
基于卷积神经网络的图像分类模型综述*
2023-10-07 03:45:42郭庆梅于恒力王中训刘宁波
电子技术应用 2023年9期
郭庆梅,于恒力,王中训,刘宁波
(1.烟台大学 物理与电子信息学院,山东 烟台 264005;2.海军航空大学 信息融合研究所,山东 烟台 264001)
0 引言
卷积神经网络(Convolutional Neural Networks,CNN)[1]是一种深度学习模型,主要应用于图像和视频等数据的识别与分类。2012 年Alex Krizhevsky 等人[2]在ImageNet 大赛中使用CNN 大幅度超越传统方法,CNN 一跃成为计算机视觉领域的热门技术。其具有表征学习能力、泛化能力以及平移不变性,可以高效处理大规模图像且能够转换成图像结构的数据,解决了传统方法需手动提取特征带来的耗时、准确率低等问题,加之计算机性能有了很大的提升[3],使得CNN 得到了质的发展,因此在图像分类、目标识别以及医疗诊断等领域被广泛应用[4],且取得了显著的成就。
1 卷积神经网络常用模型
CNN 的结构一般由卷积层、池化层、全连接层和激活层组成。卷积层由多个卷积核和对应的偏移值组成,通过卷积核与输入的图像进行卷积操作来提取特征[5],池化层的本质是下采样,从而减少参数量,降低过拟合的风险,其非线性池化函数有最大池化和平均池化等,特点是不改变神经网络深度,只改变其大小,减少最后全连接层中节点的数量;全连接层的主要功能是将卷积层和池化层提取到的特征进行整合[6],构建出高层次的特征表示,从而使模型能够更好地进行分类、识别等任务;激活层的作用是增加模型的非线性特征,提高其拟合能力和表达能力,使模型可以更好地适应复杂的数据分布,常用的激活函数有Sigmoid、Tanh、ReLU、Leaky ReLU 和SELU 等。常见的卷积神经网络模型如图1所示。
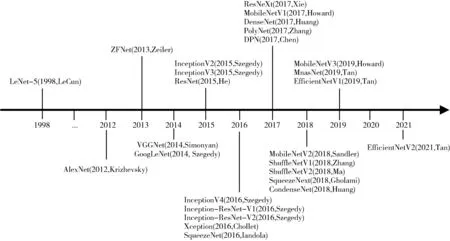
图1 常见的卷积神经网络模型发展时间轴
1.1 LeNet 模型
LeCun 等人[7]在1994 年提出LeNet 模型,经过多次改进,于1998 年发布LeNet-5,主要是用于手写字符和英文字符的识别与分类,利用二维卷积进行图像处理,奠定了现代CNN 的基础。该模型能够做到卷积核共享,减少网络参数,但是限于当时硬件性能低和数据集不够丰富等原因,导致其不适合处理复杂问题。
