
社会科学数据集的跨学科性研究
2023-08-31 02:26:34刘智锋王继民
现代情报 2023年9期
刘智锋 王继民

关键词: 社会科学; 数据集; 跨学科; CHARLS; CGSS
DOI:10.3969 / j.issn.1008-0821.2023.09.014
〔中图分类号〕G203 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 09-0165-13
随着开放获取运动的不断兴起, 开放科学得到了科研社区的广泛关注[1] 。开放科学数据作为开放科学的重要组成部分, 是促进科学数据高效利用的重要途径。早在2018 年, 国务院办公厅发布了《科学数据管理办法》[2] , 提出促进科学数据的开放共享, 以支撑科技创新与社会经济发展。学界围绕开放科学数据开放共享开展研究, 重点关注科学数据共享平台[3] 、开放政策[4] 、影响因素[5] 等方面。
科学数据集开放只是共享的第一步, 数据集开放之后如何被学者利用, 则是科学数据发挥价值的关键所在, 同时也是理解科学数据开放共享如何促进科学进步的途径。关于数据集的利用, 当前图情领域学者多数从数据集利用主体出发, 重点关注数据复用行为特征[6] 及其影响因素[7] ; 也有学者研究了科学数据集的知识扩散[8] ; 却鲜有研究关注数据集如何被不同学科领域的学者利用。数据集作为实证研究的基础, 同一数据集不仅被本学科领域的学者利用, 也可被不同学科的学者复用[9] 。分析数据集被哪些学科使用, 跨学科性如何、是否存在跨学科合作社区, 相关研究的主题以及跨学科研究如何演化等问题, 有助于理解数据集在不同学科的扩散规律以及数据集如何在不同学科发挥作用的机制。
随着数据驱动的研究范式在社会科学领域不断盛行, 数据集已成为社会科学领域量化分析的重要基础[10] , 社会科学数据集的数量快速增长, 数据集的影响力不断增强。社会科学数据是指人类各类社会系统运行过程中所产生的各类数据[11] , 与自然科学数据存在显著差异。在自然科学研究中, 实验等方法获取的数据标准性较好, 如在计算机科学和生物医学等领域, 基于同一实验数据集, 研究者可以从不同角度或采用不同方法进行研究, 从而具有较高的重复利用率; 相比之下, 社会科学数据主要通过调查等收集, 数据较为主观, 质量参差不齐,且大部分社科数据集是研究者根据自身研究需求进行获取, 尽管存在一些高質量数据集, 但满足统一标准的数据集相对较少, 数据集的共享和重复利用率较低。为了促进社会科学数据集的共享与使用,社会科学领域学者不断推进高质量的数据集建设,如北京大学牵头开展了中国健康与养老追踪调查,收集一套中国中老年人及其家庭的高质量微观数据等, 高质量的社科数据不断增加。
以往研究更多聚焦于科学数据集的共享与重复利用研究[12] , 对社会科学数据集的跨学科扩散研究较少。因此, 本文拟以被广泛使用的中国健康与养老追踪调查(CHARLS)和中国综合社会调查(CGSS)两个社会科学数据集为研究对象, 从数据集的跨学科性测度分析、数据集跨学科合作社区结构与主题识别以及数据集跨学科合作演化研究3 个方面, 对社会科学数据集的跨学科性进行研究, 以期为促进社会科学数据集在不同学科之间的开放共享、高效利用以及数据集的影响力评价等方面提供理论支持。
1相关研究
1.1科学数据集使用特征研究
