
深度特征维纳反卷积用于均匀离焦盲去模糊
2023-09-27 07:22:12王成曦罗晨周江澔邹浪贾磊
光学精密工程 2023年18期
王成曦, 罗晨, 周江澔, 邹浪, 贾磊
(1.东南大学软件学院,江苏 苏州 215123;2.东南大学机械工程学院,江苏 南京 211189;3.无锡尚实电子科技有限公司,江苏 无锡 200240)
1 引 言
物体到摄像机焦平面的场景距离是决定相机所拍摄图像清晰度的主要因素。远离相机焦平面的光线会聚到成像平面上时是一个类似圆形的区域而不是点,该区域被称为弥散圆(Circle of confusion)。当弥散圆的尺寸大过成像传感器单元的尺寸时,相机成像就会产生离焦模糊现象[1]。离焦模糊会导致视觉信息丢失,严重影响图像分类,目标检测以及语义分割等视觉任务的精度[2]。因此,单幅离焦图片去模糊研究在机器视觉的多个应用领域都有实用价值。
机器视觉领域,自动光学检测设备的成像系统往往景深较小,容易产生离焦模糊,严重影响视觉检测效果。为了简化研究,将工业成像系统近似看作一个空间不变的线性系统,将这种离焦模糊近似看作均匀离焦模糊。均匀离焦模糊图像的退化过程可以近似看作清晰原图与一个高斯或者圆盘模糊核卷积的过程,即高斯离焦模型和圆盘离焦模型[3]。
图像去模糊的方法一般分为两种,非盲去模糊[4]和盲去模糊[5-6]。早期关于图像去模糊的研究主要集中在相对简单的非盲去模糊问题上。非盲去模糊是一个病态问题,因为在图像退化的过程中,丢失大量视觉信息是不可避免的[7]。所以,后续大部分研究都致力于构造各种图像先验来约束解空间,如总变分[8]、超拉普拉斯先验[9]、局部颜色先验[10]等。经典的盲去模糊算法[11-13]同样是依靠手工制作图像先验作为图像去模糊目标函数的正则化项,然后通过设计有效的迭代算法逐步估计出模糊核以及清晰图像。经典的图像去模糊算法虽然可以通过严格的数学模型进行解释,但是也存在着计算量太大,比较耗时,且容易出现伪影和振铃现象等问题[14]。
由于难以从模糊图像中获得关于模糊核的信息,大多数基于深度学习的去模糊方法都采用了端到端网络模型来解决盲去模糊的。Nah等人[15]提出一种称为DeepDeblur的端到端多尺度去模糊网络,无须估计模糊核,直接由模糊图像估计清晰的图像;Tao等人[16]提出了一种多尺度递归网络,利用金字塔形式逐渐恢复出清晰图像,实现更好的去模糊效果;Chen等人[17]提出了专用于图像复原的简单基线(Simple Baseline),验证了图像复原网络不需要很复杂的网络结构,一个非线性的,无激活函数的简单网络模块(Nonlinear Activation Free Network Block,NAFNet-Block)在图像复原任务中也可以达到当时SOTA(State-of-the-art)的效果。然而,这些基于直接预测的方法过于依赖训练数据,反而容易丢失图像的高频信息,导致去模糊的结果细节不足。所以,如果能够准确地预测模糊图像的模糊核,则可以进一步提高去模糊算法的性能。从这个角度出发,文献[18-19]中提出了基于深度学习的两阶段图像盲去模糊算法。