1.2 AlexNet 模型
Krizhevsky 等人[2]在2012 年提出了AlexNet 模型,该模型在ILSVRC 2012 竞赛中折桂,分类准确率达到了80%以上,极大地促进了深度学习的快速发展。主要特点是通过使用GPU 来提高网络训练速度;采用ReLU 激活函数来缓解梯度消失[8]的问题;引入局部响应归一化来改善局部的对比度,提高其泛化能力以及准确率;使用随机失活来减少过拟合;使用重叠最大池化来提高特征的丰富性。该模型存在的缺点是卷积层不够深,去掉任何一个卷积层,效果都会变差。
1.3 ZFNet 模型
Zeiler 等人[9]在2013 年对AlexNet 进行改进提出了ZFNet 模型,此模型使用反卷积网络[10]来对AlexNet 达到特征可视化的目的,清晰展示CNN 中间层和全连接层学习到的特征,是CNN 领域对模型可视化的开山之作。明确得出特征之间有层次性,随着网络层数的不断加深,其特征不变性越强,类别的判别能力越强。同时调整模型超参数,即将第一个卷积层的卷积核大小缩小为7×7、步长调整为2,提高采样频率,解决了AlexNet 第2 层会出现信号混叠现象的问题,增强了特征提取能力。通过进行遮挡图像局部的实验,明确分类任务中哪部分输入信息更重要。
1.4 VGGNet 模型
Simonyan 等人[11]在2014 年提出了主要用于大规模图像识别的VGGNet 模型,该模型通过增加网络结构来提升性能,具有良好的迁移学习能力;使用3×3 的小卷积核代替其他大尺寸的卷积核,在具有相同感受野[12]的情况下,降低了参数量,提高了特征的学习能力;使用小尺寸的池化核来增加通道数。该模型存在的缺点是参数量大,耗费存储空间资源。
1.5 GoogLeNet 系列模型
