
基于云平台的消防员自主导航与搜救系统设计与实现
2023-08-31 03:05:28李婷婷徐勇军安郎平
指挥与控制学报 2023年3期
李婷婷 王 琪,2 徐勇军 安郎平 王 莽
火灾给人们的生命及财产带来了极大的威胁,火场救援面临的环境结构复杂、封闭性强、信号较弱且易受干扰,这严重影响了消防员火场救援效率,甚至给救援人员带来生命威胁.在复杂的室内环境下,如何精准定位、有效部署、科学救援、多方协同作战是消防救援领域研究的重点问题.
消防员的火场救援还存在以下难点:
1)消防员自主定位难.室内环境下由于卫星拒止、建筑物遮挡的影响,无法很好地接收到卫星信号,引起较大的定位误差,单一定位手段难以实现卫星拒止环境下的准确定位.
2)消防员环境感知难.由于火场烟雾弥漫,消防员配备的视觉传感设备工作性能大大下降,难以获取现场的清晰图像,致使难以探测到障碍物信息.另外,火灾容易致使建筑物的结构破坏,造成搜救环境的目标检测和地图重建难度增大,使得自主定位的精度受限,搜救环境的环境感知信息缺少,影响消防员搜救路径和逃生路径的选择.
3)消防班组指挥控制协同难.消防官兵在救援现场的位置信息不能实时共享,现场监控指挥人员缺乏对室内救援的消防员进行定位以及运动状态等信息的监测.指挥中心通过喊话的方式与救援人员沟通,效率低下,信息交互质量和协同作战效率都有待提高.另外当消防员出现安全问题时,指挥终端无法及时发现并对队员实施有效救援.
本文针对以上问题,重点研究消防火场环境下的自主导航与救援的问题,主要贡献有:
1)设计了一个面向火场环境的消防员火场自主导航与搜救系统.实现了消防员的精准定位、运动分析和状态监督,动态火场下的自适应导航和三维场景重构.
2)提出一种基于因子图的多源融合导航方法.融合多源信息实现了室内复杂环境下消防员的高精度自主导航,并通过信息源的即插即用实现自适应智能导航.
3)设计了一种面向火场环境的视觉定位与建图(simultaneous localization and mapping,SLAM)动态场景自适应方法.在传统SLAM 算法的基础上增加目标识别和语义分割模块,检测场景中有价值的目标,过滤掉火场中与移动对象相关的数据,并融合多源信息实现了对复杂火场环境的自适应导航算法.
1 相关工作
国内外对救援场景下搜救导航定位技术的研究很多,提高导航定位系统的精度是一个备受关注的研究课题.在国内研究中目前关于消防员室内导航定位算法主要以惯性导航、无线射频识别(radio frequency identification,RFID)、ZigBee、WIFI、超宽带(ultra wide band,UWB)等方面的研究为主.文献[1]提出了一种基于惯性导航技术的消防室内三维定位系统,利用惯性导航技术,利用位置估算、步伐估计以及零速修正等算法来提供救援人员的三维位置信息;文献[2]利用计算机视觉来辅助RFID 定位,通过目标检测行人的脚步坐标,融合RFID 的标签坐标,从而得到救援人员的位置坐标;文献[3]将BP 神经网络加入到ZigBee 的室内定位系统中,弥补了ZigBee 的缺陷与不足,改善了目标节点的定位精度;文献[4]提出了一种基于扩展卡尔曼滤波的WIFI-PDR 融合定位算法,通过降低WIFI 定位回跳和行人航位推算(pedestrian dead reckonin,PDR)累计误差,来提高定位精度;文献[5]提出了一种火场恶劣环境下救援人员的定位方法,该方法通过双极卡尔曼滤波框架惯性导航系统,并利用UWB 技术具有的低功耗、高速度、良好的抗多径效应、高安全性获得了较高的定位精度.但是它受室内障碍物的影响,很大程度上取决于基站的事前布置.目前国内的很多研究都无法满足实际需求,存在实时性差、依赖定位基站等问题,在复杂的室内环境下不能得到很好的适用,且现有产品的成本高,体积大,不便于救援人员携带和部署.相较于国内,国外很多关于室内搜救导航定位的相关研究更加成熟.文献[6]提出了一种利用UWB 和到达相位差估计实现无基础设施三维自定定位的新方法,以支持救援部队在低能见度危险行动中执行任务;文献[7]提出了一个基于AR 技术的六自由度(6 degree of freedom,6DoF)定位系统LocAR,LocAR 设计了一个协同粒子滤波器,联合估计所有AR 用户相对于彼此的6DoF 姿势,使用来自视觉惯性里程计(visual-inertial odometry,VIO)的运动信息和UWB 无线电用户之间的距离测量,建立一个精确的相对坐标系来解决消防员协调定位难的问题;文献[8]通过追踪难以进入的倒塌地点和未知障碍的位置,识别危险因素障碍物信息,生成最新的灾难现场数字地图,为消防人员快速搜救工作提供有效解决方案.
