
基于机器学习的两个代表城市上呼吸道感染与气象要素关系及其发病风险预测研究
2023-09-07 02:07:46郑甲炜王式功吴千鹏张祥健黄开龙
沙漠与绿洲气象 2023年4期
郑甲炜,王式功,尹 立,吴千鹏,张祥健,杨 燕,黄开龙
(1.成都信息工程大学大气科学学院/环境气象与健康研究院,四川 成都 610225;2.中国气象局兰州干旱气象研究所,甘肃 兰州 730020;3.中国气象局—成都信息工程大学气象环境与健康联合实验室,四川 成都 610225;4.攀枝花市中心医院气象医学研究中心,四川 攀枝花 617000;5.汕头市气象局,广东 汕头 515000)
全球气候变暖及其对人类健康的影响是当今社会的热点之一。政府间气候变化专门委员会(Intergovernmental Panel on Climate Change,IPCC)的第五次评估报告(Assessment Report 5,AR5)明确指出:全球气候变暖已成为不争的事实,并且正在影响和改变每个人的生活。据报道,气候变暖每年可在全球范围内导致超过10 万人死亡。若依然不能有效改善全球气候变暖,到2030 年这个数字将变成30万[1]。因此,将气象学和医学结合,探索气象条件对人体健康的直接影响,进而对相关疾病的发病风险进行预测,助力疾病防控能力提升,具有重要的科学价值和现实意义。
以往诸多研究表明,多种疾病的诱发因素和传播过程都和气象条件有着密切的联系。气温的变化直接影响到上呼吸道感染疾病的发病、传播以及心血管疾病的发作[2-4]。温度和湿度呈现典型的季节性变化特征,而一些慢性病,譬如消化系统疾病、泌尿生殖系统疾病等,它们的发病也呈现季节性变化特征[5-6]。一项针对接受住院治疗和医院看护的老人群体身体健康情况的研究表明,昼夜温差变化会直接影响到这些老人的心血管、呼吸系统、消化系统以及泌尿生殖系统的健康状况,甚至有可能导致老人在夜间死亡[7]。一项针对高温对人体消化系统疾病影响的研究表明,高温会直接影响人体消化系统,高温情况下,尤其是当气温>25 ℃时,人体罹患消化系统疾病的风险骤增[8]。而湿度变化对人体健康的影响则更为直接和迅速[9]。无论是在高温高湿还是低温干燥的气象条件下,人体都会感到不舒适。因此,气象条件和人体健康必然存在着或多或少的联系,这种联系可用气候舒适度表征[10]。
