
基于多尺度加权特征融合的网络信息安全风险识别方法
2023-08-22 01:23吴秦鹏
通信电源技术 2023年13期
吴秦鹏
(国网兴平市供电公司,陕西 兴平 713100)
0 引 言
随着互联网技术的广泛普及和发展,使得日常的运营和商业交易依赖于网络信息与数字化技术。然而其为各项服务提供便利的同时,也使得网络空间产生安全隐患问题[1]。一方面,大多数企业在追求网络新技术的同时,忽略新技术可能存在的网络漏洞和网络本身存在的脆弱性问题[2]。另一方面,当前企业缺少专业的IT 技术人员对网络空间环境进行安全维护,对于网络信息安全防护方面的投资没有侧重点,造成重复投资、投资过多等问题[3]。虽提出多种用以实现对网络信息安全风险识别的方法,但现有方法部分仍然处于理论研究阶段,限制着网络信息安全风险识别发展,无法为保障网络信息安全提供条件。在电网运行中发生的各种故障、事故影响着电网的正常运行,为促进电力生产安全性提升及可持续发展,本文将引入多尺度加权特征融合方法,开展对网络信息安全风险识别方法的设计研究。
1 网络信息安全风险数据采集
对网络空间内电力安全生产过程中产生的安全风险数据进行采集和进一步的挖掘。在生产过程中可能存在的风险包括技术、管理、经济、环境等,针对能够充分反应各项风险的网络信息安全风险数据,其特征分布概率密度函数可表示为
式中:p(y|α,θ)为网络信息安全风险数据的特征分布概率密度函数;k为网络信息安全风险数据;αk为符合异构形式特征的表达函数;pk为网络信息的安全风险特征系数,其取值可以结合网络信息安全风险的分布特征进行关联性检测;μk为分布特征。假设在网络空间环境中存在一个节点mi,并且mi∈M,引入空间采样技术对网络信息安全风险预测和识别。给定网络信息安全风险识别的统计特征集,对网络信息传输信道中节点mi与其他节点在可观测范围内被感染的概率进行计算[4]。再结合信息跟踪方法,构建一个网络信道均衡调度函数,获取网络信息安全风险预测的统计特征量,公式为
式中:Etotal为网络信息安全风险预测的统计特征量;α1和α2为异构特征;d1n0、d2n0为分布时间序列;为网络信道均衡调度函数。对网络信息安全风险的统计特征进行分析,根据特征聚类得到的结果为后续网络信息安全风险的预测与识别提供依据[5]。
2 基于多尺度加权特征融合的电力安全生产风险分类
利用多尺度加权特征融合初步完成对电力安全生产风险威胁源的识别[6]。若加权特征融合系数为0,说明该子集合与该数组类别一致,计算求解出数组基尼因子,公式为
