
基于ECA 和BIFPN 的低照度环境下的行人目标检测算法
2023-09-21 15:49相敏月涂振宇孙逸飞
智能计算机与应用 2023年9期
相敏月, 涂振宇, 孙逸飞, 方 强, 马 飞
(南昌工程学院信息工程学院, 南昌 330000)
0 引 言
行人检测是目标检测的重要研究领域之一,在智能交通、视频监控及无人机等方面的应用十分广泛。
传统的行人检测方法主要依赖于人工提取特征的方式,Dalal 等人[1]于2005 年开发了一种使用方向梯度直方图(Histogram of Oriented Gradient,HOG)特征和支持向量机(Support Vector Machine,SVM)分类器的行人检测模型。 该模型首先使用滑动窗口在图像中识别候选区域;其次,提取HOG 特征并使用SVM 对其进行分类;最后,使用极大抑制方法将输出结果组合在一起。 Felzenszwal 等人[2]在2008 年引入了可变形零件模型(Deformable Part Model,DPM)用于行人检测。 DPM 使用HOG 特征并将图像分成几个部分,DPM 可以使用组件的组合来检测行人,并能够对行人的可变形部分建模,从而更准确地检测不同大小和形状的行人。 这些模型存在明显的局限性,手工特征提取单一,难以适用于遮挡、姿态变化和低照度等复杂环境下的行人目标检测,导致不同程度的漏检和误检等问题。
近年来,深度学习在行人检测中逐渐得到广泛的应用。 这种方法具有强大的表征能力,能够解决传统方法需要人工提取特征的问题。 目标检测从阶段上分为两种,一阶段和二阶段。 一阶段主要包括快速区域卷积神经网络(Fast Region - based Convolutional Neural Network,Fast R-CNN)和更快速的区域卷积神经网络(Faster Region - based Convolutional Neural Network,Faster R-CNN)等,这类网络预先回归一次目标候选框,再利用网络对候选框进行分类和回归,虽然精度较高但检测时间过长。 二阶段主要包括单激发多框探测器(Single Shot MultiBoxDetector,SSD) 和YOLO (You Only Look Once)等为代表,只进行一次分类和定位,大大提高了检测速度,但同时也导致了精度较差。 何自芬[3]等针对辅助驾驶中夜间小目标红外行人检测精度低的问题,提出在网络中添加空间金字塔池化模块与更小的感受野的检测层,来增强网络输出特征图的表征能力;郝帅[4]等通过构建分层注意力映射模块来增强行人特征表达能力;李传东[5]以轻量级LFFD(Light and Fast Face Detector)网络为基础,由两级改进网络组合,提高了检测精度。 但是在低照度环境下,这些研究依旧存在不同程度的漏检问题。
深度学习的行人检测方法大多应用于可见光下的场景,针对低照度等复杂环境下的检测,往往效果较差。 可见光图像的优势在于依据物体的反射率的不同进行成像,光谱信息较多,分辨率较高,图像背景比较丰富,但易受到外界环境因素的影响,在低照度等复杂环境下不能正常工作。 而在红外图像中,受光照条件的影响较少,更容易识别出行人位置。
