
基于注意力机制的深度学习图像压缩
2023-09-25 13:04:09李玉峰刘倩宇林鹏
现代信息科技 2023年16期
李玉峰 刘倩宇 林鹏


摘 要:图像压缩是一个基础性的研究领域,许多压缩标准已经发展了几十年。最近,基于卷积神经网络的图像有损压缩逐渐取得一系列显著的进展。目前,最有效的基于学习的图像编解码器采用自动编码器的形式,采用了通道调节(CC)和潜在残差预测(LRP)来提高压缩性能,但图像仍然存在空间上的冗余,从而影响到率失真性能。为了使这一问题得到改善,文章提出使用RBAM注意力模块融入网络体系结构中,以提高性能。实验结果表明,用峰值信噪比(PSNR)作为评价指标,文章所提出的网络结构优于传统方法,达到了更好的率失真性能。
关键词:图像压缩;卷积神经网络;注意力机制;潜在残差预测
中图分类号:TP391.4;TP18 文献标识码:A 文章编号:2096-4706(2023)16-0049-05
Deep Learning Image Compression Based on Attention Mechanism
LI Yufeng, LIU Qianyu, LIN Peng
(College of Electronic and Information Engineering, Shenyang Aerospace University, Shenyang 110136, China)
Abstract: Image compression is a fundamental research field, and many compression standards have been developed for decades. Recently, image lossy compression based on Convolutional Neural Networks has made a series of remarkable progress. At present, the most effective image codec based on learning uses the form of automatic encoders, which uses Channel Conditioning (CC) and Latent Residual Prediction (LRP) to improve compression performance, but the image still has spatial redundancy and the rate-distortion performance is affected. To remedy this problem, this paper proposes to integrate the RBAM attention module into the network architecture to improve performance. The experimental results show that the proposed network structure is superior to the traditional method by using the Peak Signal-to-Noise Ratio (PSNR) as the evaluation index, and it achieves better rate-distortion performance.
Keywords: image compression; Convolutional Neural Networks; attention mechanism; potential residual prediction
0 引 言