不同于上述的基于监督学习的方法,Ren等人[20]提出了一种基于自监督方法的盲去模糊网络SelfDeblur,该算法包含两个生成网络,深度图像先验网络(Deep Image Prior,DIP)[21]和全连接网络(Full Connect Network,FCN),它们分别用于估计去模糊图像和估计模糊核。该网络采用自监督的方法,所以不需要依赖海量的训练数据。但是,该算法复原一张模糊图像需要数千次的迭代,计算成本极大,非常耗时。
为了解决以往算法的局限性以及改善离焦去模糊的效果,本文提出了一种针对于均匀离焦图像的盲去模糊网络(Uniform Defocus Blind Deblur Net,UDBD-Net)。首先,采用两阶段网络,先准确估计出离焦模糊核,并且在反卷积网络中充分利用估计出的模糊核信息,以获得更优的去模糊效果。其次,在非盲反卷积网络中,将经典维纳反卷积融入深度神经网络中,组成深度特征维纳反卷积模块(Deeper Feature-based Wiener Deconvolution,DFWD),增强网络的可解释性,然后使用一个基于编解码网络的特征强化模块(Feature Reinforcement Module,FRM)来增强复原图像的细节,同时去除伪影和振铃现象。
2 均匀离焦去模糊方法
针对现有盲去模糊网络的细节特征恢复较差,本文构建一个针对均匀离焦模糊有效的盲去模糊网络(UDBD-Net)。如图1所示,均匀离焦盲去模糊网络UDBD-Net主要包括一个离焦模糊核估计网络和一个非盲反卷积的复原网络。
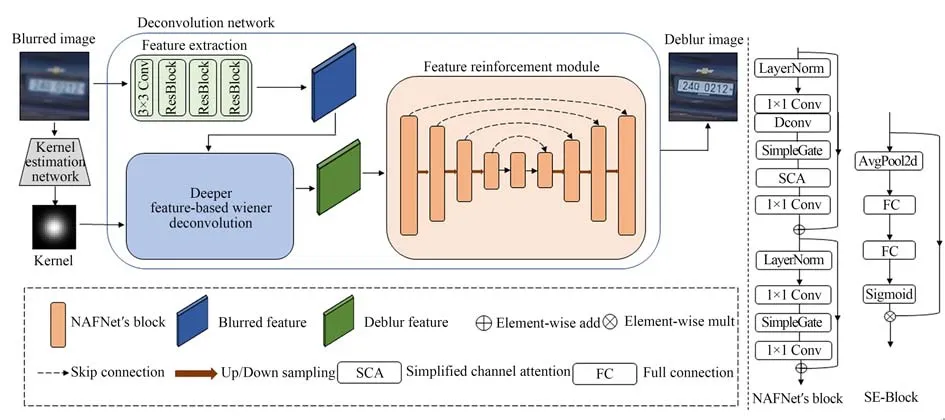
图1 均匀离焦去模糊网络的整体结构Fig.1 Overview architecture of uniform defocusing deblurring network
2.1 均匀离焦模糊核估计网络
为了预先获得模糊图像的模糊信息,以便于得到更好地去模糊结果,模糊核估计通常是两阶段盲去模糊算法的第一步。受到Luo等人[22]提出的深度动态线性核估计器的启发,本文提出一种均匀离焦模糊核估计网络,其结构如图2所示。首先,使用一个11×11大小的卷积核以及Res-Block模块进行特征提取。大的卷积核可以获取大的视野,以捕捉模糊图像整体的离焦信息。由于模糊核本身包含的信息有限,所以使用全局平均池化将特征图压缩为一维,以减少学习的参数并提高速度。然后,使用1×1的卷积核进行维度转换,然后通过Reshape操作将一维的特征图分别转换成11×11,7×7,5×5和1×1的二维滤波核。最后,将二维滤波核依次卷积,得到一个21×21的离焦模糊核。
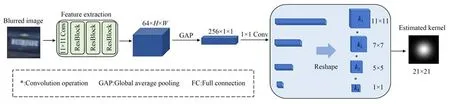
图2 模糊核估计网络的结构Fig.2 Architecture of blur kernel estimation network
2.2 非盲反卷积网络
首先,为了让估计出来的模糊核得到充分利用的同时,能够从模糊图像中提取到更加有用的信息,所以将基于特征空间上的维纳反卷积模块(Feature-based Wiener Deconvolution,FWD)[23]引入模型当中。FWD算子公式如式(1)所示:
式(1)是特征空间下图像退化过程的表达式。其中Fi(̂)和Fi(y)分别表示清晰图像x以及模糊图像y的在特征图空间中第i通道的张量,Hi表示FWD算子。式(2)是计算FWD算子的表达式。其中变量k表示模糊核,F表示离散的傅里叶变换表示F(k)的复共轭。和图像空间中的维纳反卷积一样,式(2)中分别表示清晰图像期望和加性噪声期望的sxi和sni都是未知的。FWD模型中将sxi近似看作模糊特征(Blurred Feature)的标准差,并将sni近似看作模糊特征与其均值滤波结果之间的偏差。
为了更加准确地估计sxi以及sni的值,本文提出将FWD算子公式简化:
不同于在标准的图像空间中的维纳反卷积简化公式,式(3)中的Ci不是一个简单的规定常数,而是可以被神经网络估计的数值,而且在特征空间中每个通道都会估计一个Ci。式(3)在简化FWD算子公式的同时,也实现了维纳反卷积与神经网络更深层次的融合,因此将该模块称为深度特征维纳反卷积(Deeper Feature-based Wiener Deconvolution,DFWD)。DFWD模块的结构示意图如图3所示。
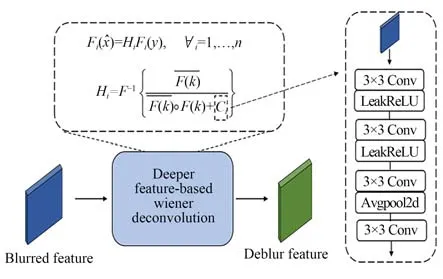
图3 深度特征维纳反卷积模块结构图Fig.3 Architecture of deeper feature-based wiener deconvolution module
模糊图像经过特征提取,得到模糊特征(Blurred Feature),在DFWD模块的帮助下,生成去模糊图像的潜在特征(Deblur Feature)。为了从潜在的特征中复原出高质量的去模糊图像,本文基于Chen等人[17]提出的NAFNet-Block模块,搭建了特征增强模块(Featuree Refinement Module,FRM)。FRM可以从反卷积模块得到的去模糊图像潜在特征(Deblur Feature)中复原出去模糊后的清晰图像。
2.3 损失函数
为了让网络更好地收敛,采取两阶段训练法训练UDBD-Net。
第一阶段中,核估计网络和反卷积网络各自单独训练,真实的模糊核作为去模糊网络的输入,核估计网络损失函数和反卷积网络的损失函数如式(4)和式(5)所示:
其中:式(4)中的LE表示核估计网络损失函数,k和̂分别表示真实的模糊核以及模糊核估计网络预测的模糊核;式(5)中LD表示反卷积网络的损失函数,x和̂分别表示真实的清晰图像和反卷积网络输出的去模糊图像。
第二阶段中,将核估计网络的输出作为反卷积网络的输入,进行联合训练。这一阶段损失函数LE+D的表达式如式(6)所示:
3 实验与结果分析
3.1 数据集生成方法
由于UDBD-Net的目标是构建一个有效的均匀离焦图像去模糊网络,然而大部分现存的去模糊数据集都是关于运动模糊的,所以采用人工合成的离焦图像作为对比实验和消融实验的训练集和验证集。首先,分别从GOPRO[15]数据集和DIV2K[24]数据集中的训练集图片选取800张清晰的原始图片作为实验训练集的原始图片。在模型训练中,训练集中的大图裁剪成256×256的小图,同时生成大小为21×21的高斯离焦模糊核,其中每个高斯核的宽度值σ为1~4之间的随机数。然后将剪切好的图片和生成的高斯核进行卷积,得到模糊程度不同的离焦模糊图片。