
基于大数据分析与机器学习的OTT设备识别研究与实践*
2023-08-22 03:46:50丁洪鑫
计算机时代 2023年8期
周 维,汪 榕,丁洪鑫
(1.中电科大数据研究院有限公司,贵州 贵阳 550022;2.提升政府治理能力大数据应用技术国家工程研究中心)
0 引言
OTT(OverThe Top,OTT)指互联网公司越过运营商,发展基于开放互联网的各种视频及数据服务业务。在智能电视的浪潮下,很多家庭用户开始回归客厅,这促使OTT 大屏广告的崛起和发展。对于广告主来说更多的考虑在通过大数据、AI 技术等职能手段,了解用户,深度挖掘用户需求,推断用户特征,锁定目标受众将广告精准地投放给用户变得很重要,让用户不在是简简单单的看而是通过品牌印象刺激获得品牌曝光效果[1,2]。由于OTT 设备和手机设备极其相似,对APP 开发者和第三方推送厂商来说存在一个问题,就是他们并不知道哪些设备是OTT 设备,如何将OTT设备与手机设备区分开来,对OTT 业务能否深入开展有着决定性作用。
本文探讨结合数据清洗加工、数据分析、机器学习等技术建立OTT设备预测模型,实现了OTT设备从数据采集、数据清洗加工、数据分析、数据应用全链路的标准化的数据探索与研究,并通过建立机器学习模型,对OTT 设备与手机设备进行分类预测,这种OTT设备识别技术提高了OTT设备业务应用的准确性,减少了手机设备与OTT 设备区分不开带来的成本,为OTT业务的深入发展创造了有利条件。
1 OTT设备识别问题描述
OTT 设备和手机设备从系统角度还是APP 开发角度都极具相似性。简单地从数据采集的角度来看,是无法区分出OTT 设备与手机设备的,其根本原因可总结为以下六点:
⑴同一款APP既可以安装在手机上,也可以安装在电视上,且不同的终端设备上同一APP的ID是惟一的;
⑵在权限允许的情况下,OTT 设备和移动端设备在数据采集上没有区别;
⑶不同的设备数据具有不同的数据采集权限,数据采集不到和没有数据难以区分;
⑷OTT 设备的APP 应用难以枚举,仅知道部分头部的应用;
⑸OTT设备没有完整的机型列表;
⑹同一厂商不仅可以生产手机,也可以生产电视、手表、PAD等。
众所周知,每个手机都有各自的机型,类似地,OTT 设备也有自己的机型,另外,同一机型的设备有相同的特性,机型是一批设备的共有名字,能区分出一批设备。于是,为了解决OTT 设备识别问题,最好的方式是维护一份OTT机型表,从而将OTT设备识别问题转化为OTT机型识别问题。
2 OTT机型识别解决思路
如何去识别OTT 机型,就需要对原始区的数据进行清洗加工,数据分析与挖掘,找出同一种OTT 机型的共有特征,通过数据的简要分析之后,可以总结出OTT设备共有以下五个特点:
⑴ OTT 设备上很少装有微信、QQ、支付宝、12306 票等非视频类应用,排除有装的可能,但不影响大数据分析结果;
⑵OTT 设备基本上长期不动,所以每次汇报的位置数据基本相同;
⑶OTT 设备不具有通话功能,设备上没有IMEI号,而不是获取不到;
⑷ OTT 设备系统版本偏低,且很少存在系统版本变动;
⑸OTT 设备基本不会有手机号,也有部分设备可以插物联网卡和手机卡,如POS机、PAD。
带着这些基本特点,可以从数据采集、数据清洗加工、数据分析等流程对不同维度的数据进行分析、洞察,借助机器学习的方法找出OTT 设备区别于其他设备的不同之处,从而有效地识别出OTT设备。
3 实施方案
3.1 整体流程
OTT 设备识别流程包括确定分析目标、搜集数据、数据清洗加工、数据提取与分析等过程;在数据分析的过程中,借助机器学习来确定识别OTT 设备的规则,机器学习的过程又包括特征提取、模型建立、模型预测、结果解析与评价。
3.2 搜集数据
本文研究所依赖的数据来源于第三方推送公司。APP 开发者为了拥有更好的智能推送服务,采取集成第三方SDK,SDK通过加密采集的方式上报数据,最后通过大数据等相关的技术手段将数据传输到大数据集群的HDFS上,具体的数据获取流程为图1所示。

