
中国政策量化研究的热点与趋势
——基于CiteSpace可视化分析
2023-10-09 09:42魏海瑞于卫红程佳雪
科技和产业 2023年16期
魏海瑞, 于卫红, 程佳雪
(大连海事大学 航运经济与管理学院, 大连 116026)
政策文件的价值已在公共政策学科中得到重视和研究,对政策文件进行研究是追溯和观察政策过程的一个重要途径。在公共政策学科中,早期的政策研究方式以政策解读为主,但是该方式是一种主观的定性研究,研究的结果过度依赖于研究者的知识背景、研究能力和个人价值立场,研究结果不能复现验证,导致研究结果的科学性、可靠性和普遍性受到质疑[1]。政策研究中迫切需要客观化的研究方法。
与此同时,数学、统计学、计量学、运筹学、系统分析等学科与技术得到进一步的发展,为政策分析的发展提供了量化研究的理论基础。随着计算机和信息存储技术的发展,越来越多存储的政策数据为政策量化研究提供了可规模化、可结构化的数据基础。在神经网络、文本挖掘等技术的发展下,政策学科及其与统计学、计量经济学、人工智能学等学科的融合发展,为政策量化研究提供了相关的技术基础[2]。基于相关理论和技术对存储的规模性政策数据进行系统、客观的量化分析变得日益重要,政策量化研究成果逐渐丰富。政策量化研究文献作为研究成果的物化载体,是政策量化研究的真实反应和记录,是对研究情况的客观、可获取、可追溯的文字记录。基于政策量化研究文献进行梳理可以把握研究的现状与趋势。
鉴于此,本文在对政策量化研究的概念和方法梳理的基础上,以2010年1月1日至2021年10月31日期间的中国知网(China National Knowledge Infrastructure,CNKI)中政策量化相关文献代表国内政策量化研究状况进行分析。首先,通过文献的发文数量分析近年来中国政策量化的研究热度;然后,从文献关键词的聚类和文献调研的结果对中国政策量化的研究热点进行分析;最后,以关键词突现性分析为视角分析中国政策量化的研究前沿。
1 政策量化研究文献回顾
在当今数据开放的时代背景下,基于政策量化相关文献的研究已经取得了一些成果。基于文献统计分析的研究方法,傅雨飞[3]回顾1999—2009年的政策量化研究相关文献,对比分析中美公共政策分析中量化方法的异同,指出量化方法在中国公共政策研究中运用不足,并提出强化量化方法在中国公共政策分析中应用的对策。