科学数据集是描述科学研究对象、状态、条件等因素的数字、文字和符号[13] , 可以分为调查数据、实验数据、统计数据、记录数据等不同类型,对实证研究具有重要研究意义[14] 。以科学数据集作为研究对象, 学界从不同视角对科学数据集的特征开展了一系列相关研究。从数据生命周期的视角出发, 孟祥保等[15] 分析了教育学、历史学等6 个学科的数据创建主体、数据组织、数据存储、数据出版以及数据引用5 个方面的特征。屈亚杰等[16] 从被引社会科学数据的被引次数、访问形式、规模、时间跨度等不同方面揭示了社会科学数据的引用特点。沈婷婷[17] 以《中国社会科学》为例, 研究了人文社会学科学者的数据来源、所用的数据类型、方法与工具等。杨宁等[18] 分别从计量分析与内容分析两个视角出发, 分析了生物医学领域数据集的使用强度、使用章节、使用位置等使用特征。戚景琳等[19] 、张莹等[20] 探索了经济学和管理学领域的科研人员数据使用行为特征。Park H[9] 通过科学数据集在不同学科之间的引用情况, 研究科学、技术、工程等理工科的科学数据集跨学科性。综上可知, 学者们主要从使用和引用两个视角出发, 分析了科学数据集的特征和科研人员的数据集复用行为。然而, 社会科学数据集的跨学科特性并未得到深入研究。
1.2跨学科性相关研究
跨学科研究, 也被称为交叉学科研究, 已被认为是人类解决重大科研难题的重要研究范式[21] 。而跨学科性是跨学科研究的特征, 如研究的跨学科分布及跨学科的广度、深度等[22] 。关于跨学科性的研究, 学者主要从跨学科理论研究、跨学科性测度、跨学科性的演化等方面展开。在跨学科性的理论研究方面, 步一等[23] 从知识重组的视角来解构跨学科性。关于跨学科性的测度, Stirling A[24] 提出可以从学科丰富性、学科均衡性以及学科差异性3 个维度对跨学科性进行测度, 学科丰富性表示学科的种类多少, 学科均衡性代表的是不同学科的数目是否均衡, 而学科的差异性反映不同学科之间的差异程度; 后续学者采用各种类型的指标来衡量这3 个维度, 如不同学科数[25] 、信息熵[26] 、基尼系数[27] 等。在此基础上, 学者们通过跨学科性测度指标随时间的变化来研究跨学科性的演化, 如Zhao Y 等[28] 分析了COVID-19 相关研究是否具有越来越高的跨学科性; 吴小兰等[29] 从学科丰富度、均衡度和差异度3 个方面研究了国家自然科学基金项目发文的跨学科演变。
此外, 部分学者从学科共现网络与跨学科引用的视角来研究特定学科领域的跨学科性。学科共现网络通过不同学科在同一篇论文共现关系来构建,特定领域论文的学科共现网络可以反映该领域的跨学科合作结构, 从而揭示该领域的跨学科特征。如Xu X 等[30] 构建了7 544篇论文的学科共现网络,并对网络进行分析以揭示精准医学领域的跨学科性。Hu J 等[31] 采用大数据领域的论文学科共现网络来分析该领域的跨学科性。跨学科引用视角, 通过分析不同学科之间的引用情况, 以揭示不同学科之间的跨学科性以及不同学科之间的知识流动, 如徐璐等[32] 分析了图书情报领域期刊的跨学科引用,来研究期刊在跨学科交流中所起的作用。施顺顺[33] 采用Rao-Stirling 多样性指标评估了公共管理学的跨学科性。
综上可知, 当前学者关于跨学科性开展了大量的研究, 然而这些研究主要研究特定主题或学科领域的跨学科性, 鲜有研究分析基于特定数据集的相关研究的跨学科性, 因此, 本文拟借鉴以往的相关研究, 从学科多样性和学科均衡性对数据集的跨学科性进行测度, 并从学科共现网络的视角出发研究基于特定数据集的相关研究的跨学科合作网络结构及其演化规律。
