
一种车载数字相机与激光雷达融合算法设计
2023-08-24 19:25:05康炳翔秦忠鑫查欣然丁士航胡江飞
专用汽车 2023年8期
康炳翔 秦忠鑫 查欣然 丁士航 胡江飞

摘要:环境感知是智能辅助驾驶的底层模块,单传感器感知存在易受干扰、所需配置传感器数量多和感知效果差等弊端,为此提出一种车载数字相机与激光雷达融合算法。综合考虑信息融合高效性与系统鲁棒性采取决策级融合策略,利用CENTER POINT算法对雷达点云数据进行处理,再利用Yolo v3算法进行密集型数据训练处理图像数据,最后使用交并比匹配(IOU)和已有文献的D-S论据实现数据融合并输出决策结果。经过KITTI数据集验证,该融合算法输出的识别效果优于单传感器,且在多种路况上均有良好的目标检测效果。
关键词:环境感知;激光雷达;Yolo;融合算法;目标检测
中图分类号:U462 收稿日期:2023-04-19
DOI:10.19999/j.cnki.1004-0226.2023.08.006
1 前言
近年来,芯片算力与网络技术的快速发展,使得智能辅助驾驶技术走向成熟。环境感知作为核心技术,包括利用机器视觉的图像识别技术、利用雷达(激光、毫米波、超声波)的周边障碍物检测技术、多源信息融合技术、传感器冗余设计技术等[1]。若仅通过单一类别传感器获取信息,则准确度低、受环境影响大、系统鲁棒性差,容易出现误判漏判的情况,因此常采取多传感器并采用多源信息融合技術实现车辆的环境感知。
多传感器信息融合能够很好地克服单一传感器所出现的问题,实现环境信息最大利用化,从而提高系统的可靠性和抗干扰能力。一些学者对此进行了研究[2-3],然而大多数研究往往在融合的网络架构上寻求突破,试图通过跨层级的数据特征融合实现目标检测的高性能。此类方法对于算法的复杂程度有较高的要求,也要求车载处理器性能优异,对于设备依赖较高。据此,本文提出一种车载数字相机与激光雷达融合算法,并进行了验证分析。
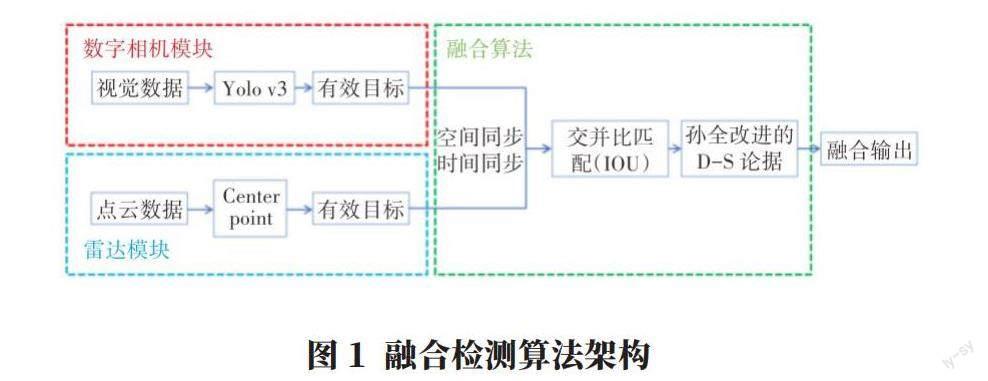
2 融合检测算法架构
多传感器信息融合可以实现各传感器感知优势互补,提高车辆感知系统灵敏性与可靠性,当前有三种策略:数据级融合、特征级融合、决策级融合[4]。
决策级融合具有层级较高、处理数据量较少、实时性好、算法鲁棒性较强等优点。因此,本文采用决策级信息融合方法。融合检测算法架构如图1所示,包含数字相机模块、雷达模块和融合模块共三个模块。数字相机模块使用Yolo v3算法处理视觉数据并框出检测目标的二维框与置信度;雷达模块使用center point算法处理点云数据并框出检测目标的三维框与置信度;融合模块利用交并比匹配(IOU)与孙全等[5]的D-S论据进行边界框融合与置信度融合,实现多传感器融合。
3 视觉数据和激光雷达点云处理
3.1 基于Yolo v3的视觉目标检测
数字相机模块基于深度学习利用Yolo v3算法进行密集型数据训练模型。此算法主干网络是Darknet-53,因其网络结构中含有53层卷积层,并且相较于之前版本Yolo算法增加了多尺度特征融合目标检测方法。跨尺度特征融合可以兼顾高低感受及不同尺寸的目标检测,极大地提高了视觉目标检测的准确率。
选取KITTI数据集,模型训练预权重设置为在COCO数据集训练的权重,首先将KITTI数据集转为VOC系列数据集格式,数据集共包含7 481条数据,并且以训练集∶验证集≈6∶1的比例划分,即训练集6 413条,验证集1 068条。数据库搭建完成后进行环境配置与模型部署,设置迭代次数为270轮,开始训练模型。数字相机模块充分利用基于神经网络的深度学习技术,通过密集型数据高重复训练得到一个参数优异的视觉目标检测模型。具体实现流程如图2所示。
3.2 基于Center point的3D目标检测