幾十年来,图像压缩一直是信号处理中实现高质量图像传输和存储的重要基础性研究课题。随着视觉应用的不断增加,有损图像压缩在有限的硬件资源中对高效存储图像和视频至关重要。经典有损图像压缩标准包括JPEG[1]、JPEG2000[2]、BPG[3]和VVC[4]遵循类似的编码方案:变换、量化和熵编码。然而,数字时代多媒体内容的爆炸性增长,对图像压缩编码的有效性和高效性提出了越来越高的要求,广泛使用的传统混合图像编解码器有其局限性。首先,这些方法都是基于图像的分块,引入了分块效应。其次,编解码器的每个模块都与其他模块有复杂的依赖关系。因此,很难对整个编解码器进行联合优化。第三,由于模型不能整体优化,一个模块的局部改进可能不会带来整体性能的提升,使得复杂的框架难以进一步改进。
近年来,随着深度学习的快速发展,已经有许多工作探索了人工神经网络的潜力,以形成端到端的优化图像压缩框架。这些基于深度学习的方法的发展与传统方法有很大的不同。基于变分自动编码器(VAE)[5]的学习型图像压缩在信噪比(PSNR)和多尺度结构相似性指数(MS-SSIM)[6]等指标上取得了比传统有损图像压缩方法更好的率失真[7]性能,显示出巨大的实际压缩应用潜力。Toderici等人的开创性工作[8]提出了一种端到端的学习图像压缩方法,它通过应用递归神经网络(RNN)来重建图像。同时,Ballé等人提出了广义分裂归一化方法[9],用密度模型对图像内容进行建模,显示出了不错的图像压缩能力。
为了开发一种能够与上下文自适应模型的率失真(RD)性能相匹配的图像压缩体系结构,同时最大限度地减少可能导致解码速度变慢的串行处理,Minnen等人提出了两种架构增强:通道调节(Channel Conditioning, CC)和潜在残差预测(Latent Residual Prediction, LRP)[10]。然而,潜在变量的估计分布与真实的边际分布之间仍有差距。在学习图像压缩任务中,很少有研究探讨参数分布模型的影响。针对文献[11]提出的想法,本文引入简化版本的注意力机制,使用残差块来增加更大的接受场,改善率失真性能,并且使学习模型更多的关注复杂区域,以适度的训练复杂度来提高编码性能。
1 基于注意力的端到端图像压缩框架
1.1 简约注意力模块
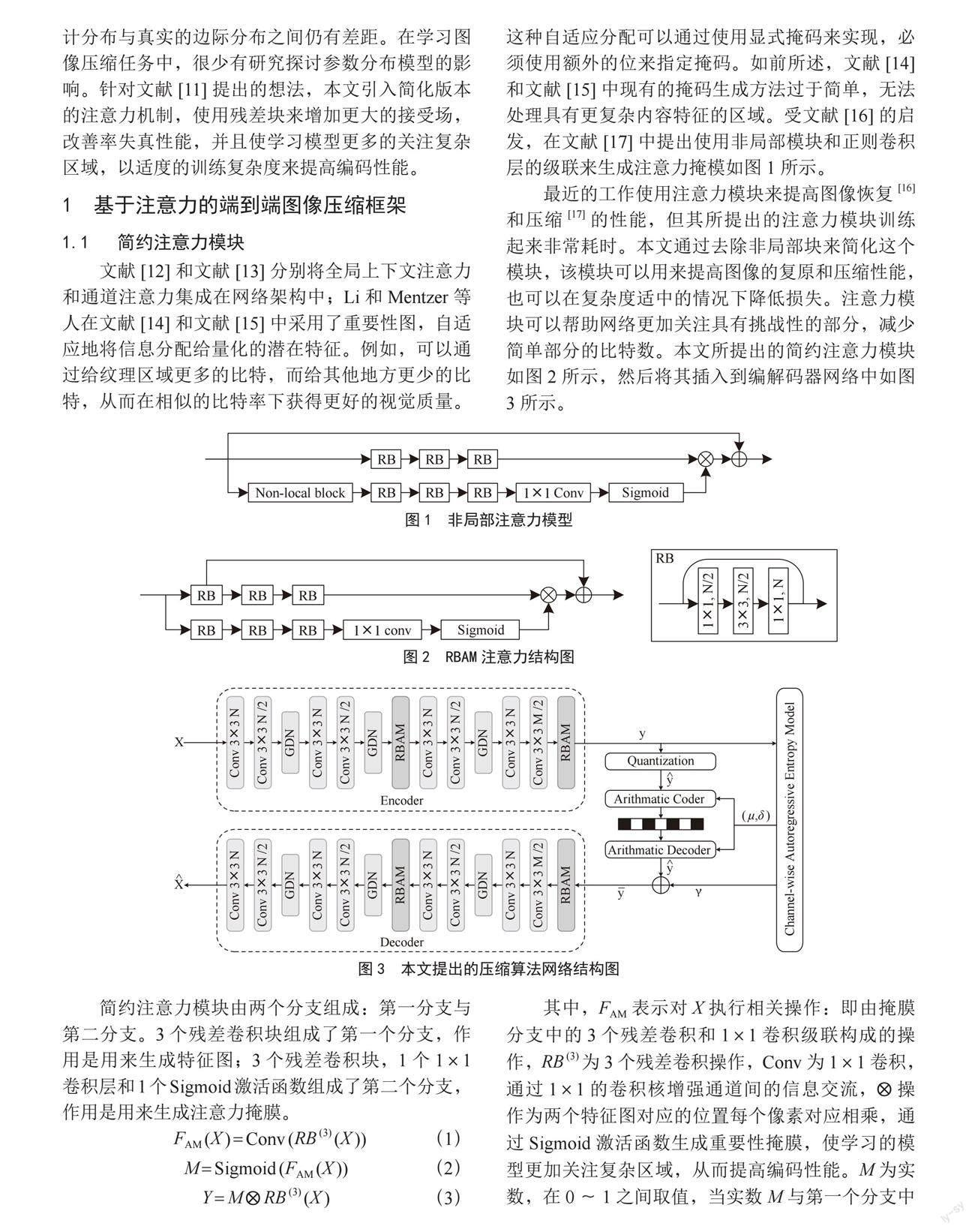
文献[12]和文献[13]分别将全局上下文注意力和通道注意力集成在网络架构中;Li和Mentzer等人在文献[14]和文献[15]中采用了重要性图,自适应地将信息分配给量化的潜在特征。例如,可以通过给纹理区域更多的比特,而给其他地方更少的比特,从而在相似的比特率下获得更好的视觉质量。这种自适应分配可以通过使用显式掩码来实现,必须使用额外的位来指定掩码。如前所述,文献[14]和文献[15]中现有的掩码生成方法过于简单,无法处理具有更复杂内容特征的区域。受文献[16]的启发,在文献[17]中提出使用非局部模块和正则卷积层的级联来生成注意力掩模如图1所示。
最近的工作使用注意力模块来提高图像恢复[16]和压缩[17]的性能,但其所提出的注意力模块训练起来非常耗时。本文通过去除非局部块来简化这个模块,该模块可以用来提高图像的复原和压缩性能,也可以在复杂度适中的情况下降低损失。注意力模块可以帮助网络更加关注具有挑战性的部分,减少简单部分的比特数。本文所提出的简约注意力模块如图2所示,然后将其插入到编解码器网络中如图3所示。
简约注意力模块由两个分支组成:第一分支与第二分支。3个残差卷积块组成了第一个分支,作用是用来生成特征图;3个残差卷积块,1个1×1卷积层和1个Sigmoid激活函数组成了第二个分支,作用是用来生成注意力掩膜。
FAM (X ) = Conv (RB (3) (X )) (1)
M = Sigmoid (FAM (X )) (2)
Y = M ? RB (3) (X ) (3)
其中,FAM表示对X执行相关操作:即由掩膜分支中的3个残差卷积和1×1卷积级联构成的操作,RB (3) 为3个残差卷积操作,Conv为1×1卷积,通过1×1的卷积核增强通道间的信息交流,?操作为两个特征图对应的位置每个像素对应相乘,通过Sigmoid激活函数生成重要性掩膜,使学习的模型更加关注复杂区域,从而提高编码性能。M为实数,在0~1之间取值,当实数M与第一个分支中的特征图每个像素按顺序相乘可以得到Y,再利用一个残差结构让网络在训练过程中能以更高的速度进行收敛。