以往研究气象条件对人体健康的影响,尤其是对上呼吸道感染疾病(以下简称“上感”)的影响主要以我国北方城市为典例,这些城市上感发病的峰值往往出现在冬季和春季。本研究选取南部沿海深圳市和西南地区攀枝花市,在地理位置和气候特征上都与北方城市有较大区别。因此,选取这两座城市进行研究与比较,可以部分地弥补我国以往同类研究的不足。
此外,现有研究中分析不同气象要素与某种疾病的关系多采用逐步回归和最优子集回归[11]。考虑到气象要素变化和人体疾病发病存在着一定的滞后响应效应,过去常采用广义相加模型和分布滞后非线性模型[11-12]。这类模型的显著优点是便于考虑滞后性,能够很好地体现气象要素和患病人数变化的时间序列关系,有利于结果的分析和检验。但缺点是预报能力不足,并且依赖数据间的回归关系。近年来,机器学习模型凭借其强大的计算机科学方法的支撑,能有效地利用大数据建立可靠模型[13-14]。同时,机器学习模型尤其是深度学习模型不需要数据间有强回归关系,模型便可通过学习搭建数据间的联系,在数据间回归关系不明显时依然能够给出较准确的预报。目前,机器学习模型在气象学领域内主要被应用在对雷暴大风、短时强降雨和暴雪等极端天气现象的短临预报中[16-17],在大气污染物浓度预报和大气主要污染物类型预报等相关方向也有应用[15]。深度学习则被应用于对闪电的预报和对雷达回波图的处理等更具挑战性的领域[18-19]。但其在气象医学这一新兴交叉学科领域应用的甚少。因此,本文拟在探明上呼吸道感染发病与气象条件关系的基础上,重点选取两种机器学习模型(经典随机森林模型和RNN 深度学习模型),利用两地疾病数据和气象数据进行训练,并考虑了气象数据所反映的天气过程及其周期性特征以及与医院就诊人数的滞后响应关系。基于对试预报结果的分析和检验,又对两种机器学习模型进行优选,旨在好中选优、最大限度提高预测效果、提升预测能力。
1 资料和方法
1.1 资料
资料选取深圳市某三甲医院2014 年8 月20日—2017 年8 月16 日的到院上呼吸道感染(ICD编码J39.900)挂号就诊的病例数据,共计1 093 组238 607 例。选取四川省攀枝花市某三甲医院2015年1 月1 日—2019 年12 月31 日到院上呼吸道感染挂号就诊的病例数据,共计1 825 组629 605 例。病例数据来自国家人口与健康科学数据共享平台(http://www.bmicc.cn/web/share/home)。在质量控制过程中已去除录入错误、重复和复诊。