1.3知识实体扩散相关研究
科学知识扩散是指知识在不同学者与学科领域之间的流动, 科学知识的扩散可以促进知识的生产与传播, 从而推动科学发展。学术论文作为科学知识的重要载体, 是科学知识扩散研究的重要对象。以往研究通常从引文分析的视角来探讨论文的扩散模式与规律。如闵超等[34] 将引文视作知识扩散的过程, 并从多个维度分析了引文扩散的要素与过程。也有研究针对经典论文(如诺贝尔奖获奖论文)[35]和著作(如《结构洞: 竞争的社会结构》)[36] 等, 揭示其引文扩散模式。同时, 部分学者关注引文扩散的影响因素[37-38] , 揭示知识扩散的内在机制。此外, 有研究从全文引文的视角出发, 研究跨学科知识扩散的特征[39] 。可见, 基于学术论文的引文分析, 可以深入了解知识扩散的模式和规律。
近年来, 随着学术论文的全文开放获取的增加以及自然语言处理技术的快速发展, 学者们开始深入研究全文内容, 采用深度学习等方法抽取论文中的知识实体, 如问题、算法、理论、数据集和软件等[40] , 使细粒度知识实体的扩散研究得以实现。如有研究者分析了论文中LDA 算法的扩散渠道及其模式[41] 。也有学者研究了CiteSpace 等科学计量相关软件在不同学科的使用情况[42-43] 。此外, 部分学者探究了数据集实体的扩散和使用情况, 如杨宁等[8] 抽取了PubMed Central 全文中使用的基因表达相关数据集, 并从科学数据集扩散广度和强度等方面揭示了扩散特征。Hou J 等[44] 研究了数据集在Twitter 上的传播方式, 以及学者和大众在传播过程中扮演的角色。此外, Jiao C 等[45] 探究了PLOS ONE论文中用于分享研究数据的机制和存储库。综上所述, 已有部分學者研究了各种类型知识实体, 如科学数据集、算法等的扩散特征与规律。然而, 当前关于高质量社会科学数据集在不同学科的扩散规律尚未得到深入研究。因此, 本研究将从社会科学数据集的跨学科视角出发, 探究其在不同学科的扩散。
2数据与方法
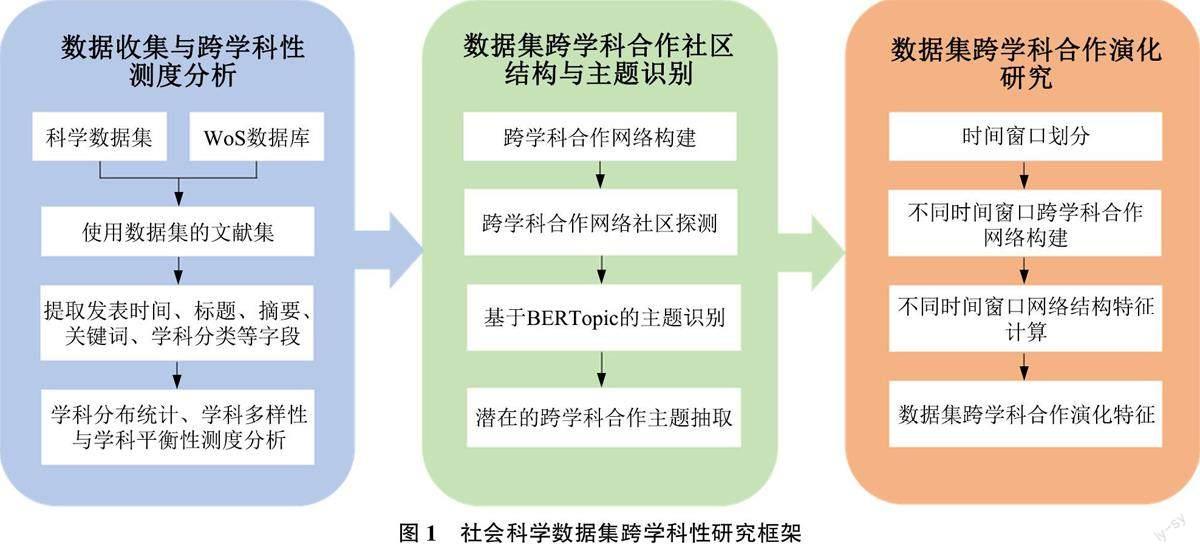
本文提出的社会科学数据集跨学科性研究框架如图1 所示。该研究框架一共包含3 个模块, 分别是数据收集与跨学科性测度分析、数据集跨学科合作社区结构与主题识别以及数据集跨学科合作演化研究。首先, 采集使用特定数据集的文献集, 提取发表时间、标题、摘要、学科分类等字段, 采用信息熵、不同学科数等指标对跨学科性进行测度; 其次, 构建跨学科合作网络, 并采用Louvain 算法对网络进行聚类, 识别数据集跨学科合作社区, 采用BERTopic 主题模型, 提取不同学科潜在的合作研究主题; 最后, 划分不同的时间窗口, 构建不同时间窗口的数据集跨学科合作网络, 观测网络结构特征指标变化, 分析网络演化特征。
2.1数据来源
本文以中国健康与养老追踪调查(CHARLS)和中国综合社会调查(CGSS)两个数据集为例, 中国健康与养老追踪调查数据集是由北京大学牵头采集的关于中国45 岁及以上中老年个人及家庭的微观数据, 广泛应用于人口老龄化等跨学科研究; 中国综合社会调查是我国最早的全国性、综合性学术调查项目, 全面采集了个人、家庭、社区和社会各个层面的数据, 是研究中国社会的最重要数据来源之一。因此, CHARLS 和CGSS 数据集均具有较好的代表性。CHARLS 数据和CGSS 数据在社会科学领域得到了广泛地使用, 产生了许多在国际期刊发表的高质量成果; 本研究拟以使用CHARLS 数据和CGSS 数据的英文论文为研究对象, 分析社会科学数据集的跨学科性。