雷达模块基于深度学习利用Center Point算法[4]实现目标检测。首先以点云数据作为输入,输出物体的细化检测框与置信度,相较于边框预测,压缩了对象检测器的搜索空间,提高了检测性能;在面向目标尺寸复杂的场景,该算法精度更高。因此本文选用Center Point算法对点云数据进行处理,完成目标检测。
具体流程如下:输入点云数据,基于基础的3D backbone网络处理得到特征地图。其维度M为:
式中,w是宽;h是长;k是通道数。
Center heatmap head预测目标中心点,生成一个大小为k的通道,同时算法会扩大每个对象中心的Gaussian peak,从而改善点云稀疏导致的目标漏检;Regression head处理数据得到3D框的类别、置信度,构成3D候选框。最终从3D候选框的每个面提取额外的特征点,通过对特征地图输出的M进行双线性插值获得特征。然后拼接这些额外的特征点输入到MLP,输出与类别无关的置信度与细化边界框,将此置信度与3D候选框所得置信度相乘再开方,得到最终置信度。
4 多传感器信息融合
4.1 空间同步
激光雷达获取的点云数据与数字相机获取的图像数据的融合首先需要进行空间同步,在此进行的两种传感器坐标标定是指将三维坐标系的点云数据投影至图像数据的二维坐标系。三维坐标系依次经过旋转平移、投影变换和离散化转为像素坐标系,如图3所示。
具体的两传感器空间同步坐标转换公式表述如下:
式中,u,v为数字相机获取的图像数据二维坐标系点坐标用;fu、fv为数字相机X轴、Y轴方向尺度因子;u0、v0是数字相机图像坐标系的中心点坐标;(x,y,z)为激光雷达获取的三维坐标系点云的坐标;R为旋转矩阵;t为平移矢量;M是投影矩阵。
4.2 基于目标检测交并比匹配的融合
在获得点云3D目标以及视觉目标后,将为点云目标3D检测框建立最小矩形边界框,再与YOLO检测出的边界框进行融合。设点云目标边界框的面积为SLIDAR,视觉目标边界框的面积为SCAMERA。重合区域面积为SRADER∩CAMERA(图4)。则交并比(IOU)计算公式为:
本文选用常用的阈值设计,即阈值取0.5、0.85,用来判断预测的边界框是否正确,IOU越高,边界框越精确。在此,设定交并比小于0.5,认为是两个独立目标,在0.5~0.85时,将相交的区域设为融合目标区域。在0.85~1时,本文认为二者完全重合,设定最小边界框住两个边界框,将其作为融合目标区域。
4.3 基于孙全等[5]的D-S证据算法的融合
基于孙全等[5]的D-S论据改进方法,对经过交并比匹配融合后的两种传感器边界框的置信度进行融合。以下对D-S论据原理[6]进行简单的介绍。
在证据理论中,对于一个问题可能有多种答案,各个答案之间是互斥的,一個答案就是一种假设,共有m种假设,所有假设的集合构成一个识别框架Θ,Θ={A1,A2,…,Ai,…,Am},其中Ai是识别框架中的某一种假设。在识别框架Θ下还存在n个证据E1,E2,…,En,每个证据对识别框架下的每一种假设都有一个预测概率,该证据对所有假设的预测概率的和为1。
对于本文的融合来说,设有一个识别框架Θ,Θ中有两个假设:“是某种类别”“不是某种类别”。在Θ下有两个证据E1(图像)、E2(点云),其构成的基本概率赋值表如表1所示。
表中m1(A1)、m2(A1)分别是图像检测框和点云检测框对某种类别的置信度,m1(A2)=1-m1(A1),m2(A2)=1-m2(A1)。然后用孙全等[5]的D-S论据改进方法求出的m(A)就是需要求出的融合置信度。
5 实验分析
5.1 Yolo v3训练分析
本文Yolo v3模型训练工作站配置方案如表2所示。
实验选取KITTI数据集进行模型训练,将完整KITTI数据集以训练集和验证集约为6∶1的比例划分,所训练模型的map=80.33%,具有较高的精度。
