
融合神经网络GRU和RRT*算法的机械臂路径规划*
2023-09-25 13:16欧阳勇
组合机床与自动化加工技术 2023年9期
周 哲,欧阳勇
(湖北工业大学计算机学院,武汉 430064)
0 引言
随着工业时代的快速发展,机器人在各行各业都得到广泛应用,包括工业制造、医疗、运输等[1-2],如何在不触碰障碍物的条件下完成轨迹规划任务是研究的重点。
理想的轨迹规划算法通常具有以下特性:完备性、最优性以及算法效率。目前机械臂轨迹规划算法通常可以分为基于图搜索的规划算法和基于随机采样的规划算法[3]。基于图搜索的规划算法有深度优先搜索[4]、广度优先搜索[5]、Dijkstra算法[6]和A*算法[7]等。这类基于图搜索的算法适用于低维空间,具有较好的完备性,但是在高维空间算法效率大大降低。
为了解决维度问题,专家学者们提出了基于采样的规划算法,这类算法通过在构型空间(C-space)中随机采样构建无碰撞路径图,主要算法包括概率路图算法(PRM)[8]和快速随机搜索树算法(RRT)[9],以及RRT算法的衍生,RRT-Connect、RRT*[10]等。这类基于采样的算法都具备完备性和快速性,但仍有如下缺点:①生成的轨迹主要由折线组成,因此平滑性较差;②由于是随机采样,所以每次采样点较多,造成资源的浪费。
为了解决上述问题,提出了融合神经网络GRU和RRT*的路径规划算法。GRU为了解决其他神经网络算法存在的梯度下降和梯度爆炸的问题[11],通过重置门和更新门决定哪些信息将最后被门控循环单元输出,并且能够长期的保存长期序列中的信息。利用该采样器,GRU-RRT*算法有效的避免了搜索的随机性,引导RRT*向着终点延伸,减少规划次数,增强算法探索能力,提高了算法搜索树的探索效率,减少规划的时间。
1 改进RRT*算法
1.1 RRT*算法
RRT*算法是一种基于随机采样的规划算法,传统的RRT*算法在RRT算法的基础上增加一个重连的操作,以初始点在配置空间中构建随机采样树扩展,满足RRT算法快速搜索的同时,达到渐进最优的目的。
RRT*算法流程图如图1所示,从初始点qinit出发,构建初始随机搜索树Tinit,利用GRU-Sampler进行采样,选择无碰撞的节点qrandom,选择搜索树中距离qrandom最近的节点qnear,从qnear向qrandom方向延伸一条步长step的路径,生成最新的节点qnew,同时判断新生成的节点路径是否有碰撞,如果有碰撞,再找下一个采样点,否则,将最新的节点qnew加入随机搜索树T中,qnear为其父节点,重复以上过程,直到随机搜索树搜索到目标点qgoal为止。在搜索树插入新节点的过程中,RRT*算法会进行一个重选父节点的操作,在找到qnew节点后,在范围内重新选择父节点,如果该父节点代价更小,则以该点作为父节点进行延伸;重选父节点之后,以qnew作为父节点遍历范围内的其他点,寻找代价最小的一条为搜索树的路径。
1.2 简单采样和GRU门控神经网络集成
1.2.1 GRU门控神经网络
GRU门控神经网络是在LSTM神经网络的基础上进行的简化,只留下重置门和更新门,减少了权重参数的个数,GRU门控单元结构如图2所示。

图2 GRU门控单元结构图
图中,Rt为重置门,Zt是更新门,Xt为输入序列,Ht-1为上一个时间步的节点状态,Ht为当前节点状态,br,bh,bz为偏置项。更新门决定上一节点隐藏状态的更新,将上一个时间步的Ht-1和输入序列Xt投入到sigmoid激活函数中,选择重要的信息进行保留;重置门对当前输入隐藏状态的记忆进行重置,忘掉上一个时间步不重要的信息。
Rt=σ(XtWxr+Ht-1Whr+br)
(1)
Zt=σ(XtWxz+Ht-1Whz+bz)
(2)
输入参数通过重置门与上一个时间步的状态的哈达玛乘积得到候选隐藏状态。
(3)
真正的隐藏状态是更新门与上一个时间步的状态和当前步的候选隐藏状态哈达玛乘积之和。Zt的值决定上一个时间步的状态和候选隐藏状态有多少能够传递下去。
(4)
1.2.2 GRU采样器
GRU-RRT*算法于RRT*算法的主要区别在于采样方式的不同,RRT*算法在给定范围内进行随机采样,时间代价大,收敛速度降低,而GRU-RRT*算法采用了一种新的方法生成节点,将GRU应用于基于采样的规划器。
GRU采样器是简单采样方法和GRU网络的集成,这种集成使采样器能够从早期的搜索经验中学习,以生成预测节点,并引导通向目标状态的路径,同时更有效的避免障碍。GRU采样器通过消除不满足期望的节点来提高路径规划过程的效率,如图3和图4所示。