测试集是选用GOPRO和DIV2K数据集中的测试集图片,并选用Gaussian8[25]模糊核作为合成模糊测试图片的模糊核,其中Gaussian8模糊核是指核宽度σ在1.8~3.2之间间隔0.2取样的8个高斯模糊核。实验测试结果使用的客观评价指标是均方误差(Mean Square Error,MSE)、峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性度(Structural Similarity Index Measure,SSIM)[26]。
3.2 离焦模糊核估计实验
在模型训练的第一阶段,模糊核估计网络单独进行训练。为了验证估计出的模糊核作为非盲复原网络输入的有效性,选择基于总有界变分模型的FTVD算法[27]对模糊核估计网络的结果进行实验。如下图4所示,图4(a)是使用宽度σ=3.5的高斯核生成的离焦模糊图;图4(b)、图4(c)和图4(d)是使用FTVD非盲去模糊算法的结果,其中模糊核分别使用的是宽度σ=3.5的真实模糊核、宽度σ=3.7的不准确模糊核以及离焦模糊核网络估计出的模糊核。对比图4(b)与图4(d)的去模糊结果,可以看出模糊核估计网络估计出的模糊核用在传统反卷积方法中可以达到与真实模糊核相近的效果。此外从图4(c)可以看出,传统反卷积算法对于模糊核的准确性非常敏感。由此可以说明模糊核估计网络的结果准确性非常高。

图4 FTVD非盲去模糊算法的结果Fig.4 Results of the non-blind deblurring algorithm FTVD
3.3 合成图像去模糊实验
为了验证UDBD-Net在均匀离焦去模糊问题上的优异性能,选择与近几年提出的图像去模糊算法进行对比实验,主要包括采用自监督策略的SelfBlur算法[20]、基于端到端网络实现的DeepDeblur算法[15]、SRN算法[16]、NAFNet算法[17]以及非盲反卷积算法FWD[23]。其中非盲反卷积算法FWD[23]在对比实验中使用本文模糊核估计网络的结果作为网络的输入。此外,选用的对比实验的算法都使用本文所用的训练集进行重新训练。
关于均匀离焦去模糊模型定量的评价指标,主要关注平均PSNR以及算法的平均推理时间。如表1所示,对比其他算法这三个指标的结果后,可以明显地发现本文提出的均匀离焦盲去模糊算法可以在没有明显增加推理时间的情况下,获得最好的去模糊效果。SelfDeblur[20]是一个基于深度图像先验(Deep Image Prior,DIP)的自监督算法,不需要海量成对的模糊和清晰的图片进行训练,直接进行优化推理。该算法对于运动模糊的效果很显著,但是对于本文中的均匀离焦模糊,不管是去模糊效果还是算法推理速度方面都远远落后于本文的算法。DeepDeblur[15],SRN[16]和NAFNet[17]都是端到端去模糊网络模型,不需要额外估计模糊核的信息,且得益于其简单的网络结构,这些模型有着非常快的推理速度,例如SRN[16]的算法预测单张DIV2K测试集图像(2 040×1 560 pixels)或者单张GOPRO测试集图片(1 280×720 pixels)都仅需要0.05 s左右。本文提出的UDBD-Net网络是一个两阶段的去模糊网络,需要准确估计模糊核信息,以辅助图像去模糊,所以要比一般的端到端模型更为复杂。