郑新曼和董瑜[4]统计分析了CNKI和Web of Science数据库2017—2020年的政策文本量化研究相关发文数量,并对2016—2020年的文献进行归纳总结,分析了政策文本定量研究的方法和进展。基于文献调研归纳的研究方法,汪大锟和化柏林[5]从政策量化研究的数据源、研究方法和分析维度等方面对政策量化研究文献进行回顾和归纳分析。曹玲静和张志强[6]以政策信息学为视角,归纳总结政策量化研究领域中政策文本量化的兴起、内涵和常用的研究框架,并分别总结各类文本量化研究方法的优缺点与应用。但研究仍未对政策量化研究的概念进行梳理,2010年后的政策量化研究文献有待进一步分析。本文基于政策量化研究概念和方法的梳理,对2010年后国内政策量化的研究文献进行回顾和分析,有助于学者了解公共政策学科的发展情况、把握中国政策量化的研究现状与前沿,为政策量化的进一步研究提供重要参考。
1.1 政策量化研究概念梳理
政策量化通过管理学、数学、统计学等多种科学方法,对公共政策文件进行量化,将重点内容或属性转化为机器可以识别的数据,支持进一步的政策分析。随着政策量化研究的进一步发展,学术界涌现了许多政策量化研究相关的概念,如“量化研究”“政策文献量化研究”“政策文本量化分析”“政策文献计量”“政策文献量化研究”“半量化分析”“政策计量研究”“政策文本计算”等。由于不同学科的侧重点不同,当前学术界对政策量化研究的概念并没有进行统一的界定,因此,本文对政策量化研究相关概念进行梳理,如表1所示。

表1 政策量化研究相关概念梳理
从本质上来说,这些概念均被包含在政策量化研究的范畴中,因此将该类研究统称为“政策量化研究”。通过对已有相关概念的梳理,并结合目前政策量化研究发展对其概念进行完善,政策量化研究的概念可以被定义为:一种基于以文本为载体记录政策过程的各类数据,将多学科中可对结构化、半结构化及非结构化的数据进行客观分析的定量研究方法和定性研究方法相结合,围绕政策相关角度发现并描述政策内在的逻辑、规律,从而获得客观、可验证的分析结论,为政策的制定或发展提供建议的政策分析范式。
1.2 政策量化研究方法梳理
目前政策量化研究中所使用的定量方法融合了多个领域学科,方法多样且近年来发展迅速,有必要进行梳理与总结。从技术的角度,可将政策量化研究方法分为传统的政策文本量化分析方法和智能的政策量化分析方法。其中,传统的政策文本量化分析主要包含文献计量法和内容分析法,其差别如图1所示。