虽然消防员火场自主导航与搜救在国内外的消防领域均存在不同程度上的研究与应用,但单一方法存在一定的局限性,尤其是在室内、障碍物多的火灾场景导航精度会大大降低,导航质量变差.因此,本文在现有消防导航搜救研究成果的技术上,综合考虑了多源信息融合的导航定位、动态场景下视觉导航、三维场景重建、自主学习等方法,设计了一个消防员火场救援的体系化系统,并首次将毫米波雷达应用于火场环境的探测,实现了复杂火场环境的高精度自主导航定位.
2 系统设计
2.1 系统功能概述
系统基于因子图框架融合惯性、视觉、GPS、毫米波雷达、UWB 和激光等信息源,实现对复杂火场环境的搜救人员精准定位和烟雾夜晚等复杂环境下的场景感知构建三维场景与智能目标识别,在此基础上基于增强现实头盔智能显示指挥控制信息,并利用云平台实现信息的交互共享、健康监测、人人协同/人机协同,来提高消防班组的救援和指挥能力.
系统体系设计框架图如图1 所示:系统第1 层实现消防员对自身状态的感知;第2 层实现消防员对自身及环境的感知;第3 层实现人人协同、人机协同;第4 层与云平台交互,实现系统整体的指挥控制.消防员火场自主导航与搜救系统以火灾救援需求为牵引,针对火场救援的自主定位难、环境感知难和指挥控制协同难的问题,设计了以下5 个主要功能:

图1 系统体系设计框架图Fig.1 System of systems design framework
1)实现复杂火场环境的高精度自主导航定位.基于北斗系统和北斗锚点,结合惯性、UWB 和地图约束等多源信息,实现消防员的高精度自主导航定位,通过信息源的即插即用实现自适应智能导航.
2)实现复杂环境下的三维场景重建和视觉SLAM自适应.系统通过视觉SLAM、激光雷达和毫米波雷达等传感器感知三维场景,尤其是毫米波雷达的高穿透性有助于在火场的烟雾环境下对场景重建.系统采集环境中的图像信息,并进行智能目标监测,有助于消防员的定位搜救目标和选择求生通道,解决消防救援火场环境感知难题.
3)实现多成员多平台自组网深层协同.基于北斗锚点和UWB 基站,提高室内导航的精度并赋予全局坐标,实现天地协同、室内外协同和班组协同三位一体,提高消防救援分队协同定位能力,提高搜救效率.
4)实现救援平台一体化显示与控制.将系统的指挥控制信息集成于增强现实智能显示终端,结合增强现实方法,设计增强现实智能信息交互系统,有助于智能显示、信息交互和指挥控制协同[9].
5)消防员健康监测.基于云平台对消防员救援信息的大数据分析,并基于自主学习算法和惯性数据分析方法实现消防员健康监测,对消防员伤病情况作出及时的预警.此外,将模拟实战从各个角度记录下来,并上传动作数据到云端,对消防员后续训练提供数据参考.
2.2 系统硬件架构
消防员火场自主导航与搜救系统在硬件上以可穿戴传感器组件和增强现实智能终端为核心,辅以云平台进行数据分析与处理.系统的硬件结构如图2所示.
