
基于Kafka 的跨节点消息队列容灾实践应用
2023-08-22 01:24林德煜
通信电源技术 2023年11期
林德煜
(中移互联网有限公司,广东 广州 510653)
0 引 言
消息队列中间件是一种为不同系统或同一系统内不同模块提供可靠异步网络通信的分布式框架,接收来自上游服务的消息,存储后转发至下游服务,在系统架构中起着承上启下的作用[1]。Kafka 是一个处理海量数据的分布式消息系统,具有高效的数据传输速率,相对于其他的消息队列系统具有较高的性能,采用发布/订阅模式,具有较强的可靠性、海量数据处理能力以及可拓展性,是不少业务平台选型队列和削峰填谷功能的很好选择[2]。
通常为了避免单点问题,高并发业务平台通常需要满足多节点部署。例如,业务平台有2 个节点A和节点B 同时对外提供服务,节点A 出现故障需要容灾切换时,通常会将网关入口全部切换到B 节点,如果A 节点中Kafka 队列存在未消费消息时,为了不影响业务,需要将A 节点的未消费数据在用户无感知的情况下同步到B 节点,并在B 节点继续消费。
1 Kafka 生产消费模式
Kafka 支持集群部署,它的数据由broker 负责存储和同步。Kafka broker 可以对队列(Topic)进一步分片,Producer 负责向broker 推送数据,Consumer 负责从broker 消费数据。
Kafka 支持消费者以不同的消费组消费相同的Topic,如图1 所示。图1 中:每个Topic 可以分为多个分区,如P0、P1、P2、P3;每个服务器负责部分分区,一个消费组中只有一个消费者能消费到特定分区,不同的消费组内消费者可以重复消费同一个特定分区,消费者可以同时消费多个分区。
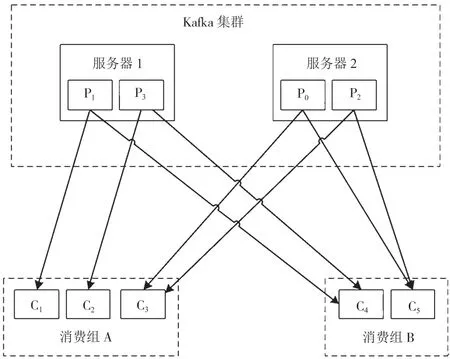
图1 Kafka 多消费组消费
2 同步选型
在实现数据同步的过程中,按照数据源节点的流量主要分为单向同步和双向同步[3]。对于要求实现业务双活节点的平台,一般需要实现双向同步。
2.1 Kafka 同步原理
Kafka 数据包含队列数据(包括队列自身的Offset)和消费组Offset 数据。这2 部分数据的同步对一个高可用系统来说至关重要。数据同步指当某一节点服务器产生一条数据时,需要把该数据实时同步到其他的节点中,以便其他节点完成必要的工作或提供相关服务[4]。基于性能考虑,通常采用定期同步的方式,将队列数据和Offset 数据从A 节点同步到备用B 节点。
为实现Kafka 不同节点的数据同步,可以在2 个节点之间引入中间件,模拟Kafka A 节点的消费者和B 节点的生产者,定期将Kafka 对应的消息数据、Topic 最新Offset 和消费组消费Offset 同步到B 节点。
2.2 Kafka 同步选型
了解了Kafka 的消费原理之后,可以选择官方/开源的第三方框架实现异地节点,也可以自己开发一套中间件实现类似功能,二者的优缺点都很明显。
(1)选择官方或开源的第三方工具。其优点是可靠性相对较高,具有一定的生态成熟度,资料文档相对完善,接入业务的时间相对较短。其缺点是相比自研工具,工具版本的更新相对不可控。
(2)选择自研工具。其优点是版本更新迭代和代码完全自主可控,缺点是开发周期时间长,成熟度需要时间。
综合时间、成熟度、业务需求考虑,本次研究采用了基于官方方案做优化改进的策略。
目前,最常用Kafka 跨节点同步工具是Kafka官方自带的Mirror Maker。Mirror Maker 在异地数据同步中广泛使用,可靠性和成熟度较高。目前,Mirror Maker 最新的版本为Mirror Maker2(以下简称MM2)。MM2 基于Kafka Connect 实现,支持跨节点复制Topics 数据以及配置信息,也支持复制消费组及其消费Topic 的Offset 信息;MM2 相比Mirror Maker有较大的优化和改善,对于同一个Topic 在不同节点中配置不同的前缀,同步时识别消息归属,从而解决回环问题。
通常Kafka 同步组件自身并不具备良好的进度检测,仅监控组件自身进程无法确定Kafka 是否已完成数据的同步。在实际应用中,引入一种基于滑动时间窗口的同步延迟检测算法,基于该算法开发脚本工具MQ_Sync_Monitor,只需要在源节点部署一套,负责从源节点A 到目标节点B 的同步延迟检测。
3 同步延迟检测算法
3.1 检测周期原理
滑动窗口指以固定窗口为单位不断进行更新,如果滑动窗口已满,那么最先进入滑动窗口的一个固定窗口被删除,滑动窗口随之更新一次[5]。
MM2 消费组Offset 同步时间配置字段为sync.group.offsets.interval.seconds,定义定期同步的时间为mq_sync_interval_seconds(以下简称MQ 同步时间MST)。该参数通常配置等于sync.group.offsets.interval.seconds,MQ 同步工具负责启动MQ 数据的同步,因为涉及A 节点和B 节点两边跨节点的输入输出(Input/Output,I/O)操作,该操作通常需要超过1 s 才能完成。
本算法处理周期保持跟MST 一致,称其为算法处理时间PT。