传统的政策量化分析方法主要关注政策文本本身的结构特征和可结构化的政策文本分析单元内容,可以有效地揭示政策的属性特征。例如,叶光辉等[14]以文献信息资源保障相关政策文本为研究对象,进行编码和数理统计,分析发现政策数量演化和执行机构合作网络等外部特征和文本内容演化特征;张志远等[15]基于文献计量法和社会网络分析法分析创新政策的发布部门及其合作特征,并运用内容分析法编码统计分析政策措施及其协调度;徐明和陈斯洁[16]基于文献计量法统计疫情前后省级层面青年就业政策的政策文本数、发布部门的发文频次及其内部的网络社会关系,统计分析政策工具及其组合应用特征;兰梓睿[17]基于文本量化分析,从可再生能源政策力度、政策目标和政策措施3个维度构建评估模型,对中国可再生能源政策的效力、效果与协同度进行评估。
随着学科的交叉融合与科学技术发展,政策量化研究中所使用的定量方法逐渐偏向智能化,进一步对政策文本进行智能深度分析和挖掘,以获取更全面、准确、有效的政策信息和分析结果。常用的智能政策量化分析方法包括自然语言处理、机器学习等。例如,李倩等[18]基于TF-IDF(term frequency-inverse document frequency)算法对新能源产业政策文本中的关键词进行提取和内容分析,基于发布机构、政策类型和政策数量量化政策力度,并采用空间效应模型回归分析政策效应;施寒潇和毛郁欣[19]基于关键词的提取、特征过滤、特征向量化、文本聚类、语义网络分析等文本挖掘技术,量化分析跨境电商政策的文本特征与内容重点;赵菲菲和王宇琪[20]基于网络媒体数据,应用数据挖掘、机器学习等数据分析技术,提出了一个面向公共政策的网络媒体内容文本分析框架,并以新能源汽车政策为例对该分析框架的有效性进行了验证;Sheng等[21]基于深度神经网络的新型文本挖掘算法对文本内容及外部特征进行了不同组合的共现分析研究,探索了基于时空分布和内外部关联映射方法的知识挖掘。
综上所述,从技术的角度可以将政策量化研究方法分为传统的政策文本量化分析方法和智能的政策量化分析方法。其中,传统的政策文本量化分析主要包含文献计量法和内容分析法。智能的政策量化分析方法包含了自然语言处理、机器学习等。针对的文献特征不尽相同,不同的分析方法互为补充,有效利用各类分析方法的不同作用,最终达到对政策深度解析的目的。
2 基于CiteSpace的可视化分析
2.1 研究思路
