用于进行语义描述信息的编码和解码过程,另一个用于进行视觉图像信息的编码和解码过程。通过两个模型来实现对于语义描述信息a和视觉图像特征x的综合利用,所采用网络模型训练的损失函数为

(2)
式中:前两项表示用于进行视觉图像特征编解码的训练损失函数;后两项表示用语义描述信息进行编解码器训练的损失函数。式(2)中的z1和z2分别表示视觉图像特征和语义描述信息的潜在变量,即视觉图像特征和语义描述信息编码器的输出。
通过式(2)的约束,本文所设计的生成模型分别对视觉图像特征和语义描述信息分别进行了自编码处理。为融合利用两种信息实现的零样本目标的识别,视觉图像特征自编码器和语义描述信息自编码器的潜在变量需要包含视觉特征和语义描述两种模态的信息,因此针对表示视觉图像特征和语义描述信息编码器的输出的潜在变量z1和z2施加互信息处理,通过互信息处理让z1和z2包含的信息相互接近,从而实现两种信息的融合。进行互信息操作的一般过程如下:
(3)
式中:X和Y表示任意的两个变量。在本文中,采用增强同类别变量之间的互信息而减弱不同类别变量之间的互信息,因此最终对模型进行训练的损失函数为
(4)
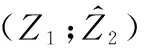
针对视觉图像特征和语义描述信息编码器输出的潜在变量z1和z2施加互信息,实现了对来自视觉图像和语义描述两种模态信息的融合。在本文所设计的方法中,最终需要针对潜变量来完成分类识别任务,因此在保证来自同一类别的潜在变量z1和z2包含模态不变信息的同时,还应保证能够充分学习两个潜在变量的特征。因此,对两个潜在变量z1和z2的联合分布进行最大化熵的操作,该操作如下:
(5)
式中:z=(z1,z2)是潜在变量的联合变量;H(z)表示计算联合变量的熵;f(·)表示进行softmax操作;pz1z2表示潜在变量z1和z2的联合分布。针对潜在变量施加互信息约束,通过最大化熵的操作,分类器在识别z1和z2时需要充分利用两个潜在变量的信息,而不会仅利用部分特殊信息来分辨潜在变量。
在零样本的学习任务中,处理了视觉图像特征模态和语义描述两种模态的数据,在涉及到多种模态处理的领域中,循环一致重构(cycle-consistent reconstruction,CCR)已被证实能够有效处理多模态数据问题[9-11]。同时,利用CCR进一步确保了潜在变量包含足够的模态不变信息。进行这一操作的过程如下:
|a-Ds(Ev(x))|]
(6)
式中:η>0是一个超参数。
在生成网络基础上,添加了互信息、最大化熵、CCR 3种技术手段来提升生成模型的表现。在进行模型训练时,将式(2)、式(4)~式(6)同时添加到训练损失中,得到的整体损失函数如下:
(7)
经过对生成模型的训练之后,针对潜在变量z1和z2训练一个softmax分类器,来执行零样本目标的识别任务。
为了方便和其他方法比较,遵循其他方法的设定,在视觉图像特征的自编码器输入端使用经过卷积神经网络提取的图像特征而非图像本身。自编码器中的编码器和解码器均由多层感知(multi-layer perception,MLP)机构成。
本文所使用算法的示意图如图1所示,本文所采用的编码器和解码器均为带有一个隐藏层的MLP机。其中,用于处理视觉图像信息的编码器隐藏层包含1 560个单元,相应的解码器隐藏层包含1 660个单元。用于处理语义描述信息的编码器隐藏层有1 450个单元,解码器的隐藏层有660个单元。

图1 本文算法示意图Fig.1 Schematic diagram of the proposed algorithm
模型进行训练的过程如图2所示,通过图2的流程使用训练数据进行模型的训练,同时每完成一次训练,使用验证集来进行模型的测试,根据测试结果判断是否继续进行训练。当验证结果及测试结果均满足预期要求时,停止训练,并保存网络模型参数。

图2 模型训练流程图Fig.2 Flowchart of model training
2 实验验证
2.1 公开数据集效果验证
为了对所提出的模型进行测试验证,同时为了表明零样本模型的真实能力,在公开动物属性(animal with attributes, AWA)数据集AwA1[12]、 AwA2[13],以及加州理工学院鸟类(caltech-USCD birds,CUB)数据集[14],以及场景理解(scene understanding,SUN)数据集[15]上进行测试。其中,AwA1和AwA2数据集为动物的图像数据集,包括50个类别的图片,其中40个类别作为训练集,10个类别作为测试集,每个类别的语义为85维。AwA1总共有30 475张图片,AwA2总计有37 322张图片。CUB全部都是鸟类的图片,总共200类,150类为训练集,50类为测试集,类别的语义为312维,有11 788张图片。SUN数据集总共有717个类别,每个类别包含20张图片,类别语义为102维,645个类别用于训练,72个类别用于测试,总计14 340张图片。上述的数据集是目前学术界进行零样本研究的主要数据集,在该类型数据集取得的效果能够证明算法模型的表现和性能。表1展示了综合识别可见类与不可见类时的结果,表格中的结果表示为可见类与不可见类识别结果的调和平均值,即调和均值=(2×可见类结果×不可见类结果)/(可见类结果+不可见类结果)。本文在公开数据集对比的方法包含特征标签嵌入(attribute label embedding,ALE)[14]、深度嵌入模型(deep embedding model, DEM)[16]、生成对抗零样本方法(generative adversarial approach for zero-shot learning,GAZSL)[17]、合成示例方法(synthesized examples, SE)[18]和自适应置信平滑方法(adaptive confidence smoothing, COSMO)[19]。