虽然UDBD-Net模型由于更复杂的网络结构以及频域转换操作使得模型推理速度变慢,但是推理速度仍然在可以接受的范围内,且算法的性能与端到端网络相比得到了很大的提升。尤其在GOPRO数据集图片上,UDBD-Net去模糊结果的PSNR值比SRN[16]中的算法提高了4.12 dB。图5表示DIV2K数据集和GOPRO数据集在模糊宽度σ在1.8~3.2之间不同模糊程度的平均PSNR值折线图。从图5中也可以看出提出的UDBD-Net在不同离焦模糊程度下的去模糊结果都是最好的。
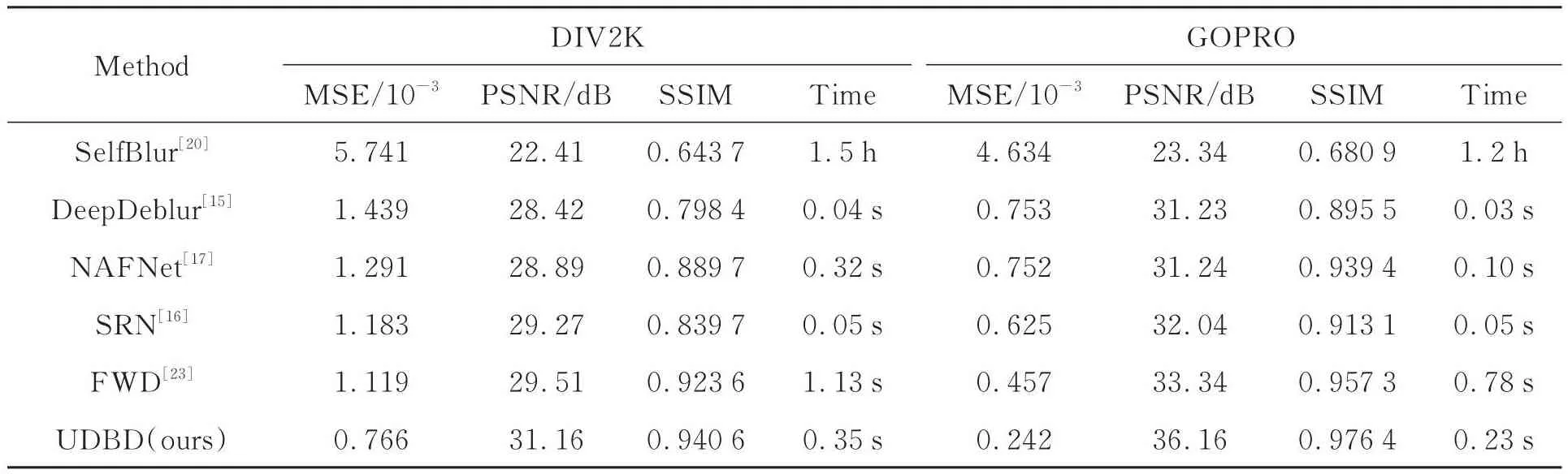
表1 不同算法的去模糊客观性能指标对比Tab.1 Comparison of objective performance indicators of different algorithms
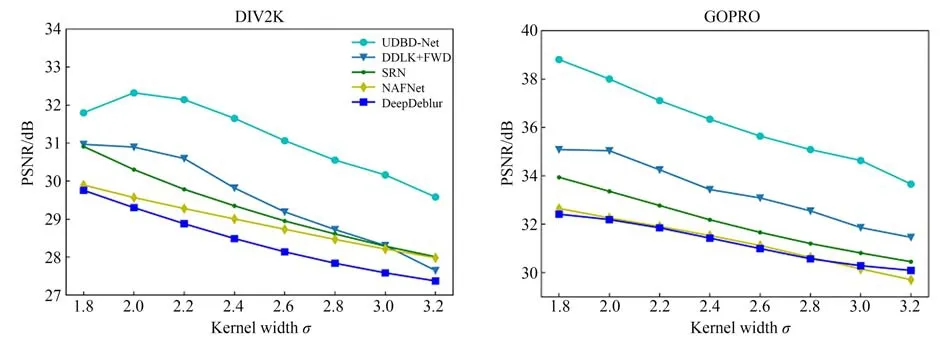
图5 不同模糊程度下PSNR值对比Fig.5 Comparison of PSNR under different blurring degrees
关于均匀离焦去模糊模型主观的评价指标,主要关注模型去模糊结果的细节性和自然性。图6和图7分别是UDBD-Net与其他模型在DIV2K数据集和GOPRO数据集上的均匀离焦去模糊结果对比图,从图中可以看出UDBD-Net对比其他去模糊算法,获得了最好的结果。从图6和图7中可以看出,SelfDeblur[20]算法结果都存在明显的模糊以及大量的噪点。从图6中的部分建筑的放大图可以看出,DeepDeblur[15],SRN[16]和NAFNet[17]三个端到端网络都能够去除部分的噪点和伪影等错误信息,但同时也丢失了部分高频信息,导致出现细节纹理消失的现象;而FWD[23]去模糊的结果保留了更多的图像纹理细节,但同时也存在明显的伪影和振铃现象。在图6和图7中,对比UDBD-Net去模糊结果与其他算法的结果,可以明显发现本文提出的UDBDNet模型,能够还原出了图像更多细节纹理的信息,并且能够去除伪影、振铃以及噪点等错误信息,使得复原的图像更加清晰自然。此外,结果最好的两个模型UDBD-Net以及FWD[23]算法都是两阶段去模糊算法,由此可以推出在能够准确地估计并充分利用输入图像的模糊核信息的情况下,两阶段的去模糊网络的效果要优于端到端的网络。

图6 DIV2K数据集中测试图片的去模糊视觉结果Fig.6 Visual results of a test image in DIV2K

图7 GOPRO数据集中测试图片的去模糊视觉结果Fig.7 Visual results of a test image in GOPRO
3.4 真实图像去模糊实验
为了进一步验证UDBD-Net模型的性能,使用真实的离焦模糊图像进行去模糊实验。实验中使用的真实模糊图像是半导体显示面板真实产线上,导电粒子检测过程中线扫相机所拍摄到的离焦模糊图像。图8是UDBD-Net与其他模型对真实模糊图像的去模糊结果对比图。如图8(e)所示,本文所提出的UDBD-Net对于真实均匀离焦模糊图像具有较好的去模糊效果,复原的图像自然,几乎没有伪影。