针对VGGNet 参数量大的问题,并为了达到提升深度神经网络性能的目的,Szegedy 等人[13]在2014 年提出了GoogLeNet 模型。加入了Inception 结构,将不同尺度的特征信息进行融合,提高网络性能和效率。初始Inception 结构如图2(a)所示,通过实验得出结构中的5×5卷积会造成参数量过大的问题,进行改进提出了InceptionV1,结构图如图2(b)所示,添加了1×1 卷积核进行降维,降低了计算量;添加了两个辅助分类器,结构图如图3 所示,避免了梯度消失和过拟合问题;使用平均池化层来减少模型参数。该模型存在的缺点是最后一层卷积层的计算量大。
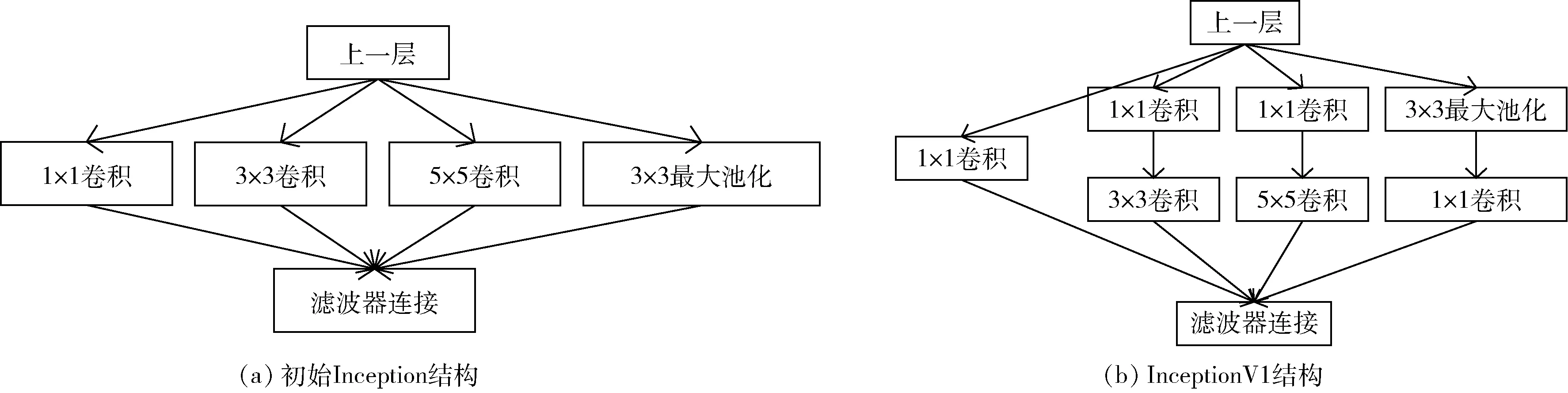
图2 Inception 模块
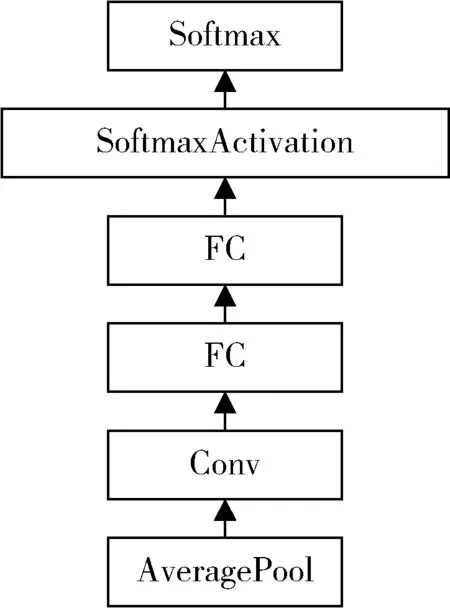
图3 辅助分类器
Szegedy 等人[14]在2015 年对Inception 结构提出了一些优化方法并发布了InceptionV2 模型,用2 个3×3 的卷积核代替1 个5×5 卷积核,1×n卷积核和n×1 卷积核代替n×n卷积核,以此来减少参数量、增加特征信息的判别性;使用并行结构来优化池化层来降低计算量;通过对标签的概率分布进行平滑处理来减少过度拟合。在此基础上,在辅助分类器中加入了批归一化(Batch Normalization,BN),构成了InceptionV3[15]模型的结构;在InceptionV3 的基础上,增加Inception block 的个数,形成了InceptionV4[16]模型;在InceptionV3 的基础上添加ResNet[17]结构,形成了Inception-ResNet-V1[16]模型;在InceptionV4 的基础上添加ResNet 结构,形成了Inception-ResNet-V2[16]模型;在InceptionV3 的基础上用深度可分离卷积(Depthwise Separable Convolution,DSC)进行卷积操作,形成了Xception[18]模型,该模型主要目的是提高性能。
1.6 ResNet 系列模型
为了解决梯度消失、梯度爆炸[19]和退化等问题,He等人在2015 年提出了残差神经网络(ResNet)模型,并在当年的比赛中折桂。该模型对此前已有的网络进行了大创新,将网络结构拓展到了1 000 层,在性能上有了很大的提升;提出了捷径分支连接来解决梯度消失问题;提出了残差模块,如图4 所示,降低了参数量;使用BN加快了收敛速度,有一定的正则化作用。该模型存在的缺点是训练需要的时间比较长。