表1 不同方法在公开数据集上的效果表现Table 1 Performance of different methods on public dataset
根据表1中的结果,该方法明显优于之前的方法,在AwA1数据集上得到了4%的提升,在AwA2数据集上得到了5.4%的提升,在CUB数据集上得到了4.8%的提升,在SUN数据集上得到了0.4%的提升。
2.2 自制数据集效果验证
在进行零样本目标识别时,由于文中待识别的目标为ISAR隐身目标,采取针对目标的光学和雷达双模态识别,首先获取光学图像,然后仿真生成雷达图像,最终达到的识别效果优于单一模态下的效果。此外,在实验中可直接获取的可见类图像主要为光学图像,因此在光学图像场景下的数据分析能够更加清晰地表明零样本学习效果,同时更便于理解零样本学习算法的实际作用。
本文的实验验证阶段首先收集了18种不同型号飞机的光学图像信息,表2详细介绍了数据集中各类型飞机及其对应的数目。

表2 进行零样本识别的飞机数据集Table 2 Aircraft dataset for zero-shot recognition

续表2Continued Table 2
针对文本语义描述信息,采用了基于目标属性的方式进行语义描述信息的制作,对“机身长度”“翼展”“是否有翼尖小翼(0,1)”“尾翼(0,1)”“机翼面积(m2)”“高度”“展弦比”“发动机个数”“机翼形状(后掠翼、三角翼、梯形翼、菱形翼)”“推进动力(螺旋桨,喷气机等)”“机翼数量”“起落架数量”“主起落架轮子数”“垂直稳定器数量”“飞机类型” 等类型属性进行标注。表3详细介绍了进行零样本识别时使用的语义描述信息。最终,将所有的属性信息按照顺序进行了排布,然后根据属性的内容处理为浮点数值,将内容中为数值的内容转换为浮点类型数据,将布尔值数据转换为用“0”与“1”代表的数值数据,将比率数据直接转化为以小数表示的浮点数据,将选项值数据按照选项个数进行编号,并以编号内容作为属性值。通过数据化的操作,最终所有的语义标注信息转变为一条由纯数据构成的属性向量。属性向量的维度为17维,每一维度对应属性中的每一个项目。
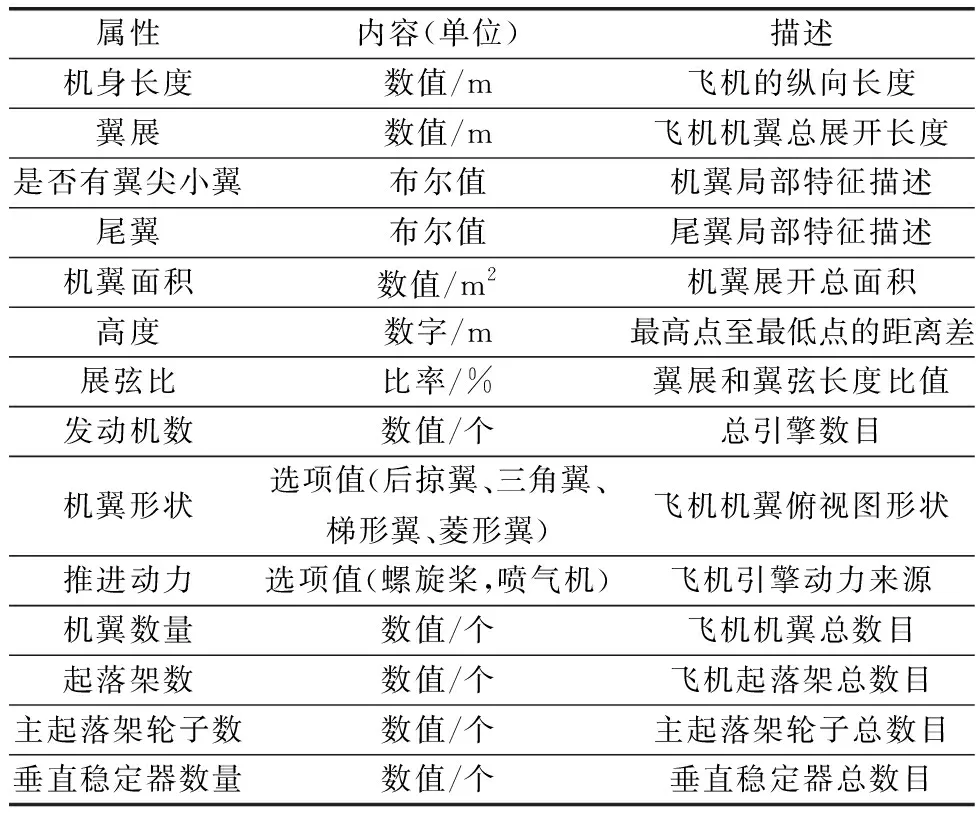
表3 进行零样本识别的语义描述含义Table 3 Meaning of semantic description for zero-shot recognition