图3 随机采样 图4 GRU采样
GRU的构图如图5所示,将预处理数据(初始点,目标点,障碍物)传入GRU采样器中,GRU采样器包括输入层和输出层, GRU神经网络隐藏层和dropout层,dropout层从GRU神经网络中获取输出并将其转化为GRU隐藏层期望的格式,最后通过线性输出层将采样点传出到RRT*算法当中,引导算法对生成节点的预测。
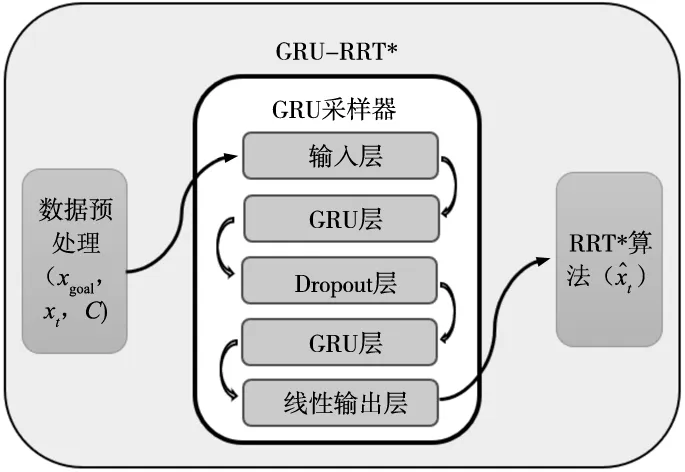
图5 GRU-RRT*算法结构图
(5)


表1 GRU-RRT*算法伪代码

图6 GRU-RRT*算法流程图
1.3 自适应步长
标准RRT算法不会利用扩展时收集到的信息去动态调整步长,固定步长过大或过小都会影响算法收敛速度,最后在搜索树接近目标点时,如果qnearest与qgoal的距离大于qgoal的搜索范围γ,则容易在目标点处振荡,增加规划的时间和路径长度,因此需要对扩展树步长进行自适应操作。因此,使用文献[12]的策略去自适应扩展步长提高算法扩展效率。
(6)
式中:s为初始步长,l为qnearest与qgoal的距离。
1.4 三次样条轨迹平滑
在多项式样条中,三次样条是保证加速度和速度的延续以及有限抖动的最低阶多项式轨迹。高阶多项式会导致更平滑的轮廓,但有更长的运动时间。运用关节空间轨迹规划方法中的三次样条插值函数方法,可以得到位置与时间的函数,及其一阶导数和二阶导数,一阶导数和二阶导数连续即速度与加速度连续。
分段式三次样条函数的通式如下:
s(t)={qk(t),t∈[tk,tk+1],k=0,1,2,…,n-1}
(7)
qk(t)=ak0+ak1(t-tk)+ak2(t-tk)2+ak3(t-tk)3
(8)
上式将整条线段分隔出n条线段,构造出n条三次多项式,ak0,ak1,ak2,ak3均为表达式待定系数,每条多项式有4个未知数,因此总共需要确认4n个未知数。每条三次函数必须满足以下条件:
①区间分隔点xi(xi∈(x0,xn))处的位置,速度和加速度连续;
②初始位置和终点位置的速度为0;

