
反迁移学习的隐私保护联邦学习
2023-09-07 08:47许勐璠李兴华
西安电子科技大学学报 2023年4期
许勐璠,李兴华
(1.陕西师范大学 计算机科学学院,陕西 西安 710199;2.西安电子科技大学 网络与信息安全学院,陕西 西安 710071)
1 引 言
近年来,联邦学习(Federated Learning,FL)作为一种新兴的机器学习隐私保护范式,通过上传各参与方的中间计算结果来保护原始数据不被泄露,已成为机器学习安全合法训练模型的一个潜在解决途径[1-2]。然而,FL在聚合全局模型的过程中对多个参与者公开全局模型,增大了全局模型泄露的风险。例如,恶意参与者通过发起模型窃取攻击,无需花费大量时间、金钱、人力去收集数据训练模型,将有价值的模型非法复制、重新分发或滥用,严重损害了诚实参与者的利益,已成为限制FL发展的一大瓶颈[3-4]。
为了对模型所有者的知识产权进行保护,现有研究分别从两个方面开展:基于所有权验证的事后举证方法和基于授权的事前防御方法。前者利用后门攻击为模型构造水印或将水印嵌入模型参数中,并从模型中提取特定的指纹来验证模型所有权[5-7]。然而,在窃取模型过程中,基于授权的事前防御方法易被攻击者改变甚至移除,此时用原来的水印将无法验证模型的所有权,即使可以利用水印进行举证并验证其所有权,仍无法防止攻击者非法使用窃取到的模型。后者需要使用正确的密钥或获得可靠硬件设备的授权才能正常使用模型[8-9]。文献[9-10]在现有基于授权的知识产权保护方案的基础上,进一步提出了反迁移学习(Non-Transferable Learning,NTL)算法,确保授权的参与者仅在授权数据上使用模型,实现了模型不被授权用户在非授权数据上滥用。近年来,基于授权的知识产权保护方案由于能够保证模型在非授权环境不被滥用,逐渐受到知识产权保护领域研究者们的关注。
现有方法利用原始数据通过生成对抗网络生成额外训练数据,最大化生成数据与原始数据的差异并训练模型,实现模型的反迁移,确保了模型被用于非授权数据时性能大幅度降低。然而,FL仅上传梯度训练全局模型,云平台无法利用本地原始数据生成额外训练数据来实现全局模型的反迁移。虽然可以在本地利用原始数据进行反迁移学习保护模型知识产权,但仍无法直接适用于FL中。这是由于FL聚合梯度的过程会破坏本地模型反迁移学习的效果,使得本地NTL失效。文中在实验中进一步验证了本地NTL后直接聚合梯度的模型在辅助域的性能,直接聚合训练的全局模型在未授权的部分本地验证集上最高性仍能达到约69%。