续表3Continued Table 3
针对飞行器数据集,采用15种类型的飞机来进行训练,经过训练和最终的测试,测试结果如图3所示,该模型成功识别了不可见类飞行器(图3所示A机型和B机型)并达到了75%的综合识别效果,其中针对A机型的识别率更是达到了86%。

图3 自制数据集零样本识别效果Fig.3 Zero-shot sample recognition performance of customized data set
在针对飞机类型的测试中,该模型在识别B机型时识别成功率为63%,即在100份B机型的雷达图像或光学图像中,能够识别出63%的目标并将其正确标记为B机型。在对A机型飞机进行识别时,该模型的成功率为86%,即在100份A机型的雷达图像或光学图像中,能够识别出86%的目标并将其正确标记为A机型。针对两者的综合情况,采取对两者的识别率计算综合分类成功概率为(86%+63%)/2=75%,因此模型综合识别两种类型的不可见类目标的效果为75%。
此外,还针对不同的生成网络生成样本的情况进行了对比实验,实验最终结果如表4所示。
护理前两组心理健康指标汉密尔顿相关指数接近,差异无统计学意义(P>0.05);护理后试验组心理健康指标汉密尔顿相关指数的改善幅度更大,差异有统计学意义(P<0.05)。

表4 3种不同生成模型的识别结果Table 4 Recognition results of three different generative models
由表4可以发现,使用单个VAE和单个GAN生成模型获得的最终识别率均低于本文所使用的方法,这也证明了本文所提算法与已有的成熟算法相比具备更高的生成效果,能够实现更好的零样本目标特征的生成。为了进一步证明本文所提算法的先进性,表4还报告了传统的零样本学习算法在飞行器数据集上的效果。需要注意的是,这里的传统零样本学习算法指的是非生成式方法。由于本文研究的是一个零样本识别问题,非零样本学习方法无法处理这一问题,所有非可见类目标都会被错误分到可见类目标中,使得非可见类目标的准确率为0。因此,本文只对零样本学习方法进行对比。
最后,为了进一步分析特征数量对精度的影响,在图4中报告了不同特征数量下精度的变化。
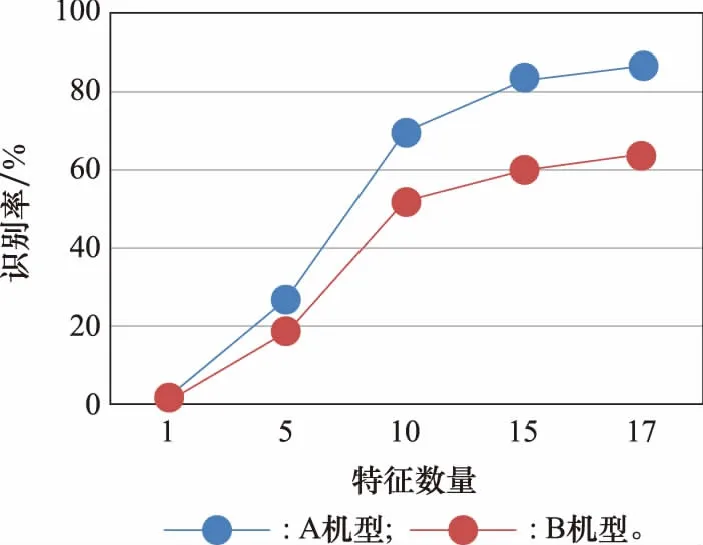
图4 特征数量对识别率的影响Fig.4 Recognition rate results with different number of features
从图4可以看出,随着特征数量的增加,模型的精度呈现增长趋势,证明了在零样本数据集中选择的特征均对最终识别精度有积极影响,没有冗余特征。
3 结 论
本文提出了ISAR隐身目标零样本学习方法的算法原理、实验验证过程及结果分析,依托不同飞机类目标细节属性的文本语义特征表达,训练零样本学习模型完成可见的源目标图像特征到具体类别的文本语义表达,不可见未知的新类别采用该语义生成不可见未知的新目标图像特征信息,支撑不可见未知的新目标识别,统计未知的新类别识别正确率达75%以上。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
开放教育研究(2020年2期)2020-03-31
成都信息工程大学学报(2018年3期)2018-08-29
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
电子设计工程(2017年20期)2017-02-10
现代语文(2016年21期)2016-05-25
中国老区建设(2016年1期)2016-02-28
电子器件(2015年5期)2015-12-29
大连民族大学学报(2015年2期)2015-02-27
