
基于改进原型网络的小样本古生物化石识别研究
2023-10-07 07:51陈杰何月顺熊凌龙钟海龙张朝锋庞振宇
地质论评 2023年5期
陈杰,何月顺,熊凌龙,钟海龙,张朝锋,庞振宇
1)东华理工大学信息工程学院,南昌,330013;2)江西省放射性地学大数据技术工程实验室,南昌,330013
内容提要:传统古生物化石鉴定方法多依赖于古生物学家的经验知识,现有的人工智能识别方法需要大量的化石训练样本才能达到较高的准确率。为解决上述问题,在少量化石图像样本情况下准确识别化石,笔者等尝试使用残差网络和注意力模块相结合的方法,并将其运用于小样本的化石鉴定。首先以残差网络作为模型的特征提取模块,并在残差网络的残差块中嵌入CBAM卷积注意力模块,提高模型对于化石纹理特征的关注,以提取更为全面的深层次化石图像特征,再使用小样本度量学习中的原型网络对提取特征进行原型计算,最后通过多轮次迭代训练得出最佳的化石判别模型。使用本文方法与5种经典的小样本学习方法进行对比实验,实验结果表明本文方法的识别准确率最高,在样本数量为1和5的情况下,准确率达到了86.32%和94.21%,对稀缺样本下的化石识别具有更显著的优势。
对于古生物化石的鉴定一直都是古生物学中的重要内容,古生物学家可以通过对化石的鉴定和地层比较来了解地球的演化历史,从而对物种的演化关系提供强有力的理论支持,如Song Haijun等(2023)在《Science》杂志上发表的研究成果就是通过对特定化石组合的鉴定,发现了距离地球历史最大一次生物灭绝事件:二叠纪—三叠纪之交生物大灭绝仅过去了一百万年的时间,这一重大发现为我们理解最大规模灭绝之后的生命恢复速度和模式提供了新的认识。但是传统的古生物系统分类对人类专家的依赖性很强,对专业知识和长时间的经验积累要求很高(任伟等,2020),在实际的化石鉴定工作中,科研人员的主观因素在很大程度上决定了鉴定结果。而人工智能技术具有高效性和客观性,可以避免传统方法鉴定过程中的主观因素干扰,并极大提高化石鉴定的精度和可信度。通过利用人工智能技术对古生物化石进行鉴定,我们能够深入挖掘其地层古生物学意义,为我们理解古生态环境和生物演化提供全新的视角和认识。
近年来,随着机器学习、深度学习技术的不断发展,带动了人工智能技术在不同领域的应用,这期间,大数据与人工智能算法的引入使地球科学实现跨越式发展(周永章等,2021),并正在改变地质学(曹蒙等,2023; 谢玉芝等,2023),越来越多的科研工作者使用计算机视觉技术在化石鉴定领域上进行方法的创新。采用机器学习方法,将化石的尺寸,颜色,纹理等形态特征送入到机器学习模型中进行学习迭代,可以实现化石快速分类。黄铮等(2009)使用非线性方法来解析牙形化石中重要且复杂的特征,并以反向传播算法来构建分类模型,取得了80%左右的准确率,但构建非线性的特征解析方法需要依赖专家的经验知识。张涛等(2019)以方向梯度直方图(Histograms of Oriented Gradient,HOG)来提取微体化石形态的特征描述因子作为主要特征向量,并在支持向量机(Support Vector Machine,SVM)的基础上设计了一种二叉树型多分类器,取得了较高的识别准确率,但模型训练使用了1500多张高质量的图像样本进行训练。
