
国外互联网开源信息处理研究综述*
2023-09-12 09:00汪明达刘世钰聂大成邱鸿杰
通信技术 2023年7期
汪明达,刘世钰,聂大成,杨 慧,张 翔,邱鸿杰
(中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引言
随着全球数字化、信息化进程的深度推进,互联网逐渐成为人类最重要的基础设施之一,承载了涉及人类生活工作方方面面的海量信息。与此同时,互联网的普及极大简化了从门户网站、社交媒体、博客等公开信息源获取信息数据的过程,这些开源信息数据可为人们提供有价值的决策支撑信息,帮助人们更好地认知、理解甚至预测特定实体或概念对象的属性和行为,进而掌握事件的规模、热度、发展趋势等。为此,互联网开源信息处理逐渐成为世界各国争相研究的热点。
互联网开源信息处理(以下简称“开源信息处理”)是指从互联网上的公开信息源获取数据并分析处理,进而获得有价值的开源信息的过程。开源信息处理中涉及的信息范围十分广泛,涵盖了政治、军事、商业、社会等众多领域。在政治领域,开源信息处理可以用于分析其他国家的政策和决策,帮助决策者预测目标国家的行为趋势。在商业领域,开源信息处理可以用于分析竞争对手的战略和市场趋势,帮助企业制定更好的市场营销策略。在社会领域,开源信息处理可用于分析犯罪活动和社会趋势,帮助执法部门和政府机构制定更好的政策和措施。
本文将对国外开源信息处理的有关研究进行综述,包括开源信息处理的定义、技术手段、应用系统等,总结现有研究存在的问题,提出未来可能的研究方向,旨在为有关领域的从业人员提供一个可参考的系统性知识框架,助力开源信息处理技术发展。
1 技术流程
开源信息处理的主要技术流程包括4 个部分,分别是数据采集、数据预处理、信息分析和决策支撑,如图1 所示。
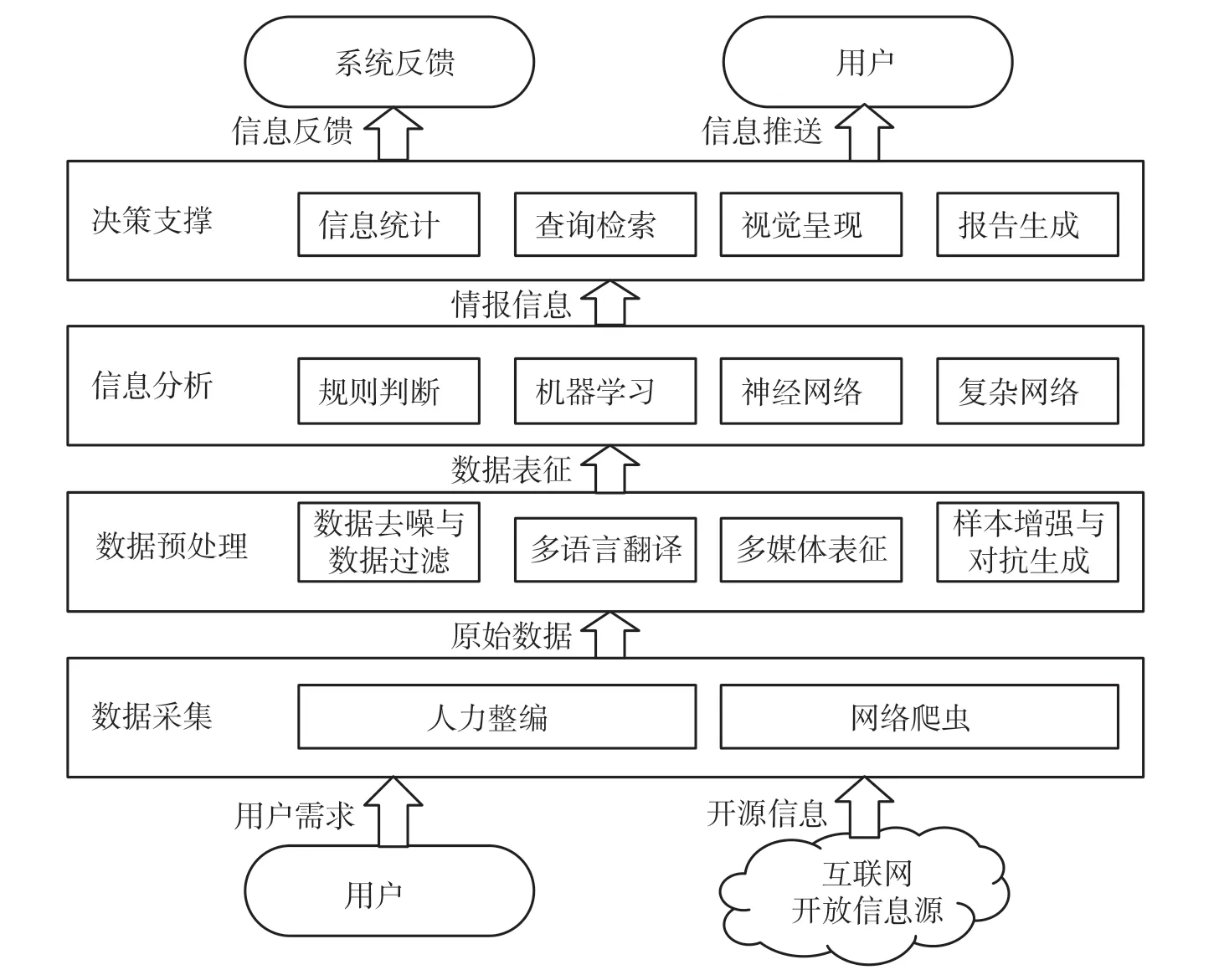
图1 开源信息处理主要技术流程
一是数据采集,是指从互联网公开数据源采集信息数据,为开源信息处理分析提供基础数据支撑。采集的信息需要经过初步筛选和过滤,以保证基本的数据准确性和有效性,避免采集资源浪费。数据预处理是指对采集到的开源数据进行分析前的预先处理。二是数据预处理,其目的是在于提高数据的质量和可用性,以便后续分析能够更加有效地利用,常见的预处理包括数据清洗、格式转换、数据重构和存储管理等,能够使数据更加规范化,降低数据冗余和错误。三是信息分析,指利用分析算法对预处理数据进行深度的统计、分析和判断,从中挖掘出有价值的信息和规律,生成有价值的决策支撑信息,为用户决策管理提供信息支撑,是开源信息处理整体流程中的核心环节。四是决策支撑,指将分析的结果通过合理的方式传递给用户,方式主要包括信息可视化、报告生成和信息共享,以便用户更好地理解和使用决策支撑信息。
2 数据采集
2.1 人力整编
人力整编也称众包数据收集,是指通过数据工作者手工收集、完善和优化从公开数据源获得的数据的过程。人力整编的优势主要在于通过引入专家知识,一定程度上提高数据质量,对于轻量级的数据采集工作能够保证数据采集和管理的效率。然而,人力整编面临数据隐私安全、人为偏见、众包质量参差不齐等问题。