图1 数据获取流程
本文研究的数据来源主要有四类数据,包括设备属性、APP活跃、设备安装列表、设备位置,具体的数据源说明如表1所示。
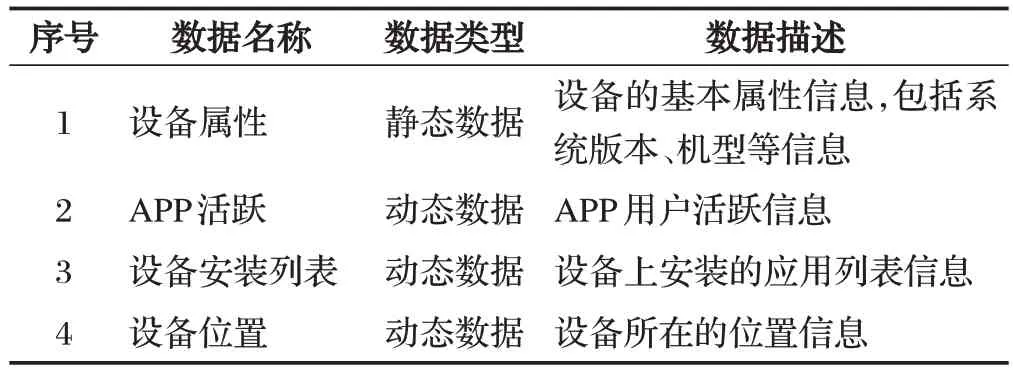
表1 数据源说明
3.3 数据清洗加工
3.3.1 数据清洗流程
对于上述四类数据,由于存在脏数据以及不完整的数据,对此,本研究按照标准的数据清洗标准制定了数据清洗流程,数据清洗流程如图2所示。

图2 数据清洗流程
3.3.2 数据清洗加工方法
数据清洗加工是指利用现有的数据挖掘手段和方法清洗“脏数据”,将“脏数据”转化为满足数据质量要求或应用要求的数据的过程。它是发现并纠正数据文件中可识别的错误的一道重要程序。用不同方法清洗的数据,对后续挖掘应用工作会产生不同的影响[3]。
对于3.2中所述四类数据源,我们采用了以下五种数据清洗加工方法,具体如表2所示。

表2 数据清洗加工方法
3.3.3 数据清洗结果
经过数据清洗加工后,一共生成三张主要的数据表,数据表详情如表3所示。
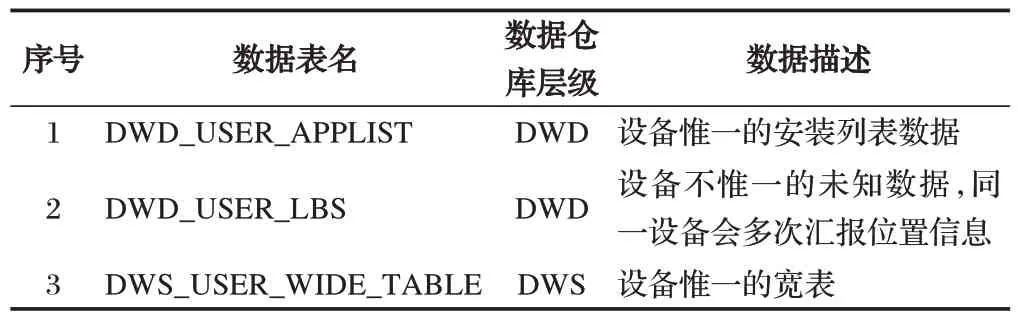
表3 清洗之后数据表详情
3.4 数据提取与分析
3.4.1 数据提取流程
⑴从DWS_USER_WIDE_TABLE 表提取安卓用户,字段信息为设备id、机型、系统版本、手机号码;
⑵从DWD_USER_APPLIST 表中提取排除安装有微信,QQ,支付宝,新浪微博,12306五个APP的数据;
⑶从DWD_USER_LBS 表中提取当天汇报三次及以上且最近三次汇报的位置信息一致的数据;
⑷步骤⑴、步骤⑵、步骤⑶关联,得到位置信息不变且没安装热门应用的设备数据;
⑸在步骤⑷的基础下,筛选出工作地和家庭地一致的数据。
3.4.2 数据分析方法
数据分析指利用恰当的统计、分析方法,对收集来的大量数据进行分析,将他们理解消化,提取有用信息加以详细研究和概括总结的过程,最大化地利用数据的功能,发挥数据的作用。大数据分析的核心是从大数据中找出可以辅助决策的隐藏模式、未知的相关关系以及其他有用信息的过程[4]。常见的数据分析方法如表4所示。