因此,如何确保全局模型的NTL有效,防止全局模型在未授权领域滥用,已成为当前FL的一大挑战。此外,在反迁移学习过程中的梯度隐私也需要保护。已有研究表明,直接共享本地梯度易遭受梯度泄露攻击[11-12],攻击者通过梯度能够进一步推断出原始数据,获取本地数据隐私。因此,还需要在保护模型知识产权的同时,确保梯度隐私不被泄露。其中,基于密码学的隐私保护方法较基于差分隐私的方法计算精度更高,且不依赖可信硬件辅助,是当前隐私保护联邦学习的一大研究方向[13-14]。
为了应对上述挑战,笔者提出了一种FL下的模型知识产权与隐私保护方法,称为联邦反迁移(Federated Non-Transferable Learning,FedNTL)。该方法采用同态加密构建FL隐私保护框架,在梯度聚合过程中引入反迁移的思想,设计一种基于梯度的反迁移算法,在保护训练过程本地梯度隐私的同时,确保了模型仅能被授权用户在已授权的领域内使用。主要贡献如下:
(1) 提出了一种基于Paillier同态加密的联邦反迁移隐私保护框架。设计了基于梯度盲聚合的交互式反迁移学习算法,在保护全局模型知识产权的同时,确保梯度隐私不被泄露。
(2) 设计了一种基于NTL的交互式协同训练方法,本地数据拥有者和云平台协同盲聚合本地表征向量,并最大化表征向量与阻碍向量之前的互信息,实现模型在未经授权的数据使用时,无法获得准确输出。
(3) 严格证明了所提方案的正确性和安全性,并在公开数据集上进行验证。与现有方案相比,文中模型在未授权领域的性能降低了约47%,计算复杂度实现了梯度维度级的降低。
2 相关工作
深度学习模型在计算机视觉、自然语言处理和数据挖掘等任务中的成功应用是以昂贵的训练过程为代价的。为了保护深度学习模型的知识产权,袁程胜等[5]设计了一种基于时间戳的后门水印验证框架,借助时间顺序来鉴别模型版权,在不削弱原始任务性能的同时,实现了模型版权的主动保护和被动验证。SHARMA等[6]使用所有者的签名和指纹作为双重水印来验证模型所有权,并在容量方面较现有方案大幅度提升;LIU等[7]提出将同一个特征域触发器解析为像素域内的多个水印,进一步提高了水印的随机性、隐蔽性和抗木马检测能力。该类方案虽然能够通过特定的输入输出或水印来验证模型所有权,但极易受到基于模型微调或再训练、水印覆盖和模型修剪等水印去除攻击,导致模型所有权验证失效。文献[15]进一步提出了一种FL中的多方纠缠水印算法。在本地训练和全局聚合过程中分别设计了一种水印增强算法和一种纠缠聚合算法,解决了多后门水印造成的版权混淆失效以及模型精度降低的问题,实现了FL的模型所有权验证。然而,在基于水印的所有权验证方案中,模型所有者仅能在发现模型被窃取后进行举证等事后维权,无法防止攻击者非法使用窃取到的模型。