气象资料选取深圳市与疾病数据同期的2014年8 月20 日—2017 年8 月16 日的常规地面气象观测资料。选取攀枝花市与疾病数据同期的2015 年1 月1 日—2019 年12 月31 日的常规地面气象观测资料。数据来源于中国气象科学数据共享服务网。包括日平均(最高、最低)气温、日平均(最高、最低)气压、日平均相对湿度、日降水量、日平均风速、日照时数等气象要素。
借鉴前人关于气象要素和呼吸系统疾病关系的研究,本文主要选取当地的气温、湿度和风速3 种与呼吸系统疾病发病密切相关的气象要素作为分析和预报因子。
1.2 研究方法
1.2.1 线性相关性分析
不同气象要素和当地医院的上呼吸道感染发病的就诊人数通常有可通过检验的明确的线性相关性,可用Pearson 相关系数来衡量。根据它们的Pearson 相关系数可以直观快速地确定不同气象要素与当地医院就诊人数的相关程度。
Pearson 相关系数计算公式:
式中:r 表示相关系数,Xi表示气象要素,Yi表示当地医院就诊人数,n 表示样本容量分别表示Xi、Yi的平均值。
1.2.2 平滑处理
一般天气过程通常持续3~5 d,往往伴随大风、降温或降雨等天气现象,各种气象要素会有较大幅度的变化。为了更好地反映整个天气过程对上感发病可能产生的影响,需对原始数据进行必要的平滑处理。平滑处理可以在滤除原始数据中小扰动的同时反映数据中天气过程的整体效应,在一定程度上会提高数据的有效性。本研究选取了3 和5 d 两种情况作为时间步长计算滑动平均。
1.2.3 随机森林(Random Forest)模型
随机森林(Random Forest,以下简称“RF”)模型是一种基于决策树的经典机器学习模型(图1)。一个完整的随机森林模型通常包含了大量的决策树,这些决策树会形成一个整体,对输入数据进行训练和学习并生成输出数据[20]。在一次完整的随机森林学习过程中,模型首先会对输入数据进行套袋,即将完整的数据按照一定的方式(随机或按序列)进行分装。数据完成套袋后统一进行分配,在每个决策树中进行训练[21]。这样的分配方式可以保证每个决策树都尽量得到相同数量的训练数据。每个决策树单独完成训练之后,所有训练结果被汇总并统计,随后给出一个预测结果。该预测结果可用于和实际数据进行比较,来检验模型的预报能力。随机森林模型的优势在于可以调整模型的训练细节,通过对决策树的适当限定和修正来防止模型过拟合[22-24]。