在进行文献分析过程中,为尽量避免主观性问题,综合运用知识图谱与文献计量等方法,应用可视化文献计量软件CiteSpace5.8探究中国政策量化研究的现状与趋势,以求研究更加科学客观和直观。研究思路如图2所示。
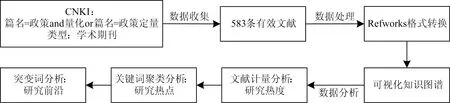
图2 研究思路
第一步,运用文献计量方法对政策量化相关文献的年度发文数量进行统计,分析中国政策量化的研究热度及演进趋势;第二步,将关键词聚类分析结果与文献调研结果相结合,分析中国政策量化研究的热点主题;第三步,利用突变词分析中国政策量化研究的前沿趋势。
2.2 工具介绍及数据来源
CiteSpace是一款基于科研文献中识别并显示科学发展动态趋势的软件,旨在通过时间分段策略均匀切片整个时区,然后根据共现关系将众多共现网络按顺序排列合并,最终递进式地生成可视化网络,具有“一图谱春秋,一览无余,一图胜万言,一目了然”的特点[22]。基于前文对已有相关文献的综述,利用CiteSpace5.8.R3可视化应用软件为分析工具进行关键词聚类分析和突现词分析,厘清中国政策量化的研究热点与趋势。
为了保证搜集的文献数据的精确度,将与检索条件有歧义的量化宽松政策排除在外,选择CNKI中政策量化研究相关文献进行分析。
在CNKI中以[篇名:政策(精确)]AND[篇名:量化(精确)]OR[篇名:政策定量(模糊)]NOT[篇名:宽松(精确)]为高级检索条件,勾选同义词扩展选项,检索并筛选出发表时间为2010年1月1日至2021年10月31日,且类型为“学术期刊”的583篇相关文献,以此为数据基础分析中国政策量化研究情况。
2.3 发文数量及变化趋势
在某领域中,学术论文的年度发文数量及变化情况,是一项能够充分体现该领域研究现状阶段和未来趋势的重要衡量指标[23],可以直观地看出该领域在特定时间段内的研究热度发展及趋势。因此,基于2010年以来政策量化研究相关文献的年度发文数量变化趋势可以直观地分析中国政策量化研究的热度变化趋势,统计结果如图3所示。由于数据收集时间的限制,2021年的政策量化文献收集不完全,因此研究热度趋势仅分析2010—2020年的数据分布情况。
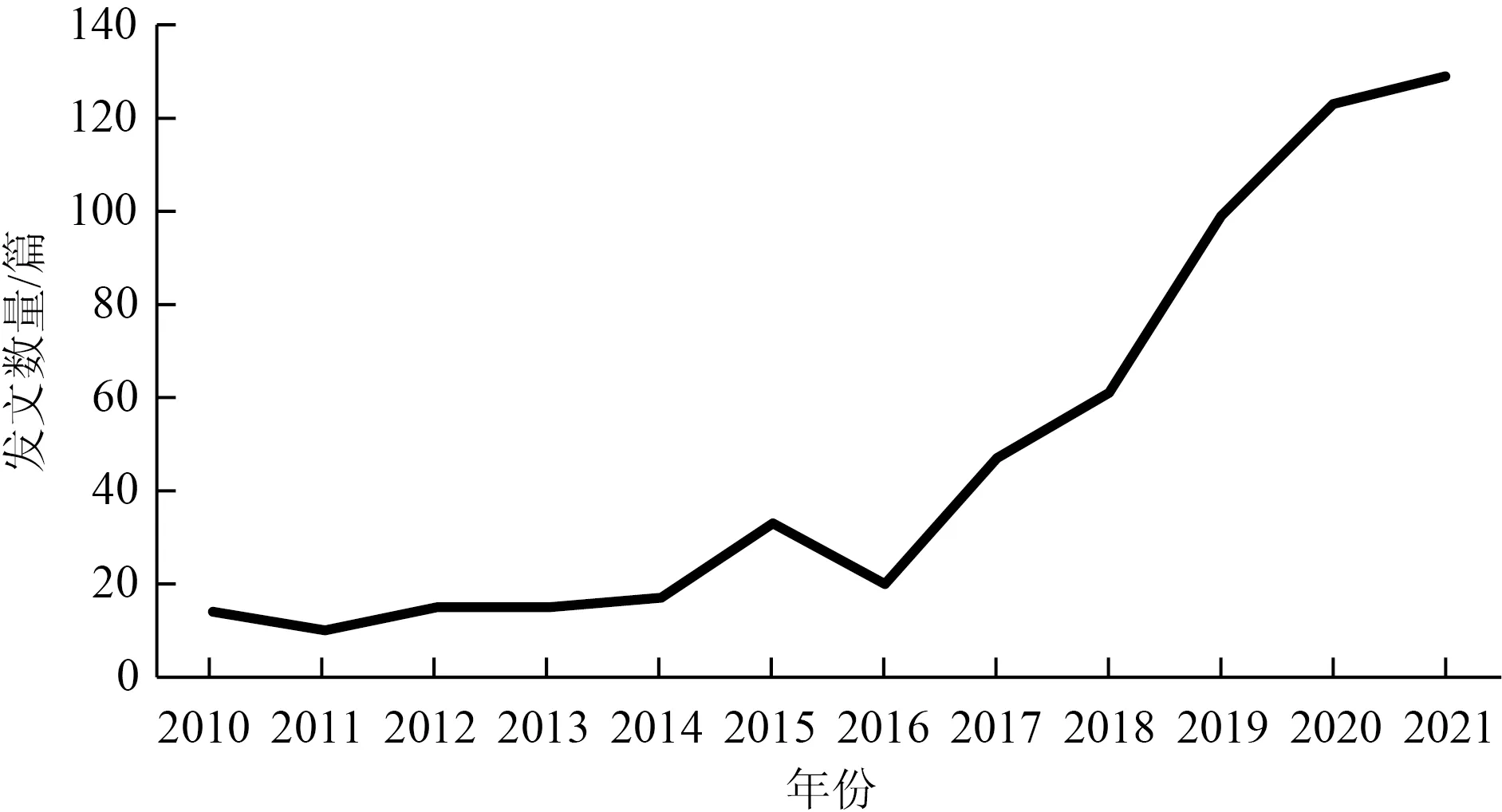
图3 年度发文数量分布
由图3可知,截至2020年底,国内政策量化研究的文献数量分布整体上呈现增长趋势。根据文献数量变化特征将国内政策量化研究从时间角度分为两个阶段。
