
基于大数据方法的大连系统性金融风险监测预警
2023-09-25 01:31李艳玲陈丹丹
中阿科技论坛(中英文) 2023年9期
李艳玲 陈丹丹
(大连财经学院,辽宁 大连 116622)
1 绪论
1.1 研究背景及意义
党的二十大报告指出,防范金融风险还须解决许多重大问题。要强化金融稳定保障体系,守住不发生系统性风险底线。这为新时代处置重大金融风险、维护人民财产安全提供了重要遵循和根本指南。大连是东北地区对外开放的窗口,经济不断发展,不同金融市场之间的联动逐渐加强,金融机构之间的业务交叉日趋密切,金融产品创新不断涌现,金融体系的复杂性变得更加突出。因此,加强对系统性金融风险的监管变得尤为重要。
大数据前沿技术逐渐渗透到各个领域,引发了现代金融业革命性的变革。苗子清等(2020)研究指出,大数据方法因具备及时性、精准性、高颗粒度、大样本量等优势[1],能够很好地完成金融领域的数据分析和信息处理,进一步丰富了监测预警系统性金融风险的手段和工具。将大数据方法应用在监测预警大连系统性金融风险中,一方面可以降低监管成本,另一方面能够及早发现危机信号,采取有效措施,从而进行有效治理,对维护大连经济健康具有重要的现实意义。
1.2 国内外研究现状
国外大数据技术在金融监管领域的应用较为成熟,主要有以下方面:一是综合指数法,此方法基于宏观经济和金融市场指标,采用各种统计学加总方法,构建可用于实时监测金融体系风险状况的综合指数,例如Illing等(2006)提出的加拿大金融压力指数[2]。二是逻辑回归法,例如Kumar等(2002)提出的Simple Logit模型用于货币危机预警[3]。三是研究风险传递和金融行业系统性关联的方法,如Nyman等(2021)利用大数据分析法对系统性风险进行评估[4]。
我国学者借鉴国外方法,结合中国特色,创造性地建立了中国的系统性金融风险监测预警模型。李梦雨(2012)利用BP神经网络打造金融风险预警系统[5];刘晓星等(2012)为了更加全面测度我国系统性金融风险,构建了一个完备的金融压力指数测度模型体系[6];李敏波等(2021)通过马尔可夫区制转换模型,对金融市场压力状态进行辨识[7]。综上所述,国内研究学者都是基于国家层面来使用大数据方法对系统性金融风险进行监测预警,但对区域系统性金融风险的监测预警也应同样重视。所以本文选择大连这一区域,使用大数据方法对其系统性金融风险进行监测预警。
2 大连系统性金融风险监测预警模型构建
2.1 指标选择原则
王克达(2019)认为针对不同金融风险的成因、影响范围和监管机构等因素,在建立风险预警指标体系时需要选取不同的具体指标[8]。虽然各指标的选择方式不相同,但是要保证指标体系的科学性与完整性,还必须遵守科学性、典型性和可得性原则。