MQ 同步的Offset 数据不一致:MQ 对应的数据从A 节点同步到B 节点时,假设A 的某个Topic 最大Offset 为A_maxOffsetLast=10 000,消费者Z 对应的消费组Offset 为A_consumeOffset=8 000。
完全同步到B 节点之后,B 节点查询得到的该Topic 最大Offset 和消费者Z 对应的消费组Offset 可能为B_maxOffsetLast=5 000、B_consumeOffset=3 000。因此,A 和B 对应的Offset 数据通常不对等。
算法原理:MQ 同步非实时,所设计B 的跨度时间要包含A 的跨度时间,假设A 的Offset 增加值为A_Sub,如果B 在跨度时间内的Offset 增加值小于A_Sub,则说明存在同步延迟问题。滑动时间活动窗口如图2 所示。考虑间隔MPT 的同步操作可能刚好在算法处理时间PT 之前1 s 内执行,而通常同步操作可能需要超过1 s 才完成,所以即使是B 的2 次算法处理时间PT,Offset 同步上限仍然没办法确保包含A的1 次算法处理时间PT,因此需要计算B 的3 次算法处理时间PT。

图2 检测滑动窗口
实现中以4 个MQ 同步时间MST 为滑动时间窗口,假如MQ 的A 间隔一次算法处理时间PT 对应的Offset 差有变动(假设差值为A_Sub),而B 对应的差值小于A_Sub,即B[times]-B[times-3]<A_SUB,则产生警告。
3.2 算法逻辑
算法逻辑如图3 所示。

图3 MQ 同步延迟检测
首先,进行初始化。其代码为
针对每个topic,包含4 个long 类型数组和一个long 类型参数
A_maxOffset//代表A 节点某topic 对应的Offset
A_consumeOffset//代表A 消费Offset
B_maxOffset//代表B 某个topic 对应的Offset
B_consumeOffset//代表B 消费Offset
times=0 算法的实现需考虑times 超过最大值的处理。同时,建议数组采用循环数组方式,只保留最新4 个元素。
其次,定时执行进度监控,间隔时间为PT,该值和MPT 时间保持一致。
通过调用MQ 提供的脚本查询A 和B 节点MQ对应Topic 的Offset 和对应客户端消费组Offset。
对于单位时间内A 节点自身的Offset 变化较小(如变化为0),为节省计算资源,可以选择不做判断处理,分别引入Min_Delay_Latest_Offset 和Min_Delay_Consume_Offset 作为topic 同一个分片最新Offset 和消费组消费Offset 同步延迟检测判断阈值。
如果times ≥3(B 的PT 最少要从3 开始计算),则启动判断:判断A 节点的A_maxOffset[times-2]和A_maxOffset[times-3]的差值A_maxOffsetSub 是否大于Max_Delay_Max_Offset,如是,则判断B_maxOffset[times]和B_maxOffset[times-3]的差值是否小于A_maxOffsetSub,如是,提示当前topic 最大Offset 同步延迟告警;判断A 节点的A_consumeOffset[times-2]和A_consumeOffset[times-3]的差值A_consumeOffsetSub是否大于Max_Delay_Max_Offset,如是,则判断B_consumeOffset[times] 和B_consumeOffset[times-3] 的差值是否小于A_consumeOffsetSub,如是,提示当前topic 消费组Offset 同步延迟告警。无论如何,执行times++。
4 生产中的应用
在实际生产中,为了实现消息队列跨节点容灾,采用Kafka MM2 实现消息数据从源节点到目标节点的同步。同时,采用脚本语言,基于上述MQ 同步延迟检测算法实现了MQ 同步延迟检测工具MQ _Sync_Monitor。
在每个源节点部署一套MQ _Sync_Monitor 脚本工具,负责同步延迟的检测。需要注意的是,要实时监控MQ 同步工具和MQ _Sync_Monitor 脚本工具自身进程。生产中,可基于配置zabbix 或Prometheus 等工具实现进程的监控。通过实现该算法,当MQ 出现容灾异地切换时,可以较好地保障消息数据的一致性,从而保障业务的高可用性。
5 结 论
为了实现中移互联网有限公司业务消息队列异地容灾,采用Kafka 官方MM2 同步工具实现源节点到目标节点的数据同步,并引入了一种基于滑动时间窗口的同步延迟检测算法,基于该算法实现Kafka 跨节点同步检测工具。该工具在生产实践中很好地解决了高可用分布式系统中Kafka 集群跨节点同步延迟检测的盲区,并为内部其他项目的容灾提供了新的思路和借鉴。
猜你喜欢
小太阳画报(2020年11期)2020-12-10
小太阳画报(2020年10期)2020-10-30
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
制造技术与机床(2018年11期)2018-11-23
红领巾·成长(2018年10期)2018-11-19
意林(绘英语)(2018年1期)2018-04-28
产品可靠性报告(2017年7期)2017-09-05
读者(2017年18期)2017-08-29