Chai 等人[1]在其综述研究中提到,众包数据库系统能够有效解决现有公共众包平台(如Amazon Mechanical Turk、CrowdFlower 等)交互设计非常不便的问题。该综述对众包平台有关研究进行了梳理,概述了众包的概念,总结了设计众包数据库的基本技术,其中包含任务设计、任务分配、解决方案推理及延迟减少等,并回顾了众包操作符设计策略,包括选择、连接、排序、前k项、最大/最小值、计数、收集和填充等。
2.2 网络爬虫
网络爬虫是一种用于自动化采集公开数据的程序,数据类型覆盖包括网页文本、图片、音频、视频等在内的多媒体数据。经过多年发展,网络爬虫逐渐成为大数据分析、搜索引擎、推荐系统等技术的数据采集基础。
Khder 等人[2]在其2021 年发表的研究综述中提到,网络爬虫的近期研究主要关注于爬虫技术的智能化及爬取效率的提高。相较于人工整编,使用网络爬虫不仅可以获得更全面、准确和一致的数据,还可从深暗网中大量获取灰黑产数据以支撑执法打击决策,应用场景更为广泛。同时,该文强调了爬虫应用导致的伦理和法律问题,尤其是个人隐私泄露、版权侵犯、不正当竞争、网络攻击等。
Neelakandan 等人[3]提出了一种用于定向网络爬虫的自动参数调整深度学习词嵌入模型。该模型涉及多个步骤,包括预处理、基于负采样的增量式跳跃语法模型词嵌入、双向长短期记忆分类以及基于鸟群优化的超参数调整。该研究的实验结果表明,所提出的模型在网页收集方面获得了更高的采集成功率,达到了85%。
3 数据预处理
在开源信息处理中,数据预处理包括很多方面的内容,例如数据的目标抽取、清洗、格式转换、取值标准化、多源数据集成、信息精炼等。
Johnsen 等人[4]提出了一种基于主题模型的隐式狄利克雷分布(Latent Dirichlet Allocation,LDA)的文本预处理方法。该研究基于对大量有关研究文献的总结,设计了一组预处理规则,并在真实的网络论坛中进行了演示应用。该研究的实验结果表明,如果要保证主题建模的结果可以实际运用于开源信息处理,其建模过程需要遵循非常严格的流程,且通过调整LDA 的超参数和主题数可以产生更可靠的结果。该研究通过对主题模型进行迭代改善,保证了所提取主题内容的连贯性和针对性。
Chandrasekar 等人[5]为提高C4.5 决策树算法信息挖掘的准确性,提出通过在数据预处理中利用监督过滤离散化操作来构建决策树,并将结果与未经离散化的C4.5 决策树进行了比较。实验结果表明,经离散化预处理后的C4.5 决策树能够取得更高的准确度。Garcia 等人[6]对大数据分析场景下的数据预处理方法进行了综述,描述了大数据中数据预处理方法的定义、特征和分类方式,探讨了大数据和数据预处理在各种方法和大数据技术族群中的作用。该综述总结了现有研究面临的挑战,重点描述了不同大数据框架(如Hadoop、Spark 和Flink)的发展状况,以及一些数据预处理方法和新大数据挖掘模式的应用。
4 信息分析
4.1 基于规则判断的开源信息处理
基于规则判断的开源信息处理是指从专家的先验知识出发,手工设计开源信息处理分析所需的判定规则,如阈值判定规则、类型判定规则、规则匹配方式等,并利用这些规则对开源信息数据进行分析处理,进而达到信息分析目的的方法。