采用深度学习方法,将化石图像输入进卷积神经网络(Convolutional Neural Networks,CNN)中进行特征提取,通过不断学习迭代更新权重参数获得最佳的识别效果。Rehn等(2019)采用U-Net和VGG两种卷积神经网络对木炭化石进行识别,在经过1600多张图片样本的训练后,两个网络模型均取得了不错的准确率。余晓露等(2021)提出了一种基于残差神经网络的碳酸盐岩生物化石显微图像的识别方法,通过不断的迭代训练实现了对薄片图像中生物化石的自动识别,识别准确率达到了86%,但模型的训练样本集数量是通过数据增强的手段扩展到1645张,原始的碳酸盐岩生物化石数据集仅为327张。Song Haijun等(2020)实现了4个经典的深度卷积神经网络来解决从微相中识别化石这一复杂繁琐的任务,在实验过程中获得了高达95%测试准确率,但使用的数据集包括了1133篇参考文献的公共数据和22个化石以及非生物颗粒组的30815张图像。在立体显微镜下手动识别有孔虫形态物种对于微体学家来说是耗时的,为了让识别过程自动化,Ross(2020)等使用卷积神经网络作为分类器来对有孔虫图像进行自动分类,其最佳精度达到了90%左右,但分类器的构建是在公开可用的超过34000张图像的大型有孔虫数据集Endless Forams(Hsiang et al., 2019)上进行的。安玉训等(2022)设计了一种分层次识别模型,即先采用Faster R-CNN算法对介形类化石进行定位和检测,再使用InceptionV3和SVM的结合分类模型对介形类化石进行分类,模型的总体准确率达到了95%,但每一类化石的识别效果并不均衡,样本数量多的东营介属类化石识别准确率最高,样本数量少的瓜星介化石识别准确率最差。Wang Haizhou等(2022)设计了一种转置卷积神经网络(Transpose Convolutional Neural Network,TCNN),在网络结构中添加了一层上采样的卷积层,将该层所提取的特征图与其他卷积层特征进行融合,以充分混合由神经网络提取化石图像的大小尺度特征,该模型的识别准确率在90%以上,能够实现对腕足化石的准确识别,但训练集样本数量少于100张时,模型并不能很好的提取到准确的化石图像特征。
虽然,上述研究在化石识别上都取得了较为满意的成果,但它们都将着重点放在了如何提高模型的识别准确率上,而忽略了化石样本的本身的稀缺性。在大量的数据下,人工智能技术能够在图像识别上表现出很好的效果,但古生物化石样本由于时间久远和样本难以保存等原因,大量的训练样本是较难获取的,一旦训练样本数量减少,模型的分类精度将大打折扣,这显然无法普遍应用于挖掘大量的稀有化石样本。基于上述情况,为了实现在少量化石样本的情况下达到较高的准确率,笔者等尝试了一种结合小样本学习(Few-Shot-learning)技术和残差网络技术的古生物化石识别方法,通过小样本学习中的度量学习技术建立识别模型,并对残差神经网络进行改进,在少量化石训练样本的情况下,采用原型网络(Prototype Network)度量分类的方式进行化石类别的判定,同时在特征提取模块上引入了残差网络和卷积注意力机制来增强模型的特征提取能力,以提高模型的识别准确率。
1 古生物化石识别模型
1.1 原型网络
原型网络以原型理论为基础,认为一个概念可以抽象出一个原型,并用该原型来表示这个概念(Snell et al., 2017)。原型网络通过特征提取模块将支持集中的所有样本提取的图像特征投影到一个较低维的嵌入空间中,然后计算该类别的原型。原型Ck的计算如公式(1)所示:
(1)
Sk表示支持集中类别的样本集,fφ表示将图像特征映射到嵌入空间的特征提取模块。计算出原型后,原型网络使用给定的距离函数d计算查询点与各原型的距离,再使用分类函数计算查询集样本所属类别的概率,从而确定分类,其示意图如图1所示。
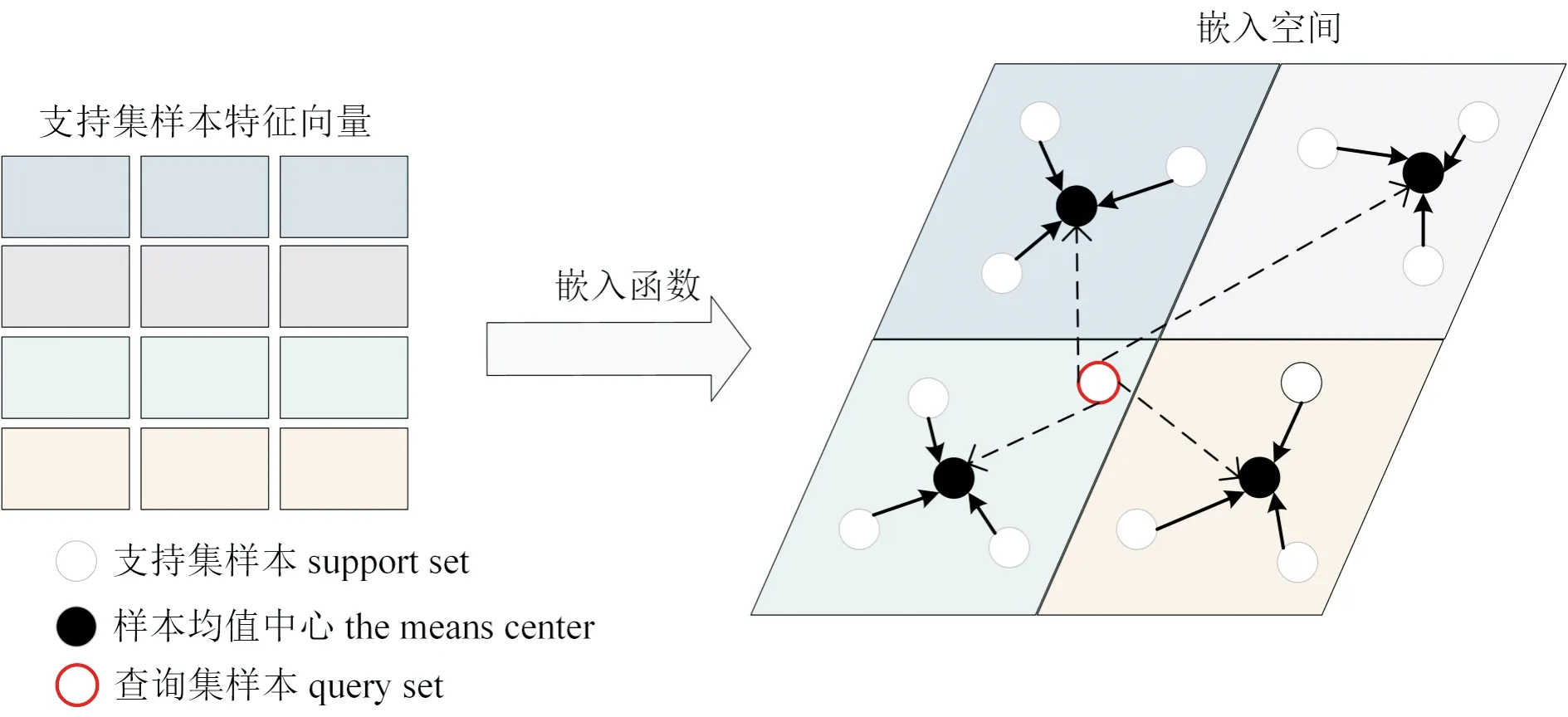
图1 原型网络判断类别过程示意图(据Snell et al., 2017)Fig.1 The process of judging categories (from Snell et al., 2017)
1.2 卷积注意力机制