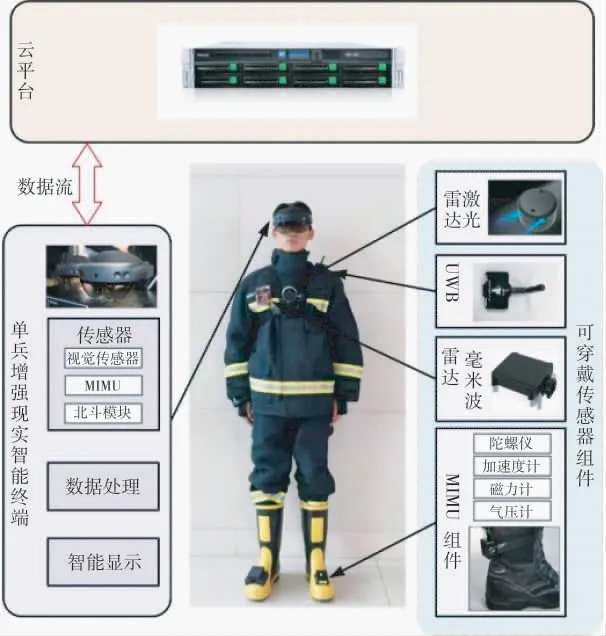
图2 系统在消防员身上的安装示意图Fig.2 Installation diagram of the system on firefighters
系统硬件组成如表1 所示.可穿戴传感器组件有微型惯性测量单元(miniature inertial measurement unit,MIMU)(包括陀螺仪、加速度计、磁力计气压计)、UWB、北斗模块、毫米波雷达、激光雷达和视觉传感器.定位信息、建图数据、目标检测信息和上级与队友的指挥控制信息,通过HoloLens2 解算并实现实时显示.云平台负责记录每名运动人员的状态数据和传感器数据进行大数据分析和处理.

表1 系统硬件组成Table 1 Composition of system hardware
MIMU:可结合零速修正提供相对位置和方向信息,实现姿态测量、加速度测量、高度测量、方向测量等功能,适用于消防员自主导航和定位系统的导航定位跟踪.
UWB:可以实现高精度的定位和距离测量,还可以提供距离观测量,降低MIMU 陀螺和加速度计漂移带来的误差发散,提高导航定位的精度,实现消防员间的协同定位.
北斗模块:可以提供绝对位置信息,但无法适用于室内等拒止环境中.结合卫星基站、北斗模块、MIMU 和UWB 等其他传感器,系统可实时获得消防员的绝对位置信息,实现室内火场环境消防员的精准定位.
毫米波雷达:可以穿透烟雾和浓雾等环境,可以检测到人、障碍物、墙壁和其他结构物,适用于火场内障碍物检测和导航.
激光雷达:可以用于生成火场内的三维稠密地图,适用于消防员自主导航和搜救系统的地图生成和路径规划.
视觉传感器:可以实现物体识别、跟踪、测距、测量和导航等功能.在消防员自主导航系统中,视觉传感器可以用于检测和识别火场内的人员和障碍物,为消防员提供更加直观的导航和搜救支持,同时可以辅助其他传感器进行定位和距离测量,提高系统的准确度和稳定性,适用于消防员自主导航和搜救系统中提供直观的导航和搜救支持.
融合上述多个传感器可以弥补单个传感器的不足之处,提高系统的鲁棒性和可靠性,为消防员提供更加精准的导航和搜救支持.在导航定位方面,卫星导航提供绝对位置信息,但无法适用于室内等拒止环境,MIMU 受环境影响较小但误差随时间累积,UWB 利用消防员与锚点之间以及消防员之间的距离测量提供相对位置信息,本系统采用在室外架设卫星基站,室内设置UWB 锚点,MIMU 实时惯性导航的方法,可以实现室内等环境的消防员准确定位,为指挥决策和搜救行动提供基础信息支撑.在感知和搜救支持方面,视觉传感器信息丰富但在低光环境下可能无法正常运行,激光雷达对物体反射率敏感但建图稠密,毫米波雷达可以穿透烟雾和浓雾等环境,因此,结合视觉、毫米波雷达和激光雷达,可以实现复杂火场环境的实时准确感知.
2.3 系统算法框架
系统的算法设计架构如图3 所示.导航定位算法模块在卡尔曼滤波框架下组合惯性和卫星信息,并结合人体运动约束实现准确的导航定位.解决了在室内卫星拒止环境下消防员定位难的问题.在第3章将详细介绍基于因子图的多源融合导航方法.
智能目标检测算法模块基于MASK R-CNN[10]检测场景中的目标,获得语义信息,并对图像进行实例分割.基于目标检测的视觉SLAM 动态场景自适应方法将在第4 章详细介绍.
三维场景重建算法模块结合深度学习,在SLAM点云地图的基础上融合场景语义信息,构建三维语义场景.将毫米波雷达应用于消防员火场救援,通过高穿透性的特征,实现在火场烟雾环境下的场景重建.