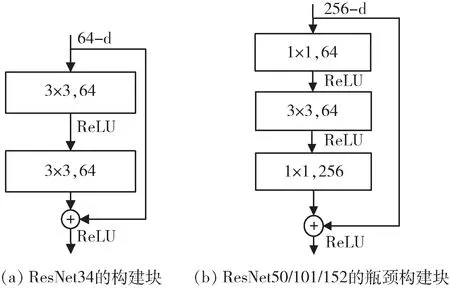
图4 ResNet 残差模块
Xie 等人[20]在2017 年将ResNet 模型和Inception 模型进行结合提出了ResNeXt 模型,使用分组卷积,通过变量基数和使用平行堆叠相同拓扑结构,如图5 所示(group 设置成32 时错误率最低),提高了准确率,由于其分支的拓扑结构相同,降低了参数量。
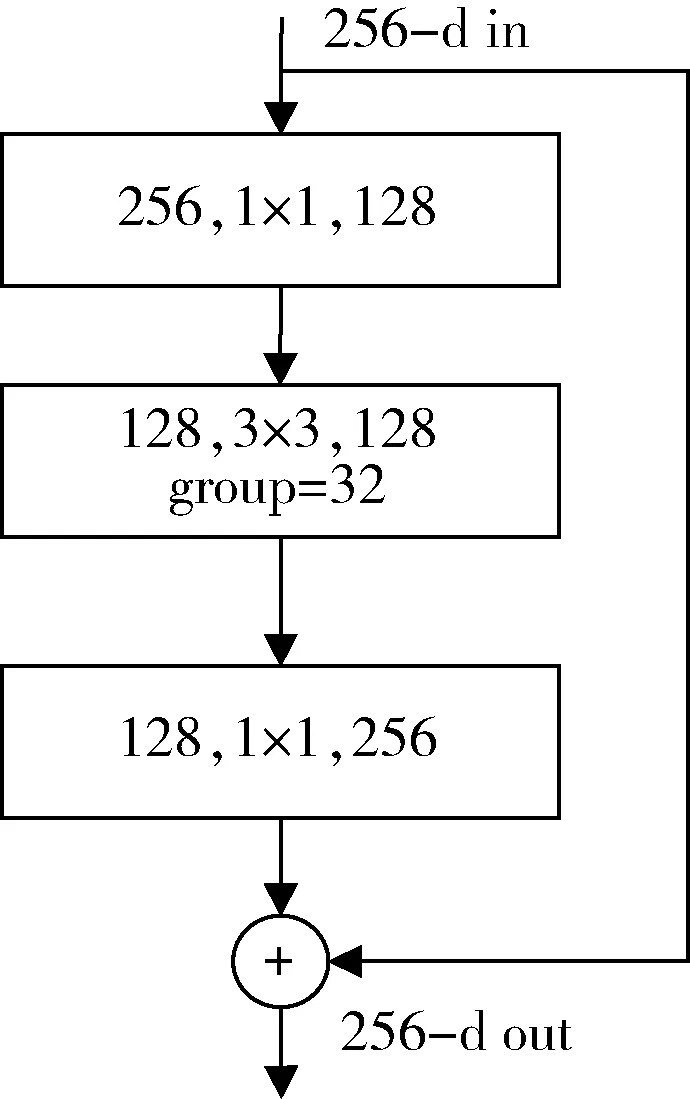
图5 ResNeXt 残差结构
1.7 SqueezeNet 系列模型
Iandola 等人[21]在2016 年提出了SqueezeNet 模型,实现了在保证相同准确率的情况下降低参数量获得更小的CNN 架构,使用模型压缩技术后,模型进一步大幅减小,但是该模型的实时性不好。Fire 模块如图6 所示,squeeze 层限制输入通道数量,显著减少参数量,expand层生成更高级别的特征。设计了普通版SqueezeNet 模型,还设计了包含简单支路的SqueezeNet 模型和包含复杂支路的SqueezeNet 模型。
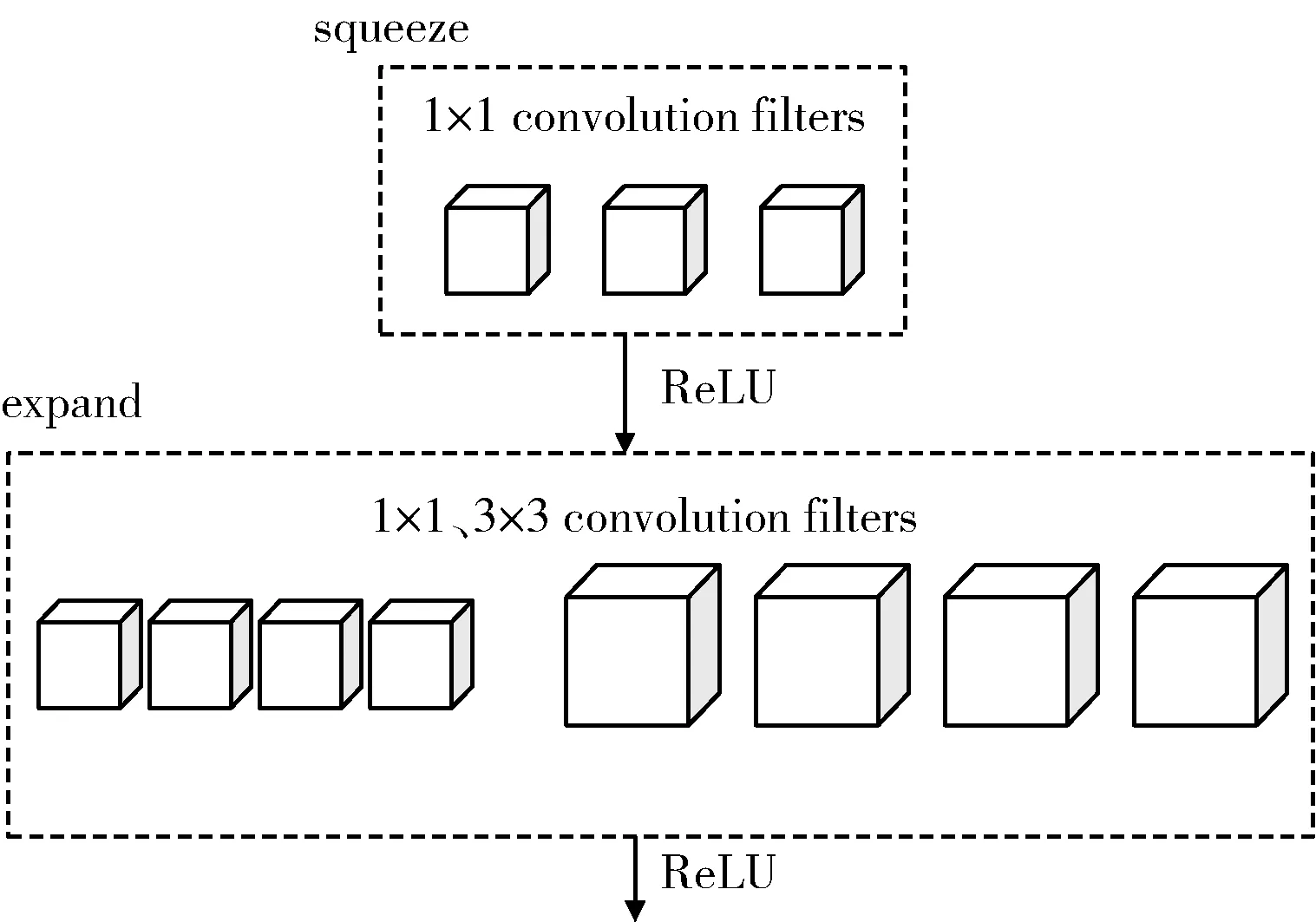
图6 Fire 模块
Gholami 等人[22]在2018 年对SqueezeNet 进行改进提出了SqueezeNext 模型,此模型是通过加深和加宽网络来提升网络性能的。Block 部分如图7 所示,有三个贡献点:(1)用1×n和n×1 的卷积核替换原来n×n的卷积核,降低了参数量;(2)设计瓶颈模块,使通道数减半;(3)最后一层卷积层使用1×1 的卷积核,进行通道数压缩,降低全连接层的输入维度,减少了参数量,提高了泛化能力。
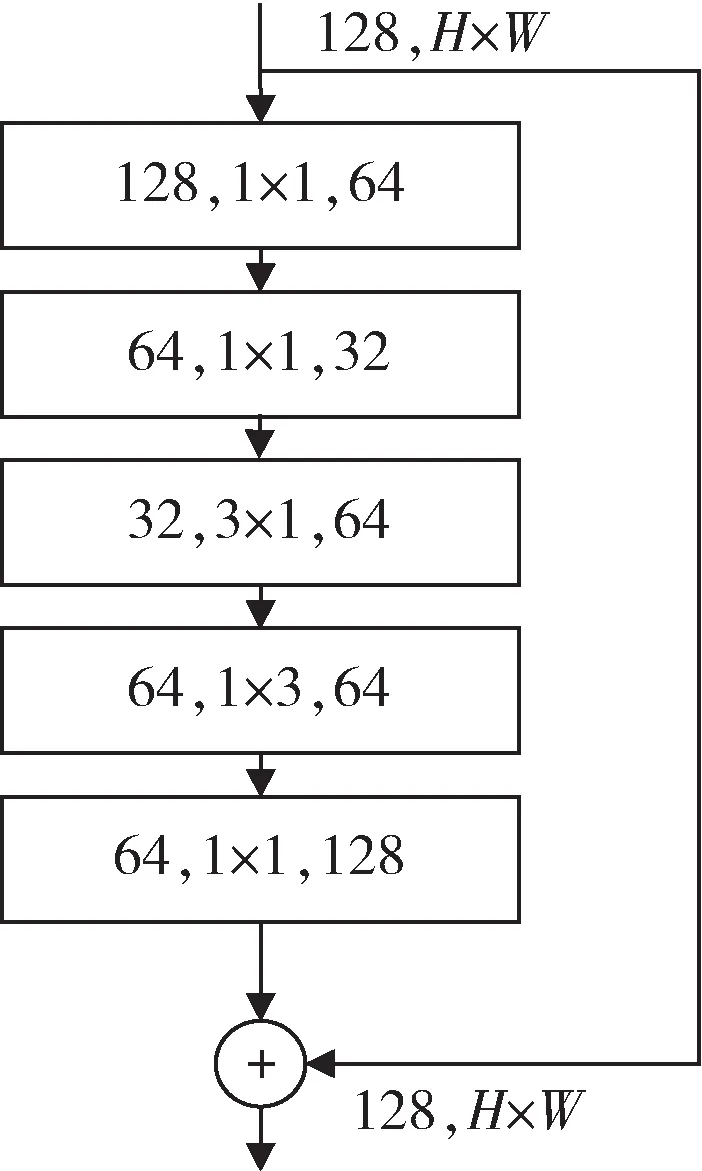
图7 SqueezeNext 模块
1.8 DenseNet 系列模型
