
面向在线健康社区的融合时间特征个性化推荐算法研究
2023-08-31 02:26曹锦丹钟玉骏邹男男等
现代情报 2023年9期
关键词:个性化推荐
曹锦丹 钟玉骏 邹男男等


关键词: 在线健康社区; 个性化推荐; 动态社交网络; 个人动态偏好
DOI:10.3969 / j.issn.1008-0821.2023.09.003
〔中图分类号〕R-058 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 09-0026-10
健全和完善“互联网+医疗健康” 服务体系及支撑体系是当前推进实施“健康中国” 战略的一项重要工作[1] 。随着这项工作的推进, 在线健康社区(Online Health Communities, OHCs)已成为人们获取健康信息的重要渠道。OHCs 是具有相同健康或疾病治疗兴趣的人在以互联网为媒介形成的健康社区集合, 是人们获取健康信息、得到情感支持、分享个人经验和健康信息以及提供情感支持等各种与健康相关的活动的平台。然而, 目前OHCs 平台的用户在健康信息搜寻和交互方面尚需进一步优化。随着OHCs 用户数量和信息资源的不断增长, 导致大数据呈现低价值密度特征, 即信息过载问题。因此, 用户对个性化推荐的需求越来越高, 以减少信息超载带来的认知负荷。但是, 用户的健康信息需求因其自身因素不同而具有个性化特点, 且用户健康状况会随着时间推移而发生改变, 目前在线健康社区个性化推荐算法鲜有对用户兴趣的时间动态迁移特征进行赋权。如何有效构建更为丰富的OHCs用户推荐算法, 提供更为针对性的服务, 以实现精准推荐, 已成为目前领域学者普遍关注的问题。
1国内外相关研究
个性化推荐是在数据挖掘基础上实现的智能信息服务, 能够有效满足人们对各类信息的个性化需求[2] 。早期的推荐算法研究主要集中于传统推荐算法, 包括基于内容的推荐算法、基于协同过滤的推荐算法和基于混合的推荐算法。近期基于深度学习的推荐模型成为一大热点[3] , 但其与传统推荐算法相比, 需要大量的数据作为支撑, 无法解决数据稀疏性问题。而研究表明, 将社交信息等辅助信息加入传统推荐算法可缓解冷启动和项目稀疏性[4] , 且考虑用户兴趣的动态迁移性可提升个性化推荐算法效率[5] 。故为弥补传统推荐算法的不足, 研究者们尝试采用多维度信息融合并加入推荐算法, 最典型的是社交关系信息、时间上下文信息。如琚春华等[6]通过构建仿真的微信平台获取数据, 将用户社交关系与信任关系和偏好融合到推荐方法中, 提高了其有效性和准确度; 董立岩等[7] 意识到研究时间对用户兴趣影响的重要性, 通过在传统的协同过滤算法中融入时间特征, 发现基于时间衰减的协同过滤算法在准确性上得到了显著的提高。上述研究集中于电子商务、新闻、社交网络、音乐、广告等领域,但在医疗健康信息服务领域的应用程度还不足。OHCs 的推荐有其显著的特殊性, 只包括提供内容服务、无评分信息、冷启动和矩阵稀疏问题更严重等特性, 而且现实中用戶兴趣会随着健康状况在不同时期阶段的变化而发生改变。所以目前的已有个性化推荐算法在OHCs 中的应用还有待深入探索。
