
基于无人机正射影像的高精地图车道线自动提取方法的研究
2023-08-21 09:39高正跃李春梅
无线互联科技 2023年12期
高正跃 李春梅


摘要:车道线作为实现精确导航和自动驾驶的基础信息,其采集方式自动化程度低、生产周期长,严重影响了高精地图的应用。因此,文章设计了一种利用无人机正射影像,基于U-Net语义分割模型,结合栅矢数据处理的高精地图车道线自动提取方法。文章利用Lovsz Loss完成20%样本的U-Net模型训练,实现了IoU在75%以上的车道线语义分割,且U-Net识别出的栅格车道线经过栅矢结合手段处理后即可得到高质量矢量车道线。文章设计的综合无人机倾斜摄影、深度学习、GIS数据处理的车道线提取方法可为高精地图车道线的获取提供一种新思路、新方法,为无人驾驶提供一种新的数据支持。
关键词:高精地图;无人机正射影像;车道线提取;U-Net;栅矢结合
中图分类号:P231.5 文献标志码:A
0 引言
高精地图[1](High-Definition Map)是一种可以提供高精细度以及高准确度地理信息的数字化地图。车道线作为高精地图一项重要的信息层,通过分析车道线的位置和形状,使车辆可以识别道路类型、车道数目、交通标志等信息,从而更好地理解道路环境和规划行驶策略。因此,车道线提取是高精地图生产的重要环节之一。
高精地图车道线的提取方式按照数据来源可分为基于卫星遥感影像、基于高分辨率无人机影像以及基于车载影像的车道线提取方法。现有的少量基于遥感影像的车道线提取研究如侯翘楚等[2]利用面向对象结合统计学的方法实现了从遥感影像中提取车道虚线、人行横道等车道要素;张世强等[3]利用车道线方向与面积因素从二值化道路中提取车道虚线。
基于高分辨率无人机影像的车道线提取研究大多采用深度学习结合图像处理的方法,现有如王立春等[4]采用Faster R-CNN目标检测框架从路面中检测车道线并连通域分析过滤非车道线噪声。袁鑫[5]利用BiSeNetV2实时语义分割网络分割出栅格车道线后通过图像处理算法实现了车道线的细化、实例化、矢量化,经过坐标转换后车道线精度达到了1.8~3.5 m。
自无人驾驶技术兴起以来,车道线提取研究大多基于车载影像展开。近年來,随着深度学习在图像处理领域的深入应用,基于卷积神经网络(Convolutional Neural Networks,CNN)[6]的方法是目前车道线检测的主流方法,如陈立潮等[7]提出了一种基于双分支卷积神经网络的车道线检测方法,该方法将车道线检测任务分为左右两个分支,同时考虑了道路几何信息和车道线的语义信息,此方法在国内的数据集上取得了较好的效果。此外,还有一些基于循环神经网络(Recurrent Neural Network, RNN)的车道线检测方法。例如,刘丹萍等[8]设计了循环神经网络检测车道线,该方法可以根据历史信息和当前信息预测未来的车道线位置。朱威等[9]通过循环神经网络模块融合提取多帧特征,并与单帧特征结合成融合模块,客观上提升了车道线检测精度。
上述车道线提取方法存在以下缺陷:(1)基于遥感影像的车道线提取成果皆为栅格格式,且此类车道线成果不具备高程信息,不满足高精地图级车道线要求;(2)基于无人机影像的车道提取研究尚显薄弱,目前针对无人机影像的车道线检测数据集甚少,且栅格形式的车道线经过多次处理及格式、坐标转换后,得到的矢量车道线成果存在米级的精度误差;(3)基于车载影像,采用深度学习提取车道线的方法存在数据集不充分导致模型的泛化能力与稳定性不佳的问题。同时,每次地图更新都需派遣搭载单源或多源传感器的数据采集车前往目标路段进行数据采集,使得车道线更新成本极为高昂。
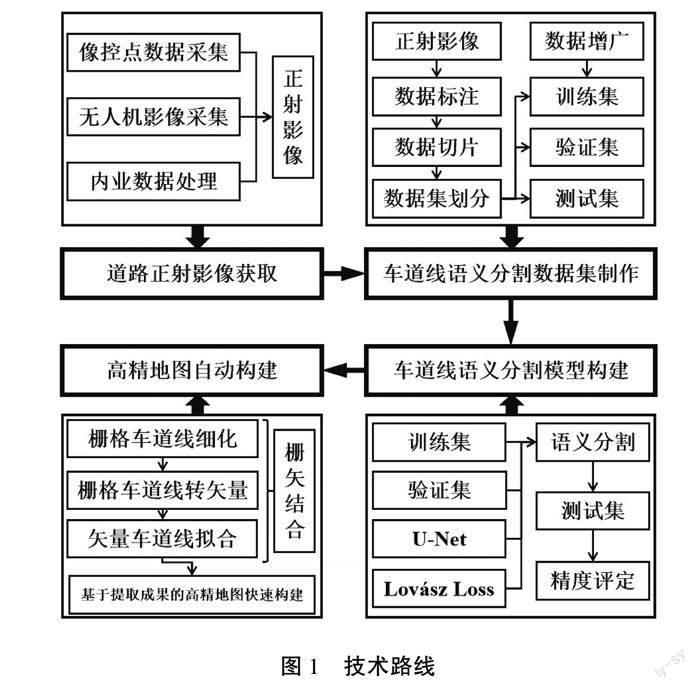
1 技术路线
针对上述问题,本文提出一种基于无人机正射影像,采用U-Net语义分割模型,结合栅格处理与矢量处理的快速构建高精地图的方法。该方法首先利用无人机技术快速获取目标路段正射影像,其次在采用U-Net模型的基础上,引入Lovsz损失函数替换原来的交叉熵损失函数,以加强网络对车道线特征的学习能力,最后利用栅格处理与矢量处理结合的手段完成栅格车道线的细化、矢量化及矢量车道线的拟合,得到可直接应用于高精地图构建的车道线成果。本文提出的高精地图车道线提取方法可提升高精地图的制作速度与更新效率,大大降低了高精地图的构建成本。
