
基于自然最近邻的不平衡数据欠采样方法
2023-08-23 07:55孟东霞魏晓光柳凌燕
统计与决策 2023年15期
孟东霞,魏晓光,柳凌燕
(河北金融学院a.金融科技学院;b.信息工程与计算机学院,河北 保定 071051)
0 引言
不平衡数据是指各类别样本的数量有巨大差异的数据集,其广泛存在于金融欺诈检测、医疗诊断、故障预测等实际应用中。在将支持向量机、贝叶斯分类器、神经网络等传统的分类模型用于不平衡数据的分类时,分类器倾向于学习多数类样本的特征而忽略了少数类,容易将少数类样本识别为多数类,无法保证少数类样本的分类准确率。而由于少数类样本往往具有重要价值,因此其类别的误判会造成严重的损失。以保险欺诈检测为例,欺诈行为的数量远远小于正常交易的数量,如果不能检测出欺诈活动,那么将会造成机构资金的损失[1]。因此,如何提高不平衡数据中少数类样本的分类准确率具有重要的研究价值。
目前,对于提升不平衡数据分类性能的研究主要包括算法改进和数据处理两种思路。在算法方面,许多学者通过代价敏感学习、组合学习等策略对传统的分类模型进行改进,使其在训练过程中关注少数类样本的特征,提高少数类的识别准确率。数据处理通常采用过采样、欠采样和混合采样三种策略获得平衡数据集,再使用分类模型对其分类。过采样方法在少数类中根据某些策略合成新样本,增加样本数量,已有研究对经典过采样算法SMOTE(Synthetic Minority Over-sampling Technique)[2]提出了多种改进方法,文献[3]总结对比了85种过采样方法的算法策略和分类表现。欠采样方法删除多数类中的部分样本,使其在数量上与少数类样本相等。混合采样[4,5]综合应用了过采样和欠采样方法,使各类样本的数量达到平衡。
随机欠采样在多数类中随机删除一定数量的样本,使剩余样本的数量与少数类相同,虽然操作简单,但有可能删掉较多对分类有重要价值的样本。为尽量保留多数类中重要样本的分类信息,学者们提出了基于聚类的欠采样、边界附近的欠采样等数据处理策略。基于聚类的欠采样方法认为多数类中可能存在类内不平衡的问题,在对多数类样本进行聚类后,从各类簇中筛选出代表性样本加入平衡数据集,采用的聚类算法和样本筛选策略是文献研究的主要内容[6—8]。在分类边界处,不同类样本的分布位置较为接近甚至重叠,文献[9,10]指出类重叠对分类模型的表现有负面影响,因此,边界区域中多数类样本的欠采样对准确识别少数类样本有积极作用:编辑最近邻欠采样方法[11]计算多数类样本的三个最近邻,若最近邻中有两个或以上为少数类样本,则样本容易被误分为少数类样本,需将其移除;由于支持向量分布在决策边界附近,吴园园和申立勇(2018)[12]将多数类样本依据类重叠度从大到小进行欠采样,保留对分类起决定性作用的支持向量;文献[13]保留了多数类中分布在分类决策面附近可用于构造特征边界的样本,减少了样本信息的流失。石洪波等(2019)[14]在多数类的欠采样中,基于安全样本的计算保留对确定决策边界有价值的样本和部分安全样本,丢弃噪声样本,结合SMOTE过采样处理后的少数类,实现了不平衡数据集的再平衡。
