
基于量子加权最小门限单元网络的出水COD 预测
2023-09-25 12:00张玉泽姚立忠罗海军
环境工程技术学报 2023年5期
张玉泽,姚立忠,罗海军
1.重庆科技学院电气工程学院
2.重庆师范大学物理与电子工程学院
3.重庆国家应用数学中心
出水化学需氧量(COD)是评价城市污水处理效果的重要指标[1]。COD 数值大小代表了水中还原性物质污染的危害程度,当其超标排放时,会造成水体有机物浓度上升,进而危害水生生物和人体健康[2]。研究表明,及时准确掌握和控制出水COD,对水体有机物污染防治具有重要意义[3]。COD 的经典化学法检测耗时长、流程繁杂、易造成二次污染,用于污水处理过程动态调控效果并不理想[4-6];在线COD 监测仪器在一定程度上能弥补上述缺陷,然而在线仪器元件易腐蚀、造价昂贵且稳定性受水样复杂程度影响较大[7-9]。因此,如何经济高效地测量出水COD 是该领域研究的热点问题。
近年来,基于数据驱动的人工智能技术在污水处理过程水质预测领域不断发展。其中,人工神经网络(artificial neural network,ANN)因其强大的非线性系统建模能力而备受关注[10-12]。如贾丽杰等[13]利用ANN 成功预测了出水COD 和生化需氧量(BOD);乔俊飞等[14]提出一种基于自组织模糊神经网络(ILM-SVDFNN)的出水总磷(TP)浓度预测方法,其利用滑动窗口技术构建包含时间序列特征的输入输出关系,提升了水质预测模型性能;李文静等[15]设计了一种基于自组织径向基网络(ASC-RBF)的水质预测模型;廉小亲等[16]给出一种基于自组织特征映射径向基(SOM-RBF)混合神经网络的出水COD 软测量模型构建方案。
然而,利用传统ANN 实现污水处理过程关键水质参数预测,易忽略水质数据的前后依赖关系,导致前序时刻学习的经验信息未能通过隐藏层结点共享给当前时刻;且在水质观测数据增多时,难以存储更多益于预测的历史信息,造成水质预测模型精度偏低。为此,诸多专家学者尝试从时间序列信息记忆的角度出发优化ANN 结构,进而提高污水处理过程水质预测模型性能[17-19]。如高德欣等[20]研究利用循环神经网络(RNN)的反馈内部传递关系提升了出水BOD 预测精度。之后,长短时记忆(LSTM)模型因其在处理时间序列长期依赖关系方面的优势逐渐取代了RNN[21]。Jiang 等[22]利用门限循环单元(GRU)模型以遗忘和重置的方式控制信息流通,提升了出水COD 模型的收敛速度。上述基于门限神经网络的水质预测模型,充分考虑到了水质数据前后时刻信息的内在依赖关系,有效提升了水质参数预测精度。Zhou 等[23]证实了最小门限单元(minimal gated unit,MGU)在结构更简单、参数更少的前提下具有与LSTM、GRU 相当的预测精度。综上所述,将MGU 模型用于污水关键水质参数预测有望进一步挖掘出模型应用潜能。
