
基于YOLOv5的荔枝果实小目标检测算法研究*
2023-08-28 09:49王萍叶
山西电子技术 2023年4期
王萍叶,毛 亮
(1.深圳职业技术学院,深圳518055; 2.粤港澳大湾区人工智能应用技术研究院,深圳518055)
1 介绍
小目标检测困难[1]的原因包括卷积神经网络的卷积步幅较大;数据集的分布情况不理想;模型泛化能力弱;先验框的设置欠优;交并比阈值的设置欠优等。本文以荔枝检测为例,讨论卷积神经网络检测步幅,数据分布情况,先验框的设置对小目标检测的影响,论证高层特征提取和金字塔特征混合对小目标检测的作用有限。
1.1 小目标的定义
小目标有两种定义方式。一种是根据相对尺寸大小定义,如目标尺寸的长宽是原图像尺寸的0.1;另外一种是根据绝对尺寸大小定义,即尺寸小于32×32像素的目标。本文使用的原始图像是高清图片。将原始图片缩放到640像素大小后,荔枝的尺寸在 2.5~56像素之间,符合小目标的标准。
1.2 YOLOv5的网络结构
本文研究基于2021年4月发布的YOLOv5 v5.0版本。5.0版本不仅保留了以前版本的对应下采样幅度分别为8、16、32的三层金字塔特征层输出,还可以增加一层,支持对应下采样幅度为64的第四层特征输出。增加第四层特征输出更有利于检测较大的物体和支持更高分辨率的图片。5.0版本用PyTorch1.7 中新支持的SiLU()激活函数[2]替换了先前版本中的LeakyReLU()和Hardswish()激活函数,整个网络中任何一个地方都只使用 SiLU 激活函数。新版本删减了以前版本中BottleneckCSP 部分的Conv模块。图1显示了YOLOv5 v5.0版本的三层特征网络结构,Backbone部分用于特征提取,Head部分包括用于组成三层金字塔特征混合层的FPN+PAN结构[3],和用于分类和定位的Detect部分。FPN 自顶向下传达强语义特征,PAN自底向上传达强定位特征,将高低层特征进行混合,可以提高特征提取的能力。