2.2 构建大连系统性金融风险预警指标体系
本文构建的大连系统性金融风险预警指标体系在遵循以上预警指标选取原则的基础上,参考了相关的金融监管机构的监管指标,并结合国内外学者的研究成果。在指标选择过程中,充分考虑了各种因素,并综合考虑其实际操作性和数据获取难易程度,最终以外部经济、大连宏观经济和大连金融机构这3个维度作为一级指标,并在此基础上选择了相应的10个二级指标。同时,本文借鉴相关文献的风险等级临界参数,设定划分指标内的预警界限,各指标具体的预警界限如表1所示。
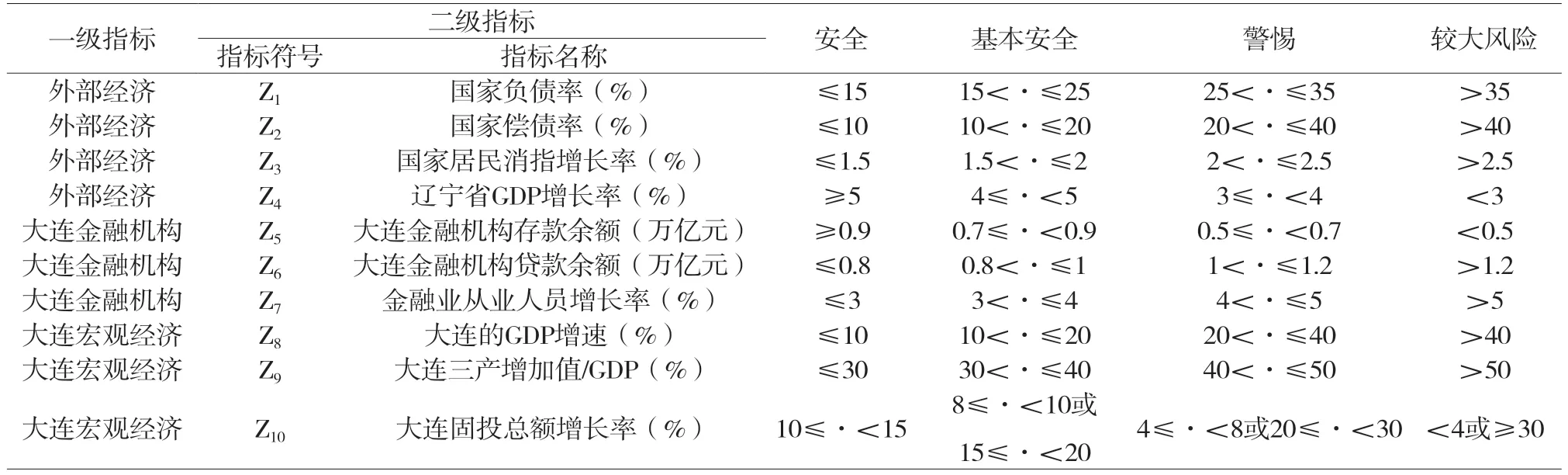
表1 大连系统性金融风险指标预警界限
3 基于径向基神经网络的大连系统性金融风险预警实证
3.1 模型数据的处理和期望值确定
本文样本选择2005—2020年的年度数据,选择的原因是数据的可得和全面。数据来源于历年《中国统计年鉴》、历年《大连统计年鉴》和万方数据库等。由于所选指标的计量单位不同,无法直接进行指标间的比较。另外,在数据分析过程中,需考虑径向基(RBF)神经网络的收敛问题。为消除数据量级和量纲对分析过程的影响,本文先对各指标的原始数据进行了处理。接下来,本文确定了输出节点和期望输出值,主要在Jupyter Notebook中使用python对10个输入样本进行主成分分析。
3.1.1 数据的处理
首先对指标数据进行标准化处理,从而使选出的指标可以相互比较。将收集到的原始指标数据导入Jupyter Notebook中,使用StandardScaler函数对数据进行归一化处理,并返回归一化后的结果。StandardScaler是Sklearn库中提供的归一化函数,它能够将数据中的每个特征转化为均值为0、方差为1的标准正态分布的数据。
3.1.2 主成分分析
主成分分析(PCA)的核心思想是利用数据降维,对多个指数进行线性变换,得到若干不相干的综合指数。各主元分量均为原变量线性合成,各主元分量间无相关性。用这种方法得到的主要元素拥有更好的性能,变量能更好地抓住问题的本质,从而简化了系统结构。在PCA中,需要确定的是特征值大于1并且累积方差贡献率大于85%的前n个主成分。经过分析,本文前三个主成分满足这些要求,这三个主成分的方差贡献率分别为0.650 35、0.160 04和0.081 99。通过三个主成分的方差贡献率,可以得到整体金融风险情况F的得分,具体如表2所示。
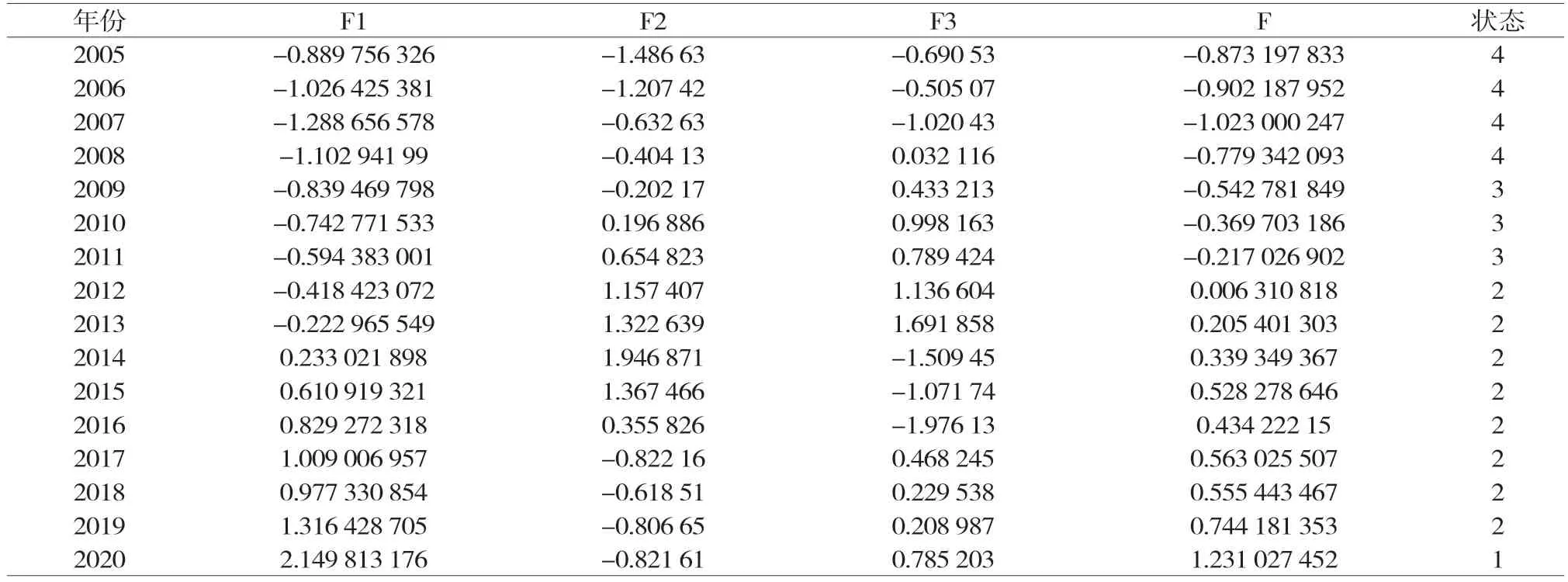
表2 各主成分得分及综合得分表
