
注意力与特征融合的未来帧预测异常行为检测算法
2023-09-12 07:26:14张瑜玮王燕妮
探测与控制学报 2023年4期
张瑜玮,王燕妮
(西安建筑科技大学信息与控制工程学院, 陕西 西安 710055)
0 引言
异常行为检测是增强监控场所安全的重要科学技术手段,具有重要的社会价值和应用价值[1]。传统的异常行为检测算法特征提取方法包括通过获取物体在运动过程中的位置、长度、速度等信息构造特征的基于轨迹的方法[2-3]和通过提取底层的空间信息的基于低维特征的方法[4-7]。虽然这些方法在某些特定的场景下能够取得较好的检测效果,但这些方法是通过人工提取特征,算法对于数据库依赖较大,其异常检测算法不具有客观性,且易受光照变换、视角转换、图像噪声等方面的影响。
随着卷积神经网络在行为识别领域研究的逐步深入,基于深度学习的视觉特征逐渐应用到异常行为检测模型中,并取得了较大的进展。目前,基于深度学习的异常行为检测主要有两个方向:一是基于重构的异常行为检测;二是基于预测的异常行为检测。基于重构的异常行为检测是对输入正常行为的视频图像进行特征提取,再解码为重构图像,最终以重构误差作为异常得分判断视频图像中是否含有异常行为。该方法包括以循环卷积网络[8-10](RNN)、生成对抗网络[11](GAN)、3D卷积网络[12]等网络为基础模型进行图像重构。由于基于重构的异常行为检测方法仅在正常数据上进行学习,因此模型不能准确判断出遮挡情况下的异常行为,导致检测效果差。基于预测的异常行为检测,通过提取一段连续帧视频图像的外观特征与运动特征进行建模,生成预测图像,将预测图像与真实图像进行对比得到预测误差来判断。该方法主要应用于异常行为类型定义不准确的检测算法中。
针对现实生活中提取到的视频无任何标签信息,异常行为类型不能准确判断等问题,提出一种注意力与特征融合的未来帧预测算法用于异常行为检测。
1 相关理论
1.1 生成对抗网络
生成对抗网络(GAN)是一种生成式的、对抗的无监督网络模型,是生成网络和判别网络两个神经网络相互竞争的过程。生成器的目的是通过学习真实的图像数据分布尽可能生成让判别器无法区分的逼真样本,而判别器则是尽可能去判别该样本是真实样本还是由生成器生成的假样本。在理想条件下,生成器和判别器会达到纳什均衡状态。图1展示了GAN的基本框架。
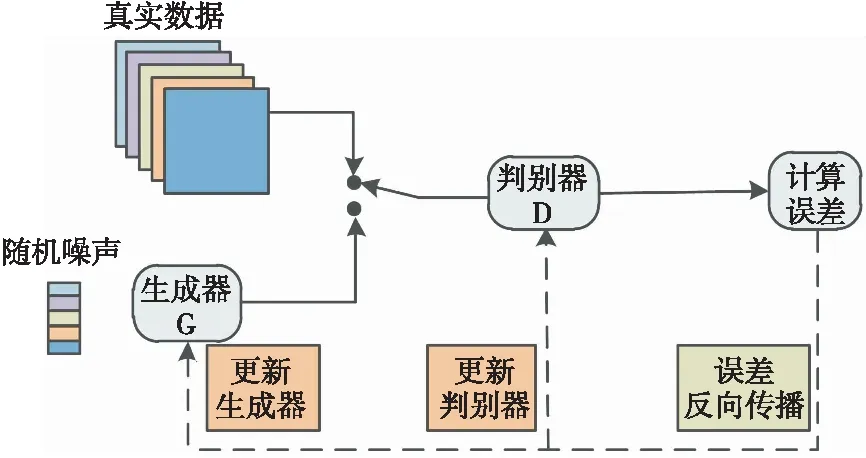
图1 生成对抗网络原理图
为了使模型更加关注图像的细节特征,提高图像的清晰度,2017年Isola等人提出马尔可夫判别器(PatchGAN)[13],将判别器改进成了全卷积网络,输出n×n的矩阵作为评价值用来评价生成器的生成图像。
1.2 U-Net网络
基于自身参数较少、易于训练的优点,U-Net网络在图像检测领域得到了广泛的应用[14]。为了解决梯度消失和信息不平衡问题, U-Net网络在编码器与解码器之间引入跳跃连接,将相同分辨率的全局空间信息与局部细节信息进行融合,生成较高质量的图像。
文献[15]提出了一种基于生成对抗网络预测未来帧的异常行为检测方法,该方法以正常样本进行学习,运用以U-Net网络作为生成器的生成对抗网络,通过对比预测帧和未来帧,判断图像是否包含异常行为,但该方法的准确率还需要进一步提升。
2 注意力与特征融合的未来帧预测异常行为检测算法
为了对原始算法的不足进行改进,本文采用无监督学习方式进行视频帧预测,利用生成对抗网络作为基础网络,以U-Net网络为基础对生成器进行改进。首先引入了SoftPool层尽可能减少池化过程中带来的信息损失;其次,为了保留更为丰富的上下文信息,突出关键信息部分,引入ECA注意力机制;然后,编码器对输入的连续帧进行下采样提取底层特征,并将最后一层特征图输入BTENet模块编码全局信息,学习特征像素之间的相关信息;最后,在网络特征图的输出部分引入CSENet模块,基于注意力机制的特征提取出更加符合要求的通道作为输出。然后将预测图像输入到马尔可夫判别器中,由其判断真假。为了提升模型的预测效果,施加强度和梯度损失函数对空间进行约束,并加入光流损失来加强时间约束,保证运动的一致性。整体网络框架如图2所示。