在实际应用中,数据集内部样本的分布密度有高和低的区别,密集区域聚集了大量的样本,区域内样本包含的特征信息较稀疏区域中的样本具有更高的价值和分类可靠性,在欠采样时应尽可能地选择保留。为了选择局部密集区域中的代表性样本构造平衡数据集,减少欠采样造成的分类信息损失,本文提出了一种利用自然最近邻的分布情况对多数类进行欠采样的数据处理方法。该方法先在数据集中计算多数类样本的自然最近邻,根据自然最近邻的分布情况移除多数类中的噪声样本和局部密度较小的样本;再计算剩余样本之间的相似度,依据相似度大小选择构造平衡数据集的多数类样本,丢弃冗余样本和相对密度较小的样本。
1 自然最近邻
自然最近邻是近年来提出的一种最近邻概念,样本的自然最近邻个数由各自的分布特征自适应生成,个数多少与样本分布的疏密程度有关。局部分布稀疏的样本所拥有的自然最近邻少于密集样本,而离群样本和噪声样本的自然最近邻个数相对更少甚至为0。考虑到自然最近邻反映出的样本分布疏密情况,有研究将其应用到聚类、离群点检测等领域。
假设有数据集X={x1,x2,…,xn},样本xi的自然最近邻如定义1所示。
定义1(自然最近邻):NNN(xi)表示样本xi的自然最近邻集合:
其中,NNk(xi)表示样本xi的k近邻集合,RNNk(xi)表示样本xi的k逆近邻集合。
由定义1得出,自然最近邻是一种对称的邻居关系,即样本xi和xj互为彼此的k近邻。与k近邻的计算相比,自然最近邻在搜索前无须指定任何参数,当所有的样本都有逆近邻或逆近邻个数为0的样本保持不变时,自然最近邻的搜索到达自然稳定状态,此时,搜索次数k被称为自然特征值,记为λ。
算法1描述了自然最近邻搜索算法的步骤。
算法1(自然最近邻搜索算法)
输入:数据集X。
输出:自然特征值λ、样本xi的自然最近邻集合NNN(xi)和数量NB(xi),1≤i≤|X|。
(1)初始化搜索次数k=1,NB(xi)=0,近邻集合NN(xi)=∅,逆近邻集合RNN(xi)=∅。
(2)计算xi的k近邻,更新NB(xi)、NN(xi)、RNN(xi)。
(3)k=k+1。
(4)当所有xi的RNN(xi)≠∅或集合{xi|RNN(xi)=∅}保持不变时,搜索过程到达自然稳定状态,λ=k-1,跳转到步骤(5),否则跳转到步骤(2)。
(5)计算所有样本的自然最近邻,NNN(xi)=NN(xi),返回λ、NNN(xi)和NB(xi)。
通过算法1可以得到所有样本的自然最近邻和数量,自然最近邻数量大于或等于λ的样本处于局部分布较为密集的区域,其余样本的局部密度较小。在不平衡数据集中,根据多数类样本的自然最近邻数量可以推测样本是否处于密集区域,如果多数类样本的自然最近邻集合中存在少数类样本,那么可以判定多数类样本距离少数类较近,甚至有可能为噪声样本。本文在确定了所有多数类样本的自然最近邻集合后,根据自然最近邻的分布情况移除噪声样本和部分分布较为稀疏的样本,选择局部密度较大的代表性样本构造平衡数据集。
2 基于自然最近邻的欠采样方法
本文利用多数类样本的自然最近邻所反映出的样本局部分布情况,提出了一种基于自然最近邻选择样本构造平衡数据集的欠采样方法(Undersampling Method based on Natural Nearest Neighbor,USNNN)。欠采样方法USNNN的实现包括四个步骤:
(1)利用算法1计算多数类样本在不平衡数据集中的自然最近邻。
(2)根据自然最近邻的数量和分布,将多数类样本分为四种类型,不同种类的样本采取不同的处理方法。
第一类:噪声样本。如果样本的自然最近邻个数大于0且所有的自然最近邻均属于少数类,那么可将此类样本判定为噪声点,为了减少其对分类模型性能的影响,在欠采样时将其移除。