在线健康社区个性化推荐方法的研究尚不多见。现有研究主要是通过分析用户社交关系和用户生成内容文本语义构建网络来实现话题内容的推荐, 且基于用户兴趣是一成不变的观点, 将用户以往产生的数据不分时间先后统一用来代表用户现在的兴趣。如Yang H 等[8] 通过隐含的社会关系, 采用自适应矩阵分解的方法为用户进行推荐; Yang CC 等[9] 通过构建用户和UGC 之间关系的异构医疗信息网络, 向OHCs 中的用户推荐话题贴; Yang H等[10] 通过构建用户影响关系(User Influence Rela?tionships, UIRs)网络计算用户相似度, 提高为用户进行内容推荐的准确度; 李贺等[11] 通过将提取的用户评论关键词之间形成语义关系网络, 以便构建模糊认知图, 实现相关疾病知识的推荐; 王欣研[12] 通过挖掘热点问题以及问题主题相关关系,构建语义关联主题图谱并搭建了个性化推荐模型。
综上所述, 个性化推荐算法已有较多研究将社交关系和时间上下文作为额外信息融入个性化推荐算法, 但是并不完全适用于OHCs 的用户推荐。而现有的面向在线健康社区的个性化推荐, 均未考虑时间特征对用户兴趣的影响, 导致用户兴趣的动态迁移性无法体现。因此, 本研究基于其他领域的个性化推荐算法研究, 构建融合时间特征的在线健康社区个性化推荐算法, 深入探讨用户兴趣的动态迁移性对提升推荐算法的准确度和有效性, 以获得更加精准的推荐结果。
2基于社交关系和个人偏好的动态个性化推荐算法框架
OHCs 与其他类型的在线社区存在的最大区别是OHCs 用户在交互过程中, 因每个用户的健康状况会随着时间的推移而产生变化, 其健康信息需求和信息交互行为具有更显著的动态迁移性。另外,OHCs 用户兴趣分为用户间互动形成的社交关系和用户日常发布信息即用户个人偏好两部分[13] 。基于以上两点, 本文所构建的融合时间特征的个性化推荐算法分为3 部分: ①社交关系与时间特征融合的动态社交关系矩阵构建; ②用户个人偏好与时间融合的用户话题帖匹配矩阵构建; ③基于动态社交关系和个人动态偏好的个性化推荐算法构建。
2.1融合时间特征的社交关系矩阵构建
OHCs 与一般在线社区相比属于弱社交关系媒体, 其社区成员间基于兴趣构建社交关系。此外,用户间的社会影响关系反映用户间通过交换健康信息产生社会影响, 从而构成社交关系的互动过程。且OHCs 用户间社会关系越强则代表两者间的社会影响力越大, 并且两用户间相似度越大, 两用户间的相互影响程度也越大[14] 。且社会关联理论表明,一方面具有相似特征的两个个体间更容易建立社会关系; 另一方面具有社会关系的个体更容易表现出相似特征[15] 。所以, 从融合时间特征的用户社会关系强度和融合时间特征的用户间相似度出发, 构建OHCs 融合时间特征的社交关系网络即用户影响力网络, 以体现用户间基于兴趣的动态社交关系。公式如下:
然而, 一方面, 用户社会关系强度依赖于连接两用户的连通路径的权值和数量; 另一方面, 用户行为模式相似度依赖于用户行为轨迹。要构建OHCs 融合时间特征的用户影响力网络, 因其不同于存在评分、评级和关注等显式行为的其他类型在线社区, 需先依据OHCs 的隐式互动行为特点, 构建基于用户间共同兴趣产生参与话题帖的互动行为来表示社会关系的隐式行为网络。因此, 本部分包括: ①融合时间特征的隐式用户行为网络构建; ②融合时间特征的用户间相似度矩阵构建; ③融入时间特征的用户间社会影响力计算。
2.1.1融合时间特征的隐式用户行为网络构建