针对该问题,ALAM等[8]提出基于深度神经网络的安全授权方案。该方案通过密钥调度算法,利用储存在S-Box设备中的主密钥生成密钥,对深度神经网络模型的每个参数进行加密,在加大模型窃取难度的同时,确保了在不知道合法密钥的情况下,未经授权的使用会大幅度降低模型输出的准确性。CHAKRABORTY等[9]提出了一种基于硬件辅助的深度模型知识产权保护框架,该架构混淆了模型的学习权重空间,以锁定深度学习模型的权重参数,并在可信硬件上运行深度神经网络,该硬件应用嵌在芯片上的密钥来运行模型,确保了训练的深度学习模型仅在此类可信硬件设备上表现出较高的预测性能。该类方法能够确保模型仅在授权的设备或用户上表现出较高的性能,非授权用户即使窃取到模型也无法准确分类或预测数据。然而,无法限制授权用户在非授权领域对模型的滥用,且需要硬件设备辅助。为了进一步确保模型仅能被授权用户在限定的领域使用,WANG等[10]提出了一种基于深度模型的反迁移学习方法,利用像素级掩码对原始数据进行处理,固定源域的Kullback-Leibler(KL)散度,提高目标域数据的KL散度,并最大化源域数据和目标域数据特征分布之间的最大均值差异(Maximum Mean Discrepancy,MMD),从而确保模型仅在授权数据上性能较高。
综上所述,现有模型知识产权保护研究已取得一定的进展,基于反迁移学习的方法可以在保护模型知识产权的同时,确保模型在授权数据和用户上的性能,但无法适用于多用户的联邦学习中。现有研究的粗粒度对比如表1所示。
3 预备知识
3.1 所用符号
为了便于参考,文中方案出现的符号和相应的描述如表2表示。

表2 符号描述
3.2 联邦学习
FL是谷歌人工智能团队于2016年提出的一种保护隐私的机器学习范式,其训练过程如图1所示。不同用户在本地训练各自的子模型,将本地训练的梯度上传到服务器进行聚合,而不直接上传原始数据。在FL中,服务器协调整个训练过程,直至模型精度达到预期水平或预设迭代次数。其中,训练的目标是找到最优的模型参数w,对于给定的特征向量x,模型的输出无限接近正确的标签y。
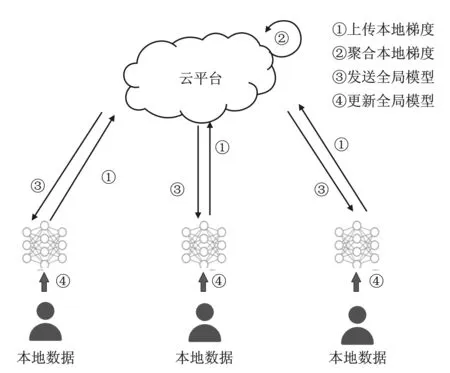
图1 联邦学习
3.3 反迁移学习