2 研究区域与数据制备
2.1 研究区域概况
本文以江苏省徐州市铜山区湘江路西段为研究区,地理位置为东经117°24′、北纬34°12′,道路宽度约为15 m,沥青路面,共有6~9股车道。研究区域形状为不规则多边形,长约1 800 m,宽约250 m,周长约为3.9 km,面积约为0.4 km2。
2.2 正射影像获取
研究人员使用GNSS-RTK连接千寻CORS进行采集像控点,采用大疆四旋翼无人机御Mavic Air 2,设定无人机相对航高为100 m,航向重叠率为80%,旁向重叠率为70%,共采集研究区影像451幅影像。影像大小为5 472×3 648像素,地面像幅约109×73 m。采用Context Capture软件将获取的影像数据处理成空间分辨率为3 cm的正射影像图(见图2)。
2.3 车道线语义分割数据集构建
采用ArcGISPro软件对获取的湘江路西段正射影像图上车道线做相应标注,裁剪到大小为256×256车道线图像及对应标签图像各5 960张。将分割后的影像分为训练集、验证集和测试集3部分,比例为2∶4∶4。其中,训练集用于训练模型,测试集用于验证模型分辨能力,验证集用于确定网络结构。为防止过拟合,本研究对训练集数据进行数据增广,增广方式包括:平移、水平翻转、随机裁剪、添加高斯噪声和90°、180°、270°旋转。训练集数据经过数据增广后被扩充至4 000组。
3 车道线语义分割模型构建
3.1 U-Net
U-Net模型是一种用于图像语义分割的卷积神经网络,它由编码器、中间层和解码器3部分组成。编码器用于对输入图像进行特征提取和降维,由4个下采样模块组成,每个下采样模块包含2个卷积层和1个最大池化层,其中,第一个卷积层的卷积核大小为3×3,输出通道数为64,第二个卷积层与第一个卷积层相同,但输出通道数翻倍。同理,第三、第四卷积层亦相同,但各自的通道数相较于前一层翻倍。最大池化层的大小为2×2,步长为2,用于将特征图的大小减半,实现图像的降维操作。中间层是由2个卷积层组成的,用于在编码器和解码器之间进行特征传递和融合,中间层由2个卷积层组成,每个卷积层的卷积核大小为3×3,输出通道数为512。解码器是由一系列上采样层和卷积层组成的,用于将编码器中抽取的特征映射还原为与原始图像大小相同的分割结果。每个上采样层通过转置卷积操作将特征图的大小扩大一倍,同时与对应的中间层特征图进行连接和融合,用于提取更多的细节信息和边缘特征。在上采样层之后,使用了2个卷积层进行特征融合和输出,输出通道数与分割目标的类别数相同。
3.2 Lovsz损失函数
图像语义分割任务中,传统的交叉熵損失函数适用于处理中等或大型目标的语义分割任务,但车道线语义分割问题属于典型的正负样本不平衡问题,即车道线通常只占图像的一小部分,导致车道线很难被正确分离出背景。为解决此问题,本文引入Lovsz损失函数替换原U-Net模型中的BCE损失函数。
Lovsz损失函数由匈牙利数学家Lszl Lovsz在1989年提出,旨在用于优化非光滑的、不可微的分类指标。Lovsz损失函数主要用于二分类问题,即每个样本只有2种可能的标签:正例或负例。神经网络模型在训练中,预测结果与真实标签之间通常会有一些误差。Lovsz损失函数的目标是将这些误差最小化,从而提高模型的性能。
具体而言,Lovsz损失函数度量预测结果与真实标签之间的差异,计算方式如式(1):
LLovász(f,y)=∑ni=1(f(xi),yi)(1)
其中,f(xi)是模型对第i个样本的预测结果,yi是该样本的真实标签,是Lovsz函数,n是样本数。
Lovsz函数的具体形式取决于问题的具体性质。对于二分类问题,通常使用的是二元Lovsz函数,定义如下:
binary(f,y)=maxσ∈sign(y)(σ·(f-y^))(2)