为了获取使用CHARLS 数据和CGSS 数据的英文论文, 本文分别采用数据集的英文全称与简写等构造检索式TS=(“China Health and Retirement Lon?gitudinal Study” OR “ China Health and RetirementLongitudinal Studies” OR “Chinese Health and Retire?ment Longitudinal Study” OR “ Chinese Health andRetirement Longitudinal Studies” OR CHARLS)和TS=(“Chinese General Social Survey” OR “China GeneralSocial Survey” OR “Chinese Social Survey” OR “ChinaSocial Survey” OR (CGSS AND Survey)), 在Web ofScience 核心合集中进行检索, 时间限制为2013—2021 年, 文献类型限制为Article, 检索时间为2022年7 月16 日, 剔除少数非目标文献, 最终得到使用CHARLS 数据集的论文数为790 篇, 使用CGSS 数据集的论文数为328 篇, 论文的时间分布如图2(a)所示, 可知使用CHARLS 数据集和CGSS 数据集的英文论文在2013—2016 年较为稳定, 而在2016—2021年呈现较快的增长趋势, 表明以中国数据集为基础的研究在国际期刊上得到了广泛的认可。
2.2研究方法
2.2.1跨学科性测度
本文的学科分类采用Web of Science 学科分类体系, 该分类体系一共包含252 个不同的学科[46] ,一篇论文可属于1 个或多个不同的学科。借鉴以往的相关研究, 本文从多样性和平衡性两个方面对社会科学数据集的跨学科性进行测度。多样性指的是使用数据集的学科的数量, 本文采用不同的学科数表示使用CHARLS 和CGSS 数据集的学科多样性;平衡性指的是使用数据集的学科数量的均衡程度,本文采用信息熵来计算使用CHARLS 和CGSS 数据集的学科平衡性。
2.2.2社会网络分析
社会网络分析已被广泛应用于揭示特定学科领域的知识结构[47] 。本文借鉴以往的研究, 采用社会网络分析揭示CHARLS 和CGSS 数据集的跨学科合作网络结构及其演化特征。首先, 基于论文所属的学科共现关系, 构建学科共现网络, 其中, 学科共现网络的节点代表特定学科, 边代表两个学科在一篇论文中同时出现, 边的粗细代表两个学科的共现强度。网络的节点数可以反映使用特定数据集的不同学科数; 网络的边数代表不同学科对数; 网络的密度为当前边数与理论最大边数的比值, 反映网络的稀疏程度。Louvain 社区发现算法是社会网络常用的聚类方法[48] , 本文采用Louvain 算法[49] 对CHARLS 和CGSS 数据集的跨学科合作网络进行社区探测, 以发现CHARLS 和CGSS 数据集的跨学科合作社群。
2.2.3 BERTopic