Huang 等人[23]在2017 年提出了DenseNet 模型,采用密集连接方式,如图8 所示,有利于特征信息被充分利用,通过特征在通道上的连接来实现特征复用,是使用的concat,这些方法使得其降低了参数量、提高了泛化能力、有很好的抗过拟合性能。同时,该模型也存在一些不足,比如需要非常大的存储空间、计算复杂度大、现有的深度学习框架不能很好地支持此模型。
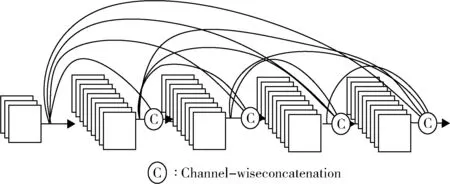
图8 DenseNet 模型的密集连接机
针对DenseNet 模型冗余度高等问题,该作者又提出了计算效率更高且参数更少的CondenseNet 模型[24],该模型将密集连接思想和可学习分组卷积模块进行了融合,效果显著。
1.9 PolyNet 模型
Zhang 等人[25]参考Inception-ResNet 的思想在2017年提出了PolyNet 模型,从多项式的角度对残差块和Inception-ResNet 进行了扩展,同时在训练时使用插入初始化策略,将新加入的随机初始化的模块交叉地插入到已有模型中,效果明显,使用基于集成思想的随机路径和加权路径,用实验结论证明了提高模型准确率的方法不仅仅是增加深度和宽度,还可以增强模型的多样性。
1.10 DPN 模型
Chen 等人[26]提取ResNeXt 与DenseNet 模型的优点并在2017 年提出了DPN(Dual Path Network)模型,使得该模型能够有效地进行特征复用,也能探索新的特征,在图像分类方面有着很高的准确率,DPN-98 模型参数量 比ResNeXt-101 少26%,DPN-98 比ResNeXt-101 少 消耗约25%的FLOP。
1.11 MobileNet 系列模型
针对传统卷积网络运算量大,无法在移动设备和嵌入式设备上运行的问题[27],Howard 等人[28]在2017 年提出了一个轻量级的网络模型,即MobileNetV1 模型。该模型使用了DSC,由深度卷积(Depthwise Convolution,DWC)和逐点卷积(Pointwise Convolution,PWC)组成,其中深度卷积的卷积核通道数为1,输入特征矩阵通道数等于卷积核个数等于输出特征矩阵通道数,逐点卷积的卷积核的大小为1×1,卷积核通道数等于输入特征矩阵通道数,输出特征矩阵通道数等于卷积核个数[29],同时引入了两个收缩超参数:宽度乘子和分辨率乘子,降低了计算量,减小了体积,提高了精确度。该模型存在的缺点是该模型性价比低,训练过程中很多卷积核参数为0。