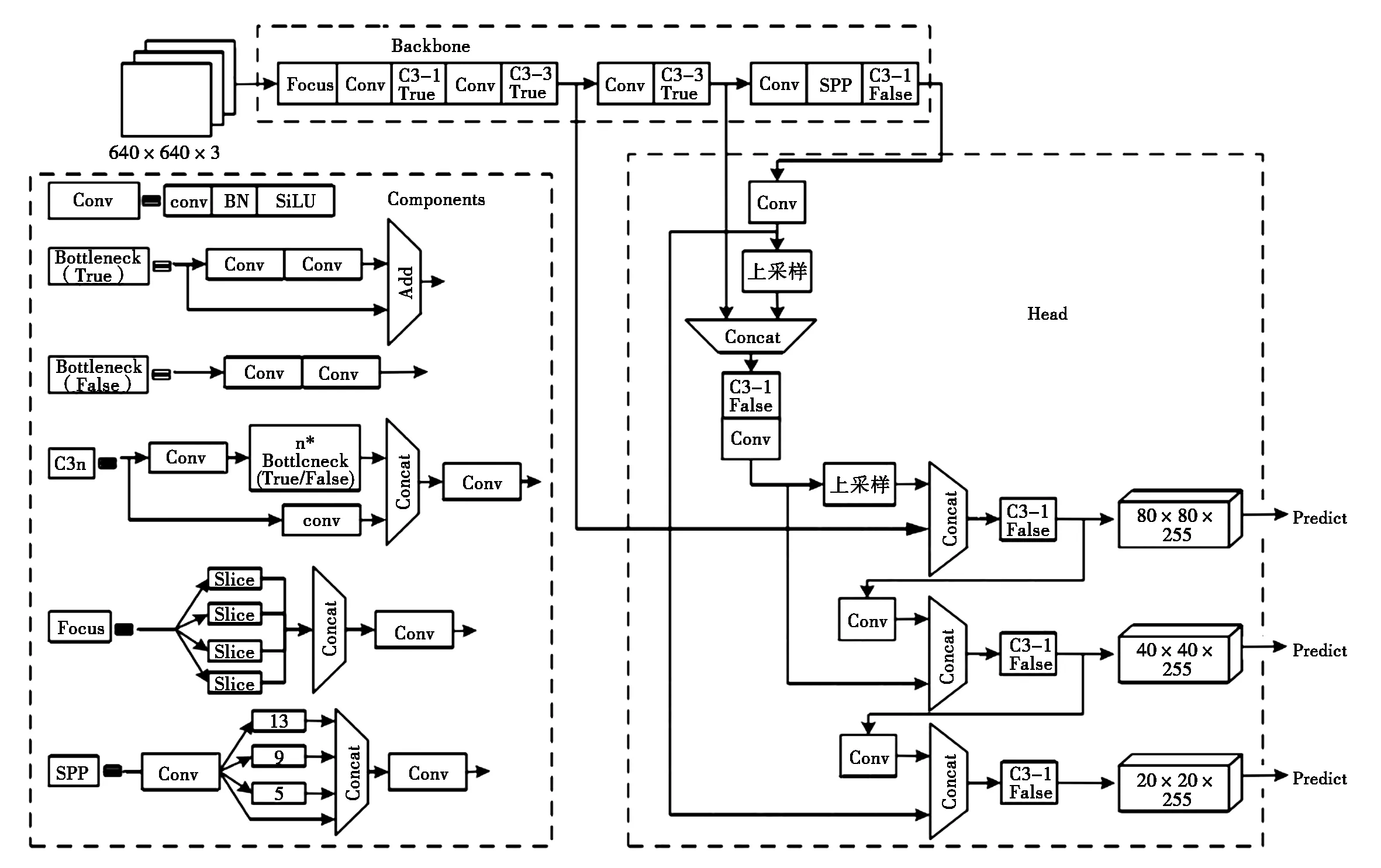
图1 YOLOv5 v5.0 三层金字塔网络结构
2 小目标检测的网络改进
2.1 删减网络结构
YOLOv5金字塔特征层的高层特征层用于检测大目标,而荔枝之类的小目标在网络卷积过程中很难传递到后面的深层网络中去。因此,我们可以去除高层部分的网络结构以期达到减少计算量,加快检测速度又不降低检测精度的效果。本文使用图2所示的结构。主干网络仅保留对应下采样幅度为8的前5层,在输入尺寸为640×640像素时,每个特征代表8×8像素的区域[4],去除对应下采样幅度为16和32的第5层到第10层。Head部分去除三层金字塔特征混合层,仅保留最后的检测层。经过简化,模型的参数从7,053,910精简到271,526,数量为原来的3.85%。
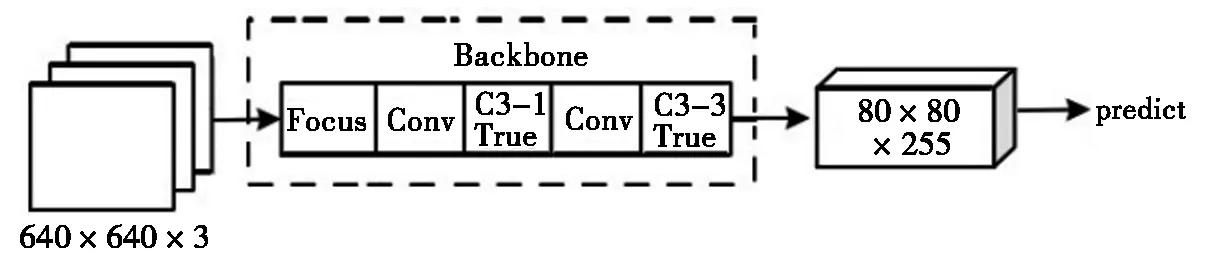
图2 简化之后的网络结构
2.2 删减高层网络对应的先验框
YOLOv5在训练模型时,首先将原始图片缩放到预先定义的大小,设为x,然后将缩放后的图片随机裁剪缩放并拼接为x×x大小的图像,这些缩放并拼接后的图片就是作为训练模型的数据图片[5]。图3显示处理后荔枝大小相对于图片的分布比例,本文预先设定的图片大小为640像素,当原始图片被缩放到640像素时,标注的荔枝的宽和高在5.4~13像素之间约占50%,3.6~25像素之间约占97%,全部荔枝的宽和高都在2.5~56像素之间。YOLOv5提供的预训练模型中,预测小目标的先验框预先设定为 [[10,13], [16,30], [33,23]]三个先验框。每个先验框可以被训练预测自己尺寸的1/4~4倍之间,因此,这三个先验框可以全覆盖所有的荔枝,原模型中用于预测中目标和大目标的先验框并不会被训练到,对以后荔枝的检测也没有作用,因此在删减高层网络的同时,删除中目标与大目标对应的两组先验框。
