
基于数据挖掘与机器学习技术的低渗储层产量预测
2023-09-23 11:01:48廖璐璐李根生曾义金宋先知高启超周珺
长江大学学报(自科版) 2023年5期
廖璐璐,李根生,曾义金,宋先知,高启超,周珺
1.中国石油大学(北京)石油工程学院,北京 102249
2.中国石化石油工程技术研究院有限公司,北京 102206
低渗储层是非常规油气储层的重要组成部分,其在全球石油天然气供应中的地位日益凸显。随着我国油气能源需求的不断增加,提升储量潜力巨大的低渗储层产量对于保障我国经济发展和能源安全保障至关重要。然而,低渗储层的区域延展性大、油气生产效率低,以及钻井和储层改造作业频繁等特点使得多年在常规油气藏生产作业中所总结出的知识体系与开发方式不能很好的应用于此。另一方面,我国石油公司在海外新区的勘探开发过程中缺乏实践经验。因此,借助以大数据和机器学习为代表的AI技术将是快速掌握储层数据信息、提升认知水平、高效制定工程措施,并实现致密储层降本增效开发的重要契机。
油气田的生产预测至关重要,需要包括地质学家、油藏工程师、采油师和钻完井工程师等多个石油领域专家们的分工合作。好的生产预测需要专业、高效和紧密的团队合作,每个领域的专家在一个项目的分析预测过程中不仅各有分工,且存在时间上的先后顺序。针对油气藏产量预测,前人进行了多方面的探索并得到了许多切实可行的方法,比如通过递减分析和典型曲线分析方法[1];利用二元非线性或多元线性回归出经验公式[2];或者使用计算科学技术进行综合油藏数值模拟[3]。区别于常规油气藏,低渗油气藏开发的成功与工程优化和合同期内的高效开发更加息息相关。因此,一个快速有效的、综合了地理/油藏/工程参数的产量预测模型非常关键。
随着数据量的爆炸式增长、计算资源的日益丰富以及数学算法的不断改善,以数据驱动、机器学习技术等为代表的现代数据科学为传统石油与天然气行业提供了技术变革的可能性。许多国家(国际石油公司)都在此投入了大量的精力,希望发现新技术可以提高、改善甚至取代传统的工业工艺流程。非常规页岩储层开发中产生的大量生产、物性和工程参数为数据挖掘的应用提供了可能性[4]。加拿大非常规油气藏资源丰富、布井密度高,可以提供充足的机器学习样本。一些经典的方法如利用基于图形辨识的人工神经网络方法预测独立变量的变化值大小[5-7];利用基于因变量与多元自变量的多元线性回归方法预测产能[8-12];利用变量结构回归(非线性)方法自动识别模型结构等[13-14];利用支持向量机(SVM)预测岩石物性和提高油藏组分模型的运行效率[15-16];基于随机变量自由组合等原理,利用随机森林(RF)回归方法和梯度提升机方法(XGboost)通过叠加效果较差的初始预测模型最终建立集合优化模型等[17-19]。