针 对MobileNetV1 出现的问题,Sandler 等人[30]在2018 年提出了MobileNetV2 模型,该模型使用了倒残差结构和线性瓶颈结构。倒残差结构先使用1 × 1 卷积进行升维,加深通道,获得更多的特征信息,再使用3×3 DWC 进行卷积操作,最后使用1×1 卷积进行降维,降低了参数量。如图9 所示,stride=1 和stride=2 时的block 结构,使用捷径分支的条件是stride=1 且输入特征矩阵与输出特征矩阵尺寸相同[31]。线性瓶颈结构时将1×1 卷积后的ReLU6 替换为线性激活函数Linear,解决了卷积核参数为0 的问题,保证了模型的表达能力。该模型存在的缺点是丢失了层与层之间的多样性,不能保证准确性。
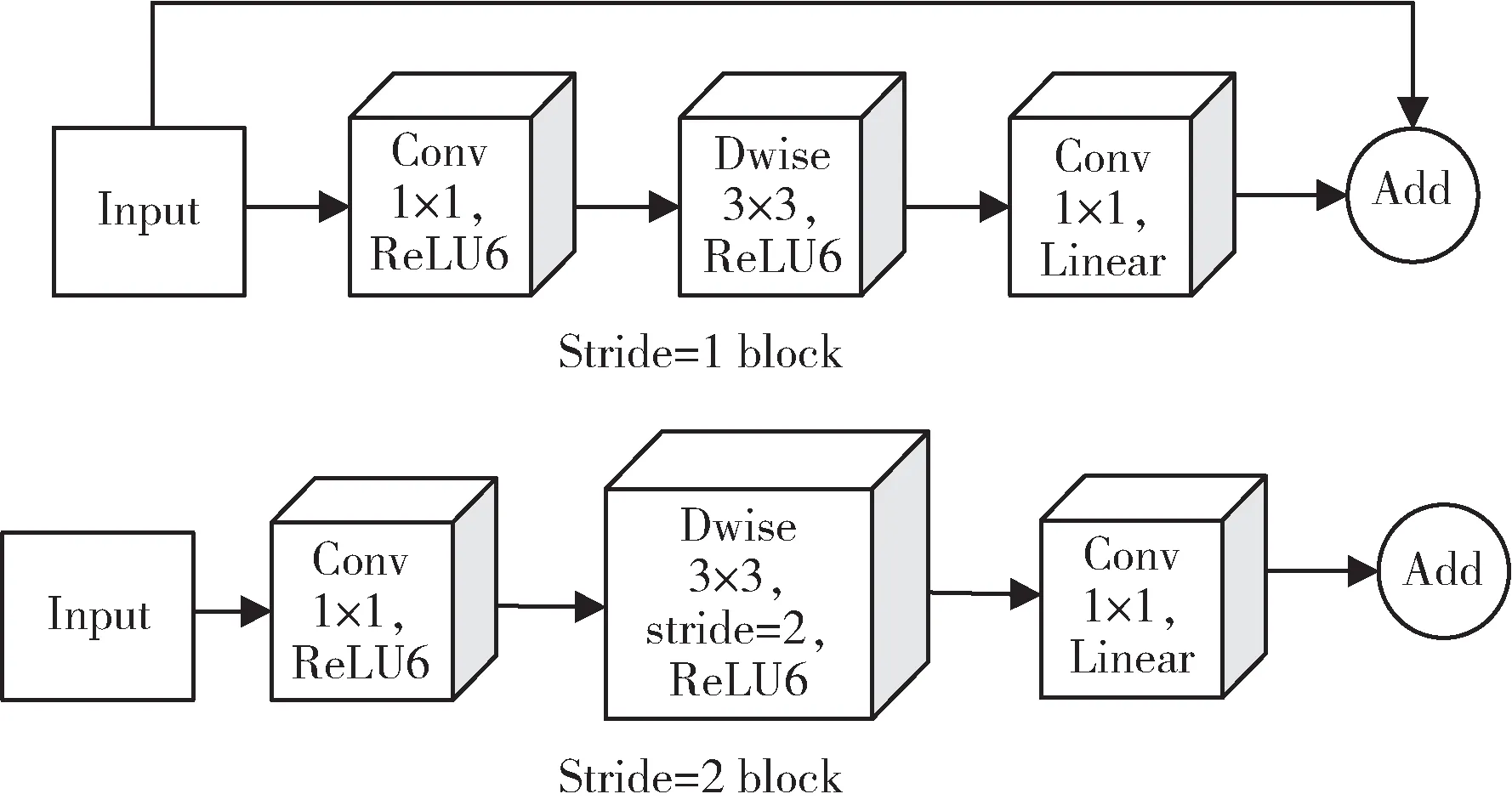
图9 MobileNetV2 模型的block 结构
针对MobileNetV2 出现的问题,Howard 等人[32]在2019 年提出了MobileNetV3 模型,该模型在block 部分加入了注意力机制模块并更新了激活函数,注意力机制的操作步骤:将得到的特征矩阵的每一个通道进行池化操作,特征矩阵的通道数等于得到的一维向量的元素数,通过两个全连接层,第一个全连接层的节点数等于输入特征矩阵通道数的1/4,第二个全连接层的节点数等于特征矩阵通道数,计算出通道权重关系,重要的通道维度将被给予更大的权重,而不重要的通道维度将被给予较小的权重[33],进而提高模型的性能。激活函数部分是将Sigmoid 和Swish 激活函数替换成Hard-sigmoid和Hard-swish 激活函数。使用捷径分支的条件与MobileNetV2 模型一样,条件为stride 为1 且输入特征矩阵与输出特征矩阵尺寸相同。使用了神经结构搜索参数(Neural Architecture Search,NAS),修改了Last Stage 结构,节约了运行时间。该模型存在的缺点是训练难度高,对于一些细粒度分类的任务效果可能不佳。