然而,当前污水处理领域历史数据的保存越来越完备,水质参数类型越来越多,单层MGU 模型难以有效记忆较长时间序列的关键水质信息。若仅进行简单的网络层数堆叠试图增加预测精度,则会导致模型计算量大幅度上升,亦会增加网络出现梯度值逐渐变小并趋近于零或梯度值呈指数级增长的风险,进而致使水质预测模型失效。因此,如何设计快速稳健的MGU 模型结构及训练规则以建立高效率的水质预测模型,是解决复杂污水处理过程重要水质参数准确检测的关键。而量子权值神经网络具有利用训练梯度调整量子比特概率幅来快速更新网络参数、借助三角函数周期性增加收敛解数量的显著特性[24-27]。受此启发,融合量子机制上述特性重新设计MGU 模型构建机制不失为精准检测污水关键水质参数的一种新方案。
为此,笔者通过充分开发量子机制与MGU 构建模型之间的内在关系来调节神经元的信息处理过程,提出量子加权最小门限单元(QWMGU)模型构建与训练规则,在保持预测模型高稳定性的同时,兼顾预测精度和计算效率,并应用于污水处理过程中关键水质参数出水COD 的预测。经德州市污水处理厂实际数据验证,该模型与LSTM、GRU、MGU、量子加权长短时记忆(QWLSTM)、量子加权门限神经(QWGRU)模型等热门预测模型对比,在预测精度和收敛速度方面均有明显优势。另外,该模型有助于污水处理厂及时把控出水水质情况,实现水质在线动态调控。
1 基于QWMGU 网络的模型分析与设计
1.1 量子加权机制调配MGU 结构的核心思想
MGU 是LSTM 的诸多变体之一,其结构如图1所示。
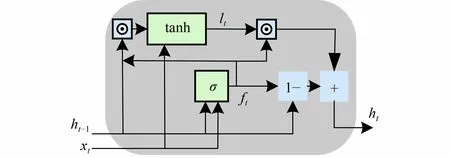
图1 最小门限单元模型结构Fig.1 Structure of minimal gated unit
MGU 模型通常采用 sigmoid (记为 σ)和 tanh作为激活函数,设t时刻的输入为,则MGU 模型的计算过程如下:
式中:ft、lt和ht分别为遗忘门、候选隐藏状态和隐藏层的输出;Wf、Uf、Wl、Ul为MGU 模型的权值;bf和bl为阈值;⊙为矩阵中元素对应相乘。由图1 可知,在单层MGU 模型中,仅有1 组权值矩阵(Wf、Uf、Wl、Ul),较少的参数量便于模型训练与调整。但面对序列过长的水质数据时,单层MGU 模型难以学习到更深层的数据信息,影响预测精度。简单进行MGU 层数堆叠,精度可能会略有提升,但弊端更甚。一是参数量上升,影响学习速度;二是MGU 层数过深,以致网络在反向传播时,依据链式求导原则梯度不断累乘,直至消失或爆炸,进而致使模型失效[28]。而量子权值神经网络通过量子比特概率幅(|δ〉、| ζ〉)替换传统神经网络中的权值,可实现网络参数快速更新;且其自身具有三角函数(| δi〉=[cosλi,sinλi]T、|ζ〉=[cosµ,sinµ]T)的周期性,可以增加传统神经网络的寻优能力,增强模型收敛稳定性。
为此,引入量子机制调配MGU 神经元计算(图2)。在MGU 模型的基础上,使用量子比特概率幅代替式(1)、式(2)中权值(Wf、Uf、Wl、Ul)内的实数值,对神经元的权值赋予量子计算特性,使得MGU 各部分输出受量子加权作用,最终得到QWMGU 预测模型。量子化的加权方式不仅优化了模型内的信息流动,将更多利于预测的特征记忆到隐藏层;而且使得QWMGU 模型的各部分(输入层、隐藏层、候选隐藏状态、输出层)数据处理效率更高,保存更多重要水质信息,进而提升QWMGU 模型的预测精度,使其适于污水处理厂关键水质参数出水COD 的准确预测。

图2 QWMGU 模型调配原理Fig.2 Allocation principle of QWMGU model