NTL是WANG等在2022年发表在深度学习领域顶级会议ICLR上剔除的针对模型窃取攻击的事前防御方案。该方案以信息瓶颈理论[16]为方法论,通过在模型训练过程增大源域和辅助域数据之间的表征距离,显著降低模型在源域之外的数据域上的性能,具体流程如图2所示。该算法主要分为:①设计生成对抗增强框架,利用原始数据生成邻域数据;②对原始数据和生成的邻域数据进行处理,通过对抗生成框架获得邻域数据,并将附加掩码的原始数据作为NTL的源域,带掩码与不带掩码的邻域数据并集作为辅助域,进行NTL训练;③通过提高辅助域数据的表征向量z与阻碍Nui之间的香农互信息I(z;n),使z中包含的关于正确标签y的信息被大大减少,从而确保模型在未经授权数据域上使用的性能显著降低。
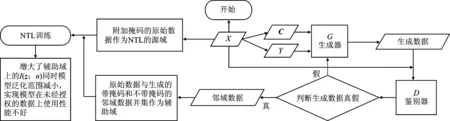
图2 反迁移学习(X:原始数据;C:噪声向量;Y:one-hot形式的标签)
4 问题描述
4.1 系统模型
如图3所示,文中系统模型包括n个本地数据拥有者(Local Data Owner,LDO)、云平台(Cloud Platform,CP)和密钥分发中心(Key Distribution Center,KDC)。
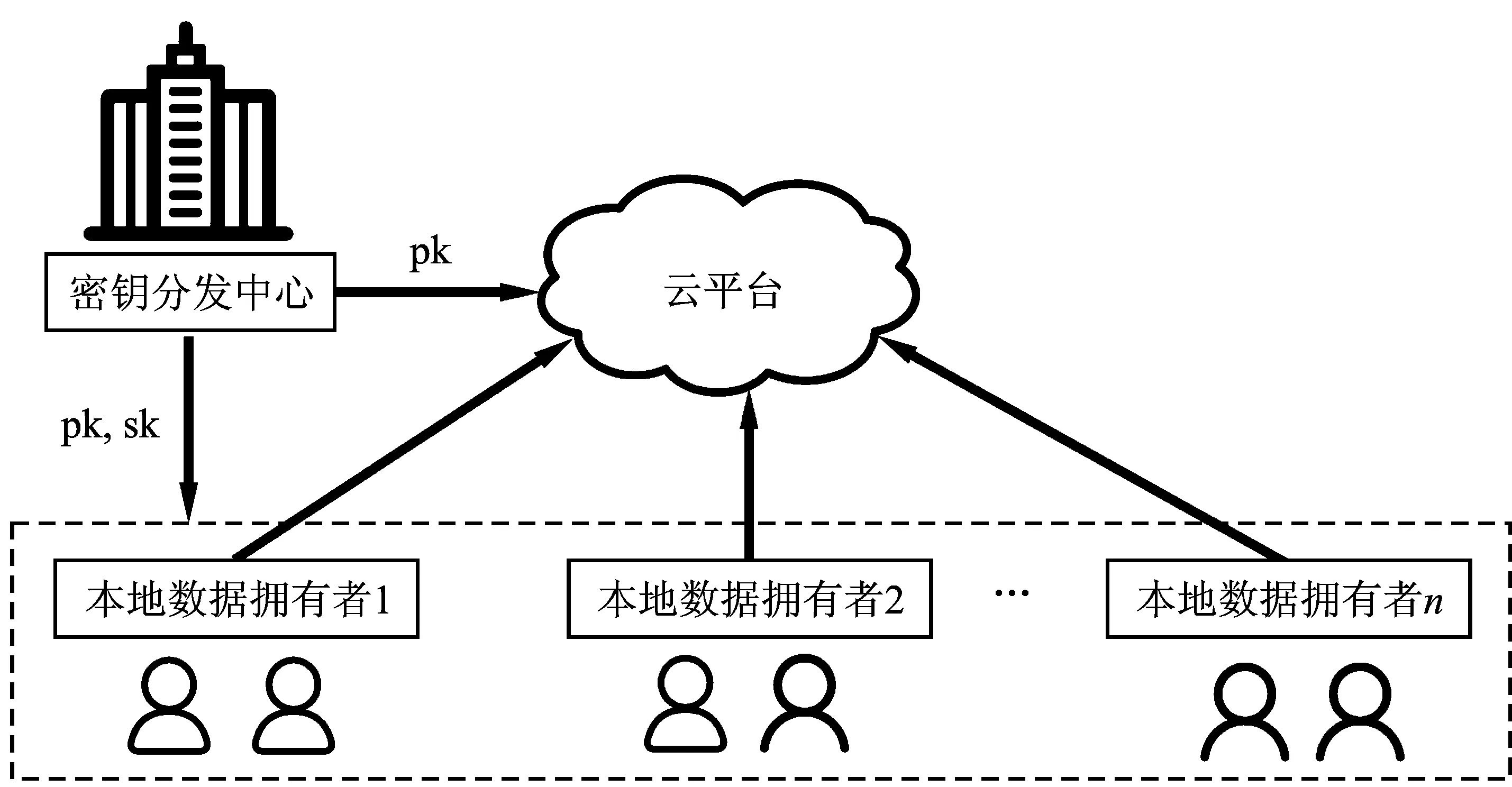
图3 系统模型
(1) 本地数据拥有者。每个本地数据拥有者在本地数据上迭代训练模型,并将每次迭代训练过程中的辅助域表征向量和梯度盲化后上传至CP。
(2) 云平台。CP是一个具有足够存储空间的半诚实云服务器,聚合不同LDO上传的盲化表征向量和盲化梯度,返回全局表征向量和全局梯度以更新全局模型。
(3) 密钥分发中心。受信任的KDC负责系统中所有密钥的分发和管理,用于模型训练的初始化阶段。
4.2 威胁模型
在文中方案中,CP和LDO在任意时刻均为诚实但好奇的半诚实实体,它们会严格执行预定义的协议和算法,但会尝试从梯度等中间参数中推断其他实体的输入信息。在模型训练过程中,潜在的安全威胁如下。
(1) 模型窃取攻击。在文中方案中,模型窃取攻击主要包括了以下3种情况:
① 未授权用户在无需花费模型训练等代价的前提下非法窃取模型后滥用,损害已授权用户的权益。
② 已授权用户能够不受限制地使用模型,将模型用于与之前领域相似的未授权数据,损害了其他已授权用户的权益。
③ 不同已授权用户利用NTL训练模型。在聚合全局模型的过程中,不同LDO在NTL训练过程中的梯度会相互干扰,导致部分本地的NTL失效,增大模型窃取攻击成功率。
(2) 梯度泄露攻击。CP聚合不同LDO上传的梯度,由于梯度是本地数据的映射,CP可以通过发起梯度泄露攻击,推断出不同LDO的原始数据。
4.3 设计目标
FedNTL有以下3个设计目标:
(1) 有效性。经过NTL后聚合本地梯度得到的全局模型,能够使其在非授权数据域上的模型性能较低,而在源域数据分布上却具有较高的模型性能。
(2) 安全性。如果一个协议对半诚实的敌手是安全的,那么它不允许参与方从协议中学习任何额外的信息。在文中方案中,需要防止CP或LDO通过梯度推导出其他LDO的原始数据,因此要确保梯度等中间参数保密不泄露。
(3) 正确性。经过L次全局梯度聚合仍可得到正确的平均梯度并更新全局模型。
5 基于盲化梯度的联邦反迁移隐私保护方法
FedNTL流程如图4所示。它主要分为3个阶段:系统初始化、模型训练和模型更新。
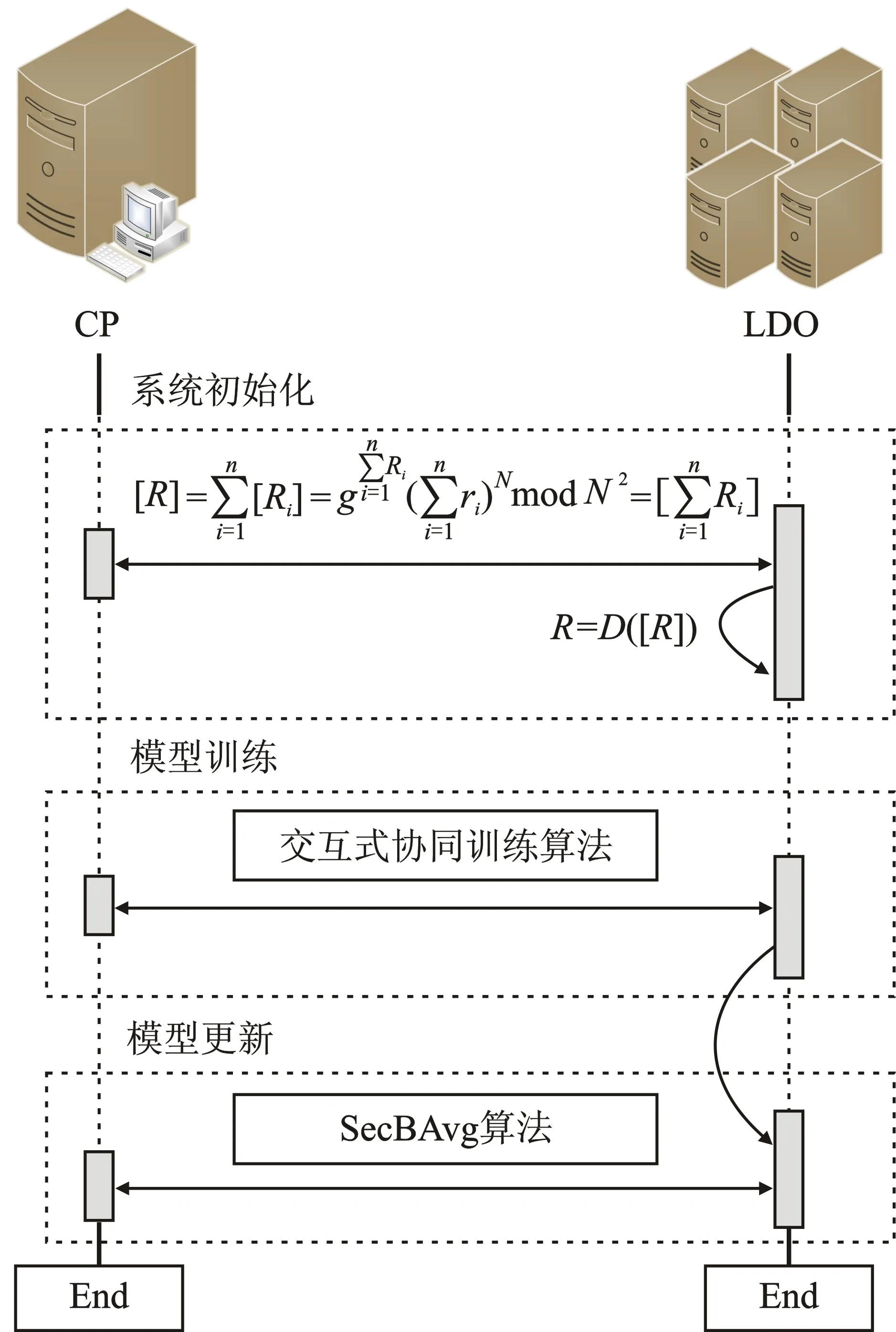
图4 FedNTL总览
5.1 系统初始化
文中方案使用的密钥对(pk,sk)由完全可信的KDC生成,并分发给授权的本地LDO。其中,密钥对是通过具有加法同态性的Paillier公钥加密系统生成。该密码系统简述如下。
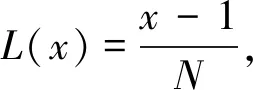

C=E(m,r)=gmrNmodN2。
(3)
(4)
(5)
Paillier密码系统是语义安全的,即同一明文可加密成多个不同的密文形式,且所有密文都是计算不可区分的。利用Paillier密码系统的加法同态性,LDO和CP协同生成盲化因子R。不同LDO随机选取一个本地盲化因子Ri,i∈[1,n],并利用公钥pk加密后上传至CP,CP聚合LDO上传的本地加密盲化因子[Ri],i∈[1,n],并结合式(3),利用Paillier的加法同态性对加密的本地盲化因子求和,得到加密的全局盲化因子[R]:
(6)
将加密的全局盲化因子[R]返回至LDO解密,结合式(4),得到全局盲化因子R。
5.2 模型训练
为了抵抗模型窃取攻击,引入NTL算法迭代训练模型,设计一种交互式协同训练算法,保护全局模型的知识产权,具体描述如算法1所示。
算法1交互式协同训练算法。
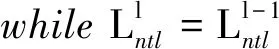
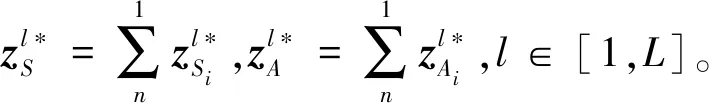
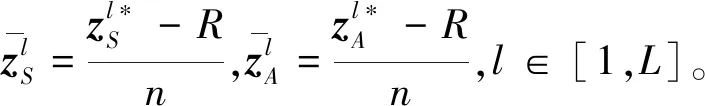
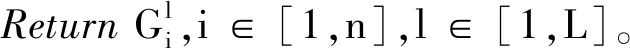
根据信息瓶颈理论中最优表征向量的充分性可知,需让表征z含有所有x中关于y的信息,即I(z;y)=I(x;y)。结合文献[17]中的命题3.1可知,存在一条马尔科夫链(y,Nui)→x→z,使得信息从(y,Nui)流向x,再流向z,进一步根据马尔科夫链的数据处理不等式[16]可知,I(z;x)≥I(z;y,Nui)。利用链式法则,变形后可以得到:
I(z;x)-I(z;y|Nui)≥I(z;Nui) ,
(7)
其中,阻碍Nui是影响输入x的一个因素,它与y协同决定于x。由信息瓶颈理论表征向量的不变性可知,I(z;n)=0,即z中不含有与y无关的信息。为了使模型在辅助域上的性能下降,NTL训练的目标与上述不变性的恰恰相反,希望通过增加输入x与阻碍Nui之间的互信息来使得未经授权的数据使用模型时获得的表示z是比较差的,不能输出正确的标签y甚至偏差很大。
LA=Ex~PX[DKL(P(Ω(Φ(x)))‖P(y))] ,
(8)
(9)
Ls=Ex~PX[DKL(P(Ω(Φ(x)))‖P(y))] 。
(10)
5.3 模型更新
在上述交互式训练过程中,CP迭代聚合不同LDO上传的盲化梯度,在不泄露梯度隐私的同时,更新全局模型。该过程的详细描述如算法2。
算法2SecBAvg算法。
输出:第L次迭代后的全局模型wL。
① whilewL=wL-1或达到指定迭代次数do。
⑥ ReturnwL。
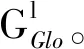
由3.2节中威胁模型的假设可知,文中方案中的训练过程均在半诚实模型下执行,对于半诚实参与者的安全性证明目前最常用的是模拟范例[17]。该方法的原理是将实际协议和理想安全多方计算协议的安全性进行比较,如果实际计算协议泄露的信息不比理想计算协议泄露的信息多,则证明实际的计算协议是安全的。
由于算法中各LDO的地位平等,因此各方的隐私要么都是安全的,要么都是不安全的,证明一方的数据是安全的即可。对特定一方隐私最严重的威胁是其他所有参与者合谋试图获取其隐私信息,这个攻击者集合被称为最大攻击者集合。特别地,如果一个人的隐私对最大的攻击者集是安全的,那么它对最大攻击者集的任何子集也是安全的。由于假设每轮的平均梯度是公开的,因此根据平均梯度结果推断出的信息均不认为是泄漏的。这里仅证明实际协议没有比理想协议泄漏更多的隐私信息。
由于训练过程计算的是中间参数的平均值,因此n-1方合谋一定能推断出另外一方的值,这和理想协议是完全相同的。实际协议没有比理想协议泄漏更多的信息。这里仅讨论最大合谋结构为n-2的情形。
不失一般性,最大合谋结构为I={O1,DO2,…,On-2},合谋者I想通过CP返回的全局梯度推断出其他LDO的信息。其中,CP与LDO不会合谋。由于每轮迭代执行的过程相同,仅证明在一次迭代过程中的信息是安全的即可。