1.12 ShuffleNet 系列模型
对于普通卷积中组与组之间没有信息交流问题,Zhang 等人[34]在2018 年提出了具有逐点群卷积和通道重排的ShuffleNetV1 模型。通过通道重排,能够使组与组之间进行特征通道信息交流,同时发挥了分组卷积的优点。在此模型中,使用的卷积为1 × 1GConv 和DWConv,模型的block 如图10 所示,(a)是具有逐点群卷积和通道重排的ShuffleNet 单元,使用add 操作,(b)是stride=2 时的block,使用concat 操作。
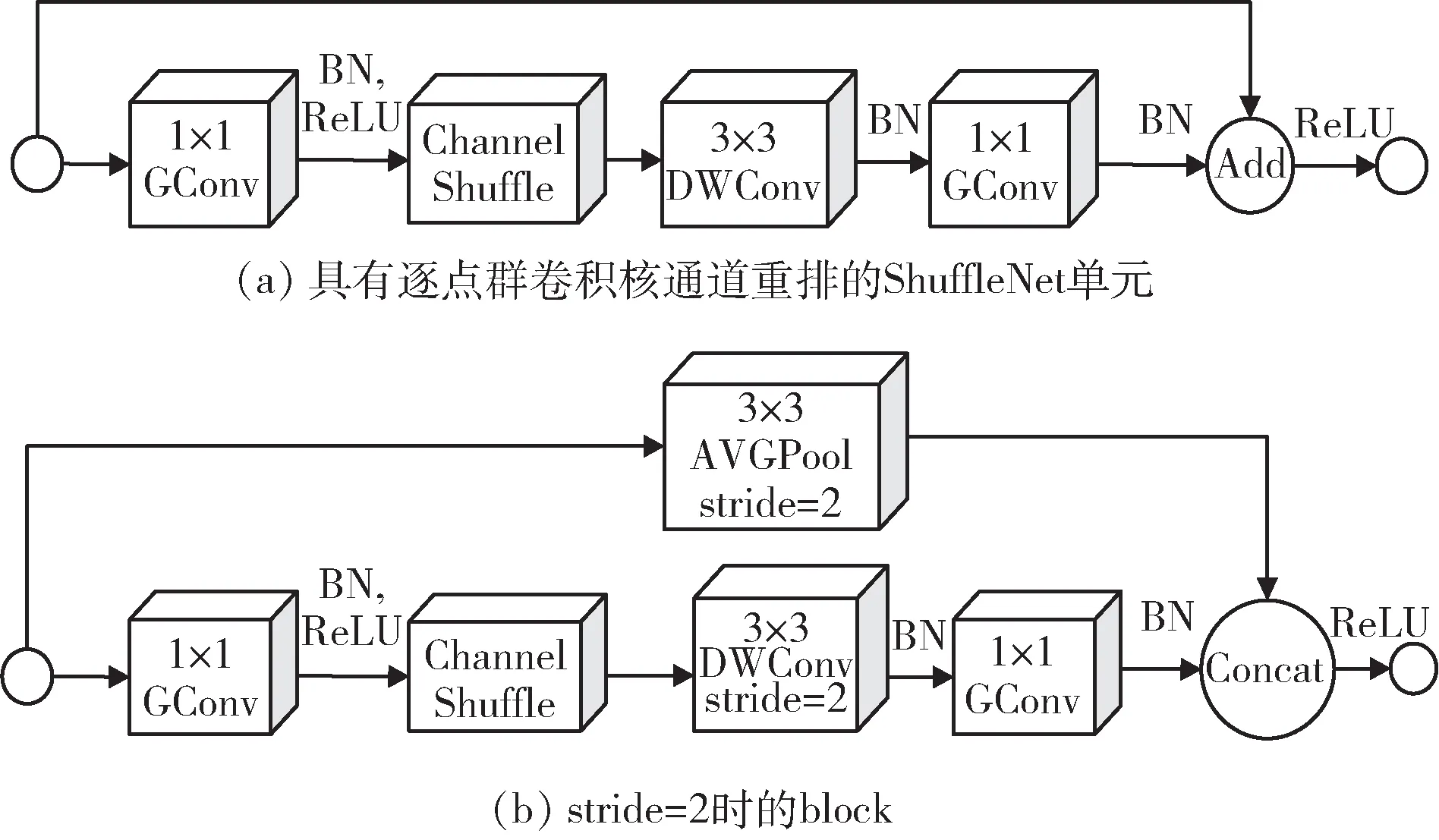
图10 ShuffleNetV1 模型的block 结构
Ma 等 人[35]在2018 年 对ShuffleNetV1 和Mobile-NetV2 模型进行总结提出了ShuffleNetV2 模型。以往衡量模型速度的指标是FLOPs,本文又添加了内存访问代价(Memory Access Cost,MAC)和GPU 并行程度两个指标;对于轻量级的CNN,给出了四条实践结论:可使用相同输入输出维度的卷积来减少MAC、过量使用组卷积会增加MAC、网络碎片化会降低并行度以及不能忽略元素级操作[36]。该模型中提出了新的block,均使用concat 操作,如图11 所示,(a)是基本的ShuffleNetV2 单元,使用Channel Split 操作将通道数拆分成两部分,(b)是ShuffleNetV2 空间下采样单元。
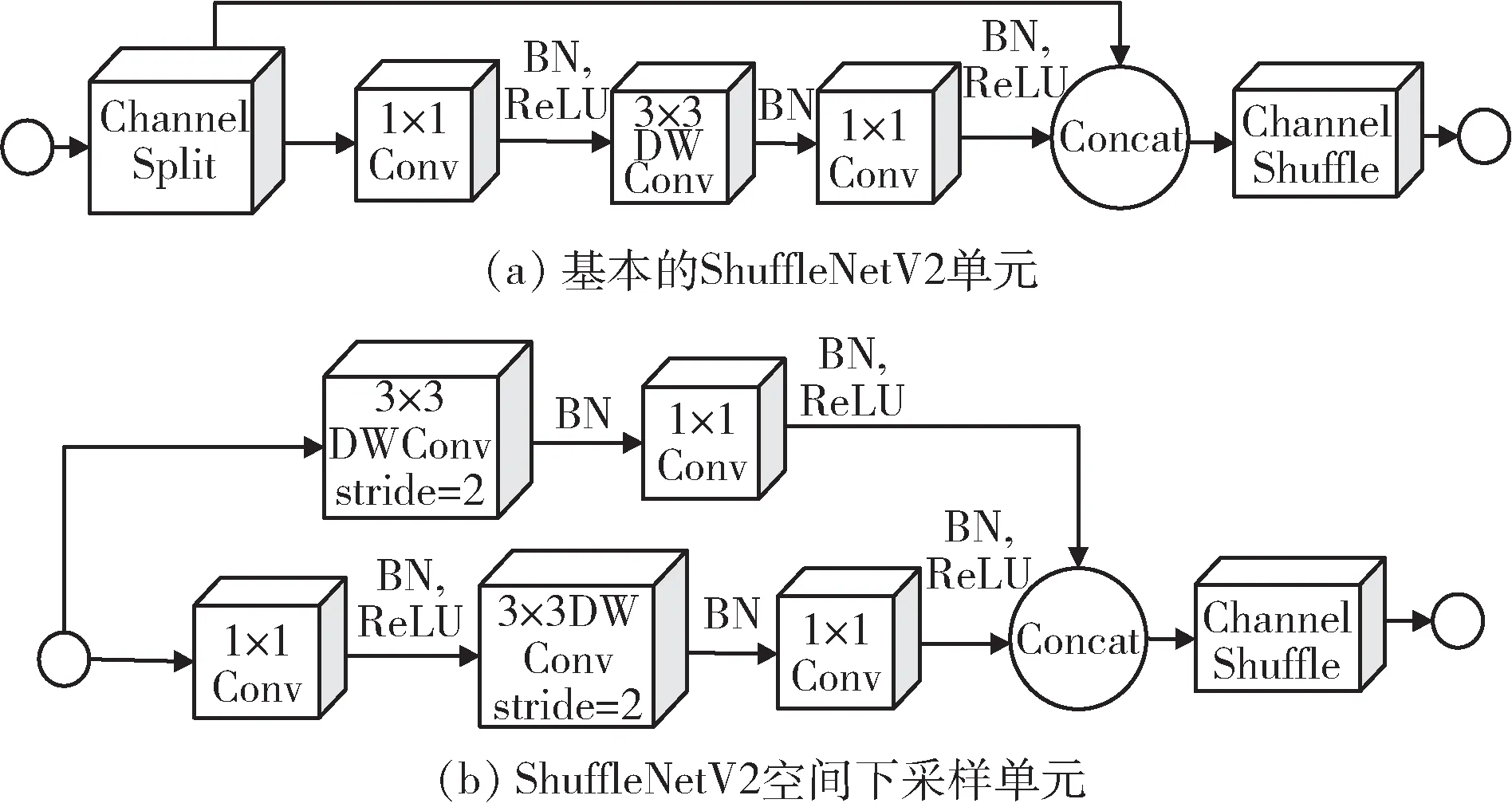
图11 ShuffleNetV2 模型的block 结构
1.13 MnasNet 模型
为了能设计出更加适合移动端的卷积网络,Tan 等人[37]在2019 年提出了重视推测速度和准确率的Mnas-Net 模型,该模型使用分解式层次搜索空间,并且通过移动设备来得出延迟,提高了网络架构的性能和效率。
1.14 EfficientNet 系列模型