从表2数据可以看出,大连的系统性金融风险一直在降低。20世纪90年代大连经济飞速发展,虽然从2000年开始大连GDP增速有所减缓,但前期经济高速发展使其金融体系变得不稳定,2005—2008年虽然系统性金融风险一直降低,但仍处于较大风险状态。而到2008年以后,国家宏观经济增速放缓,大连的系统性金融风险也逐渐降低,到2012年进入相对安全状态。本文使用SPSS对上述数据进行了聚类分析,根据数据之间的相似度对它们进行分类,结果如图1所示。经过聚类分析,将数据分为四类:“较大风险”“警惕”“相对安全”以及“安全”。
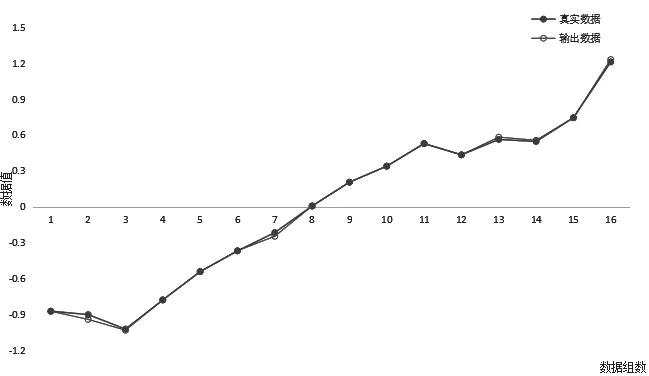
图1 数据拟合图
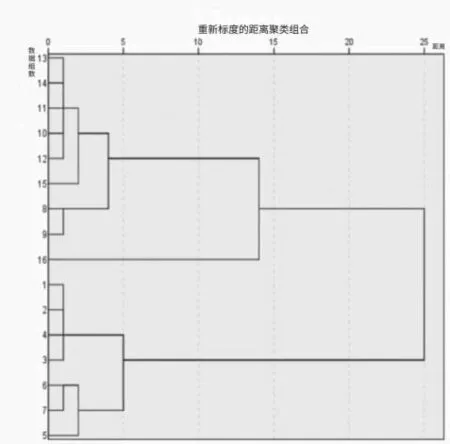
图1 各主成分及综合得分聚类分析结果图
通过分析得出,本文将大连系统性金融风险阈值划分为较大风险(-∞,-0.8]、警惕(-0.8,0.006]、相对安全(0.006,1.2]和安全(1.2,+∞)。
3.2 径向基神经网络模型的训练与测试
径向基神经网络(RBFNN)是一种非线性模型,它基于神经网络,具备出色的逼近能力和泛化能力。它的工作原理是将输入数据映射到高维空间中,然后使用线性模型进行分类或回归等任务。RBFNN的结构包含三个部分:输入层、隐含层和输出层。输入层接收原始数据,并将其传递到隐含层。隐含层由一组径向基函数组成,这些函数将输入数据映射到高维空间中。径向基函数通常是高斯函数或者多项式函数等。隐含层的每个神经元都代表一个径向基函数,其输出值是输入数据与该函数中心点之间的距离。隐含层的输出被送到输出层,通过权重矩阵和偏置项进行线性组合,得到最终的输出结果。本文主要基于径向基神经网络模型,来对系统性金融风险达到预警目的。在Jupyter Notebook中使用randperm()函数,从2005—2020年的数据样本中随机选取了13年的数据作为训练集,剩下3年的数据则作为测试集。这样能够保证模型的公正性与有效性,提高训练结果在实证中的可靠性。
3.2.1 模型构建和参数设置
靠近地平线的太阳,像一团快要熄灭的火球,几乎被那些混混沌沌的浓雾同蒸气遮没了,让你觉得它好像是什么密密团团,然而轮廓模糊、不可捉摸的东西。这个人单腿立着休息,掏出了他的表,现在是四点钟,在这种七月底或者八月初的季节里——他说不出一两个星期之内的确切的日期——他知道太阳大约是在西北方。他瞧了瞧南面,知道在那些荒凉的小山后面就是大熊湖;同时,他还知道在那个方向,北极圈的禁区界线深入到加拿大冻土地带之内。他所站的地方,是铜矿河的一条支流,铜矿河本身则向北流去,通向加冕湾和北冰洋。他从来没到过那儿,但是,有一次,他在赫德森湾公司的地图上曾经瞧见过那地方。