其中,sign(y)是标签y的符号函数,y^是样本的平均标签。符号函数将正例标签映射到+1,负例标签映射到-1。
在计算二元Lovsz函数时,首先对预测结果进行排序,然后按照排序后的顺序依次计算函数值。具体而言,假设有m个预测结果f(1),f(2),...,f(m),按照从大到小的顺序排列,令Sk=∑ki=1f(i),则binary(f,y)的计算方式如下:
binary(f,y)=∑mk=1wkmax(0,σk(Sk-σkwk))(3)
其中,wk是排序后第k个样本的权重,σk是排序后第k个样本的符号,即σk=sign(yk)。
使用Lovsz损失函数后,不仅可以有效地解决因正负样本不均衡导致的IoU评价指标低的问题,同样也可以使像素分类准确率得到一定程度的提升,提高模型进行车道线语义分割的性能。
3.3 语义分割精度验证
本文使用像素精度[10](Pixel Accuracy,PA)、交并比[10](Intersection over Union,IoU)2个指标来评估车道线语义分割模型的性能,其定义如下所示:
PA=TP+TNTP+TN+FP+FN(4)
IoU=TPTP+TN+FP(5)
式中,TP表示正确识别的车道线区域像素点的数量,FP表示非车道线区域像素而被识别为车道线区域像素点的数量,TN表示正确识别的非车道线区域像素点的数量,FN表示车道线区域像素被识别为非车道线区域像素点的数量。
4 栅矢结合
车道线语义分割模型仅获得以像素点集形式表达的面状车道线掩膜图像,由于其格式是栅格并非矢量,因此无法直接提取高精地图格式的车道线。对此,本文采用栅格处理与矢量处理结合的手段来提取车道线,首先通过图像细化算法将面状栅格车道线细化至单像素宽度,其次将单像素宽的栅格车道线转换为矢量车道线并进行拟合。
4.1 栅格车道线细化
4.1.1 相关定义
为介绍图像细化算法,首先给出一些重要的相关定义。
(1)像素八邻域。
像素八邻域指一个像素点P1周围的8个相邻像素点(P2,P3,P4,P5,P6,P7,P8,P9)。
(2)像素连通数。
像素连通数是指一个像素周围相邻像素中与其相连通(像素值相同)的像素数量。
4.1.2 Hilditch图像细化算法
Hilditch图像细化算法[11]是一种基于像素点的图像处理算法,用于将二值图像中的粗线条细化为单像素的线条。Hilditch算法的核心思想是在保持原始形状的前提下,删除尽可能少的像素点,以确保细化后的线条仍然可以准确地代表原始形状。其原理是通过对图像中的像素点进行判断和删除来实现细化,具体细化步骤如下:
(1)输入一幅二值图像,算法首先会将所有像素值为1的像素点设为前景像素点,所有像素值为0的像素点设为背景像素点。遍历图像中的所有像素点,对于每一个像素点P1,若是背景像素点,则跳过;若是前景像素点,则执行下一步骤。
(2)对于每个前景像素点P1,检查它是否满足式(5)中的4个条件,若满足,则将P1记为待删除点;
(a)2≤N(P1)≤6
(b)S(P1)=1(5)
(c)P2×P4×P6=0orS(P4)≠1
(d)P2×P4×P8=0orS(P2)≠1
式(5)中,N(P1)为像素点P1的8连通数;在像素点P1八邻域中按顺时针方向检索像素点,统计由0跨越至1的次数作为S(P1)的值。同理,S(P2)和S(P4)的值为分别在像素点P2、P4八邻域中顺时针方向像素值由0跨越至1的次数。
(3)删除所有记的待删除点,并更新图像,然后进入下一次迭代,直到图像没有需要删除的像素,算法结束。
4.2 矢量车道线提取拟合
车道线在经过细化处理后,首先采用ArcGIS工具箱中的栅格转折线工具完成栅格车道线至矢量车道线的转换,此时得到的矢量车道线并非平滑的直线 或曲线,而是带有噪声结点的折线段,故最后需采用ArcGIS的PAEK平滑线工具去除车道线噪声结点,以达到拟合车道线的目的。
5 实验结果与分析
5.1 U-Net模型训练及车道线识别