规则判断在开源信息处理中的应用优势主要有两点。一是由于规则判断能够根据领域专家的经验进行快速设计,因此相较于其他基于复杂算法的开源信息处理,基于规则判断的开源信息处理能够快速、高效地满足轻量数据的分类和筛选需求。二是手工规则可以充分利用专家的主观经验判断力,能够在某些数据分析领域中准确描述分析需求,定位关键问题,例如对于具体自然语言的解释和推断等。但与此同时,手工规则对专家的专业知识的高要求导致规则维护所需的人工开销大,容易被专家知识的偏向性影响,且囿于数据的复杂性而难以处理大量数据。
Tariq Soomro 等人[7]分析了收集自2020 年3月1 日至2020 年5 月31 日的超过1 800 万条与冠状病毒有关的Twitter 消息,并利用基于规则的监督机器学习工具Vader 来进行情感分析,以评估公众情绪与新型冠状病毒肺炎(Corona Virus Disease 2019,COVID-19)病例数之间的关系。此外,该研究还分析了在推文中提到一个国家的数量与该国COVID-19 每日病例数的增加之间的关系。该研究发现,一些结果表明在意大利、美国和英国提到的推文数量与这些国家每日新COVID-19 病例数的增加之间存在相关性。
4.2 基于机器学习的开源信息处理
在开源信息处理中广泛应用的传统机器学习算法主要包括决策树类算法、朴素贝叶斯、最近邻居算法、支持向量机、逻辑回归等。开源信息处理中应用机器学习的优势主要在于能够有效平衡专家经验知识和算法自动化的影响,能够处理结构化和非结构化等多种数据类型,具有较高的容错性、可扩展性。然而,传统机器学习仍然存在对数据预处理要求高、过度依赖手工特征等问题,特征提取中专家知识的专业性和偏向性将对算法输出产生较大影响。
Balaji 等人[8]对使用机器学习进行开源信息处理分析,尤其是社交媒体分析方面的研究进行了综述。该综述认为,机器学习已经成为社交媒体分析的基础技术手段,在社交媒体的情感分析、用户画像、社交网络分析、事件检测和推荐系统等方面发挥着重要作用,技术类型包括监督学习、无监督学习、半监督学习等。现有研究面临的挑战主要在于数据获取、数据质量、算法效率、模型解释性等方面,可以在算法的效率和准确性,如特征选择、深度学习、自适应算法等角度开展进一步研究。
Khadjeh Nassirtoussi 等人[9]对文本挖掘在开源股市预测方面的应用研究进行了综述。文本挖掘在股市预测方面的应用已经得到了广泛的研究,数据源主要包括新闻、社交媒体、公司报告、股市评论等方面的数据。在方法和模型方面,研究者们主要采用了机器学习、自然语言处理、情感分析等技术来进行文本挖掘和预测。该论文指出,文本挖掘在股市预测方面的应用可以提高预测的准确性和效率,但数据来源不确定、模型过度拟合等问题带来的预测效果下降的情况不容忽视。因此,在进行文本挖掘的时候需要注意数据的质量并选择合适的模型和方法,以提高预测的准确性和可靠性。
Abbass 等人[10]提出了一个基于开源数据进行社交媒体犯罪行为预测的技术框架,涉及的网络犯罪类型包括网络跟踪、网络欺凌、网络黑客、网络骚扰和网络诈骗。该框架由三个模块组成,包括数据(推文)预处理、分类模型构建和预测。为构建预测模型,该研究使用了多项式朴素贝叶斯(Multinomial Naïve Bayes,MNB)、K 近 邻(K Nearest Neighbors,KNN)和支持向量机(Support Vector Machine,SVM)对数据进行分类,以确定不同的犯罪类别。使用这些机器学习算法的N-Gram语言模型来识别n的最佳值,并测量系统在不同n取值(例如Unigram、Bigram、Trigram 和4-gram)下的准确性。实验结果表明,所有三个算法的精确度、召回率和F 值均超过0.9,其中支持向量机表现略优。