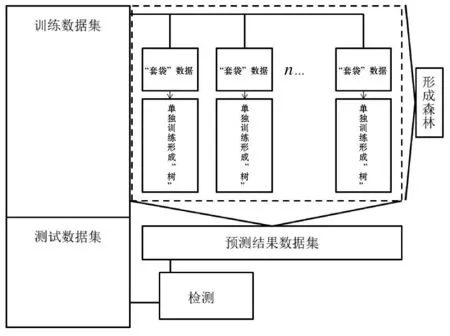
图1 随机森林模型训练和测试过程
1.2.4 RNN(Recurrent neural network)模型
递归神经网络模型(RNN 模型)源自前馈神经网络模型。RNN 模型可以使用其内部状态(内存)来处理可变长度的输入序列[25]。RNN 模型能够利用输入数据对模型本身完成多次重复性的训练,最终的训练结果取决于所有先前的计算和输入。选取一个恰当的训练次数,可以防止模型过拟合。RNN 模型在执行具有时间序列性的预测任务时能够展示出强大的计算和预报能力。
图2 为基本RNN 模型的结构。xt,st和ot分别是时间t 的输入、隐藏状态和输出。U、V、W 是所有步骤/时刻共享的网络参数,用于计算隐藏状态和输出。作为网络的存储单元,st是通过上一步的隐藏状态和当前步骤的输入获得:
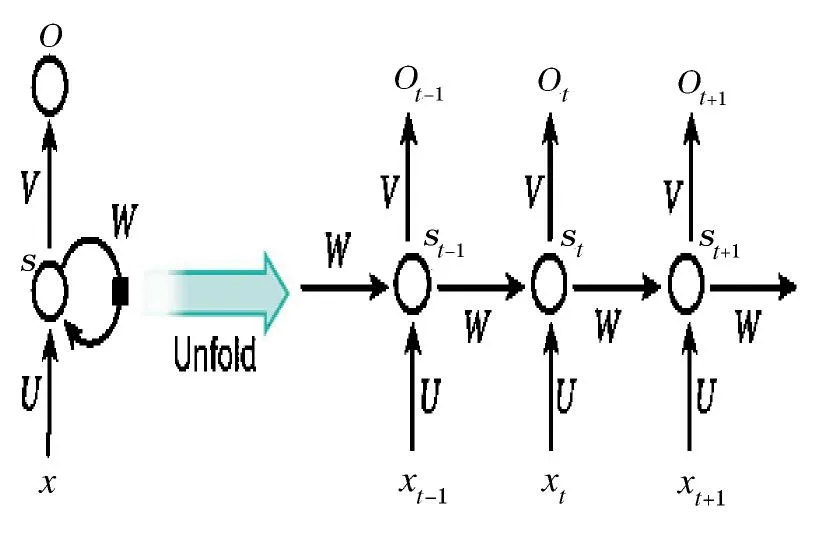
图2 基本RNN 模型结构展示
激活函数f 通常是非线性的;初始的隐藏状态通常会用全零初始化,作为时间t 的输出。
为避免出现过度拟合现象,本次研究中在常规训练误差中加入了Validation 误差(检验误差)来决定何时终止重复训练,以保证恰当有效的预报结果。
1.2.5 数据样本划分
为保证模型获取足够的样本进行训练,同时留恰当的样本对模型给出的试预报结果进行检验比较,本文在综合考虑并试验了几种不同的数据样本划分方法后,优选了将数据样本序列按8∶2 的比例进行划分。即按时间顺序选取前80%的数据样本对模型进行训练,保留后20%的数据样本对模型进行试预报检验。划分后的数据样本集即可直接用于RNN 模型的训练,但是,基于随机森林模型的特殊训练方式,还需将划分后用于训练的数据再次进行划分。依据对深圳市和攀枝花市上呼吸道感染发病年际变化特征的分析,本文对深圳市的气象要素和患病人数数据分别按9 月—次年2 月、3—8 月进行划分。将9 月—次年2 月的数据样本集称为深圳市就诊人数下降趋势数据样本集;将3—8 月的数据样本集称为深圳市就诊人数上升趋势数据样本集。同理,对攀枝花市的气象条件和患病人数数据分别按照1—6 月、7—12 月进行划分。将1—6 月的数据样本集称为攀枝花市就诊人数下降趋势数据样本集;将7—12 月的数据样本集称为攀枝花市就诊人数上升趋势数据样本集。