人员状态监测算法模块以惯性测量和深度学习为基础,将原始惯性数据进行预处理,解算出基础运动指标,如触地腾空比、左右平衡和配速等.该模块基于深度学习方法解算更加准确的基础指标,并分析更深层次的运动信息,如是否跨步、触地方式等.
智能自学习算法模块通过多时间尺度采集的用户运动大数据,分析人体运动规律和能量消耗等指标,挖掘更有价值的深层次信息,提供损伤预防建议和健康方案.本文基于Hadoop 构建用于大数据分析的云平台,通过足部惯性信息和北斗卫星数据,采用卫星/惯性组合导航算法、数据驱动的运动指标解算算法,对救援过程采集到的数据进行分析,实现对消防员救援的过程监控、运动分析、效果评估和救援指导,从而提高救援效率,预防训练伤病,增强消防员体能水平.
3 基于因子图的多源融合导航方法
本文设计的多源融合导航方法面向消防员设计,在惯性导航的基础上融合视觉、GPS、磁力计等辅助信息建立因子图,并对全局位姿进行优化.根据步态特征对救援人员的运动过程进行分割,确定变量节点,并以运动约束和场景约束为因子构建因子图,建立误差能量函数,再通过优化的方法求取误差能量函数的最小值,得到位姿最小二乘意义下的最优估计.
融合过程如图4 所示,足部MIMU 数据经捷联惯导解算后的位姿信息,与视觉/惯性SLAM 位姿估计结果相结合,实现对消防员的局部位姿的融合估计.在此基础上,全局优化模块融合了视觉回环信息和其他传感器,如Wi-Fi 指纹、GPS、UWB 测距信息和地图信息,评估导航系统的全局误差,并批量优化位姿图.
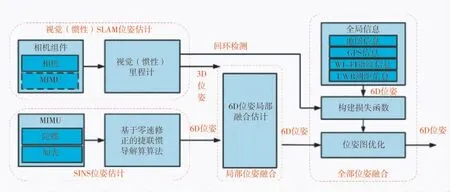
图4 多源融合导航框图Fig.4 Block diagram of multi-source fusion navigation
基于零速修正的捷联惯导解算算法利用消防员运动约束进行误差修正.运动约束主要指零速修正,若第k 时刻,足部处于静止状态,则足部此时的速度为零,利用足部MIMU 解算的速度vk作为系统速度误差的观测量,修正卡尔曼滤波的其他误差量,可以抑制误差发散.在零速阶段,系统的观测量Z 为
式中,δvk=vk-[0 0 0] 为第k 时刻的速度误差.那么,系统的观测矩阵H为:
由此在消防员捷联惯性导航系统(strapdown inertial navigation system,SINS)误差模型的基础上,建立起了15 状态的卡尔曼滤波器,并把脚步落地或静止时的零速作为系统观测量,对系统在零速阶段的误差进行修正,进而抑制导航误差的发散,提高消防员的导航定位精度.
全局位姿优化的因子图结构如图5 所示.因子图节点为救援人员六自由度的位姿(包含相对于初始点的位置和方向),各节点的采样频率由步态更新频率决定.相邻节点之间的位姿约束由MIMU 提供.视觉信息不仅可利用相邻节点之间的位姿变化约束节点状态,也可以通过图像特征匹配提供全局约束,抑制误差的漂移.磁强计提供航向信息,约束航向的发散.WIFI 指纹和GPS 因子提供全局位置的约束信息,地图因子以通过特征匹配对比地图中储存的特征点及其对应的相机帧的位姿,提供回环约束.

图5 全局位姿优化因子图结构Fig.5 Global attitude optimization factor graph structure
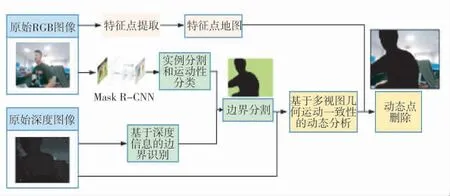
图6 基于语义信息和深度信息的视觉SLAM 场景自适应算法框架Fig.6 Visual SLAM scene adaptive algorithm framework based on semantic information and depth information
本文将系统在第ti时刻的位姿状态定义为:
若测量值是条件独立的,并且噪声服从零均值高斯分布,则MAP 估计值可以写成残差平方和:
在算法体系中,各因子及其信息矩阵的定义是由信息源的数量和质量而定.