表4 数据清洗加工方法
3.4.3 数据分析结果
利用数据分析方法中的分层分析方法,分别计算出每个机型的用户数量、中国设备数量、中国设备占比、IMEI数量、IMEI占比、安卓8版本以下数量、安卓8版本以下占比、最主要系统版本、最主要系统版本数量、最主要系统版本占比、手机号数量、手机号占比等指标,数据分析结果样例如图3所示。将数据分析结果按照设备数降序取top30,筛选出的top30 机型中,通过人工校验比对,可以证实绝大部分机型都是OTT 设备机型。此时,通过简单地人工规则确定也能将OTT 设备机型区分出来,为了更加准确地确定筛选规则,接下来将借助机器学习技术来确定OTT机型的分类规则。

图3 数据分析结果
3.4.4 机器学习
⑴基本概念
机器学习是一门关于数据学习的科学技术,它能帮助机器从现有的复杂数据中学习规律,以预测未来的行为结果和趋势。例如:当用户在网上商城购物时,机器学习算法会根据该用户的购买历史来推荐其可能会喜欢的其他产品,以提升购买概率。机器学习的基本流程如图4所示。

图4 机器学习基本流程
其中模型评估与验证是整个模型构建中的最后一步,通过对模型的评估和验证能够得出所构建的相关性能指标,并判断模型是否具备实际运用的能力[5]。下面介绍几种常用的性能评估指标。
①准确率,表示正确分类的测试实例的个占测试实例总数的比例,计算公式为
② 精确率,也叫查准率,表示正确分类的测试实例的个数占试实例总数的比例,计算公式为
③召回率,也叫查全率,表示正确分类的正例个数占实际正例个数的比例,计算公式为:
④F1 分数,表示准确率和召回率的调和平均值,计算公式为:
⑤ 度量分类中的非均衡性的工具ROC 曲线(ROC Curve),TPR(True Positive Rate)表示在所有实际为阳性的样本中,被正确地判断为阳性的比率,即;FPR(False Positive Rate)表示在所有实际为阴性的样本中,被错误地判断为阳性的比率,即
⑥AUC 值(Area Unser the Curve)是ROC 曲线下的面积,AUC 值给出的是分类器的平均性能值。使用AUC值可以评估二分类问题分类效果的优劣,计算公式如下:
一个完美的分类器的AUC 为1.0,而随机猜测的AUC为0.5,显然AUC值在0和1之间,并且数值越高,代表模型的性能越好。
⑵模型构建与分析
接下来,将对3.4.3步骤中的数据分析结果数据进行模型构建,本文将采用决策树的方式进行OTT 机型的预测。在模型预测之前,首先要对数据进行打标,这里选择了400条数据进行打标,打标数据样式如图5所示。