2 结果分析
2.1 上呼吸道感染发病的月际变化特征分析
2014 年8 月—2017 年8 月深圳市上感就诊人数共计239 293 人次。如图3 所示,深圳市上感的逐月就诊人数呈明显的年变化特征。2 月出现一个谷值,这可能与中国传统节日春节有密切关系。此时有大量外地务工人员回家探亲。之后,就诊人数出现了大幅反弹,3—7 月上感就诊人数增幅较大,并在7月达到峰值,反映出深圳市居民受热不舒适度气候条件的影响较大。
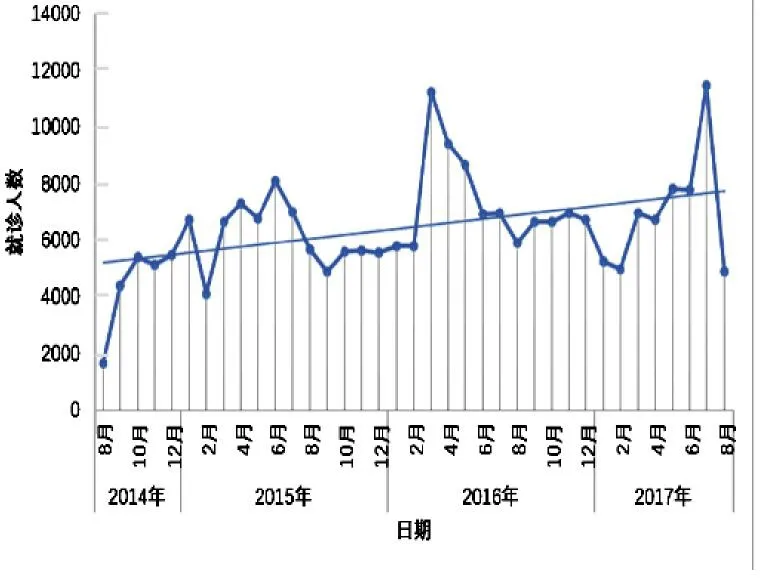
图3 2014—2017 年深圳市上呼吸道感染月发病就诊人数变化特征
2015 年1 月—2019 年12 月攀枝花市上感就诊人数共计629 605 人次。如图4 所示,攀枝花市上感的逐月就诊人数同样呈明显的年变化特征。上半年(1—6 月)上感就诊人数呈波动式下降,6 月降到谷值;从7 月开始上感就诊人数又呈波动式增加,次年1 月达到最大峰值。另外,2018 年12 月当地上感就诊人数达到峰值(接近2 000 例)。
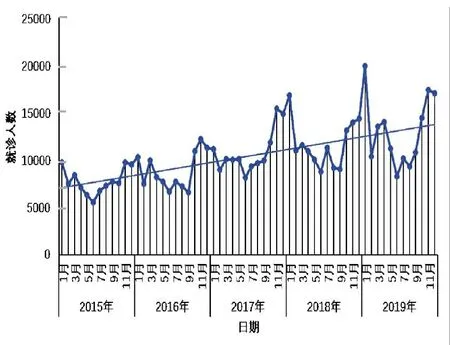
图4 2015 年1 月—2019 年12 月攀枝花市上呼吸道感染逐月发病人数的变化特征
2.2 上呼吸道感染发病人数与气象要素关系的分析
借鉴以往的研究,直接使用气象数据与上感就诊人数数据间的线性关系进行分析的效果并不理想,但对数据间的线性关系进行分析依然能够对选取恰当的数据输入后续模型提供必要的参考。采用线性关系更强的数据对机器学习模型进行训练可以减少训练时间,提高训练结果。因此,本研究首先评估了深圳市和攀枝花市1~6 d 的滞后时段,分别计算了3 和5 d 滑动平均日平均气温、日平均相对湿度和日平均风速与上感就诊人数的Pearson 相关系数(表1~4)。
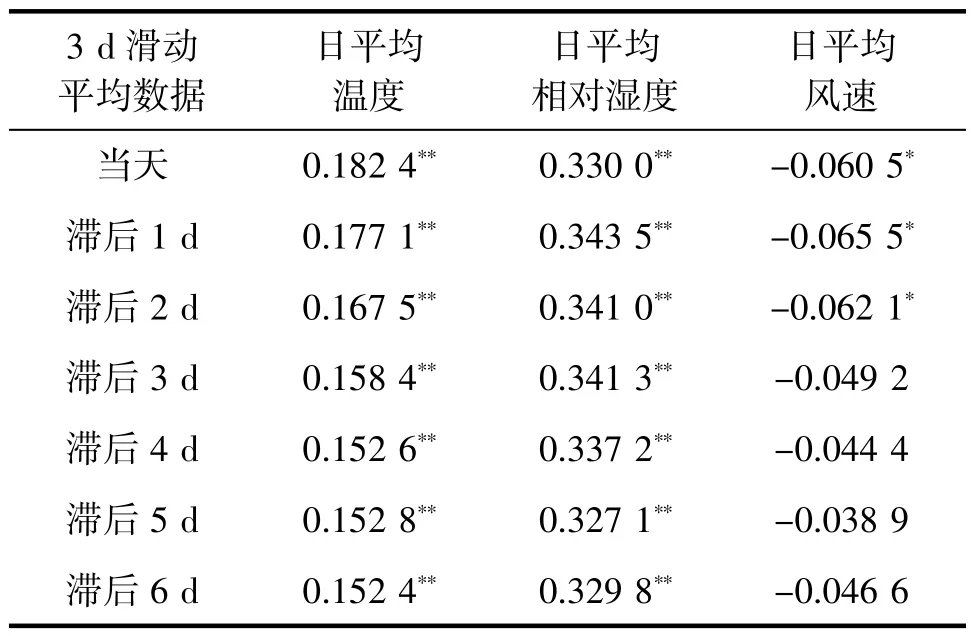
表1 深圳市3 d 滑动平均气象要素在不同滞后时间与上呼吸道感染发病就诊人数的Pearson 相关系数
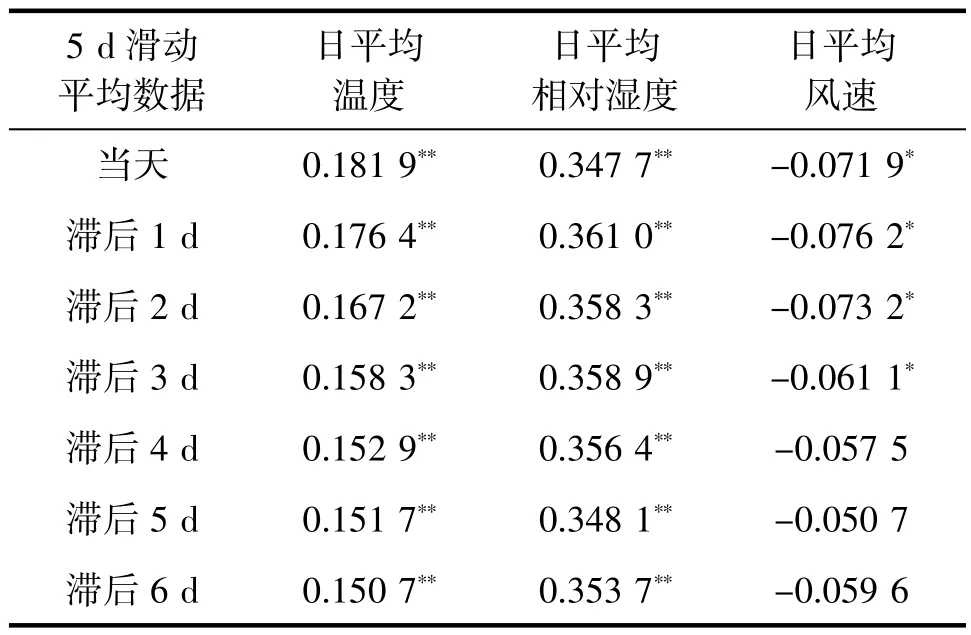