OHCs 是用户发布和回复话题帖进行交流的平臺, 其互动行为是基于兴趣产生的隐式行为, 而不像其他社区存在显式行为。因此, 本研究构建的行为网络基于OHCs 中的隐式互动行为构建。其隐式交互行为定义为用户参与同一话题帖, 认为参与同一话题帖的用户具有相似的兴趣, 且相似程度与共同参与话题帖的数量成正比, 且回复量比访问量更能体现话题帖的受关注程度[16] 。但当一个话题帖成为热门话题帖导致大多数用户普遍参与其中时,反而该话题帖不能很好地代表用户的兴趣, 因而此帖对用户共同兴趣的贡献度应相对降低。此外,OHCs 中用户的健康状况会随时间改变而变化, 导致用户兴趣也随之发生变化, 致使用户间基于兴趣的影响力随时间推移而衰减, 表现为对时刻tk 的用户uk 来说, 同一级联中时刻tk 附近的用户对uk的影响力应远大于较早时刻的用户, 有研究[17-18]证明了这一点[19] 。且Muniz C P M T 等[20] 受弱联系社会理论的启发, 认为最近的互动比以前的互动具有更大的影响力。
因此, 上述内容表现在隐式用户行为网络中,概括为以下3点:
1) 用户间共同参与的话题帖数量越多, 即交互次数越多(当两个用户在多次参与一个话题帖时, 只能算为1 次), 表明两者间健康信息兴趣越相似, 用户之间的权重越大。
2) 参与一个话题帖的人数越多, 表明该话题帖受欢迎程度越大, 此帖对边权重的贡献越小, 即每个话题帖的参与人数定义为Nu, 用其倒数代表该话题帖对本用户边权重的贡献值。
3) 两用户间的交互时间距离现在越近, 表明两者间的健康状况相似可能性越大, 用户间产生的社会影响力越大, 相应的边权重值也越大, 其互动时间定义为两者中后参与该话题帖的时间。
基于上述观点首先构建动态隐式行为网络, 以便获取用户间的连接强度, 公式如下:
然而, 在线健康社区中每个用户的活跃程度不同, 越活跃的用户, 参与的话题帖数量越多, 这就导致用户差异问题的出现。为了解决上述问题, 本研究把用户参与的话题帖数量用来代表用户的活跃程度, 参与话题帖数量多的用户, 兴趣分布更为广泛, 导致单一话题帖在该用户参与的所有话题帖中所占的比重较小。因此, 为了区分每个用户的活跃程度差异, 需要从每个用户的角度出发, 构建有方向的用户行为网络。步骤包括:
首先, 将每个用户参与的话题帖数量作为节点权重。
其次, 将用户的活跃程度加入边权重, 即在原有边权重的基础上除以起点用户的节点权重。
最后, 将边权重进行最大值归一化。
2.1.2融合时间特征的用户间相似度矩阵构建
因OHCs 是用户根据自己的兴趣参与话题帖讨论产生互动行为的平台, 所以其用户倾向于与具有相似特征或相似健康状况的用户产生交流, 其相似度越大, 健康状况越相似, 彼此间的社会影响力越大。而OHCs 的用户间相似度通常采用用户信息的相似度来衡量。且OHCs 中的用户信息分为静态信息和动态信息, 其中静态信息主要是指用户属性信息, 动态信息包括用户生成内容和用户行为轨迹[22] 。故本研究融合时间特征的用户相似度, 从用户的属性、用户生成内容和用户行为模式相似度展开, 其中融合时间特征体现在动态信息上。用户相似度的计算公式如下:
①按权重排序选取n 个关键词, 将其权值作为中心向量, 目标用户的每一条内容变为n 维向量,称作扩展向量, 若两者出自同一文档文本, 则表示为(0,0,0,…,wsx), 若存在m 个, 则扩展向量对应维度的值为wsx/ m。
②设置阈值。将上面的两个向量利用余弦相似度公式计算两者间的相似度, 如果相似度大于设定的阈值则加入用户关键词序列, 否则舍弃。
③若新加入的关键词在Ku 中已经存在, 则进行关键词权值的叠加, 否则, 直接加入新关键词及其对应的权值, 即原来权值与时间衰减因子相乘后的值。使用归一化余弦相似度衡量用户生成内容关键词序列相似度KSij。