CBAM(Convolutional Block Attention Module)是一种轻型注意力模块,可以在通道和空间维度上进行注意力计算(Woo et al., 2018)。CBAM的结构图如图2所示。CBAM包含两个子模块,通道注意模块(Channel Attention Module,CAM)和空间注意模块(Spatial Attention Module,SAM),用于计算通道和空间上的注意力权重。
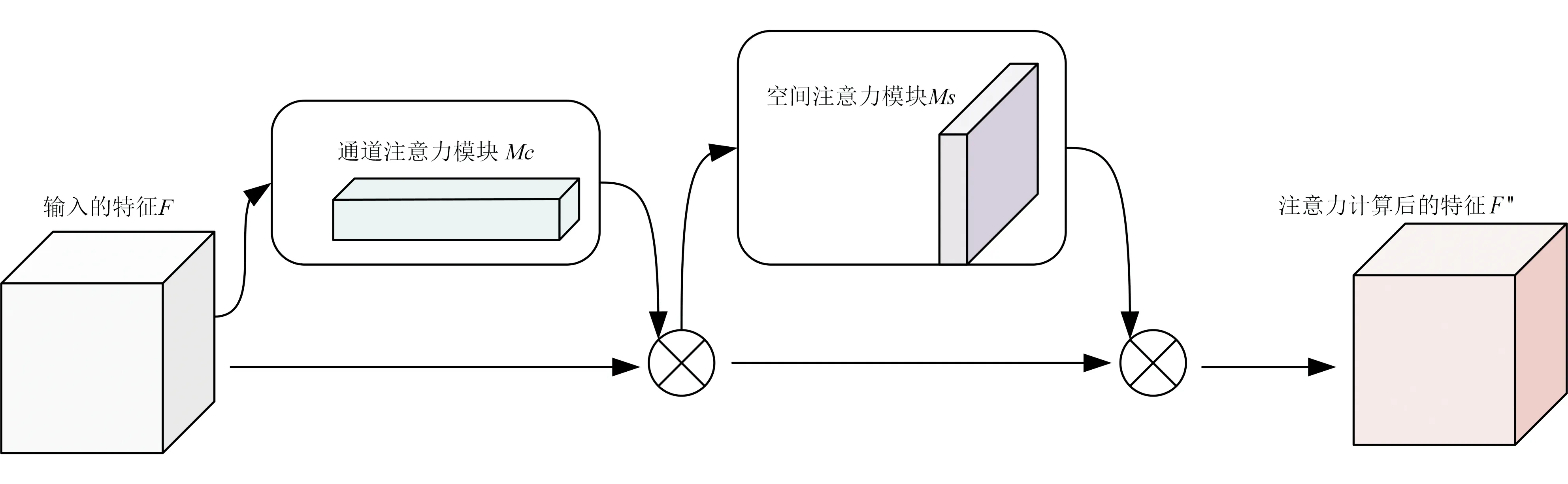
图2 CBAM模块架构(据Woo et al., 2018)Fig.2 Convolutional Block Attention Modulestructure(from to Woo et al., 2018)
从图2可知,以卷积神经网络提取的特征图F为输入,进行CBAM操作,可以获得一个一维通道注意力特征图Mc和一个二维空间注意力特征图Ms。 整个注意力计算过程可以概括为:
F′=Mc(F)❋F
(2)
F″=Mc(F′)❋F′
(3)
符号❋表示乘以元素,F′表示通过通道注意获得的新特征,用作空间注意的输入,最后,得到整个CBAM模块输出的特征F″。
1.3 改进CBAM—ResNet
在小样本度量学习的众多模型中,可以将模型的组成部分大致分为特征提取和相似度度量两大模块,其中特征提取模块的性能可以较大程度影响到整个模型的准确率。而笔者等采集的化石图像具有较大的类内样本差异,且包含丰富的纹理、颜色和形态特征。使用常规的浅层卷积神经网络并不能很好的捕捉化石图像的深层次细节特征,使用深层的卷积神经网络会有较大概率出现过拟合的问题,故笔者等采用ResNet-12浅层残差神经网络作为模型的主干网络。残差神经网络是在2016年由He Kaiming等(2016)提出,该网络引入了跳跃连接,使得前馈神经网络部分可以更深,从而收敛速度更快,可以有效解决在计算梯度的过程中存在的梯度爆炸或梯度消失等问题。其结构图如图3所示:
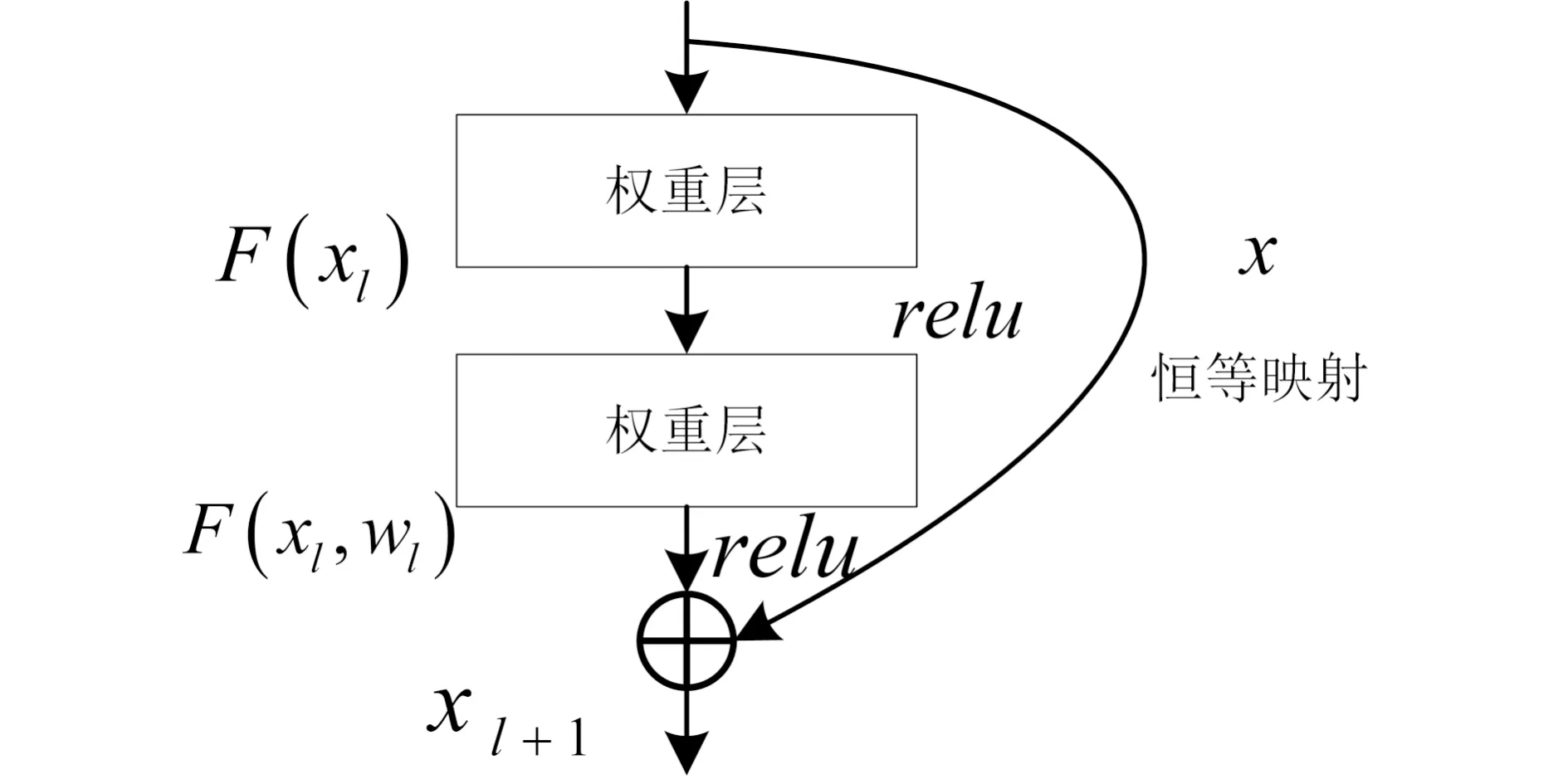
图3 残差单元结构(据He Kaiming et al., 2016)Fig.3 The structure of residual block (from He Kaiming et al., 2016&)
化石图像中的纹理特征多存在于图像的通道信息中,颜色形态特征多存在于空间信息中,为了进一步的提取化石图像的空间—通道信息,将CBAM注意力模块融合进残差网络中,借助CAM(通道注意力模块)和SAM(空间注意力模块)两个子模块的能力,改进后的网络能够捕捉到图像在通道和空间上的特征,从而对化石的纹理特征更为敏感。通道注意力和空间注意力的结构图如下图4和图5所示。
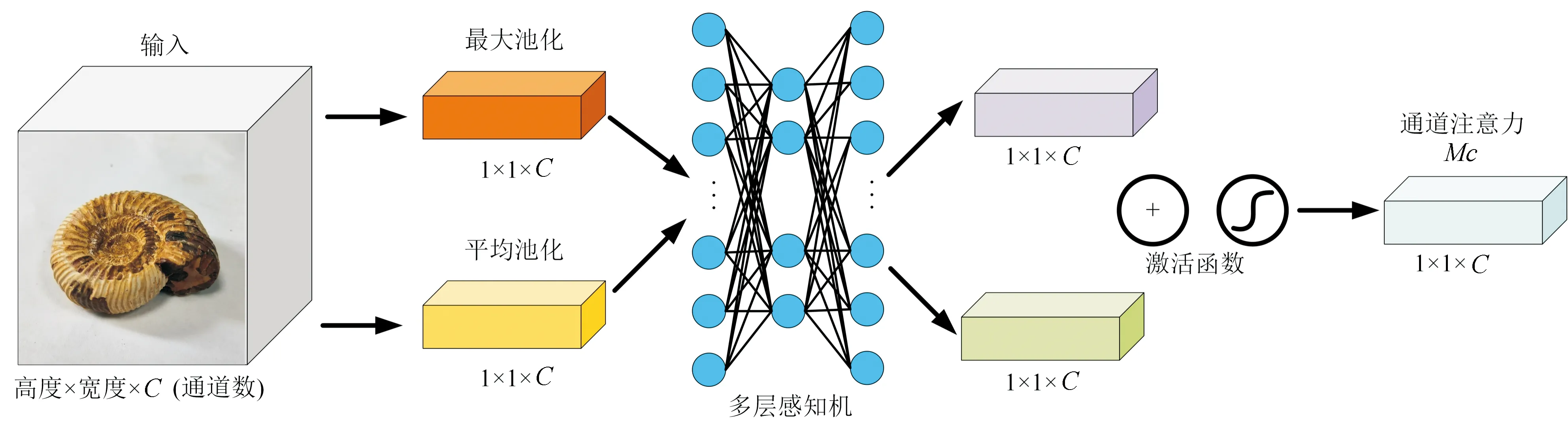
图4 通道注意力模块结构图(据Woo et al., 2018)Fig.4 Structure of channel attention module (from Woo et al., 2018)
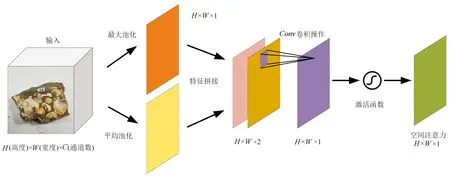
图5 空间注意力模块结构图(据Woo et al., 2018)Fig.5 Structure of sptial attention module (from Woo et al., 2018)
在CAM模块中,输入的化石图像特征维度为高度×宽度×通道数,特征会经过最大池化层和平均池化层得到化石图像在两个通道的描述,其中平均池化层可以对通道特征进行有效压缩,而最大池化层可以根据最大值保留的特性对目标在通道上的特征进行收集,随后将池化的特征图送入到由全连接层组成的多层感知机中进行权重计算和更新,再对多层感知机产出的特征结果进行对位相乘并求和,将求和结果经由Sigmod激活函数进行非线性激活,从而输出通道注意力特征图。通道注意力特征图的计算过程如下公式(4)所示:
Mc(F)=σsigmod{MLP[AvgPool(F)]+
MLP[MaxPool(F)]}
(4)
式中:F为图像特征;MLP多层感知机;Avgpool为平均池化操作;MaxPool为最大池化操作。
在SAM模块中,会对CAM所产出的通道注意力特征图进行空间特征信息的提取,以提高网络对于化石纹理等图像特征的提取能力,加强其在图像细节部分的关注和学习。CAM模块将通道注意力特征图送入到最大池化层和平均池化层进行特征的拼接,再进入到一层卷积层中进行特征的提取,由于在CAM模块中通过多层感知机进行了权重的更新优化,此时SAM模块进行卷积提取的特征会更加符合化石图像的本质特征,最后由激活函数进行非线性变换得到注意力特征图。SAM的计算过程如公式(5)所示:
Ms(F′)=σsigmod{f[AvgPool(F′)];
[MaxPool(F′)]}
(5)
式中:F′为通道注意力模块输入的特征图;f为进行的卷积运算。
在整个CBAM注意力模块中,CAM子模块和SAM子模块呈现串联结构,先进行CAM操作再进行SAM操作,SAM为CAM进行补充,让网络提取的特征更为全面。结合所采集的化石图像特点,笔者等将CBAM模块嵌入到残差网络的每一个残差块中,而不是将其放在残差网络的开始与结尾这两个部分,若在开始和结尾两部分嵌入CBAM模块,这会让CBAM模块的参与度减少,从而忽略中间残差部分的特征提取,而将其嵌入到每一个残差块中则可以让残差网络对CBAM模块计算后的特征图也进行残差计算,有助于提取化石图像更深层次的特征,故笔者等所提出融合卷积注意力机制的改进残差网络CBAM—ResNet结构如图6所示,该网络结构由4层嵌入CBAM注意力的残差层和一层全局平均池化层组成。其中每一个残差块由3层卷积核为3×3的卷积层、3层标准归一化层、一层最大池化层、两个ReLu激活函数和CBAM卷积注意力模块组成。损失函数采用交叉熵损失函数。
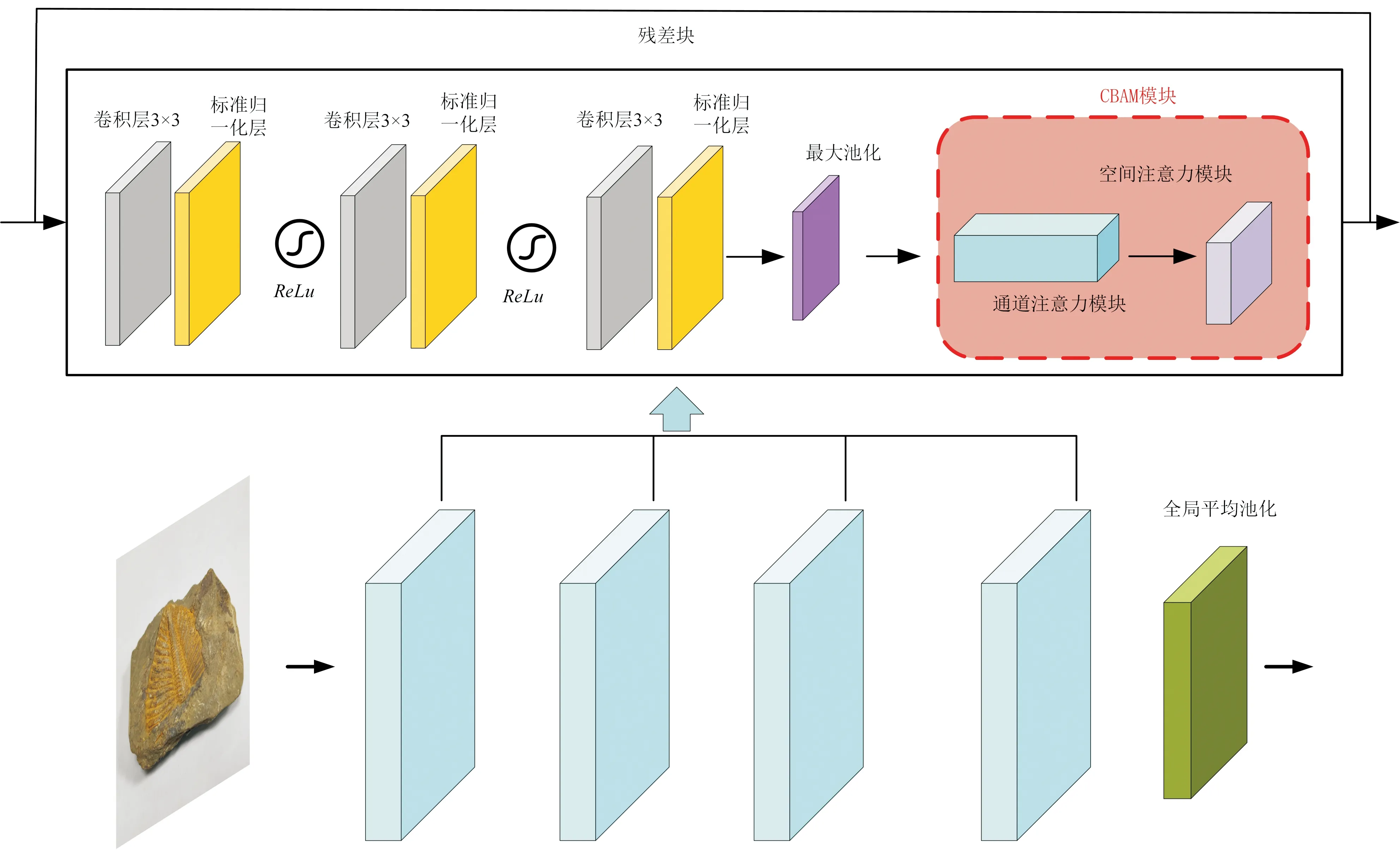
图6 CBAM—ResNet网络结构图Fig.6 CBAM—ResNet structure
1.4 识别流程
本文模型的训练过程是以元任务形式展开的,每一个元任务的样本数量为N(S+Q)个,其中N为元任务的分类数量,S为支持集的样本数量,Q为查询集的样本数量。除了用于训练的样本,元任务中还包含特征提取模块F,即改进后的残差神经网络CBAM—ResNet,用欧氏距离计算查询样本与原型之间距离的度量模块M。
在元任务的训练过程中,特征提取模块会同时对支持集的样本和查询集的样本进行特征提取,特征提取的过程如下:①首先,化石图像进入到一层卷积层中进行维度降低。② 然后将第一层卷积提取的特征图送入到标准归一化层中进行数据归一化处理,在卷积层后进行标准归一化处理可以减少模型对于在训练过程中对于上层输入的依赖,从而提高模型的鲁棒性。归一化的计算过程如公式(6)所示:
(6)
式中:E(x)为所输入的数据均值;Var为方差计算;y为归一化后的结果。③ 将归一化后的特征图送入到融合CBAM模块的改进残差神经网络部分中进一步提取化石图像中更加细节更加全面的特征。④将改进残差块(Residual Block)产出的特征图经由一层全局平均池化层进行特征过滤与降维,并将特征向量展开。