本文改进YOLOv5s 的主干网络,加入通道注意力机制ECA(Efficient Channel Attention),加强网络对行人特征的初步提取;在颈部网络中引入加权双向特征金字塔( Bidirectional Feature Pyramid Network,BIFPN),通过残差连接增强特征的融合能力;最后,采用公开的韩国科学技术院KAIST 多光谱行人检测数据集作为实验数据,进行模型性能测试,并与YOLOv5 其他模型进行对比。
1 YOLOv5s 模型原理
YOLOv5 通过调整两个参数,即网络深度和特征图宽度划分出多个模型,其中YOLOv5s 深度最小,特征图的宽度最小,是当前一种实时性和准确性俱佳的行人检测模型,并且在多尺度目标检测中具有良好的效果。 所以本文采用YOLOv5s 模型,模型结构如图1 所示。

图1 YOLOv5s 模型结构Fig. 1 YOLOv5s model structure
整个模型结构主要包含4 个部位,分别为输入端(Input)、主干网络(Backbone)、颈部网络(Neck)和头部(Head)检测模块。 检测模块相对于YOLOv3和YOLOv4 没有变化;主干网络(Backbone)主要是用于提取输入图像的特征,Foucs 模块对图片进行切片操作,使网络提取到更加充分的特征信息;颈部网络主要用于生成特征金字塔,增强网络模型对不同尺度物体的检测能力,实现对同一物体不同尺寸和尺度的识别。 YOLOv5s 在特征金字塔网络(Feature Pyramid Networks,FPN)结构的基础上参考路径聚合网络(Path Aggregation Network,PANet),实现了多尺度特征融合,增强了特征的表达能力。
2 改进YOLOv5s 模型
在低照度环境下,行人检测或多或少会存在漏检和误检的问题,本文在YOLOv5s 的基础上,在主干网络中插入ECA 通道注意力机制,提升模型对低照度环境下行人细节的提取能力;在颈部网络中,用BIFPN 网络来代替PANet 网络,使得模型可以更精确的识别行人目标,加快特征融合。 改进后的BEYOLOv5s 模型结构如图2 所示。
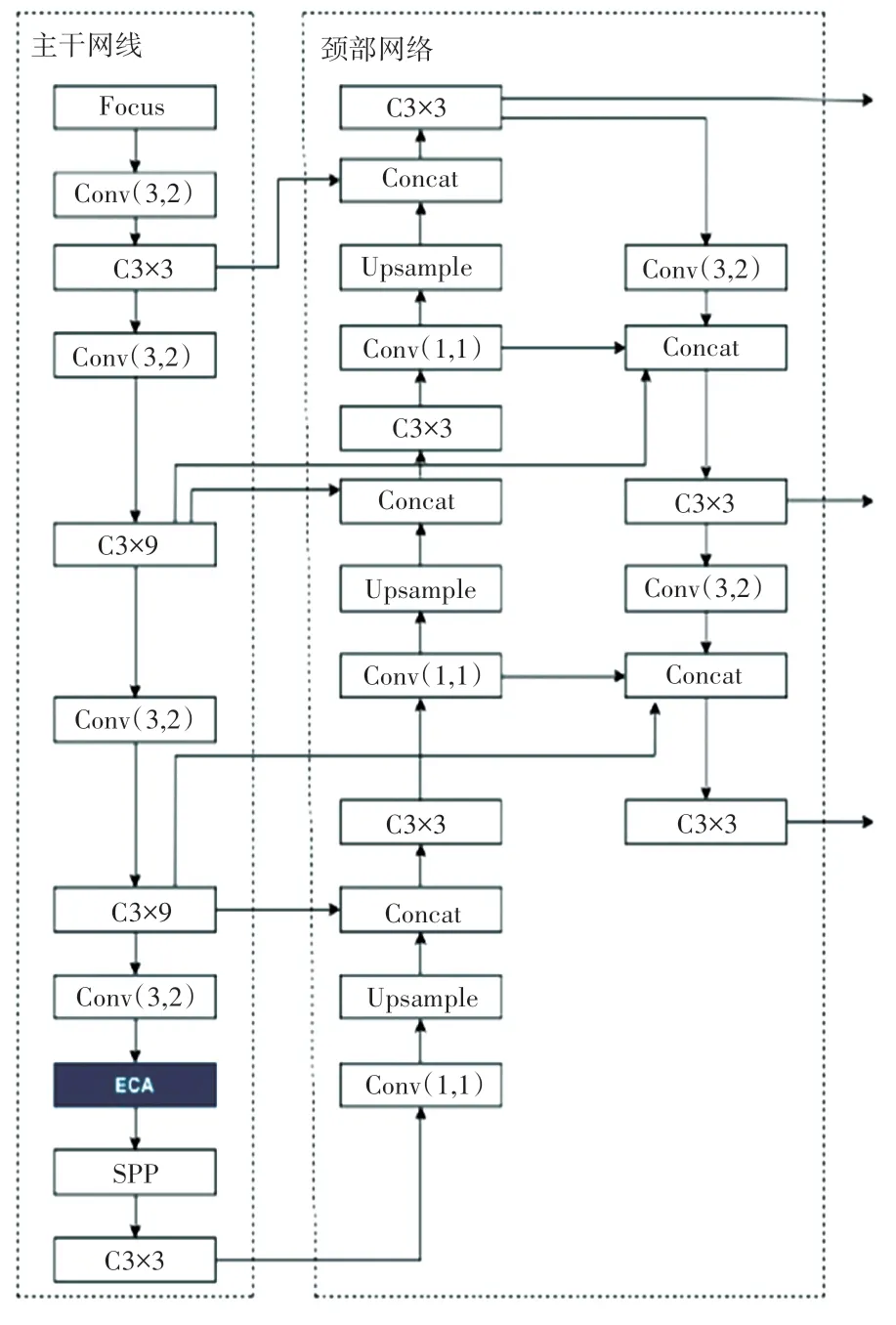
图2 改进后的BE-YOLOv5s 模型结构Fig. 2 Improved BE-YOLOv5s module structure
2.1 主干网络改进
在神经网络中加入不同的通道注意力机制,可以提升模型的检测精度,更准确的识别和定位在低照度环境下的行人目标。 注意力机制的原理是根据权重系数,重新加权求和。 注意力机制的本质在于对不同的任务可以根据输入进行特征匹配,ECA 通道注意力机制有效的减少了参数计算量,提升了检测速度。
ECA 通道注意力机制的工作原理如图3 所示。首先, 剔除原来的压缩和激励(Squeeze - and Excitation,SE)模块中的全连接层,将输入特征图进行全局平均化池操作;其次,进行卷积核大小为k的一维卷积操作,使用Sigmoid 激活函数生成通道权重;最后,将特征图与通道权重相乘,得到输出特征图。 同时ECA 通道注意力机制将原来SE 模块中的多层感知机模块转变为一维卷积形式,降低了参数计算量,实现了跨通道交互,用更少的计算成本提高检测网络的性能。