实验基于Pytorch深度学习框架,使用NVIDIA GTX 1660 GPU進行计算,同时采用cuDnn11.0库进行加速。在语义分割模型训练过程中采用数据增广策略,将训练集、验证集分别放入采用BCE Loss与Lovsz Loss的U-Net模型中进行训练、验证,设置批大小为2,迭代周期设置为200次,初始学习率设为0.001,选择Adam作为优化器。不同损失函数精度对比结果如表1所示,车道线语义分割效果如图4所示。
表1中,Lovsz函数两项精度评价指标均优于BCE函数,相较于BCE损失函数,Lovsz损失函数在IoU上提升了0.189 8,在PA上提升了0.012 6。因此采用Lovsz函数的U-Net模型的车道线分割效果应明显优于BCE函数。
5.2 栅矢结合提取车道线
以语义分割模型识别出的栅格车道线为数据源,利用Hilditch细化算法进行实验测试,实验结果如图4(c)和(d)所示。
栅格车道线在经过细化处理后,利用ArcGIS工具箱中的栅格转折线工具完成栅格车道线至矢量车道线的转换,此时得到的矢量车道线并非平滑的直线或曲线,而是带有噪声结点的折线段,如图5(a)和(b)所示。最后采用ArcGIS的PAEK平滑线工具对细化后栅格车道线进行拟合,图5为同方向直车道线与曲车道线拟合前后的结果对比,由图5可知,该方法可有效去除车道线噪声结点,使车道线平滑性更好、延展性更佳。
5.3 基于车道线提取成果的高精地图构建
将所有的栅格车道线经过细化后转为矢量并拟合,最后得到矢量车道线。基于本文方法提取的矢量车道线成果,使用MPC高精地图绘制软件进行车道线图层制作。本文自动提取的车道线主要为长线与短线两种基本车道线图层,如图6所示,部分车道线虽不完整,但精度满足要求,编辑时可直接吸附对应车道位置,大大提高了高精地图的生产效率。
通过对长线与短线进行简单的复制、平移、拓扑关系修正、编辑属性等处理之后,可得到车道边界线、车道中心线、路边线以及路面线(见图7)。以上图层往往需要以人工方式逐个提取,而本文自动提取的结果在经过简单编辑后可直接生产出高精地图车道线相关图层。
6 结语
本文以辅助无人驾驶技术、推动数字测绘向智能测绘的转型为主要目的,开展面向高精地图的无人机正射影像车道线自动提取研究,主要取得了以下研究成果:针对无人机正射影像车道线自动提取的需求,以江苏省徐州市铜山区湘江路西段为实验区,基于无人机倾斜摄影技术获得目标路段3 cm分辨率正射影像,据此构建了车道线语义分割数据集,以用于车道线语义分割模型的训练、测试及验证;基于Lovsz损失函数的小样本车道线语义分割。基于卷积神经网络及语义分割理论,对BCE及Lovsz两种损失函数U-Net模型车道线语义分割精度进行实验对比,Lovsz函数在IoU与PA两项精度评价指标精度均高于BCE函数,可改善车道线语义分割的效果;栅矢结合提取高精度车道线。为实现车道线识别结果转为高精地图格式,通过图像细化算法对面状栅格车道线进行处理得到单像素宽的栅格车道线,最后采用ArcGIS工具箱中的栅格转折线工具与PAEK平滑线工具完成车道线的提取拟合。利用本文方法自动提取的车道线成果可直接用于生产高精地图车道线相关图层,提高了车道线数据的采集与更新效率,从而降低高精地图的构建成本。
参考文献
[1]吴喜庆,吴征,周怡博.我国高精地图产业发展现状及政策建议[J].汽车文摘,2022(7):1-4.
[2]侯翘楚,李必军,蔡毅.高分辨率遥感影像的车道级高精地图要素提取[J].测绘通报,2021(3):38-43.
[3]张世强,王贵山.基于高分辨率遥感影像的车道线提取[J].测绘通报,2019(12):22-25.
[4]王立春.基于无人机航拍的公路标线提取与破损检测的研究与实现[D].南京:南京航空航天大学,2018.
[5]袁鑫.具备自主进化能力的无人机视角车道标线识别算法[D].武汉:武汉大学,2022.
[6]KIM D H, HA J E. Lane detection using a fusion of two different CNN architectures[J]. Journal of Institute of Control,Robotics and Systems, 2019(9):753-759.