式中:Gi为数组的基尼因子;ai为网络信息在某一节点上出现的概率;m为该节点对应的标签序号。构建决策函数,该方法最大的限制是函数对于熵的依赖性。确定网络信息安全风险数据的矩阵特征,若选取的属性不是最优解,则会造成决策函数出现局部最优的情况,影响到后续识别结果的准确性[7]。在构造决策函数时,通过计算得出网络信息的增益率,达到最佳状态。设网络信息安全风险特征为X,则此时X存在一个解,将分类信息设置为S,直到S的倒数接近0,电力安全生产网络信息安全风险数据的增益值将会逐渐接近0[8]。将决策函数中的平衡因素引入算法,降低在决策函数构建过程中出现的多值偏差。
本文选择零熵值对节点进行量化评价,计算公式为
式中:E(R)为熵值计算结果;pq为带有决策行为的数据。将提取参数作为识别标准,归类为网络信息。得出熵值与电力安全生产风险指标体系中各个分类的标准熵值对比,并组成决策树分支,给决策树赋值。得出赋值结果后,将与其相对应的网络信息归类于相应的属性类别当中,实现对网络信息安全风险数据分类处理。
3 网络信息攻击路径预测与风险识别
采用自适应参量融合方式,对各电力安全生产风险进行网络信息攻击路径的预测。引入网络信息攻击路径预测窗口函数,公式为
式中:R2TR2为窗口函数;V2为信道均衡系数。当网络信息攻击路径预测窗口函数R2TR2的取值最小,提取反映网络信息安全风险的特征量。假设网络信息攻击路径内的安全风险代价函数为
式中:y(t)为安全风险代价函数;P为以实现网络信息攻击路径预测的关联维数;x(t)为完成网络信息攻击路径风险评价的施加序列;τ为时间延迟。构建网络信息攻击路径预测统计特征量,统计特征函数服从参数为的标准分布,得到网络信息安全风险评价的模糊评价集为
式中:Lteff为网络信息安全风险评价特征量;nj为自相关变量;Pjmin为网络信息安全风险检测负载迁移;P0min为决策变量。对网络信息安全风险的识别,可通过应用自适应寻优学习方法,得到准确风险评价特征量,根据函数输出的结果,实现对网络信息安全风险的自动识别,保障电力安全生产。
4 对比实验
将多尺度加权特征融合应用到网络信息安全风险识别中,提出全新的识别方法。依托某电力企业,获取其近几年的电力安全生产数据作为实验依据,设计对比实验。
实验中将基于数字技术的识别方法作为对照A组,将基于关联规则的识别方法作为对照B 组,将上述提出的基于多尺度加权特征融合的识别方法作为实验组。分别利用上述3 种识别方法,对同一网络运行环境中的信息安全风险进行识别,结果如表1 所示。
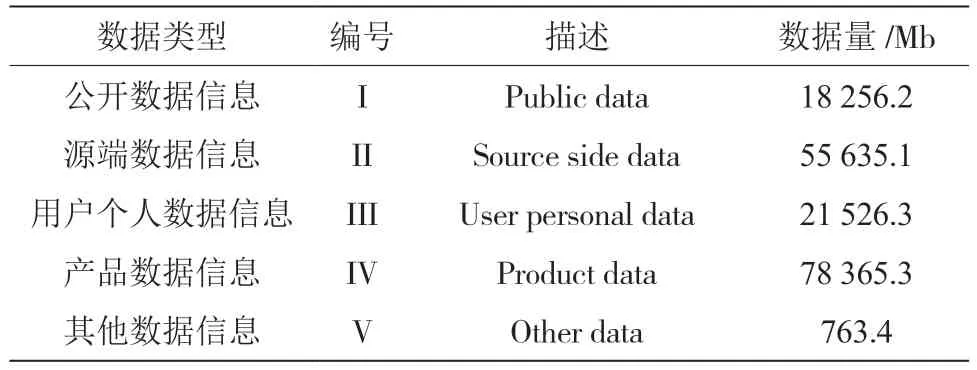
表1 识别结果
根据表1,将识别时间作为其识别速度的评价指标,在被识别的数据量相同的情况下,若识别所用的时间越短,则说明识别速度越高;若识别所用的时间越长,则说明识别速度越低。将上述3 种识别方法针对每一种类型数据的识别时间进行记录,结果如表2 所示。