(9)
4n个表达式可以求解出4n个未知系数,利用上述等式,可以得到以下结果:
(10)
(11)
式中:Tk=tk+1-tk,Qk=qk+1-qk。知道每段三次样条曲线所需时间T,即可利用追赶法可以求出中间的速度值,从而得到分段式三次样条插值平滑曲线。
2 实验仿真
为了验证GRU-RRT*算法的有效性,从二维平面和三维空间两个角度分别对RRT,RRT*和GRU-RRT*算法进行验证,通过不同的算法在路径长度,规划时间等方面进行算法验证。
GRU采样器参数设置如下,GRU神经层设置80个神经元,利用Adam优化器调整学习率,将学习率设置为0.000 1,中间dropout层选择0.5的丢失率来最小化损失值,激活函数为tanh。
2.1 二维地图仿真
二维地图的环境场景大小设置为500×500,初始坐标点qinit为(1,1),目标点qgoal为(19,19),随机在地图中摆放障碍物,GRU-RRT*设置起始步长为1,目标点区域半径设置为0.35。4种算法在二维平面下的规划如图7~图10所示。
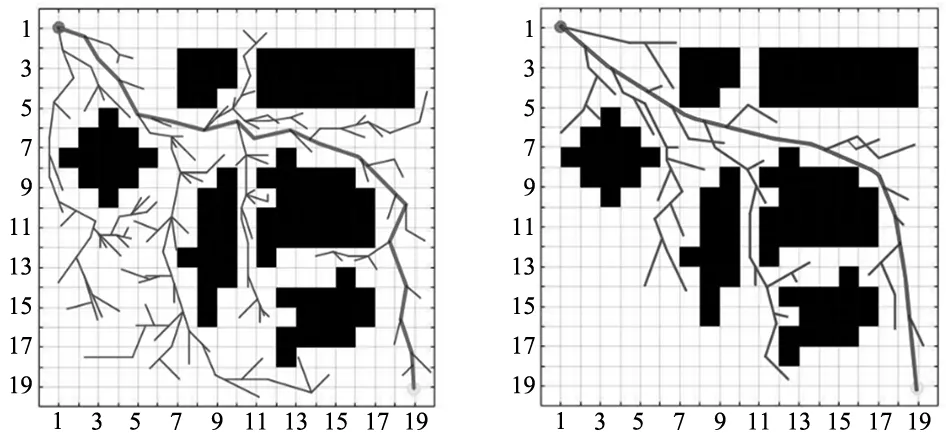
图9 RRT*二维规划图 图10 GRU-RRT*二维规划图
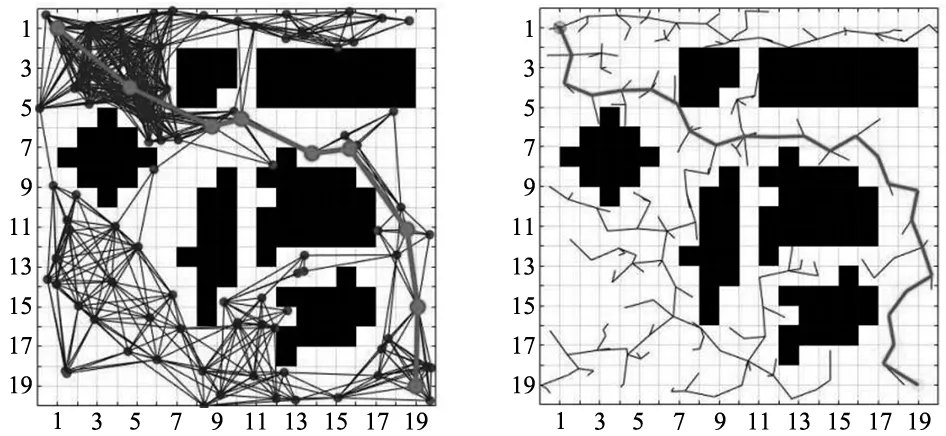
图7 PRM二维规划图图8 RRT二维规划图
如表2所示,分别将PRM、RRT、RRT*和GRU-RRT*算法在二维地图上做20次实验取平均值,平均路径长度为31.192 3,耗时0.893 s,相比于PRM、RRT和RRT*,平均路径长度缩短了11%、18%、6%,在时间损耗上分别降低了1.04 s、0.76 s、0.233 s。在二维栅格地图中,改进算法无论在长度规划还是在算法运行时间上,效率都高于原始算法。
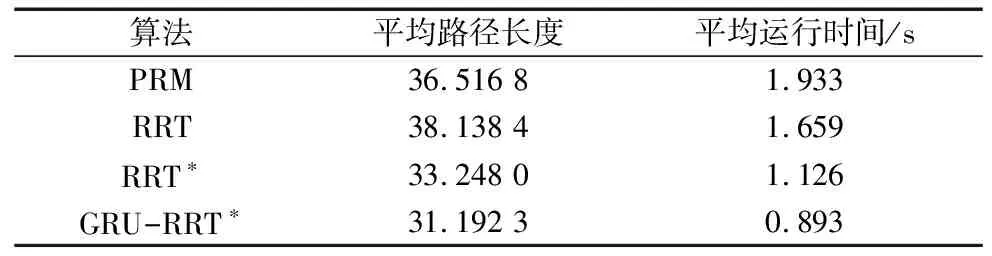
表2 算法结果对比图
2.2 三维地图仿真
三维地图的环境场景大小设置为100×100×100,初始坐标点qinit为(1,1,1),目标点qgoal为(99,99,99),随机在地图中摆放障碍物,GRU-RRT*设置起始步长为8,目标点区域半径设置为3,4种算法在二维平面下的规划如图11~图13所示。
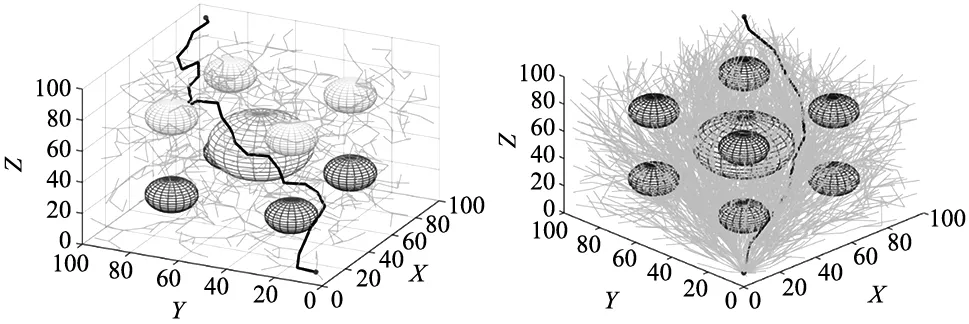
图11 RRT算法三维规划图 图12 RRT*算法三维规划图
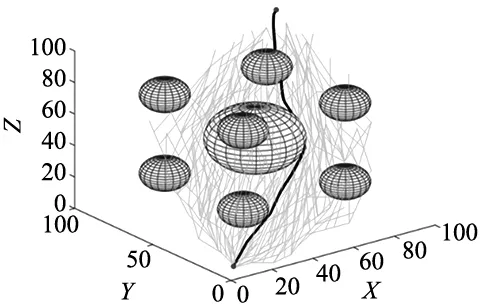
图13 GRU-RRT*算法三维规划图
由表3可知,在经过20次实验之后,改进算法平均耗时7.692 s,平均路径长度为172.961 1,较改进之前快了2.293 s,长度也缩短了17.632 5。