4 视觉SLAM 动态场景自适应方法
典型的动态SLAM 基于先验信息不加判断地剔除具有动态性的物体,这将严重影响SLAM 算法的导航精度,而传统的SLAM 系统仍采用动态物体进行特征匹配和位姿估计,将导致更大的导航误差[11-12].为了解决这一问题,本文在结合深度信息和语义信息,基于ORB-SLAM2 设计了面向消防员的视觉SLAM 动态场景自适应算法.ORB-SLAM2[13]是目前比较完善、成熟的视觉SLAM 系统,主要包括追踪定位线程(tracking)、局部地图构建线程(local mapping)和回环检测线程(looping closing),同时还维护场景识别中的特征点BoW 字典和识别数据库,可以在闭环检测时计算关键帧相似度.场景自适应算法过滤掉与移动对象相关的数据,从而减少SLAM 前端中不正确的数据关联.算法主要包括面向消防员自主导航的目标识别和边界分割方法,以及基于区域分割和多视图几何的动态物体去除方法.
4.1 面向消防员导航的目标识别算法设计
面向消防员导航的目标识别融合了图像分割与目标识别两个任务,其目标是将图像分割为若干组具有某种特定语义含义的像素区域,并逐像素地判断每一像素所属的类别,最终生成标注有像素语义的图像,完成图像的像素级分类[14-16].本文在传统语义分割的基础上,根据物体的刚性结构进行动态区域分割,并结合深度信息确定区域边界.通过MASK R-CNN[10]实例分割网络对RGB 图像进行处理,实现像素级语义分割.在此基础上,结合MASK R-CNN的目标检测,对边界框内外延一定像素值之后进行边界分割,从而克服语义分割网络对边界的欠分割问题.由于目标识别可以完成对图像中物体的检测与位置识别,因此,可以用于检测火场场景中的潜在运动物体.具体算法流程为:
使用大小为2×2 的滑块遍历深度图像,并记录滑块中的深度值:
其中,(u,v)表示与滑块左上角的像素对应的图像坐标.可通过以下方式获得边缘点的集合Edge:
4.2 面向消防员导航的目标边界分割算法
实例分割网络可以基于先验信息实现对图像帧中动态对象的识别和像素级分割,而基于深度学习的目标边界分割算法基于目标是凸的假设,通过对比滑动块内对角像素的深度,实现对物体的边界检测.然后,基于Mask R-CNN 的实例分割网络在处理高动态性对象时常常无法对其边界进行准确检测,且实时性较差.而“图像中的目标是凸的”的假设在某些情况下并不一定适用.
由于基于先验信息与基于深度学习两种方法的优点和缺点是互补的,而它们的组合使用是实现精确且实时性更高的边界分割的有效方式.因此,本文设计了一种结合语义标签和深度信息的边界分割算法,算法框图如图7 所示.将图像输入Mask R-CNN网络进行实例分割,获得图像中的对象数目,以及每一类对象所对应的像素点和边界框.在每个物体的边界框的基础上,对图像所对应的深度图分别向两边扩展n 个像素点(在本文中,n 取3),然后对物体的边界进行分割,并于Mask R-CNN 输出的掩模向结合,生成准确的物体边界.

图7 结合语义标签和深度信息的边界分割算法图Fig.7 Boundary segmentation algorithm combining semantic labels and depth information
由图7 可知,仅使用Mask R-CNN 网络,则对物体边界无法实现准确分割,而在Mask R-CNN 的基础上结合深度信息,可以获得较为准确的动态物体掩模,从而实现对动态物体的准确去除.
4.3 抑制环境动态信息影响的视觉导航算法
环境中的运动物体对于图像的特征匹配会产生较大影响且使相机视场被大面积遮挡,进而影响SLAM 算法位姿估计的精度,因此,基于多视图几何对动态物体检测并基于语义分割和深度信息,对动态物体边界分割、去除.在去除运动目标后对背景进行修复,通过环境静态结构的合成框架可提升SLAM系统的位姿估计精度.