第二类:离群样本。如果样本的自然最近邻个数为0,那么可判断此样本为多数类中的离群点,对分类的影响较小,在欠采样时将其移除。
第三类:稀疏样本。如果样本的自然最近邻均属于多数类且数量小于λ/2,那么根据自然最近邻的概念,此类样本位于较为稀疏的区域,样本特征对分类的影响较小,在欠采样时将其移除。
第四类:由不属于前三类的样本构成。其中,自然最近邻个数大于或等于λ/2且近邻均属于多数类的样本,处于局部密度相对较大的区域,且自然最近邻的个数越多,该样本的局部分布越密集,如果样本的自然最近邻具有相同的特点,那么样本与其自然最近邻可能分布在多数类内部某个子类簇的中心区域或距离中心较近,样本的保留能体现原始数据的主要分布结构信息。该类中其他样本的自然最近邻同时分布在少数类和多数类两个类别中,可推测此样本距离少数类较近,样本特征对训练分类模型有重要价值,在欠采样过程中可选择部分样本保留。由于此类样本的数量较多,且存在分布位置较为接近的冗余样本,因此USNNN算法将在后续步骤中对其做欠采样处理。
(3)在第四类样本中,计算任意两个样本之间的相似度,构造相似度矩阵。
样本xi和xj的相似度sim(xi,xj)可由公式(1)计算得到:
其中,inter(xi,xj)表示样本xi和xj共同拥有的自然最近邻的个数,其值越大,表示样本xi和xj在空间分布上越接近,相似程度越高,若两者不存在共同自然最近邻,则相似度为0;dist(xi,xj)是xi和xj之间的欧几里德距离,距离越近,相似度sim(xi,xj)的值越大,反之则越小。因此,由公式(1)定义样本间的相似性是合理的。
相似度矩阵的行数和列数与第四类样本的数量相同。
(4)根据相似度选择样本构造平衡数据集。挑选相似度矩阵中相似度最高的两个样本,将其中自然最近邻较多的样本保留,删除另外一个样本,并在相似度矩阵中删除两个样本对应的行和列,重复此步骤直到保留的样本个数与少数类样本的数量一致或相似度矩阵为空矩阵。当矩阵为空矩阵时,保留的多数类样本个数小于少数类,从第四类样本中随机选择部分样本加入平衡数据集。
算法2描述了USNNN的实现步骤。
算法2(基于自然最近邻的欠采样方法)
输入:不平衡数据集S。
输出:平衡数据集Sbal。
(1)将数据集S中的多数类样本和少数类样本分别划分到集合Smaj和Smin中,得到两类样本的个数Nmaj和Nmin。
(2)利用算法1计算Smaj中的所有样本在S中的自然最近邻,得到自然特征值λ、样本xi的自然最近邻集合NNN(xi)和自然最近邻的数量NB(xi),i=1,2,…,Nmaj。
(3)根据NNN(xi)和NB(xi),将噪声点、离群点和稀疏样本从Smaj中删除。
①定义噪声样本的集合S1、离群样本的集合S2和稀疏样本的集合S3,初始值均为∅。
②如果NB(xi)>0且NNN(xi)中的所有自然最近邻样本均属于Smin,那么样本xi为噪声点,将xi加入集合S1,执行操作Smaj=Smaj-S1和Nmaj=Nmaj-|S1|,将S1中的样本从Smaj中删除。若Nmaj≤Nmin,则将集合Smaj和Smin构造平衡数据集Sbal并输出,算法2结束,否则执行步骤③。
③如果NB(xi)=0,那么样本xi为离群点,将xi加入集合S2,执行操作Smaj=Smaj-S2和Nmaj=Nmaj-|S2|,将S2中的样本从Smaj中删除。若Nmaj≤Nmin,则将集合Smaj和Smin构造平衡数据集Sbal并输出,算法2结束,否则执行步骤④。