3) 用户属性相似度
社会网络理论中的个体属性在社会关系的形成中起着非常重要的作用[27] , 并且疾病与个体属性相关, 所以OHCs 中的个体属性也是计算用户健康状况相似度的重要组成部分。而本文在用户属性相似度的计算方法上依旧沿用Yang H 等[10] 的研究,面对用户属性值的不同类型: 文本型数据若相同,赋值为1, 否则为0; 数值型数据采用最大最小值标准化公式进行求值。最后利用用户所有属性相似度的平均值代表用户属性相似度。
4) 利用XGBoost 确定权重系数
使用XGBoost 模型得到用户相似度中3 个特征的重要性。XGBoost 模型中特征重要性是通过对数据集包含的每个特征进行计算并排序得出, 通常而言, 一个特征越多的被用来在模型中构建决策树,它的重要性得分越高。
2.1.3融入时间特征的用户间社会影响力计算
在OHCs中, 用户根据其发帖和回帖产生的隐式交互活动进行连接, 产生社会影响, 且交互越频繁越容易产生较大的社会影响。而用户间的社会关系强度反映了两者间的社会影响力, 且依赖于连接他们的连通路径的权值和数量, 且随着用户之间距离的增加而降低[28] 。所以为了获得两用户间最强的社会关系, 需要求两点间的最短路径。
Dijkstra最短路径算法是有向加权图中最基本和应用最广泛的最短路径算法。在有向图中Dijk?stra 最短路径算法可以表示为: 在构建好的有向带权图G 中, 给定源点A, 求其到图G 中其他顶点的最短路径, 具体贪心算法的策略是遍历距起始点最近且未访问过的顶点的邻接节点, 直到遍历到结束点。所以, 本文选用Dijkstra 最短路径算法并基于上文构建的融合时间特征的有向隐式用户行为网络找出两用户间的最短路径, 若存在多条最短路径,取其中路径权值和最大的路径作为最短路径。
两用户间社会影响力取决于用户间路径的边权重和经过的边数量, 故根据求得两用户间的最短路径, 其包含的所有节点, 依次将两节点的权值相乘,权值乘积越大, 代表用户间基于兴趣的社会影响力越强。
2.2融入时间特征的用户话题帖匹配矩阵构建
OHCs 中最主要、最有价值的内容是反映用户健康状况和健康信息需求的话题帖。且OHCs 内的用户兴趣不仅受社交关系的影响, 还受其自身内容偏好的影响[10] 。故在获得用户间基于兴趣的社交关系而产生的社会影响后, 还需根据用户的自身偏好来判断推荐给用户的话题帖是否满足用户的健康信息需求, 具体可分为用户自身内容偏好的特征提取、话题帖内容特征提取以及两者之间的匹配程度3 部分。
1) 用户自身内容偏好。其提取方法同上文中对用户内容相似度中内容特征的提取方法, 即采用LDA 主题模型和融合时间的关键词提取技术分别提取反映用户健康信息需求的主题偏好和关键词偏好。在数据利用方面, 利用OHCs 中用户产生最多也是最重要组成部分的文本数据来分析用户自身偏好: 一方面, 各大社交网站一般通过用户生成的文本信息来挖掘用户的自身偏好[29] ; 另一方面, OHCs成为公众获取健康信息的重要渠道, 其用户基于发帖和回帖产生了大量用户交互数据, 其中价值最大的是用户沟通交流时所产生的文本数据。