第一阶段:2010—2016年,国内有关政策量化研究发文数量与2016年后的发文数量相比较少,增长速度缓慢,并在2015年出现一次高峰,整体上呈现缓慢波动增长的热度发展态势。表明该时期内的政策量化研究已经逐渐开始得到国内学术界的关注和研究,不仅将数学模型、金融、内容分析法、文献计量学等跨学科方法应用在政策分析中进行探索和实践[24],在政策量化维度方面也进行多样化的探索[25],奠定了政策量化研究的理论和基础。
第二阶段:2016年后,国内政策量化领域的文献数量急剧增加,研究热度呈现快速增长态势。表明该时期内的政策量化研究迅猛发展,相关研究主要基于发展成熟的政策量化维度和量化方法拓展政策量化的研究领域。
分析文献数量趋势线可知,2016年后,中国政策量化的研究热度增速显著。根据截至2021年的不完全统计,可以预测在2021年后国内有关政策量化的研究热度将仍具有显著的增长趋势。
2.4 研究热点分析
关键词是映射文献主题内容的术语或词汇,能够高度凝练文献的文本内容和研究主题[26],对于关键词进行分析可以有效实现对文献整体内容的分析,可以保证分析的有效性和高效性。因此,对文献的关键词进行聚类和主题总结可以直观地反映某领域的研究热点。
运用CiteSpace对关键词进行聚类分析,如图4所示。可以发现国内政策量化研究文献关键词聚类模块值Q=0.905 4(>0.3),聚类加权平均轮廓值S=0.986 2(>0.7),关键词共现图谱的聚类结构显著,聚类结果高效[27]。
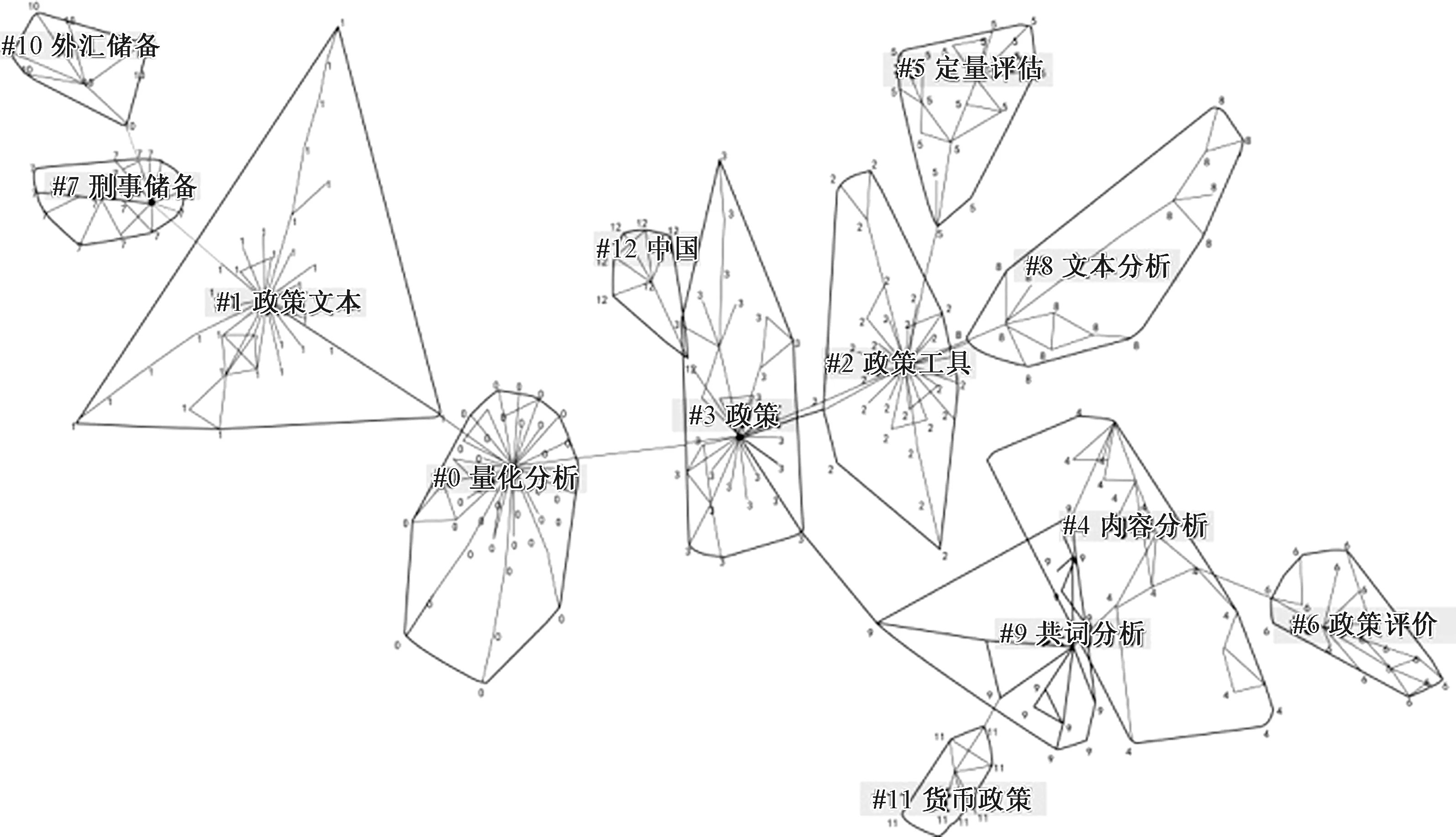
图4 文献关键词聚类
基于文献关键词聚类(图4)和通过对数极大似然率(log likelihood ratio,LLR)计算得出国内关键词聚类详情(表2)可以总结得出中国政策量化研究以“政策”为中心组成了3个研究热点主题。
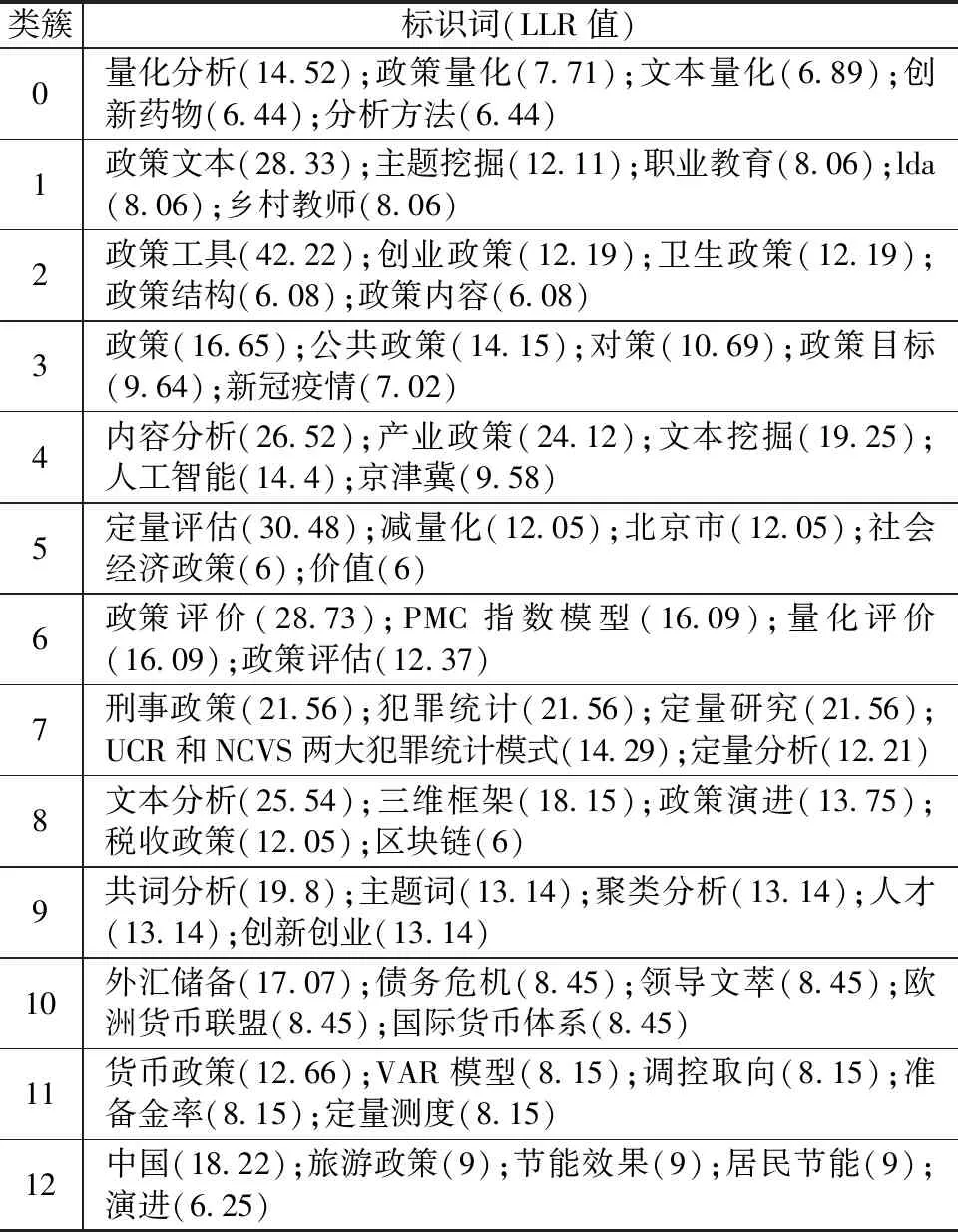
表2 关键词聚类
2.4.1 热点主题1:基于主题挖掘的政策文本语义量化分析