通过改进残差网络提取到支持集样本和查询集样本的特征向量后,会先将支持集样本的特征向量映射至嵌入空间中,计算每一类别的均值中心以形成每一类别的原型,再将查询集样本的特征向量映射至嵌入空间中,由度量模块计算查询集样本与各类别的相似性,给出查询集样本所属类别的概率。通过多轮次的不断重复上述的类别判断过程,在训练中对网络模型的权重参数进行优化,各类别支持集的样本的特征向量被映射到嵌入空间的位置会更加聚集,可以计算得出更加准确的类别均值中心,形成较为合理的类别原型,进而做到较为准确的类别判断。整个识别方法的流程如图7所示。
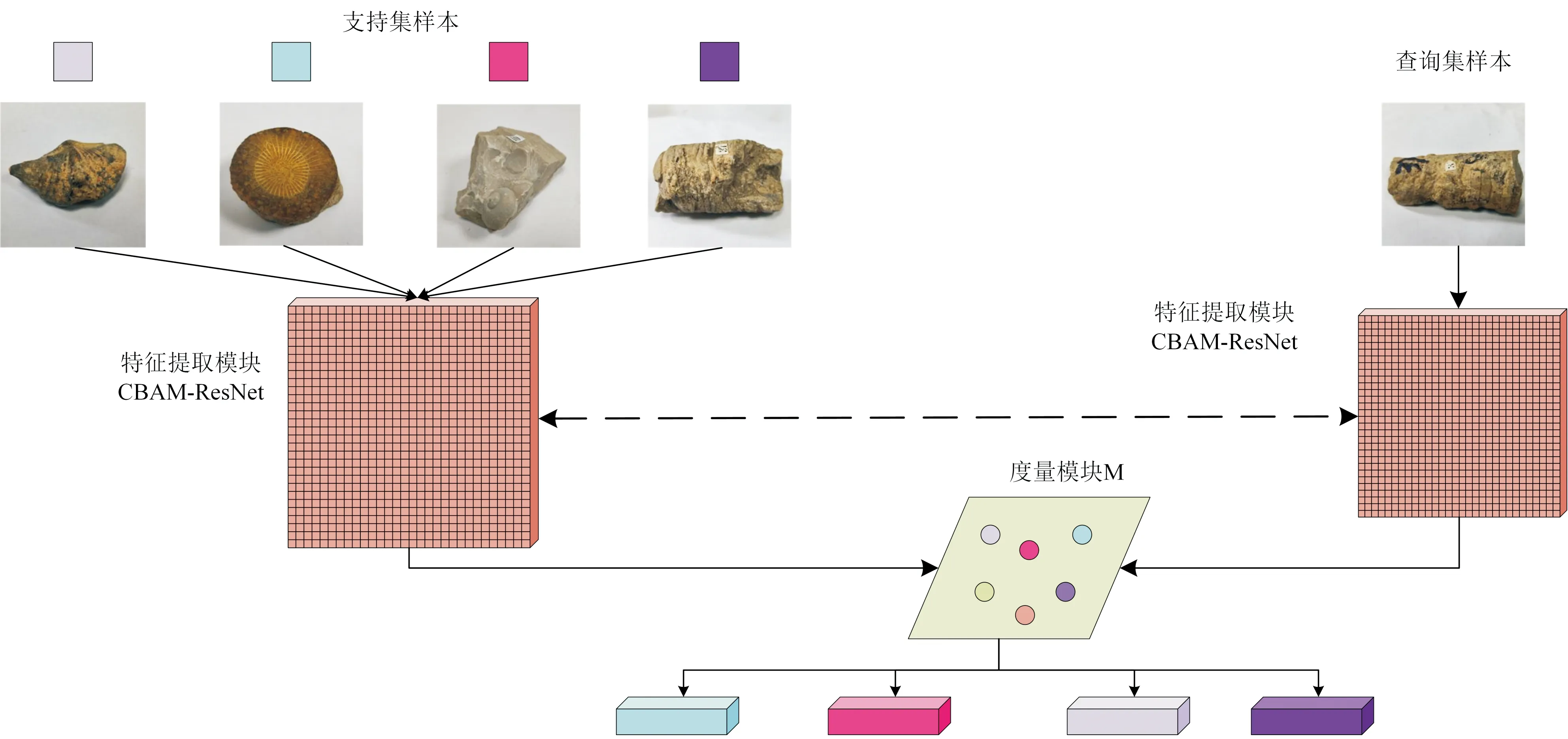
图7 本文模型识别流程示意Fig.7 Flow chart of theproposed method in this paper
2 古生物化石数据集及预处理
2.1 数据采集
笔者等对东华理工大学地质博物馆中所收藏的化石标本进行采集。共采集角石、菊石、三叶虫、鹦鹉螺、双壳纲、腹足纲、植物、腕足纲等17种不同类别纲目的化石图像样本,合计417张图片。采集的化石样本部分实例如图8所示。
所采集数据集详细信息如表1所示。
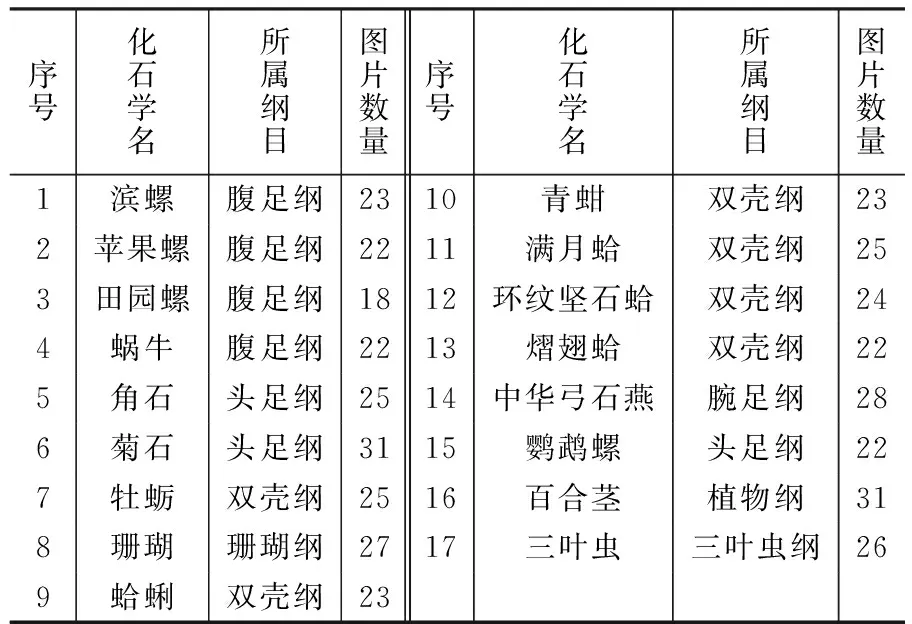
表1 化石数据集详情Table 1 Details of fossil data sets
2.2 数据预处理
所采集的化石数据集中,各分类的图片数量并不一致,且417张图片不能很好完成一个小样本分类模型的实验。为了让采集的图像质量更高以及扩充数据集数量,采用提取目标中心和图像翻转两种数据增强方法对数据集进行预处理。
2.2.1提取化石目标
化石图像的背景区域较多,以及化石图像中存在的其他干扰因素会影响到特征提取网络对化石特征的有效提取,从而较低模型识别准确率。为减少背景区域,采用裁剪等方式提取图像中化石目标。提取前后的效果图如图9所示。
2.2.2数据增强
为了让每一个化石类别的图片数量一致,采用随机向左向右旋转90°、旋转180°以及高斯滤波等方式从各类别化石图片中随机抽取若干张图片进行操作,将每一类别的图像数量在原有基础上增加若干张图片,其中翻转图像的效果图10所示。通过上述的数据增强方法后,原有的数据集数量增加为510张图片,且每一类图片数量都在30张。各类别化石图像数量的一致有利于小样本分类模型的训练。
3 实验结果与分析
3.1 实验配置
实验所采用配置如下:实验平台为Windows11,64位操作系统;CPU为i7-9900k;GPU为NVIDA Geforce GTX3080Ti,12GB显存;计算机运行内存为32GB。CUDA版本为11.1;Python版本为3.8;Pytorch版本为1.7。实验所用代码参考了开源的小样本学习算法库LibFewShot (Li Wenbin et al, 2021),该算法库是一个主要用于小样本学习的综合算法库。其中以统一框架集成了多种经典的小样本学习方法,包含4种基于微调的方法,6种基于元学习的方法,以及8种基于度量学习的方法。其代码简洁,结构明了,适合计算机基础较为薄弱的的地质工作者使用。
3.2 评价指标
笔者等采用准确率(Accarcy,Acc)作为模型性能的评价标准,准确率的计算过程如公式(7)所示:
(7)
式中:真正例(True Positive,TP)表示预测为正类且实际为正类的样本数,真反例(True Negative,TN)表示预测为负类且实际为负类的样本数,TP+TN为正确预测的样本数;total为总样本数。准确率可以很直观的表现出模型对化石图像判断正确的比例,可以评判模型的总体性能。
3.3 实验设定