2) 话题帖文本内容的特征提取。其具体步骤为: 先利用LDA 主题模型提取此话题帖在健康信息各个主题下的分布概率, 即该话题帖的主题特征向量; 再利用关键词提取技术得到该话题帖中与疾病有关且反映用户健康需求的关键词向量, 但此处的关键词提取技术不同于前文中的关键词提取技术, 这里未融合时间, 原因为此处对话题帖的关键词提取只是对话题帖本身内容特征的表示, 并非从用户层面表示其健康信息兴趣演变。
为了检验用户内容偏好与话题帖的符合程度,需要将上述得到的表示融合时间的用户内容偏好向量和话题帖向量, 利用余弦相似度计算两者间相似度大小, 值越大表明两者越相似, 用户参与该话题帖的可能性越大, 也就是该话题帖越能满足用户的健康需求。根据匹配度得分形成用户话题帖匹配矩阵, 公式为:
最后, 将R′与F 对应位置相乘, 得到最后的用户话题帖兴趣评分矩阵。针对目标用户, 对其按分值大小排序, 形成TOP-N 推荐列表。
3实证研究
3.1数据来源
本研究以糖尿病为例。《Ⅱ型糖尿病防治指南》指出, 通过生活方式的干预, 可以减少糖尿病各种并发症, 有效提高糖尿病患者的生存质量[31] 。其生活方式的干预需要根据病情和生活习惯等综合因素制定个性化方案; 甜蜜家园是一个创办于2005年的国内最知名、规模较大、管理制度比较完善、用户的活跃程度较高的糖尿病社区[32] 。综上, 本文选择甜蜜家园中的“Ⅱ型糖尿病” 社区版块, 并使用“后裔采集器” 采集2019 年5 月30 日—2022年7 月25 日的发帖数据: ①参与话题帖用户的个人属性包括性别、回帖数、主题数、糖尿病类型、治疗方案、生日、签到等级、用户组、注册时间和在线时间; ②用户发布的文本内容及其发布时间;③用户ID。
本研究共采集了3 699条主题帖, 包含2 424个用户, 48 725条话题帖信息。根据本研究中构建算法的需要将其分为两个大小不同的数据集, 其中小数据集包含13 955条数据, 应用于XGBoost 特征重要性算法确定用户间相似度3 个组成指标的权重系数以及内容相似度中两个模型向量的权重系数; 大数据集包含34 770条数据, 用来评价确定权重系数的个性化推荐算法和基准模型中的推荐算法。
3.2数据预处理
为保证数据的有效可用, 删除发表的表情符号或“谢谢分享” “顶” “赞” 等评论、空评论, 以及参与话题帖小于3 和用户信息缺失严重的数据。数据集中序数值属性的空值利用其均值填充。
目前研究用戶在线生成内容得到认可最多且被广泛使用的停用词表有中文停用词表、百度停用词表、哈工大停用词表以及四川大学机器智能实验室停用词库, 本研究为了构建相对完整的停用词表,在这4 个停用词表的基础上, 先将其整合, 再去除重复内容。使用Jieba分词对评论文本进行分词。
本研究认为随机划分训练集和测试集会导致数据泄露的前瞻偏差问题, 致使存在把用户最近的评论用于训练, 而把早期的评论用于测试的可能性,丧失公平性, 且随机划分数据集训练出来的模型的性能也无法推广到现实世界的性能。因此, 本文利用时间戳列, 分别对每个用户按照时间顺序进行排序, 再按照8 ∶2 的比例划分训练集和测试集, 数据集中时间距离现在最近的20% 归为测试集, 远离现在时间的80%为训练集。
3.3评价指标
在模型的评价指标上, 本研究选用个性化推荐算法领域中最常用的评价指标, 包括精确率(Preci?sion, P)、召回率(Recall, R)和F1 评分(F1-Score,F1)。F1-Score 评估算法的整体性能, 具体含义Precision 和Recall 的调和平均值。具体计算方法见式(12) ~(14):