[7]陈立潮,徐秀芝,曹建芳,等.引入辅助损失的多场景车道线检测[J].中国图象图形学报,2020(9):1882-1893.
[8]劉丹萍,汪珺,葛文祥.面向园区场景的车道线局部定位检测方法研究[J].重庆工商大学学报(自然科学版),2022(4):19-25.
[9]朱威,欧全林,洪力栋,等.基于图像序列的车道线并行检测网络[J].模式识别与人工智能,2021(5):434-445.
[10]于营,王春平,付强,等.语义分割评价指标和评价方法综述[J].计算机工程与应用,2023(6):57-69.
[11]NACCACHE N J, SHINGHAL R. An investigation into the skeletonization approach of hilditch[J]. Pattern Recognition, 1984(3):279-284.
(编辑 王雪芬)
Research on automatic extraction of lane lines in high-definition map
based on UAV orthophoto
Gao Zhengyue, Li Chunmei*
(School of Geography, Geomatics and Planning, Jiangsu Normal University, Xuzhou 221116, China)
Abstract: Lane lines as the basic information to realize accurate navigation and autonomous driving, the current acquisition method has low automation and long production cycle, which seriously affects the application of high-definition maps. Therefore, this paper designs an automatic lane line extraction method for high-definition maps using UAV orthophoto, based on U-Net semantic segmentation model, combined with raster vector data processing. In the experiment, the U-Net model is trained with 20% of the samples using Lovsz Loss, and the semantic segmentation of lane lines with IoU above 75% is achieved, and the raster lane lines identified by U-Net can be processed by combining raster and vector means to obtain high quality vector lane lines. The lane line extraction method designed in this paper, which integrates UAV tilt photography, deep learning and GIS data processing, can provide a new idea and method for acquiring lane lines in high-definition maps and provide a new data support for autonomous driving.
Key words: high-definition map; UAV orthphoto; lane line extraction; U-Net; raster vector combination