BERTopic 是由Grootendorst M[50] 于2022 年提出的一种基于Transformer 语言模型的主题建模方法, 该方法基于预训练语言模型进行动态的嵌入表示, 可以更好地对文档进行语义表示, 还可以自动生成特定的主题, 避免了主题数的设定, 相对以往的LDA 主题建模和Top2vec 方法均具有更好的效果。因此, 本文拟采用BERTopic 对使用CHARLS 和CGSS 数据集的论文进行主题识别, 以揭示潜在的跨学科合作主题。
BERTopic 算法包含4 个主要模块, 首先采用预训练语言模型对每个文档进行嵌入表示, 然后对获取的文档向量表示进行降维处理, 接着采用聚类算法对文档进行聚类, 最后对同类的文档进行合并, 并采用基于类别的c-TF-IDF 算法提取同类别中的重要关键词以表征该类别的主题。其中, 各个模块是相对独立的, 不同的模块可以选取不同的算法进行组合, 本文使用官方推荐的组合方案, 选取Sentence-transformer 的All-MiniLM-L6-v2 版本作为文档的词嵌入模型, 首先采用UMAP 对高维向量进行降维, 然后采取HDBSCAN 聚类算法[51] 对文档进行聚类, 最后采取c-TF-IDF 算法进行主题提取。
3结果与分析
3.1 CHARLS 和CGSS数据集的学科分布
CHARLS 数据和CGSS 数据作为跨学科的数据集, 分别被74 个和58 个不同的学科所使用, 论文篇均学科数分别为1.54 和1. 53 个。学科频次和不同学科数随时间的变化如图2(b)和图2(c)所示,可知使用CHARLS 和CGSS 数据集的学科不断增加。进一步, 采用信息熵度量学科的均衡性, 由图2(d)可知, 随着时间的推移, 信息熵不断增大, 使用CHARLS 和CGSS 数据集的学科分布越来越均衡。
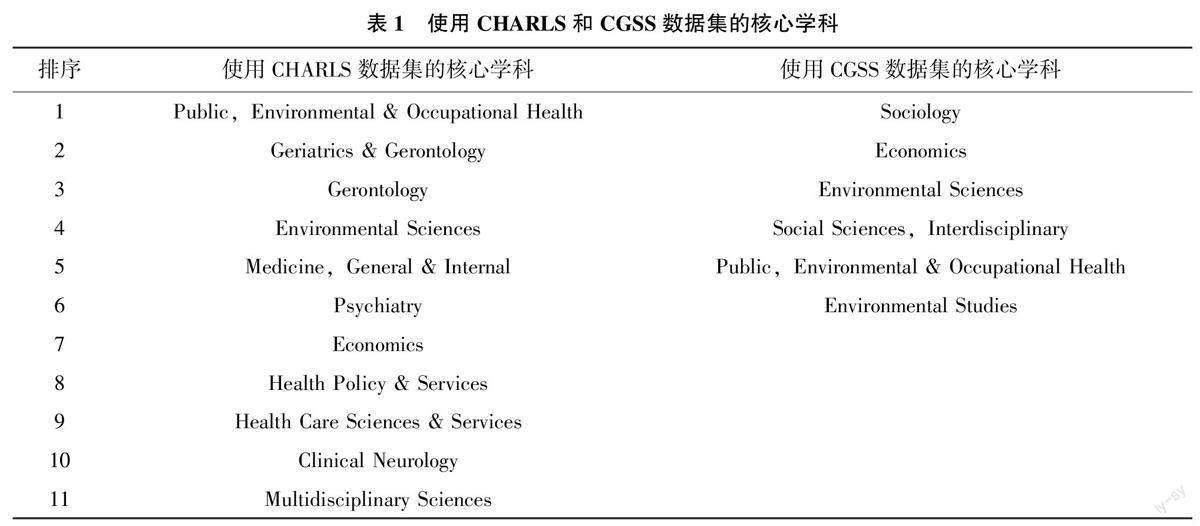
根据各个学科使用数据集的频次, 可将使用CHARLS 和CGSS 数据集的学科分为核心、主要和边缘3 类。核心学科为使用数据集的论文数30 篇以上, 主要学科为使用数据集的论文数10 篇以上,边缘学科为使用数据集的论文数小于10 篇。基于此, 可得使用CHARLS 数据集的核心学科有11 个,主要学科有14 个, 边缘学科有49 个; 使用CGSS 数据集的核心学科有6 个, 主要学科有8 个, 边缘学科有44 个。CHARLS 数据集涉及的3 类学科数多于CGSS 数据集涉及的学科数。具体而言, 使用CHARLS 数据集和CGSS 数据集的核心学科如表1所示, CHARLS 数据的核心学科主要与公共卫生、老年学、环境科学、经济学、健康政策与服务等相关。而CGSS 数据的核心学科主要与社会学、经济学、公共卫生以及环境研究相关。
3.2 CHARLS 和CGSS 数据集的跨学科合作社区探测
跨学科合作网络可以刻画出使用数据集的相关学科以及学科之间的合作关系。图3(a)和图3(b)分别是CHARLS 和CGSS 数据集的跨学科合作网络, 节点代表学科, 边代表学科的共现关系, 边的粗细代表学科共现的频次。具体而言, CHARLS 数据集跨学科合作网络包含64 个节点, 107 条不同的边, 平均度为3.344, 网络密度为0. 053; CGSS数据集学科合作网络的节点包含54 个节点, 形成76 条不同的边, 平均度为2.815, 网络密度为0.053。CHARLS 和CGSS 数据集跨学科合作网络度排名前十的学科如表2 所示, 通过学科的度的大小可以揭示学科的重要程度。