5.2 融合数据分析
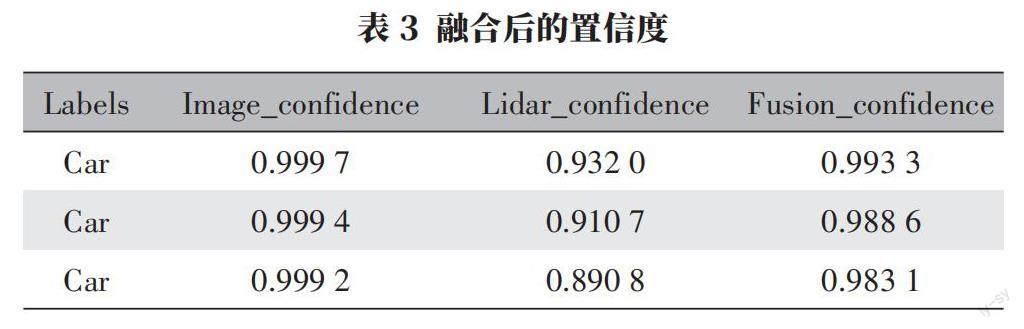
同一场景目标检测定量分析如表格,选取其中三个融合结果进行分析,融合后的置信度如表3所示。
不同路况行驶场景目标检测效果图见图5。
单独使用激光雷达检测并不具有很高的置信度,而与数字相机所检测结果融合之后置信度提高,有效地改善了激光雷达所识别物体置信度不足的问题。注意到融合置信度小于数字相机单检测的置信度,其降低了因完全依赖数字相机误判而引发危险的可能。该融合算法在多种路况上均表现良好的目标检测效果。
6 结语
本文提出了一种车载数字相机与激光雷达融合算法设计,利用center point算法对雷达点云数据进行处理,利用Yolo v3算法进行密集型数据训练处理图像数据,并使用交并比匹配(IOU)和孙全改进的D-S论据实现数据融合并输出决策结果。结果表明:该融合算法在不增加算法网络架构复杂度,不提高硬件成本的情况下,输出的识别效果优于单传感器,且在多种路况上均表现良好的目标检测效果。但值得注意的是,在街边行人检测和密集的街口等复杂场景,此算法会出现一定的漏检与误检情况。
参考文献:
[1]李克强,戴一凡,李升波,等.智能网联汽车(ICV)技术的发展现状及趋势[J].汽车安全与节能学报,2017,8(1):1-14.
[2]Pang S,Morris D,Radha H. Fast-CLOCs:Fast camera-LiDAR object candidates fusion for 3D object detection[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision.2022:187-196.
[3]Wang L,Zhang X,Qin W,et al.CAMO-MOT:combined appearance-motion optimization for 3D multi-Object tracking with camera-LiDAR fusion[J].arXiv preprint arXiv:2209.02540,2022.
[4]Yin T,Zhou X,Kr?henbühl P.Center-based 3D object detection and tracking[C]//2021 IEEE/CVF conference on computer vision and pattern recognition(CVPR).Nashville,TN,USA,2021:11779-11788.
[5]孙全,叶秀清,顾伟康.一种新的基于证据理论的合成公式[J].电子学报,2000,28(8):117-119.
[6]Smith A F M,Shafer G.A mathematical theory of evidence[J].Biometrics,1976,32(3):17-24.
作者简介:
康炳翔,男,2002年生,研究方向为基于深度学习的智能汽车感知与规划控制。
猜你喜欢
北京测绘(2022年5期)2022-11-22 06:57:43
中国交通信息化(2021年8期)2021-11-02 05:26:02
汽车观察(2021年8期)2021-09-01 10:12:41
空间科学学报(2020年6期)2020-07-21 05:36:50
中国交通信息化(2019年1期)2019-03-26 06:43:46
电子制作(2018年16期)2018-09-26 03:27:00
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
电脑知识与技术(2016年5期)2016-04-14 13:48:16