动态物体检测:基于多视图通过当前帧和其高重叠关键帧之间的几何约束关系,来去除图像中的动态特征点.具体来讲,对当前帧与具有较高相似度的关键帧之间的所有特征点进行匹配,并去除视差角大于30°的特征点.这是由于当视角大于30°时,图像中可能会出现对物体深度测量的遮挡,从而影响对特征点动态性的判断.利用重投影求得空间点的深度值Δz,并与深度图像对比,求得深度值
当深度差Δz 大于动态阈值时,则判定该点属于动态点集合Dynapoint.即
动态物体去除:当检测到场景中的目标为动态性时,结合4.2 节所述的物体边界分割和多视图几何方法,去除该物体上面的所有特征点,实现环境动态物体去除.
动态场景下图像背景修复:在去除运动目标后,根据先前的静态观察结果修复被遮挡的背景,可合成一个没有动态内容的真实图像,如图8 所示.这种包含环境静态结构的合成框架对于SLAM 系统后端的循环闭合和映射非常有用.

图8 动态场景下图像背景修复图Fig.8 Background restoration image in dynamic scene
5 实验及结果
5.1 基于多源融合的导航算法验证实验
如图9 所示,在某室内复杂环境下进行实验.行走路线为二楼折线,中间穿插办公室、会议室、装备室等复杂场景,设定3 个标记点作为误差计算依据,正常行走3 圈,实验的起点和终点为同一标记点.

图9 室内复杂场景局部位姿融合实验测试路线Fig.9 Experimental test route of local attitude fusion in indoor complex scene
实验时间约为1 200.98 s(20 min 0.98 s),运动距离约为923.22 m.图10(a)中,蓝色曲线为脚部解算轨迹,图10(b)中,红色曲线为融合轨迹.融合结果终点与起点的水平误差距离为0.64 m.

图10 室内复杂场景局部位姿融合实验结果Fig.10 Experimental results of local attitude fusion in complex indoor scenes
从实验结果可以看出,惯性导航系统的误差随时间发散,而结合惯性和视觉的局部位姿优化抑制了导航误差的发散,提高了导航系统的性能.
5.2 动态场景下视觉导航自适应算法验证实验
为验证算法对复杂室内动态场景的适应性,本文在某实验室内搭建实验平台,设计了室内动态场景实验.实验人员携带RealsenseD455 深度相机,从室内一个已知起点出发,沿着固定线路行走一个闭环,最终回到起点,实验时长13 min 43 s,约行走43.22 m.实验人员不仅途经动态物体占主要视场的场景,而且还遇到行走中的人.