图3 QWMGU 模型结构Fig.3 Architecture of QWMGU model
量子加权神经元输入输出关系如下所示:
1.2 QWMGU 模型具体设计过程
依据上述量子机制与MGU 模型融合思想,QWMGU 模型具体设计过程为:
结合式(1)、式(4),可得到QWMGU 模型的遗忘门输出:
结合式(2)、式(4),可得到QWMGU 模型的候选隐藏状态输出:
结合式(5)、式(6)可得到QWMGU 模型的隐藏层输出:
综上可知,新开发的QWMGU 模型沿用了MGU 网络的拓扑结构,其学习训练方式与常规循环神经网络(RNN)类似。因此,使用程阳洋等[28]设计的量子梯度下降反向传播算法对QWMGU 进行更新。在训练QWMGU 的过程中,为实现对QWMGU权值量子位和活性值量子位的更新,需要求得其对应的相位增量。因此,在QWMGU 网络中,需要更新的参数有 |(δw f)ij〉、|(δu f)k j〉、|(δw)ij〉、|(δu)kl〉、|(δwy)k j〉和| (ζwf)j〉、|(ζuf)j〉、|(ζw)j〉、| (ζwy)l〉、| (ζu)j〉。而需要求得的相位增量分别有 ∆(λwf)ij(t)、∆(λuf)k j(t)、∆(λw)ij(t)、∆(λu)k j(t)、∆(λwy)kl(t)、∆(µw f)j(t)、∆(µu f)j(t)、∆(µw)j(t)、∆(µu)j(t)、∆(µwy)l(t)。采用均方误差(MSE)作为QWMGU 网络的逼近误差函数,公式如下:
2 出水COD 预测模型
2.1 QWMGU 预测模型的训练流程
在如前所述的QWMGU 网络模型基础上,结合数据准备和模型训练、模型评价环节,设计得到完整的污水处理过程出水COD 预测流程,如图4 所示。具体流程为:首先,将城市污水处理厂原始数据集进行数据预处理;随后,将处理后的数据集变换为时间序列滑动窗口数据;最后,将其输入到QWMGU预测模型进行训练和测试,并完成污水处理过程中关键参数出水COD 预测。
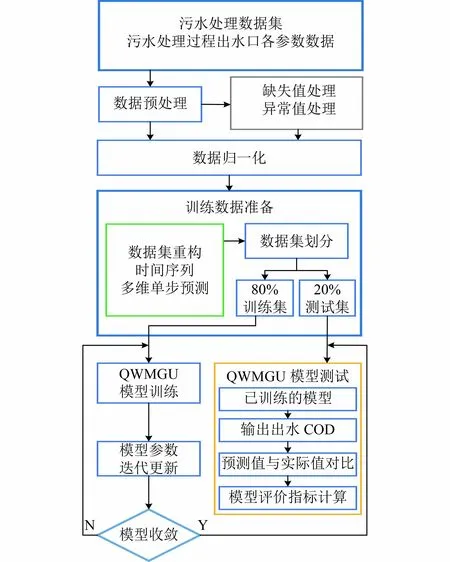
图4 QWMGU 预测模型训练流程Fig.4 Training process of QWMGU prediction model
2.2 数据准备
由于污水处理过程复杂,生化反应繁多,其水质数据易受各种因素影响而产生误差,如进水组分和流量、天气变化频繁、现场环境恶劣、人工操作不当以及测量设备元件老化失真等。轻则影响预测效果,重则导致预测模型失效。因此,在输入出水COD 预测模型前需对数据进行预处理,包括缺失值填充、数据归一化和异常数据剔除。其中,针对缺失情况,采用均值法进行填充;采取线性归一化方法处理数据;为了减少原始水质数据的噪声,对异常数据进行剔除。采用标准分数(Z-score)法,假定数据是满足高斯分布的,而检测到的异常数据点则距离均值较远,超过合理阈值范围。设Zi为数据点xi的得分,Zth为设定阈值,具体计算公式为:
式中:ε为平均值;ρ为标准偏差。经过标准化处理后,若|Zi|>Zth,此时xi被判定为异常值。Zth一般设置为2.5。
2.3 模型训练与评价