Ghazi 等人[11]提出采用有监督的机器学习从不规整、高噪声、海量的开源非结构化威胁信息数据中提取威胁数据源,提取精度约为70%,且该方法能生成符合STIX 等标准的全面的威胁报告,进而帮助组织主动防御已知和未知的威胁,减少手动分析的烦琐工作。
4.3 基于神经网络的开源信息处理
神经网络系列算法已经广泛应用于开源信息处理分析领域,主要包括前向全连接网络、卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络、图卷积神经网络、自编码器、生成对抗网络、残差网络等,以及深度学习、注意力机制、预训练模型、增强学习、迁移学习、少样本学习等新型学习框架的应用。神经网络分析方法的优势在于能够自适应和自我学习,可以进行端到端的学习和操作,对非线性和复杂数据具有良好的拟合能力,适合进行预测和分类任务。然而,神经网络的模型训练需要大量的数据和计算资源,模型的可解释性有待提高,难以评估网络的鲁棒性,模型容易出现过拟合情况。
Martins 等人[12]提出了一种基于神经网络的联合学习框架,将命名实体识别(Named Entity Recognition,NER)和实体链接(Entity Linking,EL)两个任务结合在一起进行学习,实现协同优化。该方法主要包括三个组件。一是共享编码器,用于将输入的文本转化为向量表示。二是NER 解码器,用于预测文本中的命名实体。三是EL 解码器,用于将预测出的命名实体链接到知识库中的实体。该框架的主要特点是可以同时考虑文本中的命名实体和知识库中的实体,从而能够提高NER 和EL 两个任务的准确率。此外,该框架还可以通过联合训练来减少模型的训练时间和资源消耗,提高模型的效率。以CoNLL 2003 和AIDA CoNLL-YAGO 为数据输入的实验结果表明,与单独训练NER 和EL 模型相比,该联合学习框架可以显著提高NER 和EL 两个任务的准确率,并且可以在保持准确率的同时减少模型的训练时间和资源消耗。
Su 等人[13]对基于深度学习的社团发现研究进行了综述。该综述认为从算法的角度来说,现有研究主要分为两类,即基于节点表征学习的方法和基于图表征学习的方法。前者主要通过学习节点的向量表征来判断节点之间的相似性,后者则是通过学习图的嵌入表征来捕捉社区结构和节点间的关系。其中,基于图表征学习的方法相对于基于节点表征学习的方法更具优势,因为它能够更好地捕捉节点之间的结构和关系,从而更精确地刻画社区结构。现有研究的挑战主要在于如何利用深度学习方法更好地发现社区结构,如何应对噪声、稀疏性和异质性等问题,以及如何处理大规模网络数据的问题。
Garcia 等人[14]针对COVID-19 病例数和死亡数均较高的巴西和美国两个国家开展了基于开源数据的主题识别和情感分析研究。该研究使用了共计六百万条英语推文和葡萄牙语推文,比较和讨论两种语言的主题识别和情感分析的效果,并基于讨论热度排名的10 个主题进行了话题演化分析。该研究填补了葡萄牙语开源分析方面的研究空白,并对情感趋势的长期分析及其与新闻报道的关系进行了探究,比较了疫情下两个不同地区的人类行为。