基于此,笔者提出了利用大数据挖掘和机器学习技术来解决中石化海外作业者项目中产量的快速预测和工程参数的综合评估问题。该研究收集了来自加拿大Cardium致密储层-Pembina油田的1 200多口油井数据:利用敏感性测试确定了与产量相关的主控因素,在该基础上建立多维数据库,并为之后的机器学习模型建立打下基础。根据敏感性分析结果,筛选出10种与Cardium低渗储层累计产量最为相关的影响参数。通过测试基于不同机器学习技术的预测模型,随机森林算法以其最低误差值、稳定的输出和优异的预测精度脱颖而出。这种以机器学习技术为基础创建的预测流程在时效性和准确度上均具备优势(精度可达85%),可以为现场压裂施工设计优化提供可靠的保障。
1 预测流程
流程分为4个步骤:①针对研究目标区域建立包含样本、协变量和标签值的数据集合;②利用皮尔逊相关系数找寻主控因素和标签函数的关键节点时间;③建立多种机器学习模型,如梯度提升机(XGboost)、随机森林(RF)、支持向量(SVM)和神经网络等,并计算预测模型精度;④利用k-Fold交叉验证方法进一步提升优选机器学习模型的预测精度,如图1所示。
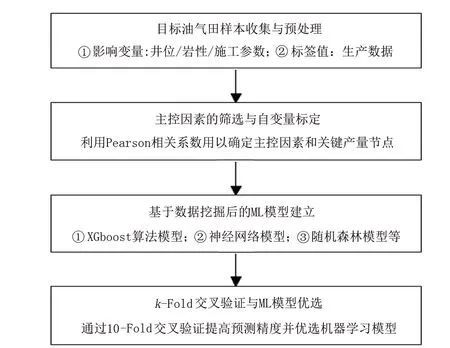
图1 基于数据挖掘与机器学习技术的低渗储层产量预测流程
2 案例概述和数据库
以加拿大阿尔伯塔省的Cardium致密储层为研究案例。Cardium致密储层向东延伸至阿尔伯塔省边界以东约200 km处。厚度从位于西部边界150 m到平原地区的不足50 m不等。Cardium致密储层深度从1 200~2 700 m不等。研究目标位于Range 09-13 &Township45-49区块,宽约50 km,长50 km,平均储层厚度10~20 m。根据预测方法步骤①,将研究区域内的1 286口井经过一系列除杂、清洗和筛选,得到可用的数据样本井为612个,每个样本中包含50种协变量(井位/岩性/工程参数)与5组标签值(3、6、9、12、18和36个月累计产量)。
2.1 主控因素排名
根据预测方法步骤②筛选了10种与标签值相关系数最高的协变量:分别是井位坐标、资源密度、垂直深度、水平井段长度、总压裂段级数、总泵入支撑剂量、单位泵入液量、加砂浓度、排量和有无泥隔层;相较于前人研究的标签参数仅局限在一个固定值上,选取了不同时间节点上的5个累计产量值,由此发现10个主控因素中的6种钻完井工程参数的相关系数存在拐点,即存在时间轴上的系数相关最大值。以水平井长度段为例,如图2(a)所示,不同时间节点上的累计产量值与其相关系数略有不同,计算值在12个月累计产量的分析中达到峰值,其他几个工程参数表现出相类似的特点,如图2(b)所示,判断“到底利用哪个时间节点为最终标签值”做好了数学理论基础依据。