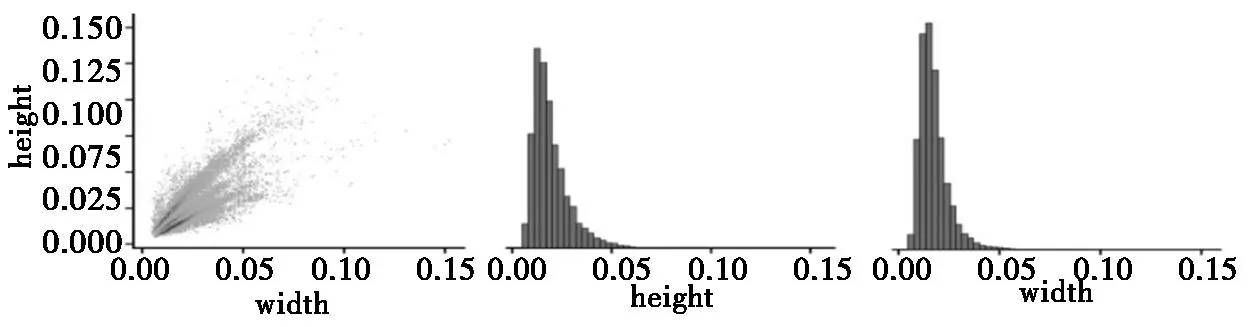
图3 荔枝尺寸相对于图像尺寸的百分比
2.3 修改先验框
非极大抑制算法[5]用于抑制不是极大值的元素,可以理解为搜素局部最大值。在小目标检测中,当同类小目标密集出现时,同一个目标会被多个先验框同时预测到,太多的先验框会增加计算量,提高NMS的检测时间,而减少先验框的数目可以提升NMS运行的效率。本文基于全部荔枝的像素在2.53~56像素之间,因此将先验框改进为只使用一个,大小为[10,14],这个尺寸就可以全覆盖所有荔枝。
3 实验及结果分析
本文实验机器操作系统为WIN10,CPU型号为Intel(R) Xeon(R) Bronze 3106 CPU @ 1.7GHz,GPU型号为NVIDIA Quadro P600,显存大小2GB,内存大小8GB。模型基于Pytorch1.7.0,使用cuda10.1和cuddn10.1对GPU加速。
本文使用的数据集有2000张高清照片,包括训练集1500张,验证集和测试集各250张图片,图片的训练尺寸设定为640,epoch设为200。数据集部分图片如图4所示,图4(a)为原始的训练图片,图4(b)为经YOLOv5图像增强后实际用于训练的图片。数据集中数据的统计信息如表1所示(缩放系数设定为0.9~1.1之间)。改进后模型的运行效果图如图5所示。
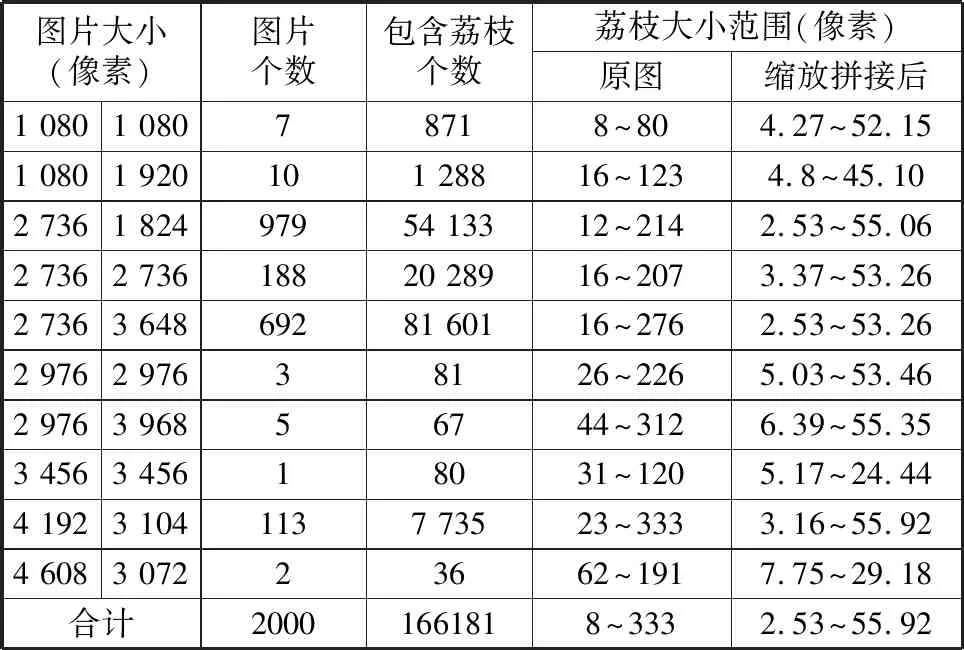
表1 数据集数据统计

图5 部分测试图片