模型的构建需要确定输入层、隐含层以及输出层的节点数。对数据进行聚类获得径向基函数的宽度向量、输出层的连接权值以及阈值进行随机初始化,模型初始化完成。本文将模型的隐含层节点数设置为8,输入层节点数设置为3,输出层节点数为1,最大训练次数为1 000,停止迭代训练条件0.000 8,学习率为0.01。
3.2.2 模型的训练和测试
为了训练模型,需要将模型的输出结果与前面的数据进行比较,并计算两者之间的误差值。在此基础上,对输入层、隐含层、输出层三个层次的连接权值进行了调整。这个过程需要重复进行,直到整个样本的误差值符合预先设定的准确度要求。通过这种迭代循环的方式,能够得到更加准确、稳定以及实用的预测模型。当迭代到一定次数,损失值变化不明显,优化成功。
根据训练结果,保存更新的权值和偏置,模型训练结束。将保存好的权值和偏置代入训练好的模型,使用测试集来核验模型的正确性。将2005—2020年的训练集与测试集的模型输出值与相应年度的真实值进行对比得到图1,从图1可以看出,模型输出数据与真实数据拟合基本一致。
3.3 大连系统性金融风险预测
4 结论
本文运用主成分分析、径向基神经网络模型和聚类分析这三种大数据方法对大连系统性金融风险预警进行了实证研究,选取了10个指标构建大连系统性金融风险预警指标体系,对大连系统性金融风险状态进行了判定。结果显示,大连在2005—2008年处于较大风险状态;2009—2011年处于警惕状态;从2012年开始大连进入相对安全状态。基于训练测试完毕的径向基神经网络模型输入大连2021年的指标数据对大连2022年的系统性金融风险做出了预测,结果显示2022年大连系统性金融风险为安全状态。总体来说,大数据技术在系统性金融风险研究中的应用,可以帮助金融机构更加准确地识别风险因素,并进行风险预测和决策,更好地实现风险监测和控制,从而降低金融风险的发生概率和影响程度,其应用前景将会越来越广阔。
猜你喜欢
中学生数理化·高一版(2021年3期)2021-06-09
中国新闻周刊(2021年9期)2021-03-29
数学物理学报(2021年1期)2021-03-29
重型机械(2020年3期)2020-08-24
大社会(2020年3期)2020-07-14
数学年刊A辑(中文版)(2019年3期)2019-10-08
当代陕西(2019年15期)2019-09-02
辽宁经济(2017年12期)2018-01-19
中国男科学杂志(2016年5期)2016-12-01
山西农经(2016年3期)2016-02-28