表2 深圳市5 d 滑动平均气象要素在不同滞后时间与上呼吸道感染发病就诊人数的Pearson 相关系数
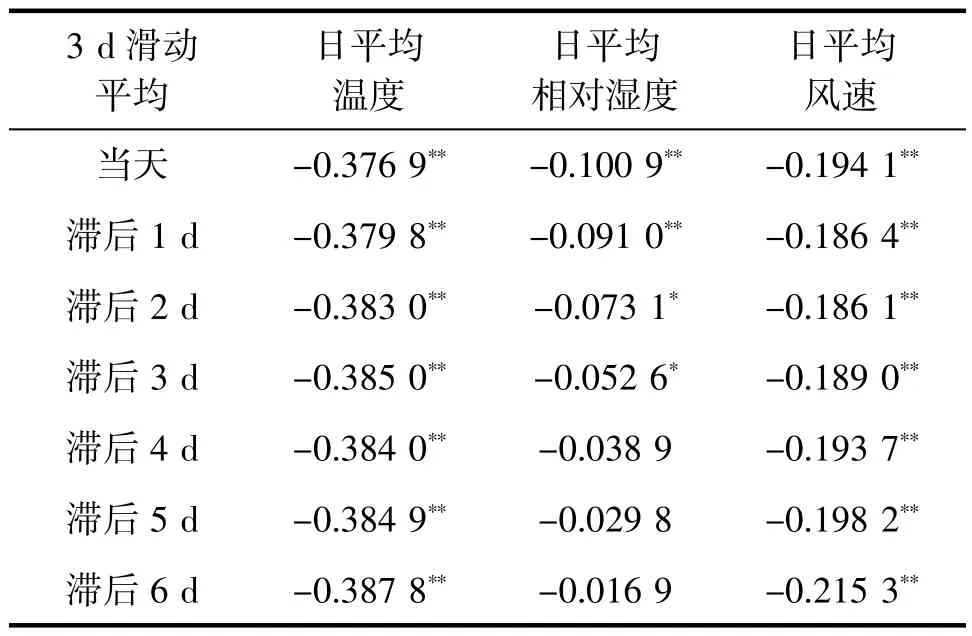
表3 攀枝花市3 d 滑动平均气象要素在不同滞后时间与上呼吸道感染发病就诊人数的Pearson 相关系数

表4 攀枝花市5 d 滑动平均气象要素在不同滞后时间与上呼吸道感染发病就诊人数的Pearson 相关系数
深圳市温度和相对湿度与上感发病人数的相关系数绝对值均<0.4,但显著性检验结果表明两者均与上感发病存在强相关;攀枝花市温度和风速与上感发病人数的相关系数绝对值均<0.43,但显著性检验结果表明两者均与上感发病存在强相关。深圳市风速均与上感发病只存在弱相关或不存在相关;攀枝花市则是湿度与上感发病的相关性会随着滞后时段的增加而减弱,在当天和滞后1 d 时存在强相关,在滞后2 和3 d 时存在弱相关,在滞后超过3 d时则不存在相关。以表中相关系数的强弱和显著性检验结果为依据,综合考虑三者体现出的不同滞后响应关系,本研究最终选取滞后时间为1 的3 d 滑动平均数据作为深圳市典型数据用于机器学习模型的训练和试预报;选取滞后时间为当天的5 d 滑动平均数据作为攀枝花市典型数据用于机器学习模型的训练和试预报。
2.3 基于随机森林模型训练和预报的结果分析
对深圳市和攀枝花市按上述数据划分方法划分后,采用随机森林模型进行训练和检验,其结果见图5,训练误差和检验结果见表5 和表6。
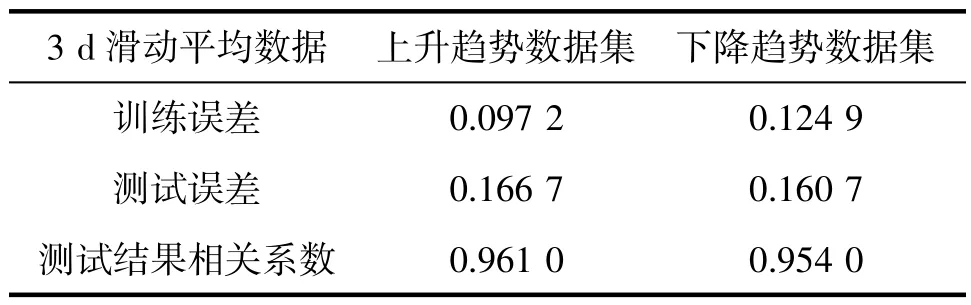
表5 基于随机森林模型使用分类数据对深圳市上呼吸道感染发病风险试预报检验结果
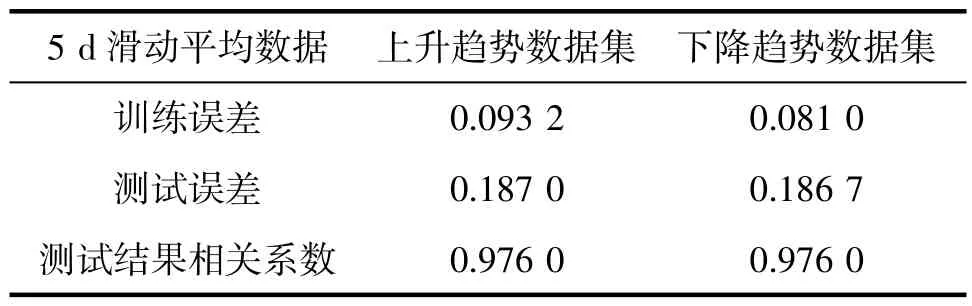
表6 基于随机森林模型使用分类数据对攀枝花市上呼吸道感染发病风险试预报检验结果
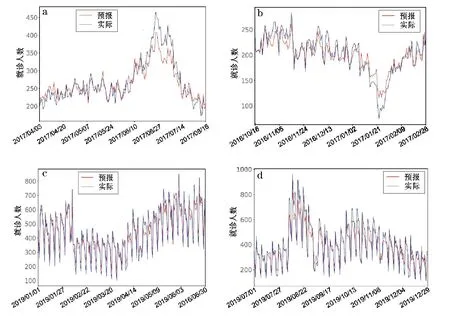
图5 基于随机森林模型使用分类数据对上呼吸道感染发病风险试预报检验结果(a、b 为深圳市,c、d 为攀枝花市)
结果显示,基于分类数据构建的随机森林模型能较好地预报大部分情况下两地的就诊人数变化情况。同时,随机森林模型能够较为准确地识别就诊人数的变化趋势,但针对极值的试预报存在极大值预报结果偏低、极小值预报结果偏高的情况,呈现出较大的预报误差。但从整体结果上来看,随机森林模型能够提供具有一定指导意义的试预报结果,但预报结果的准确率还有待进一步提高。