定理1FedNTL在存在半诚实敌手时是安全的。
证明 在实际执行算法时,I作为一个整体在第l次迭代过程中收到CP返回的全局盲化梯度Gl*和加密的全局盲化因子R,因此有
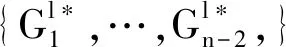
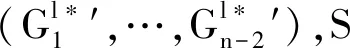
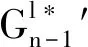
定理2FedNTL能够正确更新全局模型。
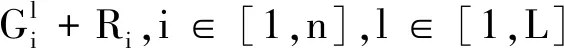
6 性能评估
6.1 实验设置
为了评价文中方案的有效性和安全性,选取了两个数据集进行实验。MNIST(Modified National Institute of Standards and Technology)数据集是美国国家标准与技术研究院发布的手写字体图像数据集,包含从0到9的10类黑白图像,它是目前公认的机器学习的基准数据集[18]。CIFAR-10(Canadian Institute For Advanced Research 10)是由HINTON的学生KRIZHEVSKY和SUTSKEVER整理的一个用于识别普适物体的小型数据集[19]。一共包含10个类别的RGB彩色图片,图片的尺寸为 32×32 ,数据集中共有 50 000 张训练图片和 10 000 张测试图片。
实验设备为个人台式PC,硬件配置为双路志强E5 2680 CPU,256 GB、1 333 MHz DDR3内存,英伟达GeForce GTX 3090 GPU和1TB固态硬盘,操作系统为Windows 10。编程语言为Python 3.7以及Pytorch编程库。
6.2 有效性分析
首先,验证方案在降低未授权辅助域模型性能的有效性。笔者在数据集MNIST和CIFAR-10上分别验证了监督学习(实验选用支持向量机算法)、NTL以及FedNTL在源域和辅助域上模型的性能,实验结果如图5所示。可以看到,监督学习算法在不同数据集的验证集性能较训练集均有小幅度下降,这是由于算法本身导致的在训练集和验证集上的性能差异,但该类算法并无任何模型知识产权保护措施,因此,在未授权数据域的性能仍然较高。对于NTL算法,笔者将训练集作为源域,验证集作为辅助域,较监督学习在未授权数据域的性能大幅度下降,但仍有至少34%的准确率。
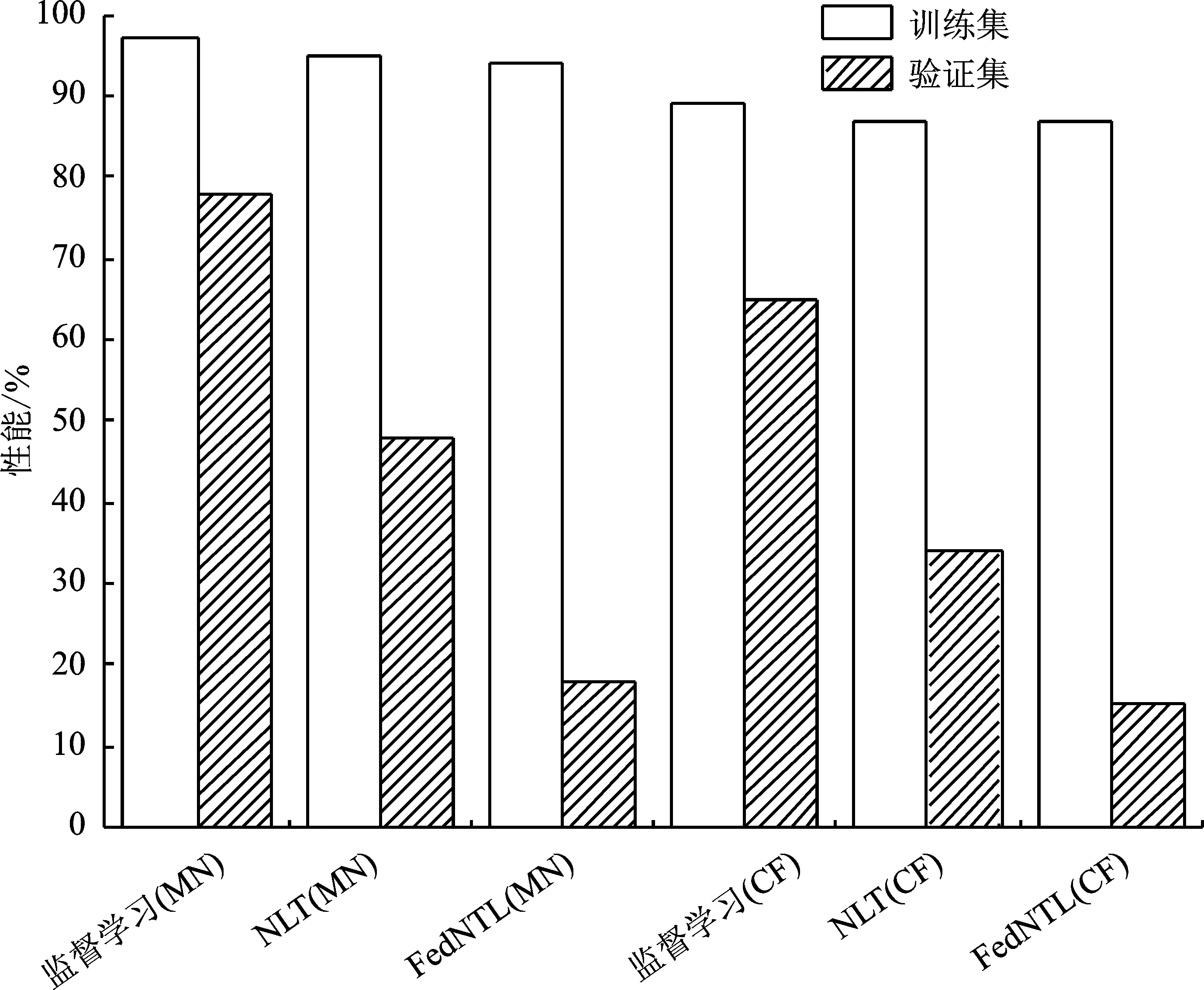
图5 不同算法在MNIST和CIFAR-10训练集和验证集上的性能对比