以生物性状差异的程度和亲缘关系的远近为依据,可以将不同的生物加以分门别类。古生物学家将生物化石依次分为:界、门、纲、目、科、属、种7个等级。笔者等所采集的的17种化石材料分布在头足纲、腹足纲、双壳纲、珊瑚纲、植物纲、腕足纲、三叶虫纲这7种纲上,但每一种纲下的属级化石数量不一致,在实验过程中,随机抽取的属级化石很有可能会同属于一个纲,从而影响实验结果。为了证明笔者所尝试的方法有效,笔者等以纲这个大类等级来划分数据集,在上述每种纲级化石中只随机抽取一个子类进行实验,从而形成分类等级一致的包含7种纲的“纲”级实验数据集,并按照3∶1∶1的比例将化石样本划分成训练集、测试集、验证集。
整个模型训练过程由50个训练轮次组成,每一个轮次包含100个元任务,每一个元任务从训练集样本中随机抽取N个化石纲,每个纲随机抽取S个样本作为支持集,再从每个纲剩下的样本中随机抽取Q个样本组成查询集。其中N、S、K的值会根据实验内容作出相应变化。图像大小为224×224像素,通道数为3。
3.4 模型性能表现
为了解模型的性能表现,使用包含7个纲的“纲”级实验数据集进行模型训练。在化石纲数为5,支持集样本数为1和5这两种参数设置中,将每一个训练轮次中所有元任务的平均准确率(Acc)进行记录,并绘制成曲线图,具体情况如图11所示:
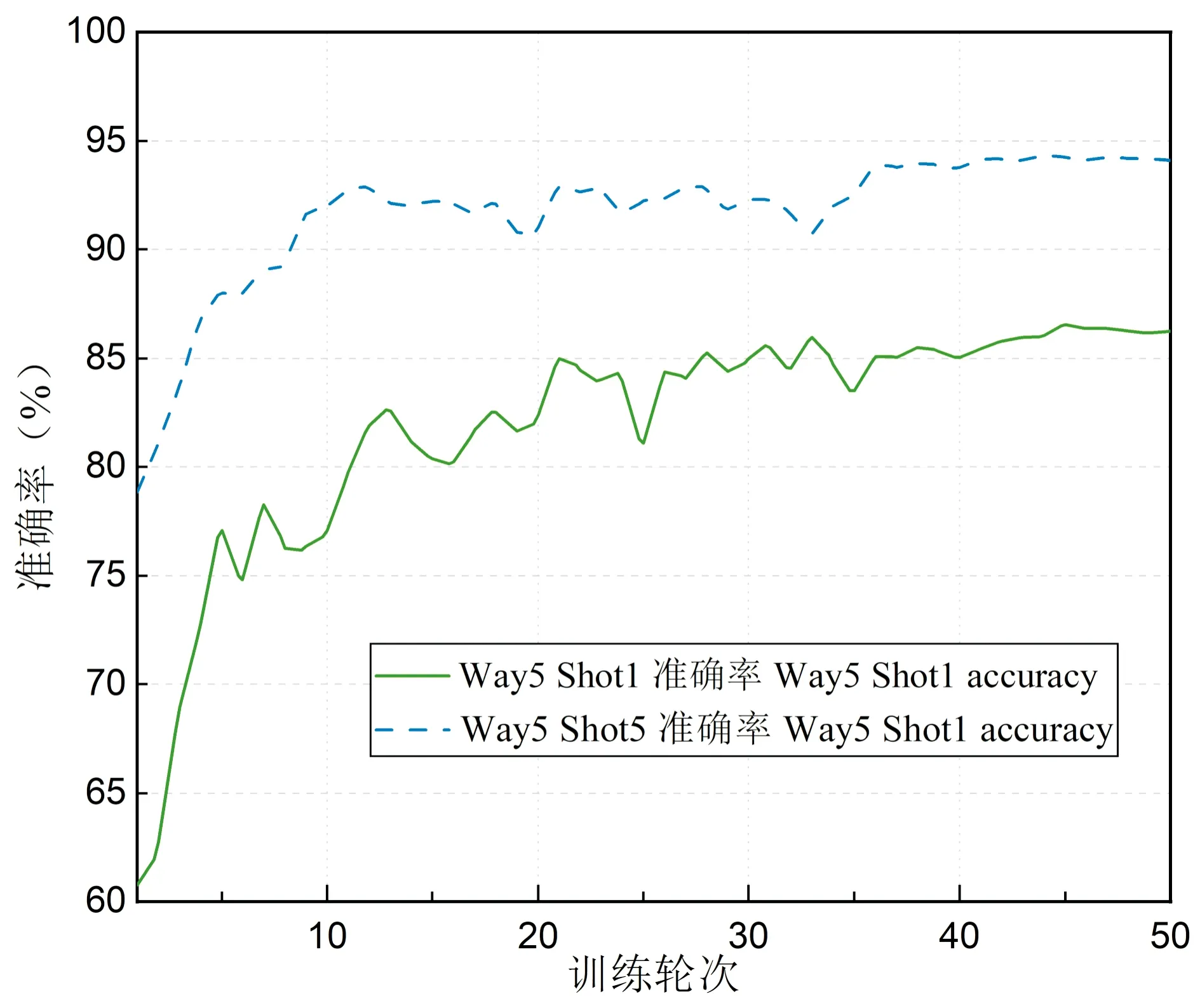
图11 模型准确率曲线图Fig.11 The Acc curve of the proposed model
通过图11可以了解到,支持集样本数量为1时的模型初始准确率为60.78%,最终准确率为86.24%,整个训练过程准确率的变化程度较大;支持样本数量为5的模型初始准确率为78.84%,最终准确率为94.21%,准确率的起伏波动不多,较为平稳。虽然样本数量对模型的性能有较大影响,但无论是在Way5 Shot1的情况下还是Way5 Shot5的情况下(其中Way代表化石纲的数量,Shot代表支持集样本数),模型的损失值都在逐步减少并下降至一个稳定值,而模型的准确率在稳步上升至一个较为满意的值,这说明该模型的性能正在不断地被优化,能够较好的开展化石识别任务。
3.5 消融实验分析
为研究卷积注意力模块CBAM和残差块对模型的性能提升,使用上述实验数据集,在“纲”这一化石分类等级中,展开消融实验。实验结果如表2所示。
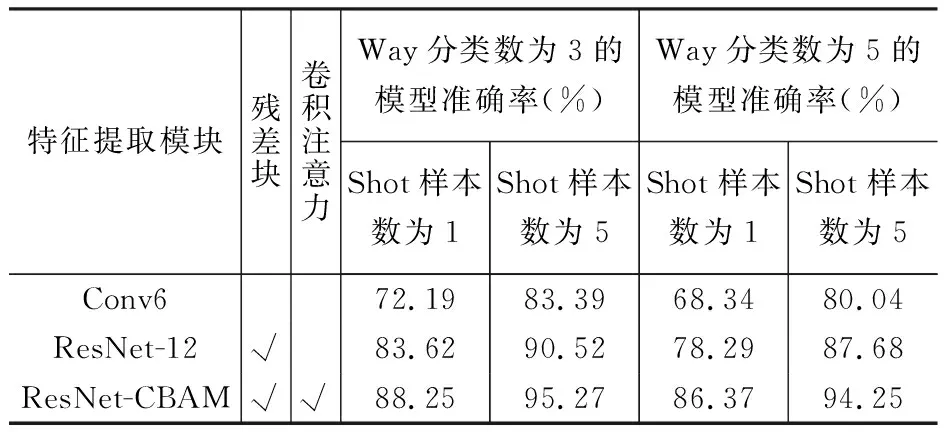
表2 消融实验结果Table 2 Results of ablation experiments
由表2可知,使用带有残差块的ResNet-12网络作为特征提取模块会比使用传统卷积神经网络Conv6的识别效果更佳,在化石纲数为3样本数为1时,嵌入ResNet-12网络的模型识别准确率相较于嵌入Conv4网络的模型高出11.43%。这说明在化石识别任务中,带有残差块的残差网络对于化石特征更加敏感,特征提取能力更强,嵌入残差块可以提高模型的识别准确率。在残差网络中嵌入卷积注意力模块CBAM的模型识别准确率最高,在化石纲数为5样本数为5的参数设置下,准确率达到了94.25%,比未嵌入CBAM模块的模型高出了6.57%,这说明嵌入卷积注意力模块进一步提高了模型的识别准确率,残差块和注意力模块的嵌入都对模型准确率的提升有促进作用。
3.6 对比实验分析
对比实验是将新的方法技术与已有模型进行比较。而已有的基准模型通常是在该领域中已经被广泛接受的、经过验证的模型或方法。通过与基准模型进行对比,可以评估新方法的性能改进或突破。使用“纲”级数据集,在纲数为5,样本数量Shot为1和5这两种参数设定的情况下,将本文模型与SiameseNet(Koch et al., 2015)、MatchingNet(Vinyals et al., 2016))、 RelationNet(Sung et al., 2018)这3种基于相似度计算的经典小样本学习模型和MAML(Finn et al., 2017)、Meta-Baseline(陈胤伯等,2020)这2种其他小样本学习模型进行性能对比测试。具体的实验结果如表3 所示。