使用优化器改进反向传播算法进行模型训练,以提升模型效率。通过试验对比自适应矩估计(Adam)、随机梯度下降(Sgd)、自适应梯度下降(Agd)、标准动量优化(Mon)、在线最优化方法(Fo)、均方根传递(Rms)、近端梯度下降(Pgd)这7 种训练优化器后,选择Adam 为QWMGU 预测模型的优化训练方法。
为量化评价所设计QWMGU 网络预测模型的性能,主要采用均方根误差(RMSE)、平均绝对误差(MAE)、均方误差(MSE)作为误差评价指标,其数值越小,表示预测精度越高。同时采用确定系数(R2)评估模型有效性,其值越接近1,表示预测模型对数据的拟合效果越好。具体计算公式如下:
3 实际案例分析
3.1 案例背景概况
在2021 年的环境状况公告中,德州市废水中COD 的排放总量为38 893.24 t,排放量仍居高位。因此,对德州市污水处理厂出水重要污染物COD 进行预测,对于污水处理厂出水水质的动态调控和水污染的有效防治至关重要。
为验证所设计QWMGU 网络出水COD 预测模型的有效性,使用实际污水处理厂相关数据进行试验。数据来源于山东省德州市某污水处理厂,采集位置均为出水口,采集时间为2020 年1—12 月,周期为1 h,共计8 764 组数据,其中80%用于训练,20%用于测试。另外,所有试验皆基于Vscode、Python 3.64 仿真平台,硬件平台为AMD Ryzen-7-4800U,CPU 频率为1.8 GHz。
3.2 模型参数选取试验
通过分析污水处理工艺机理,并综合考虑数据采集现场情况以及相关专家经验,选取COD、氨氮(NH3-N)浓度、小时流量(WD)、TP 浓度、总氮(TN)浓度和pH 共6 组变量。各出水水质总样本数前3 组数据如表1 所示。

表1 出水COD 预测模型相关变量Table 1 Relevant variables of COD concentration prediction model for effluent water
首先,经过数据预处理筛选出基于正常状态下的污水历史数据。此时,通过数据重构后输入数据维度为“样本数目,时间步数,特征维数”的三维向量,输出数据维度为“出水COD,1”的一维向量。而数据重构技术的重要参数为时间步数,因模型预测目标为获取未来1 h 的出水COD,时间步数是代表使用过去多少时刻的输入数据对应未来1 h 出水COD 的输出数据。其值过大,信息冗余,计算量增加,模型训练速度慢。因此,首先针对时间步数进行测试,组合为[3,6,9,12,24]。结果如表2 所示。
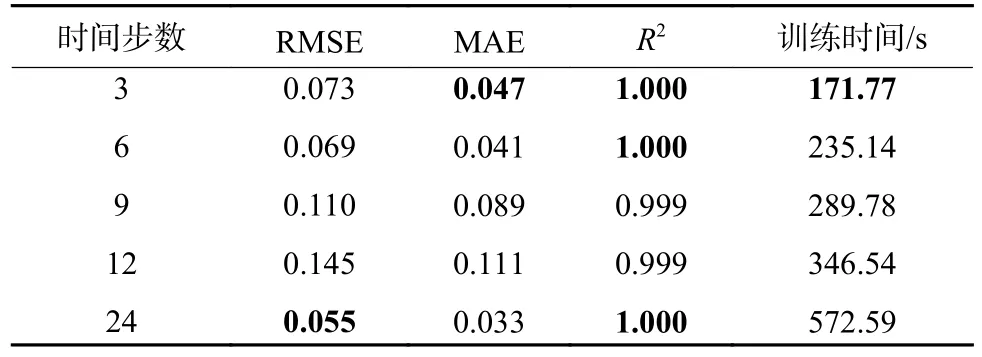
表2 5 种时间步数预测结果对比Table 2 Comparison of prediction results of five timesteps
由表2 可知,当时间步数增加时,训练时间亦逐步增加。在综合考虑时间成本和预测精度后,确定最优时间步数为3。然后,测试隐藏层神经元数目,组合为[5,10,15,20],确定为5;而训练批次测试组合为[32,64,96,128],测试结果为96。为测试QWMGU 模型的稳定性,将模型输出层的激活函数设为Relu,此时模型的稳定性较差,易使神经元坏死,无法参与训练,但收敛速度和预测精度较高。通过对超参数组合(时间步-隐藏层神经元-训练批次)进行测试,每个组合重复30 次,结果如图5 所示。由图5 可知,MGU模型未收敛的次数远超QWMGU 模型。说明本文设计的算法有效增加了收敛概率,侧面反映出量子计算机制增加全局最优解数量,模型稳定性较高。