因此,笔者进一步将NTL后直接聚合梯度的全局模型在不同LDO进行测试,结果如表3所示。可以看到,在部分LDO验证集上的性能接近无知识产权保护措施方案的性能,这是由于直接聚合梯度使得部分本地NTL失效导致的。对于FedNTL,可以观察到所有辅助域性能都降低到20%以下,相较于NTL的模型在辅助域的性能下降了至少47%,并且源域的精度几乎没有降低。这表明,FedNTL可以在不牺牲源域性能的情况下有效降低模型在未授权数据域中的性能。

表3 全局模型在本地训练集和验证集性能分析 %
6.3 复杂度分析
文中方案假设本地梯度向量为γ维。方案执行的过程中,n个LDO分别加密了一个一维的本地盲化因子[Ri],i∈[1,n],即需要执行n次加密操作。不同LDO还需解密全局盲化因子[R],需要执行n次解密操作。因此,由Paillier加解密一次需要运行两次模指数运算可知,FedNTL需要进行4n次模指数运算,其计算复杂度为O(n),即FedNTL的计算复杂度仅与LDO的个数n有关,不依赖于本地梯度的维数γ。由于聚合过程全部在明文计算,与现有基于同态的隐私保护联邦学习方案对不同节点的γ维梯度分别加密不同[20-21],FedNTL仅对不同LDO的一维盲化因子加解密,大大降低了模型更新过程中的计算开销。
此外,所有的通信开销均在聚合过程中产生,n个LDO上传本地盲化梯度至CP,CP聚合后分别向n个LDO返回全局盲化梯度。因此,FedNTL的通信复杂度为O(nl),如表4所示。

表4 复杂度分析
7 结束语
笔者提出了一种联邦学习下的模型知识产权与隐私保护方案,设计了一种基于盲化因子的轻量级梯度聚合方法,大幅度降低加解密过程的计算开销。在此基础上,进一步提出了一种基于反迁移学习的交互式协同训练方法,实现在保护本地梯度隐私的同时,确保模型仅能被授权用户在已授权的领域使用。未来,笔者将考虑在LDO存在恶意行为的情况下,如何同时保护模型的知识产权和梯度隐私。
猜你喜欢
China Report Asean(2022年8期)2022-09-02
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
数学物理学报(2021年6期)2021-12-21
物联网技术(2020年12期)2021-01-27
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
金桥(2018年4期)2018-09-26
汽车零部件(2017年4期)2017-07-12
中国卫生(2014年5期)2014-11-10