图5 打标数据样式
决策树进行分类预测时,需要提前确定决策树的深度,但并不是决策树的深度越深,模型预测的结果就更准确。为了确定最优的模型参数,本文用PYTHON代码来校验并绘制决策树深度和错误率关系图,关系图如图6所示。
从图6 可以看到,当决策树在深度小于等于3 时错误率是最低的,当再次提升树的深度时,错误率就上升了;于是,根据图中结果分析之后,本文选取树的深度为2进行OTT机型预测分类。
在模型预测过程,还需要确认模型是否出现过拟合现象。为了准更加准确地验证模型的预测效果,本文通过PYTHON 代码绘制样本量和准确率的关系图,关系图如图7所示。从中可以看出,随着样本量增加,模型的准确率并没有出现异常的波动,由此可得,模型在预测过程中没出现过拟合现象。
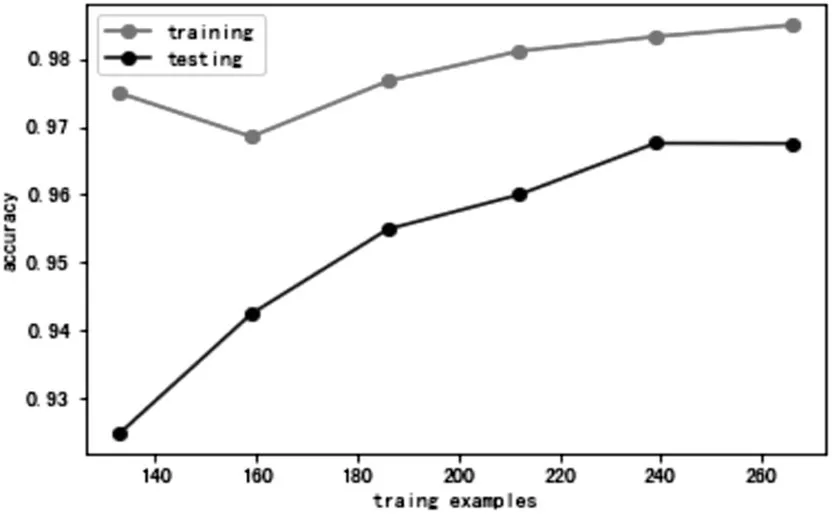
图7 样本量与准确率关系
⑶分类规则确定
最后,通过模型预测结果,就可以确定OTT 机型分类规则[6,7]。模型预测结果如图8所示。
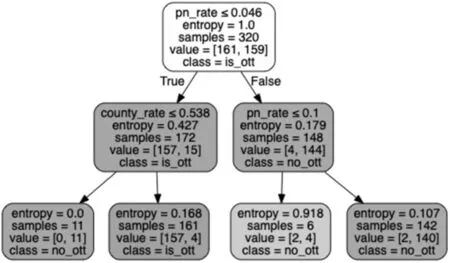
图8 模型预测结果
从图8 中可以看出,OTT 机型的训练集中,有320条数据,划分为两个类别,数量分别为161、159,对应的标签分别为is_ott、no_ott;当手机号数占比小于等于0.046 时,有172 个样本,2 个类别的数量分别为157、15,其中is_ott 的类别最多,信息熵为0.427,比上面节点要低,说明分类结果更加确定了;当中国用户占比大于0.538 时,有161 个样本,2 个类别的数量分别为157、4,其中is_ott的类别最多,信息熵变为0.168,此时说明分类结果变得更加确定了。
根据上面的分析可得,OTT 机型的分类规则为手机号数占比小于等于0.046且中国用户占比大于0.538。
⑷结果验证
为了验证模型的效果,选取200条数据进行验证,模型在预测集上的准确率为97.49%。所以,可以说该模型效果良好,能够有效地将OTT 机型分类规则确定下来并达到实现OTT机型分类的效果。
4 结束语
在研究与实践过程中,首先采用大数据采集、数据清洗加工、数据分析技术,对OTT 设备数据进行采集、汇集、清洗,采用不同的分析方法挖掘OTT 设备的隐藏价值。另外,本文有效地将数据分析和机器学习两者相结合,数据分析的结果对机器学习的特征选择和模型的建立打好了坚实的基础,而机器学习的结果又为数据分析提供了有力的帮助。最后,通过机器学习决策树模型区,确定了OTT机型和非OTT机型的筛选规则,从而得到了一份OTT 机型的维度表,因为每个设备的机型是确定的,所以,确定了OTT 机型就相当于确定了OTT设备,这样就解决了OTT设备的识别问题。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
民用飞机设计与研究(2020年4期)2021-01-21 09:15:26
家庭影院技术(2019年11期)2019-12-09 09:14:08
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
家庭影院技术(2019年1期)2019-01-21 02:25:02
电子制作(2018年16期)2018-09-26 03:27:06
电影(2018年8期)2018-09-21 08:00:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