将实验结果与ORB-SLAM2 进行对比.由图11可知,在实验前期的静止场景和低动态场景下,ORB-SLAM2 和本文提出的算法都能保持较高精度,且精度相近.但大约在第783 s 时,遇到动态物体占相机大部分视野的场景,这直接导致ORB-SLAM2算法无法进行正确的特征匹配,从而无法进行位姿估计;本文提出的算法去除了场景中的动态物体,可以克服动态场景的不利影响,在复杂场景下依然保持较高的定位精度,实现了对场景的自适应.
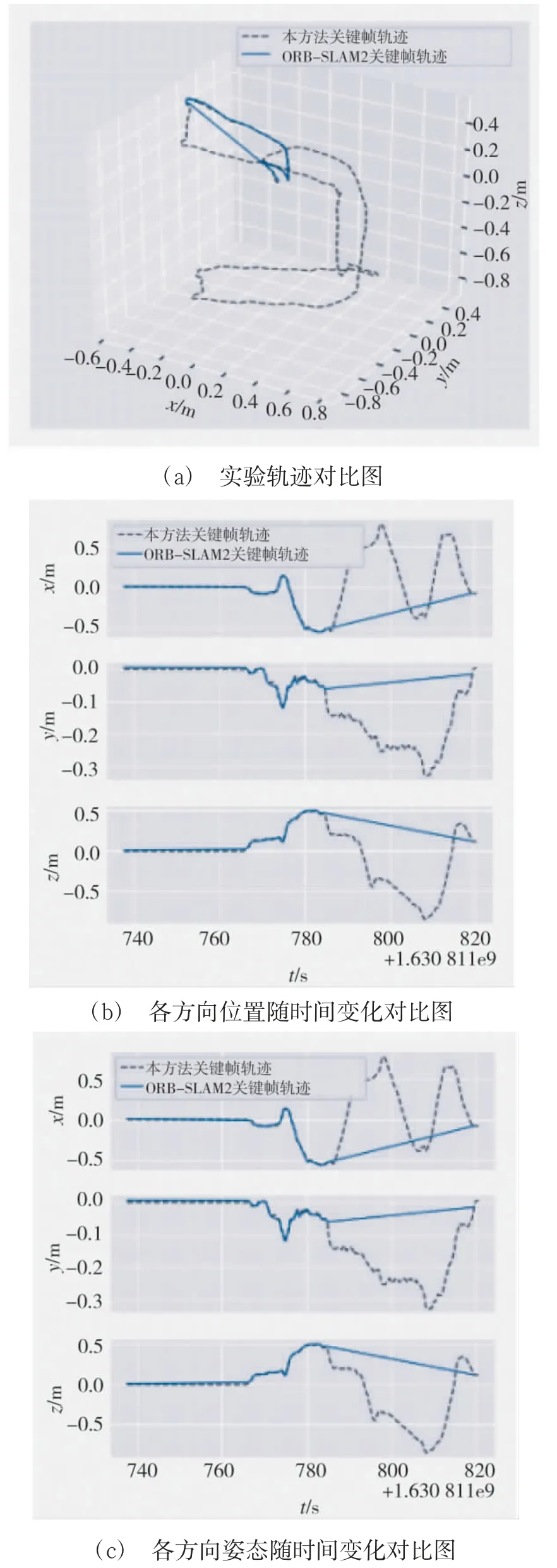
图11 动态场景实验本文算法估计轨迹与ORB-SLAM2轨迹对比图Fig.11 Dynamic scene experiment:comparison between the trajectory estimated by the proposed algorithm and the ORB-SLAM2 trajectory
5.3 场景重构算法验证实验
实验人员携带LivoxMid-40 小型固态激光雷达、毫米波雷达,以及足部安装的微惯性传感器在复杂室内场景下采集得到相关数据,利用三维场景重建相关算法构建3D 室内场景.
图12(a)为整体的建图效果,图12(b)为点云地图在实际地图上的位置.由图12(a)和图12(b)可知,室内建筑和道路部分建图效果较好,点云地图基本可以和实际地图相匹配.

图12 场景重构效果图Fig.12 Scene reconstruction rendering
5.4 云平台健康监测验证实验
消防员通过佩戴运动传感器组件获取其运动状态和运动数据并上传至云平台,通过云平台对数据的分析和处理,选取典型训练阶段的运动数据(2 387条)进行指标解算,结果如表2 所示.利用指标结算结果,从爆发力、耐力、运动效率、健康检测和伤病预警5 个方面进行评估.根据评估结果可指导训练和健康维护.
图13(a)所示为运动初期的加速度特征,三轴加表数据整合峰值约150 m/s,由此可见,受训人员爆发力较强.图13(b)所示为运动末期的加速度特征,加表数据整合峰值约60 m/s,对比运动初期和末期冲刺的加速度特征,可见其耐力较差.典型训练阶段触地腾空比为1.48,垂直幅度为8.1,故该受训人员运动效率一般,需要下一步改变运动姿势,提高运动效率.在跑步的全程,左右不平衡,左脚受力较大,说明其右腿部有劳损,需加强右腿肌群的训练.因此,在综合大量的运动数据后,可以根据运动特征曲线判断潜在的运动风险对其进行伤病预警.