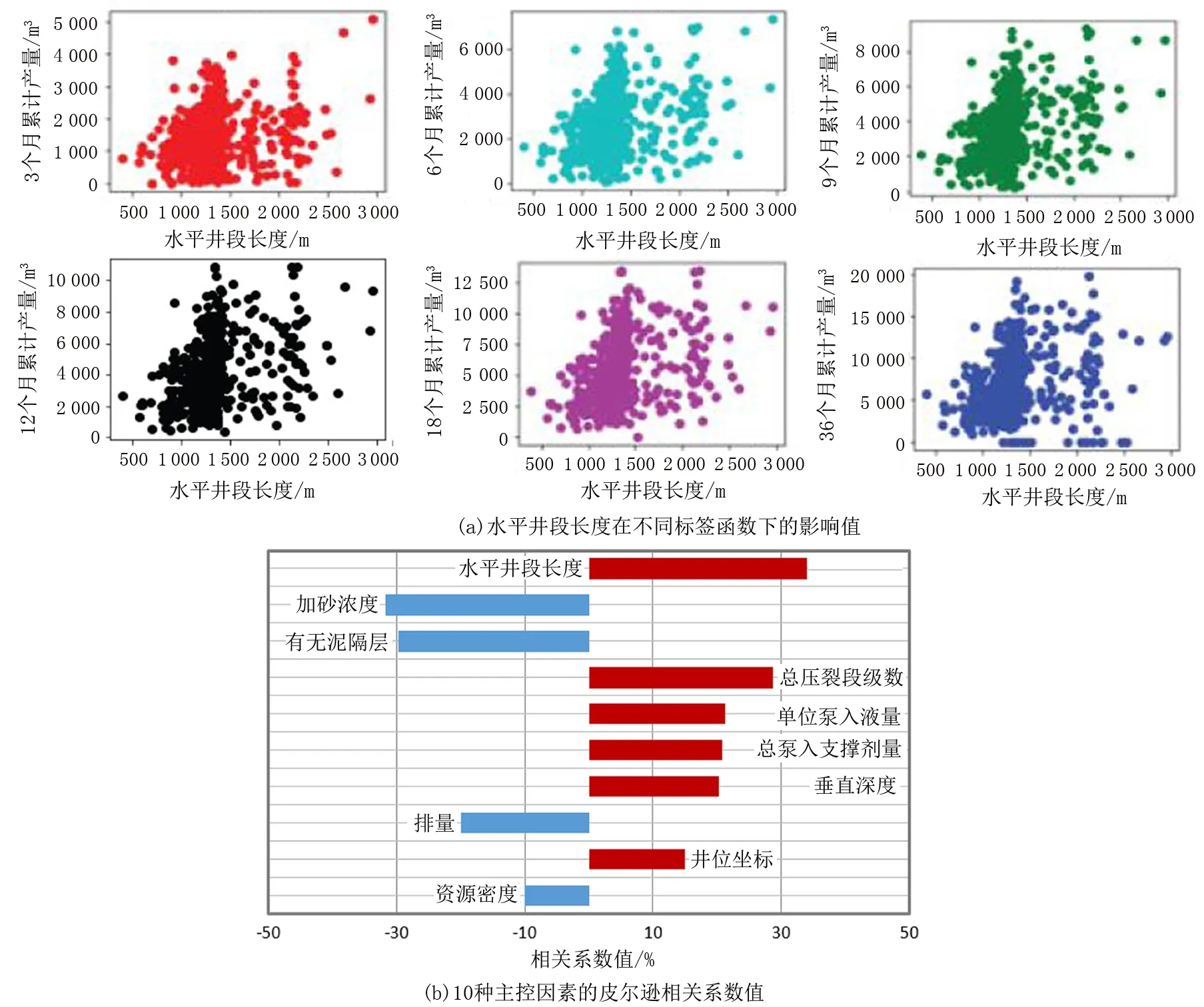
图2 主控因素筛选
2.2 优选算法
尝试了多种机器学习模型,结果表明随机森林算法在同等条件下所得到的误差值最低,拥有最好的表现。图3(a)为决策树的逻辑表达,图3(b)为随机森林的逻辑表达。

图3 算法优选
前文提到的运算条件指的是数据库总样本量、训练集/测试集比例、协变量值、标签值和验证方法等,如表1所示,该模型建立涉及到的总数据量为3万多个,协变量包括27个工程参数与23个非工程参数,标签值的最终选择为12个月累计产量,验证方法为10-Fold交叉验证方法,最终的预测精度到达85%以上。对比不同的运算条件可以看出:①总样本数量的增加可以显著减低误差率;②训练集/测试集比例控制在80∶20~90∶10的区间比较合适,比例过大或过小可能造成过拟合和欠拟合;③协变量数量一定的情况下,标签值选择累计产量为12个月的预测误差值越低,这也与之前皮尔逊相关系数的分析相一致;④k-Fold交叉验证方法可以提高预测精度和稳定性。
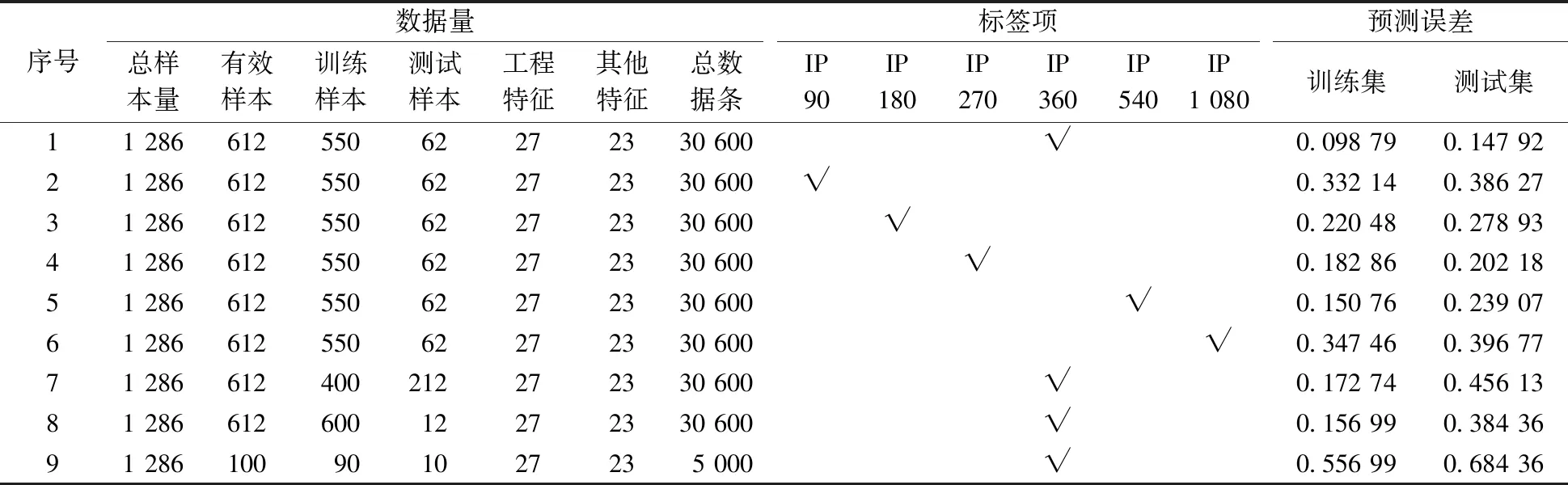
表1 随机森林结果展示
2.3 现场施工参数优化
在油藏地质相似的情况下,认为优选6个工程主控因素将会对Cardium致密储层开发产生积极的作用,研究的最后一项内容则围绕着如何利用数据挖掘解决工程参数优化问题。首先对全区的620口井进行了分类:类Ⅰ为RT-全区,包含全部井的样本(地质油藏条件良莠不齐,水力压裂技术方案多样);类Ⅱ为RT-对比区(该处地质油藏条件较差,未采用改良水力压裂技术);类Ⅲ为RT-西南角(该处地质油藏条件最差,但采用了改良的水力压裂技术),并对此3类的3个月、6个月、9个月、12个月和36个月的平均累计产量进行了对比。需要注意的是类Ⅱ为未来布井的研究区域,分区和具体产值如表2所示。
对比类Ⅰ与类Ⅱ可以看出,在12个月前,RT-西南角的水平井的产量表现更为优异。在地质油藏条件更差的前提下,说明了类Ⅱ储层改造的效果很好,12个月后,地质油藏因素与产量的相关性增强,产量开始更多的受到储层本身性质的影响。12个月产量两类产值持平,而到36个月时全区平均累计产量比西南角仅高出了500 m3左右。另外,12个月这个转折节点也与之前皮尔逊相关系数值的拐点相一致,相互印证。