④如果NB(xi)<λ/2且NNN(xi)中的任意自然最近邻样本均属于Smaj,那么样本xi为多数类中的稀疏样本,将xi加入集合S3,执行操作Smaj=Smaj-S3和Nmaj=Nmaj-|S3|,将S3中的样本从Smaj中删除。若Nmaj≤Nmin,则将集合Smaj和Smin构造平衡数据集Sbal并输出,算法2结束,否则执行步骤(4)。
(4)对Smaj中剩余的第四类样本计算相似度,构造相似度矩阵M。M的行数和列数均等于Nmaj,第i行第j列位置上的元素值是样本xi和xj的相似度(1≤i,j≤Nmaj),可通过公式计算得到,inter(xi,xj)是xi和xj共有的自然最近邻的个数,dist(xi,xj)是两者之间的欧几里德距离。
(5)根据相似度的值挑选样本构造平衡数据集。
①定义集合S'maj表示平衡后的多数类样本集合,初始值为∅。
②选择矩阵M中最大的相似度值Mi,j,比较Mi,j对应的样本xi和xj的自然最近邻数NB(xi)和NB(xj),将自然最近邻数量较多的样本加入集合Sm'aj,并且在集合Smaj中移除xi和xj。将矩阵M的第i行和第j列删除,得到新的矩阵。重复执行此步骤直到或M为空矩阵。
③步骤②结束后,如果M为空矩阵且,那么在集合Smaj中随机挑选个样本加入Sm'aj,使,否则跳转到步骤④。
下页图1展示了应用USNNN方法对二维不平衡数据集欠采样的过程。图1(a)中的数据集包括200个样本,其中,少数类样本有50个,多数类样本有150个,在图1(a)中分别用“•”和“×”表示。多数类中包括多个子类簇,样本具有分布不平衡的特点,边界处和类内均包含密集区域和稀疏区域。使用算法2中的步骤(2)计算了所有多数类样本的自然最近邻后,通过步骤(3)确定多数类中的噪声样本、离群样本和稀疏样本,并在图1(b)和图1(c)中进行标记。在图1(b)中,噪声样本和离群样本分别用“▲”和“▼”表示。噪声样本的自然最近邻均属于少数类,位置处于少数类样本较多的区域。噪声样本的存在会对分类模型的训练产生干扰,在欠采样时应删掉。离群样本距离多数类样本较远,其特征对分类模型的影响较小,可以删除。图1(c)中的“◀”是由自然最近邻确定的稀疏样本,其所在区域的密度较小,样本特征的价值小于密集区域的样本,在欠采样过程中可移除。对图1(c)中的剩余样本使用算法2中的步骤(4)计算相似度矩阵后,使用步骤(5)挑选代表性样本构造平衡数据集,欠采样后的平衡数据集如图1(d)所示。与原始数据集相比,在多数类的各个类簇中,类内密度较大的代表性样本被保留,冗余样本和对训练分类模型价值较小的样本被移除。
3 实验
为了验证USNNN欠采样方法的分类效果,本文利用Random UnderSampling(RUS)、Cluster Centroids(CC)、TomekLinks(TL)、Edited Nearest Neighbors(ENN)和USNNN对来自KEEL[15]的12组数据集进行欠采样处理。表1列出了数据集的基本信息,IR是多数类样本数量和少数类样本数量的比值,表示不平衡率。在多类别数据集中,指定一个类别为少数类,其余类合并为多数类。在实验前,将所有样本的特征值归一化到[0,1]区间内。实验采用五折交叉验证的方法,各组训练集和测试集的IR与原数据集保持一致,各指标的实验结果取五组实验的平均值。USNNN方法使用Python实现,其余欠采样方法使用Python库imbalance-learn package中的代码,分类模型为支持向量机,核函数采用高斯核,使用Python库scikit-learn中的SVC代码实现。