随着对非结构化数据的关注和计算机技术的发展,针对非结构化政策文本的主题挖掘研究得以展开,其中包括通过高频关键词的词频随时间的变化[28]和共现聚类[29]分析政策的主题及变迁。随着文本挖掘技术的不断发展,国内运用隐含狄利克雷分布(latent Dirichlet allocation,LDA)主题模型及参数对政策的主题内容[30]、主题强度演化[31]、主题关注度演化和主题认同度演化[32]进行量化分析。但LDA主题模型只考虑了政策文本中的主题词,缺少与政策文本相关联的其他数据信息对主题的贡献[33],因此基于LDA的扩展模型研究及应用成为国内政策主题量化研究的热点。
2.4.2 热点主题2:以政策工具为基础的多维框架政策文本分析
政策工具是政府达成政策目标的手段,也是政策的重要组成部分,依据文圆等[34]、毛超和岳奥博[35]、王国华和李文娟[36]的政策工具分类思路量化分析政策文本,分析政策工具的运用状况已成为国内研究的热点。随着政策科学的不断发展,国内研究不断地将政策时间、政策主体、政策目标、政策效力、政策发布形式、政策作用对象等多样的政策结构或分析要素与政策工具相结合,构建政策多维分析框架,分析政策工具与不同维度间的相互关系[37]。随着政策多维分析框架应用领域的不断拓展,国内研究在政策多维分析框架中加入具体领域政策中的专业化要素维度[38],不仅提高了领域政策研究的科学性,也提高了政策多维分析框架的适应性。
2.4.3 热点主题3:基于PMC指数模型的政策量化评价
政策内容制定的科学性和有效性关乎政策的最终执行的效果,因此为了帮助政策发布者判定政策产生的实际影响并针对政策存在的不足提出改进意见,国内研究基于政策高频词构建政策一致性指数模型(policy modeling consistency,PMC)的评价指标体系,对政策进行量化评价,并通过PMC曲面图可视化分析政策的改进方向[39]。目前,PMC指数模型被广泛应用于量化评价卫生、教育、旅游、养老、脱贫等与社会发展相关的民生领域政策[40]和数据开放、创新创业、能源、机器人产业、人工智能等具有时代特征的国家重点发展领域政策[41]。
经分析可知,在研究热点数据方面,中国主要集中于政策文本的分析研究,政策文件的发布部门、效力级别等外部属性数据、政策相关的截面数据等有待进一步的研究。在研究热点方法方面,主要采用以LDA主题模型、PMC指数模型及高频关键词共现聚类等为基础的智能文本分析技术,还需要进一步的丰富智能量化研究方法。在研究热点维度方面,国内研究对政策工具、政策主题和政策评价的维度较为关注,并通过多维分析框架实现多维交叉量化研究,但研究维度较为集中,仍需要进一步丰富研究维度。