图2 整体网络框架图
2.1 SoftPool池化层
异常行为检测中所采集到的数据集大多包含大量背景信息,人在图像中所占像素较少且相邻帧图像的相似度较高。原U-Net网络利用最大值池化实现下采样的过程容易损失部分重要信息导致误检。因此,使用SoftPool[16]池化层替换U-Net中的最大池化层,利用softmax的加权方法保留输入图像的特征属性,对感受野内的所有像素以加权求和的方式映射到网络的下一层,使得网络在对特征图进行下采样的同时,尽量减少特征信息的丢失,更多保留图中的细粒度信息,适用于异常行为的特征提取网络。
2.2 高效通道注意力机制
考虑到计算性能和模型的复杂度,在特征融合层中引入了一种轻量级注意力机制ECA-Net[17],其架构图如图3所示。

图3 ECA架构图
该网络在不降低通道维数的情况下进行跨通道信息交互。首先采用全局平均池化操作实现低维嵌入,得到1×1×C的特征向量,其次采用大小为K的一维卷积进行局部跨通道连接操作。通道数C和局部跨通道卷积核K对应关系为
(1)
式(1)中,r=2,b=1,K为计算出来临近的奇数值。
2.3 BTENet模块
基于BoTNet模型[18]在低层U-Net编码器与解码器之间添加改进的Bottleneck Transformers模块和ECA模块组合而成的BTENet模块,其结构图如图4所示。其中Bottleneck Transformers模块借鉴了ResNet Bottleneck模块结构,将ResNet Bottleneck模块中的空间卷积层替换成多头自注意力块MHSA(multi-head self-attention),如图5所示。添加BTENet模块后,提升目标检测的性能,使得网络能够更好地提取图像中有效的局部特征,聚合图像全局信息的同时降低模型参数量,使延迟最小化。

图4 BTE Net结构图

图5 MHSA结构图
2.4 CSENet模块
为了更好融合图像的上下文信息,增强特征表示,改进了解码器输出分类层的上采样网络结构,将其命名为CSENet。该模块将单一的卷积层替换成残差网络结构[19],同时考虑到特征通道间重要程度的不同,提高对图像帧关键信息的提取能力,引入SE注意力模块[20],为后续图像预测过程打基础。CSENet模块的结构图如图6所示。
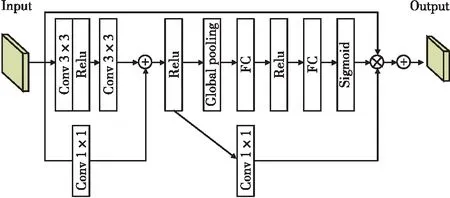
图6 CSE Net结构图
3 实验与结果分析
3.1 约束条件与评价指标
3.1.1损失函数
在本文实验中,生成器不仅被训练用来欺骗判别器,而且还被要求约束条件中生成的图像和原图像之间的相似性。因此,生成器的损失函数由强度损失、梯度损失、光流损失、对抗损失组成。
强度损失用来保证两帧图像的RGB空间中对应像素的相似性;梯度损失可以使生成的图像锐化,更好地保持帧的清晰度;引入光流损失为了约束运动信息,计算预测帧与真实帧之间运动信息。
生成对抗网络的训练过程包含训练判别器和训练生成器。判别器和生成器的训练过程的损失函数为
(2)
(3)
(4)