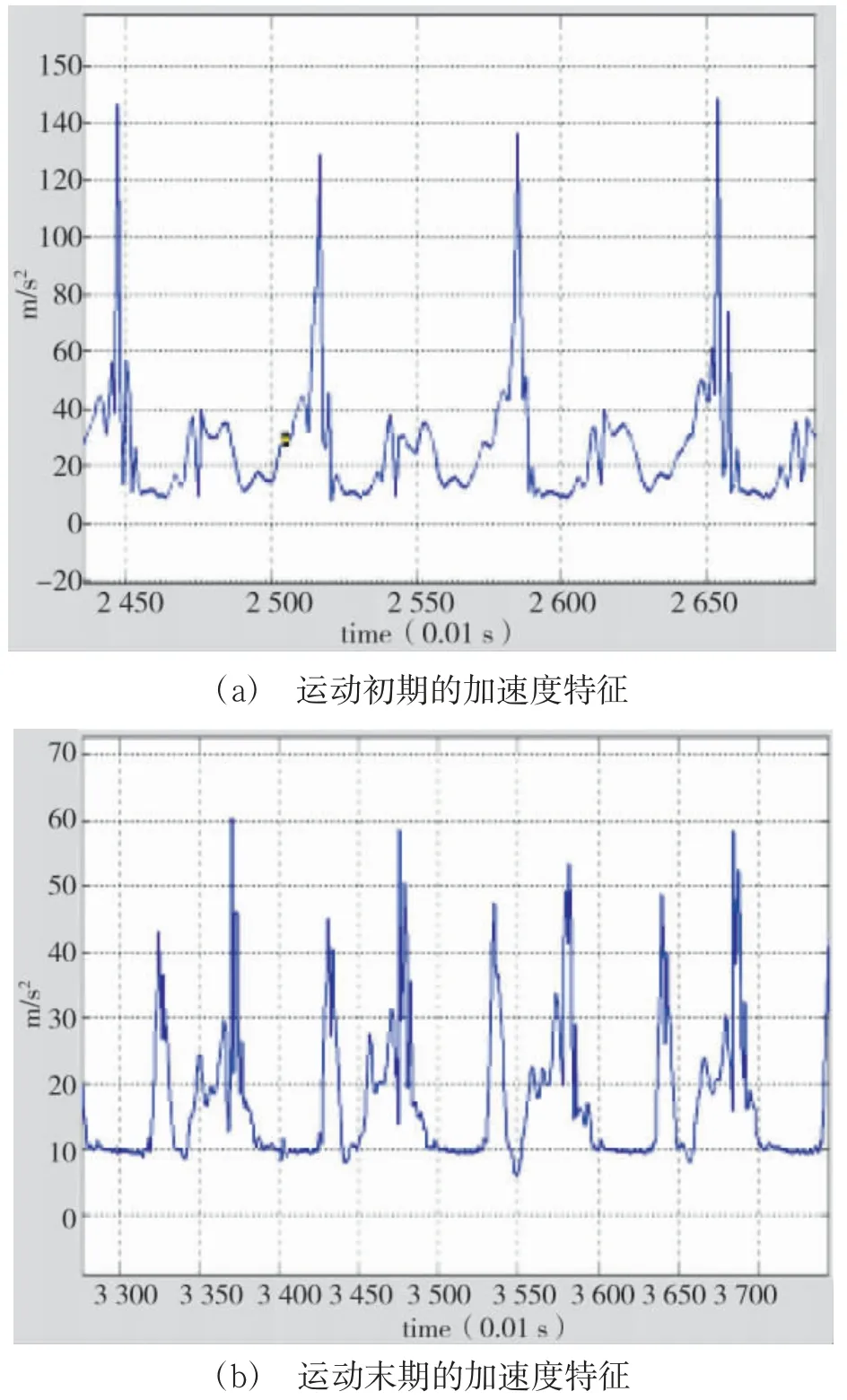
图13 典型路段的加速度峰值特征Fig.13 Acceleration peak characteristics of typical road sections
6 结论
本文着眼于解决消防火场环境下的自主导航与救援的问题,重点开展了基于多源信息融合的自主导航算法、复杂环境下视觉SLAM 自适应方法、三维场景重构方法等内容研究,设计了一个消防员火场自主导航与搜救系统.该系统基于北斗系统和北斗锚点,结合惯性、UWB 和地图约束等多源信息,实现对复杂火场环境下消防员的高精度自主导航定位;系统通过视觉SLAM、激光雷达和毫米波雷达等传感器感知三维场景,实现火场烟雾环境下的场景重建;提出了基于语义信息和深度信息的视觉SLAM 场景自适应方法,设计了边界分割方法和基于运动一致性的动态物体去除方法,提高了系统在复杂场景下的适应性;在此基础上利用云平台实现信息的交互共享、健康监测、人/人协同和人/机协同,来提高消防班组的救援和指挥能力.最后通过丰富的实验展示了本文算法的有效性.
猜你喜欢
电子制作(2018年18期)2018-11-14 01:48:00
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
小樱桃·童年阅读(2015年9期)2015-11-26 14:30:45
儿童故事画报·发现号趣味百科(2015年6期)2015-08-17 17:36:54
小樱桃·童年阅读(2015年6期)2015-06-26 14:18:51
小樱桃·童年阅读(2015年5期)2015-06-02 14:39:47
组合机床与自动化加工技术(2014年12期)2014-03-01 02:22:51