2.5 研究前沿分析
突现词是指在特定的时间段内频次快速增长的词汇。关键词突现分析可以反映某领域中的研究前沿[42]。因此,对排名前十的关键词突现性分析结果进行综合研究,分析近年来的政策量化文献的研究前沿。
通过对国内文献前十个突现关键词(图5)分析,可以看出国内研究近四年突现强度较大的关键词主要包括政策分析、量化评价、政策评价和智慧城市,研究前沿主题主要包括政策量化评价和智慧城市相关政策量化研究。

图5 文献关键词突现(排名前十)
2.5.1 前沿主题1:政策量化评价研究
关键词“量化评价”的突现强度显著高于其他关键词,表明国内自2020年开始对政策量化评价的关注较高。国内学者早期运用内容分析法、共词分析法、层次分析法、PMC指数模型等从政策内容出发评价政策优劣,但均在不同程度上存在缺乏客观性、评价精度低、无法衡量政策评价指标间的关系等问题。随着学科交叉的发展,近年来国内研究将神经网络理论中的自编码(auto encoder,AE)技术引入PMC指数模型的得分计算过程中,构建PMC-AE指数模型。基于PMC-AE指数模型对政策进行量化评价可以更好地表征评价指标之间的关系,可以提高政策量化评价的科学性和合理性[43]。目前,PMC-AE指数模型已经开始被用于军民融合政策[44]、税收政策[45]、体教融合政策[46]研究。
2.5.2 前沿主题2:智慧城市相关政策量化研究
随着中国对智慧城市建设的关注与政策支持,以智慧城市相关的国家政策文件为研究对象进行量化分析的研究开始得到关注,不同的学者分别通过由政策区域分布、政策数量、政策主题、政策主体构建的四维分析框架[47],由政策数量、文本形式、发布部门、政策主题和政策工具构建的五维分析框架[48]和由政策内容、组织构架和政策效力构建的政策科学理论框架[35]下对政策文本进行量化分析,探索了政策的演进特征或演进阶段,并对未来的智慧城市政策制定提出相关建议。除此之外,杨凯瑞等[49-50]通过政策文本量化分析,分别对智慧城市建设的客体和影响因子进行研究。
经分析可知,前沿的研究方法仍以PMC模型为基础进行优化完善,需进一步地丰富政策量化理论基础与技术方法。在智慧城市领域的政策量化研究中,开始探索发展区域、组织架构、政策效力等具有领域专业化特征维度的研究。
3 结论与展望
3.1 结论
对2010年1月1日至2021年10月31日时间段内CNKI的政策量化相关文献进行了梳理,并根据政策文献发文数量趋势、关键词聚类和突现性分析,探讨了中国政策量化研究的热点与趋势。