1.2 超先验图像自编码器
本文基于CNN的端到端图像压缩框架中引入了超先验的编解码模块。在原有传统的基于CNN的图像压缩中,输入图像x经过了主编码器ga后得到了具有空间变化的标准偏差响应y,即通过编码器得到的潜在表示,通过量化器对其进行量化编码后得到输出 ,用量化后的数据概率模型对图像进行熵编码,该概率模型一般为一个已知的联合分布,但是由于实际的分布是未知的,所以该概率模型与实际分布存在差异。为了尽可能地降低概率模型与实际模型的不匹配,我们引入一个新的变量z,然后将z量化、压缩并作为辅助信息传输,用来实现概率模型的精确估计。本文实现概率模型的精确估计由主编解码模型、超先验编解码模型、量化模块、算术模块和通道自回归熵模型等共同实现的。在超先验的模型中,引入超先验作为边信息导入码流,可以很好地对潜在特征点进行结构层次的信息捕获,感知潜在点的结构信息,为潜在表示建立更精确的熵模型。超先验图像自编码器框架如图4所示。
在图像的压缩变换中,编码器ga将给定图像x映射到潜在图像y,经过量化器Q后,得到潜在图像y的离散表示 ,然后使用解码器gs根据 生成重构图像 ,主要过程如下式:
(4)
(5)
(6)
φ和θ表示优化参数。在超先验的方法中,通过引入新的变量z来解决y之间的依赖关系:
(7)
(8)
(9)
其中ha和hs表示自编码器中的分析和合成变换,其中φh和θh表示优化参数。 是基于z的估计分布。再将熵解码结果 输入到主解码器gs端,重建源图像 。最后计算源图像与重建图像的失真,構建损失函数进行端到端的整体优化函数:
(10)
式中L包含两项,其中D表示重建图像与原图的失真度,R表示整体框架的压缩码率,系数λ表示控制速率和失真之间的平衡。
2 通道自回归熵模型
2.1 通道调节熵模型
通道调节模型首先建立在超先验体系结构[18]之上,超先验模型通常使用方差或方差和均值参数化的条件高斯模型,最有效的模型在预测熵参数μ和σ [19-21]之前,将来自超先验(前向适应)的信息与空间自回归模型(后向适应)结合起来。对因果上下文进行条件调节可以更好地建模空间相关性,通常用于标准图像编解码器[22,23],和视频编解码器[24-26]中的帧内预测。在基于学习的编解码器中,模型必须估计空间自回归(AR)模型的参数,会增加解码时间。所以整体架构通过对主编码器生成的潜在表示y进行通道层次的分离,该模型沿通道维度将潜在图像分成N个大致相等的切片,并在先前解码的切片上调节每个切片的熵参数,以此来提高框架的并行能力。
2.2 潜在残差预测
自编码器将输入图像x转换为潜在表示y,这些潜在表示在被无损压缩之前会被量化成 以便于熵编码。在这个过程中不可避免地导致量化误差r = y - ,这部分损失导致解码图片的额外失真问题。
潛在残差预测LRP通过基于超先验模块和先前解码的切片预测残差来减少量化误差,预测残差被逐个切片地添加到量化后的潜在片段,这允许LRP通过减少失真和减少熵来改善结果,因为用于编码后面的切片的熵参数是以包含LRP前面的切片为条件的。
3 实验与分析
3.1 评价指标
本文中使用的评价指标是峰值信噪比(Peak Signal to Noise Ratio, PSNR)[27],PSNR是最普遍,最广泛使用的评鉴画质的客观量测法,PSNR值与图像质量成正比,是一种客观的评价指标,是两个图像峰值误差的度量,如式(11)所示,R表示输入图像的最大值。
(11)
3.2 实验配置
本文实验在配置为NVIDIA GeForce RTX 2080 SUPER、Xeon Silver 4208处理器、2.1 GHz主频、32 GB内存、8 GB显存的实验平台进行训练,实现了本文提出的基于CNN的架构。相关实验设置如下:模型训练批量大小设置为8,模型通道数N设置为192,学习率设置为1×10-4,模型使用Adam优化器。
3.3 方法对比
对于训练,本文从Open Images数据集[28]中随机选择图像,并随机将它们裁剪成256×256的大小。本文通过计算常用Kodak数据集和CLIC专业验证集上的平均RD性能,以此来评估本文的基于注意力机制的图像压缩模型。在训练之后,我们将本文所提出的方法与知名的压缩标准以及最近的基于卷积神经网络图像压缩模型分别在Kodak和CLIC数据集上做了对比,例如JPEG、JPEG2000、BPG、ballé2018、cheng2020、Minnen2020。