本文实验结果从AP@0.5,AP@0.5:0.95,准确率Precision,召回率Recall、模型参数量,模型大小,模型计算量和平均检测处理时间8个角度进行衡量[2]。图6显示使用YOLOv5s自带模型和简化后模型的训练过程对比,表2显示模型的性能对比。

表2 模型性能对比

图6 训练过程对比
从表2和图6可以看出,本文模型的参数量,模型大小,模型计算量分别为原来的3.85%,4.38%和34.36%,GPU环境模型计算速度提升了48.1%。但模型的精确度,召回率和AP@0.5分别下降1.6%,1.1%和0.2%,AP@0.5:0.95下降较大达到了5.7%。模型的参数大规模减少但计算量减少不多的原因在于大量计算集中在前面的浅层网络。
4 结论
针对自然场景下荔枝果实小目标的检测难点,本文在YOLOv5模型的基础上进行改进,极大地简化了模型,显著地加快了模型的推理速度,同时目标检测的准确率只降低了1%~2%之间。本文模型在GPU为NVIDIA Quadro P600的台式计算机上进行实验,实验结果表明计算速度提升了48.1%,但模型的精确度下降1.6%。本文模型精确度下降主要是因为提取后的浅层特征缺少了原模型提取并融合的高层特征部分,降低了特征表达能力。
因此,本文研究进一步证明了只提取高层特征或只在金字塔部分进行特征融合,对小目标的检测准确率提升有限。
猜你喜欢
艺术家(2023年8期)2023-11-02
科学大众(2022年23期)2023-01-30
小哥白尼(军事科学)(2022年2期)2022-05-25
成都信息工程大学学报(2019年3期)2019-09-25
红领巾·萌芽(2019年8期)2019-08-27
中国(俄文)(2019年8期)2019-08-24
意林·全彩Color(2019年4期)2019-05-11
岭南音乐(2017年2期)2017-05-17
自动化学报(2017年5期)2017-05-14
CHIP新电脑(2016年3期)2016-03-10