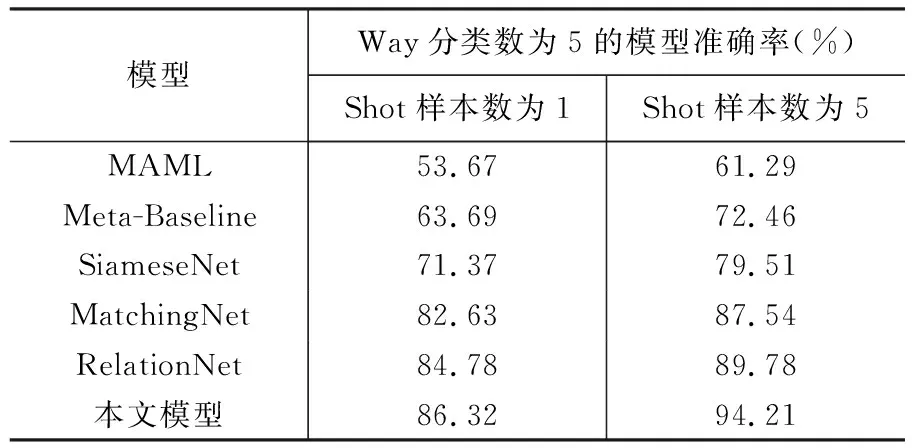
表3 各模型在“纲”级化石数据集上的Acc值Table 3 Acc value comparison of different methods on fossil data set of order level
从表3可以看出,在“纲”级数据集中,本文模型的准确率远高于MAML和Meta-Baseline这两种模型,与SiameseNet、MatchingNet和RelationNet这三种经典的小样本度量学习模型相比,在支持集数量为1的情况下,准确率分别高出14.95%、3.69%、1.54%,在支持集数量为5的情况下,准确率分别高出14.7%、6.67%、4.43%。而在“属”级数据集中,本文模型的识别准确率在样本数为1和5这两种设定下分别达到了89.27%和95.64%,在所有对比模型中表现最佳。
为了进一步评价本文模型在化石识别任务中的有效性,可以在现有的“纲”级实验数据集基础上,引入更高级别的分类等级进行对比实验。具体而言,就是把原始数据集中双壳纲包含的熠翅蛤、牡蛎等6个属级化石进行抽取,形成“属”这一分类等级的实验数据集,然后使用相同的模型进行对比实验,以验证本文模型在化石识别任务中的有效性。通过比较模型在“纲”级和“属”级数据集上的表现,可以评估模型在更具挑战性和精细化的分类任务中的准确性。“属”级数据集的具体实验结果如表4所示。
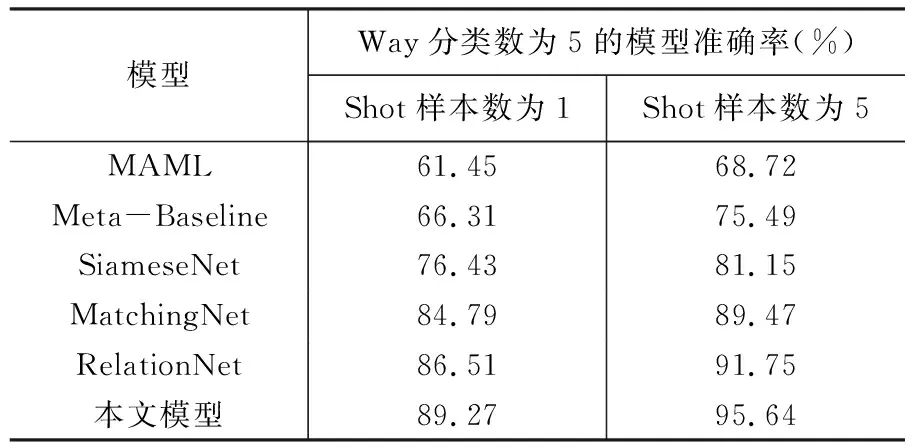
表4 各模型在“属”级化石数据集上的Acc值Table 4 Acc value comparison of different methods on fossil data set of genus level
从表4可以看出,在“属”级数据集中,本文模型的识别性能在所有对比的小样本模型中依然是最佳的,在支持集数量为1和5的情况下,准确率分别达到了89.27%和95.64%,比其它小样本学习模型都有显著的提升。与“纲”级数据集的实验结果相对比,可以看出本文模型在“属”级实验数据集的识别效果会比在“纲”级数据集的识别效果更好,且所有模型的整体准确率都有提升。但这并不能说明本文模型的泛化能力较强,这是因为“属”级实验数据集中属的数量为6,比“纲”级数据集的分类数量少,准确率的提升是由于类别数量的下降,要证实本文模型的泛化能力还需要进一步扩充实验数据集,这也反映出笔者等所采集的数据集不够全面,模型的泛化能力有待进一步增强。
损失函数的绘制可以提供对模型性能的可解释性和可沟通性。通过损失曲线图表,可以直观地展示模型的训练过程和性能表现。对各模型在“纲”级数据集训练的损失值进行记录并绘制成曲线图,具体情况如图12所示。
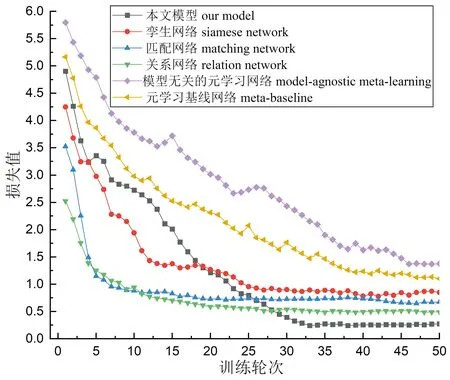
图12 各模型训练损失值曲线Fig.12 Training loss curves of each model
由图12可以看出,本文模型初始值较高,在训练过程中不如RelationNet模型收敛地平稳,存在较大波动,这是因为本文模型在加入CBAM注意力机制后对图像的纹理特征捕捉得更为具体,故在进行迭代优化的过程中会出现反复,但本文模型的损失值在第35轮训练后趋于平稳,且损失值最小,这说明本文模型在化石识别任务上有更好的性能。
由上述所有实验可以看出,在不同的设定条件下,本文模型的准确率和损失值均为最优,但MatchingNet和RelationNet的总体性能也表现较好,在支持集样本数量更少时,与本文模型的识别准确率并无较大差距。且由于笔者等所采集的数据集类别较少,较为局限,所以本文模型在泛化能力上还存在着不足,在实际的化石鉴定工作中,笔者等的工作还需要进一步深入才能面对各种复杂的实际情况。