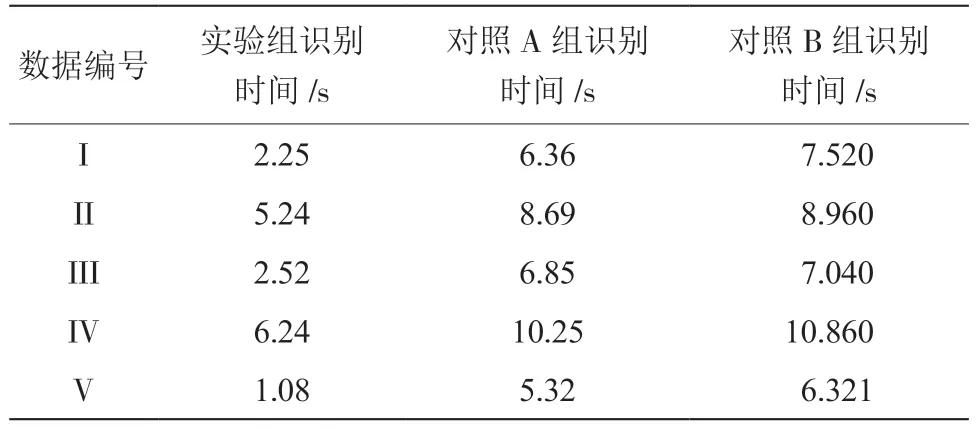
表2 3 种识别方法识别数据所用时间的对比
由表2 可知,3 种识别方法识别的数据量越多,识别所用的时间越长。对比看出明显实验组识别的时间最短,而对照A 组和对照B 组识别方法的识别时间较长,在对IV 类型数据识别时,时间超过10 s,严重不符合网络信息安全风险识别的时效性。结合本文实验得到的结果可初步验证,本文设计的基于多尺度加权特征融合的识别方法在实际应用中具备更高的识别速度。
为实现对3 种识别方法识别准确性的对比,选择将真阳率(True Positive Rate,TPR)作为量化评价指标。TPR 是正确识别数据量与实际归为该类别总量比值,利用指标可实现对3 种方法网络信息安全风险识别准确性的比较,计算公式为
式中:TPR(i)为利用识别方法正确识别某一类信息数据的准确率;ei为某一识别方法正确识别某一类型数据的数据量;Ei为某一类别实际安全风险总量。计算得出TPR(i),其取值范围为0 ~1。若取值越接近0,则说明该识别方法的识别准确性越低;若取值越接近1,说明该识别方法的识别准确性越高。对3 种识别方法识别结果的TPR(i)值进行统计,结果如图1 所示。
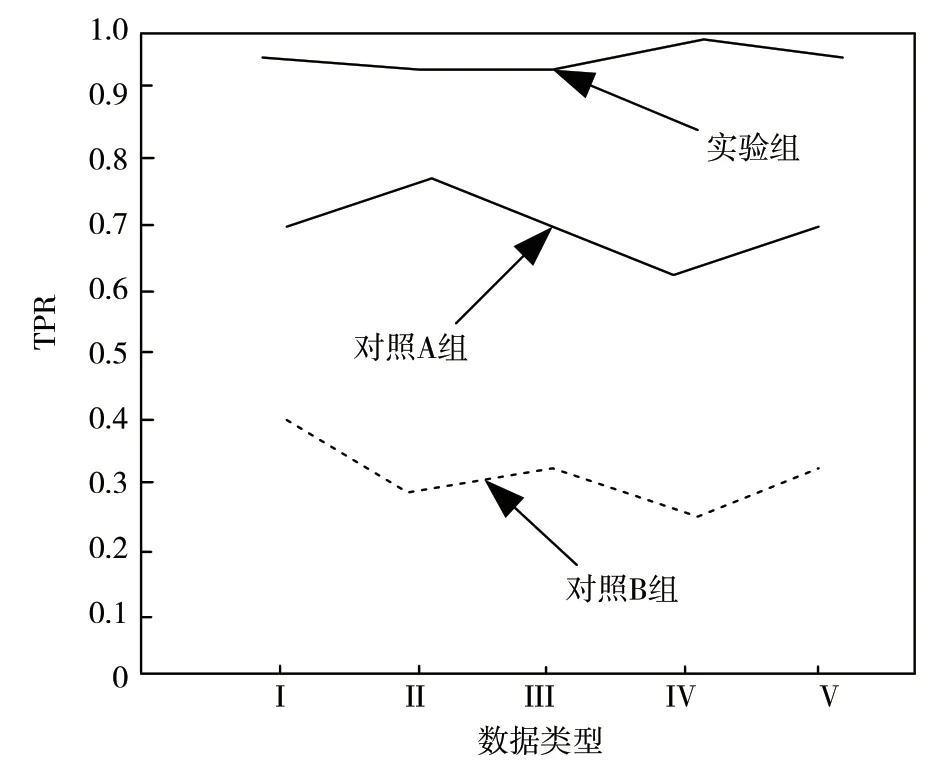
图1 3 种识别方法的识别结果
根据图1 得出,实验组针对每一种数据类型的TPR 值均最高,控制在0.9 以上;对照A 组识别方法的TPR 值较低,保持在0.6 ~0.8;对照B 组识别方法的TPR 值最低,最大值不超过0.4。表明实验组识别方法的识别准确性最高,其次为对照A 组,最后为对照B 组。
实验组识别方法无论是在识别速度上,还是在识别准确性上都具备更高的优势,在实际应用中的识别性能最强,同时能够促进电力安全生产数据利用价值的提升。
5 结 论
本文引入多尺度加权特征融合,提出全新安全风险识别方法,实验证明该识别方法具有广泛的应用条件。将该识别方法应用于实际可以有效促进网络空间环境中数据和信息安全性的提升,同时提升电力企业部署网络安全设备资产的安全能力,避免成为攻击利用的突破口,为用户提供更加安全的存储和传输服务,促进信息共享,加快数字化时代的前进步伐。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
现代企业文化(2018年13期)2018-06-09
消费导刊(2017年20期)2018-01-03
数学小灵通·3-4年级(2017年9期)2017-10-13
公民与法治(2016年21期)2016-05-17