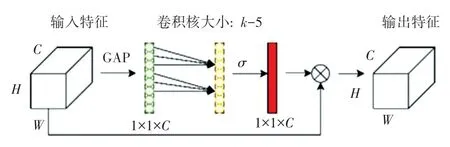
图3 ECA 通道注意力机制Fig. 3 ECA Channel attention mechanism
在YOLOv5 提取行人的初始特征过程中,由于受到低照度环境的影响,特征显示不足,本文在主干网络的最后一个CSP(Cross Stage Partial)模块后加入ECA 通道注意力机制,控制了参数量且增强了对行人特征的提取能力。
2.2 特征金字塔改进
引入BIFPN 加权双向特征金字塔,该结构多次使用特征网络层,进行加权特征融合。 对于不同分辨率特征的融合,BIPFN 为每个输入添加额外的权重,并让网络区分不同特征的重要程度,结构设计如图4 所示。

图4 加权双向特征金字塔Fig. 4 Bidirectional Feature Pyramid
本文在YOLOv5s 的颈部采用BIFPN 网络,快速进行多尺度特征融合,提升检测效果。
3 实验与结果分析
3.1 实验环境
实验采用Pytorch 深度学习框架进行网络模型部署,整体基于Windows10 操作系统,CPU 为AMD Ryzen 5 3600X 处理器,显卡为NVIDIA GeForce RTX 2070S(8 G)。
3.2 实验设计
本文网络模型训练所用实验数据来源于韩国科学技术院公开的KAIST 数据集,抽取2 000 张可见光图像,以及与之对应的2 000 张红外图像作为数据集,按照8 ∶1 ∶1 的比例,划分训练集、验证集和测试集。
3.3 实验评价指标
本文主要采用准确率(P,Precision)、召回率(R,Recall)、 平均精度均值(mAP,mean Average Precision)以及推理时间作为模型评价指标。P和R的计算公式如式(1) 和式(2):
其中,TP表示正例被正确预测;FP表示负例被错误预测为正例;FN表示正例被错误预测。
mAP是对P和R的一种综合处理指标,表示PR曲线下的面积。 推理时间代表检测每个图像需要消耗的时间。
3.4 实验数据分析
与YOLOv5s、YOLOv5l、YOLOv5n 模型进行实验对比,在可见光数据集和红外数据集上的实验结果见表1、表2。

表1 可见光数据集性能指标对比Tab. 1 Comparison of performance indicators for visible light datasets
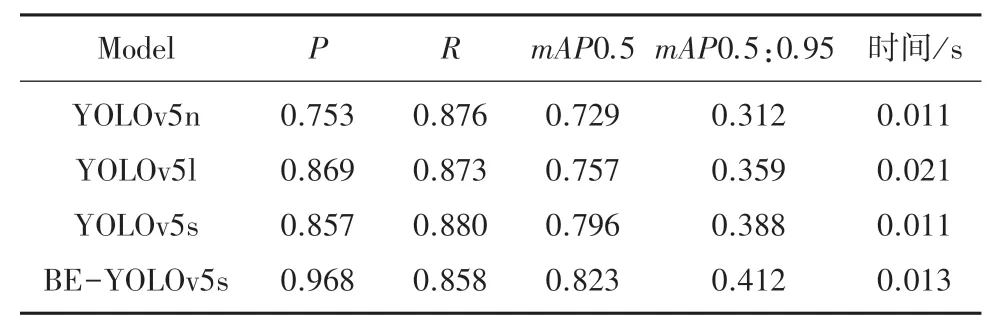
表2 红外数据集性能指标对比Tab. 2 Comparison of performance indicators for infrared datasets