在此基础上, 本研究采用Louvain 算法分别对CHARLS 和CGSS 数据集的跨学科合作网络进行聚类分析, 如图3 所示, 节点大小表示节点的度, 相同颜色的节点属于同一个社区; 可以发现, 使用CHARLS 数据集存在7 个跨学科协作社区, 形成了以老年医学、环境卫生与职业健康以及健康经济与卫生服务为主的三大研究社区; 使用CGSS 数据集的研究社区较为分散, 存在10 个不同的跨学科协作社区, 形成了以经济学、社会学以及环境科学为主的三大研究社区。
3.3 CHARLS 和CGSS 数据集的跨学科合作主题识别
识别基于CHARLS 和CGSS 数据集的研究主题, 可以发现不同学科潜在的合作方向。本文采用BERTopic 模型分别对使用CHARLS 和CGSS 数据集的论文主题进行识别, 共识别出使用CHARLS数据集的论文研究主题19 个, 图4 表示了其中的8 个主题排名前5 的特征词, 结合相关文献可知,CHARLS 数据集是关于中国老年的微观调查数据,使用CHARLS 数据集的研究主要围绕老年人的抑郁状况、医疗保险、睡眠状况、高血压状况、家庭经济支出、空气污染、吸烟行为、能源消费等影响因素及其之间的相互作用机制等展开, 受到社会学、经济学、环境科学、公共卫生等学科领域学者的关注, 也是后續可以进一步合作的学科交叉点。
基于同样的方法, 共识别出使用CGSS 数据集的论文研究主题10 个, 图5 展示了其中8 个主题排名前5 的特征词, 结合使用CGSS 数据集的相关论文, 可得研究主题主要包含环境行为与能源消费、员工工作满意度、居民幸福感、婚姻与家庭、互联网使用、政治民主与信任、教育支出与回报、区域差异等, 主要涉及的学科有社会学、经济学、政治学、教育学、环境科学等, 不同学科领域的学者可以基于CGSS 数据集, 同时引入外部数据集等, 开展更多的跨学科合作研究。
对基于CHARLS和CGSS数据集研究的主题进行可视化, 图6为研究主题的可视化图谱, 每个圆圈代表一个研究主题, 圆圈的大小代表该主题相关文档的出现频率, 越大代表出现的频率越高, 不同圆圈的距离代表主题之间的相似度, 通过对不同主题及其之间的关系进行可视化, 可以揭示主题的结构特征。由图6可知, 使用CHARLS 数据集的研究主题可以分为6 个不同的簇, 不同学科合作或关注的主题较为集中; 而基于CGSS 数据集的相关研究主题的结构较为分散; 造成两者差异的可能原因是, CHARLS 数据集的主要调查对象为中老年, 数据收集的范围以及所包含的信息量较为有限, 而CGSS 是一个综合性的数据集, 数据包含的范围较为广泛, 可以开展关于中國社会不同方面与层面的研究。
3.4 CHARLS 和CGSS数据集的跨学科研究演化分析
使用CHARLS 和CGSS 数据集的论文数在2013—2015 年较为稳定, 在2016—2018 年实现了一定程度的增长, 2019—2021 年呈现快速增长的趋势, 基于此将时间窗口划分为3 段。本文首先统计了2013—2015 年、2016—2018 年以及2019—2021年3 个时间段使用CHARLS 和CGSS 数据集的相关学科频次的变化以反映学科的演化情况。其中, 3个阶段使用CHARLS 数据集学科频次前5 的学科如表3所示。第二阶段即2016—2018 年使用CHARLS 数据集的学科除了社会与医学相关的学科, 经济学和环境科学等学科使用该数据集的频次不断增加, 并进入前5; 到第三个时间段, 环境科学使用该数据集的频次进一步提升, 其他学科相对稳定。