Hashida 等人[15]提出了一种基于深度学习的分类方法,采用一种新的分布式单词表示方法——多通道分布式表示法,表示一个单词潜在特征的单词向量。在此基础上,为了进一步增强分布式表示的能力,该研究在多通道分布式表示中使每个项都包含多个通道值。与其他CNN 模型和长短期记忆模型(Long Short-Time Memory,LSTM)进行的对比实验结果表明,深度学习模型的分类性能优于朴素贝叶斯分类器,同时具有多通道分布式表示的CNN在分类推文方面表现更好。
4.4 基于复杂网络的开源信息处理
开源信息处理中采用的复杂网络分析主要面向图结构的开源信息处理数据进行处理,常用于传播分析、用户关联关系挖掘等任务。复杂网络分析通过模拟分析大规模图结构的复杂系统,包括网络拓扑结构和系统动力学,在系统演化方面具有分析优势、较高的容错性和鲁棒性。然而,复杂网络分析对数据量的要求很高,计算复杂度高,可解释性和可控制性较弱。
Berahmand 等人[16]提出了一种改进欧几里得随机游走有效的方法进行链路预测。该方法鼓励随机游走向具有更强影响力的节点移动,每一步都根据所在节点的影响力选择下一个节点。该研究基于互信息度量,提出了节点之间的非对称互惠影响的概念。实验结果表明,与其他链路预测方法相比,所提出的方法有更高的预测准确性。
Li 等人[17]提出了一种基于自因果推断中的混杂因素分析的无偏网络混淆技术,以解决推荐系统中非随机缺失(Missing-Not-At-Random,MNAR)的问题。该方法通过控制社交网络的混淆保留观测到的曝光信息,同时可以通过平衡表示学习实现去混淆,以保留主要的用户和物品特征,在推荐评级预测方面具有很好的泛化能力。
Naik 等人[18]面向社交网络复杂社团划分的并行处理和共享/分布式技术应用情况开展了综述研究。该研究全面讨论了在现有的社群检测方法中应用并行计算、共享内存和分布式内存的情况。
5 决策支撑
5.1 信息可视化
信息可视化通过将数据呈现为可交互的实体,帮助用户更快捷、更直观地理解信息,并在分析过程中更快捷地定位信息中的关键结构和重点内容。
Gonzalez-Granadillo 等人[19]使用Gephi 和D3.js两种工具进行开源信息处理的网络可视化及界面交互。该研究将网络中的节点和边用图结构的形式在屏幕上呈现,方便用户直观地了解文本或其他类型数据中的关系,并提供更为丰富的交互式可视化,比如通过鼠标拖拽、缩放和筛选等手段,实现对可视化数据的自定义和过滤。Hoppa 等人[20]使用多种数据可视化技术,如热力图、时间线、饼图和条形图等,以帮助用户更好地理解和分析收集到的Twitter 开源信息处理数据。
5.2 报告生成及信息共享
信息报告生成有助于总结分析过程和结果,有利于信息的共享。信息共享的技术特点和效果通过提高安全性、可持续性和可扩展性,使得安全生态系统的不同组织和应用程序之间可以更好地协作和共享信息数据,支持更有效的安全决策和风险管理。
Cerutti 等人[21]利用语言生成技术生成报告,并对分析过的数据进行整理和归纳,该报告能够清晰地反映事件的发展过程、现状和未来预测。该技术的优点在于将已有数据进行人类语言转化的同时,能够提高报告生成的效率和准确性。生成的报告还可以提供交互式的方式,使用户能够根据自己的需求自由地选择并浏览报告中的信息。