图5为在柯达数据集上的比较结果,可以看出本文基于简约注意力的模型优于其他学习的压缩方法,并获得了比以前基于深度学习的方法更好的编码性能。注意机制更多地关注高对比度区域,从而在其上分配更多比特。如图6所示,在CLIC专业验证数据集上的比较结果表明了相同的结论,这表明了我们基于简约注意力模型的鲁棒性。
4 结 论
本文通过结合简约注意力、通道调节模型和潜在残差预测开发了一种于深度卷积神经网络的端到端图像压缩架构,它优于相应的上下文自适应模型,同时最大限度地减少串行处理。由实验结果证实,嵌入了简约注意力模块的网络结构,其率失真性能会有一定程度的提升。在未来的研究中,我们计划在本文的基础上深入探索影响图像压缩中局部细节重建的其他因素,例如熵参数模块,从而更好优化图像压缩算法的率失真性能。
参考文献:
[1] WALLACE G K. The JPEG still picture compression standard [J].Communications of the ACM,1991,34(4):30-44.
[2] TAUBMAN D S,MARCELLIN M W. JPEG2000 Image Compression Fundamentals,Standards and Practice [M].Kluwer Academic Publishers,2002.
[3] BELLARD F. BPG image format (2014) [EB/OL].(2016-08-05).http://bellard.org/bpg/.
[4] BROSS B,CHEN J,LIU S,et al. Versatile video coding (draft 5) [J].Joint Video Experts Team (JVET) of Itu-T Sg,2019,16:3-12.
[5] KINGMA D P,WELLING M. Auto-encoding variational bayes [J/OL].arXiv:1312.6114 [stat.ML].(2013-12-20).https://arxiv.org/abs/1312.6114.
[6] WANG Z,SIMONCELLI E P,BOVIK A C. Multiscale structural similarity for image quality assessment [C]//The Thrity-Seventh Asilomar Conference on Signals,Systems & Computers,2003.Pacific Grove:IEEE,2003:1398-1402.
[7] SHANNON C E. A mathematical theory of communication [J].ACM SIGMOBILE mobile computing and communications review,2001,5(1):3-55.
[8] TODERICI G,O'MALLEY S M,HWANG S J,et al. Variable rate image compression with recurrent neural networks [J/OL].arXiv:1511.06085 [cs.CV].(2015-11-19). https://arxiv.org/abs/1511.06085v5.
[9] BALL? J,LAPARRA V,SIMONCELLI E P. Density modeling of images using a generalized normalization transformation [J/OL].arXiv:1511.06281 [cs.LG].(2015-11-19).https://arxiv.org/abs/1511.06281.