图5 MGU 与QWMGU 模型收敛稳定性对比Fig.5 Comparison of convergence stability between MGU and QWMGU models
另外,若各评价指标在训练过程中数值较大且保持不变,则认定为模型未收敛。若在实际污水处理过程中模型仍遇到上述未收敛情况,可按照以下解决办法进行操作:1)重新启动模型进行训练,但耗费时间成本;2)通过调整模型的超参数,使之适于具体预测任务。本文所设计算法的高稳定性有助于其适应复杂多变的污水处理过程。
在试验时,不同优化器对于模型训练十分重要,对于训练时间和预测精度都存在较大影响。选择7 种不同优化器测试其性能,由于其训练原理类似,而实现方法不同,所以其参数设置皆为默认情况。重复20 次试验取均值,结果如表3 所示。由表3 可知,QWMGU 模型稳定性远超MGU 模型。在综合考虑模型训练速度、预测精度和模型稳定性3 个方面,选择Adam 优化器训练所设计的QWMGU 预测模型,后续试验模型优化器类型皆一致。
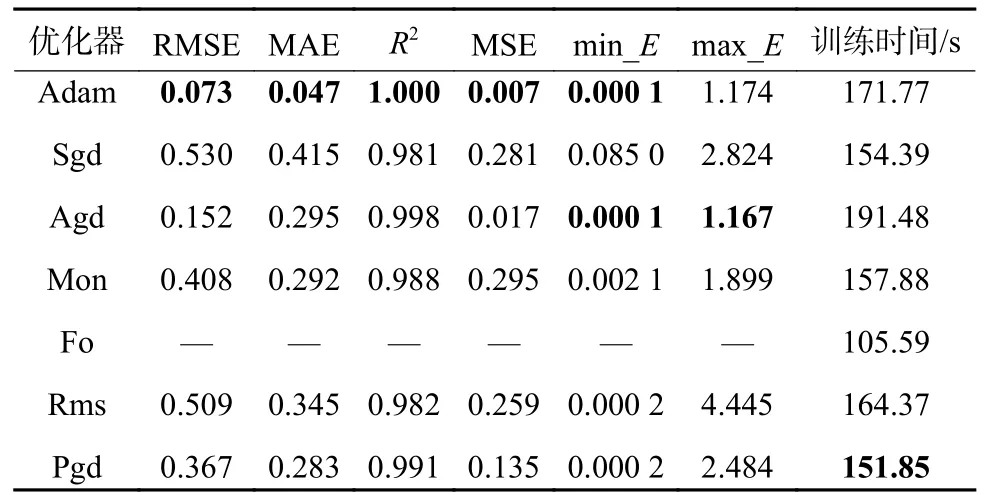
表3 7 种优化器预测结果对比Table 3 Comparison of prediction results of seven optimizers
3.3 模型性能对比试验
在QWMGU 网络中,最终确定隐含层神经元个数为5,时间步数为3,训练批次为96,优化器选择Adam,初始学习速率为0.001,训练次数为1 000。为了验证所提出的基于QWMGU 神经网络的出水COD 预测方法的优越性,选取LSTM、MGU、GRU、QWGRU、QWLSTM 5 种对比算法,其超参数设置、预测方法(输入输出关系)、优化器种类(选用Adam)皆与QWMGU 网络一致,重复训练20 次取平均值,预测结果如图6 所示。

图6 6 种模型预测值与实际值对比Fig.6 Comparison of predicted value and actual value of six models
仅选择30 个样本进行展示,实际测试集样本为数据集的20%。由图6 可知,QWMGU 预测模型的拟合数据与实际值的数据点几乎重合,更加接近出水COD 实际值,说明QWMGU 模型拟合能力较强,更适于污水处理过程中水质参数的快速准确预测。
从图6 与表4 可以看出,相比其他算法,QWMGU模型的预测精度最高,消耗时间较短,说明了算法的有效性。以测试集拟合效果的评价函数RMSE 为例,QWMGU 模型相较于MGU 模型提升约52.3%,相较于QWLSTM 模型、QWGRU 模型分别提升约38.7%、39.7%。可见,通过构造量子相移门矩阵以实现参数更新的方式对于传统MGU 模型各部分在数据处理速度和特征学习能力方面的优化作用效果显著,获得了预测性能更佳的模型结构,在实际污水处理过程出水COD 预测试验中兼顾了预测精度和收敛速度。同时,由于本算法从理论上来说计算效率较高,故可推论当水质预测模型所需计算复杂度进一步增加时,QWMGU 模型虽略慢于MGU 模型,但预测精度将显著提高。此外,引入量子加权思想算法的最小误差和最大误差也普遍小于其他算法,证明引入量子加权机制更适于污水处理过程中关键水质参数出水COD 的快速精准预测。