2.4 基于RNN 模型训练和试预报的结果分析
将深圳市和攀枝花市典型数据按数据划分方法划分后,利用RNN 模型进行训练和检验,训练次数分别设置为50 次(图6a、6c)和300 次(图6b、6d),并对试预报结果进行检验。训练误差和检验结果见表7~8。
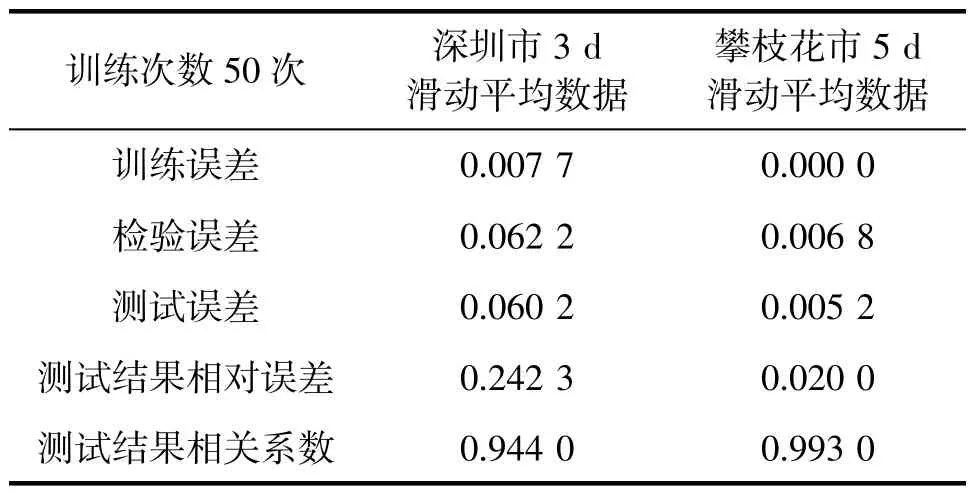
表7 基于RNN 模型训练50 次时对上呼吸道感染发病风险试预报检验结果
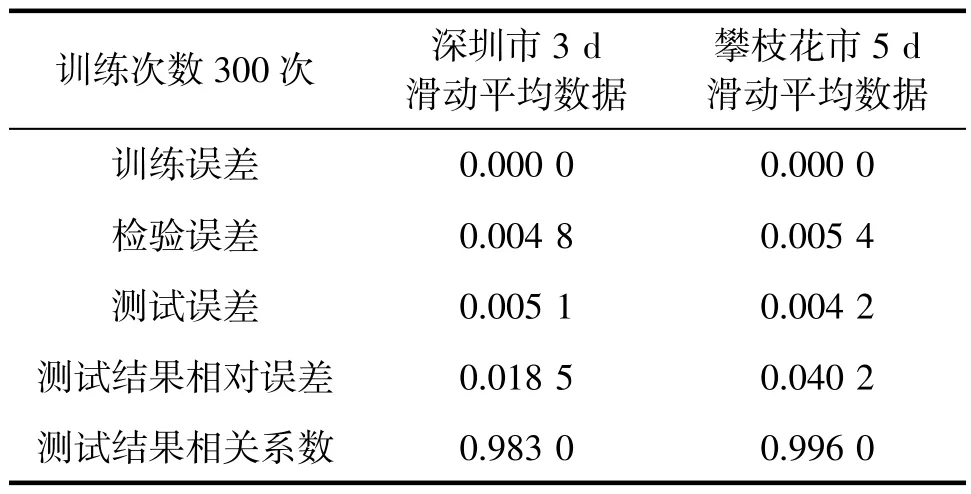
表8 基于RNN 模型训练300 次时对上呼吸道感染发病风险试预报检验结果
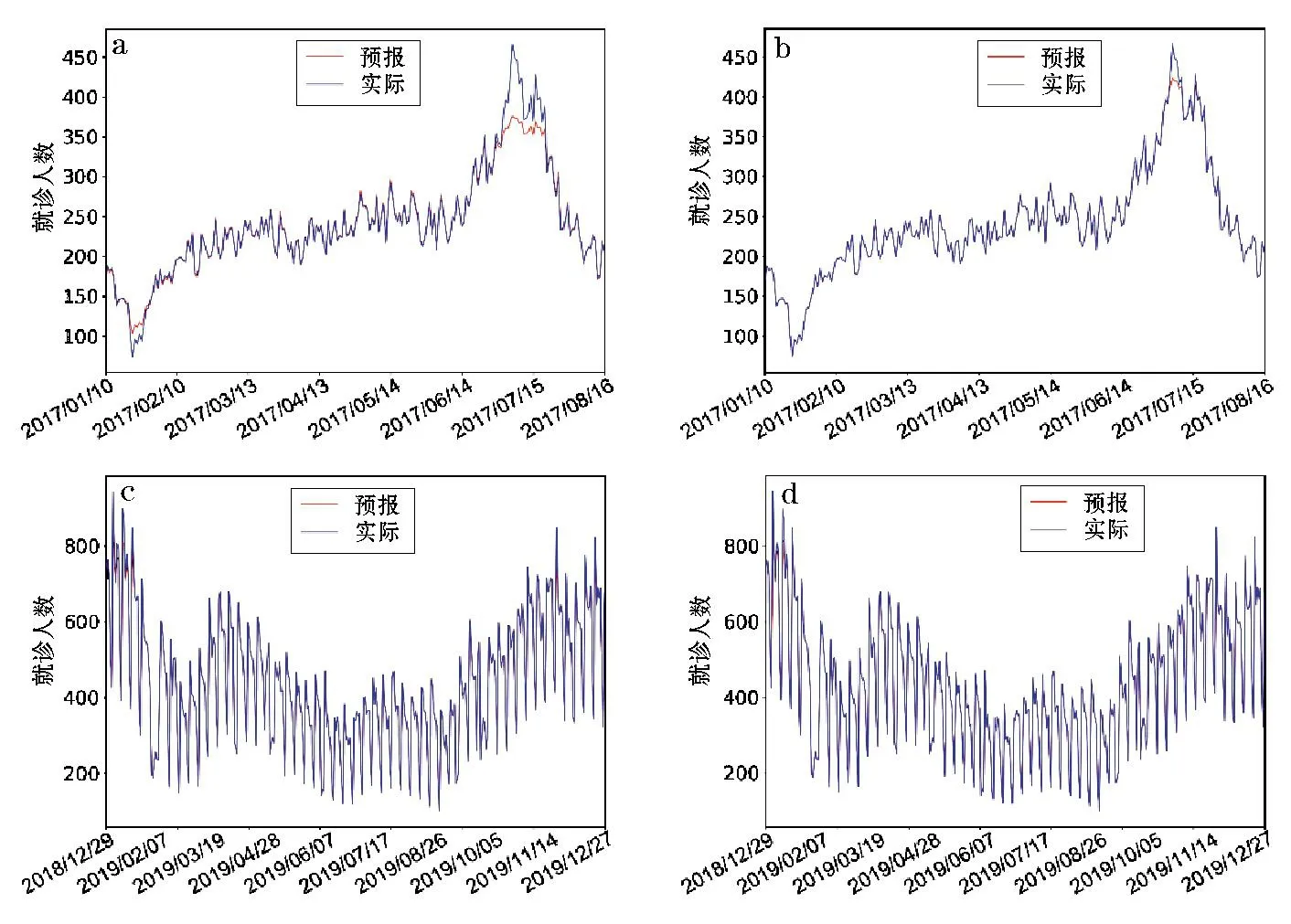
图6 基于RNN 模型对上呼吸道感染发病风险试预报检验结果(a、b 为深圳市,c、d 为攀枝花市)
深圳市、攀枝花市上感发病风险RNN 模型试预报检验结果显示,与随机森林模型试预报结果相比,该模型对上感就诊人数有很好的预报效果,试预报就诊人数和实际就诊人数契合度高,在峰值预报上有较明显的改进。通过比对训练误差和Validation误差(检验误差),发现两者相差不大,说明RNN 模型没有出现过拟合的现象,模型有效。试预报误差主要分布在上感就诊人数的峰值和谷值。同时比较50和300 次训练所得试预报结果发现,提高RNN 模型训练次数可以有效提高模型的预报。
通过对比随机森林模型和RNN 模型(表5~8)的具体训练误差和检验误差可知,RNN 模型的试预报能力明显好于随机森林模型,大部分情况下RNN模型给出的试预报结果与实际就诊人数基本吻合。但是,对于RNN 模型在上感就诊人数的峰值和谷值的试预报上仍然存在有误差,且该误差无法通过增加训练次数来完全消除,有待后续工作中增加样本、改进方法等多措并举来进一步改进与提高。
3 结论与讨论
本文对华南地区深圳市、西南地区攀枝花市2个不同气候区上呼吸道感染发病特征及其与气象条件关系分析的基础上,进而对其发病风险预测进行了探究,主要得出以下结论:
(1)2014 年8 月—2017 年8 月深圳市上感发病集中在3—7 月,8—12 月发病人数相对较少,谷值出现在2 月(可能与深圳市外来人口多,大批人员返乡过春节有关),以热不舒适效应为主导。2015 年1 月—2019 年12 月攀枝花市上感发病集中在11月—次年1 月,夏半年(4—9 月)发病人数相对较少,谷值出现在6 月,以冷不舒适效应为主导。