图8中(f)UDBD*表示使用UDBD-Net模型迭代3次的结果,从图中可以明显看出,迭代3次后的去模糊图像更加清晰,且没有增加明显的伪影。对图8中各模型的去模糊图像进行导电粒子检测实验,实验中导电粒子检测算法采用相同的参数,最终实验结果如图9所示。从图9(e)和图9(f)可以看出,经过UDBD-Net去模糊之后的图像在导电粒子检测中的表现要好于去模糊之前的模糊图像;经过UDBD-Net迭代3次后的去模糊图像相较于只迭代1次的图像,其粒子检测结果有大幅提升。DeepDeblur[15],SRN[16]和FWD[23]三个模型的去模糊结果都存在严重的伪影问题,所以在导电粒子检测中出现大量误检,无法在实际生产中使用。

图8 真实模糊图像的去模糊视觉结果Fig.8 Visual results of a true blurred image
3.5 消融实验
消融实验固定模糊核估计网络,对UDBDNet网络中的DFWD模块、FRM模块的有效性进行研究。首先分别用移除FRM模块、替换DFWD模块为FWD模块等方式对UDBD-Net网络进行改造。对改造后的模型进行重新训练,并对训练好的模型进行去模糊测试,其中测试图片是应用了Gaussian8[25]模糊核的GOPRO测试集图片。本文在消融实验中依然使用PSNR和SSIM作为去模糊模型的评价指标。
如表2所示,将DFWD模块换成FWD模块之后,模型的测试结果的PSNR比完整的的UDBD-Net网络下降1.27 dB;将FRM中上下采样操作去除后模型去模糊结果的PSNR下降6 dB左右。SSIM指标在网络改造后都有轻微的下降。综上所述,UDBD-Net网络中的DFWD模块,FRM模块都对提升UDBD-Net的去模糊性能有很大帮助。
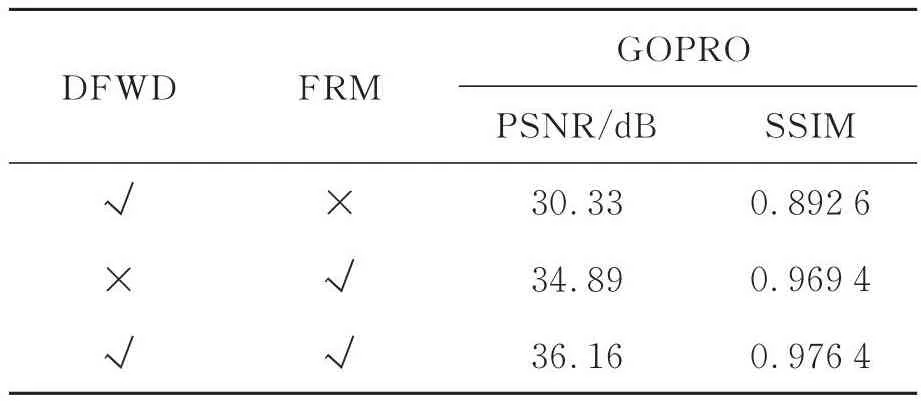
表2 消融实验结果Tab.2 Results of ablation experiment
4 结 论
本文的工作主要是提出一个针对于均匀离焦模糊的图像的两阶段去模糊网络UDBDNet。该网络使用深度回归网络准确估计均匀离焦图像的模糊核,并通过神经网络估计特征维纳反卷积公式中的未知量,改进反卷积网络的性能,最后通过编码解码网络进一步去除错误信息,复原出清晰的图像。通过实验表明,UDBD-Net对于不同离焦程度的合成图像下都能获得清晰自然,伪影少的结果,在DIV2K和GOPRO测试集图片上的PSNR分别达到31.16 dB和36.16 dB。对于真实离焦图像而言,需要使用UDBD-Net模型迭代推理三次,才能得到较理想的去模糊效果。在未来的工作中,将改善网络结构,以提高模型对于真实模糊图像的单次复原能力,并且尝试研究非均匀离焦模糊图像复原。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:30
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01 06:27:42
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
文理导航·教育研究与实践(2015年12期)2015-12-04 00:49:23
电视技术(2014年19期)2014-03-11 15:38:20