表4 6 种模型量化预测结果对比Table 4 Comparison of quantitative prediction results of six models
利用LSTM、GRU、MGU、QWGRU 与QWMGU进行收敛速度对比,曲线为归一化后训练集的损失值变化,各预测模型参数设置保持不变(图7)。当迭代次数增加时,6 种预测模型的逼近误差均不断下降,QWMGU、QWGRU、QWLSTM 收敛速度相当,仅选择前200 次迭代进行展示。由图7 可见,3 种算法的曲线皆在MGU、GRU、LSTM 的下面,说明融入量子加权机制的神经网络预测模型普遍具有较快的收敛速度,证明QWMGU 预测模型有助于污水处理厂及时把控出水水质的情况,进而实现德州市水污染的有效防治。

图7 6 种模型Loss 曲线对比Fig.7 Comparison of Loss curves of six models
4 结论
(1)针对污水处理过程中关键水质参数出水COD 难以快速准确预测的问题,提出了基于QWMGU模型的预测方法。从计算效率和预测精度2 个方面对传统MGU 模型进行了改进:在计算效率方面,将量子计算并行性优势引入到传统MGU 模型各结构中,提升模型计算效率;在精度方面,使用量子比特概率幅替代原模型的权值进行更新,提升了模型的信息记忆能力,进而提高预测精度。另外,利用量子比特三角函数特性增加了收敛解的数量,提升了模型收敛稳定性。
(2)利用实际污水处理厂水质数据,将5 种流行预测模型(MGU、GRU、LSTM、QWGRU、QWLSTM)进行试验对比,结果显示,QWMGU 预测模型的测试集评价函数(RMSE、MAE、R2、MSE)均为最优,且min_E和max_E相对较小。证明QWMGU模型具有较高的预测精度,同时保证了计算效率,满足污水处理厂的快速准确预测要求。
(3)QWMGU 预测模型为污水处理过程关键水质参数快速准确预测提供了方法,可实现污水处理厂水质的在线动态调控,对于德州市水体污染的防治具有重要意义。然而,由于污水处理过程具有强耦合性、时变性、强干扰性等特征,需要水质预测模型有较好的自调整能力以适应复杂工况的变化。因此,如何利用滤波技术动态更新QWMGU 模型中的参数将是下一步研究需解决的重点问题。
猜你喜欢
环境(2023年5期)2023-06-30
青少年科技博览(中学版)(2023年3期)2023-05-11
中国应急管理科学(2022年2期)2022-05-23
今日农业(2021年20期)2021-11-26
小学科学(学生版)(2020年1期)2020-01-19
当代水产(2019年1期)2019-05-16
科学大众(中学)(2019年2期)2019-04-08
资源节约与环保(2018年1期)2018-02-08
西安工程大学学报(2016年6期)2017-01-15
河南科技(2014年23期)2014-02-27