表3 算法结果对比图
利用睿尔曼机械臂模型在rviz上进行仿真,图14为GRU-RRT*算法的仿真效果图,灰色部分为设置5个障碍物a,b,c,d,e。在机械臂从起始点到目标点移动的过程中,GRU-RRT*算法很好的避开了所有的障碍物,同时运行轨迹也十分平滑。

图14 睿尔曼机械臂轨迹规划
3 结束语
针对机械臂的轨迹规划,提出了融合神经网络GRU的RRT*算法,解决了原始RRT*算法存在的收敛速度慢,路径质量差的问题。
(1)提出将门控神经网络算法GRU算法作为采样器,替代RRT*算法中的随机采样来生成节点,预测扩展树节点生成方向,同时将RRT*算法步长进行自适应,减少轨迹搜索的时间,提高了算法的收敛速度。
(2)利用分段三次样条曲线对规划的路径进行平滑,最后得到一条满足要求的平滑的曲线。
分别在二维、三维环境下使用不同地图对该算法进行仿真测试,GRU-RRT算法在轨迹规划和平滑上都有显著的效果,验证了该算法的可行性。
猜你喜欢
安徽师范大学学报(自然科学版)(2022年3期)2022-07-14
成都信息工程大学学报(2021年5期)2021-12-30
商品与质量(2020年21期)2020-11-26
中国化工贸易·上旬刊(2020年1期)2020-09-10
商品与质量(2020年10期)2020-07-10
制造技术与机床(2017年7期)2018-01-19
软件(2017年6期)2017-09-23
计算机测量与控制(2017年6期)2017-07-01
河北科技大学学报(2015年5期)2015-03-11
电测与仪表(2014年2期)2014-04-04