3 个阶段使用CGSS 数据集学科频次前5 的学科如表4 所示, 在第一阶段使用CGSS 数据集的学科主要有社会学、政治学、教育学以及经济学; 第二阶段经济学使用CGSS 数据集的频次快速提升,位居第一, 公共卫生与环境相关学科亦较多使用该数据集; 第三阶段则以环境科学相关学者使用该数据集居多。
分别构建CHARLS 和CGSS 数据集在3 个时间窗口的跨学科合作网络, 以揭示跨学科合作网络的演化特征。CHARLS 和CGSS 数据集3 个不同阶段的跨学科合作网络节点数、边数、密度以及社区数等指标的变化如图7 所示。由图7 可知, 3 个阶段的跨学科合作网络的节点数和边数都在不断增长,反映了使用CHARLS 和CGSS 数据集的相关学科以及不同学科之间的合作不断加强; 由于网络节点数增长较快, 导致跨学科合作网络的密度有所下降,表明不同学科之间的合作存在较大的空间; 此外,相关的研究社区数也呈现增长的趋势, 表明CHARLS 和CGSS 数据集的研究社区不断兴起。
CHARLS 和CGSS 数据集3 个阶段的跨学科合作网络结构如图8 和图9 所示, 采用Louvain 算法分别对不同阶段的网络进行聚类分析。对比图8(a) ~(c)可知, CHARLS 数据集的跨学科合作网络不断扩张, 2013—2015 年以老年学相关学科为研究主导; 2016—2018 年, 形成了经济学、老年学以及公共卫生与职业健康三足鼎立的学科格局;2019—2021 年, 延续了上一阶段的学科格局, 且3个不同学科主导的网络不断充实, 越来越多学科参与合作。对比图9(a) ~ (c), 可知, CGSS 数据集的跨学科合作网络不断扩张, 在第一阶段以社会学和政治学相关学科为主; 第二阶段, 则以社会学、经济学和环境科学相关学科为主; 第三阶段, 仍以社会学、经济学和环境科学等学科为主, 且计算机科学、健康政策与服务等一批新的学科不断加入。
4结论与讨论
随着数据驱动的研究范式在社会科学中不断盛行, 数据集已成为社会科学研究的重要战略资源。社会科学数据集为社会科学领域各个学科的实证研究提供了重要基础。同一社会科学数据集可被不同学科用于相关领域的研究问题, 不同的学科也可基于特定的数据集进行合作研究, 社会科学数据集已成为学科交叉的重要载体和机制之一。通过分析社会科学数据集的跨学科性, 可以促进数据集在不同学科间的开放共享, 并推动基于数据集的跨学科研究。
本文提出了一个针对社会科学数据集的跨学科性研究框架, 并以社会科学领域具有代表性的CHARLS 和CGSS 数据集为例。首先, 采用信息熵和不同学科数等指标对数据集的跨学科多样性和平衡性进行测度, 以揭示使用CHARLS 和CGSS 数据集的学科分布及其变化趋势。其次, 构建了数据集的跨学科合作网络, 并采用Louvain 算法和BER?Topic 模型对网络结构和主题进行了分析, 发现不同学科之间的合作社区和潜在的研究主题。最后,通过划分不同时间窗口, 可以观察数据集跨学科合作网络的演化特征, 从而揭示不同阶段的主导学科和合作模式。