最终得到生成器的损失函数为
(5)
判别器的损失函数为
(6)
式(6)中,λi表示强度损失函数的权重,λg表示梯度损失函数的权重,λo表示光流损失函数的权重,λa表示对抗损失函数的权重。
3.1.2异常得分函数
(7)
PSNR越小表明该帧是异常的概率越大,因此,可根据PSNR设置阈值判断视频帧是否异常。
3.2 实验数据及评价指标
CUHK Avenue数据集是目前视频异常检测领域最广泛使用的数据集之一,其主要包括16个训练视频段和21个测试视频段,测试视频中总共包含有47个异常事件。每个视频时长约为1 min,视频帧的分辨率大小为640×360。部分异常行为示例如图7所示。

图7 CUHK Avenue数据集部分异常行为示例
UCSD Ped2数据集由加州大学制作的视频异常检测数据集,其异常事件都与交通工具有关,部分异常行为如图8所示。该数据集包含16个训练视频段和12个测试视频端,测试视频共包含12个异常事件。每个视频段大约包含170帧灰度图,视频的分辨率大小为360×240。

图8 UCSD Ped2数据集部分异常行为示例
该模型在NVIDIA Tesla V100,显存为16 GB的平台上进行实验,使用Python3.8语言,软件环境为Pytorch 1.8.1,cuda 10.2。
为了衡量本文方法用于视频异常行为检测的有效性,采用了控制异常得分阈值来绘制接收者操作特征曲线(receiver operating characteristic,ROC)的曲线下面积(area under curve,AUC)作为评价指标。本文方法和大多数算法一样,使用帧级别AUC来评价算法性能,即只要在视频帧中任何一个位置被判定为异常,则该视频帧就被判定为异常。
3.3 参数设置
训练时,所有帧的像素被归一化值[-1,1],每帧图像大小设置为256×256,将连续4帧图像作为生成器的输入数据,即设置t=4。使用Adam优化方法,生成器和判别器的学习率分别设置为0.000 2和0.000 02,目标函数中λi、λg、λo、λa分别设置为1.0、1.0、2.0、0.05。
3.4 实验结果
3.4.1检测性能比较
为了证明本文方法在视频异常检测方面的有效性,将改进的方法与现有的7种不同方法在CUHK Avenue数据集和UCSD Ped2数据集中进行比较。其中包含构建传统浅层模型、深度重构模型、深度预测模型三类。MPPCA(概率主成分分析器的混合)+SF(社会力)[6]、MDT(动态纹理的混合)[21]是基于手工特征的方法;Conv-AE[22]、Convlstm-AE[9]、Stacked RNN[10]和Self-training[23]是基于自编码器的方法,通过重构模型检测异常行为;Pred+Recon[15]是基于生成对抗网络的方法,通过预测模型检测异常行为。表1显示了各种方法的帧级视频异常检测结果。