(2)日平均气温的变化对两地上呼吸道感染发病的影响最明显,当日平均气温>25 ℃或者<10 ℃时,两地上呼吸道感染发病风险明显上升;影响次之的是日平均风速,风速的大小可侧面反映当地的大气扩散条件和舒适感,进而对上呼吸道感染发病产生影响;日平均相对湿度和日平均气温的协同作用对人体舒适度产生影响,同样也会影响人群上呼吸道感染发病情况。
(3)运用随机森林机器模型和RNN 深度学习模型对深圳市和攀枝花市两地上呼吸道感染发病风险进行预测研究。结果表明,两种方法均能通过所构建的预测模型,有效地运用相关气象资料预报上感发病人数的变化情况。使用随机森林模型时需要根据当地气候特点和上感发病特征对数据进行分类,预报结果虽然存在误差,但也能够反映上感发病变化趋势。使用RNN 模型时无需对数据进行分类,且能给出更为准确的患病人数试预报结果,只在峰值和谷值处存在部分误差。与随机森林模型相比,RNN模型在运用气象资料预报上呼吸道患病人数方面精度更高,表明其在健康气象领域内将有更好的应用潜力。
与国内外同类研究所表现出的不足之处有相似性,即随机森林和RNN 两种方法所构建的预测模型,对峰值和谷值的预测有缺陷,即预测的峰值偏低、而谷值则往往偏高;相比之下RNN 方法比随机森林方法对峰值和谷值的预报误差要小得多,但仍需通过多种方法进一步改进提高。
猜你喜欢
猪业科学(2022年4期)2022-04-29 07:40:24
中国土壤与肥料(2021年5期)2021-12-02 01:06:00
成都信息工程大学学报(2021年3期)2021-11-22 07:17:52
汽车维修与保养(2021年12期)2021-03-08 09:33:30
汽车维修与保养(2020年10期)2021-01-22 06:36:06
汽车维修与保养(2020年4期)2020-07-18 02:33:00
时代人物(2019年29期)2019-11-25 01:35:04
水利技术监督(2018年5期)2018-10-20 02:07:42
当代县域经济(2018年8期)2018-08-10 08:06:32
环境保护与循环经济(2017年1期)2017-09-26 11:44:31