由表1 和表2 可见,在两种不同的数据集上,改进后的BE-YOLOv5s 模型相比于改进前,均大幅提升了检测准确率P,由于P和R之间存在一定的相关性,所以难以避免地会使检测召回率R稍有降低,改进后的模型在两种数据集上均显著提升了mAP。 推理时间方面,改进后模型的检测时间相比于改进前虽有所提高,但仍满足实时性要求。YOLOv5l 和YOLOv5n 是通过调整YOLOv5 不同的网络深度和宽度这两个参数得到的模型,YOLOv5n的两个参数小于YOLOv5s,其检测速度更快,但精度更差。 YOLOv5l 的两个参数均大于YOLOv5s,其检测速度更慢,但精度更高。 由此可见,BE -YOLOv5s 模型在提升行人检测准确性的同时,保持了原模型的检测速度。 在两种数据集上训练时,4种模型在验证集上的mAP0.5: 0.95 对比如图5 所示。
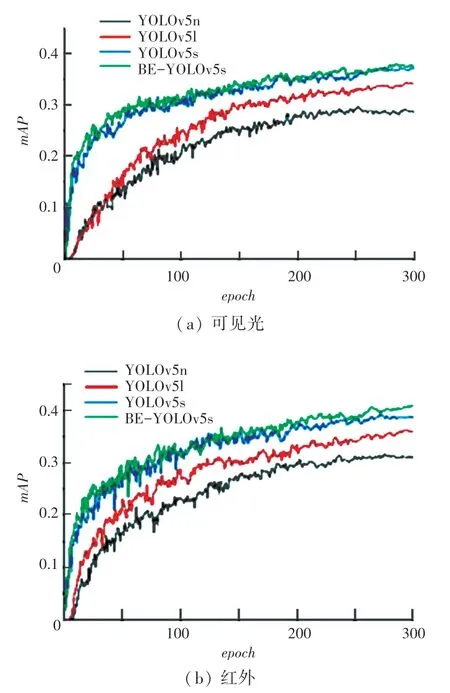
图5 4 个模型mAP0.5:0.95 对比Fig. 5 Comparison of four models mAP0.5:0.95
另一方面,从表2 可见,红外数据集上的各项精度指标均高于可见光数据集,推理时间满足实时性要求。 由此可见,红外图像增强了行人目标与背景信息之间的特征差异,提升行人检测的准确性。 在YOLOv5s 模型的部分测试集的可见光图像与红外图像的行人检测结果如图6 所示,目标框上的数字表示置信度。

图6 YOLOv5s 模型的检测结果Fig. 6 YOLOv5s model detection performance
由图6 可见,由于夜晚光照条件不足,YOLOv5s模型在可见光图像上检测效果较差,可见光图像中的3 个位于光线较暗处的行人均未检测出,而在红外图像中,依旧有两位行人未检测出。 改进后的BE-YOLOv5s 模型下的行人检测结果如图7 所示,可见两种图像中均可准确检测出所有行人。 综合结果分析,BE-YOLOv5s 模型在低照度的环境下检测效果较好。

图7 BE-YOLOv5s 模型的检测结果Fig. 7 BE-YOLOv5s model detection results
4 结束语
本文针对YOLOv5s 模型在低照度环境下对多尺度行人检测准确率低的问题,引入ECA 通道注意力机制,提高模型对行人特征的提取,将原PANet网络替换为BIFPN 网络,加强了不同尺度的特征融合,得到了准确性和实时性俱佳的BE-YOLOv5s 目标检测模型。 在可见光数据集和红外数据集上分别进行测试,并与YOLOv5s、YOLOv5l、YOLOv5n模型进行对比,实验结果表明:改进后的BE-YOLOv5s模型在两种数据集上的mAP值均高于原模型,并且保持了原模型高实时性,有效提升了行人检测的精度。 未来将融合可见光图像和红外图像各自的优势,不断提升检测精度。
猜你喜欢
意林(2021年5期)2021-04-18
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
光源与照明(2019年4期)2019-05-20
扬子江(2019年1期)2019-03-08
电子测试(2018年9期)2018-06-26
数学物理学报(2017年5期)2017-11-23
小天使·一年级语数英综合(2017年6期)2017-06-07
新课程学习·中(2013年3期)2013-06-14
上海理工大学学报(2012年2期)2012-03-20