本文采用召回率(Recall)、F-value和G-mean评估不同欠采样方法对不平衡数据集分类效果的影响。Recall、F-value和G-mean的计算过程由表2所示的混淆矩阵得到。表2中,正类代表少数类,负类代表多数类。

表2 混淆矩阵
召回率表示分类正确的少数类样本个数占所有少数类样本的比例,召回率越高,表示被正确分类的少数类样本越多。
G-mean同时衡量了分类器对多数类和少数类的识别能力,可用于衡量整体分类效果。
表3汇总了使用SVM对不同欠采样方法进行处理后的平衡数据集进行分类得到的F-value、G-mean和Recall的值,各项指标的最佳结果使用下划线表示。将五种欠采样方法在同一数据集、同一指标上的结果按照降序排列,结果最高的名次为1,依次递增,下页表4列出了五种方法在所有数据集中的平均排名。
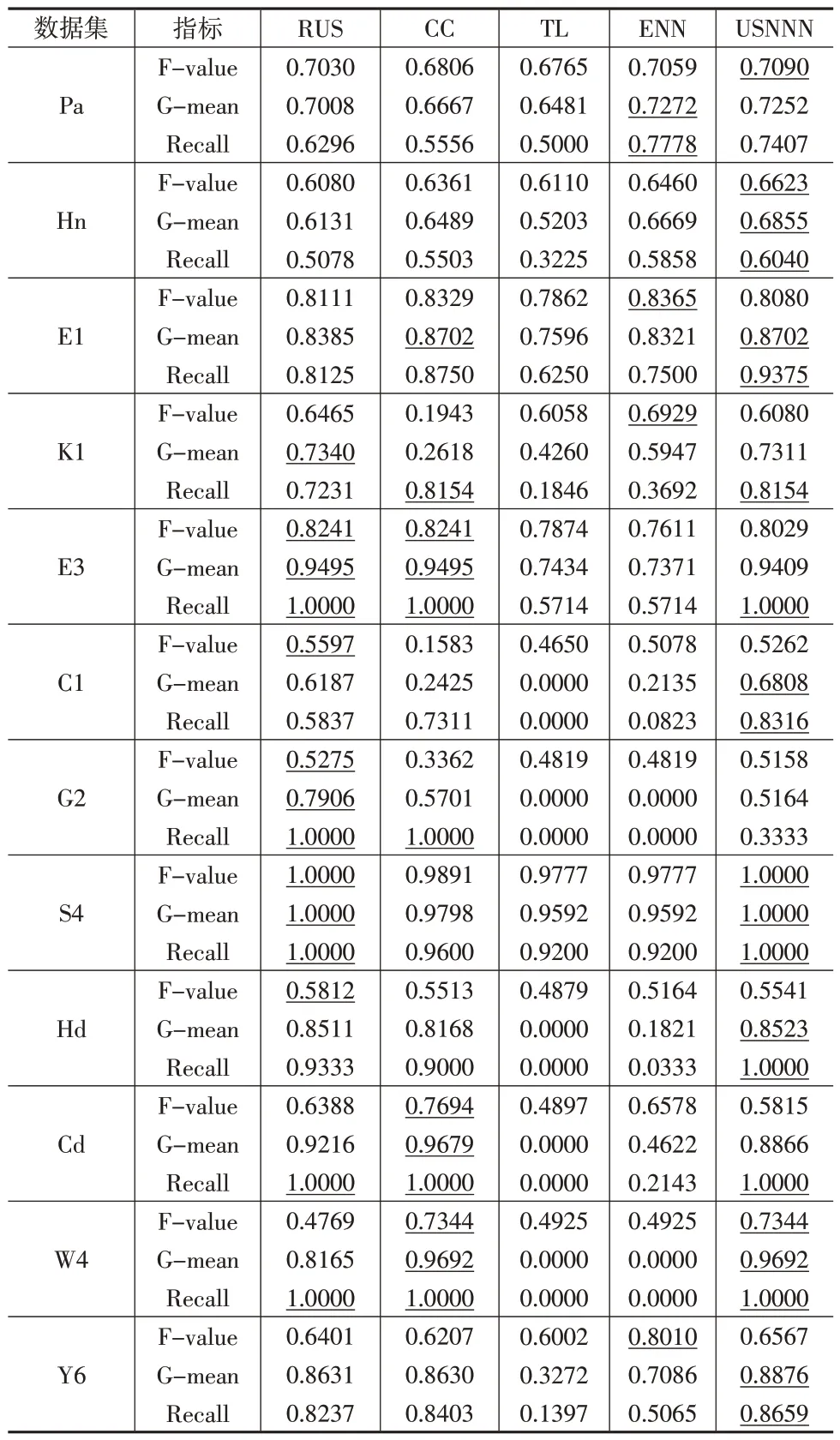
表3 SVM对不同欠采样方法构造的平衡数据集的分类结果

表4 不同欠采样方法在同一指标上的平均排名
对比表3中不同欠采样方法在指标F-value上得到的计算结果,本文方法USNNN在4个数据集上取得了最高的F-value值,在数据集C1、G2、Hd、Y6上的排名为第2,在数据集K1和E3上取得的名次为第3,在数据集E1和Cd上的排名较TL方法靠前。结合表4中显示的USNNN在指标F-value上获得了最高排名,可以发现USNNN方法对不平衡数据集中的少数类样本具有较高的识别准确率。对比G-mean的结果,USNNN在7个数据集上得到了最高的G-mean值,在数据集Pa、K1上获得的名次为第2,在数据集E3、Cd和G2上的排名为第3,在所有数据集上的平均排名为第1,说明USNNN对不平衡数据集的整体分类性能较好。USNNN在10个数据集上得到了最佳的Recall值,在数据集Pa和G2上的排名分别为第2和第3,平均排名为第1,说明USNNN对少数类样本的召回率普遍优于对比算法,能使分类器更加关注少数类样本。以上结果证明USNNN提高了对少数类样本的识别能力,是有效的欠采样方法。
4 结束语
本文提出了一种基于多数类样本的自然最近邻进行欠采样的不平衡数据处理方法。该方法先计算多数类样本在数据集中的自然最近邻,依据自然最近邻的分布情况移除噪声样本和稀疏样本;再根据剩余样本间的相似度,移除冗余样本,选择密集区域中的代表性样本构造平衡数据集。实验结果显示,本文方法提高了少数类样本的分类准确率,验证了本文方法的有效性。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
数学年刊A辑(中文版)(2020年3期)2020-10-27
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
中国房地产业(2016年9期)2016-03-01
噪声与振动控制(2015年4期)2015-01-01
西安交通大学学报(2014年8期)2014-04-16
振动、测试与诊断(2014年4期)2014-03-01