对比类Ⅰ与类Ⅱ说明,RT-西南角相较于油藏地质同等或稍好的RT-对比区有更高的平均累计产量,并且一直领先。从3个月到36个月累计产量,差值分别为338.02、655.67、822.40、909.42和1 258.18 m3,增速逐渐变缓。综上所述,对比研究的储层改造工艺有很大提高和优化的空间,36个月产值提高可达到25%以上,如图4所示。

图4 RT全区、RT-对比区和RT-西南区在不同 时间上的平均产值对比
研究相应总结与归纳了该6项工程主控参数在类Ⅰ、类Ⅱ和类Ⅲ的数学统计值。以寻求产量差异的工程因素差别,在不同的分区下,施工数据存在个性差别,可以通过对比区(需改进区域)与西南角的工程参数的统计值的对比,为对比区的新井钻完井工程参数设计提供参考意见。水平井段长度方面,类Ⅱ的平均值为1 158.0 m,比类Ⅰ和类Ⅲ的均值小15%~16%,并且全区范围内的长度最小值出现在类Ⅱ,最大值出现在类Ⅲ;压裂级数方面,类Ⅱ的平均值为18.5级,比类Ⅰ和类Ⅲ的均值小5%~12%,并且全区范围内的长度最小值出现在类Ⅱ,最大值出现在类Ⅲ;每米加砂量方面,类Ⅱ的平均值为361.3 kg/m,比类Ⅰ和类Ⅲ的均值高13%~7%,对比各项统计结果为3种类型中的最高值;每米加液量方面,类Ⅱ的平均值为3.6 m3/m,与类Ⅰ持平,比类Ⅲ高出19%;加砂质量浓度方面,类Ⅱ的平均值为481.0 kg/m3,与类Ⅰ持平,比类Ⅲ高出18%;排量方面,类Ⅱ的平均值为7.8 m3/min,与类Ⅰ和类Ⅲ几乎持平(见表3)。

表3 Cardium致密储层水平井-关键完井参数统计表
最终依据皮尔逊相关系数、累计产量对比和不同工程参数的统计情况,基于宏观统计提出对比区域新井的施工改进方案:在原有的基础上将水平井段增加15%~20%;压裂级数相应增加10%~15%,即在原有的段间距基础上保持不变甚至略微加大;每米加砂量和每米加液量保持不变或略微减少;加砂质量浓度在原有基础上减少10%~15%;排量在原有基础上减少5%~10%。采用该改良工程施工方案,并通过本文提到的优化随机森林方法可以预测对比区的12个月或36个月累计产量,结果相较于研究区域的历史平均产量提高15%~20%。考虑到压裂技术水平井段长度、级数和压裂规模等费用的增加,初步计算了基于数据挖掘和机器学习技术改良钻完井参数后的单井创收值,如表4所示。36个月累计提高产量为7185.85桶,考虑桶油操作成本为9.8美元/桶,36个月累计创收43.12万美元,年增收利润约为5.5万美金/井。