1)中国有关政策量化的年度发文数量呈现两阶段增长趋势,2016年后研究热度具有显著的增长趋势,从侧面表明政策量化研究的重要性与意义,仍需进一步的探索研究。
2)中国政策量化研究以“政策”为中心组成了3个研究热点主题,分别是基于主题挖掘的政策文本语义量化分析、以政策工具为基础的多维框架政策文本分析以及基于PMC指数模型的政策量化评价,但研究数据、研究方法和研究维度仍需进一步丰富和完善。
3)研究前沿主题主要包括政策量化评价和智慧城市相关政策量化研究,但研究方法仍以PMC模型为基础进行优化完善,开始探索领域专业化特征维度研究。
3.2 展望
基于中国政策量化研究文献分析,国内现有研究已经取得了一定的成果,但仍存在进一步深化研究之处。
1)规范和丰富政策量化的研究数据。在研究数据获取方面,应进一步规范和建设政策数据库。在研究数据类型方面,国内目前大量研究主要对政策文本进行分析,应进一步结合相关结构化的数据,以进一步增强中国政策量化研究的客观性。
2)跨学科融合发展政策量化的研究方法。目前,国内在传统的文献计量法和内容分析法的基础上运用了文本挖掘领域中的相关技术。未来的研究可以引入人工智能等学科中的研究方法,也可以将政策量化结果应用于其他学科的影响因素研究中。
3)探索专业化政策量化的研究维度。基于政策多维分析框架的量化分析仍将是中国未来一段时间内政策量化研究的热点。未来应根据各领域的活动或工作特点设计专业化的维度,有助于丰富多维分析框架,使政策量化的分析结果的合理化、专业化和科学化。
本文主要以中文期刊文献为研究对象,未来可以进一步扩大文献的分析范围,并结合其他文本挖掘技术,丰富政策量化研究进展与趋势的内容。
猜你喜欢
房地产导刊(2022年8期)2022-10-09
房地产导刊(2022年6期)2022-06-16
速读·下旬(2021年11期)2021-10-12
非公有制企业党建(2020年2期)2020-03-08
华人时刊(2019年21期)2019-11-17
制造技术与机床(2019年10期)2019-10-26
大东方(2019年12期)2019-10-20
电子制作(2018年18期)2018-11-14
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