Tan 等人[38]对网络结构的操作层个数、通道数和输入图片的分辨率进行综合研究并在2019 年提出了EfficientNetV1 模型,EfficientNet-B7 在Imagenet top-1 上准确率达到了84.3%,与GPipe[39]相比,参数量为其1/8.4,推理速度提升了6.1 倍。该模型存在的缺点有:(1)当图像很大时,速度会很慢;(2)使用DW 卷积会降低速度;(3)同等缩放stage 不合理。
针对这些问题,又提出了能够平衡参数量和速度的EfficientNetV2[40]模型,该模型引入了Fused-MBConv 到搜索空间中,以实现更高效的特征提取和参数共享,同时引入了自适应正则强度调整机制来支持渐进式学习,使得模型的性能和效率都大幅提升。
2 卷积神经网络模型优缺点
总结CNN 模型优缺点,如表1 所示。

表1 CNN 模型优缺点
3 结束语
本文对CNN 的发展进行了梳理,详细剖析了常用的典型模型。CNN 经过不断的演化和改进,使其在保证参数量的情况下,前向传播速度和训练速度都有很大的提升,同时,提高了泛化能力、优化了抗过拟合性能。CNN仍然有许多方面需要改进:
(1) 数据方面:CNN 进行训练时需要大量的标注数据,对未标注的物体不能进行判断类别,限制了CNN 的应用范围,要考虑如何使用少量标注、自动标注、迁移学习以及无监督等方面减少人工代价。
(2) 参数方面:CNN 网络结构与参数设置一般都是经过多次实验得出的最优化结果,如何使其网络自动设置超参数使性能最佳,对于网络更加实用性具有促进作用。
(3) 成本方面:CNN 为了获取更多的深层次信息,会加深网络层数,这需要大量存储空间,对计算机算力有很高的要求,如何使网络降低对计算机性能的要求,方便更多研究者对其进行使用。
总体而言,CNN 的出现促进了计算机视觉和人工智能的发展,使其更加满足社会需求,在未来CNN 仍然是该领域中的一个热点,期待更多新成果的出现。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:42
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
小猕猴智力画刊(2016年6期)2016-05-14 21:40:48
现代企业(2015年5期)2015-02-28 18:51:08