表4 Cardium致密储层水平井-采用优化钻完井参数后的年创收效益
3 结论
从大数据的角度出发,在Cardium致密储层建立了地理/物性/工程与生产数据的机器学习模型。完成了该储层600多口水平井的单因素敏感分析,筛选了主控因素,建立并优选了机器学习预测模型,优化后的精度可以达到85%以上。该研究为Cardium致密储层提供了一套切实可行的集数据库建立、主控因素筛选和机器学习方法建立优化等一体的产量预测方法,进而可以更加快速合理地评估储层和降低开发成本。
1)利用皮尔逊相关性分析,在50种协变量中甄选了10个主控因素,分别是井位坐标、资源密度、垂直深度、水平井段长度、总压裂段级数、总泵入支撑剂量、单位泵入液量、加砂浓度、排量和有无泥隔层。参数不仅仅局限在一个固定值上,而是找到了不同时间节点上的5个累计生产产量值,并利用相关值的拐点找到时间轴上的系数最相关值。
2)众多模型中随机森林的预测模型具有最低的误差值,预测精度可以达到85%以上。中小型数据库中可以利用k-Fold交叉验证方法来提升模型预测精度和预测稳定性。
3)训练集/测试集比例控制在80∶20~90∶10的区间比较合适,比例过大或过小可能造成过拟合和欠拟合,另外,通过降低叶子节点维数也可以解决过度拟合的问题。
4)结合皮尔逊相关性研究,Cardium致密储层前12个月累计产量与工程参数更相关,而之后则逐渐受到地质油藏条件的影响。西南角在相同甚至更差的地质油藏情况下,仍然可以通过增加水平井段长度、每米加砂量、每米加液量和减少加砂质量浓度来提高产量。预计在目标区域,通过基于数据挖掘与机器学期技术优化后的钻完井参数将为目标区域创造5~6万美元/井的增收效益。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
云南化工(2020年11期)2021-01-14 00:51:02
云南化工(2020年11期)2021-01-14 00:50:42
西南石油大学学报(自然科学版)(2019年2期)2019-04-25 13:07:26
电力与能源(2017年6期)2017-05-14 06:19:37
西南石油大学学报(自然科学版)(2016年6期)2017-01-15 14:14:10
信息通信技术(2015年6期)2015-12-26 01:16:46
天然气勘探与开发(2015年3期)2015-12-08 08:28:37
西南石油大学学报(自然科学版)(2015年4期)2015-08-20 09:05:24
中国海上油气(2015年3期)2015-07-01 16:32:08