Schwarz 等人[22]根据抓取到的数据和分析的结果,自动化地生成报告。报告生成的过程中可以完成报告格式的设定,包括报告样式、字体大小等。同时,也可以根据用户的需求进行调整,并且可以输出多种格式的文件,如PDF、WORD、HTML 格式的文档等。
Suryotrisongko 等人[23]将可解释人工智能(Explainable Artificial Intelligence,XAI)引入到开源信息处理中,实现了威胁信息的报告生成及共享。该研究利用XAI 技术解释机器学习算法的特征决策贡献,从而加强对恶意域名生成算法的识别、查找和分析。同时,XAI 技术也可以让分析人员更直观地理解和分析算法的结果,提高了分析的准确性和可靠性。对于报告生成,通过数据库技术来存储搜集到的威胁信息,并利用可视化技术将数据进行汇总和组织。报告不仅可以反映出威胁信息的趋势和异常点,还可以展示详细的信息内容和历史数据,让用户能够更好地理解和利用数据。
6 应用系统
在互联网大数据时代,世界各国不断加大对开源信息处理的研究部署和系统开发的投入,形成的有关成果系统已纷纷得到应用。
美国中央情报局、国家安全局等机构支持研发并应用了由Palantir 公司设计开发的Gotham 开源信息处理分析系统[24]。该系统的特点是能够处理大量的多源异构信息数据,进行数据的全方位整合与挖掘,并提供强大的数据可视化、模拟分析、信息查询和预测建模等功能。在美国政府和军队部门方面,Palantir Gotham 系统被广泛使用。在阿富汗和伊拉克战争期间,该系统被用于收集、整理和分析情报信息,发现恐怖组织的嫌疑人并进行定位。
I2-Analyst’s Notebook(i2AN)[25]是美国IBM公司开发的一款面向情报分析领域的数据分析软件,主要用于互联网开源犯罪情报分析、反恐调查、金融欺诈案件分析、情报综合分析等。i2AN 拥有多种分析功能,包括人物、地点、组织关系的可视化分析、时间线分析等,能够挖掘出隐藏在数据中的潜在线索,理清有关事件的脉络,帮助用户更加快速准确地做出判断,并可将所提供的信息、证据和结论生动展示给申请人和决策者。i2AN 的用户包括了全球许多机构和部门,特别是在美国政府和军队部门方面,包括联邦调查局、中央情报局、国土安全部等部门都在使用该软件。
Rosette[26]是美国Babel Street 公司的开源信息处理产品,旨在帮助分析人员从多种非结构化数据源中获取信息,并进行相关的分析和预测,包括社交媒体、博客、新闻报道、图片和音频等。与传统的信息分析方法不同,Rosette 采用了自然语言处理、机器学习和人工智能等前沿技术来辅助分析人员进行信息分析。它具有多种语言支持、实时数据收集和处理、可视化分析和用户定制等特点。Babel X在美国和其他国家的军队和情报机构中得到了广泛的应用。
此外,现在已有很多开源信息处理分析工具供世界范围内的研究者使用。SpiderFoot[27]是一款开源的自动化信息收集工具,可帮助用户收集数据、分析数据、生成报告及进行关联分析,可用于情报分析、网络侦察、趋势分析和风险评估等。theHarvester[28]是一款使用Python 编程语言开发的命令行工具,可帮助安全研究人员、渗透测试人员、信息安全企业、国家安全机构等用户,从互联网上收集各种类型的信息,如电子邮件、域名、虚拟主机、URL、IP 地址等。Metagoofil[29]是一款开源的可定制搜索引擎,支持从Google、Bing 和Yahoo 等搜索引擎中获取有关目标的信息,旨在帮助安全研究人员、渗透测试人员和安全顾问等用户,从互联网上搜索与目标公司或组织相关的文件,如文档、图片、代码和其他文件。Mitaka[30]可以将多源数据聚合,自动检测并删除无用数据,并提供各种图表和视图,帮助用户更好地理解数据和信息。