在数据集跨学科性特征方面,研究发现CHARLS和CGSS 分别在74 个和58 个不同学科得到了广泛的应用, 其学科多样性和平衡性在不断增长。除社会学外, 还在公共卫生、环境科学、经济学等不同学科被使用, 表明这两个数据集在各学科之间具有较强的扩散能力和影响力。因此, 学者在选择数据集时, 不应局限于本学科领域, 可以根据研究问题的需求, 从其他学科获取相应的数据集。关于数据集跨学科合作社区的分布,结果表明使用CHARLS和CGSS 数据集均呈现以少数跨学科合作社区为主导的格局, 使用CHARLS 数据集的学科形成了以老年医学、环境卫生与职业健康以及健康经济与卫生服务为主的三大研究社区; 使用CGSS 数据集的研究社区较为分散, 形成了以经济学、社会学以及环境科学为主的三大研究社区。可见, 除了以研究问题为中心构建跨学科合作社区, 还可以研究数据集为纽带, 促进多个学科之间的合作。
在数据集跨学科合作主题方面, 使用CHARLS的研究主题达到19 个, 围绕老年人的抑郁状况、医疗保险、睡眠状况、高血压状况、家庭经济支出等多个主题展开。采用CGSS 数据集进行的研究主题有10 个, 包含环境行为与能源消费、员工工作满意度、教育支出与回报等多个主题。然而, CHARLS的研究主题相对较为集中, CGSS 的则较为分散,可能由于CGSS 作为综合性数据集, 调查对象更为多样化, 数据项更加丰富, 从而研究问题分布较为广泛。关于跨学科演化分析, 研究发现CHARLS 和CGSS 数据集跨学科合作网络的节点数、边数、社区数随着时间在不断增长, 表明不断有学科使用这两个数据集, 且形成了新的跨学科合作社区。
本文从新的视角探讨了社会科学数据集的跨学科性, 为理解数据集在不同学科间的开放共享和高效利用提供了新的思路和方法, 对于促进社会科学数据集在各学科间的扩散以及数据集的评价具有一定的理论与实践意义。在理论意义方面, 本文为数据集的跨学科研究提供了一个较为完整的框架, 后续可以在此基础上研究不同数据集的跨学科性。此外, 还为评价社会科学数据集的质量和影响力提供了新的指标和方法, 有助于后续从数据集的跨学科性视角对数据集进行评价; 在实践意义方面, 本文揭示了CHARLS 和CGSS 数据集的使用学科分布、潜在的研究主题以及潜在的合作学科, 为相关研究人员提供了启示和借鉴。同时, 也为数据集建设者和管理者如何促进数据集在不同学科之间的扩散提供参考依据。
本研究存在一定的不足之处。首先, 本文的数据集来源于Web of Science 核心合集, 主要分析了使用CHARLS 和CGSS 数据集的英文文献集。在后续研究中, 可以纳入使用CHARLS 和CGSS 数据集的中文文献集作为研究数据源的补充, 并对使用CHARLS 和CGSS 数据集的中英文文献集的跨学科性进行对比分析。其次, 未来的研究可以进一步探索社会科学数据集和自然科学数据集在扩散特征和模式方面的差异, 以期更好地理解数据在不同学科间的扩散和应用规律, 为各领域数据集的开放共享与利用提供有益的启示。
猜你喜欢
科学大众·教师版(2022年6期)2022-05-23 02:17:51
云南社会科学(2022年1期)2022-03-16 06:29:30
历史教学问题(2022年6期)2022-02-28 08:15:38
理论纵横(2022年1期)2022-02-16 07:26:06
河北农业大学学报(社会科学版)(2021年6期)2021-12-29 09:18:36
大学(2021年2期)2021-06-11 01:13:32
浙江树人大学学报(人文社会科学版)(2021年2期)2021-04-15 09:14:06
课程教育研究(2021年21期)2021-04-14 01:23:39
知识产权(2016年4期)2016-12-01 06:57:47
数学理论与应用(2016年1期)2016-02-28 09:26:17