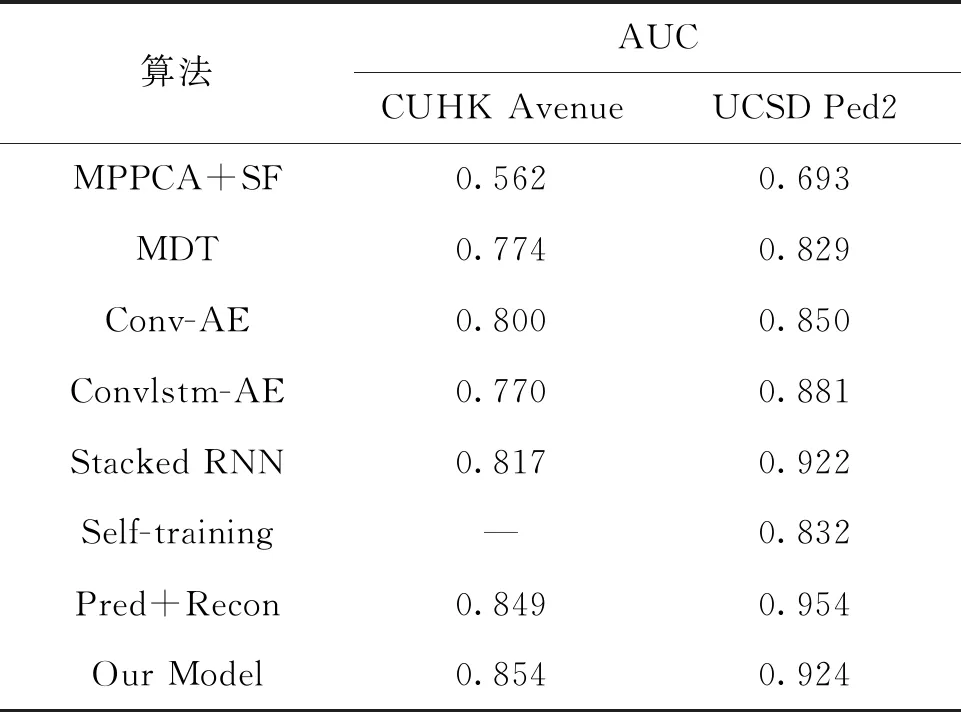
表1 不同算法在CUHK Avenue和UCSD Ped2数据集上的AUC结果对比
从表1可以观察到,基于自编码器的深度重构模型通常优于基于手工特征的传统浅层模型。这是因为手工特征的提取通常是基于其他的任务而取得的,因此可能是次优的。此外,从表中数据还可以发现基于生成对抗网络的深度预测模型比大多数基线方法表现更优。本文提出的算法在CUHK Avenue数据集上取得了85.4%的AUC,比效果最优的Pred+Recon方法领先0.5%。在UCSD Ped2数据集上AUC达到了92.4%。
为了更直观地显示本文算法的有效性,图9展示了最优的深度学习预测算法同一视频帧的热图和本文改进算法的热图。通过对比可以看出,改进算法中目标和背景差被明显放大,背景噪声减小,亮度被抑制,有利于网络更专注于提取运动的目标,同时减少了背景对目标的影响。
3.4.2有效性验证及讨论
为了验证本文方法中各个模块的有效性,在CUHK Avenue数据集上做了消融实验来验证。实现结果如表2所示。
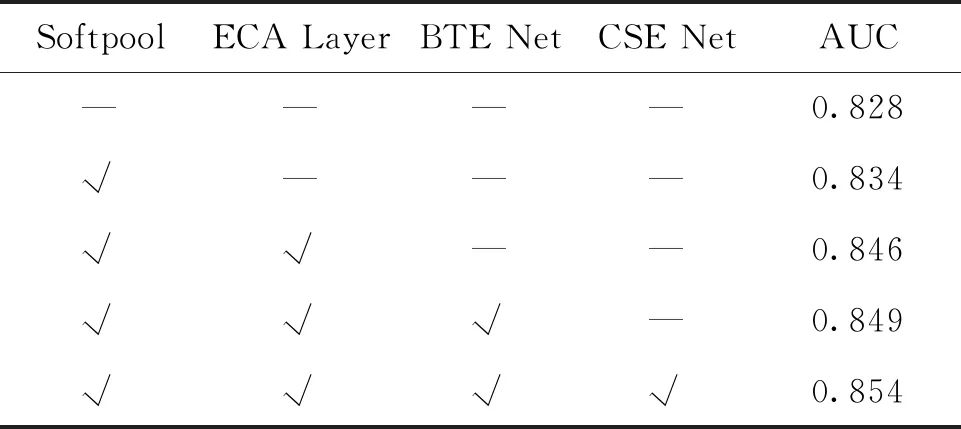
表2 不同模块结果对比
3.4.3异常行为结果显示
以CUHK Avenue数据集的Testing05测试视频为示例显示异常检测结果,如图10所示。横轴表示视频帧数,纵轴用预测帧与真实帧之间的峰值信噪比(PSNR)作为异常得分的评判指标,本文将阈值设置为35,PSNR值越小,则表明有异常行为出现,PSNR值越大,则行为正常。从图中可以看出,当行人正常行走时,PSNR保持较高值,当有行人出现并抛掷物体时,异常得分极速降低;最后行人恢复正常行走时,PSNR又恢复到较高水平值。

图10 异常检测结果
4 结论
注意力与特征融合的未来帧预测异常行为检测算法通过构建生成对抗网络对视频进行未来帧预测来检测异常行为,该算法对U-Net网络框架进行了改进,引入了一种快速高效的池化方法,设计了新的特征融合模块和特征提取模块,引入了轻量级注意力机制,有效改善了复杂场景下前景背景区分不明显,视频流时空间信息量不均衡,检测效果差等问题。实验结果表明,该算法对复杂场景中的人体异常检测更准确,在CUHK Avenue数据集中AUC达到了0.854,在UCSD Ped2数据集中AUC达到了0.924,证明了改进方法的有效性。但该算法的检测速度有所下降,在后续工作中将进一步轻量化网络结构,提升算法的检测速度。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
今日农业(2019年15期)2019-01-03 12:11:33
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