7 现有挑战
在世界各国和学术界的共同推动下,开源信息处理技术已取得长足进步,但仍面临以下3 个方面的挑战。
一是数据质量方面的挑战。数据是一切开源信息处理分析的基石,而开源信息处理通常面对巨大的数据量,且不同源的数据结构不统一,信息缺损的情况频繁发生,数据可靠性评估过于依赖专业知识,提高了人力、时间和空间开销。
二是分析算法方面的挑战。如今,开源信息处理常面临跨域目标分析需求,如何构建合理的目标行为表征,将跨域多源信息与目标进行有效关联,实现对目标的全面分析,是如今开源信息处理研究面临的关键技术挑战。
三是法律伦理方面的挑战。开源信息处理使用开源数据时须遵守相应的伦理规范和法律法规,尤其是在处理敏感领域及个人隐私方面的信息时,如何从技术上实现敏感及个人信息保护,防范化解敏感信息泄露风险,是如今开源信息处理分析面临的挑战之一。
8 未来展望
未来开源信息处理的研究大致有三个方向。一是先进技术在开源信息处理中的应用,尤其是以深度学习为代表的人工智能技术,其在开源信息处理领域的应用将会有效支撑开源数据的快速处理和信息的精准分析。二是跨学科研究。由于开源信息处理涉及很多不同的领域,如商业、政治、军事、国际关系等,如何将领域知识与开源信息处理相结合,在实际领域应用中解决实际的信息分析问题,将成为开源信息处理未来的研究热点。三是决策支撑和信息检索优化。如何将开源信息处理数据通过信息可视化的方式呈现出来,生成信息分析报告并有效地传递到用户手中,提供高效的信息检索方式,将是未来开源信息处理的研究方向之一。
9 结语
开源信息处理具有数据获取简易、信息覆盖面广等优势,现已成为世界各国研究的热点,相关成果已应用于社会各领域并发挥着重要作用。本文对当前国外开源信息处理研究的进展进行了综述。在技术方面,本综述覆盖了数据采集、数据预处理、信息分析和决策支撑4 个开源信息处理关键步骤的有关技术,其中人工智能技术在开源信息处理中的应用最为广泛。在应用系统方面,本综述对国外流行的开源信息处理系统进行了介绍,包括商业系统和开源系统。在现有挑战方面,数据质量、算法分析和法律伦理是现有研究面临的主要挑战,而先进技术的应用、跨学科研究、决策支撑和信息检索优化将是未来开源信息处理的研究热点。
猜你喜欢
中国石油大学胜利学院学报(2022年1期)2022-04-21
建材发展导向(2021年13期)2021-07-28
创新作文(1-2年级)(2019年3期)2019-09-03
铁道通信信号(2018年11期)2019-01-19
铁道通信信号(2018年1期)2018-06-06
制导与引信(2017年3期)2017-11-02
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
工业设计(2016年11期)2016-04-16
上海理工大学学报(社会科学版)(2015年3期)2015-11-30