其中, Hits 是目标用户参与推荐的帖子数, r是推荐的话题帖数量, Miss 表示目标用户参与但未正确推荐的话题帖数量。
3.4实验结果
1) 在利用LDA 主题模型对文本内容进行主题分析时, 通过计算不同主题数K 所对应的主题一致性Coherence, 确定LDA 主题模型最优的主题数。主题一致性Coherence 越高表示可解释性和语义连贯性越好, 则对应的K 值可以作为LDA 模型最优主题数, 两个数据集分别对应K = 3 和K = 2,结果如图1 和图2 所示。
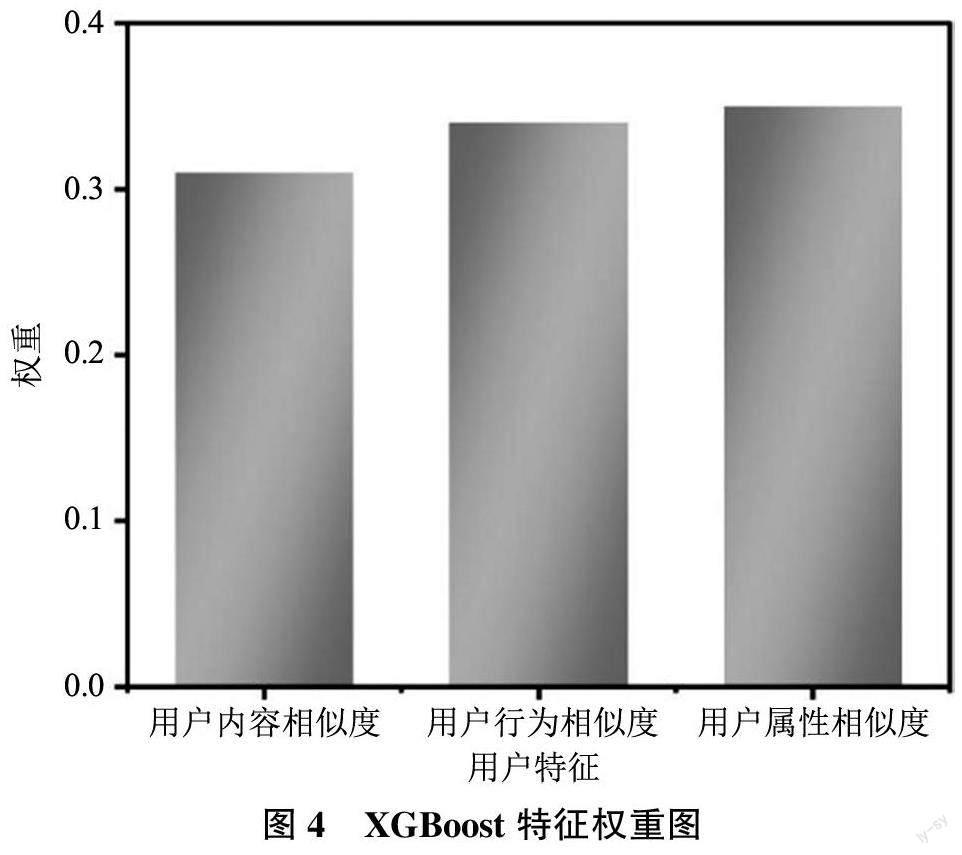
3) 利用XGBoost 确定用户相似度3 个特征权重系数, 用户内容相似度权重为0.31, 用户行为相似度权重为0.34, 用户属性相似度权重为0.35。结果如图4 所示。
4) 为了验证本文构建的融合动态社交关系和个人动态偏好的个性化推荐算法(TOHCRec), 选取时间上下相关的项目协同过滤推荐算法(TItem?CF)、时间上下相关的用户协同过滤推荐算法(TUserCF)、时间上下相关的内容推荐算法(TCB)、基于用户社交关系和个人偏好兴趣建模的推荐算法(OHCRec)。
推荐列表长度r从50~500, 步长为50。Preci?sion 随推荐列表的增长而降低, 本文提出的TO?HCRec 方法在Precision 上明显优于所有基准方法;Recall 随着推荐列表长度r 的增加而上升, 本文提出的TOHCRec 方法在召回率上明显优于所有基准方法。TOHCRec 和OHCRec 的F1-Score 随着推荐列表长度r 的增加先下降后趋于稳定, 其他基准模型趋于稳定。
总体来看, 本文构建的TOHCRec 优于OHCRec,原因为TOHCRec 在计算用户间社会关系和个人偏好时基于用户兴趣的动态迁移性, 考虑了时间特征, 能更加及时地感知到用户兴趣的变化。TO?HCRec 优于TCBRec 是因为TCBRec 中只考虑了用户的个人偏好, 在很大程度上无法准确地捕捉到用户的兴趣。TUserCF 和TItemCF 是根据用户的历史记录对用户兴趣建模, 分别根据用户和话题帖的相似性生成推荐结果。其中TItemCF 更加个性化, 是将用户参与过的话题帖进行相似度计算, 根据话题帖相似度为用户推荐可能感兴趣的内容; TUserCF与TItemCF 相比更加偏向社会化, 其考虑了两用户间的相互影响, 具体为先找到与目标用户兴趣相似的用户群, 并按照相似度大小对相似用户排序, 再将相似用户感兴趣的话题帖推荐给目标用户。但由于OHCs 中用户的社交关系属于基于兴趣的弱关系,导致TItemCF 的效果优于TUserCF; 而TOHCRec 优于TItemCF、TUserCF, 則是融合社交关系和个人偏好的个性化推荐算法能更准确地描绘用户的兴趣。以上所有实验结果表明, 融合动态社交关系和个人动态偏好的个性化推荐算法, 可显著提高推荐算法的性能。
4结语
本研究构建的融合时间特征的在线健康社区个性化推荐算法在一定程度上解决了用户兴趣存在动态迁移性的问题, 并提高了在线健康社区个性化推荐算法的准确度, 为用户兴趣存在动态迁移性和缓解冷启动、矩阵稀疏问题提供了解决思路, 进一步完善了在线健康社区的个性化推荐算法研究, 为后续在线健康社区的个性化推荐研究提供了参考。但本研究还存在一定的局限性: 由于论坛和伦理道德的限制, 导致本研究中用户的个体属性不够充足,数据来源有限, 后续可获取多个数据平台的数据,进行跨平台数据的研究。