3.7 参数对模型的影响
在模型训练的实验中,笔者等发现支持集的样本数量会在一定程度上影响模型的性能。为研究Way分类数量与Shot支持集样本数量对模型的具体影响,采用控制变量法,使用本文模型在Way为5,分别设置shot为1~10和在Shot为5,分别设置Way数量为2~6这两种情况下在化石数据集中进行实验,实验结果如图13所示:
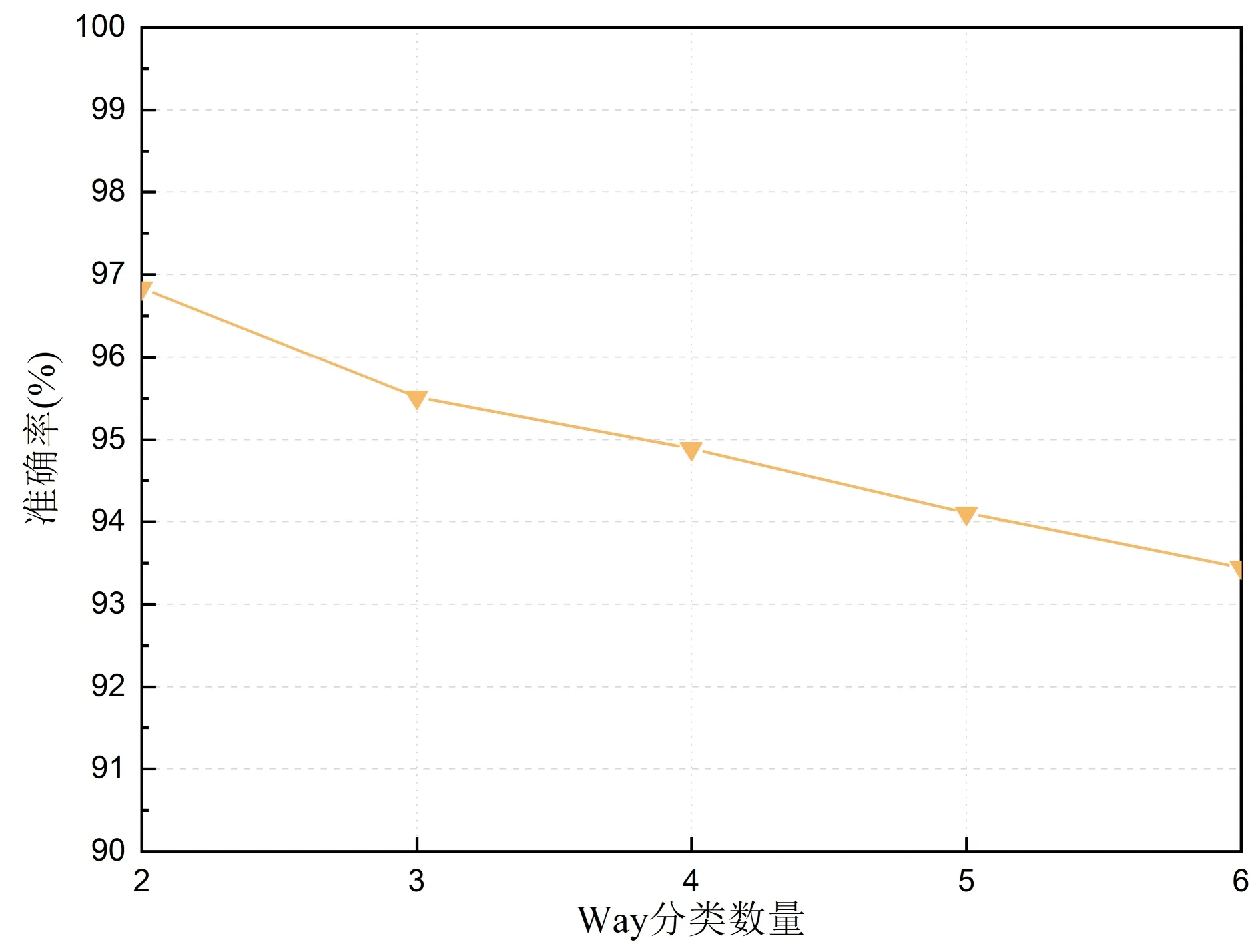
图13 Way参数对本文模型Acc精度结果Fig.13 Influence of Way parameter on Acc accuracy results of this model
由图13和图14可知,在分类数量(Way)相同时,随着支持集样本Shot数量的不断增加,模型的识别精度在逐渐的上升,在Shot数量相同时,随着Way数量的不断增加,模型的识别精度会不断的下降,这可以说明在相同分类数量的情况下,提高支持集样本数量可以有效提高模型的精度,在相同样本数量的情况下,减少Way分类数量可以提高模型的性能。
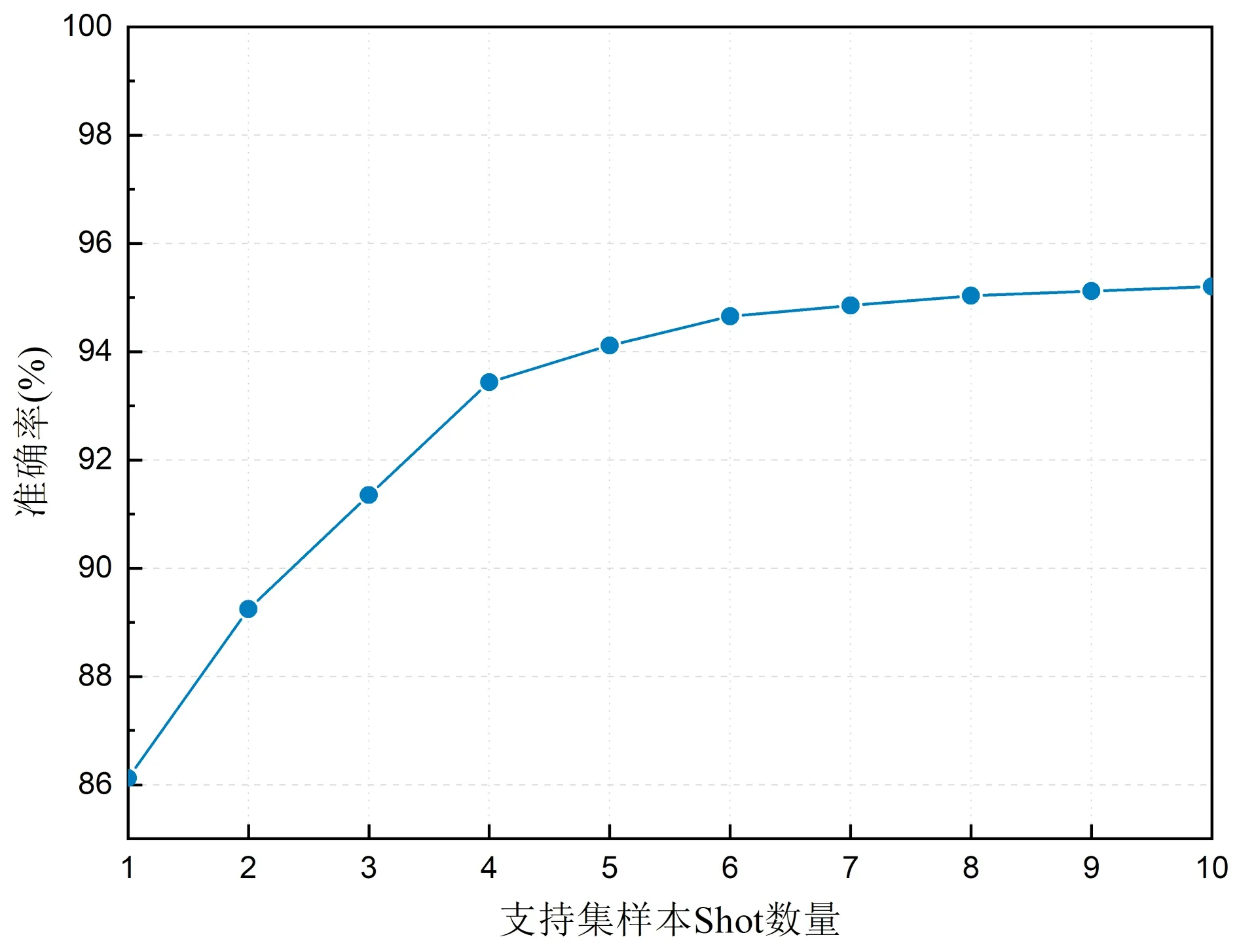
图14 Shot参数对本文模型Acc精度结果影响Fig.14 Influence of Shot parameter on Acc accuracy results of this model
3.8 实际应用
Song Haijun等(2022)通过网络爬虫技术收集了415339张化石图像,使用高性能工作站训练了三个强大的卷积神经网络,实现了90%的平均准确率,并将模型部署在了www.ai-fossil.com网站上以便公众使用。为探究本文模型的实用价值以及开展后续工作,笔者等也将模型进行部署并尝试开发了一套古生物化石智能识别软件平台。该平台如图15所示:
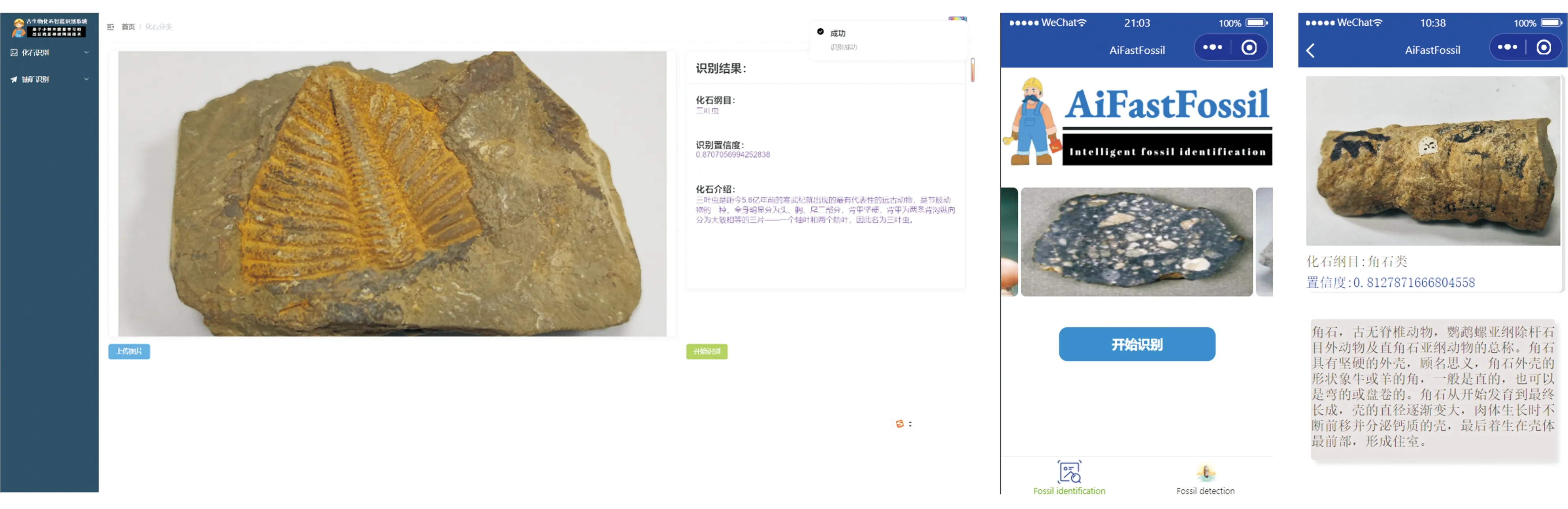
图15古生物化石智能识别系统Fig.15 Intelligent identification system of paleontological fossils
目前,该平台可以对所采集的7个化石纲下的17种化石图像进行准确识别,虽然分类数量较少,但这为后续小样本古生物化石识别的研究工作提供了新的尝试。
4 结论
采用传统方法鉴定化石过于消耗人力物力,而且化石专家的主观意识会在一定程度上影响到鉴定结果,若采用常规的人工智能方法进行识别则需要大量的高质量化石图像样本才能到达较高准确率。笔者等所提方法采用小样本度量学习中的原型网络作为主干框架,将CBAM卷积注意力模块嵌入ResNet12残差网络的残差块中,可以有效提高网络的特征提取能力,实现在少量化石图像训练样本的情况下,达到较高的识别准确率,能够有效解决化石样本图像少与传统卷积神经网络需要大量化石图像样本才能达到较高准确率相矛盾的问题。目前,笔者等的工作只是对所采集的7个“纲”等级下的17类化石图像进行小样本模型的训练,化石数据集的类别尚不丰富,还需进一步的拓展,本文模型的泛化能力也需进一步增强,如何在不同级别分类单元中差异很大的情况下使用小样本学习模型,并达到较高的识别精度是笔者等今后的研究方向。
致谢:感谢审稿专家黄浩博士和孙超博士的宝贵意见,在此致以诚挚的谢意。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
小学科学(2015年2期)2015-03-11
河南科技(2015年8期)2015-03-11
小学科学(2015年1期)2015-03-11
科学大众·小诺贝尔(2009年9期)2009-10-23