[10] MINNEN D,SINGH S. Channel-wise autoregressive entropy models for learned image compression [C]//2020 IEEE International Conference on Image Processing (ICIP).Abu Dhabi:IEEE,2020:3339-3343.
[11] CHENG Z,SUN H,TAKEUCHI M,et al. Learned image compression with discretized gaussian mixture likelihoods and attention modules [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:7939-7948.
[12] 朱俊,高陈强,陈志乾,等.基于注意力机制和离散高斯混合模型的端到端图像压缩方法 [J].重庆邮电大学学报:自然科学版,2020,32(5):769-778.
[13] 祝启斌,夏巧桥,张青林,等.基于通道注意力的全注意力端到端压缩方法 [J].激光杂志,2022,43(6):96-104.
[14] LI M,ZUO W,GU S,et al. Learning convolutional networks for content-weighted image compression [C]//Proceedings of the IEEE conference on computer vision and pattern recognition.Salt Lake City:IEEE,2018:3214-3223.
[15] MENTZER F,AGUSTSSON E,TSCHANNEN M,et al. Conditional probability models for deep image compression [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:4394-4402.
[16] ZHANG Y,LI K,LI K,et al. Residual non-local attention networks for image restoration [J].arXiv:1903.10082 [cs.CV].(2019-05-24).https://arxiv.org/abs/1903.10082
[17] LIU H,CHEN T,GUO P,et al. Non-local attention optimized deep image compression [J/OL].arXiv:1904.09757 [eess.IV].(2019-04-22).https://arxiv.org/abs/1904.09757.
[18] BALL? J,MINNEN D,SINGH S,et al. Variational image compression with a scale hyperprior [J/OL].arXiv:1802.01436 [eess.IV].(2018-02-01).https://arxiv.org/abs/1802.01436
[19] KLOPP J,WANG Y C F,CHIEN S Y,et al. Learning a Code-Space Predictor by Exploiting Intra-Image-Dependencies [C]//British Machine Vision Conference 2018.Newcastle:BMVA Press,2018:124.
[20] MINNEN D,BALL? J,TODERICI G D. Joint autoregressive and hierarchical priors for learned image compression [J].Advances in neural information processing systems,2018,31:10794-10803.
[21] LEE J,CHO S,BEACK S K. Context-adaptive entropy model for end-to-end optimized image compression [J].arXiv:1809.10452 [eess.IV].(2018-08-27).https://arxiv.org/abs/1809.10452.
[22] Google. WebP:Compression techniques [EB/OL].(2017-01-30).http://developers.google.com/speed/webp/docs/compression.
[23] BOLIEK M,CHRISTOPOULOS C,MAJANI E. Information technology - JPEG 2000 image coding system - Part 1:Core coding system (Fourth Edition):ISO/IEC 15444-1-2019 [S/OL].(2019-10-01).https://www.nssi.org.cn/nssi/front/112033336.html.
[24] REC I. H. High efficiency video coding:265 and ISO/IEC 23008-2 [S].ITU-T and ISO/IEC JTC,2013:20.
[25] CHEN Y,MUKHERJEE D,HAN J,et al. An Overview of Coding Tools in AV1:the First Video Codec from the Alliance for Open Media [J/OL].APSIPA Transactions on Signal and Information Processing,2020,9(1):(2020-02-24)http://dx.doi.org/10.1017/ATSIP.2020.
[26] RICHARDSON I E. The H.264 Advanced Video Compression Standard [M].Wiley Publishing,2010.
[27] TANCHENKO A. Visual-PSNR measure of image quality [J].Journal of Visual Communication and Image Representation,2014,25(5):874-878.
[28] KRASIN I,DUERIG T,ALLDRIN N,et al. Openimages:A public dataset for large-scale multi-label and multi-class image classification [EB/OL].[2023-01-16].https://github. com/openimages.
作者簡介:李玉峰(1969—),男,汉族,辽宁沈阳人,博士,教授,研究方向:图像处理与传输技术;刘倩宇(1998—),女,汉族,辽宁丹东人,硕士研究生,研究方向:图像处理与传输技术;林鹏(1996—),男,满族,辽宁丹东人,硕士研究生,研究方向:信息获取与处理技术。
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
科技创新与应用(2016年35期)2017-02-21 19:16:50
计算机应用(2016年12期)2017-01-13 20:26:21
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
